Heute werden wir das Channel Spanning Tree Protokoll STP untersuchen. Dieses Thema macht vielen Menschen aufgrund ihrer offensichtlichen Komplexität Angst, weil sie nicht verstehen können, was das STP-Protokoll tut. Ich hoffe, dass Sie am Ende dieses Video-Tutorials oder in der nächsten Lektion verstehen, wie dieser „Baum“ funktioniert. Bevor ich mit der Lektion beginne, möchte ich Ihnen das neue Design meines Desktops für diese Woche zeigen.
Sie können Ihren Desktop auch auf ähnliche Weise einrichten, wenn Sie den Link in der oberen rechten Ecke dieses Videos verwenden. Und bitte vergessen Sie nicht, meine Videokurse zu „mögen“ und mit Freunden zu teilen.
Wie beim letzten Mal werden wir heute ein anderes Thema gemäß dem ICND2-Zeitplan diskutieren, der auf der Cisco-Website vorgestellt wird. Dies ist Abschnitt 1.3, „Konfigurieren, Überprüfen und Probleme mit STP-Protokollen“, Unterabsatz 1.3a, „STP-Modi (PVST + und RPVST +)“ und 1.3b, „Auswählen eines STP-Root-Bridge-Switch“.
Da dies ein umfangreiches Thema ist, habe ich die Diskussion von Unterabschnitt 1.3b in die nächste Lektion, „Tag 37“, verschoben und dort Abschnitt 1.4 hinzugefügt. Heute schauen wir uns also an, wie STP ist, schauen uns die Modi dieses Protokolls PVST + und RPVST + an und schauen uns dann die Bridge ID-Root-Switch-ID und die Kosten der Route zum Port Cost-Root-Port an.

Zunächst müssen wir verstehen, welche Schaltschleife auf der 2. Ebene des OSI-Modells (auf Frame-Ebene) angezeigt wird und welche Probleme damit verbunden sind. Wir haben bereits in einer der vorherigen Episoden über Verkehrsschleifen gesprochen, und diese Lektion kann als Einführung in das heutige Thema betrachtet werden. Lassen Sie mich ein Beispiel geben: Wir haben Schalter A und Schalter B, die durch zwei Kommunikationsleitungen miteinander verbunden sind. Der erste Benutzer heißt Joe und der zweite ist Jim.

Wenn Joe eine Nachricht an Jim sendet, sendet er den Frame an Switch A. Switch A kennt Jims MAC-Adresse nicht, sodass er einen Broadcast-Frame über alle Ports sendet, mit Ausnahme desjenigen, über den Joe die Nachricht empfangen hat. Wenn der Broadcast-Frame von den Ports von Switch B empfangen wird, wird das auf einer Schnittstelle ankommende Paket an Jim gesendet, und das auf der zweiten Schnittstelle ankommende Paket wird an den ersten Port weitergeleitet und an Switch A zurückgesendet.

Gleichzeitig wird eine an der ersten Schnittstelle ankommende Anforderung an den zweiten Port weitergeleitet und auch an Switch A gesendet.
