In großen oder Microservice-Architekturen ist der wichtigste Service nicht immer der produktivste und manchmal nicht für Hochlast vorgesehen. Wir sprechen über das Backend. Es arbeitet langsam - es verliert Zeit bei der Datenverarbeitung und wartet auf eine Antwort zwischen ihm und dem DBMS und skaliert nicht. Selbst wenn sich die Anwendung selbst leicht skalieren lässt, lässt sich dieser Engpass überhaupt nicht skalieren. Wie kann dieses Problem gelöst und eine hohe Leistung sichergestellt werden? Wie kann eine Systemantwort bereitgestellt werden, wenn wichtige Informationsquellen stumm sind?

Wenn Ihre Architektur vollständig mit dem Reactive-Manifest übereinstimmt, skalieren die Komponenten der Anwendung unbegrenzt mit zunehmender Last unabhängig voneinander und halten dem Fall eines Knotens stand - Sie kennen die Antwort. Wenn nicht, wird
Oleg Nizhnikov (
Odomontois )
erklären , wie das Skalierbarkeitsproblem bei Tinkoff gelöst wurde, indem er seinen schmerzlosen Fallback-Cache auf Scala erstellt, ohne die Anwendung neu zu schreiben.
Hinweis Der Artikel enthält ein Minimum an Scala-Code und ein Maximum an allgemeinen Prinzipien und Ideen.Instabiles oder langsames Backend
Bei der Interaktion mit dem Backend ist die durchschnittliche Anwendung schnell. Das Backend erledigt jedoch den Großteil der Arbeit und mahlt die meisten Daten intern - es dauert länger. Es wird zusätzliche Zeit verschwendet, auf ein Backend und eine DBMS-Antwort zu warten. Selbst wenn sich die Anwendung selbst leicht skalieren lässt, lässt sich dieser Engpass überhaupt nicht skalieren. Wie kann das Backend entlastet und das Problem gelöst werden?
Eingebetteter Cache
Die erste Idee besteht darin, Daten zum Lesen zu nehmen, Daten anzufordern und den Cache auf der Ebene jedes speicherinternen Knotens zu konfigurieren.
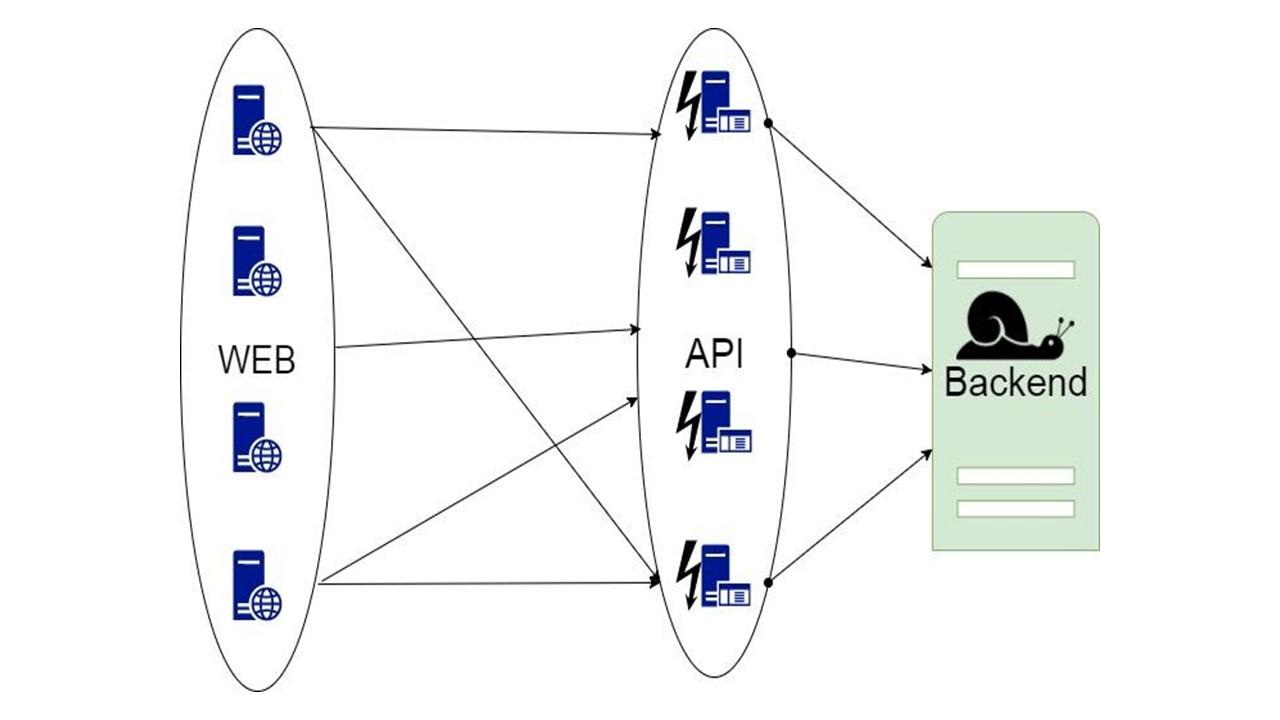
Der Cache bleibt so lange bestehen, bis der Knoten neu gestartet wird und nur die letzten Daten gespeichert werden. Wenn die Anwendung abstürzt und neue Benutzer hinzukommen, die nicht in der letzten Stunde, am letzten Tag oder in der letzten Woche waren, kann die Anwendung nichts dagegen tun.
Proxy
Die zweite Option ist ein Proxy, der einen Teil der Anforderungen übernimmt oder die Anwendung ändert.
Im Proxy können Sie jedoch nicht die gesamte Arbeit für die Anwendung selbst erledigen.
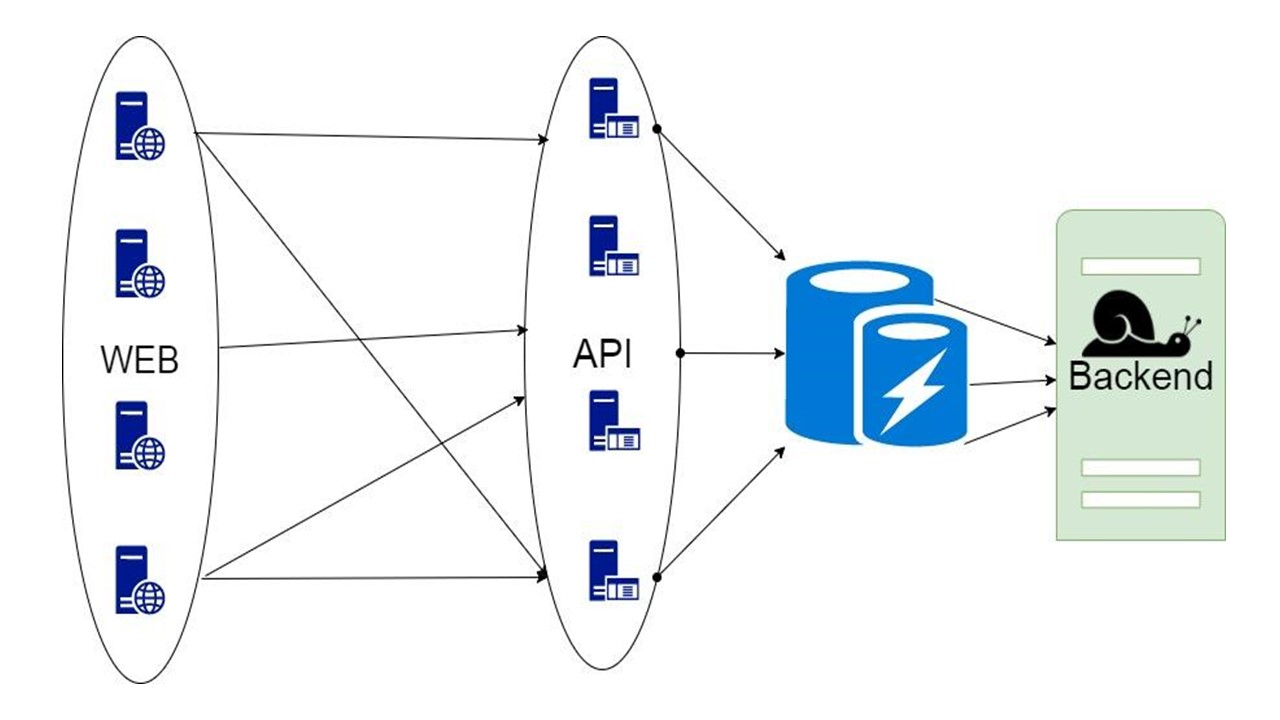
Datenbank zwischenspeichern
Die dritte Option ist schwierig, wenn der Teil der Daten, den das Backend zurückgibt, für lange Zeit gespeichert werden kann. Wenn sie gebraucht werden, zeigen wir dem Kunden, auch wenn sie nicht mehr relevant sind. Das ist besser als nichts.
Diese Entscheidung wird diskutiert.
