Obwohl neuronale Netze vor nicht allzu langer Zeit ( zum Beispiel ) für die Sprachsynthese verwendet wurden, haben sie es bereits geschafft, die klassischen Ansätze zu überholen, und jedes Jahr treten immer neuere Aufgaben auf.
Zum Beispiel gab es vor ein paar Monaten eine Implementierung der Sprachsynthese mit Voice Cloning Real-Time-Voice-Cloning . Versuchen wir herauszufinden, woraus es besteht, und realisieren wir unser mehrsprachiges (russisch-englisches) Phonemmodell.
Gebäude
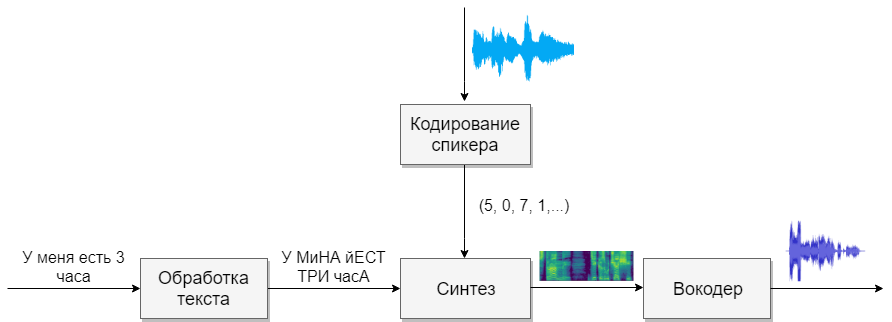
Unser Modell wird aus vier neuronalen Netzen bestehen. Der erste konvertiert den Text in Phoneme (g2p), der zweite konvertiert die Sprache, die wir klonen möchten, in einen Vektor von Zeichen (Zahlen). Das dritte wird Mel-Spektrogramme basierend auf den Ausgaben der ersten beiden synthetisieren. Und schließlich wird der vierte Ton von Spektrogrammen empfangen.
Datensätze
Dieses Modell braucht viel Sprache. Nachfolgend finden Sie die Grundlagen, die Ihnen dabei helfen werden.
Textverarbeitung
Die erste Aufgabe ist die Textverarbeitung. Stellen Sie sich den Text in der Form vor, in der er weiter gesprochen wird. Wir werden Zahlen in Worten darstellen und Abkürzungen öffnen. Lesen Sie mehr im Artikel über Synthese . Dies ist eine schwierige Aufgabe. Nehmen wir also an, wir haben bereits Text verarbeitet (er wurde in den obigen Datenbanken verarbeitet).
Die nächste Frage ist, ob Graphem- oder Phonemaufzeichnung verwendet werden soll. Für eine monophone und einsprachige Stimme eignet sich auch ein Buchstabenmodell. Wenn Sie mit einem mehrsprachigen mehrsprachigen Modell arbeiten möchten, empfehle ich Ihnen, die Transkription zu verwenden (auch Google).
G2p
Für die russische Sprache gibt es eine Implementierung namens russian_g2p . Es basiert auf den Regeln der russischen Sprache und kommt mit der Aufgabe gut zurecht, hat aber Nachteile. Nicht alle Wörter betonen und sind auch nicht für ein mehrsprachiges Modell geeignet. Nehmen Sie daher das für sie erstellte Wörterbuch, fügen Sie das Wörterbuch für die englische Sprache hinzu und speisen Sie das neuronale Netzwerk (z. B. 1 , 2 ).
Bevor Sie das Netzwerk trainieren, sollten Sie sich überlegen, welche Klänge aus verschiedenen Sprachen ähnlich klingen, und Sie können ein Zeichen für sie auswählen, für das dies unmöglich ist. Je mehr Geräusche es gibt, desto schwieriger ist es, das Modell zu lernen, und wenn es zu wenige davon gibt, hat das Modell einen Akzent. Denken Sie daran, einzelne Zeichen mit betonten Vokalen hervorzuheben. Für die englische Sprache spielt sekundärer Stress eine kleine Rolle, und ich würde es nicht unterscheiden.