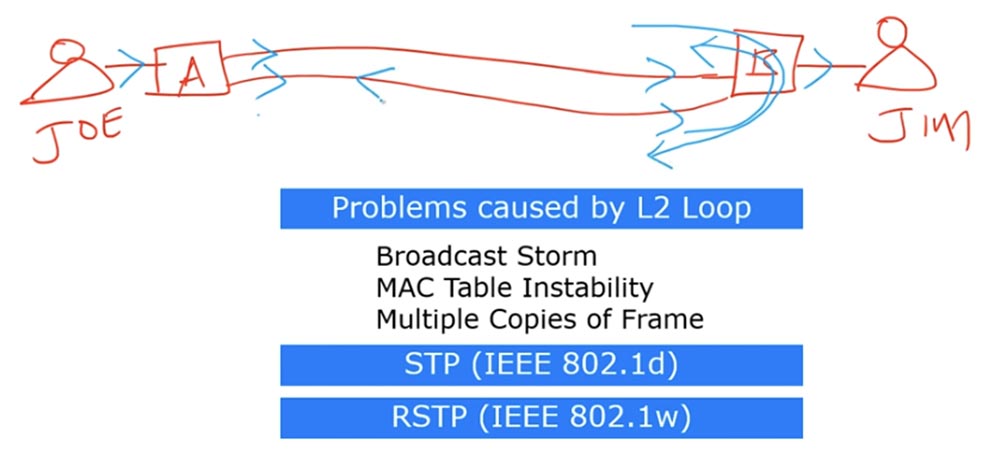
Nachdem Switch A diese Broadcast-Frames empfangen hat, sendet er sie zurück: Der auf der ersten Schnittstelle empfangene Frame wird auf der zweiten und der auf der zweiten empfangene Frame über die erste Schnittstelle an das Netzwerk gesendet. Dieser Vorgang wiederholt sich immer wieder und bildet eine Schleife von Broadcast-Anforderungen. Wenn ein anderer Broadcast in das Netzwerk eingeht, wird er auf die gleiche Weise wie der erste wiederholt. Das Ergebnis ist ein Phänomen, das als Broadcast Storm oder Broadcast Storm bezeichnet wird. Das Netzwerk überflutet so viele Broadcast-Frames, dass es abstürzt. Dieser Sturm kann nur aufhören, wenn eines der Geräte die Verbindung trennt oder die Verbindung unterbrochen wird. Wenn die Leitung betriebsbereit bleibt, funktioniert kurz nach dem Beginn eines solchen Sturms einer der Schalter aufgrund eines Speicherüberlaufs nicht mehr. Im zweiten Fall kann eine Schleife aufgrund der Weiterleitung eines Rahmens mit einer Unicast-MAC-Adresse auftreten. Dieses Problem wird als "Instabilität der MAC-Adresstabelle" bezeichnet. Es tritt auf, wenn mehr als zwei Verbindungen zwischen Switches bestehen. Ich werde ein Diagramm zeichnen, in dem die Schalter A, B und C miteinander verbunden sind und sich auch eine Schleife zwischen ihnen bilden kann.
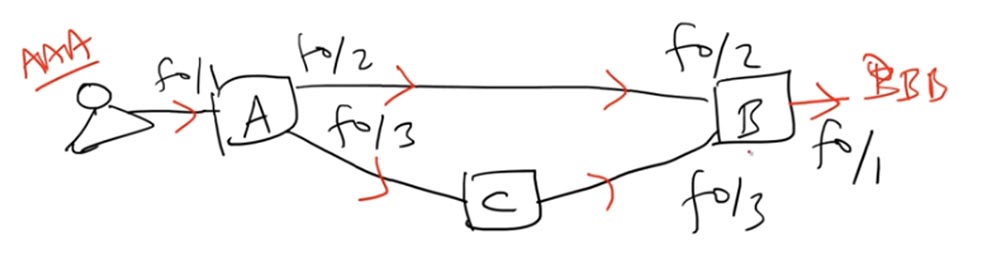
Schalter A hat drei Schnittstellen: f0 / 1, f0 / 2 und f0 / 3. Angenommen, der Benutzer verfügt über einen Computer mit der AAA-MAC-Adresse und sendet einen Broadcast-Frame an Switch A. Der Switch akzeptiert diesen Frame über die f0 / 1-Schnittstelle. Es gibt einen anderen Benutzer im Netzwerk, dessen Computer eine BBB-MAC-Adresse hat. Somit haben wir die Quelladresse AAA und die Zieladresse BBB.
