A / B-Tests sind eine leistungsstarke Methode zum Testen von Schnittstellen, bevor sie für ein ganzes Publikum veröffentlicht werden. Ich habe mich entschlossen zu erklären, woraus dieses Tool besteht, welche Protokollierungsfunktionen es hat, wie Metriken kompiliert werden und was die Essenz der Experimente im Frontend ist. Lassen Sie uns über ihre Geräte und Dienste zur Lösung der täglichen analytischen Aufgaben sprechen. Wir werden verschiedene Entwicklungspfade für einen Entwickler diskutieren, der anscheinend bereits in der Lage ist, alles zu tun, aber mehr will.
- Mein Name ist Lesha, ich arbeite in der Suche und entwickle die wichtigsten, wahrscheinlich Yandex-Produkt - Suchergebnisse.
Sie alle haben auf die eine oder andere Weise jemals eine der Suchanfragen verwendet. Ein paar Begriffe. Das Problem besteht aus verschiedenen Blöcken. Es gibt einfache organische Dokumente, die wir aus dem gesamten Internet sammeln und irgendwie präsentieren können, und es gibt spezielle Blöcke, die wir als spezielles Markup anzeigen. Wir kennen viele Daten über deren Inhalt. Diese Blöcke werden Zauberer genannt. Spezifische Terminologie von Yandex und nicht nur.
Heute möchte ich Ihnen erzählen, wie wir Experimente durchführen, welche Nuancen, Werkzeuge und welche wunderbaren Erfindungen in unseren Zaschniks in diesem Bereich unserer Tätigkeit stecken.
Wofür werden A / B-Tests durchgeführt?
Wo soll ich anfangen? Warum braucht Yandex A / B-Experimente?
Ich möchte mit den Texten beginnen. Vor nicht allzu langer Zeit habe ich mit meiner Tochter einen kurzen wissenschaftlichen Film „4,5 Milliarden Jahre in 40 Minuten“ gesehen. Geschichte der Erde. " Es gibt sehr oft A / B-Experimente. Einschließlich dieser. Ich habe versucht, eine der interessantesten und unterhaltsamsten auf dieser Folie zu machen. Dies ist, wenn die Evolution mehrere Zweige hat. Zum Beispiel gibt es zwei Familien: Beuteltiere und Plazenta. Und wie wir jetzt sehen, gewinnt die Plazenta irgendwie. Deshalb gewinnen sie.

Dies ist bereits das menschliche Gehirn konzipiert. Bei der pränatalen und Weiterentwicklung von Beuteltieren härtet die Schädelbox schnell aus und verhindert die Entwicklung des Gehirns. Und in der Plazenta schreitet alles voran, alles ist weich, bis sich das Gehirn mit Rillen faltet, die Oberfläche wächst und der Neokortex steil wird. Infolgedessen wird die Plazenta in der Evolution gewinnen. Was ist der Punkt? Die Natur hat Evolution und ihre treibenden Kräfte sind Mutation und natürliche Selektion, wie Sie wahrscheinlich wissen.

Das Unternehmen hat eine Analogie zu den A / B-Experimenten der Natur: Jedes Unternehmen möchte sich stabil entwickeln und investiert bestimmte Anstrengungen, indem es A / B-Experimente verwendet, um etwas zu mutieren, etwas zu ändern. Das Unternehmen nutzt die gesamte mathematische Kraft der Analytik, um genau diese Experimente auszuwählen.
A / B-Experimente und die gesamte Entwicklung zielen darauf ab, Ziele zu erreichen, sich von außen beobachten zu können, sich mit Wettbewerbern zu vergleichen und nach bestimmten neuen Nischen und Hypothesen zu suchen. Für Entwickler im Allgemeinen, insbesondere für Front-End-Anbieter, ist es wichtig, neue Funktionen auf einem kleinen Teil der Produktion zu testen.

Eine Kurzgeschichte sieht ungefähr so aus. Wir können sagen, dass 2010, als unsere Produktmanager die ersten A / B-Experimente durchgeführt haben, eine solche Nachperiode nach dem Urknall ist. Bestimmte Sternhaufen sind gerade erst entstanden, ein Verständnis dafür, wie A / B-Experimente durchgeführt werden, was zu betrachten ist, wie zu protokollieren ist. Die ersten Unebenheiten, die ersten Fehler wurden angesammelt.
In diesem Zeitraum von 2010 bis 2019 haben wir signifikante Ergebnisse erzielt. Alle diese Begriffe in Bezug auf Protokolle, Experimente, Metriken, Ziele, Erfolge usw. sind für uns bereits heute grundlegend, insbesondere für Neulinge bei neuen Entwicklern. Dies ist unser Slang, unsere innere Yandex-Mentalität.
Große Suche
Wir gehen direkt zum Fleisch über die große Suche. Big Search in seiner Struktur sieht ungefähr so aus.
