Warum wollen wir überhaupt wettbewerbsfähigen Code schreiben? Weil die Prozessoren nicht mehr entlang der Dips wuchsen und entlang der Kerne zu wachsen begannen. Die Anzahl der Prozessorkerne nimmt von Jahr zu Jahr zu und wir möchten sie effektiv nutzen. Go ist die dafür erstellte Sprache. Die Dokumentation sagt es.
Wir nehmen Go und schreiben Wettbewerbscode. Natürlich erwarten wir, dass wir die Leistung jedes Kerns unseres Prozessors problemlos reduzieren können. Ist es so?
Ich heiße Artemy. Dieser Beitrag ist eine kostenlose Abschrift meines Gesprächs mit GopherCon Russia. Es schien ein Versuch zu sein, Menschen Impulse zu geben, die herausfinden wollen, wie man guten, wettbewerbsfähigen Code schreibt.
Video von der GopherCon Russia Konferenz
Interaktionsmodelle
Um zu verstehen, ob Go es uns wirklich einfacher macht, schauen wir uns zwei Interaktionsmodelle an: Shared Memory und Message Passing .

Bei Shared Memory handelt es sich um Shared Memory, den mehrere Threads zum Datenaustausch verwenden. Der Zugriff auf den Speicher muss synchronisiert werden. Diese Synchronisation wird normalerweise durch eine Art von Sperren implementiert. Dieser Ansatz wird als implizite Kommunikation betrachtet.
Message Passing besagt, dass wir explizit interagieren und dafür die Kanäle verwenden, in denen wir Nachrichten senden. Das CSP ( Communicating Sequential Processes ) und das Actor Model basieren auf diesem Ansatz.

Rob Pike , der Gründungsvater von Go, sagt, dass Sie die Low-Level-Programmierung mit Shared Memory aufgeben und den Message Passing- Ansatz verwenden müssen. Dieser Ansatz hilft Ihnen dabei, Code einfacher, effizienter und vor allem mit weniger Fehlern zu schreiben. Go wählt den CSP- Ansatz. Der gleiche Ansatz hat die Entwicklung einer solchen Sprache wie Erlang stark beeinflusst.
Frage: Stimmt es, dass alles in Ordnung ist, wenn wir Go nehmen?

Ich bin auf eine Studie gestoßen, in der diese Tablette gefunden wurde. Das Tablet zeigt die Gründe und die Anzahl der Fehler im Zusammenhang mit Sperren an. Die erste Spalte zeigt die Produkte, die in die Studie aufgenommen wurden. Dies sind die beliebtesten Produkte in Go. In der Spalte Shared Memory wird die Anzahl der Fehler angezeigt, die aufgrund einer nicht ordnungsgemäßen Verwendung des Shared Memory auftreten, und in der Spalte Message Passing wird die Anzahl der Fehler angezeigt, die aufgrund der Weitergabe von Nachrichten auftreten.
Das Wichtigste auf dieser Platte ist die Total- Linie. Wenn Sie es sich ansehen, werden Sie feststellen, dass bei der Verwendung der Nachrichtenübermittlung mehr Fehler auftreten als bei der Verwendung des gemeinsam genutzten Speichers . Ich bin sicher, dass die Leute, die Kubernetes, Docker oder etcd schreiben, ziemlich erfahrene Entwickler sind, aber selbst Message Passing rettet sie nicht vor Fehlern, und diese Fehler sind nicht geringer als bei Shared Memory.
Wenn Sie also einfach Go nehmen und mit dem Schreiben von fehlerfreiem Code beginnen, schlägt dies fehl.
Parallelität und Parallelität
Wenn wir über Multithread-Entwicklung sprechen, müssen wir Konzepte wie Parallelität und Parallelität einführen. In der Welt von Go gibt es den Ausdruck "Parallelität ist keine Parallelität". Das Fazit ist, dass es bei Concurrency um Design geht, also darum, wie wir unser Programm entwerfen. Parallelität ist nur eine Möglichkeit, unseren Code auszuführen.