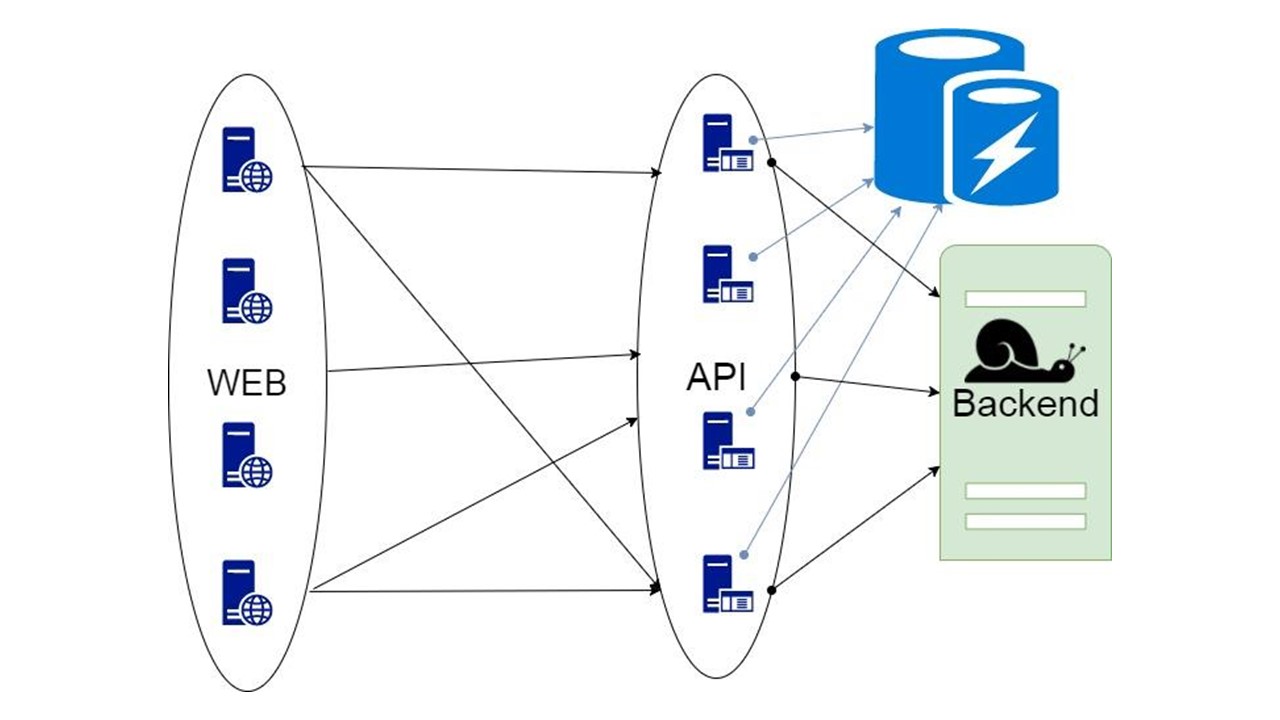
Fallback-Cache
Dies ist unsere Bibliothek. Es ist in die Anwendung eingebettet und kommuniziert mit dem Backend. Mit minimaler Verfeinerung analysiert es die Datenstruktur, generiert Serialisierungsformate und erhöht mit Hilfe des Leistungsschalteralgorithmus die Fehlertoleranz. Eine effektive Serialisierung kann in jeder Sprache implementiert werden, in der Typen im Voraus analysiert werden können, wenn sie streng genug definiert sind.
Komponenten
Unsere Bibliothek sieht ungefähr so aus.

Der linke Teil ist der Interaktion mit diesem Repository gewidmet, das zwei wichtige Komponenten enthält:
- die Komponente, die für den Initialisierungsprozess verantwortlich ist - vorbereitende Aktionen mit dem DBMS vor Verwendung des Fallback-Cache;
- Modul zur automatischen Serialisierung.
Die rechte Seite ist die allgemeine Funktionalität, die sich auf Fallback bezieht.
Wie funktioniert das alles? In der Mitte der Anwendung befinden sich Abfragen und Zwischentypen zum Speichern des Status. Dieses Formular drückt die Daten aus, die wir vom Backend für eine oder mehrere Anfragen erhalten haben. Wir senden die Parameter an unsere Methode und erhalten die Daten von dort. Diese Daten müssen irgendwie serialisiert werden, um gespeichert zu werden, also verpacken wir sie in Code. Ein separates Modul ist dafür verantwortlich. Wir haben das Leistungsschaltermuster verwendet.
Speicheranforderungen
Lange Haltbarkeit - 30-500 Tage . Einige Aktionen können lange dauern, und während dieser ganzen Zeit müssen Daten gespeichert werden. Daher möchten wir einen Speicher, in dem Daten für lange Zeit gespeichert werden können. In-Memory ist dafür nicht geeignet.
Großes Datenvolumen - 100 GB-20 TB . Wir möchten Dutzende Terabyte Daten im Cache speichern, und noch mehr aufgrund des Wachstums. All dies im Speicher zu halten ist ineffizient - die meisten Daten werden nicht ständig angefordert. Sie lügen lange und warten auf ihren Benutzer, der hereinkommt und fragt. In-Memory fällt nicht unter diese Anforderungen.
Hohe Datenverfügbarkeit . Mit dem Service kann alles passieren, aber wir möchten, dass das DBMS jederzeit verfügbar bleibt.
Niedrige Lagerkosten . Wir senden zusätzliche Daten an den Cache. Infolgedessen tritt Overhead auf. Bei der Implementierung unserer Lösung möchten wir diese minimieren.
Unterstützung für Abfragen in regelmäßigen Abständen . Unsere Datenbank sollte in der Lage sein, Daten nicht nur vollständig, sondern in Intervallen abzurufen: eine Liste von Aktionen, den Verlauf eines Benutzers für einen bestimmten Zeitraum. Daher ist ein reiner Schlüsselwert nicht geeignet.
Annahmen
Anforderungen schränken die Liste der Kandidaten ein. Wir gehen davon aus, dass wir den Rest implementiert haben, und gehen von den folgenden Annahmen aus, wobei wir wissen, warum genau wir den Fallback-Cache benötigen.
Datenintegrität zwischen zwei verschiedenen GET-Anforderungen ist nicht erforderlich . Wenn sie also zwei verschiedene Zustände aufweisen, die nicht miteinander übereinstimmen, werden wir dies ertragen.
Die Relevanz und Ungültigmachung von Daten ist nicht erforderlich . Zum Zeitpunkt der Anfrage wird davon ausgegangen, dass wir die neueste Version haben, die wir anzeigen.
Wir senden und empfangen Daten vom Backend.
Die Struktur dieser Daten ist im Voraus bekannt .
Speicherauswahl
Als Alternative haben wir drei Hauptoptionen in Betracht gezogen.
Der erste ist
Cassandra . Vorteile: hohe Verfügbarkeit, einfache Skalierbarkeit und integrierter Serialisierungsmechanismus mit der UDT-Sammlung.
UDT oder
benutzerdefinierte Typen bedeutet einen Typ. Mit ihnen können Sie strukturierte Typen effizient stapeln. Typfelder sind im Voraus bekannt. Diese Serialisierungsfelder sind wie in Protokollpuffern mit separaten Tags gekennzeichnet. Nach dem Lesen dieser Struktur ist es möglich zu verstehen, welche Felder dort auf Tags basieren. Genug Metadaten, um ihren Namen und Typ herauszufinden.
Ein weiteres Plus von Cassandra ist, dass es neben dem Partitionsschlüssel einen zusätzlichen
Clustering-Schlüssel gibt . Dies ist ein spezieller Schlüssel, aufgrund dessen die Daten auf einem Knoten sortiert werden. Auf diese Weise können Sie eine Option wie Intervallabfragen implementieren.
Cassandra gibt es schon relativ lange, es gibt
viele Überwachungslösungen dafür , und
ein Minus ist die JVM . Dies ist nicht die produktivste Option für Plattformen, auf denen Sie ein DBMS schreiben können. Die JVM hat Probleme mit der Speicherbereinigung und dem Overhead.
Die zweite Option ist
CouchBase . Vorteile: Datenzugriff, Skalierbarkeit und Schema.
Mit CouchBase müssen Sie weniger über Serialisierung nachdenken. Dies ist sowohl ein Plus als auch ein Minus - wir müssen das Datenschema nicht steuern. Es gibt globale Indizes, mit denen Sie Intervallabfragen global in einem Cluster ausführen können.
CouchBase ist ein Hybrid, bei dem
Memcache zu einem üblichen DBMS hinzugefügt wird
- schneller Cache . Sie können damit automatisch alle Daten auf dem Knoten zwischenspeichern - die heißesten mit sehr hoher Verfügbarkeit. Dank seines Caches kann CouchBase schnell sein, wenn dieselben Daten sehr oft angefordert werden.
Schemaless und
JSON können auch ein Minus sein. Daten können so lange gespeichert werden, dass die Anwendung Zeit zum Ändern hat. In diesem Fall ändert sich auch die Datenstruktur, die CouchBase speichern und lesen wird. Die vorherige Version ist möglicherweise nicht kompatibel. Dies erfahren Sie nur beim Lesen und nicht beim Entwickeln von Daten, wenn diese irgendwo in der Produktion liegen. Wir müssen über eine ordnungsgemäße Migration nachdenken, und genau das wollen wir nicht tun.
Die dritte Option ist
Tarantool . Es ist berühmt für seine super Geschwindigkeit. Es hat eine wunderbare LUA-Engine, mit der Sie eine Reihe von Logik schreiben können, die direkt auf dem Server von LuaJit ausgeführt wird.
Andererseits ist dies ein modifizierter Schlüsselwert. Daten werden in Tupeln gespeichert. Wir müssen selbst über die richtige Serialisierung nachdenken, dies ist nicht immer eine offensichtliche Aufgabe. Tarantool hat auch einen spezifischen Ansatz zur
Skalierbarkeit . Was mit ihm los ist, werden wir weiter diskutieren.
Sharding / Replikation
Möglicherweise benötigt unsere Anwendung
Sharding / Replication . Drei Repositorys implementieren sie unterschiedlich.
Cassandra schlägt eine Struktur vor, die normalerweise als "Ring" bezeichnet wird.
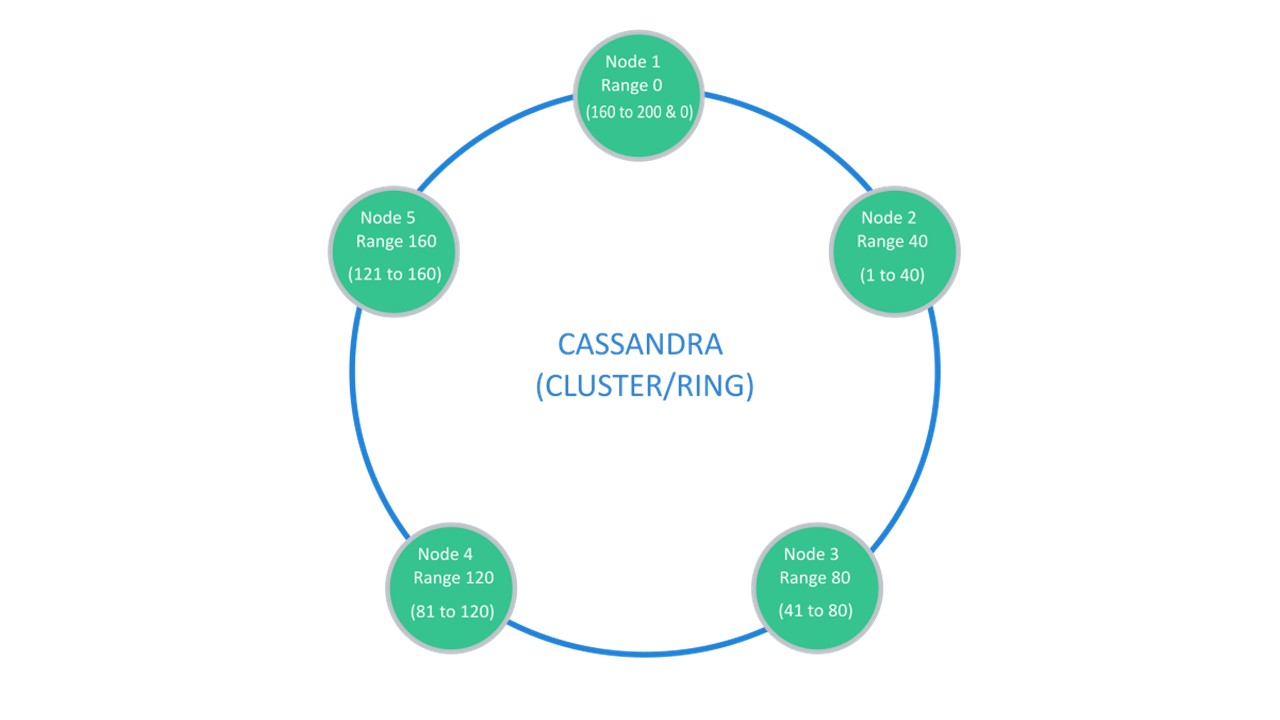
Viele Knoten sind verfügbar. Jeder von ihnen speichert seine Daten und Daten von den nächstgelegenen Knoten als Replikate. Wenn einer ausfällt, können die Knoten daneben einen Teil seiner Daten bedienen, bis der Ausfall steigt.
