Hallo! Verbundenes Big-Data-Ad-hoc-Analyseteam der X5 Retail Group.
In diesem Artikel werden wir über unsere A / B-Testmethode und die Herausforderungen sprechen, denen wir täglich gegenüberstehen.
Big Data X5 beschäftigt etwa 200 Mitarbeiter, darunter 70 Mitarbeiter und Wissenschaftler. Unser Hauptteil befasst sich mit bestimmten Produkten - Nachfrage, Sortiment, Werbekampagnen usw. Darüber hinaus gibt es unser separates Ad-hoc-Analyseteam.
Wir sind:
- Wir unterstützen Geschäftsbereiche bei Datenanalyseanfragen, die nicht in vorhandene Produkte passen.
- Wir helfen Produktteams, wenn sie zusätzliche Hände benötigen.
- Wir beschäftigen uns mit A / B-Tests - und dies ist die Hauptfunktion des Teams.
Die Situation, in der wir arbeiten, unterscheidet sich stark von typischen A / B-Tests. In der Regel wird die Technik mit Online- und Online-Metriken verknüpft: Auswirkungen von Änderungen auf Conversion, Aufbewahrung, Klickrate usw. Die meisten Experimente beziehen sich auf Änderungen an der Benutzeroberfläche: Neuanordnen des Banners, Neulackieren der Schaltfläche, Ersetzen des Texts usw.
Das X5-Geschäft ist anders - es handelt sich um 15.000 Live-Offline-Geschäfte in verschiedenen Formaten, die im ganzen Land verteilt sind. Diese Funktion unterliegt bestimmten Einschränkungen. Erstens variiert der Satz von Metriken, die getestet werden können, stark, und zweitens wird die Beschränkung für Experimente auferlegt. Die Aufgabe, das Design einer Storefront eines Online-Shops zu ändern, ist in Bezug auf die Arbeit nicht mit der Aufgabe vergleichbar, die Reihenfolge der Abteilungen in Offline-Stores zu ändern.
Das Unternehmen verfügt über ein Team, das an einem Treueprogramm beteiligt ist, und seine Piloten sind der klassischen Idee des A / B-Testens am nächsten. Die Fragen, die uns gestellt werden, sind für „normale“ A / B-Tests sehr untypisch. Zum Beispiel:
- Wie wird sich die finanzielle Leistung des Geschäfts ändern, wenn ich die Reihenfolge der Abteilungen Wurst und Kuchen ändere?
- Wie wird sich das Modell der Kundenabwanderung auf das Finanzergebnis auswirken?
- Wie wirkt sich das Festlegen von Postamaten auf die Leistung des Geschäfts aus?
Kunden glauben, dass sich eine bestimmte Änderung positiv auf einen der Indikatoren auswirkt (wir werden später darüber sprechen). Unsere Aufgabe ist es, ihnen zu helfen, ihre Hypothesen anhand von Daten zu validieren.
Metriken
Welche Indikatoren testen wir?
RTO ,
durchschnittlicher Check und
Verkehr sind die am häufigsten verwendeten Wörter in unserem Open Space-Flügel.
- RTO (Einzelhandelsumsatz) - der Geldbetrag, den das Geschäft verdient.
Eine der wichtigsten Kennzahlen für Unternehmen und die am schwierigsten zu testenden.
Der tägliche Umsatz des Geschäfts wird in Millionen Rubel gemessen. Dementsprechend wird die Ausbreitung des Indikators in mindestens Tausenden von Rubel gemessen. Die komplexe und lange Formel zur Bestimmung der Stichprobengröße besagt, dass je größer die Varianz ist, desto mehr Daten für aussagekräftige Schlussfolgerungen benötigt werden. Um den Effekt selbst im zehnten Prozent bei einer so großen Streuung der Zapfwelle zu erfassen, müssen Piloten in Geschäften sechs Monate verbringen.
Stellen Sie sich die Reaktion des Vorstands vor, wenn der Pilot bei einem Treffen mit ihm sagt, dass er sechs Monate oder sogar ein Jahr in allen Geschäften verbringen muss? =)
Wir haben zwei Standardansätze.
Der erste Ansatz: Wir betrachten nicht die RTO des gesamten Geschäfts, sondern eine Art Produktkategorie. Beispielsweise wird aufgrund der Neuordnung von zwei Abschnitten im Geschäft („Kuchen“ und „Würste“) eine Erhöhung der Zapfwelle in beiden Kategorien erwartet. Die RTO einer Kategorie ist viel kleiner als die RTO des gesamten Geschäfts, daher ist die Streuung geringer. In diesem Fall hoffen wir, dass der Pilot in diesen Kategorien von den übrigen Kategorien isoliert ist.