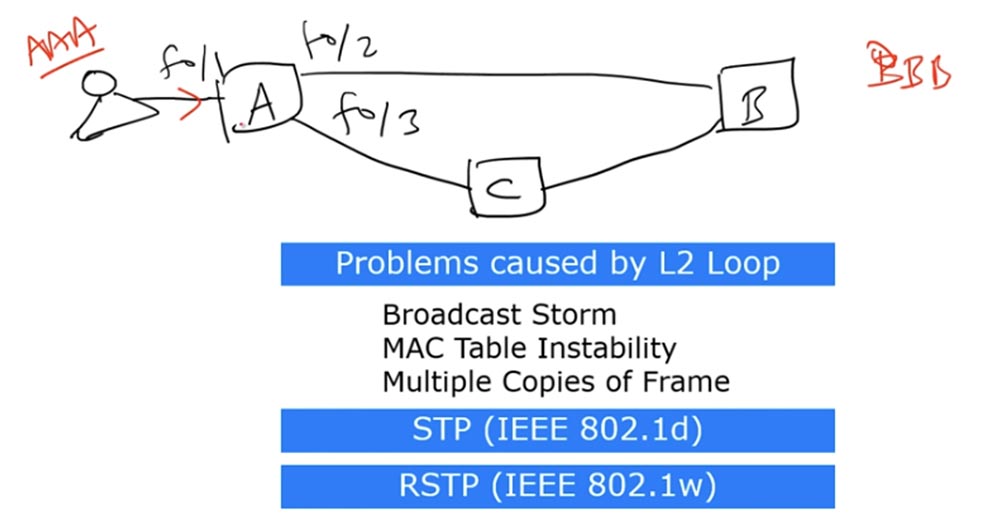
Switch A weiß nicht, wie er zur Ziel-MAC-Adresse der BBB gelangt, aber er weiß, dass die Quell-MAC-Adresse von AAA über die f0 / 1-Schnittstelle erreichbar ist, und schreibt einen Datensatz darüber in seine MAC-Adresstabelle. Schalter A sendet dann eine Anfrage nach der Zieladresse an die beiden anderen Schnittstellen - f0 / 2 und f0 / 3.
Beim Empfang der AAA-Anforderung erkennt Switch B, dass sie von der Quelle f0 / 2 stammt, und fügt in seine MAC-Adresstabelle einen Datensatz ein, dass das AAA-Gerät über die f0 / 2-Schnittstelle erreichbar ist. Außerdem hat er bereits einen Eintrag, dass die fB / 1-Schnittstelle dem Ziel der BBB entspricht, sodass er die Anfrage an den Adressaten sendet.
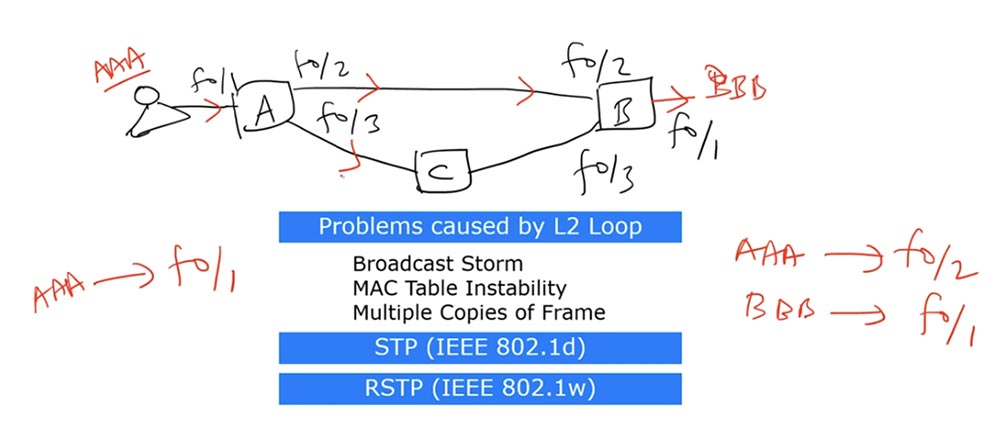
Da Switch A einen Broadcast-Frame gesendet hat, ging er nicht nur über die f0 / 2-Schnittstelle zu Switch B, sondern auch über die f0 / 3-Schnittstelle zu Switch C, der ihn wiederum an die f0 / 3-Schnittstelle von Switch B sendete.