Sharding \ Replication ist für dieselbe Struktur verantwortlich. Zum Auspacken in 10 Teile und Replikationsfaktor 3 reichen 10 Knoten aus. Jeder der Knoten speichert 2 Replikate der benachbarten.
In CouchBase ist die Interaktionsstruktur zwischen Knoten ähnlich aufgebaut:
- Es gibt Daten, die als aktiv markiert sind und für die der Knoten selbst verantwortlich ist.
- Es gibt Replikate benachbarter Knoten, die CouchBase speichert.
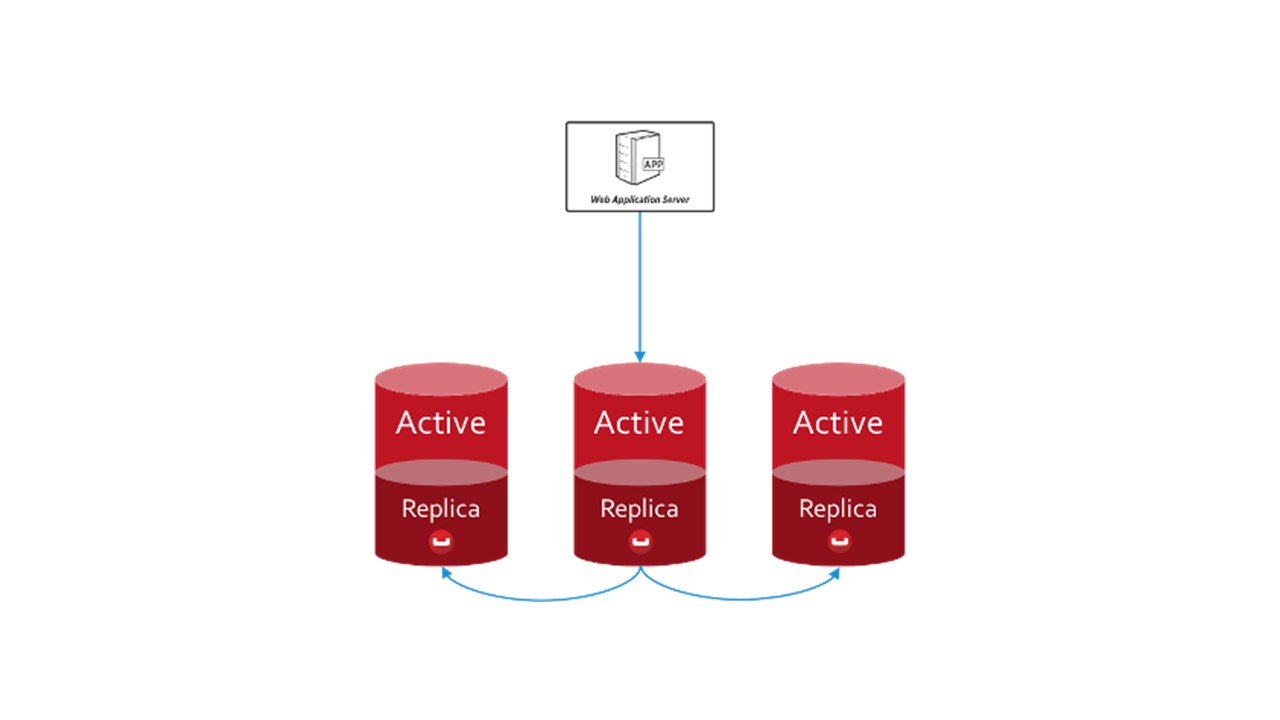
Wenn ein Knoten ausfällt, übernehmen die benachbarten, gemeinsam genutzten Knoten die Verantwortung für die Wartung dieses Teils der Schlüssel.
In Tarantool ähnelt die Architektur MongoDB. Aber mit einer Nuance: Es gibt Sharding-Gruppen, die miteinander repliziert werden.
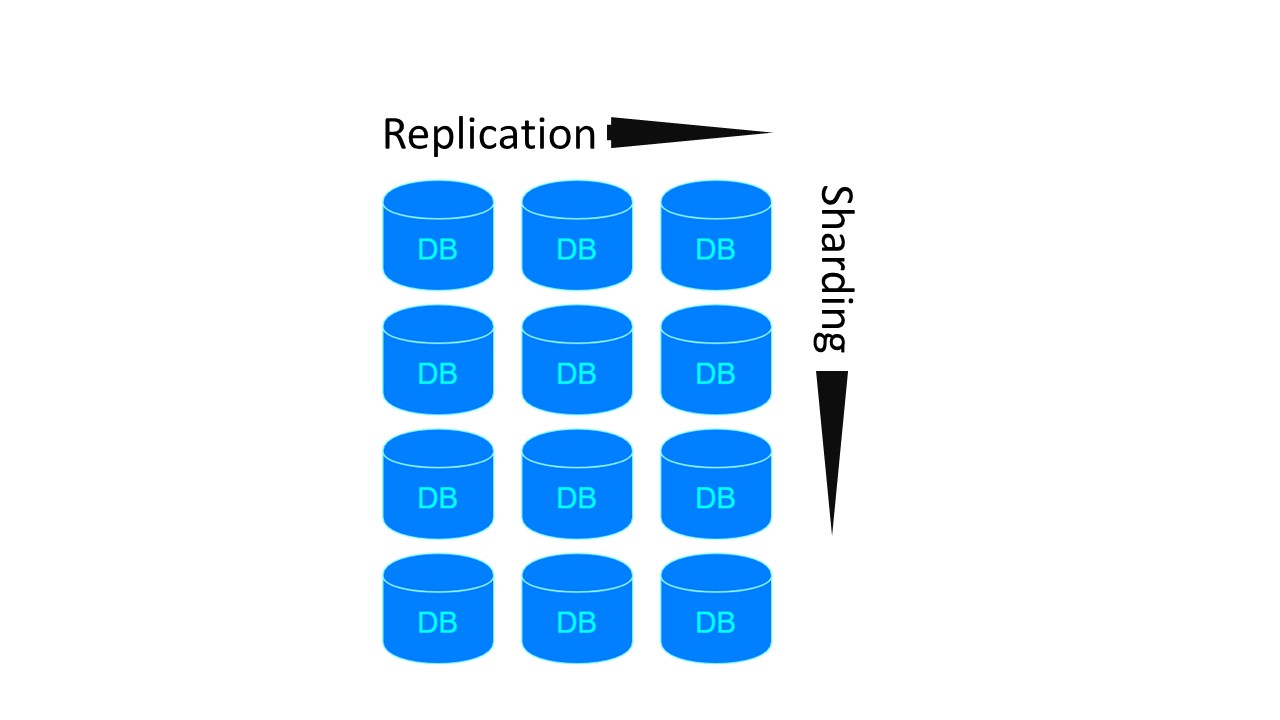
Für die beiden vorherigen Architekturen sind 4 Knoten erforderlich, wenn 4 Shards und Replikationsfaktor 3 erstellt werden sollen. Für Tarantool - 12! Der Nachteil wird jedoch durch die von Tarantool garantierte Geschwindigkeit ausgeglichen.
Cassandra
Optionale Module für das Sharding in Tarantool wurden erst kürzlich veröffentlicht. Aus diesem Grund haben wir das Cassandra DBMS als Hauptkandidaten ausgewählt. Denken Sie daran, dass wir über die spezifische Serialisierung gesprochen haben.
Automatische Serialisierung
Das SQL-Protokoll setzt voraus, dass Sie ein Datenschema ziemlich frei definieren können.
Sie können dies als Vorteil nutzen. Serialisieren Sie beispielsweise Daten so, dass die langen Feldnamen unserer Blattstrukturen nicht jedes Mal in unseren Werten gespeichert werden. In diesem Fall verfügen wir über einige Metadaten, die das Datengerät beschreiben. UDTs selbst geben auch an, welche Felder Beschriftungen und Tags entsprechen.
Daher erfolgt die automatisch generierte Serialisierung ungefähr auf die gleiche Weise. Wenn wir einen der Grundtypen haben, der dem Typ aus der Datenbank eins zu eins entsprechen kann, tun wir das. Eine Reihe von Typen Int, Long, String, Double befindet sich ebenfalls in Cassandra.
Wenn in einer Struktur ein optionales Feld auftritt, tun wir nichts extra. Wir geben ihm den Typ an, in den sich dieses Feld verwandeln soll. Die Struktur speichert null. Wenn wir in der Struktur auf der Deserialisierungsebene Null finden, nehmen wir an, dass dies das Fehlen eines Wertes ist.
Alle Sammlungstypen aus der Sammlung in Scala werden in eine Typliste konvertiert. Hierbei handelt es sich um geordnete Sammlungen mit einem Index-Matching-Element.
Ungeordnete Set-Sammlungen garantieren, dass jeder Wert genau ein Element enthält. Cassandra hat auch einen speziellen Set-Typ für sie.
