In den letzten Jahren hat die
neuronale maschinelle Übersetzung (NMP) unter Verwendung der "Transformator" -Modelle außerordentliche Erfolge erzielt. IWFs, die auf tiefen neuronalen Netzen basieren, werden normalerweise von Anfang bis Ende in sehr umfangreichen parallelen Fällen von Texten (Textpaaren) ausschließlich auf der Grundlage der Daten selbst trainiert, ohne dass genaue Sprachregeln zugewiesen werden müssen.
Trotz aller Erfolge können NMP-Modelle empfindlich auf kleine Änderungen der Eingabedaten reagieren, die sich in Form verschiedener Fehler äußern können - Unterübersetzung, Überübersetzung, falsche Übersetzung. Zum Beispiel wird der nächste deutsche Vorschlag, der hochwertige NMP-Modell „Transformator“, korrekt übersetzt.
"Der Sprecher des Untersuchungsbefehls hat die Berechtigung, vor Gericht zu ziehen, fällt sich die geladenen Zeugenaussichten weigern gehört, eine Aussage zu machen."
(Maschinelle Übersetzung: „Der Sprecher des Untersuchungsausschusses hat angekündigt, dass er vor Gericht gestellt wird, wenn sich die vorgeladenen Zeugen weiterhin weigern, auszusagen.“)
Übersetzung: Ein Vertreter des Untersuchungsausschusses gab bekannt, dass eingeladene Zeugen, die sich weiterhin weigern, auszusagen, zur Rechenschaft gezogen werden.
Wenn Sie jedoch eine kleine Änderung am eingehenden Satz vornehmen und das Wort geladenen durch das Synonym vorgeladenen ersetzen, ändert sich die Übersetzung dramatisch (und wird falsch):
"Der Sprecher des Untersuchungsbefehls hat, vor Gericht zu ziehen, fällt sich die vorgeladenen Zeugenaussichten weigern gehört, eine Aussage zu machen."
(Maschinelle Übersetzung: „Der Untersuchungsausschuss hat angekündigt, dass er vor Gericht gestellt wird, wenn die eingeladenen Zeugen sich weiterhin weigern, auszusagen.“)
Übersetzung: Der Untersuchungsausschuss kündigte an, dass er vor Gericht gestellt werde, wenn eingeladene Zeugen sich weiterhin weigern, auszusagen.
Die mangelnde Stabilität von NMP-Modellen ermöglicht es nicht, kommerzielle Systeme auf Aufgaben anzuwenden, bei denen ein ähnliches Maß an Instabilität nicht akzeptabel ist. Daher ist die Verfügbarkeit des Lernens nachhaltiger Übersetzungsmodelle nicht nur wünschenswert, sondern häufig erforderlich. Obwohl die Stabilität neuronaler Netze von einer Gemeinschaft von Computer-Vision-Forschern aktiv untersucht wird, gibt es nur wenige Materialien zu stabilen Lern-NMP-Modellen.
In unserem
Artikel „Nachhaltige maschinelle Übersetzung mit doppeltem kontradiktorischem Input“ schlagen wir einen Ansatz vor, der die generierten konträren Beispiele verwendet, um die Stabilität maschineller Übersetzungsmodelle für kleine Input-Änderungen zu verbessern. Wir unterrichten ein stabiles NMP-Modell, um Wettbewerbsbeispiele zu überwinden, die unter Berücksichtigung des Wissens über dieses Modell generiert wurden, und um seine Vorhersagen zu verzerren. Wir zeigen, dass dieser Ansatz die Effizienz des NMP-Modells in Standardtests verbessert.
Modelltraining mit AdvGen
Ein ideales NMP-Modell sollte ähnliche Übersetzungen für verschiedene Eingaben generieren, die geringfügige Unterschiede aufweisen. Die Idee unseres Ansatzes ist es, das Übersetzungsmodell mithilfe von Wettbewerbsinformationen zu stören, um seine Stabilität zu erhöhen. Dies erfolgt mithilfe des AdvGen-Algorithmus (Adversarial Generation), der gültige Wettbewerbsbeispiele generiert, die das Modell stören, und diese dann für das Training in das Modell einspeist. Obwohl diese Methode von der Idee der generativen Wettbewerbsnetze (GSS) inspiriert ist, wird kein diskriminierendes Netzwerk verwendet, sondern lediglich ein Wettbewerbsbeispiel für die Ausbildung, nämlich die Diversifizierung und Erweiterung des Schulungssatzes.