Lautsprecherkodierung
Das Netzwerk ähnelt der Aufgabe, einen Benutzer per Sprache zu identifizieren. Am Ausgang erhalten verschiedene Benutzer unterschiedliche Vektoren mit Zahlen. Ich schlage vor, die Implementierung von CorentinJ selbst zu verwenden, die auf dem Artikel basiert. Das Modell ist ein dreischichtiges LSTM mit 768 Knoten, gefolgt von einer vollständig verbundenen Schicht von 256 Neuronen, was einen Vektor von 256 Zahlen ergibt.
Die Erfahrung hat gezeigt, dass ein in Englisch geschultes Netzwerk gut Russisch spricht. Dies vereinfacht das Leben erheblich, da für das Training viele Daten erforderlich sind. Ich empfehle, ein bereits geschultes Modell zu nehmen und von VoxCeleb und LibriSpeech auf Englisch umzuschulen sowie alle russischen Sprachen, die Sie finden. Der Encoder benötigt keine Textanmerkung von Sprachfragmenten.
Schulung
- Führen Sie
python encoder_preprocess.py <datasets_root> , um die Daten zu verarbeiten - Führen Sie "visdom" in einem separaten Terminal aus.
- Führen Sie
python encoder_train.py my_run <datasets_root> , um den Encoder zu trainieren
Synthese
Fahren wir mit der Synthese fort. Die Modelle, die ich kenne, erhalten keinen Ton direkt aus dem Text, da dies schwierig ist (zu viele Daten). Erstens erzeugt der Text Ton in spektraler Form, und erst dann wird das vierte Netzwerk in eine vertraute Stimme übersetzt. Daher verstehen wir zunächst, wie die Spektralform mit der Stimme verbunden ist. Es ist einfacher, das umgekehrte Problem herauszufinden, wie man ein Spektrogramm aus Ton erhält.
Der Ton ist in Schritten von 10 ms in Segmente von 25 ms unterteilt (die Standardeinstellung bei den meisten Modellen). Dann wird unter Verwendung der Fourier-Transformation für jedes Stück das Spektrum berechnet (harmonische Schwingungen, deren Summe das ursprüngliche Signal ergibt) und in Form eines Diagramms dargestellt, wobei der vertikale Streifen das Spektrum eines Segments (in der Frequenz) und in der Horizontalen eine Folge von Segmenten (in der Zeit) ist. Dieser Graph wird als Spektrogramm bezeichnet. Wenn die Frequenz nichtlinear codiert wird (die unteren Frequenzen sind besser als die oberen), ändert sich die vertikale Skala (erforderlich, um die Daten zu reduzieren). Dieser Graph wird dann als Mel-Spektrogramm bezeichnet. So funktioniert das menschliche Gehör, dass wir bei den niedrigeren Frequenzen eine leichte Abweichung besser hören als bei den höheren, daher wird die Klangqualität nicht leiden
Es gibt mehrere gute Implementierungen der Spektrogrammsynthese wie Tacotron 2 und Deepvoice 3 . Jedes dieser Modelle verfügt über eigene Implementierungen, z. B. 1 , 2 , 3 , 4 . Wir werden (wie CorentinJ) das Tacotron-Modell von Rayhane-mamah verwenden.
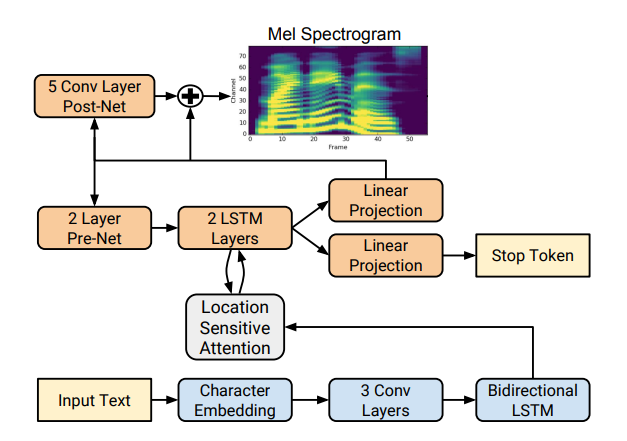
Tacotron basiert auf dem seq2seq-Netzwerk mit einem Aufmerksamkeitsmechanismus. Lesen Sie die Details im Artikel .