Nachdem Switch B den Frame erhalten hat, denkt er folgendermaßen: „Ich weiß, dass sich die AAA-Quelle zuvor auf der f0 / 2-Schnittstelle befand, aber jetzt kam der Frame von ihm über die f0 / 3-Schnittstelle zu mir, sodass ich meine MAC-Adresstabelle aktualisieren und f0 ersetzen muss / 2 auf f0 / 3. "
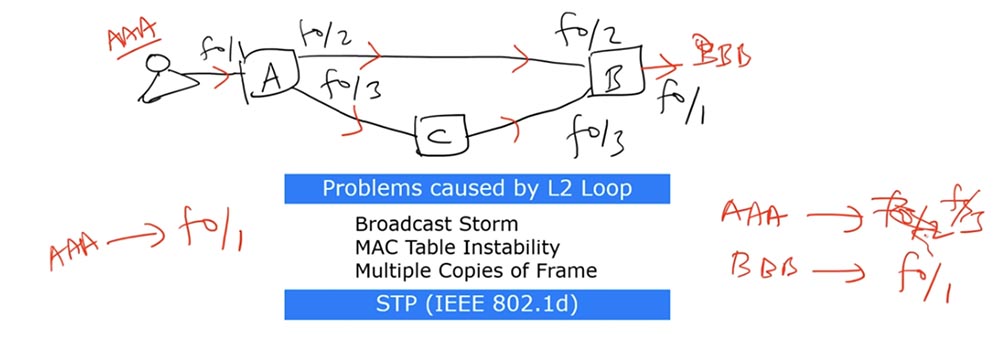
Als nächstes kehrt der Frame zu Schalter A zurück und „überrascht“ ihn sehr: Vor Schalter A dachte er, dass die Quelle AAA mit der f0 / 1-Schnittstelle verbunden ist, und nun stellt sich heraus, dass die Nachricht von der f0 / 2-Schnittstelle kam. In umgekehrter Richtung des Rahmens über Schalter B und C erhält Schalter A eine Nachricht, die ihn erneut verwirrt - jetzt stellt sich heraus, dass sich die AAA-Quelle auf der f0 / 3-Schnittstelle befindet.
Somit wird die MAC-Adresstabelle dieses Schalters zwischen diesen drei Schnittstellen ständig aktualisiert, dh das oben erwähnte Problem der Instabilität der MAC-Adresstabelle wird auftreten. Wie im ersten Fall wird hier eine Frame-Schleife gebildet, die alle paar Sekunden zu einer Tabellenaktualisierung führt.
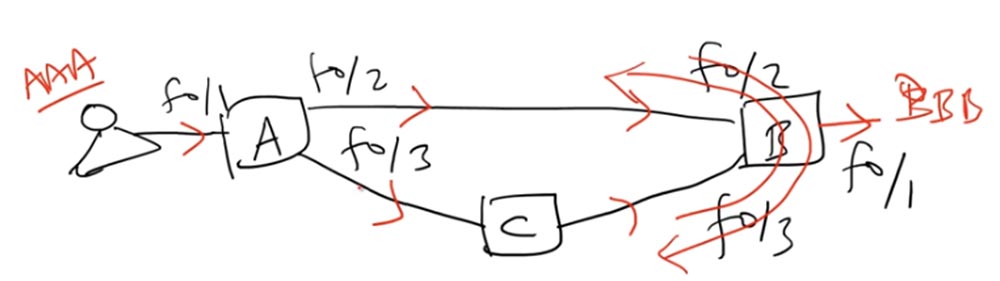
Es gibt ein drittes Schleifenproblem - mehrere Kopien des Rahmens. Benutzer AAA sendet den Frame an Schalter A und sendet ihn dann über die f0 / 2-Schnittstelle an Schalter B, der ihn über die f0 / 1-Schnittstelle an das BBB-Ziel liefert. Es gibt keine Probleme.
Gleichzeitig sendet Switch A denselben Frame über seine zweite Schnittstelle f0 / 3 an Switch C, der ihn an Switch B weiterleitet. Beim Empfang des Pakets oder Frames von Switch C erkennt Switch B, dass es an BBB adressiert ist, und sendet es an den Adressaten. Somit empfängt der BBB-Benutzer dasselbe Paket zweimal. Hier tritt das Problem auf - wenn dies die Verteilung der von der Anwendung durchgeführten Daten ist, sollte derselbe Frame nicht zweimal zum Benutzer gelangen.