Zweiter Ansatz: Wir probieren die Zeit. Die Beobachtungseinheit ist nicht die Zapfwelle des Geschäfts für den gesamten Piloten, sondern die Zapfwelle pro Woche oder Tag. Somit erhöhen wir die Anzahl der Beobachtungen, während die Varianz der Rohdaten beibehalten wird.
- Durchschnittlicher Scheck oder RTO / Anzahl der Schecks - der durchschnittliche Geldbetrag in einem Scheck.
Ein Teil der Änderungen zielt darauf ab, die Leute dazu zu bringen, mehr zu kaufen. Daher testen wir die RTO / Anzahl der Schecks oder den durchschnittlichen Scheck, wenn wir Analogien zu den üblichen Metriken ziehen.
Die Schwierigkeit beim Testen dieser Metrik hängt mit den Besonderheiten des Einzelhandels zusammen. Mit dem Pilotstart der Aktion „3 zum Preis von 2“ würde beispielsweise eine Person, die ein Produkt kaufen wollte, drei kaufen, und der Scheckbetrag erhöht sich. Aber was ist, wenn er später weniger wahrscheinlich in den Laden geht und der Pilot tatsächlich nicht so erfolgreich ist?
- Verkehr - Die Anzahl der Schecks im Geschäft für einen bestimmten Zeitraum.
Um falsche Schlussfolgerungen beim Testen von Hypothesen zu vermeiden, die sich auf die durchschnittliche Überprüfung auswirken, betrachten wir gleichzeitig Verkehrsänderungen. Wir können nicht direkt verfolgen, wie viele Leute in den Laden gekommen sind Nicht alle Besucher sind Kunden des Treueprogramms. Daher ist jeder Scheck für A / B-Tests ein „einzigartiger Besuch“ für den Kunden. In Analogie zur Zapfwelle betrachten wir den Verkehr in verschiedenen Zeitintervallen: Verkehr pro Tag, Verkehr pro Stunde.
Das Verhältnis zwischen durchschnittlicher Kontrolle und Verkehr ist sehr wichtig: Könnte der Pilot die durchschnittliche Kontrolle erhöhen, aber den Verkehr verringern und letztendlich nicht zu einer Erhöhung der Zapfwelle führen, sondern zu deren Verringerung? Könnte der Pilot dazu beitragen, den Verkehr zu erhöhen, ohne die durchschnittliche Rechnung zu ändern?
- Margin - die Differenz zwischen dem Preis eines Produkts und seinen Kosten
Es gibt Piloten, in deren Rahmen wir die Warenpreise ändern - für einige ist der Preis gestiegen, für andere im Gegenteil. Da wir die Produktionskosten nicht beeinflussen, ändern wir durch Preisänderungen die Warenmarge. Ein solcher Pilot kann zu erhöhtem Verkehr und zu einer Erhöhung der durchschnittlichen Kontrolle führen. Aber bedeutet dies, dass der Pilot erfolgreich ist und es wert ist, die Preise in allen Filialen des Netzwerks zu ändern? Nein, es könnte sehr gut passieren, dass Menschen häufiger Waren mit einer negativen oder kleinen Marge kauften und Waren mit einer hohen Marge aufgaben. Auf eine Erhöhung der RTO folgt daher nicht immer eine Erhöhung der Gesamtmarge. Daher lohnt es sich, diese Indikatoren separat zu testen.
Nehmen wir an, wir haben uns für die Zielmetriken entschieden. Folgende Fragen:
- Welchen Größeneffekt plant der Kunde zu erhalten?
- Welcher Effekt kann im Experiment tatsächlich festgestellt werden?
- Wie lange dauert das Experiment?
- Welche Gruppen?
Versuchszusammenfassung
A / B-Tests, die an Online-Benutzern durchgeführt wurden, haben einen erheblichen Vorteil - sie verfügen über eine hohe Generalisierungsfähigkeit. Mit anderen Worten, die während des Experiments erhaltenen Schlussfolgerungen können auf alle Benutzer skaliert werden. Die Verallgemeinerungsfähigkeit wird durch die Einstellung des Experiments garantiert: Die Kontroll- und Testgruppen werden zufällig gebildet, fast genau beide Gruppen aus derselben Verteilung, Sie können in beiden Gruppen viel Verkehr fangen - es würde ein Budget geben.