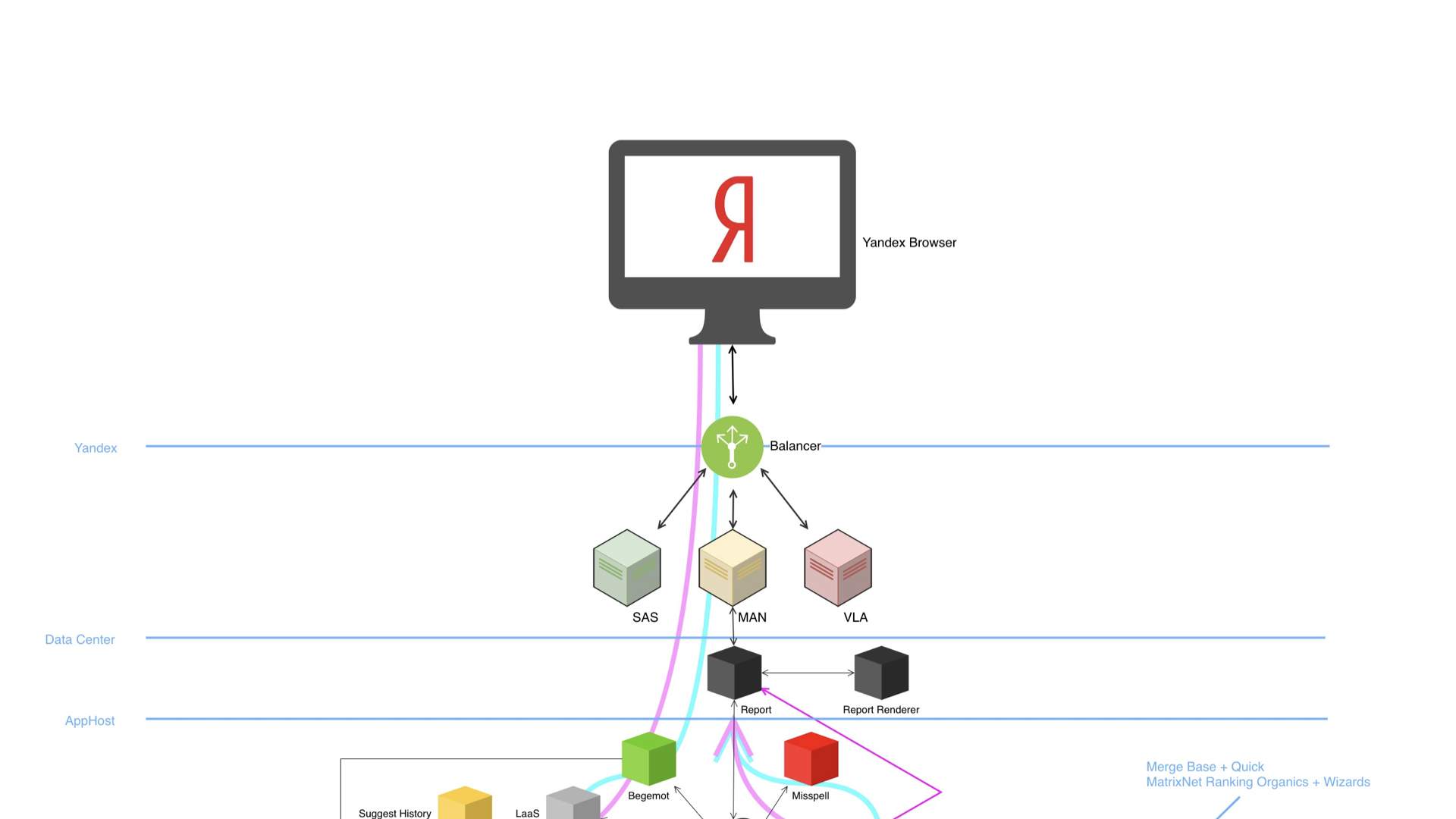
Wir haben einen Browser, einen Balancer, viele Rechenzentren und eine riesige Infrastruktur unter der Haube. Das Diagramm zeigt, dass das Gerät komplex ist, es gibt viele Komponenten. Und was am meisten überrascht, all diese Komponenten können A / B-Experimente durchführen und natürlich Protokolle schreiben und analysieren.
Protokolle

Protokolle werden von vielen, vielen Komponenten geschrieben. Natürlich ist es für uns interessanter, im Kontext des Frontends zu sprechen. Das Frontend protokolliert zwei große signifikante Slices. Hierbei handelt es sich um rein technische Protokolle, die sich auf die direkte Messung der Leistung einiger Zeit auf Clientgeräten beziehen. Echte Benutzermessung, RUM-Metriken. Hier sind die Zeiten vor dem ersten Byte, vor dem ersten Rendern, vor dem Laden des gesamten DOM-Inhalts und vor der Interaktivität.
Daneben gibt es Protokolle, die sowohl vom Server- als auch vom Client-Satz geschrieben wurden. Dies sind Lebensmittelprotokolle. In unserer Realität gibt es auch hier einen Begriff „Affenbrotbaum“. Warum Affenbrotbaum? Denn der Baum: der Komponentenbaum, der Feature-Baum, in dem eines der Hauptprotokolle die Protokolle von Impressionen, Klicks und anderen technischen Ereignissen sind, die wir für die nachfolgende Analyse registrieren.