Wenn wir mehrere Threads von Anweisungen haben, die gleichzeitig ausgeführt werden, führen wir den Code parallel aus. Parallelität erfordert Wettbewerb. Es wird nicht möglich sein, ein Programm ohne ein wettbewerbsfähiges Design zu parallelisieren, während Wettbewerbsfähigkeit keine Parallelität erfordert, da ein Programm, das auf vielen Kernen ausgeführt werden kann, tatsächlich auf einem einzelnen Kern ausgeführt werden kann.
Go ist eine Sprache, die uns hilft, wettbewerbsfähige Programme zu schreiben und Design zu entwickeln. Sie können ein wenig weniger über Dinge auf niedriger Ebene nachdenken.
Amdahls Gesetz
Wir wollen die Prozessorkerne nutzen, wir schreiben dafür einen Code. Es stellt sich jedoch die Frage, welche Art von Produktivitätssteigerung wir mit einer Erhöhung der Anzahl der Kerne erzielen. Die Beschleunigung, die wir bekommen können, ist in der Tat durch das Gesetz von Amdal begrenzt .
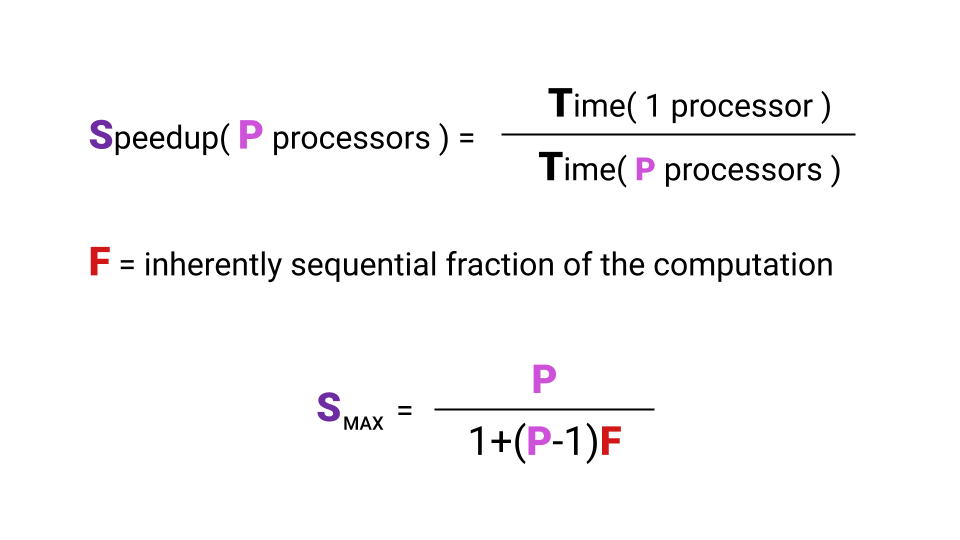
Was ist Beschleunigung? Die Beschleunigung ist die Zeit, die ein Programm auf einem einzelnen Prozessor ausgeführt wird, geteilt durch die Zeit, die ein Programm auf P- Prozessoren ausgeführt wird. Der Buchstabe F ( Bruch ) bezeichnet den Teil des Programms, der nacheinander ausgeführt werden muss. Und hier ist es nicht einmal notwendig, sich mit der Formel zu befassen. Die Hauptsache ist, dass die maximale Beschleunigung, die wir mit einer Erhöhung der Anzahl der Kerne erhalten, von F abhängt . Schauen Sie sich das Diagramm an, um diese Beziehung zu visualisieren.
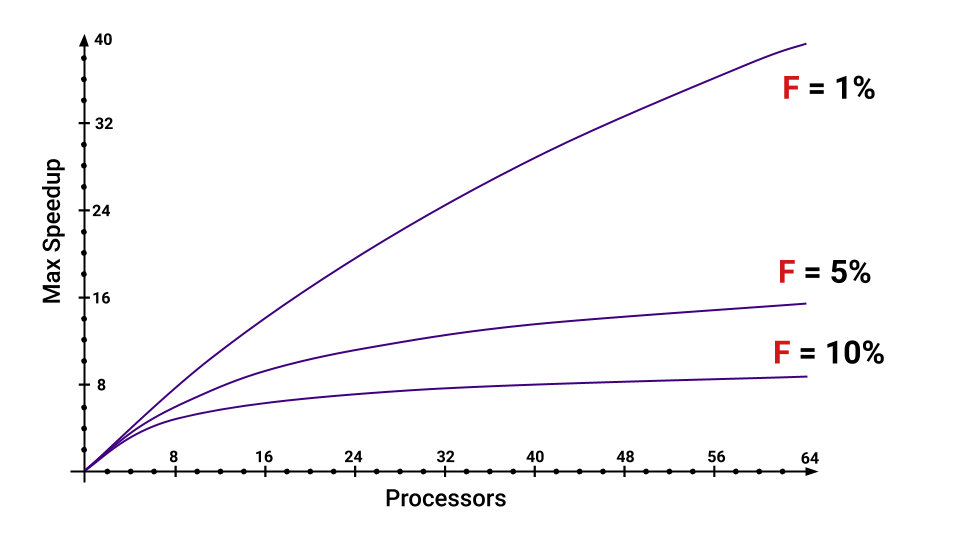
Selbst wenn nur 5% des Programms nacheinander ausgeführt werden müssen, nimmt die maximale Beschleunigung, die wir erhalten, mit zunehmender Anzahl von Kernen stark ab. Sie können schätzen, welche Teile F erhöhen .
CPU Bound vs I / O Bound