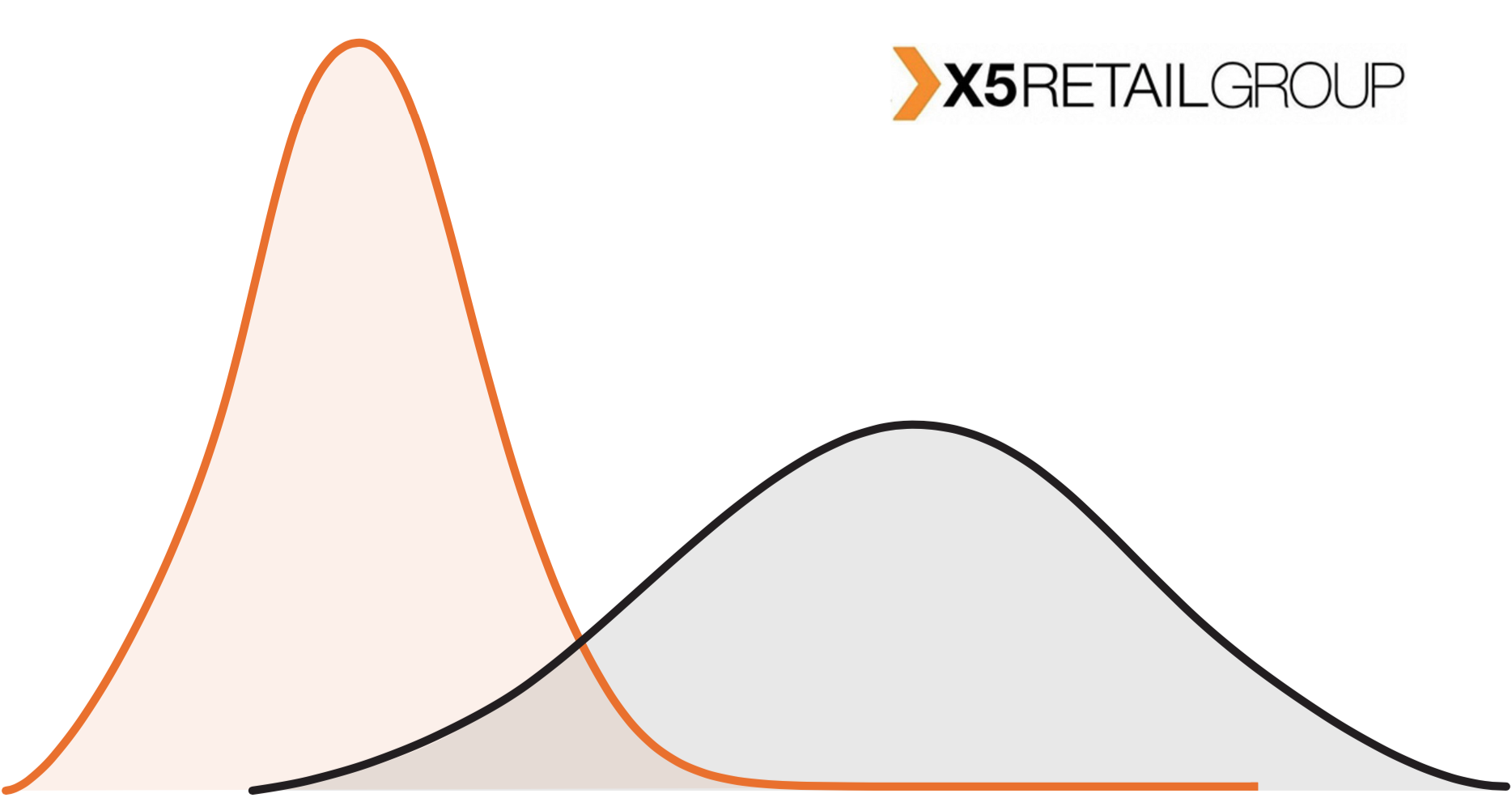
Im Offline-Einzelhandel funktioniert keine dieser Einstellungen. Erstens ist die Anzahl der Geschäfte begrenzt. Zweitens unterscheiden sich die Geschäfte stark voneinander. Das Perekrestok-Geschäft in der Wohngegend und das Perekrestok-Geschäft in der Nähe des Geschäftszentrums sind in der Tat sehr unterschiedliche Objekte aus verschiedenen Distributionen.

In der Grafik sehen wir, dass sich die Geschäfte aus der Testgruppe von den Geschäften des gesamten Netzwerks unterscheiden. Dies ist eine ziemlich typische Situation: In Pyaterochka befinden sich Filialisten nicht nur in Städten, sondern auch in kleinen Siedlungen. Große Piloten werden meist in Städten gehalten. Unabhängig davon, welchen Effekt wir erzielen, ist es falsch, ihn über das gesamte Netzwerk zu skalieren.