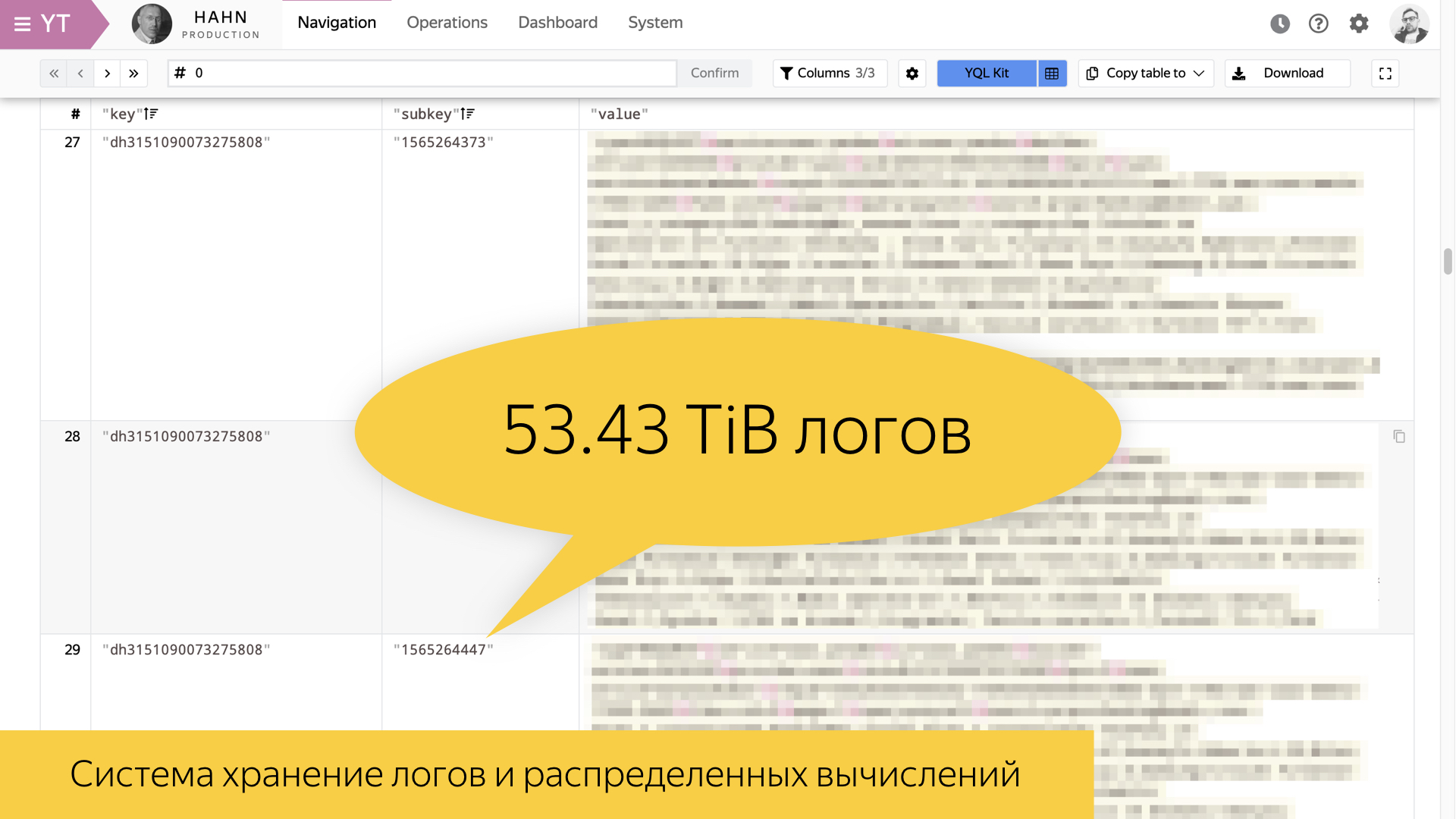
Diese Folie zeigt ein Tool zum Speichern von Protokollen in Yandex und zum verteilten Rechnen. Wir haben es
Yandex Tables genannt, YT . Alles, was in Yandex entwickelt wurde, hat den Buchstaben Y. Ich habe versucht, mich an das Analogon dieses Werkzeugs in der Außenwelt zu erinnern. Meiner Meinung nach hat Facebook ein MapReduce-Tool namens Hadoop. Damit können Sie Speicher und Berechnung implementieren.
Die Folie zeigt Statistiken für den 8. August dieses Jahres. Eines der wertvollsten Suchprotokolle, Benutzersitzungen, hat in seiner Form 54 Terabyte pro Tag. Dies ist eine riesige Menge an Informationen, die nicht in ihrer Rohform geschaufelt werden können. Daher muss man in der Lage sein, einige hochrangige Geschichten zu erstellen.
Insbesondere um mit Protokollen arbeiten zu können, müssen alle unsere besonders erfahrenen Entwickler eine Art Analysetool beherrschen.
In Yandex gibt es ein
YQL- Tool. Dies ist eine SQL-ähnliche Abfrage- und Berechnungssprache über unsere Protokolle, mit der Sie alle Arten von Umgebungen erstellen, nur Analysen auf niedriger Ebene durchführen, bestimmte Zahlen, durchschnittliche Perzentile direkt anzeigen und Berichte erstellen können. Das Tool ist sehr leistungsfähig, hat eine riesige verzweigte API und viele Funktionen. Viele Infrastrukturprozesse bauen auf dieser Basis auf.
Darüber hinaus ist das Jupyter-Tool bei unseren Front-End-Entwicklern und insbesondere bei Analysten sehr gefragt und beliebt. Mit der Leistung von Numpy-Tools und anderen Ihnen bekannten Tools, z. B. Pandas, ist es bereits möglich, Transformationen und Analysen auf hoher Ebene über unsere Protokolle durchzuführen.
Wir schätzen die Protokolle sehr und kämpfen buchstäblich um jeden Eintrag. Zu diesem Zweck gibt es im Repository unseres Suchprojekts Tests im Front-End-Code, mit denen wir überprüfen können, ob alle Ereignisse korrekt aufgezeichnet wurden. Wir schreiben Tests für jede unserer Funktionen, können ein bestimmtes Skript überprüfen, auf bestimmte Links und Schaltflächen klicken, durch bestimmte Galerien in unserer Benutzeroberfläche scrollen und sehen, wie genau die Anzahl der Protokolle genau mit den erwarteten Werten aufgezeichnet wird, die wir aufgezeichnet haben und für die wir erstellt haben einige Standards. Und dann gehen wir auf diese Referenzwerte ein.