Dies sind die drei Probleme, die Frame-Loops verursachen können. Alle werden auf eine Weise gelöst, über die wir bereits gesprochen haben - mithilfe des STP-Protokolls. In einem der vorherigen Videos erinnere ich mich nicht an seine Nummer. Als wir die Portmodi diskutierten, wurde dieses Protokoll bereits erwähnt, das dazu dient, Verkehrsschleifen im Netzwerk zu verhindern.
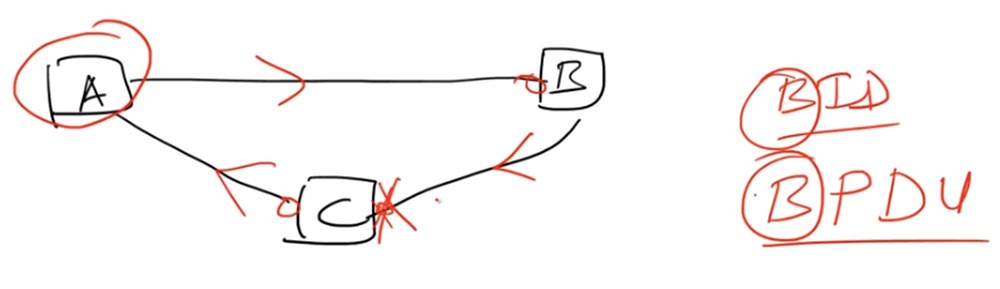
Eine Schleife wird also gebildet, wenn drei Geräte miteinander verbunden sind, eine geschlossene Netzwerkschleife bilden und zu derselben Broadcast-Domäne gehören. In diesem Fall bezeichnet der vom STP-Protokoll verwendete Algorithmus einen der Switches als Root-Switch - Root Bridge. Wählen wir Schalter A als Root-Schalter.

Jeder mit dem Root-Switch verbundene Port muss sich im Weiterleitungsstatus befinden. Dies sind die linken Ports des Switches C und B. Diese Ports ermöglichen die Übertragung von Paketen oder Frames in Richtung des Root-Switch A. Auf der Verbindungsleitung der Switches C und B muss sich einer der Ports befinden im Sperrzustand Blockieren.
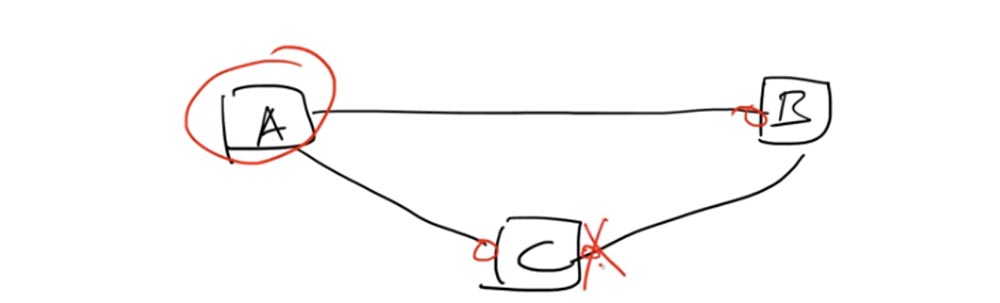
Dies bedeutet, dass kein Datenverkehr gesendet wird. Switch B sendet möglicherweise weiterhin Datenverkehr an Switch C, aber sein rechter Port verarbeitet diesen Datenverkehr nicht, obwohl er physisch weiterhin funktioniert. Dies erfolgt mithilfe der Bridge-ID oder der BID-Switch-ID - Bridge-ID.
Sie müssen sich daran erinnern, dass STP lange vor dem Erscheinen von Ethernet-Switches erstellt wurde. Dann wurde anstelle des Begriffs switch der Begriff Bridge verwendet, und viele Protokolle verwenden immer noch die klassische Terminologie technischer Standards. Jetzt ist BID die Schalterkennung.
