Vor einiger Zeit haben wir
eine Veröffentlichung
angekündigt und unter der MIT-Lizenz den Quellcode von
LuaVela eröffnet - eine Implementierung von Lua 5.1, basierend auf LuaJIT 2.0. Wir haben 2015 damit begonnen, daran zu arbeiten, und Anfang 2017 wurde es in mehr als 95% der Projekte des Unternehmens verwendet. Jetzt möchte ich auf den zurückgelegten Weg zurückblicken. Welche Umstände haben uns veranlasst, eine eigene Implementierung einer Programmiersprache zu entwickeln? Auf welche Probleme sind wir gestoßen und wie haben wir sie gelöst? Wie unterscheidet sich LuaVela von anderen LuaJIT-Gabeln?
Hintergrund
Dieser Abschnitt basiert auf unserem
Bericht über HighLoad ++. Seit 2008 nutzen wir Lua aktiv, um die Geschäftslogik unserer Produkte zu schreiben. Zuerst war es Vanille Lua und seit 2009 - LuaJIT. Das RTB-Protokoll legte einen engen Rahmen für die Verarbeitung der Anforderung fest, sodass der Übergang zu einer schnelleren Implementierung der Sprache eine logische und ab einem gewissen Punkt notwendige Lösung war.
Im Laufe der Zeit stellten wir fest, dass die LuaJIT-Architektur gewisse Einschränkungen aufweist. Das Wichtigste für uns war, dass LuaJIT 2.0 ausschließlich 32-Bit-Zeiger verwendet. Dies führte zu einer Situation, in der unter 64-Bit-Linux die Größe des virtuellen Adressraums des Prozessspeichers auf ein Gigabyte begrenzt wurde (in späteren Versionen des Linux-Kernels wurde diese Grenze auf zwei Gigabyte angehoben):
void *ptr = mmap((void *)MMAP_REGION_START, size, MMAP_PROT, MAP_32BIT | MMAP_FLAGS, -1, 0);
Diese Einschränkung wurde zu einem großen Problem - bis 2015 reichten 1-2 Gigabyte Speicher für viele Projekte nicht mehr aus, um die Daten zu laden, mit denen die Logik arbeitete. Es ist anzumerken, dass jede Instanz der virtuellen Lua-Maschine Single-Threaded ist und nicht weiß, wie Daten mit anderen Instanzen geteilt werden sollen. Dies bedeutet, dass in der Praxis jede virtuelle Maschine eine Speichergröße von nicht mehr als 2 GB / n beanspruchen kann, wobei n die Anzahl der Worker-Threads unseres Servers ist Anwendungen.
Wir haben verschiedene Lösungen für das Problem durchlaufen: Wir haben die Anzahl der Threads in unserem Anwendungsserver reduziert, versucht, den Zugriff auf Daten über LuaJIT FFI zu organisieren, und den Übergang zu LuaJIT 2.1 getestet. Leider waren alle diese Optionen entweder wirtschaftlich nachteilig oder auf lange Sicht nicht gut skalierbar. Das einzige, was uns noch blieb, war, ein Risiko einzugehen und LuaJIT zu teilen. In diesem Moment haben wir Entscheidungen getroffen, die das Schicksal des Projekts maßgeblich bestimmt haben.
Zunächst beschlossen wir sofort, keine Änderungen an der Syntax und Semantik der Sprache vorzunehmen, und konzentrierten uns darauf, die architektonischen Einschränkungen von LuaJIT zu beseitigen, die sich als Problem für das Unternehmen herausstellten. Natürlich haben wir im Verlauf des Projekts begonnen, Erweiterungen hinzuzufügen (wir werden dies weiter unten diskutieren) - aber wir haben alle neuen APIs aus der Standard-Sprachbibliothek isoliert.
Darüber hinaus haben wir plattformübergreifend aufgegeben und nur Linux x86-64 unterstützt, unsere einzige Produktionsplattform. Leider hatten wir nicht genügend Ressourcen, um die gigantische Menge an Änderungen, die wir an der Plattform vornehmen würden, angemessen zu testen.