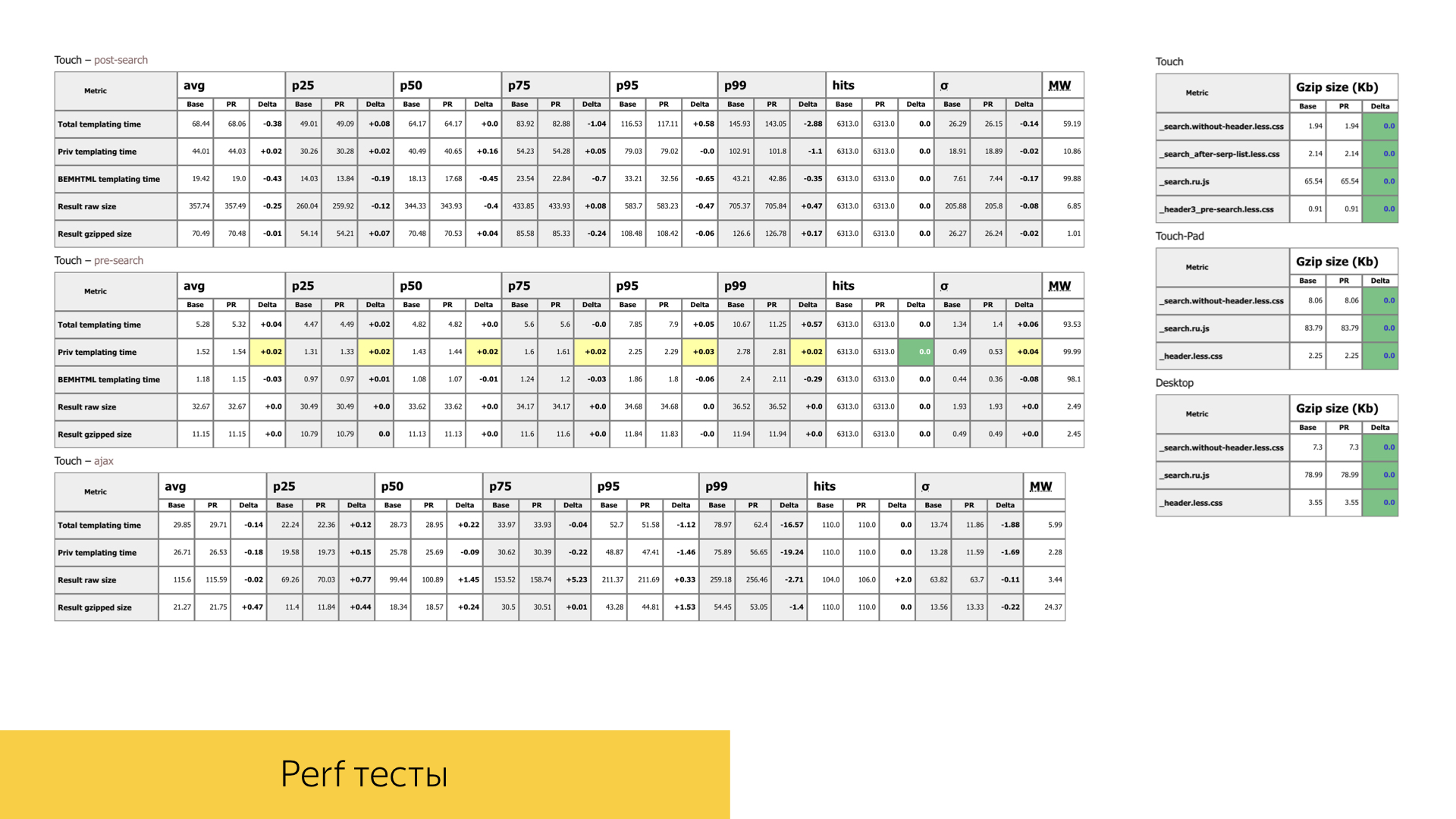
Wir achten auch sehr auf die Leistung unserer Schnittstellen. Bei jeder Poolanforderung mit neuen Funktionen oder beim Refactoring vorhandener Funktionen achten wir besonders auf die Zeiten, das Volumen und die Anzahl der Aufrufe bestimmter Funktionen. Auf der Folie befindet sich einer der Berichte einer vollständig zufälligen Poolanforderung. Wir haben zwei Suchphasen, eine ist vom Ajax-Typ: Zuerst laden wir den Header auf der Seite mit dem Suchpfeil, und wenn alle Suchquellen funktionieren, können wir beim Rendern des Hauptteils der Ausgabe immer noch die Vorlagenzeiten und die gesamte Leistung messen.