Höchstwahrscheinlich werden wir viel Mapping () haben, insbesondere mit String-Schlüsseln. Cassandra hat einen speziellen Kartentyp für sie. Es ist auch typisiert und hat zwei Typparameter. Damit können wir für jeden Schlüssel einen passenden Typ erstellen
Es gibt Datentypen, die wir selbst in unserer Anwendung definieren. In vielen Sprachen werden sie als
algebraische Datentypen bezeichnet . Sie werden definiert, indem ein benanntes Produkt von Typen definiert wird, dh eine Struktur. Wir weisen diese Struktur dem benutzerdefinierten Typ zu. Jedes Feld der Struktur entspricht einem Feld in der UDT.
Der zweite Typ ist die
algebraische Summe der Typen . In diesem Fall entspricht der Typ mehreren zuvor bekannten Subtypen oder Unterarten. In gewisser Weise weisen wir ihm auch eine Struktur zu.
Abstrakter Datentyp in UDT übersetzen
Wir haben eine Struktur und zeigen sie eins zu eins an - für jedes Feld definieren wir das Feld in der erstellten UDT in Cassandra:
case class Account ( id: Long, tags: List[String], user: User, finData: Option[FinData] ) create type account ( id bigint, tags: frozen<list<text>>, user frozen<user>, fin_data frozen<fin_data> )
Primitive Typen werden zu primitiven Typen. Ein Link zu einem vordefinierten Typ, bevor dieser eingefroren wird. Dies ist ein spezieller Wrapper in Cassandra, was bedeutet, dass Sie nicht Stück für Stück aus diesem Feld lesen können. Der Wrapper ist in diesem Zustand "eingefroren". Wir können nur den Benutzer oder die Liste lesen oder speichern, wie im Fall von Tags.
Wenn wir auf ein optionales Feld treffen, verwerfen wir dieses Merkmal. Wir nehmen nur den Datentyp, der dem Feldtyp entspricht, der sein wird. Wenn wir hier nicht treffen - das Fehlen eines Wertes - schreiben wir null in das entsprechende Feld. Beim Lesen nehmen wir auch Korrespondenz ungleich Null entgegen.
Wenn wir auf einen Typ treffen, der mehrere bekannte Alternativen aufweist, definieren wir in Cassandra auch einen neuen Datentyp. Für jede Alternative ein Feld in unserem Datentyp in UDT.
Infolgedessen ist in dieser Struktur zu einem bestimmten Zeitpunkt nur eines der Felder nicht null. Wenn Sie einen Benutzertyp kennengelernt haben und sich zur Laufzeit als Instanz eines Moderators herausstellte, enthält das Moderatorfeld einen Wert, der Rest ist null. Für admin - admin ist der Rest - null.
Auf diese Weise können Sie die Struktur wie folgt codieren: Wir haben 4 optionale Felder, wir garantieren, dass nur eines von ihnen geschrieben wird. Cassandra verwendet nur ein Tag, um das Vorhandensein eines bestimmten Feldes in der Struktur zu identifizieren. Dank dessen erhalten wir eine Speicherstruktur ohne Overhead.
Um den Benutzertyp zu speichern, wird als Moderator dieselbe Anzahl von Bytes benötigt, die zum Speichern des Moderators erforderlich sind. Plus ein Byte, um zu zeigen, welche bestimmte Alternative hier vorhanden ist.
Initialisierung
Die Initialisierung ist ein vorläufiges Verfahren, das abgeschlossen sein muss, bevor wir unseren Fallback verwenden können.
Wie funktioniert dieser Prozess?
- Auf jedem Knoten generieren wir Definitionen von Tabellen, Typen und Abfragetexten basierend auf den dargestellten Typen.
- Lesen Sie das aktuelle Schema aus dem DBMS. In Cassandra ist dies einfach, indem Sie einfach eine Verbindung herstellen. Wenn eine Verbindung besteht, pumpt das "Sitzungs" -Objekt in fast allen Treibern die Metadaten des Schlüsselbereichs aus, mit denen es verbunden ist. Dann können Sie sehen, was sie haben.
- Wir gehen die Metadaten durch, vergleichen und überprüfen, ob alles, was wir erstellen möchten, zulässig ist und ob eine inkrementelle Migration möglich ist.
- Wenn alles normal ist und eine Initialisierung möglich ist, führen wir die Migration durch.
- Wir bereiten Anfragen vor.
sealed trait User case class Anonymous extends User case class Registered extends User case class Moderator extends User case class Admin extends User create type user ( anonymous frozen<anonymous>, registered frozen<registered>, moderator frozen<moderator>, admin frozen<admin> )
Es passiert so. Wir haben
Typen ,
Tabellen und
Abfragen . Typen hängen von anderen Typen ab, die von anderen. Tabellen hängen von diesen Typen ab. Abfragen hängen bereits von den Tabellen ab, aus denen sie Daten lesen. Bei der Initialisierung werden alle diese Abhängigkeiten überprüft und im DBMS alles erstellt, was nach bestimmten Regeln erstellt werden kann.
Geben Sie Migration ein
Wie kann festgestellt werden, dass ein Typ schrittweise migriert werden kann?
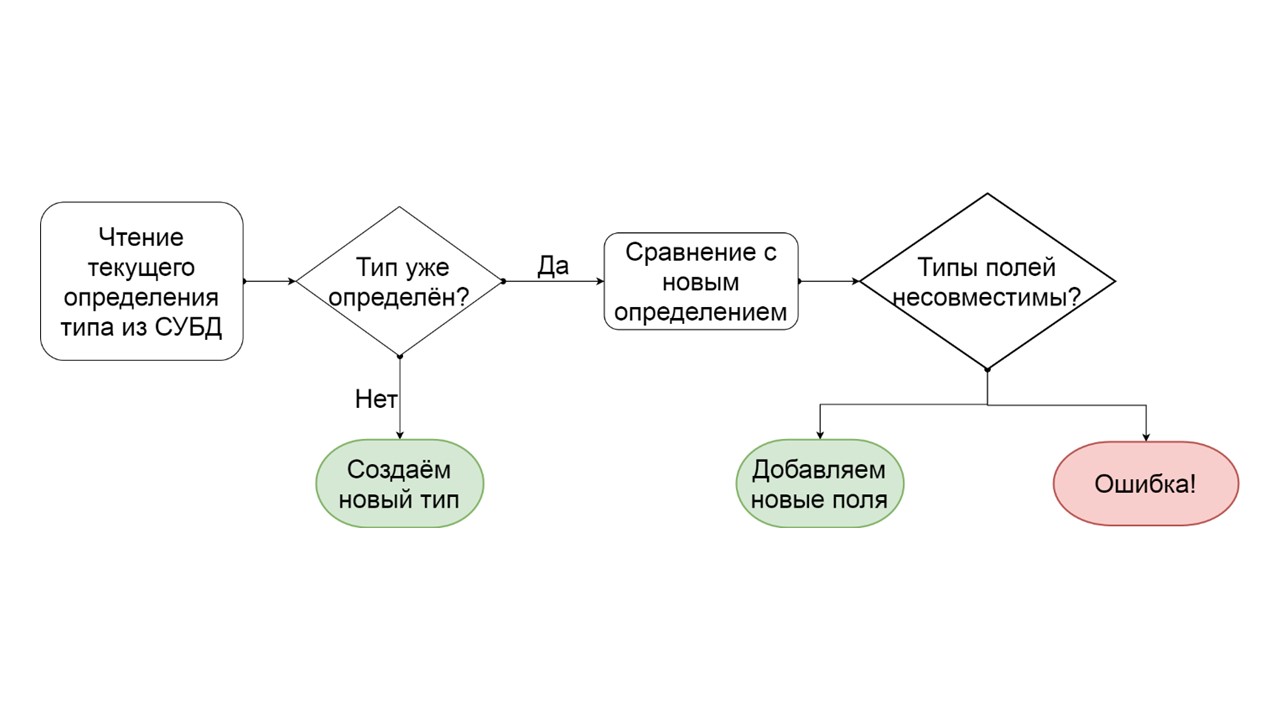
- Wir lesen, wie dieser Typ im DBMS definiert ist.
- Wenn es keinen solchen Typ gibt, haben wir uns einen neuen ausgedacht - wir erstellen ihn.
- Wenn ein solcher Typ bereits vorhanden ist, versuchen wir, die vorhandene Definition Feld für Feld mit der zu vergleichen, die wir diesem Typ geben möchten.
- Wenn sich herausstellt, dass wir nur einige Felder hinzufügen möchten, die nicht mehr existieren, tun wir dies. Erstellen Sie eine Liste mutierender ALTER TYPE-Operationen und starten Sie sie.
- Wenn sich herausstellt, dass wir ein Feld eines anderen Typs haben, generieren wir einen Fehler. Zum Beispiel gab es eine Liste - wurde zu einer Karte oder es gab einen Link zu einem benutzerdefinierten Typ, und wir versuchen, ihn anders zu machen.
Der Entwickler kann diesen Fehler sehen, noch bevor er die Funktionalität in der Produktion startet. Ich gehe davon aus, dass sich in seiner Entwicklungsumgebung genau das gleiche Datenschema befindet. Er sieht, dass er irgendwie ein nicht migrierbares Datenschema erstellt hat, und um diese Fehler zu vermeiden, kann er die automatisch generierte Serialisierung überschreiben, Optionen hinzufügen, Felder umbenennen oder alle Typen und Tabellen als Ganzes.
Initialisierung: Typen
Stellen Sie sich vor, es gibt verschiedene Arten von Definitionen:
case class Product (id: Long, name: ctring, price: BigDecimal) case class UserOffers (valiDate: LocalDate, offers: Seq[Products]) case class UserProducts (user User, products: Map[Date, Product]) case class UserInfo: UserOffers, products: UserProducts)
Fallklasse - Eine Klasse, die eine Reihe von Feldern enthält. Dies ist ein Analogon von struct in Rust.
