Viele Programmierer haben gehört, dass der Code manchmal separaten Bibliotheken zur weiteren Wiederverwendung zugewiesen werden sollte. Die Frage, welche Art von Code als separate Einheit herausgegriffen werden soll, verwirrt jedoch viele Entwickler. Beim Lesen von Artikeln / Konversationen zu diesem Thema wird normalerweise an das Problem der vorzeitigen Verallgemeinerung erinnert.
Erfahrene Programmierer haben normalerweise ihre eigenen Regeln, nach denen sie verstehen, ob der Code als wiederverwendbar unterschieden werden sollte. Zum Beispiel, wenn ein solcher (oder sehr ähnlicher) Code an drei oder mehr Stellen verwendet wird. Trotzdem sind sich alle einig, mit denen ich Gelegenheit hatte, zu diesem Thema zu sprechen, dass ein solcher wiederverwendbarer Code existieren muss, seine Erstellung ein Segen ist und es sich lohnt, Ihre Zeit zu verbringen.
Ich möchte das Thema der Wiederverwendung von Code im Zusammenhang mit der Erstellung einer serviceorientierten und Microservice-Architektur ansprechen.
Was ist wiederverwendbarer Code?
Wiederverwendbarer Code ist Code, der in einer separaten Entität isoliert ist und in verschiedenen Sprachen unterschiedlich aufgerufen wird - Bibliothek, Paket, Abhängigkeit usw. In der Regel wird dieser Code in einem separaten Repository gespeichert, und es gibt eine Dokumentation zum Verbinden und Verwenden dieses Codes (README.md). Zusätzlich kann der Code durch Tests abgedeckt werden, es kann Anweisungen zum Vornehmen von Änderungen geben (CONTRIBUTING.md) und CI kann konfiguriert werden. Verschiedene der Beschreibung beigefügte Abzeichen verbessern nur die visuelle Darstellung der Reife einer bestimmten Entität, und die Anzahl der zugewiesenen Sterne zeigt die Beliebtheit dieser Lösung an. Sie müssen für Beispiele nicht weit gehen - öffnen Sie einfach die Github-Seite eines der gängigen Frameworks in Ihrer Lieblingssprache, zum Beispiel
vue.js. Im Allgemeinen sind die Methoden zur hochwertigen Gestaltung von Bibliotheken ein Wagen und ein kleiner Wagen.
Dienstleistungen und Microservices
In diesem Artikel ist ein Service eine vollständige Entität, die einen bestimmten Satz spezifischer Aufgaben in ihrem Verantwortungsbereich ausführt und eine Schnittstelle für die Interaktion bereitstellt. Der Service oder Microservice in diesem Artikel kann aus architektonischer Sicht identische Konzepte sein, die Frage ist nur maßstabsgetreu. Ein Service kann aus einer Reihe von Microservices bestehen, die ihren Geschäftslogiksektor implementieren, oder ein stolzer Microservice sein.
Die serviceorientierte Architektur setzt voraus, dass jeder Service nur minimal mit anderen verbunden ist. Trotzdem ist eine dienstübergreifende Interaktion nicht ausgeschlossen, sondern es wird nur davon ausgegangen, dass sie minimiert werden sollte. Um Anforderungen zu empfangen, implementiert ein Dienst normalerweise eine standardisierte API. Es kann alles sein - REST, SOAP, JSONRPC oder das neue GraphQL.
Herkömmlicherweise können Dienstleistungen in Infrastruktur und Lebensmittelgeschäft unterteilt werden. Produktdienstleistungen sind solche, die die Logik eines Kundenprodukts implementieren. Sie arbeiten beispielsweise mit Anwendungen für die Verbindung oder organisieren den Support für dieses Produkt über den gesamten Lebenszyklus eines Kunden. Bei Infrastrukturservices geht es eher um die Grundfunktionalität eines Unternehmens (oder Projekts), z. B. einen Service mit Kundeninformationen oder einen Service, der Informationen zu bestimmten Bestellungen speichert. Zu den Infrastrukturdiensten gehören auch Dienste, die Zusatzfunktionen implementieren, z. B. ein Kundeninformationsdienst (Senden von Push-Nachrichten oder SMS) oder ein Dienst zur Interaktion mit Dadata.
Eine kleine Fantasie
Angenommen, es gibt einen hypothetischen Online-Shop, der auf einer serviceorientierten Architektur basiert. Die Entwickler dieses technischen Wunders konnten sich einig sein und kamen zu dem Schluss, dass alle ihre Dienste als APIs funktionieren werden, beispielsweise unter Verwendung des jsonrpc-Protokolls. Da der Online-Shop jedoch groß ist, nicht stillsteht und sich aktiv weiterentwickelt, gibt es dort mehrere Entwicklungsgruppen, also mehr als zwei - zwei Design-Gruppen, eine begleitet von dem, was bereits geschrieben wurde. Um den Effekt zu verstärken, schreiben alle Teams auf denselben Stapel.