Der erste Schritt besteht darin, die Daten mit AdvGen zu empören. Wir beginnen mit der Verwendung eines Transformators, um den Verlust einer Übertragung basierend auf dem ursprünglichen eingehenden Angebot, dem Zieleingangsangebot und dem Zielausgangsangebot zu berechnen. AdvGen wählt dann zufällig die Wörter im ursprünglichen Satz aus und geht davon aus, dass sie gleichmäßig verteilt sind. Jedes Wort hat eine entsprechende Liste ähnlicher Wörter, d.h. Substitutionskandidaten. Daraus wählt AdvGen das Wort aus, das am wahrscheinlichsten zu Fehlern im Ausgang des Transformators führt. Dann wird dieser erzeugte gegnerische Satz an den Transformator zurückgeführt, wodurch die Verteidigungsphase gestartet wird.
 Zuerst wird das Transformatormodell auf den eingehenden Satz (unten links) angewendet, und dann wird der Übersetzungsverlust zusammen mit dem Zielausgabesatz (oben oben) und dem Zieleingabesatz (in der Mitte rechts, beginnend mit „<sos>“) berechnet. AdvGen akzeptiert dann den ursprünglichen Satz, die Wortauswahlverteilung, die Wortkandidaten und den Übersetzungsverlust als Eingabe und erstellt ein Beispiel für einen kontroversen Quellcode.
Zuerst wird das Transformatormodell auf den eingehenden Satz (unten links) angewendet, und dann wird der Übersetzungsverlust zusammen mit dem Zielausgabesatz (oben oben) und dem Zieleingabesatz (in der Mitte rechts, beginnend mit „<sos>“) berechnet. AdvGen akzeptiert dann den ursprünglichen Satz, die Wortauswahlverteilung, die Wortkandidaten und den Übersetzungsverlust als Eingabe und erstellt ein Beispiel für einen kontroversen Quellcode.In der Verteidigungsphase wird der gegnerische Quellcode an den Transformator zurückgemeldet. Der Übersetzungsverlust wird erneut gezählt, diesmal jedoch unter Verwendung der umstrittenen Eingabequelle. Mit der gleichen Methode wie zuvor verwendet AdvGen einen gezielten eingehenden Satz, eine aus der Aufmerksamkeitsmatrix berechnete Wortauswahlverteilung, Kandidaten für das Ersetzen von Wörtern und einen Übersetzungsverlust, um ein Beispiel für umstrittenen Quellcode zu erstellen.
 In der Verteidigungsphase wird der gegnerische Quellcode zum Eingang für den Transformator, und die Übersetzungsverluste werden berechnet. Mit der gleichen Methode wie zuvor erstellt AdvGen ein Beispiel für umstrittenen Quellcode basierend auf der Zieleingabe.
In der Verteidigungsphase wird der gegnerische Quellcode zum Eingang für den Transformator, und die Übersetzungsverluste werden berechnet. Mit der gleichen Methode wie zuvor erstellt AdvGen ein Beispiel für umstrittenen Quellcode basierend auf der Zieleingabe.Schließlich wird der gegnerische Satz zum Transformator zurückgeführt, und der Stabilitätsverlust wird basierend auf dem gegnerischen Quellenbeispiel, dem gegnerischen Zieleingabebeispiel und dem Zielsatz berechnet. Wenn der Eingriff in den Text zu erheblichen Verlusten führte, werden diese minimiert, sodass die Modelle nicht denselben Fehler wiederholen, wenn sie auf ähnliche Störungen stoßen. Wenn andererseits die Störung zu kleinen Verlusten führt, passiert nichts, was darauf hindeutet, dass das Modell solche Störungen bereits bewältigen kann.
Modellleistung
Wir demonstrieren die Wirksamkeit unseres Ansatzes, indem wir ihn auf Standardübersetzungstests von Chinesisch nach Englisch und von Englisch nach Deutsch anwenden. Wir erzielen eine signifikante Verbesserung der Übersetzung um 2,8 bzw. 1,6 Punkte BLEU im Vergleich zum Konkurrenzmodell des Transformators und erzielen eine neue Rekordqualität der Übersetzung.