Wir werden ungefähr solche Datendefinitionen für jeden der 4 Typen generieren - was wir schließlich ankurbeln wollen:
CREATE TYPE product (id bigint, name text, price decimal); CREATE TYPE user_offers (valid_date date, offers frozen<list<frozen<offer>>>); CREATE TYPE user_products (user frozen<user>, products frozen<map<date, frozen<product>>); CREATE TYPE user_jnfo (offers: frozen<user_offers>, products: frozen<user_products>);
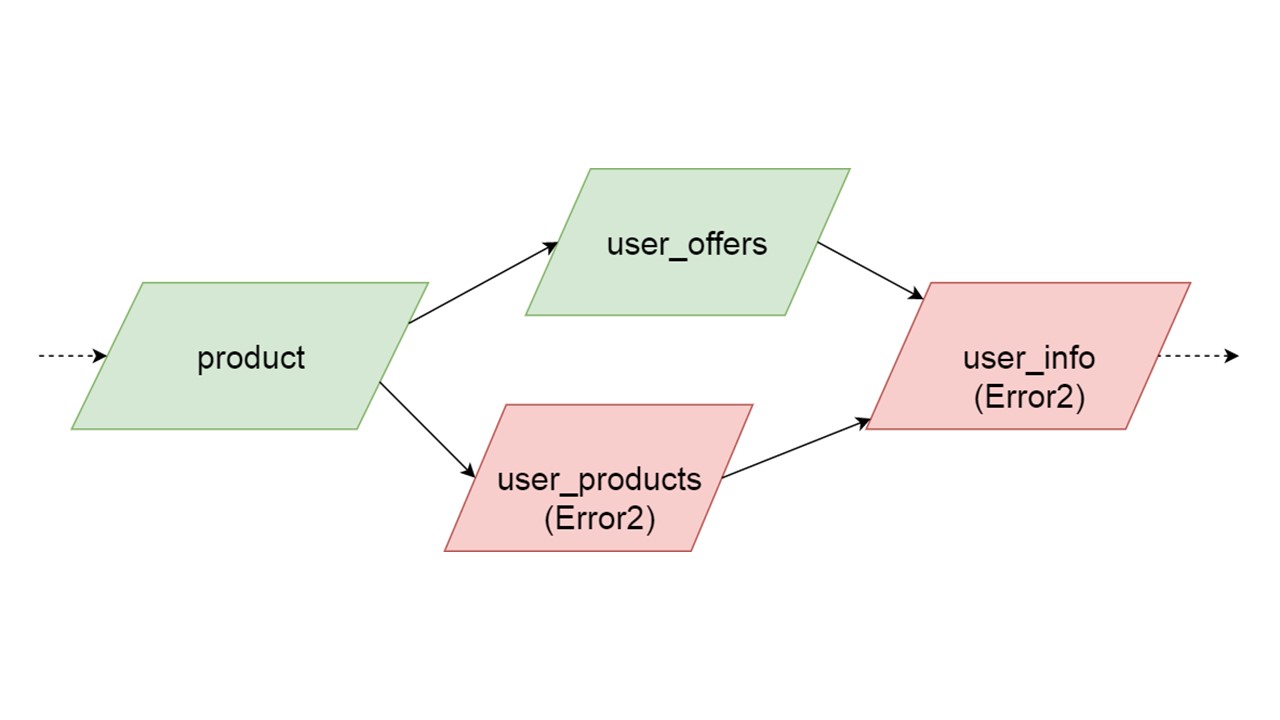
Die Art der user_offers hängt von der Art des Angebots ab, user_products hängt von der Art des Produkts ab, user_info vom zweiten und dritten Typ.

Wir haben eine solche Abhängigkeit zwischen Typen und möchten sie korrekt initialisieren. Das Diagramm zeigt, dass wir user_offers und user_products parallel initialisieren. Dies bedeutet nicht, dass wir zwei parallele Operationen starten werden. Nein, wir starten alle Anweisungen, alle Analysen nacheinander, um nicht versehentlich denselben Typ in zwei parallelen Threads zu erstellen.
Auf der Ebene der Fehlerkorrektur besteht jedoch eine gewisse Parallelität. Wenn ein Typfehler auftritt, wird bei allem, was davon abhängt, der ursprüngliche Fehler abgerufen.
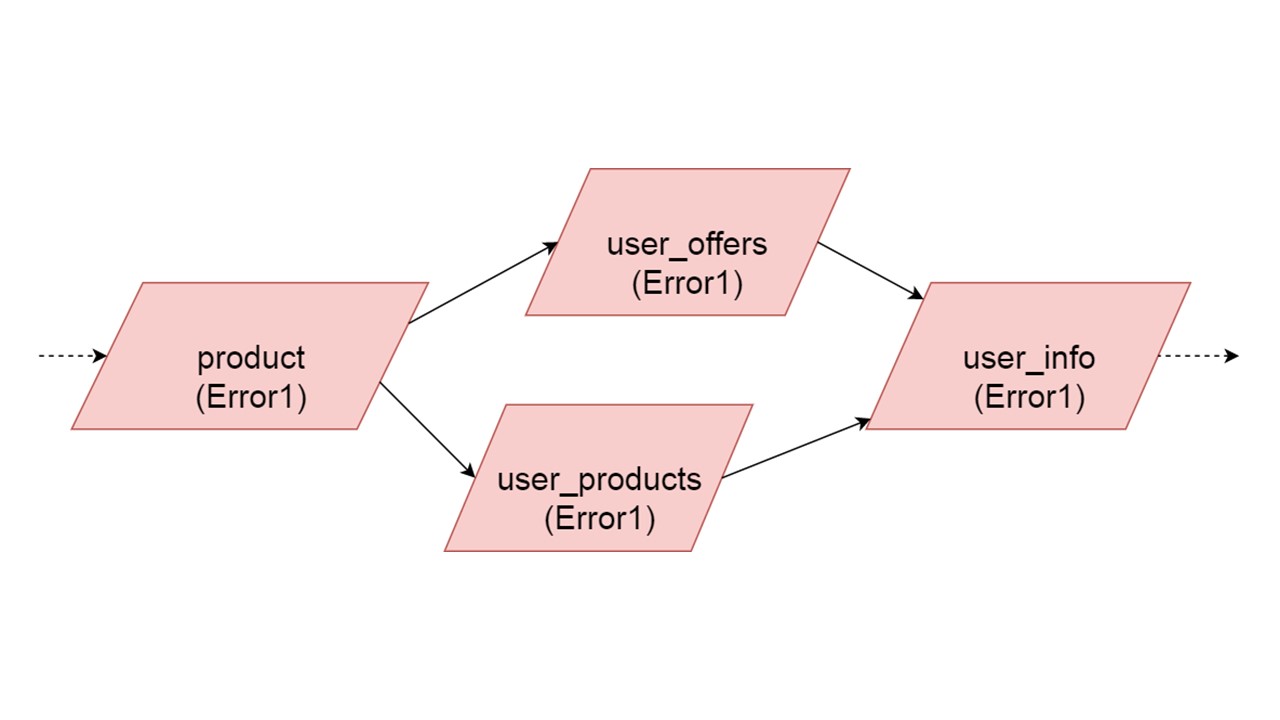
Wenn ein Fehler von einem der parallelen Zweige generiert wird, wird alles, was von normal migrierten Daten abhängt, fehlerfrei generiert. Wenn es weitere Definitionen von Tabellen und vorbereitete Anweisungen gibt, können wir diesen Teil unseres Fallback-Cache sicher initialisieren. Die Kommunikation geht nur mit einem Teil der Backends oder mit einigen Funktionen verloren. Die restlichen werden initialisiert.
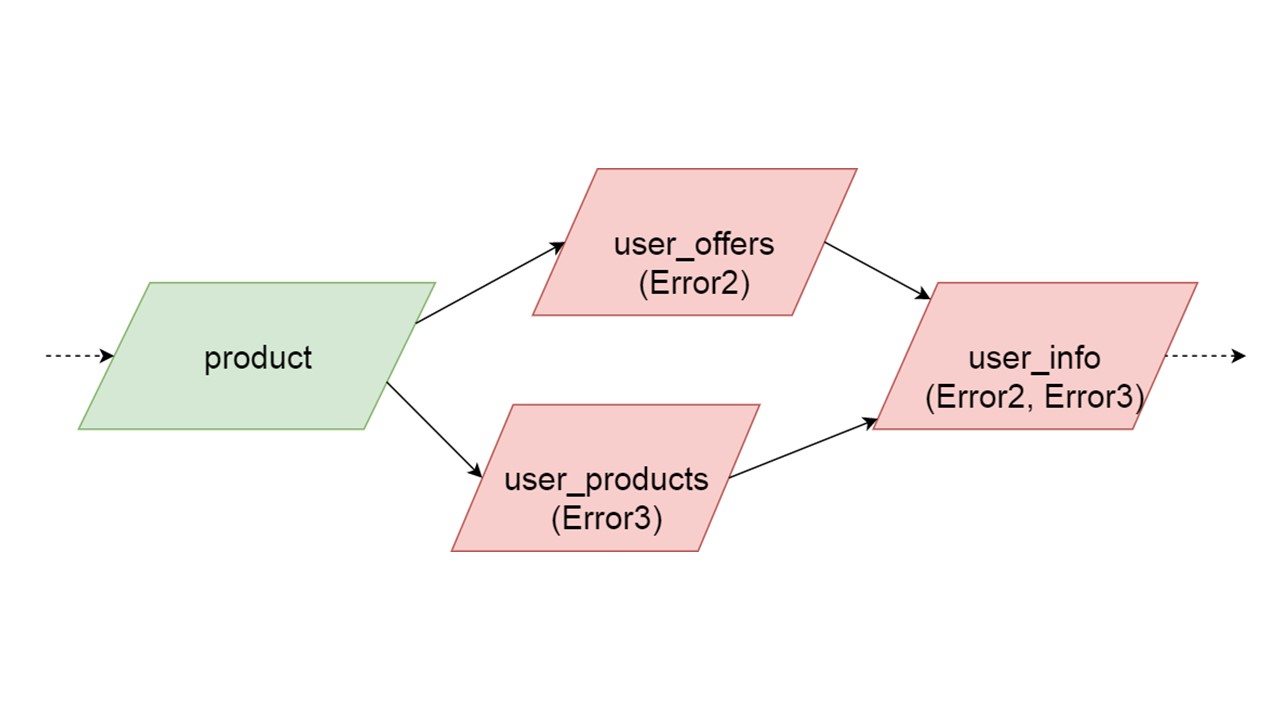
Es kann vorkommen, dass zwei gleichzeitig initialisierte Typen unterschiedliche Fehler erzeugen. In diesem Fall führt eine Funktionalität, die von beiden Typen abhängt, zu einem summierenden Fehlertyp. Der Entwickler, der seinen Fallback in der Entwicklungsumgebung initialisiert, erhält eine vollständige Liste der fehlerhaften Daten. Natürlich kann er es hier beheben und den Fehler weiter bringen. Es wird jedoch nicht so sein, dass ein völlig unabhängiger Zweig die Fehler schließt, die wir bekommen könnten, unabhängig von diesem Zweig.