Es ist nicht immer sinnvoll, Multithreading zu verwenden. Zuerst müssen Sie sich die Art der Ladung ansehen. Es gibt zwei Arten von Lasten: CPU-gebunden und E / A-gebunden . Der Unterschied besteht darin, dass wir mit CPU Bound durch die Prozessorleistung und mit I / O Bound durch die Geschwindigkeit unseres E / A-Subsystems begrenzt sind. Nicht einmal Geschwindigkeit, sondern Wartezeit auf eine Antwort. Online gehen - auf eine Antwort warten, auf die Festplatte gehen - wieder auf eine Antwort warten. Was ist der Unterschied, wie viele Kerne gibt es, wenn wir die meiste Zeit auf eine Antwort warten?
Daher erhalten wir mit einem Kern oder tausend keine Leistungssteigerung unter der E / A-gebundenen Last. Wenn wir jedoch eine CPU-gebundene Last haben, besteht die Möglichkeit einer Beschleunigung bei der Parallelisierung unseres Programms.
Obwohl es Situationen gibt, in denen die scheinbare CPU-gebundene Last tatsächlich zu einer E / A-Bindung degeneriert. Wenn wir zum Beispiel alle Elemente eines großen Arrays nehmen und summieren wollen, was werden wir dann tun? Wir werden einen Zyklus schreiben, alles wird funktionieren. Dann denken wir: „Wir haben also ein paar Kerne. Nehmen wir es einfach, teilen das Array in Stücke und parallelisieren das Ganze. “ Was wird das Ergebnis sein?
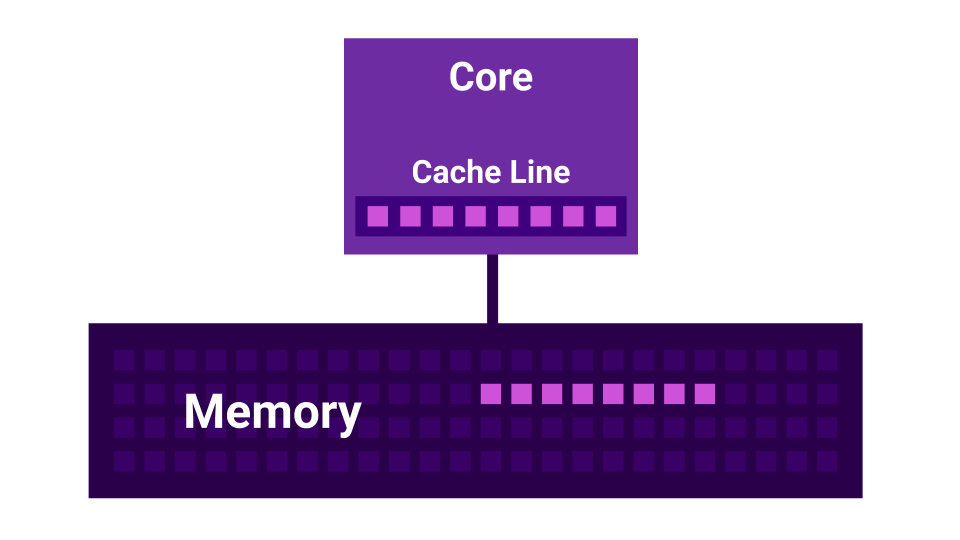
Das Ergebnis ist eine Situation, in der unser Prozessor Daten schneller verarbeitet, als sie aus dem Speicher stammen. In diesem Fall warten wir die meiste Zeit auf Daten aus dem Speicher, und die Last, die CPU-gebunden zu sein schien, stellt sich tatsächlich als E / A-gebunden heraus.
Falsches Teilen
Darüber hinaus gibt es eine Geschichte wie False Sharing . Falsches Teilen ist eine Situation, in der sich die Kernel gegenseitig stören. Es gibt einen ersten Kern, es gibt einen zweiten Kern und jeder von ihnen hat seinen eigenen L1-Cache . Der L1-Cache ist in Zeilen ( Cache-Zeile ) von 64 Byte unterteilt. Wenn wir Daten aus dem Speicher abrufen, erhalten wir immer nicht weniger als 64 Bytes. Durch Ändern dieser Daten deaktivieren wir die Caches aller Kerne.