Schulung
Vergessen Sie nicht, utils / symbols.py zu bearbeiten, wenn Sie nicht nur die englische Sprache hparams.p, sondern auch preprocess.py synthetisieren.
Die Synthese erfordert viel sauberen, gut markierten Klang von verschiedenen Lautsprechern. Hier hilft eine Fremdsprache nicht weiter.
- Führen Sie
python synthesizer_preprocess_audio.py <datasets_root> , um verarbeiteten Sound und Spektrogramme zu erstellen - Führen Sie
python synthesizer_preprocess_embeds.py <datasets_root> , um den Sound zu codieren (erhalten Sie die Zeichen einer Stimme). - Führen Sie
python synthesizer_train.py my_run <datasets_root> , um den Synthesizer zu trainieren
Vocoder
Jetzt müssen nur noch die Spektrogramme in Ton umgewandelt werden. Das letzte Netzwerk ist dafür der Vocoder. Es stellt sich die Frage, ob es möglich ist, mit der inversen Transformation wieder Schall zu erhalten, wenn Spektrogramme aus Schall mit der Fourier-Transformation erhalten werden. Die Antwort lautet ja und nein. Die harmonischen Schwingungen, aus denen das ursprüngliche Signal besteht, enthalten sowohl Amplitude als auch Phase, und unsere Spektrogramme enthalten nur Informationen über die Amplitude (um Parameter zu reduzieren und mit Spektrogrammen zu arbeiten). Wenn wir also die inverse Fourier-Transformation durchführen, erhalten wir einen schlechten Klang.
Um dieses Problem zu lösen, erfanden sie einen schnellen Griffin-Lim-Algorithmus. Er macht die inverse Fourier-Transformation des Spektrogramms und erhält einen "schlechten" Klang. Dann wandelt er diesen Ton direkt um und empfängt ein Spektrum, das bereits einige Informationen über die Phase enthält, und die Amplitude ändert sich dabei nicht. Als nächstes wird die inverse Transformation erneut durchgeführt und ein saubererer Klang erhalten. Leider lässt die durch einen solchen Algorithmus erzeugte Sprachqualität zu wünschen übrig.
Es wurde durch neuronale Vocoder wie WaveNet , WaveRNN , WaveGlow und andere ersetzt. CorentinJ verwendete das WaveRNN-Modell von fatchord

Für die Datenvorverarbeitung werden zwei Ansätze verwendet. Erhalten Sie entweder Spektrogramme aus Ton (mithilfe der Fourier-Transformation) oder aus Text (mithilfe des Synthesemodells). Google empfiehlt einen zweiten Ansatz.
Schulung
- Führen Sie
python vocoder_preprocess.py <datasets_root> , um Spektrogramme zu synthetisieren - Führen Sie
python vocoder_train.py <datasets_root> für python vocoder_train.py <datasets_root> aus
Insgesamt
Wir haben ein Modell der mehrsprachigen Sprachsynthese, mit dem eine Stimme geklont werden kann.
Führen Sie die Toolbox aus: python demo_toolbox.py -d <datasets_root>
Beispiele sind hier zu hören
Tipps und Schlussfolgerungen
- Benötigen Sie viele Daten (> 1000 Stimmen,> 1000 Stunden)
- Die Betriebsgeschwindigkeit ist nur bei der Synthese von mindestens 4 Sätzen mit Echtzeit vergleichbar
- Verwenden Sie für den Encoder das vorgefertigte Modell für die englische Sprache, und trainieren Sie es leicht um. Ihr geht es gut
- Ein Synthesizer, der auf "saubere" Daten trainiert ist, funktioniert besser, klont jedoch schlechter als einer, der auf einem größeren Volumen trainiert hat, aber schmutzige Daten
- Das Modell funktioniert nur mit den Daten, an denen ich studiert habe
Sie können Ihre Stimme online mit colab synthetisieren oder meine Implementierung auf github sehen und meine Gewichte herunterladen.