Initialisierung: Tabellen
Als nächstes erstellen wir die Tabellen.
def getOffer (user: User, number: Long): Future[OfferData] create table get_offer( key frozen<tuple<frozen<user>, bigint>>PRIMARY KEY, value frozen<friend_data> )
Eine solche Anforderung kann direkt eine REST- oder SOAP-Anforderung starten, zusätzliche Vorgänge darin erstellen oder sogar mehrere Anforderungen ausführen. Es hängt alles von Ihrem Code ab - wie Sie den Code organisiert haben. Fallback analysiert nicht vollständig, was innerhalb der Methode passiert, an der Sie einen solchen Stub aufhängen.
Die Methode muss asynchron sein, da Fallback identisch ist.
In Scala ist dies mit einer besonderen Art von Zukunft gekennzeichnet. Dies bedeutet, dass das Ergebnis eines Tages zurückkehren wird. Wann genau - es ist unbekannt: vielleicht sofort oder vielleicht auch nicht.
Erstellen Sie für die Methode eine Tabelle. Der Schlüssel in der Tabelle ist ein Tupel aller Typen, die den Parametern dieser Methode entsprechen. Der Nichtschlüsselwert ist das Ergebnis, das asynchron zurückgegeben wird. Für jede solche Tabelle bereiten wir im Voraus zwei parametrische Abfragen vor: Daten einfügen und Daten lesen.
insert into get_offer(key, value) values (?key, ?value); select value from get_offer where key = ?key;
Alles ist bereit, mit dem DBMS zu interagieren. Es bleibt abzuwarten, wie wir Daten aus Fallback lesen werden.
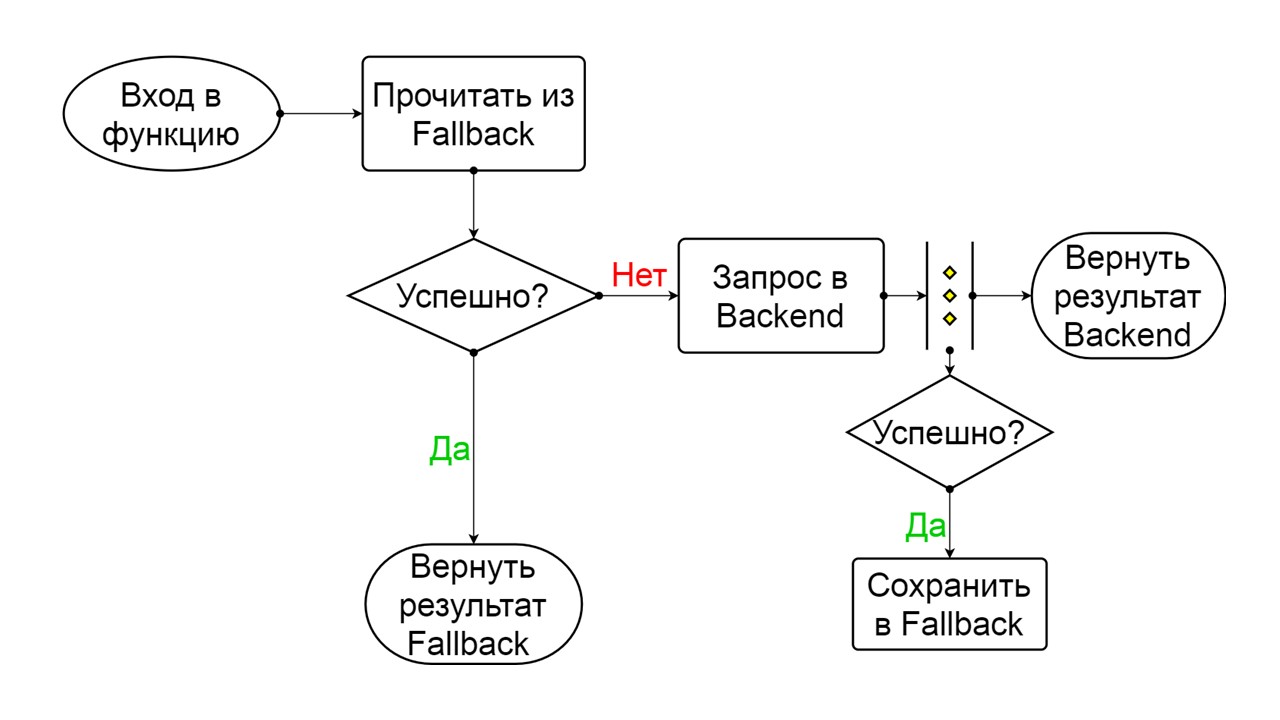
Leistungsschalter
Hier geht die Verantwortung in die Zone des berühmten Leistungsschaltermusters über.
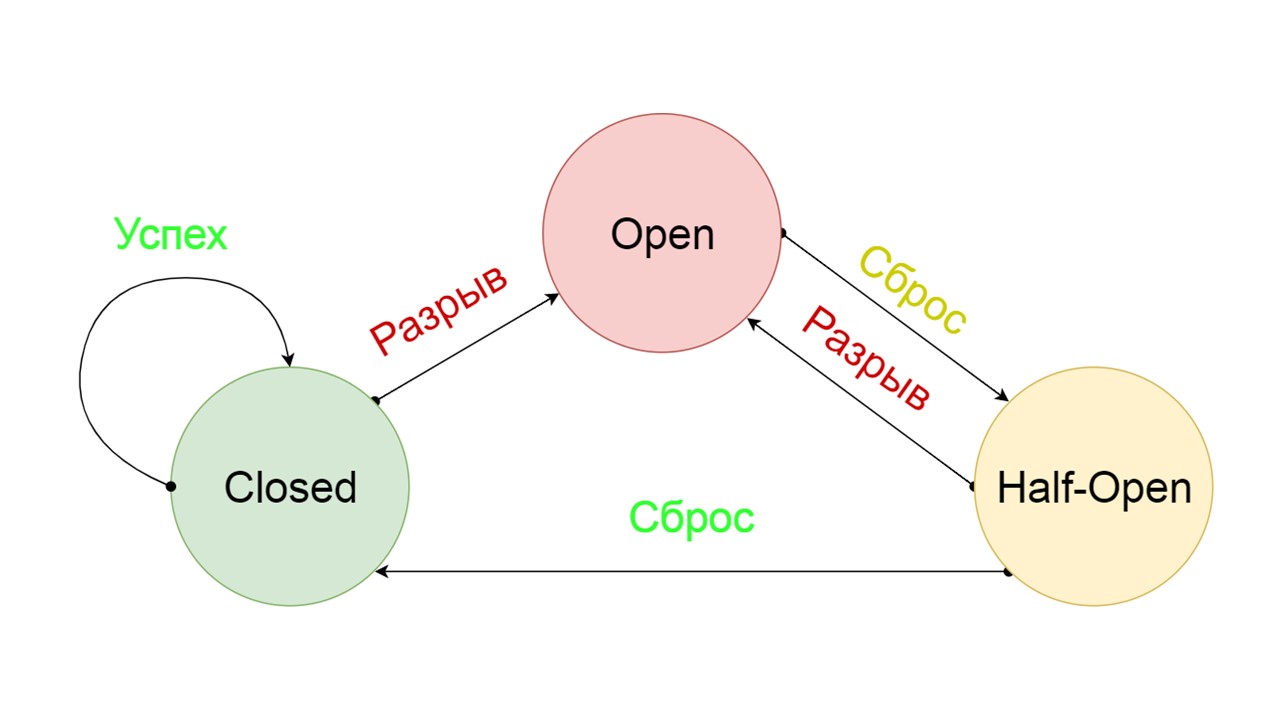
Ein typischer Leistungsschalter enthält drei Zustände.
Geschlossen - der standardmäßig geschlossene Zustand , der unser Backend schließt. Das Prinzip ist, dass wir die Daten zuerst aus dem Backend lesen und nur dann zu Fallback gehen, wenn wir sie nicht erhalten konnten. Wenn es uns gelungen ist, die Daten abzurufen, suchen wir nicht in Fallback, sondern speichern die Daten darin, und es passiert nichts.
Wenn die Probleme nacheinander auftreten, gehen wir davon aus, dass das Backend liegt. Um es nicht mit einer riesigen Menge neuer Anfragen zu spammen, wechseln wir zu
Open - in einem zerrissenen Zustand . Darin versuchen wir, Daten nur aus Fallback zu lesen. Wenn es nicht funktioniert, geben wir sofort einen Fehler zurück und berühren nicht einmal das Haupt-Backend.
Nach einer Weile entscheiden wir uns herauszufinden, ob das Backend aufgewacht ist, und versuchen, den
halboffenen Zustand - einen kurzlebigen Zustand - zurückzusetzen . Seine Lebensspanne ist eine Bitte.
Im kurzlebigen Zustand entscheiden wir uns, wieder zu schließen oder für eine noch längere Zeit zu öffnen. Wenn wir im halboffenen Zustand erfolgreich Fallback erreichen und die nächste Anfrage erhalten, gehen wir in den geschlossenen Zustand. Wenn wir nicht durchkommen konnten, kehren wir zu Open zurück, aber für eine lange Zeit.