 Vergleich von Transformatormodellen bei Standardtests
Vergleich von Transformatormodellen bei StandardtestsAnschließend bewerten wir die Leistung unseres Modells anhand eines verrauschten Datensatzes mithilfe eines Verfahrens, das dem für AdvGen beschriebenen ähnlich ist. Wir nehmen reine Eingabedaten, zum Beispiel solche, die in Standardtests von Übersetzern verwendet werden, und wählen zufällig Wörter aus, die wir durch ähnliche ersetzen. Wir stellen fest, dass unser Modell im Vergleich zu anderen neueren Modellen eine verbesserte Stabilität aufweist.
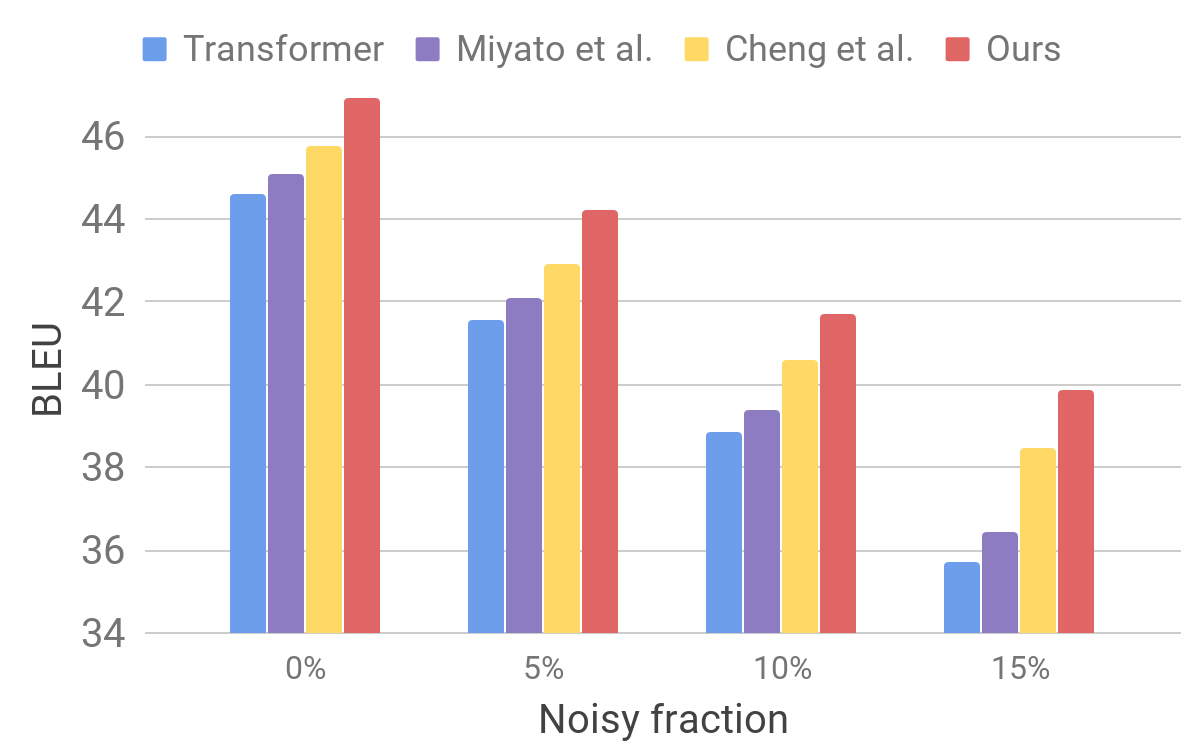 Vergleich von Transformatoren und anderen Modellen mit künstlich verrauschten Eingangsdaten
Vergleich von Transformatoren und anderen Modellen mit künstlich verrauschten EingangsdatenDiese Ergebnisse zeigen, dass unsere Methoden in der Lage sind, kleine Störungen im eingehenden Satz zu überwinden und die Effizienz der Verallgemeinerung zu verbessern. Er ist konkurrierenden Übersetzungsmodellen voraus und erzielt bei Standardtests eine Rekordübersetzungseffizienz. Wir hoffen, dass unser Übersetzermodell eine stabile Grundlage für die Verbesserung der Ergebnisse der Lösung vieler der folgenden Probleme darstellt, insbesondere derjenigen, die unvollkommene Eingabetexte empfindlich oder nicht tolerieren.