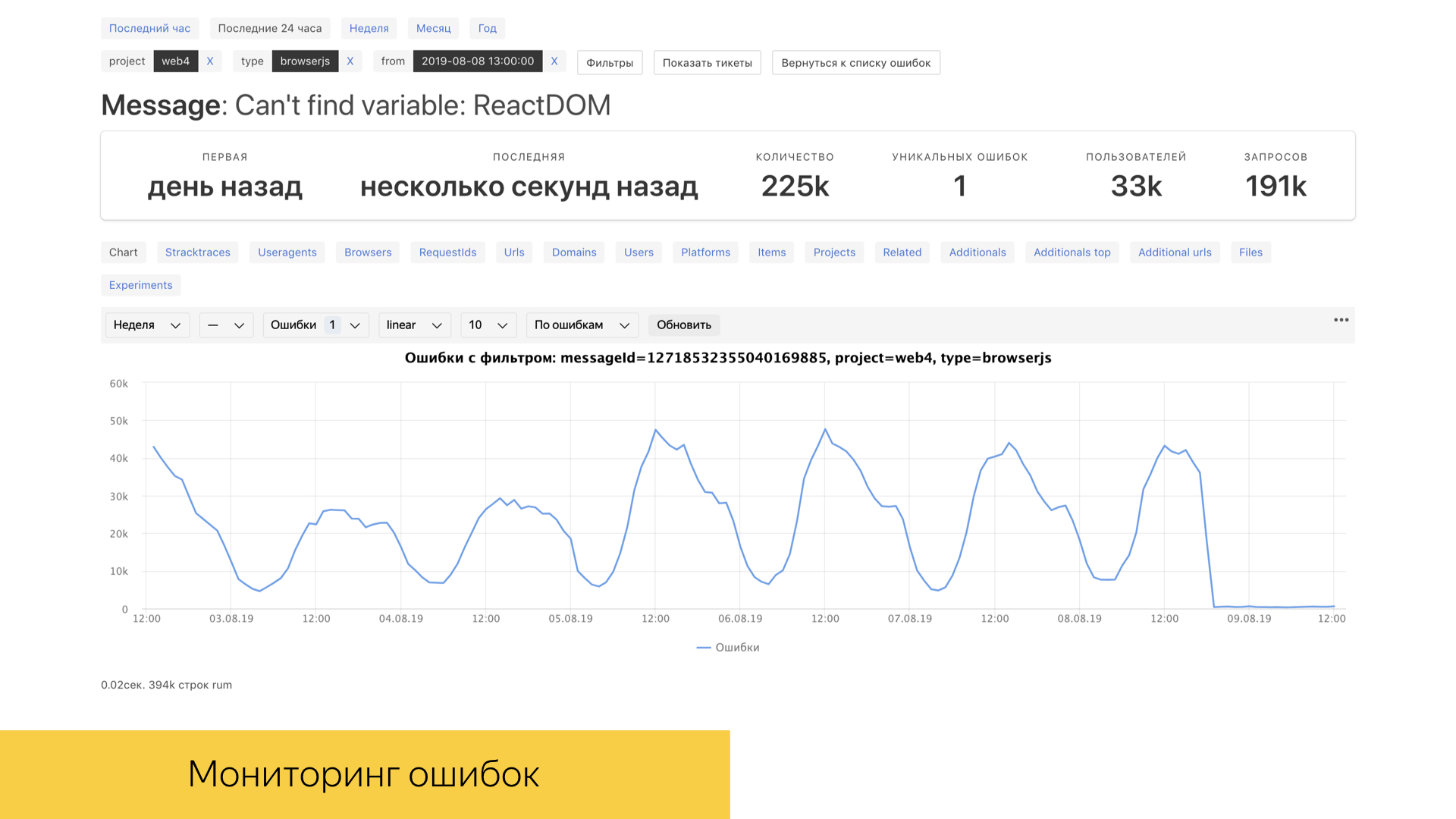
Für uns wie natürlich und für jedes andere Thema in der IT sind Fehler in der Produktion und in speziellen Umgebungen sehr wichtig. Wir haben ein Tool namens Fehlerverstärker, mit dem Sie echte Produktionsfehler in Echtzeit mit einem relativ guten Zeitrahmen anzeigen können. Unter der Haube verwendet dieses Tool die ClickHouse-Datenbank, in der Anforderungen recht schnell verarbeitet werden, und die Datenbank selbst ist für analytische Arbeiten ausgelegt. Die meisten Interaktionen werden speziell mit ClickHouse implementiert.
Wir sprachen über Protokolle, über ihre Sorten. Es gibt viele von ihnen. Um Experimente zu verschieben und etwas zu analysieren, um Entscheidungen über etwas zu treffen, haben wir eine große Anzahl von Metriken. Dies sind einige Windungen über große Mengen von Rohdaten.
