Früher hatte ich Angst vor dem Caching. Ich wollte wirklich nicht klettern und herausfinden, was es war, ich stellte mir sofort einige Dinge im Motorraum vor, die nur der Gewinner der Mathematikolympiade herausfinden konnte. Es stellte sich heraus, dass dies nicht so ist. Das Caching erwies sich als sehr einfach, verständlich und unglaublich einfach in jedem Projekt zu implementieren.
In diesem Beitrag werde ich versuchen, das Caching so einfach zu erklären, wie ich es jetzt verstehe. Sie erfahren, wie Sie das Caching in 1 Minute implementieren, wie Sie nach Schlüssel zwischenspeichern, die Cache-Lebensdauer festlegen und viele andere Dinge, die Sie wissen müssen, wenn Sie angewiesen wurden, etwas in Ihrem Arbeitsprojekt zwischenzuspeichern, und Sie möchten nicht schmutzig werden Gesicht.
Warum sage ich "anvertraut"? Da Caching in der Regel sinnvoll ist, ist es sinnvoll, es in großen, hoch ausgelasteten Projekten mit Zehntausenden von Anforderungen pro Minute anzuwenden. In solchen Projekten werden normalerweise Repository-Aufrufe zwischengespeichert, um die Datenbank nicht zu überlasten. Insbesondere wenn bekannt ist, dass die Daten eines Mastersystems mit einer bestimmten Häufigkeit aktualisiert werden. Wir selbst schreiben solche Projekte nicht, wir arbeiten daran. Wenn das Projekt klein ist und keine Überlastung droht, ist es natürlich besser, nichts zwischenzuspeichern - immer frische Daten sind immer besser als regelmäßig aktualisierte.
Normalerweise kriecht der Sprecher in den Schulungsbeiträgen zuerst unter die Motorhaube, beginnt, sich in die Eingeweide der Technologie zu vertiefen, was den Leser sehr stört, und erst dann, wenn er die gute Hälfte des Artikels durchblättert und nichts verstanden hat, wird erklärt, wie es funktioniert. Bei uns wird alles anders sein. Zuerst sorgen wir dafür, dass es funktioniert, und vorzugsweise mit geringstem Aufwand. Erst dann können Sie, wenn Sie interessiert sind, unter die Cache-Haube schauen, in den Bin selbst schauen und das Caching optimieren. Aber selbst wenn Sie dies nicht tun (und dies beginnt mit Punkt 6), funktioniert Ihr Caching so.
Wir werden ein Projekt erstellen, in dem wir alle Aspekte des Caching analysieren, die ich versprochen habe. Am Ende wird wie gewohnt ein Link zum Projekt selbst vorhanden sein.
0. Ein Projekt erstellen
Wir werden ein sehr einfaches Projekt erstellen, in dem wir die Entität aus der Datenbank entnehmen können. Ich habe dem Projekt Lombok, Spring Cache, Spring Data JPA und H2 hinzugefügt. Es kann jedoch nur auf Spring Cache verzichtet werden.
plugins { id 'org.springframework.boot' version '2.1.7.RELEASE' id 'io.spring.dependency-management' version '1.0.8.RELEASE' id 'java' } group = 'ru.xpendence' version = '0.0.1-SNAPSHOT' sourceCompatibility = '1.8' configurations { compileOnly { extendsFrom annotationProcessor } } repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-cache' implementation 'org.springframework.boot:spring-boot-starter-data-jpa' compileOnly 'org.projectlombok:lombok' runtimeOnly 'com.h2database:h2' annotationProcessor 'org.projectlombok:lombok' testImplementation 'org.springframework.boot:spring-boot-starter-test' }
Wir werden nur eine Entität haben, nennen wir es Benutzer.
@Entity @Table(name = "users") @Data @NoArgsConstructor @ToString public class User implements Serializable { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(name = "name") private String name; @Column(name = "email") private String email; public User(String name, String email) { this.name = name; this.email = email; } }
Fügen Sie das Repository und den Service hinzu:
public interface UserRepository extends JpaRepository<User, Long> { } @Slf4j @Service public class UserServiceImpl implements UserService { private final UserRepository repository; public UserServiceImpl(UserRepository repository) { this.repository = repository; } @Override public User create(User user) { return repository.save(user); } @Override public User get(Long id) { log.info("getting user by id: {}", id); return repository.findById(id) .orElseThrow(() -> new EntityNotFoundException("User not found by id " + id)); } }
Wenn wir die Dienstmethode get () eingeben, schreiben wir darüber in das Protokoll.
