In einem
früheren Artikel haben wir über den Versuch gesprochen, Watcher zu verwenden, und einen Testbericht vorgelegt. Wir führen solche Tests regelmäßig durch, um das Gleichgewicht und andere wichtige Funktionen einer großen Unternehmens- oder Betreiberwolke auszugleichen.
Die hohe Komplexität des zu lösenden Problems erfordert möglicherweise mehrere Artikel, um unser Projekt zu beschreiben. Heute veröffentlichen wir den zweiten Artikel in der Reihe zum Ausgleich virtueller Maschinen in der Cloud.
Einige Begriffe
VmWare hat das DRS-Dienstprogramm (Distributed Resource Scheduler) eingeführt, um die Last der Virtualisierungsumgebung auszugleichen.
Wie
searchvmware.techtarget.com/definition/VMware-DRS schreibt
„VMware DRS (Distributed Resource Scheduler) ist ein Dienstprogramm, das die Rechenlast mit den verfügbaren Ressourcen in einer virtuellen Umgebung in Einklang bringt. Das Dienstprogramm ist Teil eines Virtualisierungspakets namens VMware Infrastructure.
Mithilfe von VMware DRS definieren Benutzer die Regeln für die Verteilung physischer Ressourcen zwischen virtuellen Maschinen (VMs). Das Dienstprogramm kann für die manuelle oder automatische Steuerung konfiguriert werden. VMware-Ressourcenpools können einfach hinzugefügt, entfernt oder neu organisiert werden. Auf Wunsch können Ressourcenpools zwischen verschiedenen Geschäftsbereichen isoliert werden. Wenn sich die Arbeitslast einer oder mehrerer virtueller Maschinen dramatisch ändert, verteilt VMware DRS die virtuellen Maschinen auf physische Server. Wenn die Gesamtauslastung verringert wird, sind einige physische Server möglicherweise vorübergehend ausgefallen und die Auslastung wird konsolidiert. “Warum brauche ich einen Ausgleich?
Unserer Meinung nach ist DRS ein unverzichtbares Merkmal der Cloud, obwohl dies nicht bedeutet, dass DRS jederzeit und überall verwendet werden sollte. Je nach Zweck und Anforderungen der Cloud können unterschiedliche Anforderungen an DRS und Ausgleichsmethoden gestellt werden. Vielleicht gibt es Situationen, in denen ein Ausgleich überhaupt nicht erforderlich ist. Oder sogar schädlich.
Um besser zu verstehen, wo und für welche DRS-Kunden benötigt werden, sollten Sie deren Ziele berücksichtigen. Wolken können in öffentliche und private unterteilt werden. Hier sind die Hauptunterschiede zwischen diesen Clouds und den Kundenzielen.
Wir ziehen folgende Schlussfolgerungen für uns:
Für private Clouds, die großen Unternehmenskunden zur Verfügung gestellt werden, kann DRS unter folgenden Einschränkungen angewendet werden:
- Regeln für Informationssicherheit und Rechnungslegungsaffinität für den Ausgleich;
- Verfügbarkeit einer ausreichenden Menge an Ressourcen im Falle eines Unfalls;
- Die Daten der virtuellen Maschine befinden sich auf einem zentralen oder verteilten Speichersystem.
- zeitliche Vielfalt der Verwaltungs-, Sicherungs- und Ausgleichsverfahren;
- Ausgleich nur innerhalb der Gesamtheit der Client-Hosts;
- Ausgleich nur mit einem starken Ungleichgewicht, der effizientesten und sichersten Migration von VMs (schließlich kann die Migration fehlschlagen);
- Ausgleichen relativ "leiser" virtueller Maschinen (die Migration "lauter" virtueller Maschinen kann sehr lange dauern);
- Ausgleich unter Berücksichtigung der "Kosten" - der Belastung des Speichersystems und des Netzwerks (mit angepassten Architekturen für Großkunden);
- Ausgleich unter Berücksichtigung des individuellen Verhaltens jeder VM;
- Ein Ausgleich ist nach Stunden (Nacht, Wochenende, Feiertag) wünschenswert.
Für öffentliche Clouds , die Dienste für kleine Kunden bereitstellen, kann DRS mit erweiterten Funktionen viel häufiger verwendet werden:
- Fehlen von Einschränkungen der Informationssicherheit und Affinitätsregeln;
- Balancieren in der Cloud;
- Ausgleich zu jeder angemessenen Zeit;
- Ausbalancieren einer VM;
- Ausgleichen von "lauten" virtuellen Maschinen (um den Rest nicht zu stören);
- Daten der virtuellen Maschine befinden sich häufig auf lokalen Laufwerken.
- Berücksichtigung der durchschnittlichen Speicher- und Netzwerkleistung (Cloud-Architektur ist einheitlich);
- Ausgleich nach allgemeinen Regeln und verfügbaren Statistiken zum Verhalten von Rechenzentren.