Ein kurzer Blick unter die Motorhaube der Plattform
Mal sehen, woher die Beschränkung der Zeigergröße kommt. Zunächst ist die Typennummer in Lua 5.1 (mit einigen geringfügigen Einschränkungen) der C-Typ double, der wiederum dem vom IEEE 754-Standard definierten Typ mit doppelter Genauigkeit entspricht. Bei der Codierung dieses 64-Bit-Typs wird der Wertebereich für die Darstellung hervorgehoben NaN. Insbesondere, wie ein Wert im Bereich [0xFFF8000000000000; 0xFFFFFFFFFFFFFFFF].
Auf diese Weise können wir entweder eine „echte“ Zahl mit doppelter Genauigkeit oder eine Entität in einen einzelnen 64-Bit-Wert packen, die aus Sicht des Typs double als NaN interpretiert wird, und aus Sicht unserer Plattform ist sie etwas aussagekräftiger - zum Beispiel. durch den Objekttyp (hohe 32 Bit) und einen Zeiger auf seinen Inhalt (niedrige 32 Bit):
union TValue { double n; struct object { void *payload; uint32_t type; } o; };
Diese Technik wird manchmal als NaN-Tagging (oder NaN-Boxing) bezeichnet, und TValue beschreibt im Wesentlichen, wie LuaJIT variable Werte in Lua darstellt. TValue hat auch eine dritte Hypostase, die zum Speichern eines Funktionszeigers und von Informationen zum Abwickeln des Lua-Stapels verwendet wird, dh letztendlich sieht die Datenstruktur folgendermaßen aus:
union TValue { double n; struct object { void *payload; uint32_t type; } o; struct frame { void *func; uintptr_t link; } f; };
Das Feld frame.link in der obigen Definition ist vom Typ uintptr_t, da es in einigen Fällen einen Zeiger speichert und in anderen eine Ganzzahl ist. Das Ergebnis ist eine sehr kompakte Darstellung des Stapels der virtuellen Maschine - tatsächlich handelt es sich um ein TValue-Array, und jedes Element des Arrays wird situativ entweder als Zahl, dann als typisierter Zeiger auf ein Objekt oder als Daten über den Rahmen des Lua-Stapels interpretiert.
Schauen wir uns ein Beispiel an. Stellen Sie sich vor, wir haben mit LuaJIT diesen Lua-Code begonnen und einen Haltepunkt innerhalb der Druckfunktion festgelegt:
local function foo(x) print("Hello, " .. x) end local function bar(a, b) local n = math.pi foo(b) end bar({}, "Lua")
Der Lua-Stapel sieht an dieser Stelle folgendermaßen aus:

Und alles wäre in Ordnung, aber diese Technik beginnt zu scheitern, sobald wir versuchen, auf x86-64 zu starten. Wenn wir im Kompatibilitätsmodus für 32-Bit-Anwendungen ausgeführt werden, lehnen wir die oben bereits erwähnte mmap-Einschränkung ab. Und 64-Bit-Zeiger funktionieren überhaupt nicht sofort. Was zu tun ist? Um das Problem zu beheben, musste ich:
- Erweitern Sie TValue von 64 auf 128 Bit: Auf diese Weise erhalten wir auf einer 64-Bit-Plattform eine „ehrliche“ Lücke *.
- Korrigieren Sie den Code der virtuellen Maschine entsprechend.
- Nehmen Sie Änderungen am JIT-Compiler vor.