Die Informationen, die der Root-Switch mit anderen Switches austauscht, werden als BPDU bezeichnet. Geräte tauschen alle 2 Sekunden BPDU-Nachrichten aus - diesmal wird dies als „Hallo-Timer“ bezeichnet. Die BPDU-Nachricht enthält die BID des Root-Switch und die Kosten für die Route zum Root-Switch oder die Root-Pfadkosten (dies ist tatsächlich die Entfernung zum Root-Switch). Die Kosten für den Pfad an jedem Port dienen dazu, den kürzesten Pfad zum Root-Switch zu berechnen, aber wir werden uns nicht mit diesem Konzept befassen.
Logischerweise funktioniert das Schema folgendermaßen: Dank des blockierten rechten Ports des Switch C gelangt der Verkehr in Richtung Switch A - Switch B - Switch C nicht zu Switch A, dh er schließt nicht in die Schleife. C leitet den Verkehr A, der ihn an B sendet, Schalter B leitet ihn an C, und an diesem Punkt wird die Schleife unterbrochen.
So funktioniert das STP-Protokoll, das dem IEEE 802.1d-Standard entspricht. Dies ist ein sehr alter Standard, dessen Nachteil die maximale Zeit für die Aktualisierung von Informationen bei Verbindungsabbruch ist, die 50 Sekunden beträgt. Zusätzlich zum Blockierungs-Port-Blockierungsstatus werden zwei weitere Zwischenzustände unterstützt - Abhören und Lernen. Danach wird in den Weiterleitungsübertragungsstatus gewechselt.
Alle 2 Sekunden tauschen die Schalter eine Hallo-Nachricht aus - C sendet sie an B und A, A sendet Hallo C und B und so weiter. Wenn das Gerät diese Nachricht nicht empfängt, wartet es eine weitere 10-fache Zeitspanne des Hallo-Timers, dh 20 Sekunden. Danach wartet es auf eine Aktion, wechselt in den Hörzustand, der 15 Sekunden dauert, geht dann in den Lernzustand über und bleibt weitere 15 Sekunden darin. Somit beträgt die Gesamtdauer der Inaktivität 50 s. Für moderne Netzwerke ist dies ein ziemlich langer Zeitraum.
Um diese Situation zu verbessern, wurde ein weiterer Standard eingeführt - IEEE 802.1w oder Rapid STP - das schnelle STP-Protokoll, das als RSTP bezeichnet wird. Es enthält keine Zwischenzustände und wechselt vom Sperrzustand in den Weiterleitungszustand.
In STP gibt es Root-Ports. Root-Port - Dies sind die Ports, über die die Kommunikation mit dem Root-Switch erfolgt. In RSTP wird das Konzept alternativer Ports hinzugefügt, die sich nicht auf den Root-Switch beziehen. Für den Fall, dass eine Trennung zwischen dem Root-Port von RP und dem Root-Switch besteht, wird der alternative ALT-Port sofort zum Root-Port von RP, und die Kommunikation erfolgt auf einer anderen Route.
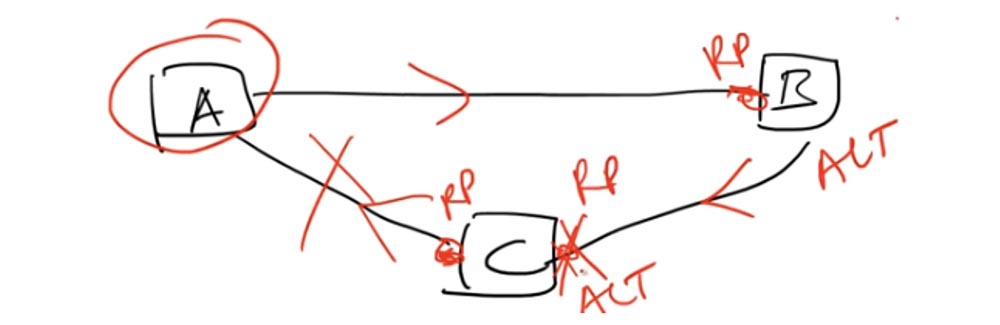
Bei den schwierigsten Ereignissen dauert dieser gesamte Vorgang maximal 10 Sekunden, und 10 Sekunden Inaktivität sind viel besser als 50 Sekunden. Dies ist der Hauptunterschied zwischen STP und RSTP.