Problemkomplexität
Die Schwierigkeit des Ausgleichs besteht darin, dass DRS mit vielen unsicheren Faktoren arbeiten muss:
- Benutzerverhalten jedes Kundeninformationssystems;
- Betriebsalgorithmen von Informationssystem-Servern;
- Verhalten des DBMS-Servers
- Belastung der Rechenressourcen, des Speichers, des Netzwerks;
- Serverinteraktion untereinander im Kampf um Cloud-Ressourcen.
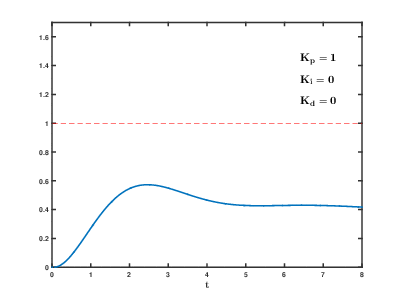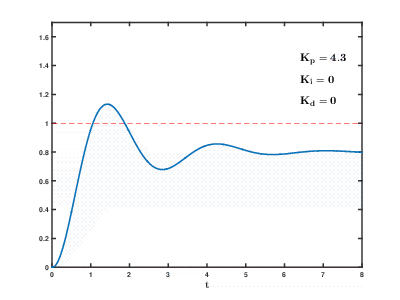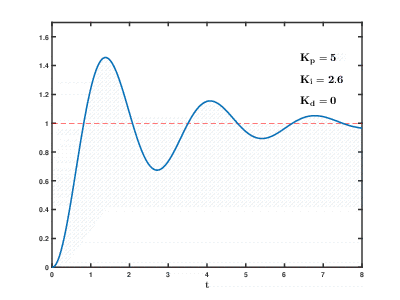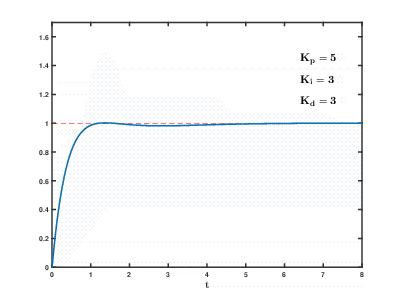
Die Belastung einer großen Anzahl virtueller Anwendungs- und Datenbankserver auf Cloud-Ressourcen erfolgt im Laufe der Zeit. Die Folgen können auftreten und sich nach einer unvorhersehbaren Zeit mit unvorhersehbaren Auswirkungen überschneiden. Selbst zur Steuerung relativ einfacher Prozesse (z. B. zur Steuerung eines Motors oder eines Warmwasserbereitungssystems zu Hause) müssen automatische Steuerungssysteme komplexe Algorithmen zur
Differenzierung proportionaler Integrale mit Rückkopplung verwenden.

Unsere Aufgabe ist um viele Größenordnungen komplizierter, und es besteht das Risiko, dass das System die Last nicht in angemessener Zeit auf festgelegte Werte ausgleichen kann, selbst wenn keine externen Einflüsse von Benutzern auftreten.
Geschichte unserer Entwicklungen
Um dieses Problem zu lösen, haben wir uns entschlossen, nicht bei Null anzufangen, sondern auf vorhandenen Erfahrungen aufzubauen, und haben begonnen, mit Spezialisten zu interagieren, die Erfahrung auf diesem Gebiet haben. Glücklicherweise stimmte unser Verständnis der Probleme vollständig überein.
Stufe 1
Wir haben ein auf neuronaler Netzwerktechnologie basierendes System verwendet und versucht, unsere Ressourcen auf dieser Basis zu optimieren.
Das Interesse dieser Phase bestand darin, die neue Technologie zu testen, und es war wichtig, einen nicht standardmäßigen Ansatz zur Lösung des Problems anzuwenden, bei dem sich die Standardansätze unter sonst gleichen Bedingungen praktisch erschöpft haben.
Wir haben das System gestartet und sind wirklich ausgeglichen. Aufgrund der Größe unserer Cloud konnten wir keine optimistischen Ergebnisse von den Entwicklern bekannt geben, aber es war klar, dass das Balancing funktioniert.
Darüber hinaus hatten wir ziemlich ernsthafte Einschränkungen:
- Um ein neuronales Netzwerk zu trainieren, müssen virtuelle Maschinen über Wochen oder Monate ohne wesentliche Änderungen ausgeführt werden.
- Der Algorithmus dient zur Optimierung auf der Grundlage der Analyse früherer "historischer" Daten.
- Um ein neuronales Netzwerk zu trainieren, ist eine ausreichend große Menge an Daten und Rechenressourcen erforderlich.
- Optimierung und Ausgleich können relativ selten durchgeführt werden - alle paar Stunden, was eindeutig nicht ausreicht.
Stufe 2
Da wir mit dem Stand der Dinge nicht zufrieden waren, haben wir beschlossen, das System zu modifizieren und damit die
Hauptfrage zu beantworten - für wen machen wir das?
Zuerst für Firmenkunden. Wir brauchen also ein System, das effizient arbeitet und über Unternehmensbeschränkungen verfügt, die die Implementierung nur vereinfachen.
Die zweite Frage ist, was unter dem Wort "operativ" zu verstehen ist. Als Ergebnis einer kurzen Debatte entschieden wir, dass es möglich ist, auf die Reaktionszeit von 5 bis 10 Minuten aufzubauen, damit kurzfristige Sprünge das System nicht in Resonanz bringen.