Das Gesamtvolumen der Änderungen erwies sich als sehr bedeutsam und entfremdete uns ziemlich vom ursprünglichen LuaJIT. Es ist erwähnenswert, dass die TValue-Erweiterung nicht die einzige Möglichkeit ist, das Problem zu lösen. In LuaJIT 2.1 haben wir den LJ_GC64-Modus implementiert. Peter Cawley, der einen enormen Beitrag zur Entwicklung dieser Arbeitsweise geleistet hat, las bei einem Treffen in London darüber. Nun, im Fall von LuaVela sieht der Stapel für dasselbe Beispiel folgendermaßen aus:
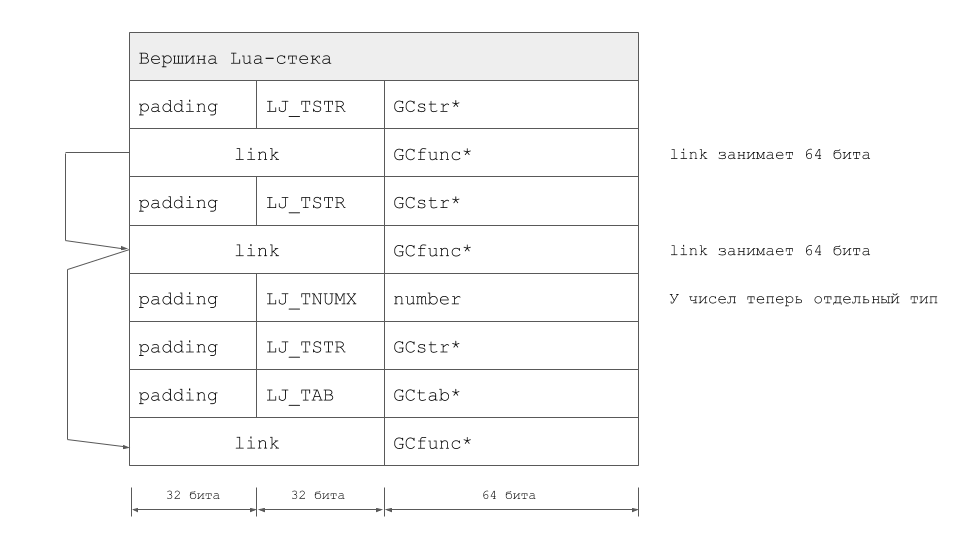
Erste Erfolge und Stabilisierung des Projekts
Nach Monaten aktiver Entwicklung ist es Zeit, LuaVela im Kampf auszuprobieren. Als Experiment haben wir die problematischsten Projekte in Bezug auf den Speicherverbrauch ausgewählt: Die Datenmenge, mit der sie arbeiten mussten, überstieg offensichtlich 1 Gigabyte, sodass sie gezwungen waren, verschiedene Problemumgehungen zu verwenden. Die ersten Ergebnisse waren ermutigend: LuaVela war stabil und zeigte eine bessere Leistung im Vergleich zu der in denselben Projekten verwendeten LuaJIT-Konfiguration.
Gleichzeitig stellte sich die Frage nach dem Testen. Glücklicherweise mussten wir nicht bei Null anfangen, da wir vom ersten Tag der Entwicklung an zusätzlich zu den Staging-Servern Folgendes zur Verfügung hatten:
- Funktions- und Integrationstests eines Anwendungsservers, der die Geschäftslogik aller Unternehmensprojekte ausführt.
- Tests einzelner Projekte.
Wie die Praxis gezeigt hat, reichten diese Ressourcen völlig aus, um das Projekt zu debuggen und auf einen stabilen Mindestzustand zu bringen (sie haben eine Entwickler-Assembly durchgeführt - auf Staging ausgerollt - es funktioniert und stürzt nicht ab). Andererseits war ein solches Testen durch andere Projekte auf lange Sicht völlig ungeeignet: Ein Projekt mit einer solchen Komplexität wie der Implementierung einer Programmiersprache kann keine eigenen Tests haben. Darüber hinaus erschwerte das Fehlen von Tests direkt im Projekt die Suche und Korrektur von Fehlern rein technisch.