Stellen Sie eine Verbindung zum Spring Cache-Projekt her.
@SpringBootApplication @EnableCaching
Das Projekt ist fertig.
1. Zwischenspeichern des Rückgabeergebnisses
Was macht Spring Cache? Spring Cache speichert einfach das Rückgabeergebnis für bestimmte Eingabeparameter zwischen. Lass es uns überprüfen. Wir werden die Annotation @Cacheable über die Dienstmethode get () setzen, um die zurückgegebenen Daten zwischenzuspeichern. Wir geben dieser Anmerkung den Namen "Benutzer" (wir werden weiter analysieren, warum dies separat erfolgt).
@Override @Cacheable("users") public User get(Long id) { log.info("getting user by id: {}", id); return repository.findById(id) .orElseThrow(() -> new EntityNotFoundException("User not found by id " + id)); }
Um zu überprüfen, wie dies funktioniert, schreiben wir einen einfachen Test.
@RunWith(SpringRunner.class) @SpringBootTest public abstract class AbstractTest { }
@Slf4j public class UserServiceTest extends AbstractTest { @Autowired private UserService service; @Test public void get() { User user1 = service.create(new User("Vasya", "vasya@mail.ru")); User user2 = service.create(new User("Kolya", "kolya@mail.ru")); getAndPrint(user1.getId()); getAndPrint(user2.getId()); getAndPrint(user1.getId()); getAndPrint(user2.getId()); } private void getAndPrint(Long id) { log.info("user found: {}", service.get(id)); } }
Ein kleiner Exkurs, warum ich normalerweise AbstractTest schreibe und alle Tests davon erbe.Wenn die Klasse über eine eigene @ SpringBootTest-Annotation verfügt, wird der Kontext für eine solche Klasse jedes Mal neu ausgelöst. Da der Kontext 5 Sekunden oder vielleicht 40 Sekunden lang ansteigen kann, wird der Testprozess in jedem Fall stark behindert. Gleichzeitig gibt es normalerweise keinen Unterschied im Kontext, und wenn Sie jede Gruppe von Tests innerhalb derselben Klasse ausführen, muss der Kontext nicht neu gestartet werden. Wenn wir wie in unserem Fall nur eine Anmerkung über eine abstrakte Klasse setzen, können wir den Kontext nur einmal erhöhen.
Daher ziehe ich es vor, die Anzahl der während des Testens / Zusammenbaus aufgeworfenen Kontexte nach Möglichkeit zu reduzieren.
Was macht unser Test? Er erstellt zwei Benutzer und zieht sie dann zweimal aus der Datenbank. Wie wir uns erinnern, setzen wir die Annotation @Cacheable ein, die die zurückgegebenen Werte zwischenspeichert. Nach dem Empfang des Objekts von der Methode get () geben wir das Objekt in das Protokoll aus. Außerdem protokollieren wir Informationen zu jedem Besuch der Anwendung in der Methode get ().
Führen Sie den Test aus. Das bekommen wir in der Konsole.
getting user by id: 1 user found: User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 user found: User(id=2, name=Kolya, email=kolya@mail.ru) user found: User(id=1, name=Vasya, email=vasya@mail.ru) user found: User(id=2, name=Kolya, email=kolya@mail.ru)
Wie wir sehen, sind wir die ersten beiden Male wirklich zur get () -Methode gegangen und haben den Benutzer tatsächlich aus der Datenbank abgerufen. In allen anderen Fällen gab es keinen wirklichen Aufruf der Methode, die Anwendung nahm zwischengespeicherte Daten per Schlüssel (in diesem Fall ist dies die ID).