Die dritte Frage ist, welche Größe der ausgeglichenen Anzahl von Servern zu wählen ist.
Dieses Problem wurde von selbst entschieden. In der Regel machen Clients Serveraggregate nicht sehr groß. Dies steht im Einklang mit den Empfehlungen im Artikel, Aggregate auf 30 bis 40 Server zu beschränken.
Durch die Segmentierung des Serverpools vereinfachen wir außerdem die Aufgabe des Ausgleichsalgorithmus.
Die vierte Frage ist, inwieweit ein neuronales Netzwerk mit seinem langen Lernprozess und dem seltenen Ausgleich zu uns passt. Wir haben beschlossen, es zugunsten einfacherer Betriebsalgorithmen aufzugeben, um das Ergebnis in Sekunden zu erhalten.
Eine Beschreibung des Systems unter Verwendung solcher Algorithmen und seiner Mängel finden Sie
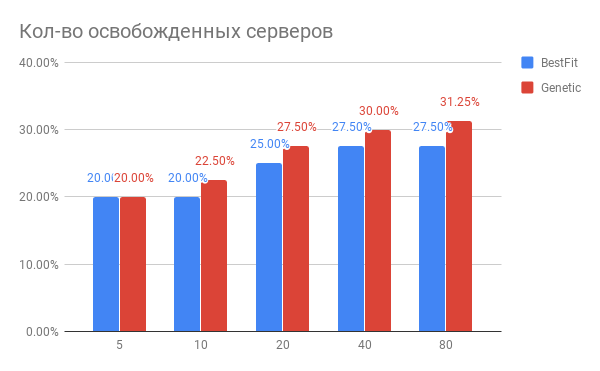
hier.Wir haben dieses System implementiert und gestartet und ermutigende Ergebnisse erhalten. Jetzt analysiert es regelmäßig die Cloud-Last und gibt Empfehlungen zum Verschieben virtueller Maschinen, die weitgehend korrekt sind. Schon jetzt ist klar, dass wir eine Ressourcenfreigabe von 10-15% für neue virtuelle Maschinen erreichen können, wobei die Qualität bestehender Maschinen verbessert wird.

Wenn RAM oder CPU ein Ungleichgewicht feststellen, gibt das System dem Tionics-Scheduler Befehle, um eine Live-Migration der erforderlichen virtuellen Maschinen durchzuführen. Wie aus dem Überwachungssystem ersichtlich ist, hat die virtuelle Maschine von einem (oberen) zu einem anderen (unteren) Host verschoben und Speicher auf dem oberen Host (in gelben Kreisen hervorgehoben) freigegeben und ihn jeweils auf dem unteren Host (in weißen Kreisen hervorgehoben) belegt.
Jetzt versuchen wir, die Wirksamkeit des aktuellen Algorithmus genauer zu bewerten und mögliche Fehler darin zu finden.
Stufe 3
Es scheint, dass Sie sich beruhigen, auf die nachgewiesene Wirksamkeit warten und das Thema schließen können.
Die folgenden offensichtlichen Optimierungsmöglichkeiten zwingen uns jedoch zu einer neuen Phase.
- Statistiken hier und hier zeigen beispielsweise, dass Systeme mit zwei und vier Prozessoren in ihrer Leistung erheblich niedriger sind als Systeme mit einem Prozessor. Dies bedeutet, dass alle Benutzer von CPUs, RAMs, SSDs, LANs und FCs, die in Multiprozessorsystemen gekauft wurden, im Vergleich zu Einzelprozessoren deutlich geringere Renditen erhalten.
- Ressourcenplaner selbst können mit schwerwiegenden Fehlern arbeiten. Hier ist einer der Artikel zu diesem Thema.
- Die von Intel und AMD angebotenen Technologien zur Überwachung von RAM und Cache ermöglichen es, das Verhalten virtueller Maschinen zu untersuchen und so zu platzieren, dass laute Nachbarn leise virtuelle Maschinen nicht stören.
- Erweiterung des Parametersatzes (Netzwerk, Speicher, Priorität der virtuellen Maschine, Migrationskosten, Migrationsbereitschaft).
Insgesamt
Das Ergebnis unserer Arbeit zur Verbesserung der Ausgleichsalgorithmen war eine eindeutige Schlussfolgerung, dass es dank moderner Algorithmen möglich ist, die Ressourcen (25-30%) der Rechenzentren erheblich zu optimieren und die Qualität des Kundendienstes zu verbessern.
Der auf neuronalen Netzen basierende Algorithmus ist natürlich eine interessante Lösung, die weiterentwickelt werden muss, und ist aufgrund bestehender Einschränkungen nicht zur Lösung solcher Probleme auf Volumes geeignet, die für private Clouds charakteristisch sind. Gleichzeitig zeigte der Algorithmus in öffentlichen Wolken von erheblicher Größe gute Ergebnisse.
In den folgenden Artikeln erfahren Sie mehr über die Funktionen von Prozessoren, Schedulern und das Balancing auf hoher Ebene.