Vergleich verschiedener Tools (RabbitMQ, Crossbar.io, Nats.io, Nginx usw.) zur Organisation von RPC zwischen Microservices.
Artikel aktualisiert 2019-12-15Zusammenfassung . Die Implementierung synchroner RPC-Aufrufe über das klassische MQ-System ist nicht effektiv - sie führt zu einer verringerten Leistung und zu Nebenwirkungen, die manuell (oder mit zusätzlichen Tools) behoben werden müssen.
Inverted Json ist ein leichtgewichtiger Task-Server, mit dem Sie „ehrliche“ synchrone RPC-Aufrufe tätigen können (Client und Server stellen über Inverted Json eine Verbindung her, um Informationen zu senden). Dies gewährleistet eine hohe Leistung (siebenmal schneller als RabbitMQ) und die Kommunikation erfolgt über http , mit dem Sie alle http-Tools verwenden können, auch wenn Sie sich von der Konsole aus kräuseln.
1. Tests
Alle Werkzeuge sind in 3 Gruppen unterteilt:
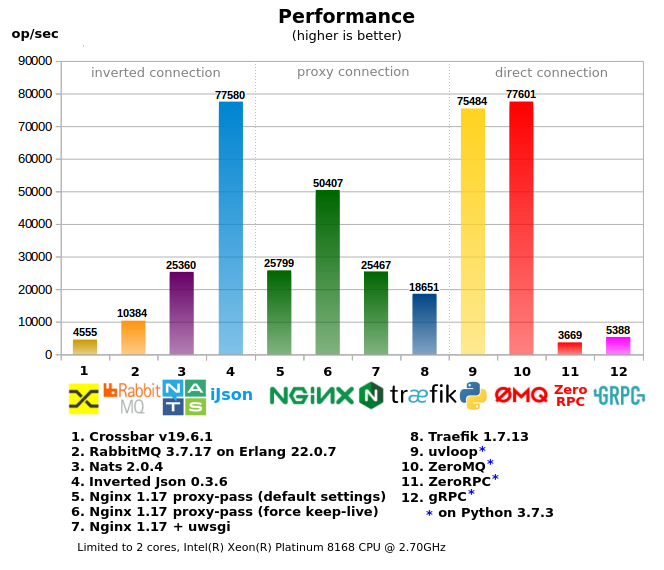
- "Direkte Verbindung" - Wenn der Client den Mitarbeiter direkt anspricht, ist die Konfiguration in Projekten mit einer großen Anzahl von Mitarbeitern / Diensten am schwierigsten. Er erfordert einen "intelligenten Client", d. H. Beim Anrufen sollte der Client Informationen darüber haben, wie und wohin die Anforderung gesendet werden soll (oder ein zusätzlicher lokaler Proxy wird benötigt). In der Regel wird das Netzwerk am wenigsten belastet.
- "Proxy-Verbindung" - eine Variante mit einem einzigen Einstiegspunkt, einem einfachen Client, aber gleichzeitig Schwierigkeiten für die Mitarbeiter / Serien - Weiterleiten und Zuweisen von Ports, Registrieren von Adressen für Proxys, kompliziertere Firewall-Einstellungen und zusätzliche Tools werden häufig zur Verwaltung dieser gesamten Farm verwendet .
- "Invertierte Verbindung" - ein einziger Einstiegspunkt für Clients und Mitarbeiter (kann als ESB betrachtet werden), die einfachste Netzwerkeinrichtung.
- Speicher- und Prozessornutzung aus "Docker-Statistiken"
- Beim „2-Core“ -Test werden Server und Clients mit Unterbrechern in verschiedene Kerne unterteilt, um den Einfluss aufeinander zu verringern. Daher ist der Server über das Task-Set auf 2 Kerne beschränkt (Multi-Core-Test ohne Einschränkungen).
Einige Gedanken zum Benchmark unten.
2. MQ oder RPC
Obwohl diese beiden Kommunikationsmethoden unterschiedlich sind, wird manchmal die erste anstelle der zweiten verwendet und umgekehrt.
Wenn Sie versuchen, die Grenzen zu skizzieren, wann Sie was verwenden sollen, können Sie Folgendes erhalten:
- RPC (Synchronous Procedure Call) - Wenn der Client sofort (in kurzer Zeit) eine Antwort benötigt, wenn der Mitarbeiter antworten muss, während der Client auf eine Antwort wartet, und wenn der Client (nach Zeitüberschreitung) gegangen ist, wird diese Antwort nicht mehr benötigt (aus diesem Grund müssen Sie nicht speichern). Anfrage “, wie dies häufig in MQ-Systemen der Fall ist.
Wenn Sie beispielsweise eine Abfrage in der Datenbank durchführen - Sie führen RPC aus, möchten Sie MQ dafür nicht verwenden. - MQ (asynchroner Prozeduraufruf) - wenn die Antwort (sofort) nicht benötigt wird, wenn Sie am Ende nur eine Aufgabe erledigen oder nur Daten übertragen müssen.