2. Caching-Schlüsseldeklaration
Es gibt Situationen, in denen mehrere Parameter zur zwischengespeicherten Methode kommen. In diesem Fall kann es erforderlich sein, den Parameter zu bestimmen, anhand dessen das Caching erfolgt. Wir fügen einer Methode ein Beispiel hinzu, mit der eine durch Parameter zusammengestellte Entität in der Datenbank gespeichert wird. Wenn jedoch bereits eine Entität mit demselben Namen vorhanden ist, wird sie nicht gespeichert. Dazu definieren wir den Parameter name als Schlüssel für das Caching. Es wird so aussehen:
@Override @Cacheable(value = "users", key = "#name") public User create(String name, String email) { log.info("creating user with parameters: {}, {}", name, email); return repository.save(new User(name, email)); }
Schreiben wir den entsprechenden Test:
@Test public void create() { createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Ivan", "ivan1122@mail.ru"); createAndPrint("Sergey", "ivan@mail.ru"); log.info("all entries are below:"); service.getAll().forEach(u -> log.info("{}", u.toString())); } private void createAndPrint(String name, String email) { log.info("created user: {}", service.create(name, email)); }
Wir werden versuchen, drei Benutzer zu erstellen, für zwei ist der Name gleich
createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Ivan", "ivan1122@mail.ru");
und für zwei davon wird die E-Mail übereinstimmen
createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Sergey", "ivan@mail.ru");
In der Erstellungsmethode protokollieren wir jede Tatsache, dass die Methode aufgerufen wird, und protokollieren außerdem alle Entitäten, die diese Methode an uns zurückgegeben hat. Das Ergebnis wird folgendermaßen aussehen:
creating user with parameters: Ivan, ivan@mail.ru created user: User(id=1, name=Ivan, email=ivan@mail.ru) created user: User(id=1, name=Ivan, email=ivan@mail.ru) creating user with parameters: Sergey, ivan@mail.ru created user: User(id=2, name=Sergey, email=ivan@mail.ru) all entries are below: User(id=1, name=Ivan, email=ivan@mail.ru) User(id=2, name=Sergey, email=ivan@mail.ru)
Wir sehen, dass die Anwendung die Methode tatsächlich dreimal aufgerufen hat und nur zweimal darauf eingegangen ist. Sobald ein Schlüssel mit einer Methode übereinstimmte und einfach einen zwischengespeicherten Wert zurückgab.
3. Erzwungenes Caching. @CachePut
Es gibt Situationen, in denen wir den Rückgabewert für eine Entität zwischenspeichern möchten, gleichzeitig aber den Cache aktualisieren müssen. Für solche Anforderungen ist die Annotation @CachePut vorhanden. Die Anwendung wird an die Methode übergeben, während der Cache für den Rückgabewert aktualisiert wird, auch wenn er bereits zwischengespeichert ist.
Fügen Sie einige Methoden hinzu, mit denen wir den Benutzer speichern. Wir werden einen von ihnen mit der üblichen @ Cache-fähigen Annotation markieren, den zweiten mit @ CachePut.
@Override @Cacheable(value = "users", key = "#user.name") public User createOrReturnCached(User user) { log.info("creating user: {}", user); return repository.save(user); } @Override @CachePut(value = "users", key = "#user.name") public User createAndRefreshCache(User user) { log.info("creating user: {}", user); return repository.save(user); }
Die erste Methode gibt einfach die zwischengespeicherten Werte zurück, die zweite erzwingt die Aktualisierung des Caches. Das Caching wird mit dem Schlüssel # user.name durchgeführt. Wir werden den entsprechenden Test schreiben.
@Test public void createAndRefresh() { User user1 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("created user1: {}", user1); User user2 = service.createOrReturnCached(new User("Vasya", "misha@mail.ru")); log.info("created user2: {}", user2); User user3 = service.createAndRefreshCache(new User("Vasya", "kolya@mail.ru")); log.info("created user3: {}", user3); User user4 = service.createOrReturnCached(new User("Vasya", "petya@mail.ru")); log.info("created user4: {}", user4); }
Gemäß der bereits beschriebenen Logik erhalten wir beim ersten Speichern eines Benutzers mit dem Namen „Vasya“ über die Methode createOrReturnCached () eine zwischengespeicherte Entität, und die Anwendung gibt die Methode selbst nicht ein. Wenn wir die Methode createAndRefreshCache () aufrufen, wird die zwischengespeicherte Entität für den Schlüssel mit dem Namen "Vasya" im Cache überschrieben. Lassen Sie uns den Test ausführen und sehen, was in der Konsole angezeigt wird.