Es stellt sich heraus, dass zwei Kerne, die Daten sehr nahe beieinander ändern ( in einem Abstand von weniger als 64 Byte ), sich gegenseitig stören und die Caches ungültig machen. In diesem Fall würde das Programm, wenn es nacheinander geschrieben würde, schneller funktionieren als bei Verwendung mehrerer Kerne, die sich gegenseitig stören. Je mehr Kerne vorhanden sind, desto geringer ist die Leistung.
Scheduler
Wir werden zur nächsten Abstraktionsebene aufsteigen - zu den Planern.
Wenn die Arbeit mit einem wettbewerbsfähigen Code beginnt, werden Planer angezeigt. Go hat einen sogenannten User-Space-Scheduler , der auf Goroutinen arbeitet . Das Betriebssystem hat auch einen eigenen Scheduler , der mit Threads des Betriebssystems arbeitet . Und selbst der Prozessor ist nicht so einfach. Zum Beispiel haben moderne Prozessoren Verzweigungsvorhersagen und andere Möglichkeiten, um unser schönes Bild von der Linearisierbarkeit der Welt zu verderben.
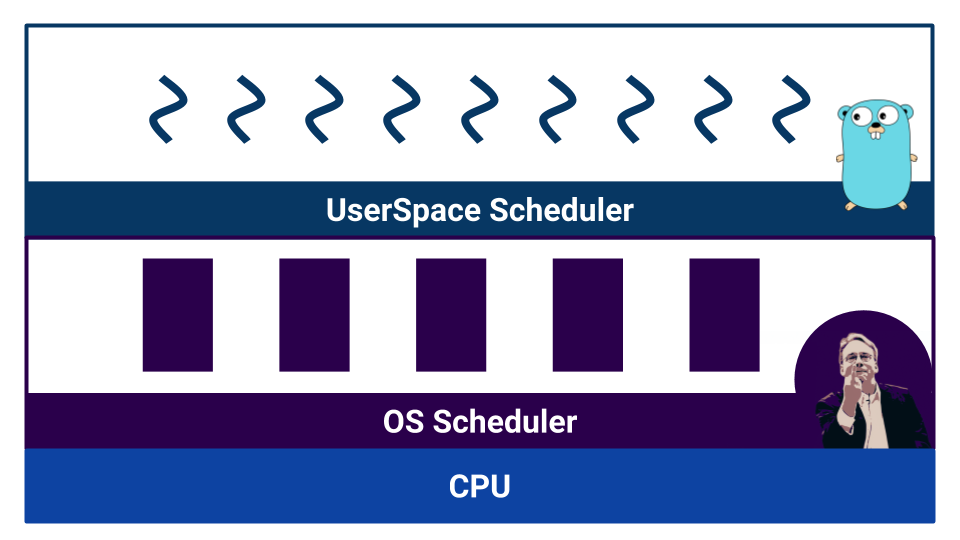
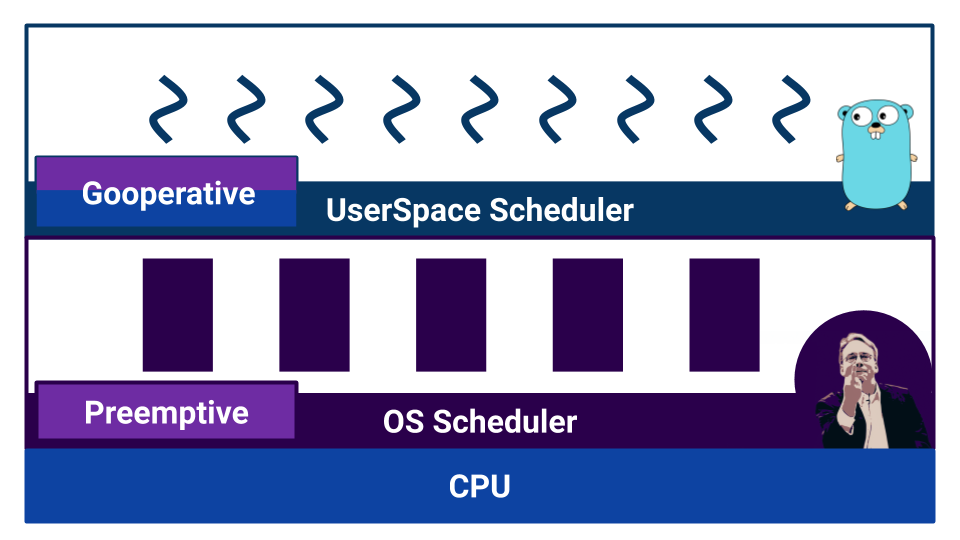
Scheduler sind nach Multitasking-Typen unterteilt. Es gibt kooperatives Multitasking und präventives Multitasking . Beim kooperativen Multitasking entscheidet der ausführende Prozess selbst, wann die Steuerung auf einen anderen Prozess übertragen werden muss, und beim überfüllten Multitasking gibt es einen externen Komponenten- Scheduler, der steuert, wie viel Ressource dem Prozess zugewiesen wird.