Die Gesamtwirkung
Є des Piloten bewerten wir anhand der Formel:

a ist der Schnittpunkt der Verteilungen der Pilotgruppe und aller Filialen im Netzwerk.
Beachten Sie, dass dies keine Folge statistischer Gesetze ist, sondern unsere Annahme, wie logisch es ist, den kumulativen Effekt zu berücksichtigen.
Die ideale Option besteht darin, eine repräsentative Stichprobe für die Testgruppe zu rekrutieren, dh die Geschäfte, die wirklich den gesamten Status des Netzwerks widerspiegeln. Repräsentativität führt jedoch zu Stichprobenheterogenität, weil Geschäfte mit niedriger oder hoher Zapfwelle werden beprobt.
Gruppengröße, Pilotdauer und minimaler nachweisbarer Effekt
Und jetzt zum Wichtigsten - der Größe des Effekts und der Dauer des Piloten. In der Regel stehen wir vor einer von drei Situationen:
- Der Kunde hat ein Zeitlimit für den Piloten und die Anzahl der Geschäfte, mit denen Sie arbeiten können.
- Der Kunde weiß, welche Effektgröße er erwartet, und fragt nach der Anzahl der Geschäfte, die der Pilot benötigt (und dann nach den Geschäften selbst).
- Der Kunde ist offen für unsere Angebote.
Es kann nicht gesagt werden, dass eines der Szenarien einfacher ist, da wir auf jeden Fall eine Tabelle des Effektfehlers erstellen.
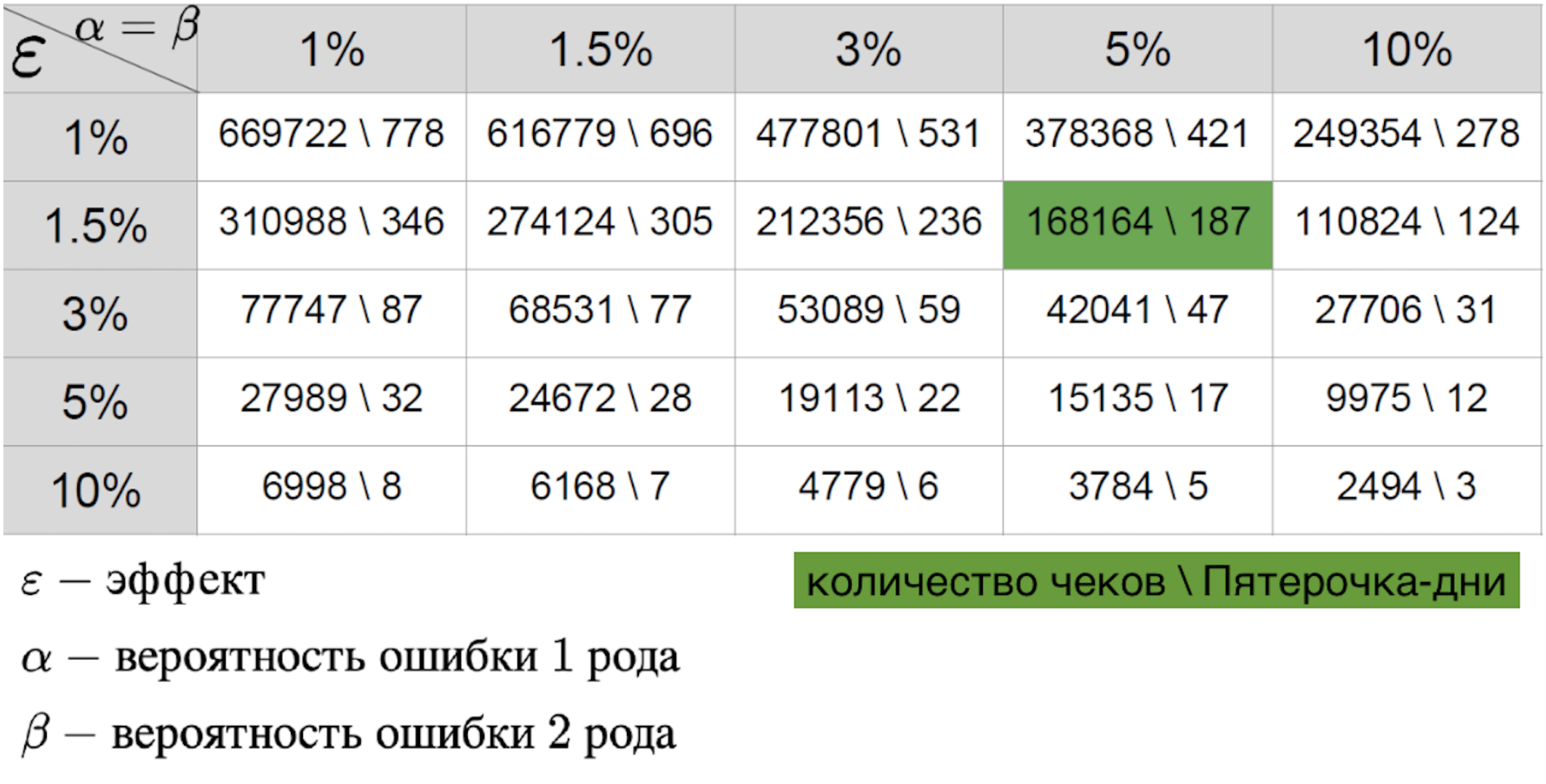
Wichtig für sie:
- ein Fehler der ersten Art - die Wahrscheinlichkeit, den Effekt zu sehen, wenn er nicht da ist;
- ein Fehler der zweiten Art - die Wahrscheinlichkeit, den Effekt zu überspringen, wenn er ist;
- die Größe des Effekts, der bei einem erfolgreichen Piloten erwartet wird.