creating user: User(id=null, name=Vasya, email=vasya@mail.ru) created user1: User(id=1, name=Vasya, email=vasya@mail.ru) created user2: User(id=1, name=Vasya, email=vasya@mail.ru) creating user: User(id=null, name=Vasya, email=kolya@mail.ru) created user3: User(id=2, name=Vasya, email=kolya@mail.ru) created user4: User(id=2, name=Vasya, email=kolya@mail.ru)
Wir sehen, dass Benutzer1 erfolgreich in die Datenbank und den Cache geschrieben hat. Wenn wir versuchen, den Benutzer mit demselben Namen erneut aufzuzeichnen, erhalten wir das zwischengespeicherte Ergebnis des ersten Aufrufs (Benutzer2, für den die ID mit Benutzer1 identisch ist, was besagt, dass der Benutzer nicht geschrieben wurde und dies nur ein Cache ist). Als nächstes schreiben wir den dritten Benutzer über die zweite Methode, die trotz des zwischengespeicherten Ergebnisses immer noch die Methode aufruft und ein neues Ergebnis in den Cache schreibt. Dies ist user3. Wie wir sehen können, hat er bereits eine neue ID. Danach rufen wir die erste Methode auf, die den von Benutzer3 hinzugefügten neuen Cache verwendet.
4. Entfernen aus dem Cache. @CacheEvict
Manchmal ist es notwendig, einige Daten im Cache hart zu aktualisieren. Beispielsweise wurde eine Entität bereits aus der Datenbank gelöscht, auf sie kann jedoch weiterhin über den Cache zugegriffen werden. Um die Datenkonsistenz zu gewährleisten, müssen gelöschte Daten zumindest nicht im Cache gespeichert werden.
Fügen Sie dem Service einige weitere Methoden hinzu.
@Override public void delete(Long id) { log.info("deleting user by id: {}", id); repository.deleteById(id); } @Override @CacheEvict("users") public void deleteAndEvict(Long id) { log.info("deleting user by id: {}", id); repository.deleteById(id); }
Der erste löscht den Benutzer einfach, der zweite löscht ihn ebenfalls, aber wir markieren ihn mit der Annotation @CacheEvict. Fügen Sie einen Test hinzu, der zwei Benutzer erstellt. Danach wird einer durch eine einfache Methode und der zweite durch eine mit Anmerkungen versehene Methode gelöscht. Danach werden wir diese Benutzer durch die get () -Methode erhalten.
@Test public void delete() { User user1 = service.create(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user1.getId())); User user2 = service.create(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user2.getId())); service.delete(user1.getId()); service.deleteAndEvict(user2.getId()); log.info("{}", service.get(user1.getId())); log.info("{}", service.get(user2.getId())); }
Es ist logisch, dass das Entfernen, da unser Benutzer bereits zwischengespeichert ist, das Entfernen nicht daran hindert, es zu erhalten, da es zwischengespeichert ist. Sehen wir uns die Protokolle an.
getting user by id: 1 User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 User(id=2, name=Vasya, email=vasya@mail.ru) deleting user by id: 1 deleting user by id: 2 User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 javax.persistence.EntityNotFoundException: User not found by id 2
Wir sehen, dass die Anwendung beide Male sicher zur get () -Methode gegangen ist und Spring diese Entitäten zwischengespeichert hat. Als nächstes haben wir sie mit verschiedenen Methoden gelöscht. Wir haben den ersten auf die übliche Weise gelöscht, und der zwischengespeicherte Wert blieb erhalten. Als wir versuchten, den Benutzer unter ID 1 zu bringen, war dies erfolgreich. Als wir versuchten, Benutzer 2 abzurufen, gab die Methode eine EntityNotFoundException zurück - es befand sich kein solcher Benutzer im Cache.
5. Gruppierungseinstellungen. @Caching
Manchmal erfordert eine einzelne Methode mehrere Caching-Einstellungen. Die Annotation @Caching wird für diese Zwecke verwendet. Es könnte ungefähr so aussehen:
@Caching( cacheable = { @Cacheable("users"), @Cacheable("contacts") }, put = { @CachePut("tables"), @CachePut("chairs"), @CachePut(value = "meals", key = "#user.email") }, evict = { @CacheEvict(value = "services", key = "#user.name") } ) void cacheExample(User user) { }
Dies ist die einzige Möglichkeit, Anmerkungen zu gruppieren. Wenn Sie versuchen, so etwas zu stapeln
@CacheEvict("users") @CacheEvict("meals") @CacheEvict("contacts") @CacheEvict("tables") void cacheExample(User user) { }
dann wird IDEA Ihnen sagen, dass dies nicht der Fall ist.