Cisco verwendet STP jetzt auf verschiedene Arten. Ursprünglich sollte es jedoch in derselben Broadcast-Domäne mit einem nativen VLAN arbeiten, sodass STP als Teil von VLAN1 angesehen wurde. Gleichzeitig wurde angenommen, dass der gesamte Datenverkehr Teil dieser einzelnen Broadcast-Domäne ist. Als sich die Netzwerkgeräte weiterentwickelten, begann Cisco, STP auf andere Weise zu verwenden, und erstellte PVSTP (Per-VLAN Spanning Tree), ein proprietäres Protokoll, das für die Arbeit mit mehreren VLANs entwickelt wurde. Dies bedeutete, dass jedes VLAN seinen eigenen STP hatte, dh seinen eigenen Root-Root-Switch Root Bridge.

Ebenso wie Cisco STP durch die Erstellung von RSTP verbessert hat, hat es die „beschleunigte“ Version von PVSTP - RPVSTP - entwickelt. Beide Protokolle wurden mit dem proprietären ISL-Protokoll gekapselt und unterstützten den 802.1q-Standard nicht, da sie vor seiner Einführung entwickelt wurden. Um die Interoperabilität zu verbessern, hat Cisco diese Protokolle um 802.1q-Unterstützung erweitert. Die neuen Protokolle, die sowohl ISL als auch 802.1q unterstützen, heißen PVSTP + und RPVSTP +. Jetzt sind sie Industriestandards für Cisco-Netzwerke.
Der STP-Prozess ist durch eine Pfadkostenmetrik an jedem Portkostenport gekennzeichnet. Als Grundlage für diesen Indikator wurde die Portgeschwindigkeitskennlinie verwendet - die Portgeschwindigkeit in mb / s. Gemäß dem IEEE 1998-Standard entsprach die Geschwindigkeit von 10 Mbit / s den Kosten von Port 100, die Geschwindigkeit von 100 Mbit / s - die Kosten von 19, 1 Gbit / s - die Kosten von 4 und 10 Gbit / s - die Kosten von 2. Dieser Standard berücksichtigte nicht die Geschwindigkeit von 100 Gbit / s und 1 Tb / s, so wurde 2004 ein neues IEEE entwickelt, bei dem der relative Indikator für die Kosten des Hafens zwischen 2 und 20 Millionen variiert.

Je höher die Geschwindigkeit, desto geringer die Kosten. Bei der Berechnung von Routen werden daher Häfen mit geringeren Kosten ausgewählt. Wenn es zwei Leitungen gibt - FastEthernet und GigabitEthernet, sind die Kosten für die letzte Kommunikationsleitung wesentlich geringer. Wenn Sie also eine Route zum Root-Switch auswählen, hat der GigabitEthern-Port Vorrang. Der Root-Switch selbst hat keine Portkosten. Im nächsten Video werden wir uns den Prozess der Routenauswahl ansehen, damit Ihnen so viel klar wird. Denken Sie vorerst nur an das Preisprinzip.
Das nächste Thema ist die Absender-ID der Bridge-ID. In STP enthält es 2 Byte Switch-Prioritätsinformationen und 6 Byte MAC-Adresse.