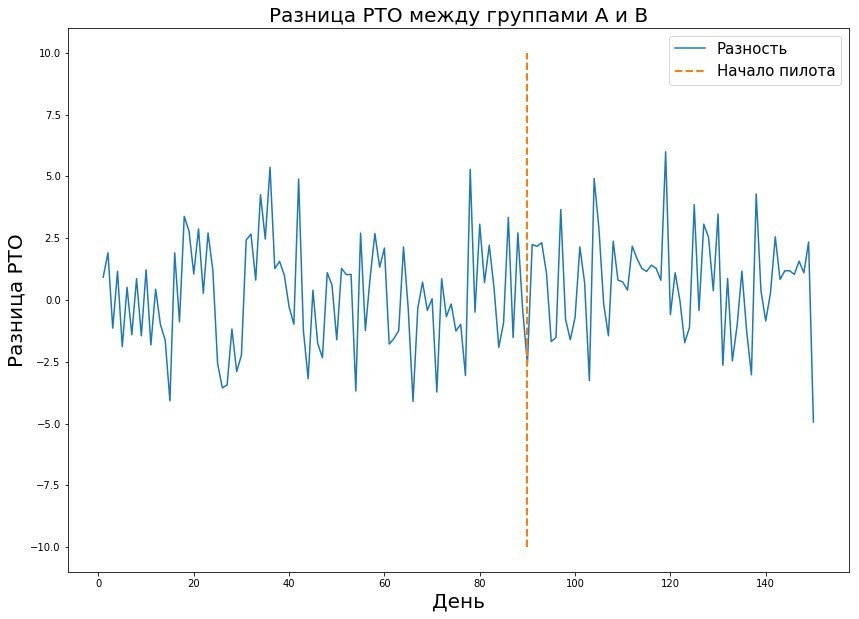
Durch die Kombination dieser drei Parameter können Sie die erforderliche Dauer des Piloten berechnen. Der Wert in der Tabelle ist die Stichprobengröße - in diesem Fall die Anzahl der Belege oder die durchschnittliche Metrik im Geschäft pro Tag, die für die Durchführung des Pilotprojekts erforderlich sind. Wenn wir über die reale Welt sprechen, beträgt die Wahrscheinlichkeit von Fehlern der ersten und zweiten Art normalerweise 5 bis 10 Prozent. Wie aus der Tabelle hervorgeht, benötigen wir bei solchen festen Fehlern 421 Pyaterochka-Tage, um den Effekt von einem Prozent zu erfassen. Es scheint, dass die Zahl ziemlich gut ist - schließlich ist 421 Pyaterochka-Tag ein Pilot in 40 Geschäften für 10 Tage. Es gibt jedoch ein „Aber“ - es gibt nur sehr wenige Piloten, die wirklich einen Ein-Prozent-Effekt erwarten. Normalerweise sprechen wir über Zehntel Prozent. Angesichts der Tatsache, dass RTO in Milliarden gemessen wird, kann ein Zehntel Prozent der Wirkung eines erfolgreichen Piloten zu einer starken Umsatzsteigerung führen. Aus diesem Grund möchte ich auch den kleinsten Effekt messen. Aber je kleiner die Effektgröße ist, desto höher ist der Fehler der zweiten Art. Dies ist verständlich: Der kleine Effekt ähnelt dem zufälligen Rauschen und wird selten als echte Abweichung von der Norm angesehen. Dies ist in der folgenden Grafik deutlich zu sehen, in der wir einen kleinen Effekt in Daten mit großer Varianz erfassen möchten.

