Als ich einmal die Tiefen des Internets erkundete, stieß ich auf ein Video, in dem eine Person eine Schlange mithilfe eines genetischen Algorithmus trainiert. Und ich wollte das gleiche. Aber es wäre nicht interessant, trotzdem zu nehmen und in Python zu schreiben. Und ich entschied mich für einen moderneren Ansatz für das Training von Agentensystemen, nämlich Q-Network. Aber fangen wir von vorne an.
Verstärkungstraining
Beim maschinellen Lernen unterscheidet sich RL (Reinforcement Learning) erheblich von anderen Bereichen. Der Unterschied besteht darin, dass der klassische ML-Algorithmus bereits auf die fertigen Daten trainiert ist, während der RL diese Daten sozusagen für sich selbst erstellt. Die Idee von RL ist, dass es zusätzlich zu dem Algorithmus selbst, der als Agent bezeichnet wird, eine Umgebung gibt, in der dieser Agent platziert ist. In jeder Phase muss der Agent eine Aktion (Aktion) ausführen, und die Umgebung antwortet mit einer Belohnung (Belohnung) und ihrem Status (Status), auf deren Grundlage der Agent die Aktion ausführt.
Dqn
Es sollte eine Erklärung geben, wie der Algorithmus funktioniert, aber ich werde einen Link hinterlassen, wo kluge Leute ihn erklären.
Schlangenimplementierung
Nachdem wir c rl herausgefunden haben, müssen wir eine Umgebung erstellen, in der wir den Agenten platzieren. Glücklicherweise muss das Rad nicht neu erfunden werden, da ein Unternehmen wie open-ai bereits die Fitness-Bibliothek geschrieben hat, mit der Sie Ihre eigene Umgebung schreiben können. In der Bibliothek sind sie bereits in großer Zahl. Von einfachen Atari-Spielen bis hin zu komplexen 3D-Modellen. Aber unter all dem gibt es keine Schlange. Deshalb fahren wir mit seiner Schaffung fort.
Ich werde nicht alle Momente der Schaffung einer Umgebung im Fitnessstudio beschreiben, sondern nur die Hauptklasse zeigen, in der mehrere Funktionen implementiert werden müssen.
import gym class Env(gym.Env): def __init__(self): pass def step(self, action): """ . , """ def reset(self): """ """ def render(self, mode='human'): """ """
Um diese Funktionen zu implementieren, müssen wir jedoch ein Belohnungssystem entwickeln und in welcher Form wir Informationen über die Umgebung geben.
Zustand
In dem Video gab ein Mann der Schlange den Abstand zur Wand, Schlange und Apfel in 8 Richtungen. Das sind 24 Zahlen. Ich habe beschlossen, die Datenmenge zu reduzieren, sie aber etwas zu komplizieren. Zuerst werde ich den Abstand zu den Wänden mit dem Abstand zur Schlange kombinieren. Einfach ausgedrückt, wir werden ihr die Entfernung zum nächsten Objekt mitteilen, das bei einer Kollision töten kann. Zweitens gibt es nur drei Richtungen, die von der Bewegungsrichtung der Schlange abhängen. Zum Beispiel schaut die Schlange beim Starten nach oben, sodass wir den Abstand zur oberen, linken und rechten Wand angeben. Wenn sich der Kopf der Schlange nach rechts dreht, werden wir bereits den Abstand zur rechten, oberen und unteren Wand angeben. Der Einfachheit halber werde ich ein Bild geben.

Ich habe auch beschlossen, mit dem Apfel zu spielen. Wir werden Informationen darüber in Form von (x, y) -Koordinaten im Koordinatensystem präsentieren, das am Kopf der Schlange entsteht. Das Koordinatensystem ändert auch seine Ausrichtung hinter dem Kopf der Schlange. Nach dem Bild denke ich, dass es definitiv klar werden sollte.
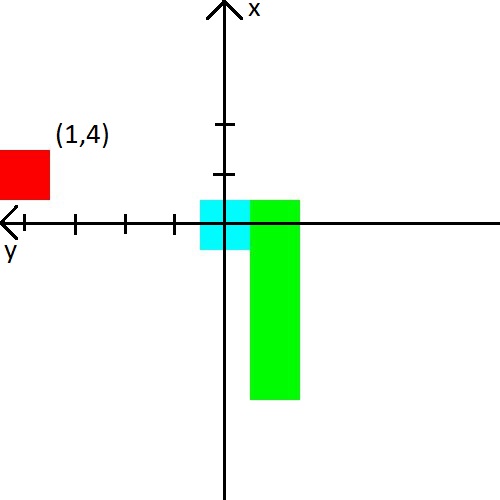
Belohnung
Wenn Sie mit dem Staat eine Art von Funktionen entwickeln können und hoffen, dass das neuronale Netzwerk dies herausfindet, dann ist mit der Auszeichnung alles komplizierter. Es hängt von ihr ab, ob der Agent lernen wird und ob er lernen wird, was wir wollen.
Ich werde sofort das Belohnungssystem geben, mit dem ich ein stabiles Training erreicht habe.
- Bei jedem Schritt beträgt die Belohnung -0,25.
- Beim Tod -10.
- Nach dem Tod bis zu 15 Schritte -100.
- Beim Verzehr eines Apfels ( Anzahl der verzehrten Äpfel ) * 3.5.
Und geben Sie auch Beispiele dafür, was zu einem schlechten Belohnungssystem führt.
- Wenn Sie in den ersten Schritten nicht genügend Belohnung für den Tod geben, wird die Schlange es vorziehen, gegen die Wand zu töten. Es ist einfacher als nach Äpfeln zu suchen :)
- Wenn Sie eine positive Belohnung für die Schritte geben, beginnt sich die Schlange endlos zu drehen. Denn ihrer Meinung nach wird es rentabler sein, als nach Äpfeln zu suchen.
- Und viele andere Fälle, in denen die Schlange einfach nicht lernt.
Nun, ein Beispiel dafür, was die Schlange in 2000 Folgen gelernt hat Zusammenfassung
Das Hauptinteresse beim Schreiben der Schlange war zu sehen, wie die Schlange lernt, indem sie so wenig über ihre Umgebung weiß. Und sie hat gut gelernt, da die durchschnittliche Rate der verzehrten Äpfel 23 erreichte, was meiner Meinung nach nicht sehr schlecht ist. Daher kann das Experiment als erfolgreich angesehen werden.
Quellcode