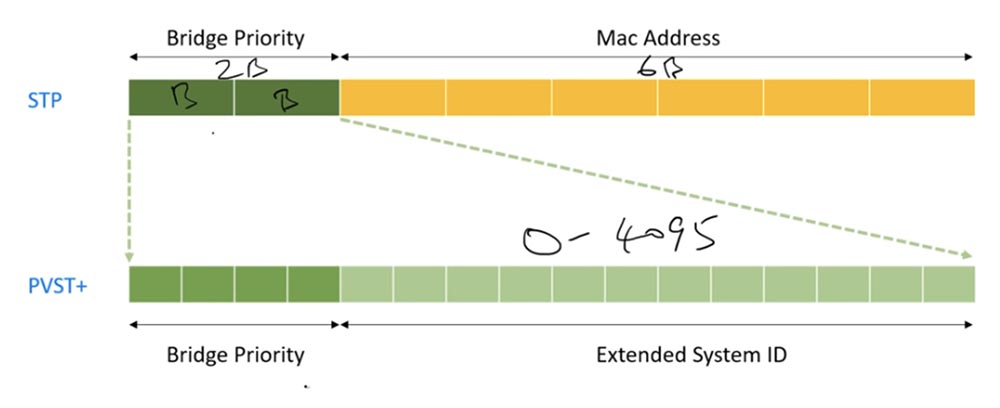
Das fortgeschrittenere PVSTP besteht aus 16 Bit. Die ersten 12 Bits werden als erweiterte System-ID oder erweiterte Systemkennung bezeichnet. Es enthält die VLAN-Netzwerkkennung - die Netzwerknummer im Bereich von 0 bis 4095 und die MAC-Adresse. Weitere 4 Bits werden verwendet, um die Priorität der Brücke oder des Schalters anzuzeigen. Wenn Sie sich an unsere magische Binärtabelle erinnern, werden Sie sehen, dass wenn alle 4 Bits 0 sind, wir die Priorität Null erhalten.
Wenn die Bits in der Reihenfolge 0001 liegen, bedeutet dies, dass die Nummer 4096 unter 1 liegt, dh die Priorität ist 4096. Abhängig von den 16 Bitkombinationen wird eine dieser Nummern als Priorität verwendet - von 0 bis 61440 und jede nachfolgende 4096 mehr als der vorherige.
Standardmäßig haben alle Cisco-Switches die Priorität 32768, Sie können jedoch eine dieser Nummern als Priorität auswählen. Bei Verwendung der erweiterten System-ID wird dieser Nummer eine VLAN-Nummer hinzugefügt. Wenn Sie also über VLAN1 verfügen, beträgt die Bridge-ID-Priorität 32768 + 1 = 32769.

Wir haben auch eine MAC-Adresse. Angenommen, die Bridge-ID eines Geräts lautet 32769: AAA: AAA: AAA und das andere 32769: BBB: BBB: BBB. Sie haben den gleichen numerischen Prioritätswert, aber das Gerät mit der niedrigeren MAC-Adresse hat einen Vorteil, dh AAA: AAA: AAA. Um besser zu verstehen, wie Bridge ID funktioniert, können Sie dieses Video erneut überprüfen.
Wir können die MAC-Adresse des zweiten Geräts nicht ändern, aber wir können den numerischen Prioritätswert 32769 ändern. Wenn Sie möchten, dass dieses Gerät eine höhere Priorität hat, können Sie den Prioritätswert auf 0 oder eine beliebige Zahl unter 32769 ändern. Wenn wir 0 und die Netzwerknummer VLAN1 verwenden, dann erhalten wir den numerischen Wert der Priorität 1. In diesem Fall hat dieses Gerät unabhängig vom Wert der MAC-Adresse eine höhere Priorität als das erste.
Wenn Sie dieses Video von unserer Website herunterladen möchten, können Sie den Gutschein für einen Rabatt von 50% verwenden, der bis Ende 22. November 2017 gültig ist. Ich erinnere Sie daran, dass wir heute ein sehr wichtiges Thema untersucht haben. Ich rate Ihnen daher, dieses Video-Tutorial erneut anzusehen.
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder Ihren Freunden empfehlen, einen
Rabatt von 30% für Habr-Benutzer auf ein einzigartiges Analogon von Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s von $ 20 oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV von 199 US-Dollar in den Niederlanden! Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über
den Aufbau eines Infrastrukturgebäudes. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?