Metriken
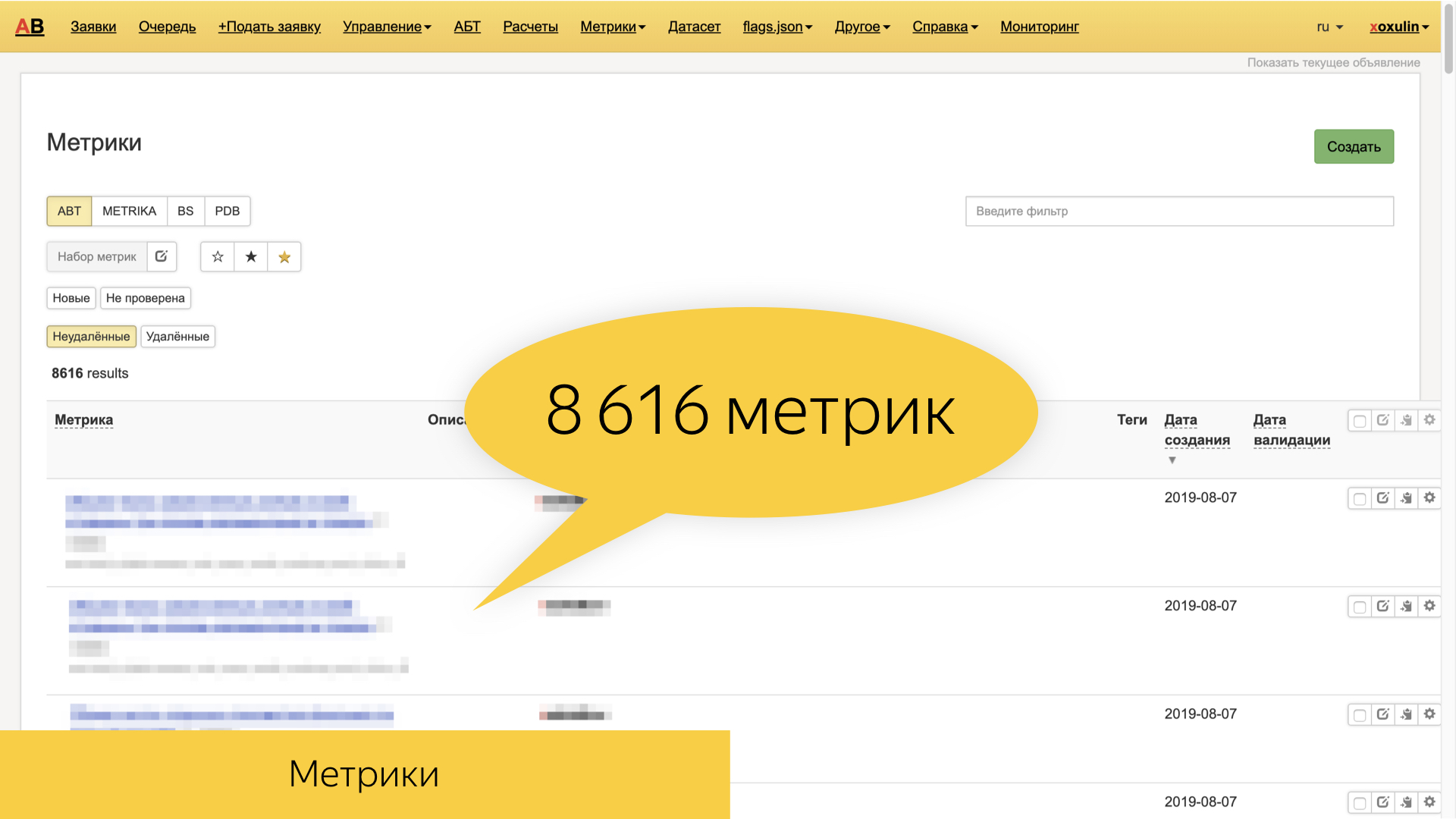
Yandex verfügt jetzt über ungefähr 8,6 Tausend verschiedene Metriken, die auf denselben Rohprotokollen basieren - und übergeordneten Protokollen wie Such- und Benutzersitzungen. Sie sind sehr vielfältig und oft präzise merkmalsorientiert. Das heißt, dies sind Metriken, die für einen bestimmten Zauberer, einen bestimmten Block, einen Teil der Anforderungen und die Art der Dokumente, die wir anzeigen, spezifisch sind.
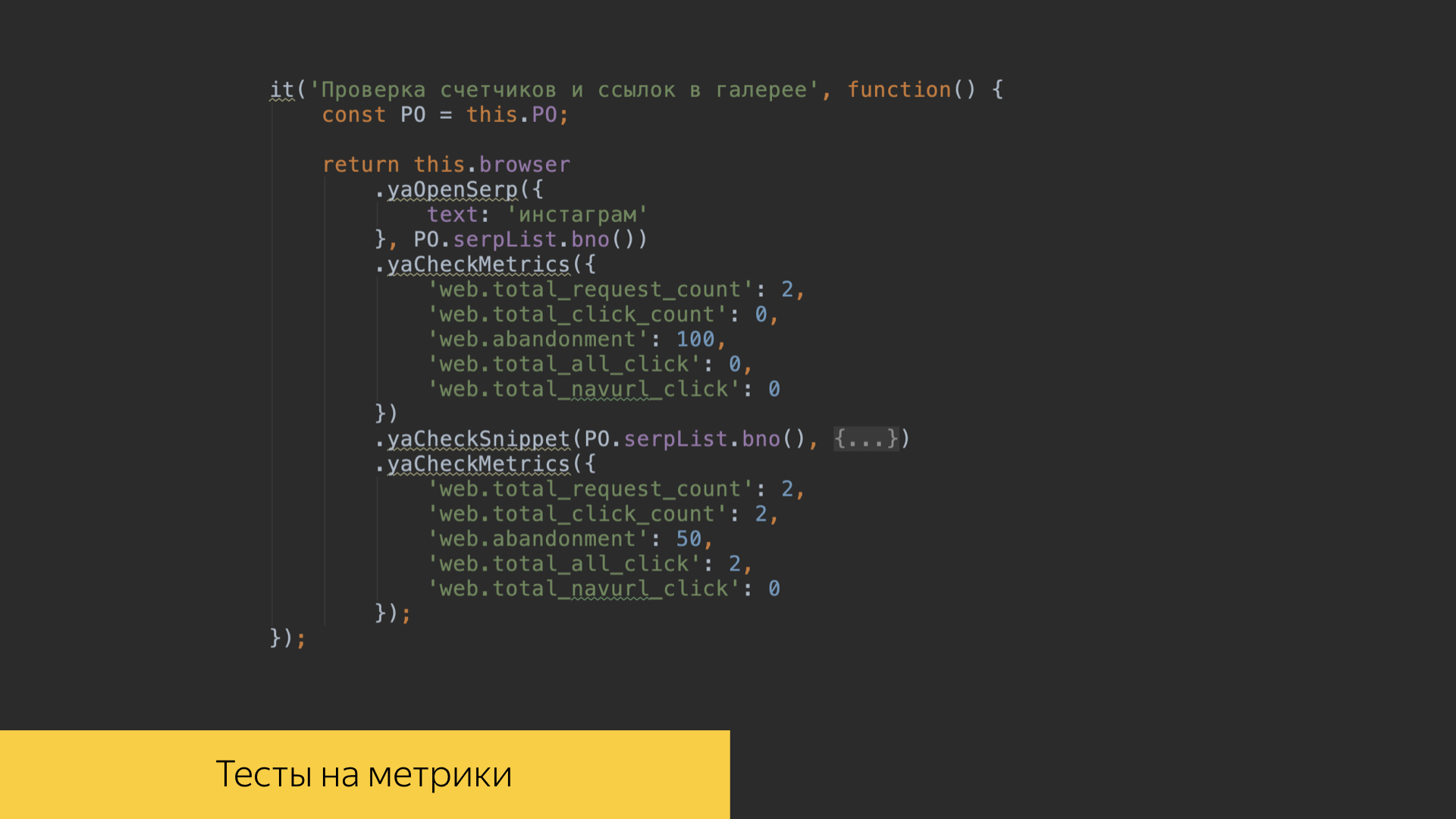
In unseren Testszenarien ist es möglich, den Wert von Metriken in unseren eigenen Schnittstellen zu überprüfen. Wenn wir bestimmte Szenarien verloren haben, können wir die Ergebnisse von Berechnungen über die Protokolle und die Beschaffung bestimmter Metrikwerte anzeigen.