Durch kooperatives Multitasking kann ein Prozess die gesamte CPU-Ressource "monopolisieren". Beim präventiven Multitasking wird dies nicht passieren, da es eine Kontrollstelle gibt. Mit kooperativem Multitasking ist die Kontextumschaltung jedoch effizienter, da der Prozess genau weiß, an welchem Punkt es besser ist, einem anderen Prozess die Kontrolle zu geben. Beim präventiven Multitasking kann der Scheduler den Prozess jederzeit stoppen - er ist nicht sehr effizient. Gleichzeitig können wir beim präemptiven Multitasking dank eines externen Schedulers für jeden Prozess dieselbe Ressource bereitstellen.
Das Betriebssystem verwendet einen Scheduler, der auf präemptivem Multitasking basiert, da das Betriebssystem für jeden Benutzer gleiche Bedingungen gewährleisten muss. Was ist mit Go?
Wenn wir die Dokumentation lesen, erfahren wir, dass der Scheduler in Go präventiv ist. Wenn wir jedoch anfangen zu verstehen, stellt sich heraus, dass Go keinen Scheduler als externe Komponente hat. In Go setzt der Compiler Kontextwechselpunkte. Und obwohl wir als Entwickler den Kontext nicht manuell wechseln müssen, wird die Schaltsteuerung nicht auf die externe Komponente übertragen. Dank dessen ist Go sehr effektiv beim Umschalten einer Goroutine auf eine andere. Ein Missverständnis der Merkmale der Arbeit eines solchen "Planers" kann jedoch zu unerwartetem Verhalten führen. Was wird dieser Code beispielsweise ausgeben?