6. Flexible Konfiguration. Cachemanager
Schließlich haben wir den Cache herausgefunden und er war für uns nicht mehr unverständlich und beängstigend. Lassen Sie uns nun unter die Haube schauen und sehen, wie wir das Caching im Allgemeinen konfigurieren können.
Für solche Aufgaben gibt es einen CacheManager. Es existiert überall dort, wo Spring Cache ist. Wenn wir die Annotation @EnableCache hinzugefügt haben, wird ein solcher Cache-Manager von Spring automatisch erstellt. Wir können dies überprüfen, wenn wir den ApplicationContext automatisch umbrechen und am Haltepunkt öffnen. Unter anderem wird es eine cacheManager-Bean geben.
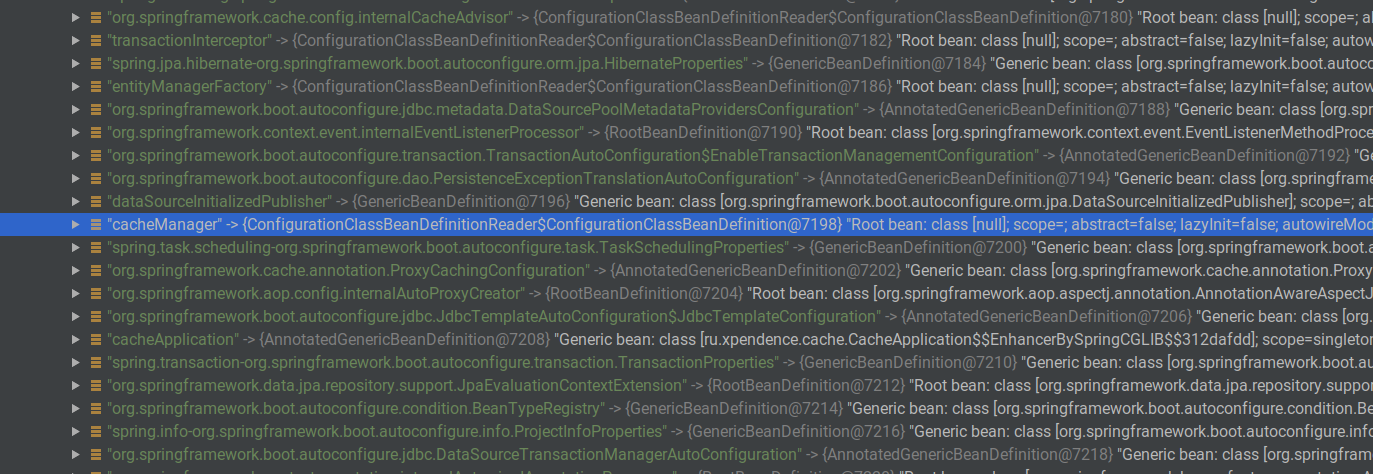
Ich habe die Anwendung zu dem Zeitpunkt gestoppt, als bereits zwei Benutzer erstellt und in den Cache gestellt wurden. Wenn wir die Bean, die wir benötigen, über Evaluate Expression aufrufen, werden wir feststellen, dass es wirklich eine solche Bean gibt. Sie hat einen ConcurentMapCache mit dem Schlüssel "users" und dem Wert ConcurrentHashMap, der bereits zwischengespeicherte Benutzer enthält.

Wir können wiederum unseren Cache-Manager mit Habr und Programmierern erstellen und ihn dann nach unserem Geschmack optimieren.
@Bean("habrCacheManager") public CacheManager cacheManager() { return null; }
Es bleibt nur zu entscheiden, welchen Cache-Manager wir verwenden, da es viele davon gibt. Ich werde nicht alle Cache-Manager auflisten, es wird ausreichen zu wissen, dass es solche gibt:
- SimpleCacheManager ist der einfachste Cache-Manager, der zum Lernen und Testen geeignet ist.
