Hallo allerseits, einige Informationen "unter der Haube" sind das Datum der technischen Werkstatt von Alfastrakhovaniya - was unsere technischen Köpfe begeistert.

Apache Spark ist ein wunderbares Tool, mit dem Sie große Datenmengen schnell und einfach auf relativ bescheidenen Computerressourcen verarbeiten können (ich meine Cluster-Verarbeitung).
Traditionell wird das Jupyter-Notebook in der Ad-hoc-Datenverarbeitung verwendet. In Kombination mit Spark können wir so langlebige Datenrahmen manipulieren (Spark befasst sich mit der Zuweisung von Ressourcen, die Datenrahmen befinden sich irgendwo im Cluster, ihre Lebensdauer ist durch die Lebensdauer des Spark-Kontexts begrenzt).
Nach der Übertragung der Datenverarbeitung an Apache Airflow wird die Lebensdauer der Frames erheblich verkürzt - der Spark-Kontext "lebt" innerhalb derselben Airflow-Anweisung. Wie man das umgeht, warum man herumkommt und was Livy damit zu tun hat - lesen Sie unter dem Schnitt.
Schauen wir uns ein sehr, sehr einfaches Beispiel an: Angenommen, wir müssen Daten in einer großen Tabelle denormalisieren und das Ergebnis zur weiteren Verarbeitung in einer anderen Tabelle speichern (ein typisches Element der Datenverarbeitungspipeline).
Wie würden wir das machen:
- geladene Daten in Datenrahmen (Auswahl aus einer großen Tabelle und Verzeichnissen)
- schaute mit "Augen" auf das Ergebnis (hat es richtig geklappt)
- gespeicherter Datenrahmen in der Hive-Tabelle (zum Beispiel)
Basierend auf den Ergebnissen der Analyse müssen wir möglicherweise im zweiten Schritt eine bestimmte Verarbeitung einfügen (Wörterbuchersatz oder etwas anderes). In Bezug auf die Logik haben wir drei Schritte
- Schritt 1: herunterladen
- Schritt 2: Verarbeitung
- Schritt 3: Speichern
In jupyter notebook machen wir das so - wir können die heruntergeladenen Daten für eine beliebig lange Zeit verarbeiten und so die Spark-Ressourcen kontrollieren.
Es ist logisch zu erwarten, dass eine solche Partition an Airflow übertragen werden kann. Das heißt, ein Diagramm dieser Art zu haben

Leider ist dies bei Verwendung der Airflow + Spark-Kombination nicht möglich: Jede Airflow-Anweisung wird in einem eigenen Python-Interpreter ausgeführt. Daher muss jede Anweisung unter anderem die Ergebnisse ihrer Aktivitäten irgendwie "beibehalten". Somit wird unsere Verarbeitung in einem Schritt "komprimiert" - "Daten denormalisieren".
Wie kann die Flexibilität des Jupyter-Notebooks wieder auf Airflow übertragen werden? Es ist klar, dass das obige Beispiel „es nicht wert“ ist (vielleicht stellt sich im Gegenteil ein gut verständlicher Verarbeitungsschritt heraus). Aber dennoch - wie können Airflow-Anweisungen im selben Spark-Kontext über den gemeinsamen Datenrahmenbereich ausgeführt werden?
Willkommen Livy
Ein weiteres Hadoop-Ökosystemprodukt kommt zur Rettung - Apache Livy.
Ich werde hier nicht versuchen zu beschreiben, was für ein "Biest" es ist. Wenn es sehr kurz und schwarzweiß ist - Mit Livy können Sie Python-Code in ein Programm "einfügen", das der Treiber ausführt:
- Zuerst erstellen wir eine Livy-Sitzung
- Danach haben wir die Möglichkeit, in dieser Sitzung beliebigen Python-Code auszuführen (sehr ähnlich der Jupyter / Ipython-Ideologie).
Und zu all dem gibt es eine REST-API.
Zurück zu unserer einfachen Aufgabe: Mit Livy können wir die ursprüngliche Logik unserer Denormalisierung speichern
- Im ersten Schritt (der ersten Anweisung unseres Diagramms) werden wir den Datenladecode in den Datenrahmen laden und ausführen
- im zweiten Schritt (zweite Anweisung) - führen Sie den Code für die notwendige zusätzliche Verarbeitung dieses Datenrahmens aus
- im dritten Schritt - der Code zum Speichern des Datenrahmens in der Tabelle
Was in Bezug auf den Luftstrom so aussehen könnte:
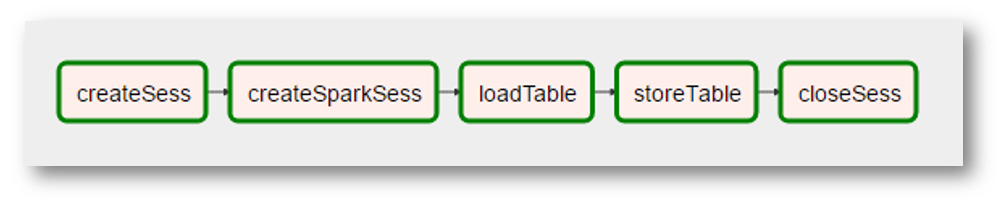
(Da es sich bei dem Bild um einen sehr realen Screenshot handelt, wurden zusätzliche „Realitäten“ hinzugefügt. Das Erstellen des Spark-Kontexts wurde zu einem separaten Vorgang mit einem seltsamen Namen. Die „Verarbeitung“ der Daten verschwand, weil sie nicht benötigt wurden usw.)
Zusammenfassend erhalten wir
- Universelle Luftstromanweisung, die Python-Code in einer Livy-Sitzung ausführt
- die Fähigkeit, Python-Code in ziemlich komplexen Graphen zu "organisieren" (Airflow dafür)
- Die Fähigkeit, Optimierungen auf höherer Ebene in Angriff zu nehmen, z. B. in welcher Reihenfolge wir unsere Transformationen durchführen müssen, damit Spark die allgemeinen Daten so lange wie möglich im Cluster-Speicher behalten kann
Eine typische Pipeline zum Vorbereiten von Daten für die Modellierung enthält ungefähr 25 Abfragen über 10 Tabellen. Es ist offensichtlich, dass einige Tabellen häufiger verwendet werden als andere (dieselben "allgemeinen Daten"), und es gibt etwas zu optimieren.
Was weiter
Die technischen Fähigkeiten wurden getestet, wir überlegen weiter - wie wir unsere Transformationen technologischer in dieses Paradigma umsetzen können. Und wie man sich der oben erwähnten Optimierung nähert. Wir stehen noch am Anfang dieses Teils unserer Reise - wenn es etwas Interessantes gibt, werden wir es definitiv teilen.