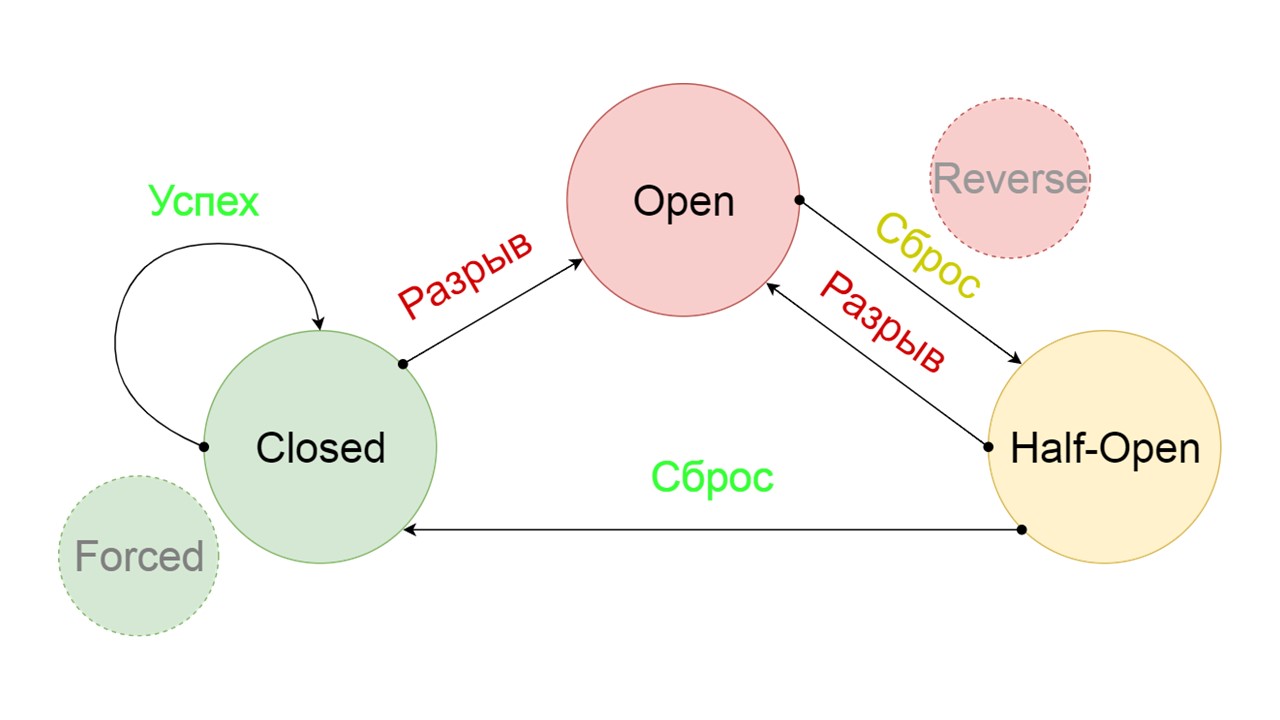
Wir haben zwei zusätzliche Zustände hinzugefügt, die eindeutig nicht mit der Leistungsschalterschaltung zusammenhängen:
- Erzwungener - gewaltsam geschlossener Zustand;
- Umgekehrt - Priorität für offenen, geschlossenen Zustand invertiert.
Mal sehen, was sie tun.
Das Funktionsprinzip von Staaten
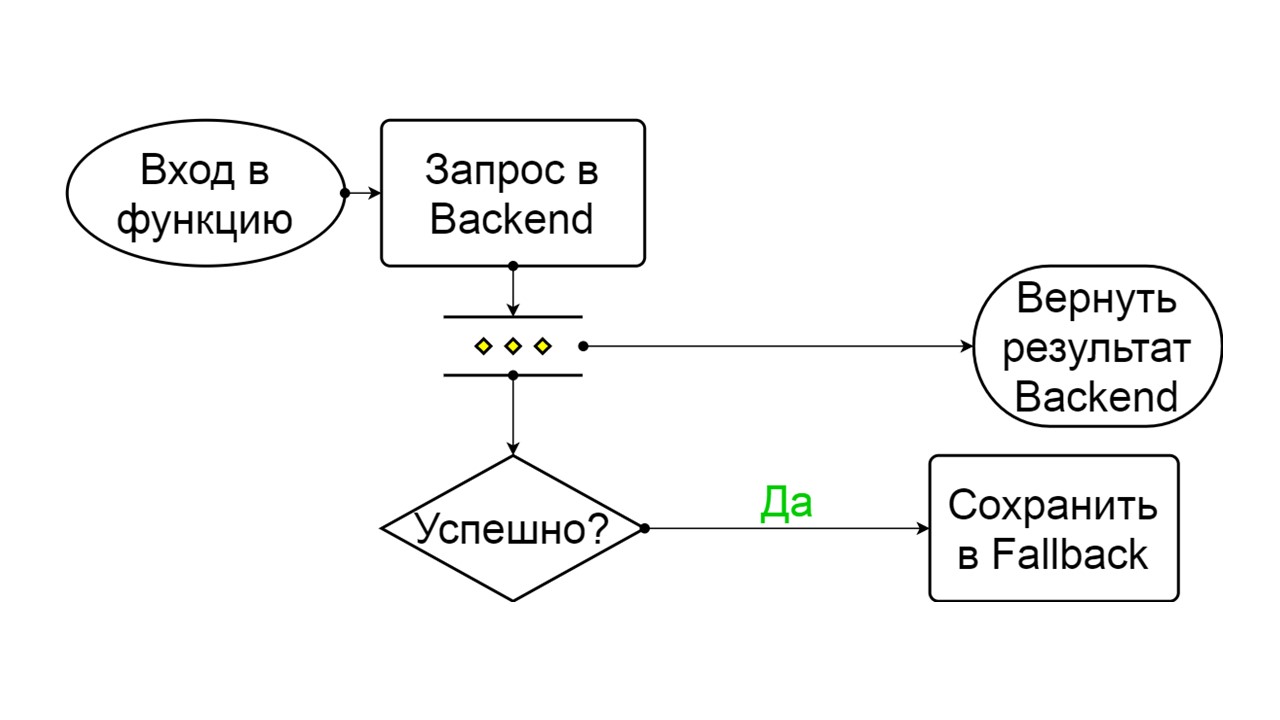
Geschlossen Das Schema ist groß, aber es reicht aus, um das allgemeine Prinzip daraus zu verstehen. Wir behalten Fallback parallel dazu bei, wie wir das Ergebnis aus dem Backend zurückgeben, wenn dort alles gut gelaufen ist und lesen aus Fallback. Wenn es überall schlecht ist, geben wir die Fehlerpriorität zurück.
Wählen Sie aus den beiden Fehlern den Backend-Fehler aus.
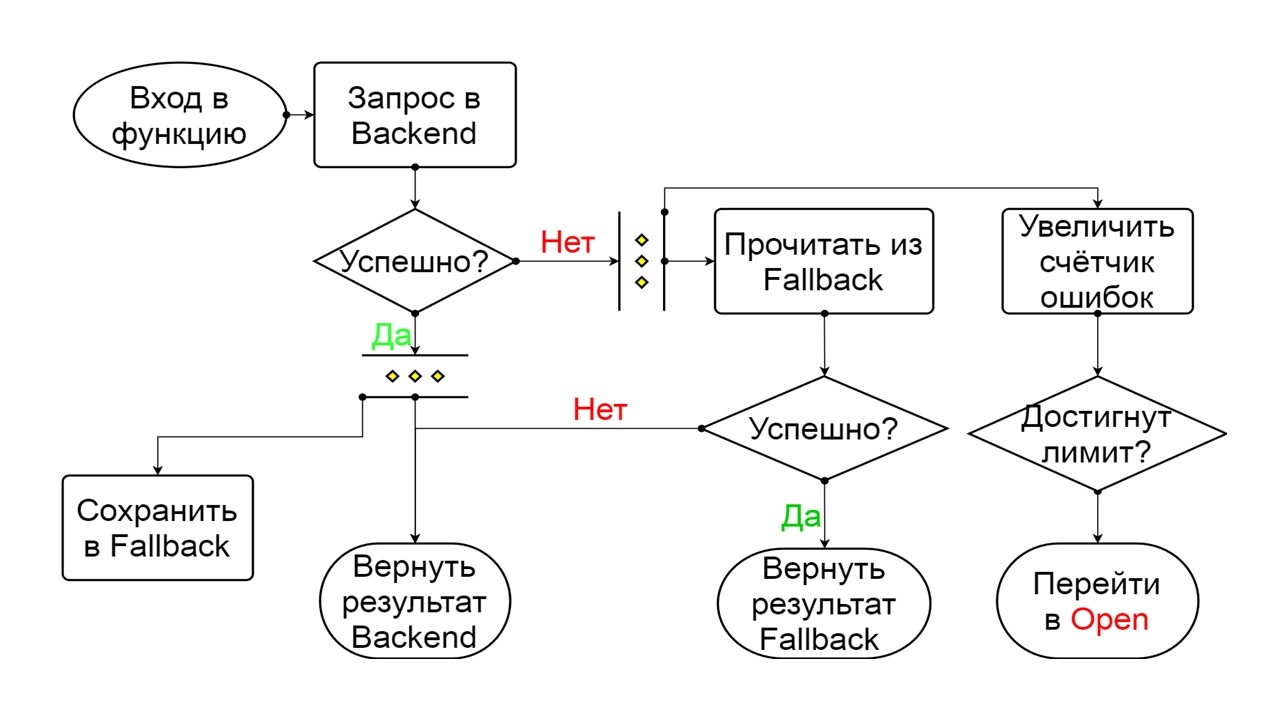
Wenn keine Fehler vorliegen, erhöhen wir parallel dazu den Zähler und gehen in den geöffneten Zustand, wenn zu viele Anforderungen vorliegen.
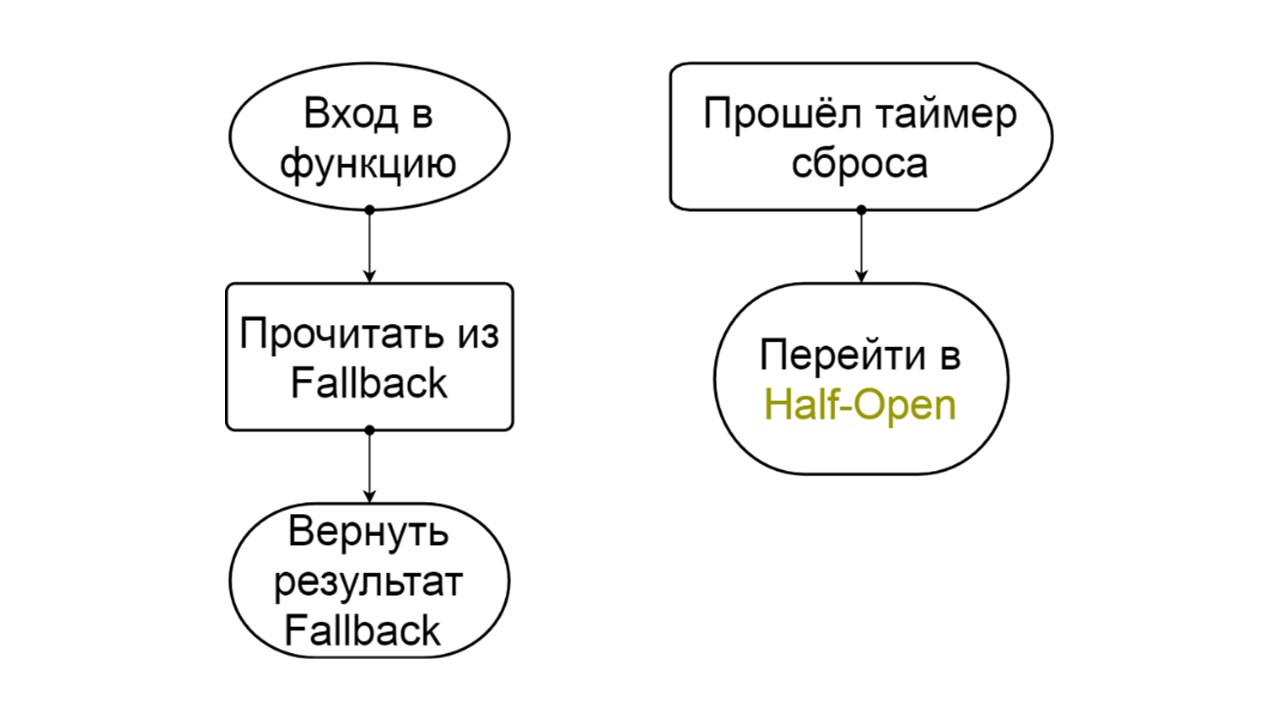 Öffnen
Öffnen Der offene Zustand von Open ist einfacher - wir lesen ständig aus Fallback, egal was passiert, und nach einer Weile versuchen wir, in den halboffenen Zustand zu wechseln.