A / A-Tests
Bevor der Pilot startet, müssen Sie sich für die Test- und Kontrollgruppe entscheiden. Der Kunde kann eine Pilotgruppe haben oder nicht. Wir sind bereit, ihm in beiden Fällen zu helfen, indem wir Einschränkungen beantragen - zum Beispiel sollten Geschäfte ausschließlich aus drei bestimmten Regionen bestehen.
Angenommen, wir haben in irgendeiner Weise eine Test- und Kontrollgruppe ausgewählt. Wie können Sie sicher sein, dass die ausgewählten Gruppen gut sind und Sie wirklich A / B-Tests an ihnen durchführen können? Es scheint, dass alles harmonisch klingt: Wir haben die erforderliche Anzahl von Beobachtungen erzielt, gemäß der Formel, mit der wir den Effekt von 0,7% erfassen können, haben wir ähnliche Geschäfte gefunden. Was passt jetzt nicht zu uns?
Leider viele ernste Fakten:
- Elemente der Stichprobe stammen nicht aus derselben Verteilung - unsere Stichprobe ist eine Mischung aus Beobachtungen aus verschiedenen Geschäften, und jedes Geschäft hat seine eigene Verteilung.
- Die Elemente der Stichprobe sind nicht unabhängig. In der Stichprobe gibt es viele Beobachtungen aus einem Geschäft, und es besteht eine Verbindung zwischen ihnen.
- Die Gleichheit der Mittel ist in Abwesenheit eines Piloten nicht garantiert - d. h. Wir sind uns überhaupt nicht sicher, ob sich die Statistiken des Geschäfts nicht unterscheiden würden, wenn es keinen Piloten gäbe.
All diese Probleme werden bei der Berechnung der Formel zur Auswahl der Anzahl der Beobachtungen in Abhängigkeit von Fehlern und Auswirkungen nicht berücksichtigt. Um das Ausmaß der Auswirkungen der oben genannten Probleme zu verstehen, führen wir A / A-Tests durch. Tatsächlich ist dies eine Simulation des gesamten Piloten in Geschäften zu einem Zeitpunkt, an dem sich kein Pilot in Geschäften befindet. Dieser Zeitraum wird als Vorpilot bezeichnet.

Während der Vorpilotperiode wiederholen wir drei Schritte viele Male:
- Auswahl ähnlicher Gruppen;
- Gleichheitsprüfung in zwei Gruppen;
- Hinzufügen von Effekten zur Testgruppe und Testen der Mittel auf Gleichheit.

Zu ähnlichen Gruppen passen
Wir erfinden kein Fahrrad, deshalb suchen wir nach ähnlichen Gruppen mit der guten alten Methode der nächsten Nachbarn. Die Strategie, Features für das Geschäft zu generieren, ist eine separate Kunst. Wir haben drei Arbeitsmethoden gefunden:
- Jedes Geschäft wird durch einen Merkmalsvektor gemäß der von uns getesteten Metrik beschrieben. Wenn wir beispielsweise den durchschnittlichen Scheck untersuchen, beschreiben wir die täglichen durchschnittlichen Schecks für 8 Wochen - wir erhalten 56 Schilder für das Geschäft. Dann nehmen wir den euklidischen Abstand zwischen den Zeichen eines Paares von Geschäften.
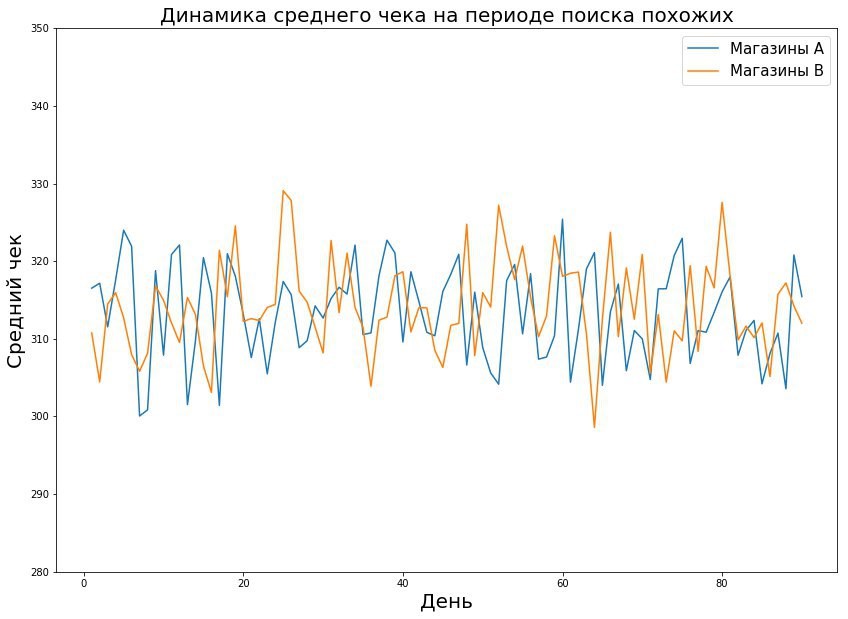
- Finden Sie Geschäfte mit ähnlicher Dynamik. Speicher können sich in absoluten Werten von Metriken unterscheiden, stimmen jedoch in Trends überein - und bei bestimmten mathematischen Manipulationen können diese Speicher als gleich angesehen werden.