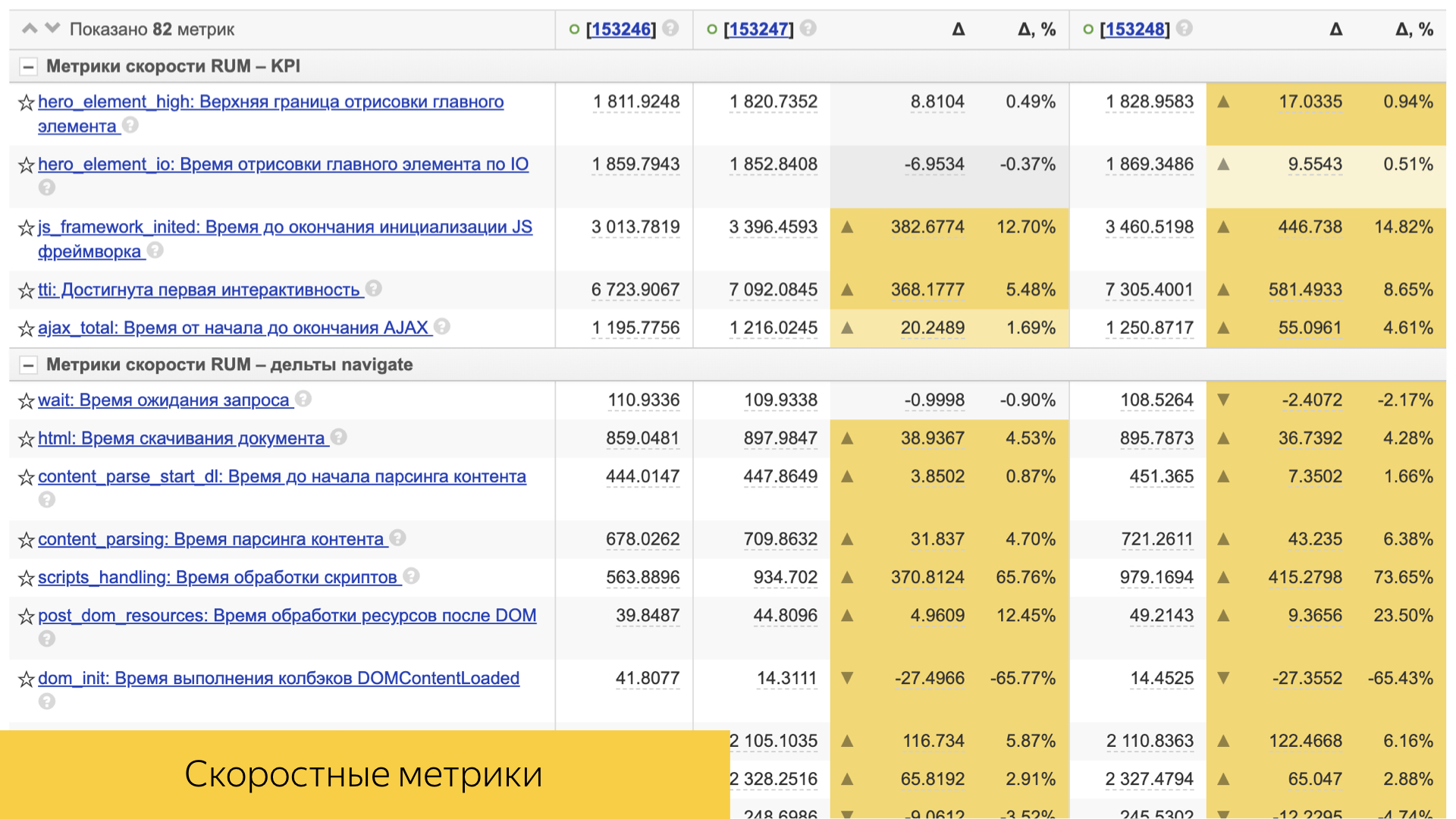
Eine wichtige Rolle spielen Geschwindigkeitsmetriken. Alle von ihnen sind einfach genug angeordnet. Dies ist normalerweise entweder eine Art Perzentil oder der Durchschnittswert und seine Abweichung und statistische Signifikanz.
Es gibt viele von ihnen, die sowohl den Zeitpunkt der Standardisierung als auch den Zeitpunkt der Übermittlung von Inhalten an das Gerät des Benutzers berücksichtigen.
Die direkte Clientleistung wird ebenfalls berücksichtigt: Renderzeit, Interaktivitätszeit und andere.