- ConcurrentMapCacheManager - Initialisiert zurückgegebene Instanzen für jede Anforderung träge. Es wird auch zum Testen und Erlernen der Arbeit mit dem Cache sowie für einige einfache Aktionen wie unsere empfohlen. Für ernsthafte Arbeiten mit dem Cache wird die folgende Implementierung empfohlen.
- JCacheCacheManager , EhCacheCacheManager und CaffeineCacheManager sind seriöse partnerbasierte Cache-Manager, die flexibel anpassbar sind und Aufgaben mit einer Vielzahl von Aktionen ausführen.
Als Teil meines bescheidenen Beitrags werde ich die Cache-Manager der letzten drei nicht beschreiben. Stattdessen werden verschiedene Aspekte des Einrichtens eines Cache-Managers am Beispiel des ConcurrentMapCacheManager betrachtet.
Erstellen wir also unseren Cache-Manager neu.
@Bean("habrCacheManager") public CacheManager cacheManager() { return new ConcurrentMapCacheManager(); }
Unser Cache-Manager ist bereit.
7. Cache-Setup. Lebensdauer, maximale Größe und so weiter.
Dazu benötigen wir eine recht beliebte Google Guava-Bibliothek. Ich habe den letzten genommen.
compile group: 'com.google.guava', name: 'guava', version: '28.1-jre'
Beim Erstellen des Cache-Managers definieren wir die Methode createConcurrentMapCache neu, in der wir CacheBuilder von Guava aus aufrufen. Dabei werden wir aufgefordert, den Cache-Manager durch Initialisieren der folgenden Methoden zu konfigurieren:
- MaximumSize - Die maximale Größe der Werte, die der Cache enthalten kann. Mit diesem Parameter können Sie versuchen, einen Kompromiss zwischen der Auslastung der Datenbank und dem JVM-RAM zu finden.
- refreshAfterWrite - Zeit nach dem Schreiben des Werts in den Cache, nach der er automatisch aktualisiert wird.
- expireAfterAccess - die Lebensdauer des Werts nach dem letzten Aufruf.
- expireAfterWrite - Lebensdauer des Werts nach dem Schreiben in den Cache. Dies ist der Parameter, den wir definieren werden.
und andere.
Wir definieren im Manager die Lebensdauer des Datensatzes. Um nicht lange zu warten, stellen Sie 1 Sekunde ein.
@Bean("habrCacheManager") public CacheManager cacheManager() { return new ConcurrentMapCacheManager() { @Override protected Cache createConcurrentMapCache(String name) { return new ConcurrentMapCache( name, CacheBuilder.newBuilder() .expireAfterWrite(1, TimeUnit.SECONDS) .build().asMap(), false); } }; }
Wir schreiben einen Test, der diesem Fall entspricht.
@Test public void checkSettings() throws InterruptedException { User user1 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user1.getId())); User user2 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user2.getId())); Thread.sleep(1000L); User user3 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user3.getId())); }
Wir speichern mehrere Werte in der Datenbank, und wenn die Daten zwischengespeichert werden, speichern wir nichts. Zuerst speichern wir zwei Werte, dann warten wir 1 Sekunde, bis der Cache leer ist. Danach speichern wir einen weiteren Wert.
creating user: User(id=null, name=Vasya, email=vasya@mail.ru) getting user by id: 1 User(id=1, name=Vasya, email=vasya@mail.ru) User(id=1, name=Vasya, email=vasya@mail.ru) creating user: User(id=null, name=Vasya, email=vasya@mail.ru) getting user by id: 2 User(id=2, name=Vasya, email=vasya@mail.ru)
Protokolle zeigen, dass wir zuerst einen Benutzer erstellt und dann einen anderen ausprobiert haben. Da die Daten jedoch zwischengespeichert wurden, haben wir sie aus dem Cache abgerufen (in beiden Fällen beim Speichern und beim Abrufen aus der Datenbank). Dann wurde der Cache fehlerhaft, da ein Datensatz uns über das tatsächliche Speichern und den tatsächlichen Empfang des Benutzers informiert.
8. Zusammenfassend
Früher oder später muss der Entwickler das Caching im Projekt implementieren. Ich hoffe, dieser Artikel hilft Ihnen dabei, das Thema zu verstehen und Caching-Probleme kühner zu betrachten.
Github des Projekts hier:
https://github.com/promoscow/cache