Um beispielsweise Briefe zu senden, können Sie eine Aufgabe über MQ senden
3. RPC über RabbitMQ
RabbitMQ wird häufig zum Organisieren von RPCs verwendet, verursacht jedoch wie ähnliche MQ-Systeme einen zusätzlichen Overhead, weshalb seine Verwendung nicht sehr produktiv ist.
Wenn Sie die "Warteschlange" für RPC verwenden, müssen Sie die Kanäle bereinigen, weil Wenn der Mitarbeiter für eine Weile gestürzt ist, kann er nach dem Neustart eine Reihe irrelevanter Aufgaben erhalten, da die Kunden die ganze Zeit über Anfragen gesendet und darüber hinaus vergeblich auf eine Antwort gewartet haben. Der Arbeiter war nicht aktiv. Insgesamt erhält der Mitarbeiter die Aufgabe auch dann, wenn der Client zuvor abgereist ist, ebenso wie der Client. Wenn der Kanal des Clients nicht gezählt wird, kann er mit nicht empfangenen Antworten des Workers verstopft sein, obwohl es in RabbitMQ möglich ist, den Client-Kanal zu schließen, aber gleichzeitig wird die Leistung drastisch reduziert.
Sie müssen auch einen Schweinefleischarbeiter machen, um zu wissen, ob er lebt.
Darüber hinaus werden Ressourcen für die Arbeit mit Kanälen aufgewendet, wenn in RPC-Systemen Daten einfach an den Mitarbeiter gesendet werden und umgekehrt.
4. Invertierter Json
Es gibt viele verschiedene MQ-Systeme, aber nicht viele Job-Server (RPCs) wie Gearman / Crossbar.io sind sehr kleine Auswahlmöglichkeiten, sodass Entwickler häufig MQ-Systeme für RPCs verwenden.
Daher wurde
Inverted JSON (iJson) erstellt - ein Proxyserver mit einer http-Schnittstelle, über die Clients und Worker eine Verbindung als Netzwerkclient herstellen: [Client] -> [Inverted Json] <- [Worker], geschrieben in C / C ++, verwendet epoll-Zustandsautomaten Für Routing, JSON-Streaming-Parser, Slices anstelle von Strings * usw. Möglichkeiten für eine bessere Leistung.
Vorteile von Inverted JSON gegenüber RabbitMQ:- Es ist nicht erforderlich, Client- und Worker-Kanäle von nicht empfangenen Nachrichten zu bereinigen
- Es ist nicht erforderlich, den Worker anzupingen. Der Client erhält sofort eine Fehlermeldung, wenn der Worker die Verbindung trennt (mit einer Keepalive-Verbindung).
- Einfachere API - nur eine http-Anfrage (in der Regel wird sie bereits von allen Sprachen und Frameworks unterstützt)
- Arbeitet schneller und verbraucht weniger Speicher
- Eine einfachere Möglichkeit, Befehle an einen bestimmten Mitarbeiter zu senden (z. B. wenn sich mehrere Mitarbeiter in der Warteschlange befinden, Sie jedoch mit einem bestimmten Mitarbeiter arbeiten müssen).
Andere invertierte Json-Informationen- Die Fähigkeit, Binärdaten zu übertragen (nicht nur json, wie der Name vermuten lässt)
- Es ist nicht erforderlich, eine ID anzugeben, wenn der Worker als Keep-Alive verbunden ist. Inverted Json verbindet den Client und den Worker einfach direkt.
- Die Möglichkeit, mehrere Befehle (Kanäle) zu "abonnieren" und ein Muster (z. B. Befehl / *) zu abonnieren, ohne an Leistung zu verlieren.
- Docker-Image ist nur 2,6 MB (schlanke Version)
- Kernel Inverted Json nur ~ 1400 Codezeilen (v0.3), weniger Code - weniger Fehler;)
- Invertiertes JSON ändert den Anforderungshauptteil (body) nicht, sondern sendet ihn unverändert.
5. Versuchen Sie Inverted Json in 3 Minuten
Sie können Inverted Json jetzt ausprobieren, wenn Sie
Docker und
Curl haben :

Beschreibung vom Bild:
1) Beim Starten des Docker-Images von
Inverted Json auf Port 8001 protokolliert --log 47 eingehende Anforderungen usw.:
$ docker run -it -p 8001:8001 lega911/ijson --log 47
2) Registrieren Sie den Worker für die Aufgabe "calc / sum" und warten Sie auf die Aufgabe. Fordern Sie den Typ "get" an, d. H. - Holen Sie sich die Aufgabe:
$ curl localhost/calc/sum -H 'type: get'
3) Der Kunde stellt eine RPC-Berechnungs- / Summenanforderung:
$ curl localhost/calc/sum -d '{"id": 15, "data": "2+3"}'
4) Der Worker erhält die Aufgabe "{" id ": 15," data ":" 2 + 3 "}" - die Daten bleiben unverändert. Jetzt müssen Sie das Ergebnis an dieselbe ID senden. Der Anforderungstyp lautet "result":
$ curl localhost -H 'type: result' -d '{"id": 15, "result": 5}'
... und der Client erhält das Ergebnis wie folgt:
`{"id": 15, "result": 5}`5.1. Jsonrpc
JsonRPC 2 wird nicht unterstützt, aber es gibt einige Grundlagen, zum Beispiel kann der Client Anforderungen senden wie (url / rpc / call):
{"jsonrpc": "2.0", "method": "calc/sum", "params": [42, 23], "id": 1}
Akzeptiere Fehler wie:
{"jsonrpc": "2.0", "error": {"code": -32601, "message": "Method not found"}, "id": null}
Bei Bedarf kann jedoch die JsonRPC-Unterstützung verbessert werden.