In einer idealen Welt wollten wir nicht nur unsere Implementierung testen, sondern auch eine Reihe von Tests durchführen, mit denen wir sie anhand der
Semantik der Sprache validieren können. Leider erwartete uns in dieser Angelegenheit eine gewisse Enttäuschung. Trotz der Tatsache, dass die Lua-Community bereitwillig Gabeln bestehender Implementierungen erstellt, fehlten bis vor kurzem ähnliche Validierungstests. Die Situation änderte sich zum Besseren, als François Perrad Ende 2018 das Projekt lua-Harness
ankündigte .
Am Ende haben wir das Testproblem geschlossen, indem wir die vollständigsten und repräsentativsten Testsuiten im Lua-Ökosystem in unser Repository integriert haben:
- Tests, die von den Erstellern der Sprache für die Implementierung von Lua 5.1 geschrieben wurden.
- Von der Community bereitgestellte Tests des LuaJIT-Autors Mike Pall.
- Lua Geschirr
- Eine Teilmenge der vom CERN entwickelten Tests des MAD- Projekts.
- Zwei Testreihen, die wir in IPONWEB erstellt haben und die bis jetzt noch aufgefüllt werden: eine für Funktionstests der Plattform, die andere mit dem cmocka- Framework zum Testen der C-API und alles, was auf Lua-Code-Ebene nicht getestet werden kann.
Die Einführung jeder Testreihe ermöglichte es uns, 2-3 kritische Fehler zu erkennen und zu korrigieren - daher ist es offensichtlich, dass sich unsere Bemühungen gelohnt haben. Obwohl das Thema des Testens von Sprachlaufzeiten und Compilern (sowohl statisch als auch dynamisch) wirklich unbegrenzt ist, glauben wir, dass wir eine ziemlich solide Grundlage für eine stabile Entwicklung des Projekts gelegt haben. Wir haben zweimal auf der
Lua in Moskau 2017 und auf der
HighLoad ++ 2018 über die Probleme beim Testen unserer eigenen Implementierung von Lua gesprochen (einschließlich Themen wie Arbeiten mit
Testbänken und Postmortem-Debugging). Jeder, der sich für Details interessiert, kann sich ein Video dieser Berichte ansehen. Schauen Sie sich natürlich das
Testverzeichnis in unserem Repository an.
Neue Funktionen
So verfügten wir über eine stabile Implementierung von Lua 5.1 für Linux x86-64, die von den Kräften eines kleinen Teams entwickelt wurde, das das LuaJIT-Erbe und das gesammelte Fachwissen schrittweise „beherrschte“. Unter solchen Bedingungen wurde der Wunsch, die Plattform zu erweitern und Funktionen hinzuzufügen, die weder in Vanilla Lua noch in LuaJIT enthalten sind, uns aber bei der Lösung anderer dringender Probleme helfen würden, ganz natürlich.
Eine detaillierte Beschreibung aller Erweiterungen finden Sie in der
Dokumentation im RST-Format (verwenden Sie cmake. && make docs, um eine lokale Kopie im HTML-Format zu erstellen). Eine vollständige Beschreibung der Lua-API-Erweiterungen finden Sie
unter diesem Link und der C-API unter
diesem Link . Leider ist es in einem Übersichtsartikel unmöglich, über alles zu sprechen. Hier ist eine Liste der wichtigsten Funktionen:
- DataState - Die Möglichkeit, den gemeinsamen Zugriff auf ein Objekt von mehreren unabhängigen Instanzen virtueller Lua-Maschinen aus zu organisieren.
- Die Möglichkeit, eine Zeitüberschreitung für Coroutine festzulegen und die Ausführung derjenigen zu unterbrechen, die länger als diese ausgeführt werden.
- Eine Reihe von JIT-Compiler-Optimierungen, mit denen die exponentielle Zunahme der Anzahl der Traces beim Kopieren von Daten zwischen Objekten bekämpft werden soll. Wir haben auf HighLoad ++ 2017 darüber gesprochen, aber vor einigen Monaten hatten wir neue Arbeitsideen, die noch dokumentiert werden müssen.