Halb offen . Der Zustand in der Struktur ähnelt geschlossen. Der Unterschied besteht darin, dass wir im Falle einer erfolgreichen Antwort in einen geschlossenen Zustand übergehen. Im Fehlerfall kehren wir mit einem längeren Intervall zum Open zurück.
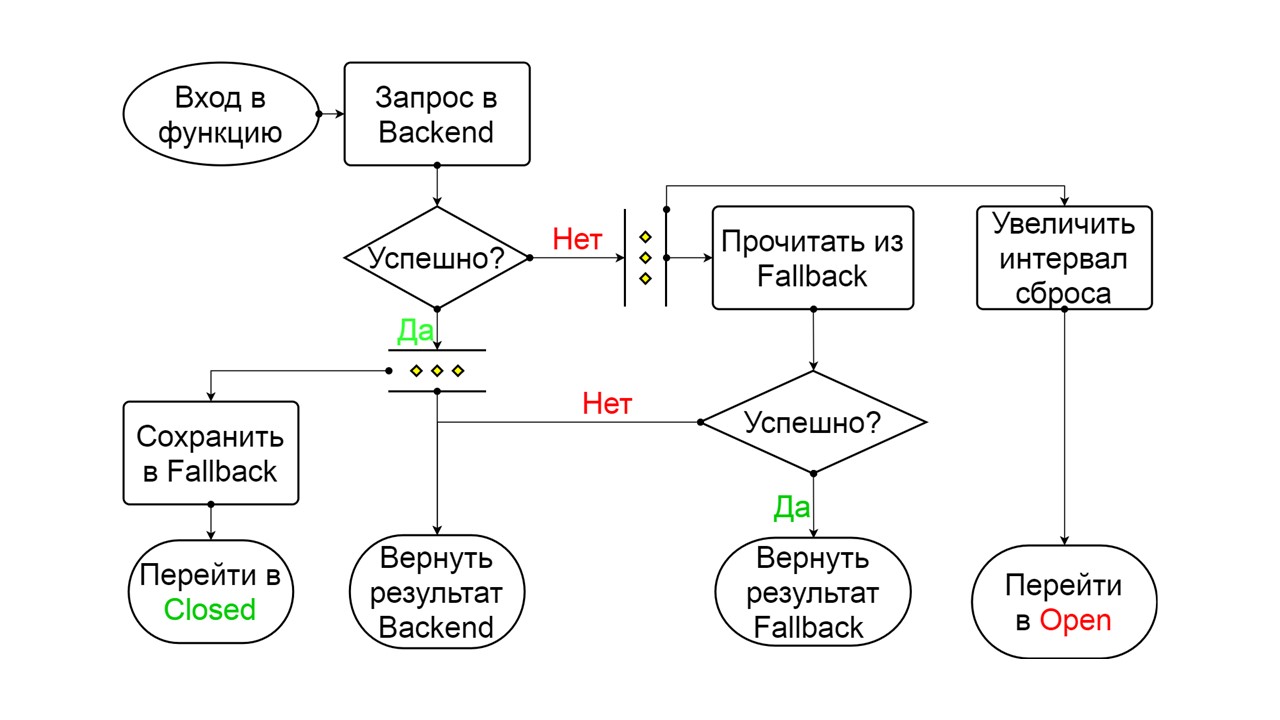 Forced ist ein zusätzlicher Status zum Aufwärmen des Caches
Forced ist ein zusätzlicher Status zum Aufwärmen des Caches . Wenn wir es mit Daten füllen, versucht es nie, aus Fallback zu lesen, sondern fügt nur Datensätze hinzu.
 Umgekehrt ist ein zweiter weit hergeholter Zustand
Umgekehrt ist ein zweiter weit hergeholter Zustand . Es funktioniert wie ein persistenter Cache. Wir aktivieren den Status, wenn wir die Last dauerhaft aus dem Backend entfernen möchten, auch wenn die Daten möglicherweise irrelevant sind. Die ersten Suchvorgänge in Fallback wurden rückgängig gemacht. Wenn die Suche fehlgeschlagen ist, wird das Backend aufgerufen und behandelt.
Die Probleme
Bei diesem ganzen Schema hatten wir mehrere Probleme. Am ernstesten ist es, zu verstehen, wie
vorbereitete Aussagen in Cassandra funktionieren. Dieses Problem wurde in Version 4.0 behoben, die noch nicht veröffentlicht wurde. Ich werde es Ihnen also sagen.
Cassandra wurde entwickelt, um Millionen von Kunden gleichzeitig damit zu verbinden, und jeder versucht, seine vorbereiteten Aussagen vorzubereiten. Natürlich bereitet Cassandra nicht jede vorbereitete Anweisung vor, da sonst der Speicherplatz knapp wird. Es berechnet den MD5-Parameter basierend auf Text, Schlüsselraum und Abfrageoptionen. Wenn sie genau dieselbe Anfrage mit genau demselben MD5 erhält, nimmt sie die bereits vorbereitete Anfrage entgegen. Es enthält bereits Informationen zu Metadaten und deren Handhabung.
Es gibt jedoch Versionsprobleme. Wir veröffentlichen eine neue Version, die erfolgreich Migrationen durchgeführt, Felder in Typen hinzugefügt und vorbereitete Anweisungen ausgeführt hat. Sie kommen mit der vorherigen Version unseres Status und unserer Metadaten zurück - mit Typen ohne Felder. Zum Zeitpunkt des Lesens der Daten versuchen wir, ihre neuen erforderlichen Spalten zu schreiben, und sehen uns mit der Tatsache konfrontiert, dass sie einfach nicht existieren! Cassandra sagt, dass dies im Allgemeinen ein anderer Typ ist, den sie nicht kennt.
Wir haben dieses Problem wie folgt behandelt: Wir haben
jeder unserer vorbereiteten Anfrage einen eindeutigen Text hinzugefügt .
create table get_offer( key frozen<tuple<frozen<user>, bigint>> PRIMARY KEY, value frozen<friend_data>, query_tag text ) insert into get_offer (key, value, query_tag) values (?key, ?value, 'tag_123'); select value as tag_123 from get_offer where key = ?key;
Wir werden nicht Millionen verbundener Clients haben, sondern nur eine Sitzung für jeden Knoten, der mehrere Verbindungen enthält. Für jede vorbereitende Anweisung einmal. Wir gehen davon aus, dass es in Ordnung ist, wenn für jede Version der Anwendung oder für jeden Start eines Knotens ein eindeutiger Text generiert wird, der eindeutig im Text unserer Anfrage enthalten ist.
Wir haben ein spezielles Feld hinzugefügt, um ihn auszutricksen. Beim Einfügen schreiben wir eine Konstante in dieses Feld. Es ist für jeden Start oder jede Anwendungsversion eindeutig - dies wird in der Bibliothek konfiguriert. Beim Lesen verwenden wir diesen Namen als Alias für den Wert, den wir erhalten. Die Anfrage ist genau die gleiche, wir machen immer noch einen ausgewählten Wert, aber der Text ist anders. Cassandra erkennt nicht, dass dies dieselbe Anforderung ist, berechnet eine andere MD5 und bereitet die Anforderung erneut mit neuen Metadaten vor.
Das zweite Problem ist das
Migrationsrennen . Zum Beispiel möchten wir mehrere parallele Migrationen durchführen. Beginnen wir mit einigen Notizen und gleichzeitig starten sie Berechnungen, führen Tabellen erstellen und Typen erstellen aus. Dies kann dazu führen, dass auf jedem Knoten oder in jedem der parallelen Threads alles erfolgreich ist und zwei Tabellen erfolgreich erstellt wurden. Aber in Cassandra ist man verwirrt und wir werden eine Auszeit zum Schreiben und Lesen erhalten.
Sie können Cassandra unterbrechen, wenn Sie versuchen, Prozesse aus mehreren Threads oder aus mehreren Knoten zu parallelisieren.
Wenn wir wissen, dass eine Fallback-Migration erforderlich ist,
migrieren wir
vor der Veröffentlichung von einem speziellen Knoten . Nur dann werden wir alle unsere Knoten während der Veröffentlichung starten. Also haben wir dieses Problem gelöst.
Das dritte Problem ist der
Mangel an Daten im Fallback-Cache . Es mag sein, dass wir die Methode „voll unterstützt“ haben, sie sollte historische Daten für ein Jahr speichern, aber in Wirklichkeit haben wir sie gestern gestartet.
Das Problem wurde durch Aufwärmen gelöst . Wir haben den Status "Erzwungen" verwendet und spezielle Knoten gestartet, die nicht mit echten Benutzern kommunizieren. Sie nehmen alle möglichen Schlüssel, die wir annehmen, und erwärmen den Cache in einem Kreis. Das Aufwärmen geht so schnell, dass das Backend, aus dem wir lesen, nicht zerstört wird.
Skalierung von Anwendungen, Backend, Big Data und Frontend - Scala ist dafür geeignet. Am 26. November veranstalten wir eine professionelle Konferenz für Scala-Entwickler . Stile, Ansätze, Dutzende von Lösungen für das gleiche Problem, die Nuancen der Verwendung alter und bewährter Ansätze, die Praxis der funktionalen Programmierung, die Theorie der radikalen funktionalen Kosmonautik - darüber werden wir auf der Konferenz sprechen. Beantragen Sie einen Bericht, wenn Sie Ihre Scala-Erfahrung vor dem 26. September teilen möchten, oder buchen Sie Ihre Tickets .