- Prognostizieren Sie die Leistung des Geschäfts über den Zeitraum des Piloten (in der Zukunft) und wählen Sie ähnliche basierend darauf aus - aber hier brauchen wir ein Orakel, das die Leistung für den Piloten ziemlich genau vorhersagen kann.
Wir halten an einer sehr einfachen Hypothese fest: Wenn die Geschäfte vor dem Piloten ähnlich gewesen wären, wären sie ähnlich geblieben, wenn es keinen Pilotenwechsel gegeben hätte.
Sie können feststellen, dass selbst bei diesen drei Arbeitsmethoden viele Aspekte variiert werden können: die Anzahl der Tage / Wochen, anhand derer ein Merkmal berücksichtigt wird, eine Methode zur Bewertung der Dynamik eines Indikators usw.
Es gibt keine universelle Pille. In jedem Experiment gehen wir je nach Ziel verschiedene Optionen durch. Aber es ist sehr einfach: Finden Sie eine Methode zur Auswahl der nächsten Nachbarn, die vernünftige Fehler der ersten und zweiten Art ergibt. Woher sie kommen, erzählen wir weiter.
Prüfung auf Gleichheit der Mittel oder auf einen Fehler der ersten Art von Methode
Denken Sie daran, dass wir an dieser Stelle:
- bestimmt mit dem Kunden die Größe des Effekts und die Dauer des Piloten
- erklärte das Wesen von Fehlern der ersten und zweiten Art
- baute eine Methode zur Auswahl ähnlicher Gruppen
Ziel dieser Phase ist es sicherzustellen, dass die in Abschnitt 3 ausgewählte Methode solche Gruppen findet, dass sich der Indikator (RTO, durchschnittlicher Check, Verkehr) in diesen Filialen statistisch nicht unterscheidet, bevor der Pilot startet.
Im Zyklus wählen wir die ausgewählten Gruppen wiederholt durch einen statistischen Test und einen Bootstrap aus, um die Gleichheit zu gewährleisten. Wenn der Fehleranteil (d. H. Die Gruppen sind nicht gleich) höher als der Schwellenwert ist, wird das Verfahren zurückgewiesen und ein neues ausgewählt. Also bis wir die gewünschte Fehlerschwelle erreichen.
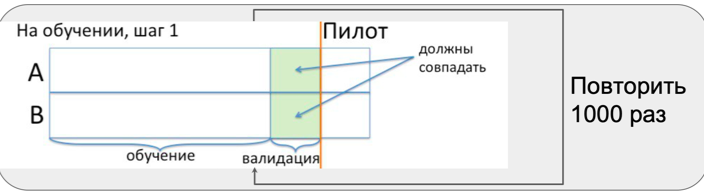
Es ist wichtig herauszufinden, wie oft wir den Effekt bemerken, wenn er nicht vorhanden ist, d. H. ob unsere Auswahlmethode auf zufällige Unterschiede zwischen Geschäften reagiert oder nicht.
Hinzufügen eines Effekts oder eines Fehlers der zweiten Art von Methode
Eine vernünftige Frage, aber bilden wir uns nicht so um, dass wir auch die tatsächlichen Auswirkungen als Lärm wahrnehmen und ignorieren? Mit anderen Worten, können wir einen Effekt erkennen, wenn er vorliegt?
Nachdem wir im letzten Schritt sichergestellt haben, dass die Gruppen zusammenfallen, fügen wir einer der Gruppen einen künstlichen Effekt hinzu, d. H. Wir garantieren, dass der Pilot erfolgreich ist und die Wirkung sein sollte.
Dieses Mal besteht das Ziel darin herauszufinden, wie oft die Gleichheitshypothese verworfen wird, d.h. Der Test konnte zwischen zwei Gruppen unterscheiden. Der Fehler in diesem Fall ist anzunehmen, dass die Gruppen gleich sind. Wir nennen diesen Fehler einen Fehler der zweiten Art.