- Neues Toolkit: Sampling Profiler. Dumpanalyze Compiler Debug Output Analyzer usw.
Jede dieser Funktionen verdient einen eigenen Artikel - schreiben Sie in die Kommentare, über welche Sie mehr lesen möchten.
Hier möchte ich etwas mehr darüber sprechen, wie wir die Belastung des Garbage Collectors reduziert haben.
Durch Versiegeln können Sie ein Objekt für den Garbage Collector unzugänglich machen. In unserem typischen Projekt handelt es sich bei den meisten Daten (bis zu 80%) in der virtuellen Lua-Maschine bereits um Geschäftsregeln, bei denen es sich um eine komplexe Lua-Tabelle handelt. Die Lebensdauer dieser Tabelle (Minuten) ist viel länger als die Lebensdauer der verarbeiteten Anforderungen (zehn Millisekunden), und die darin enthaltenen Daten ändern sich während der Abfrageverarbeitung nicht. In einer solchen Situation macht es keinen Sinn, den Garbage Collector zu zwingen, diese riesige Datenstruktur immer wieder zu durchlaufen. Dazu "versiegeln" wir das Objekt rekursiv und ordnen die Daten so um, dass der Garbage Collector weder das "versiegelte" Objekt noch dessen Inhalt erreicht. In Vanilla Lua 5.4 wird dieses Problem
gelöst, indem Generationen von Objekten in der Speicherbereinigung für Generationen unterstützt werden.
Es ist wichtig zu beachten, dass „versiegelte“ Objekte nicht beschreibbar sein dürfen. Die Nichtbeachtung dieser Invariante führt zum Auftreten baumelnder Zeiger: Beispielsweise bezieht sich ein „versiegeltes“ Objekt auf ein reguläres Objekt, und ein Müllsammler, der ein „versiegeltes“ Objekt überspringt, wenn er einen Haufen umrundet, überspringt ein reguläres Objekt - mit dem Unterschied, dass ein „versiegeltes“ Objekt nicht freigegeben werden kann. und das übliche kann man. Nachdem wir die Unterstützung für diese Invariante implementiert haben, erhalten wir im Wesentlichen kostenlose
Immunitätsunterstützung für Objekte, deren Fehlen in Lua häufig beklagt wird. Ich betone, dass unveränderliche und „versiegelte“ Objekte nicht dasselbe sind. Die zweite Eigenschaft impliziert die erste, aber nicht umgekehrt.
Ich stelle auch fest, dass in Lua 5.1 die Immunität mithilfe von Metatables implementiert werden kann - die Lösung funktioniert recht gut, ist jedoch in Bezug auf die Leistung nicht die rentabelste. Weitere Informationen zu „Versiegelung“, Immunität und deren Verwendung im Alltag finden Sie in
diesem Bericht.
Schlussfolgerungen
Im Moment sind wir mit der Stabilität und den Möglichkeiten für unsere Implementierung zufrieden. Und obwohl unsere Implementierung aufgrund der anfänglichen Einschränkungen Vanilla Lua und LuaJIT in Bezug auf die Portabilität erheblich unterlegen ist, löst sie viele unserer Probleme - wir hoffen, dass diese Lösungen für andere nützlich sind.
Auch wenn LuaVela nicht für die Produktion geeignet ist, laden wir Sie ein, es als Einstiegspunkt zu verwenden, um zu verstehen, wie LuaJIT oder seine Gabel funktionieren. Neben der Lösung von Problemen und der Erweiterung der Funktionalität haben wir im Laufe der Jahre einen wesentlichen Teil der Codebasis überarbeitet und
Schulungsartikel zur internen Struktur des Projekts verfasst - viele davon gelten nicht nur für LuaVela, sondern auch für LuaJIT.
Vielen Dank für Ihre Aufmerksamkeit, wir warten auf Pull-Anfragen!