Die Experimente

Wie führen wir also Experimente durch? Zum Beispiel gibt es zwei Benutzer, die sich plötzlich für die Yandex-Suche entschieden haben. Wir haben uns geeinigt - wir gehen heute zum Beispiel zu Starbucks und suchen ihn über unsere Suche. Ihre Anfragen, die in die Infrastruktur unserer Suchquellen fallen, sind mit bestimmten Markierungen gekennzeichnet. Durch Marker fallen diese Benutzer in verschiedene Experimentierkörbe. Jeder Korb enthält einen bestimmten Satz von Flags, die Experimente in jeder der Suchquellen aktivieren. Diese beiden Benutzer haben beispielsweise Suchergebnisse aufgerufen und Suchhinweise verwendet. Die erste führt "Starbucks" ein, sieht einige Wort-für-Wort-Hinweise in Form von Wörtern. Als er mit einer Suche endet, sieht er einen Block über diese Organisation, sagt - ja, ich habe ihn gefunden, ich gehe dorthin. Und der zweite Benutzer entdeckt einen Navigationshinweis bereits in der Oberfläche der Suchhinweise, wechselt schnell zur Organisation und erhält schneller eine Antwort.
Für all diese Vielzahl von Änderungen, Unterschiede in der Benutzeroberfläche und einer bestimmten Funktionalität ist das BEM-Tool verantwortlich. Dies ist nicht nur ein Framework, sondern eine ganze Methodik für die Deklaration visueller Komponenten, deren Modifikationen. Auch hier im Hintergrund befinden sich die DNA-Chromosomen, die durch bem zu mutieren scheinen. Tatsächlich ist bem Yandex-DNA, die DNA von Experimenten im Frontend.

Es gibt mehrere Implementierungen in der Methodik. Eine davon befindet sich auf dem bereits etablierten i-bem-Stack, der sich irgendwo unter der mit jQuery verbundenen Haube befindet. Dies ist bereits eine ziemlich ausgereifte Technologie. Auf einem solchen Stapel können wir viele Probleme lösen. Die bem-react-Technologie, die bereits im React-Framework und in der TypeScript-Sprache implementiert ist, gewinnt heute erheblich an Bedeutung und Entwicklung. Mit all diesen Tools können Sie Experimente erstellen und die Hauptidee predigen - die Möglichkeit, sowohl visuelle Komponenten als auch deren Modifikationen zu deklarieren. Wir haben eine ganz eigene Ebene im Repository mit Deklarationen dieser Experimente. Um 2015 stellten sie jedoch fest, dass es wirtschaftlich unrentabel war, unsere experimentellen Flaggen über den gesamten Front-End-Code zu verteilen. Tatsache ist, dass Versuchseinheiten eine echte Produktion erreichen und alles, was nicht verwendet wird, später nur sehr schwer aus dem Code herausgeschnitten werden kann. Deshalb haben wir sie auf eine separate Definitionsebene vertrieben. Und auch hier dank der Bem-Methodik, die uns die Möglichkeit gab, Neudefinitionsebenen zu verwenden. Wir erklären unsere Experimente mit ihnen.

Dies ist einer der Berichte von Experimenten. Zwei Spalten: Kontrolle und Experiment. Vor Ihnen steht noch nicht einmal alles, was im Bericht steht. Warum ist er so lang? Zunächst haben Sie gesehen, wie viele Metriken wir haben - 8,6 Tausend.

Die Hauptrolle spielen jedoch nur die unterschiedlichen Metriken. Und wir können unsere Experimente gleichzeitig durchführen, dh bei einem Benutzer können wir gleichzeitig etwa 20 Experimente durchführen. Sie stehen in keiner Weise in Konflikt miteinander, und in allen unseren Experimenten werden nur ihre reinen Produktmetriken gefärbt, ohne sich gegenseitig zu beeinflussen. Mittlerweile sind rund 800 Experimente in der Produktion: nicht nur Suchmaschinen, sondern auch von so vielen Diensten. Das Tool heißt AB, was nicht überraschend ist. Die Dienste starten Experimente darin, deklarieren bestimmte Stichproben und untersuchen dann die Unterschiede zwischen den Metriken, die sich nach einiger Zeit in Experiment und Kontrolle zu unterscheiden beginnen.
Verwandte Entwicklerrollen
Infolge dieser Verschiedenartigkeit in der Arbeit von Front-End-Entwicklern gibt es sogar Rollen unter ihnen. Es gibt Experten für Experimente, und dafür geben wir offiziell Erfolge im Rahmen des internen Yandex-Netzwerks, die Leute bestehen wirklich Prüfungen. Sie analysieren Experimente, validieren ihre Ergebnisse über Experten und erhalten einen Pass mit der Aufschrift: "Ich bin Analyst, ich kann Experimente analysieren." Im Allgemeinen konzentrieren sich alle Arbeiten mit Experimenten mit unseren Metriken in erster Linie auf die Verbesserung des Produkts selbst. Ich bin einer der Vertreter, ich bin sehr motiviert, das Produkt zu entwickeln, und nicht nur den Code und nicht die Technologie. Und es treibt mich wirklich an, wenn ich zu einem Team komme und ein Produkt herstelle.

Was ist das Endergebnis? Wir haben eine große Anzahl von Protokollen, die täglich auf unsere Speichersysteme geschrieben werden. Es gibt eine große Anzahl von Metriken, die wir berechnen und mit denen wir Experimente durchführen. Sehr große Infrastruktur. Das modernste Tool, mit dem Sie eine Vielzahl von Tools implementieren können, ist das bem-react-Paket. Wir legen großen Wert auf Indikatoren für Geschwindigkeit und Qualität sowie Produktstabilität. Und im Allgemeinen wachsen in unseren Entwicklern immer mehr neue Rollen in Bezug auf die Hauptspezialität - das Frontend. Ich habe alles Vielen Dank für Ihre Aufmerksamkeit.