5.2. Python-Client und Worker-Beispiel
Und hier finden Sie ein Beispiel im "Worker-Modus", der produktiver und kompakter ist.
6. Einige Gedanken zum Benchmark-Ergebnis
- Crossbar.io : basiert auf Python, ist also nicht so schnell und kann aufgrund der GIL nicht mehrere Kerne verwenden.
- RabbitMQ : RPC über MQ, was einen zusätzlichen Overhead verursacht. Ein schneller Leistungsabfall mit zunehmender Belastung (im Test nicht berücksichtigt).
- Nats : keine schlechte, obwohl sie Inverted Json unterlegen ist RPC über MQ wird auch die gleichen Probleme haben.
- Inverted Json : Das Erreichen des Netzwerklimits (d. H. Das Starten mehrerer Kopien von Tests auf verschiedenen Kernen führt insgesamt nicht zu einem besseren Ergebnis) zeigte die im Verhältnis zur Leistung effizienteste Nutzung von Speicher und Prozessor.
- Nginx : Beim Proxy-Pass sinkt die Leistung schnell, wenn der Keep-Alive-Modus nicht aktiviert ist (standardmäßig deaktiviert), da Linux das Öffnen / Schließen vieler Sockets in kurzer Zeit nicht zulässt (dies spiegelt sich nicht im Test wider).
- Traefik : sehr unersättlich, verbraucht 600% der CPU in der Spitze, schlechter als Nginx in der Geschwindigkeit
- uvloop (unter asyncio) - gibt sehr gute leistung, weil Die meisten sind in C / C ++ geschrieben, denn RPC ist ZeroMQ vorzuziehen
- ZeroMQ - Der Worker selbst ist in Python geschrieben, daher lief er in den Kernel, obwohl der Multiprozessortest mehr als 100% CPU verbraucht. Dies liegt an der Tatsache, dass zeromq selbst in C / C ++ ohne GIL-Erfassung geschrieben ist. Es bietet eine großartige Leistung, aber wenn der Arbeiter nicht nur a + b tut, führt jede Komplikation zu einer signifikanten Reduzierung der RPC, weil wird den Kern noch früher treffen.
- ZeroRPC : Als leichter Wrapper über ZeroMQ deklariert, gehen in Wirklichkeit 95% der Leistung von ZeroMQ verloren, es scheint, dass es nicht so leicht ist.
- GRPC : Die Option für Python erzeugt viel Python-Code auf Boilerplate, d. H. Der Prozessor stellt sich als schwer heraus und ruht schnell auf der CPU. Für kompilierte Sprachen gibt es wahrscheinlich kein solches Problem.
- 2-Core- und Multi-Core-Tests, bei Multi-Core-Tests nahmen einige Indikatoren ab, da Sie mit dem Client-Testcode um CPU-Ressourcen konkurrieren müssen. Andererseits ergaben einige Tests eine hervorragende Leistung, z. B. Traefik, das 600% CPU verbrauchte
7. Fazit
Wenn Sie ein großes Unternehmen und viele Mitarbeiter haben, können Sie verschiedene komplexe Tools zum Organisieren direkter Verbindungen zwischen Microservices unterstützen, die eine effektive Kommunikation ermöglichen.
Und für kleine Unternehmen und Startups, bei denen ein kleines Team Probleme aus verschiedenen Bereichen lösen muss, kann Inverted Json Zeit und Ressourcen sparen.
Für die Entwicklung von Inverted Json ist die Unterstützung von Pubsub, Kubernetes und anderen interessanten Ideen geplant.
Wenn Sie an dem Projekt interessiert sind oder nur dem Autor helfen möchten, können Sie dem
Github-Projekt ein Sternchen
hinzufügen , danke.
PS:
- Das Erstellen dieses Artikels einschließlich Tests dauerte länger als das Erstellen von Inverted Json selbst
- Invertierte Json-Prototypen wurden auch in 1. Python + Asyncio + Uvloop, 2. in GoLang geschrieben
- Die Tests wurden von verschiedenen Experten überprüft.
- "Slices statt Strings" - In den meisten Fällen werden beim Parsen von http / json die Daten nicht in Strings kopiert, sondern die Verknüpfung zu den Quelldaten wird verwendet, sodass keine unnötige Zuordnung und kein Kopieren des Speichers erfolgt.
- Wenn Sie testen - verwenden Sie keine Anforderungen in Python, es ist sehr langsam, besser als Pycurl, dieser Wrapper wird in Tests verwendet.
- Der Benchmark ist hier
- Quellen hier