Die Architektur eines hypothetischen Online-Shops: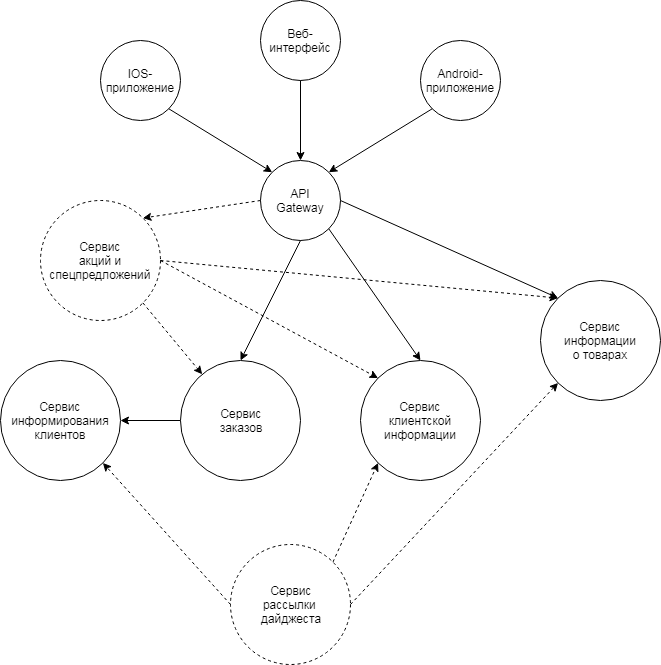
Nur der im Internet herausragende API-Dienst bietet Zugriff auf alle Front-End-Systeme - die Weboberfläche des Online-Shops sowie auf mobile Anwendungen.
Der Kundeninformationsdienst speichert Informationen über Kunden, weiß, wie diese gestartet, autorisiert und die erforderlichen Informationen über sie ausgegeben werden.
Der Produktinformationsdienst speichert Informationen zu Produkten, deren Guthaben und Verfügbarkeit für Bestellungen und bietet Methoden zum bequemen Abrufen der erforderlichen Informationen.
Der Bestellservice arbeitet mit Bestellungen. Hier ist die Logik der Auftragserstellung, ihrer Bestätigung, der Wahl der Zahlungsart und der Lieferadresse usw.
Der Kundeninformationsdienst kann PUSH / SMS / E-Mail-Nachrichten senden. Die Art der Kommunikation hängt beispielsweise von den Einstellungen eines bestimmten Clients ab, und der Client kann auch die gewünschte Zeit für den Empfang von Benachrichtigungen festlegen.
Diese Dienste sind bedingt infrastrukturell, da ein Online-Shop ohne sie nicht als solche funktionieren kann.
Dienstleistungen für Werbeaktionen und Angebote sowie die Verteilung des Digests sollen in naher Zukunft von Projektteams entwickelt werden. Diese Dienstleistungen sind bedingt Lebensmittel.
In jedem Fall kann ein neuer Produktservice ohne Interaktion mit Infrastrukturdiensten nicht existieren - er muss höchstwahrscheinlich Informationen über Kunden erhalten oder Benachrichtigungen senden.
In dem oben beschriebenen Beispiel werden die Details der Implementierung jedes Dienstes absichtlich ausgeblendet. So verfügt beispielsweise ein Kundeninformationsdienst wahrscheinlich über einen Mechanismus zur verzögerten Codeausführung, z. B. eine Ausführungswarteschlange, und ein Produktinformationsdienst kann über ein eigenes Admin-Panel für eine bequeme Warenverwaltung verfügen, und die API für Front-End-Systeme verfügt wahrscheinlich über mehrere Replikate. Darüber hinaus ist die beschriebene Architektur möglicherweise nicht optimal, sie wird einfach dem Kopf entnommen.
Im Kontext der vorgeschlagenen Architektur wird sofort klar, dass vorgefertigte Bibliotheken für eine schnelle Produktentwicklung unerlässlich sind. Daher ist es wichtig, eine vorgefertigte Implementierung des jsonrpc-Servers sowie des Clients dafür zu haben, da dies das Hauptprotokoll für die Organisation der dienstübergreifenden Interaktion ist. Auch in diesem Beispiel wird das Problem der Dokumentation der API voll ausgeschöpft. Für die Erstellung der Dokumentation sollten die Teams natürlich auch über ein vorgefertigtes Tool verfügen. Wenn wir davon ausgehen, dass es noch ein vorgefertigtes Tool zum Generieren von SMD-Schemata für jsonrpc-Server gibt, kann sich die Geschwindigkeit der Entwicklung neuer Dienste noch weiter erhöhen. Daher sollte es im Unternehmen idealerweise eine Reihe vorgefertigter Bibliotheken geben, mit denen alle Teams typische Aufgaben ausführen. Diese Bibliotheken können entweder proprietär oder Open Source sein. Hauptsache, sie erfüllen ihre Aufgaben gut. Offensichtlich ist ein Team, das sich auf dem allgemeinen Stapel befindet und Dienste mit vorgefertigten Bibliotheken schreibt, effektiver als ein Team, das ständig zyklisch arbeitet. Das Vorhandensein eines einzigen Frameworks und einer einzigen Datenbank von Bibliotheken, die in allen Projektteams verwendet werden, nenne ich ein einziges Ökosystem.