Wieder im Zyklus testen wir die Kontrollgruppe und die "laute" Testgruppe auf Gleichheit. Wenn wir selten genug Fehler machen, glauben wir, dass die Methode zur Auswahl von Gruppen die Validierung bestanden hat. Es kann verwendet werden, um Gruppen in der Pilotperiode auszuwählen und sicherzustellen, dass wir den Effekt erkennen können, wenn der Pilot einen Effekt erzielt.

Über Heterogenität
Wir haben bereits erwähnt, dass Datenheterogenität einer der schlimmsten Feinde ist, gegen die wir kämpfen. Inhomogenitäten entstehen durch verschiedene Ursachen:
- Einkaufsheterogenität - jedes Geschäft hat seinen eigenen Durchschnittswert (in Moskauer RTO-Geschäften ist der Verkehr viel größer als in Dorfgeschäften).
- Heterogenität nach Wochentag - unterschiedliche Verkehrsverteilung und unterschiedliche durchschnittliche Kontrolle an verschiedenen Wochentagen: Der Verkehr am Dienstag sieht nicht wie der Verkehr am Freitag aus
- Heterogenität im Wetter - Menschen gehen bei unterschiedlichen Wetterbedingungen unterschiedlich einkaufen
- Heterogenität in der Jahreszeit - der Verkehr in den Wintermonaten unterscheidet sich vom Verkehr im Sommer - dies muss berücksichtigt werden, wenn der Pilot mehrere Wochen dauert.
Inhomogenität erhöht die Varianz, die, wie oben erwähnt, bei der Bewertung von Zapfwellenlagern bereits eine enorme Bedeutung hat. Die Größe des erfassten Effekts hängt direkt von der Varianz ab. Wenn Sie beispielsweise die Dispersion um den Faktor vier reduzieren, können Sie einen halben Effekt feststellen.
Im einfachsten Fall kämpfen wir mit der Heterogenität der Linearisierung.
Angenommen, wir hatten drei Tage lang einen Piloten in zwei Filialen (ja, dies widerspricht allen vorgeschriebenen Formeln über die Größe des Effekts, aber dies ist ein Beispiel). Die durchschnittlichen
RTOs in Geschäften betragen
200.000 bzw.
500.000 , während die Varianz in beiden Gruppen 10.000 und nach allen Beobachtungen 35.000 beträgt
Nach dem Piloten liegen die Durchschnittswerte in den Gruppen 300 und 600, die Abweichungen bei 10.000 bzw. 22.500 und die gesamte Gruppe bei 40.000.

Ein einfacher und eleganter Schritt besteht darin, die Daten zu linearisieren, d.h. subtrahieren Sie von jedem Periodenwert den Durchschnitt für den vorherigen.

Am Ausgang die Probe: 100, 0, 200, -50, 100, 250. Die Dispersion in der Pilotperiode wurde um das Dreifache auf 13000 reduziert.
Dies bedeutet, dass wir einen viel subtileren Effekt sehen können als bei den ursprünglichen absoluten Werten.
Dies ist nicht der einzige Weg, um mit Heterogenität umzugehen. Wir werden im nächsten Artikel über andere sprechen.
Allgemeiner Ansatz für A / B-Tests
Die Vorbereitung für große Piloten und deren Bewertung durchlaufen unser Team und werden gründlich getestet.
Unser Protokoll:
- vom Kunden Informationen über die Metrik und den erwarteten Effekt erhalten;
- Bestimmen Sie die Größe der Gruppen und die Dauer des Piloten.
- Entwicklung eines Algorithmus zur Verteilung von Geschäften nach Gruppen;
- Führen Sie einen A / A-Test zwischen Gruppen durch und validieren Sie diesen Algorithmus.
- Warten Sie, bis der Pilot fertig ist, und berechnen Sie den Effekt.
Keine dieser Stufen verläuft ohne Schwierigkeiten, jede hat Merkmale. Wie wir mit einigen von ihnen umgehen, haben wir in diesem Artikel beschrieben. Im nächsten werden wir darüber sprechen ...
Das Team
Am Ende möchte ich alle Schauspieler erwähnen:
- Valery Babushkin
- Alexander Sachnow
- Denis Ivanov
- Sergey Demchenko
- Nikolay Nazarov
- Sergey Kabanov
- Yuri Galimullin
- Helen Tevanyan
- Vladislav Ladenkov
- Sergey Zakharov
- Vasily Geschichten
- Alexander Belyaev
- Kismat Magomedov
- Egor Krashennikov
- Egor Karnaukh
- Svyatoslav Oreshin
- Yuri Trubitsyn