Und was ist mit großen Unternehmen?
In großen Unternehmen gibt es viel mehr Infrastrukturdienste sowie die verwendeten Interaktionsprotokolle. Die Anzahl der fertigen Bibliotheken kann bis zu zehn oder sogar Hunderten betragen. Noch wichtiger ist es, hier wiederverwendbaren Code hervorzuheben.
Zufällig habe ich Erfahrung in einem Unternehmen, das etwa 200 Entwickler beschäftigt, die in verschiedenen Sprachen schreiben - Java, C #, PHP, Python, Go, Js usw. Überraschenderweise ist das gemeinsame Ökosystem im Kontext eines einzelnen Stapels. weit entfernt von allen Entwicklungsteams haben und nutzen. Es scheint, dass das Offensichtliche - wiederverwendbaren Code vorzubereiten, richtig zu formatieren und zu verwenden - alles andere als offensichtlich ist. Natürlich lösen Entwicklungsteams ihre Probleme. Jemand verwendet eine Dienstvorlage - einen Satz Code, der den Kern jedes neuen Dienstes bildet, aus dem alles Unnötige herausgeworfen und der erforderliche hinzugefügt wird.
Andere Entwicklungsteams verwenden ihre eigenen Motorräder, kopieren sie und fügen sie von Projekt zu Projekt ein. Es ist ihnen egal, sie zu dokumentieren und zu testen. Im Allgemeinen gibt es große Unstimmigkeiten bei den Tools und Ansätzen, die innerhalb desselben Stacks in einem Unternehmen verwendet werden. Darüber hinaus geografisch in einer Stadt gelegen.
Die Vorteile eines einzigen Ökosystems
Die Bildung eines einzigen Ökosystems kann viele Schwierigkeiten lösen und birgt ein großes Potenzial zur Steigerung der Produktivität eines großen Unternehmens. Tatsächlich stammt diese Praxis aus der Open Source-Community - die besten Lösungen auf ihrem Gebiet überleben und sind am beliebtesten. Jetzt reicht es aus, einen Abhängigkeitsmanager zu öffnen und sich über die Fülle der vorgeschlagenen Lösungen zu wundern. Ein solcher Ansatz kann jedoch im Unternehmen umgesetzt werden. Die Vorteile dieses Ansatzes bei der Implementierung eines neuen Dienstes sind folgende:
- Hohe Stabilität - Die Verwendung von testbedeckten, gut dokumentierten Bibliotheken erhöht die Stabilität des gesamten Dienstes.
- Einfache Rotation von Kollegen zwischen Teams - Wenn sich alle Teams in einem einzigen Ökosystem befinden, muss der Entwickler beim Wechsel von einem Team zu einem anderen nicht viel Zeit damit verbringen, die verwendeten Tools kennenzulernen, da er sie bereits kennt.
- Konzentration auf Geschäftslogik - in der Tat läuft die Entwicklung eines neuen Dienstes darauf hinaus, die notwendigen Abhängigkeiten zu verschärfen, die alle Infrastrukturaufgaben lösen und nur Geschäftslogik schreiben;
- Beschleunigung der Entwicklung - es besteht keine Notwendigkeit zum Radfahren, alles ist bereit, außer Geschäftslogik;
- Vereinfachung des Testens - Es muss nur die Geschäftslogik getestet werden, da die Bibliotheken bereits getestet wurden.
Fliege in die Salbe
Es ist klar, dass zur Erreichung dieses Ansatzes einige Praktiken befolgt werden sollten, nämlich Bibliotheken mit semantischer Versionierung zu entwickeln, sich um Dokumentation und Tests zu kümmern und ci zu konfigurieren. Dies ist eine Art Indikator für die Reife nicht nur des Entwicklungsteams, sondern auch der Entwickler im gesamten Unternehmen.
PS
Der paketorientierte Ansatz besteht nur darin, dass der wiederverwendbare Code auf meinem Stapel als Paket bezeichnet wird. Das klingt lustig. Kürzlich hatte ich einen Dialog mit einem meiner Kollegen, der mich dazu veranlasste, diesen Artikel zu schreiben:
- Kollege: Sie werden in fünf zu einer Kassiererin
- ich: Bedeutung?)
- Kollege: Bald werden Sie fragen: "Benötigen Sie ein Paket?"
- Ich: Bitte öffnen Sie einen Gedanken. Ich verstehe nicht
- Kollege: Nun, zum x-ten Mal haben Sie ein fertiges Paket, um mein Problem zu lösen
Die Sache ist, dass es in unserer Entwicklergemeinschaft innerhalb des Unternehmens ungefähr 20 vorgefertigte Pakete gibt, und die Erstellung eines neuen Dienstes bedeutet, die erforderlichen Abhängigkeiten aufzurufen und Geschäftslogik zu schreiben. Die Kosten für das Binden in Bezug auf das Schreiben von Code sind nahezu ungültig.