Ein solcher Code friert ein.
Warum? Da wir mit GOMAXPROCS das Programm gezwungen haben, nur einen Kern zu verwenden. Danach wurde Goroutine in die Warteschlange gestellt, in der ein endloser Zyklus funktionieren sollte. Dann warten wir 500 ms und drucken x . Nach der Zeit. time.Sleep Goroutine startet tatsächlich, aber es gibt keinen Ausweg aus der Endlosschleife, da der Compiler den Kontextwechselpunkt nicht setzt. Das Programm friert ein.
Und wenn wir runtime.Gosched() in die Schleife runtime.Gosched() , ist alles in Ordnung, da wir explizit angeben, dass wir den Kontext wechseln möchten.
Solche Funktionen müssen auch kennen und sich merken.
Wir haben über Kontextwechsel gesprochen, aber wo fügt Go normalerweise Schaltpunkte ein?

runtime.morestack() und runtime.newstack() werden normalerweise zum Zeitpunkt des runtime.newstack() der Funktion eingefügt. runtime.Goshed() wir uns selbst versorgen. Und natürlich erfolgt die Kontextumschaltung während Sperren, Netzwerkwanderungen und Systemaufrufen. Sie können sich zu diesem Thema einen Bericht von Kirill Lashkevich ansehen . Sehr gut, rate ich.
Gehen wir dem Code näher. Wir werden uns die Fehler ansehen.
Rennbedingung
Einer der beliebtesten Fehler, den wir machen, ist die Race Condition . Die Quintessenz ist, dass wir, wenn wir zum Beispiel ein Inkrement ausführen, tatsächlich nicht eine Operation ausführen, sondern mehrere: Der Prozessor liest Daten aus dem Speicher in das Register, aktualisiert das Register und schreibt Daten in den Speicher.

Diese drei Operationen werden nicht atomar ausgeführt. Daher kann der Planer bei jeder dieser Operationen jederzeit unseren Fluss nehmen und verdrängen. Es stellt sich heraus, dass die Aktion nicht abgeschlossen ist, und aus diesem Grund fangen wir Fehler.
Hier ist ein Beispiel für einen solchen Code (das Inkrement wird sofort in mehrere Operationen zerlegt ).

Der Scheduler kann den ersten Thread nach Ausführung der ersten Zeile und den zweiten Thread nach Überprüfung der Bedingung vorwegnehmen. In diesem Fall fallen beide Flows in den kritischen Bereich und sind daher „kritisch“ - beide Flows können dort nicht gleichzeitig eingegeben werden.
Wir können mit sync.Mutex aus dem Standard- sync Paket sperren. Durch die Blockierung des Zugriffs können wir explizit angeben, dass Code jeweils von einem Thread ausgeführt werden soll. Mit diesem Code bekommen wir, was wir brauchen.

Schlösser sind eine ziemlich teure Operation. Daher gibt es atomare Operationen auf Prozessorebene. In diesem Fall kann das Inkrement atomar gemacht werden, indem es durch die atomic.AddInt64 Operation aus dem atomic Paket ersetzt wird.
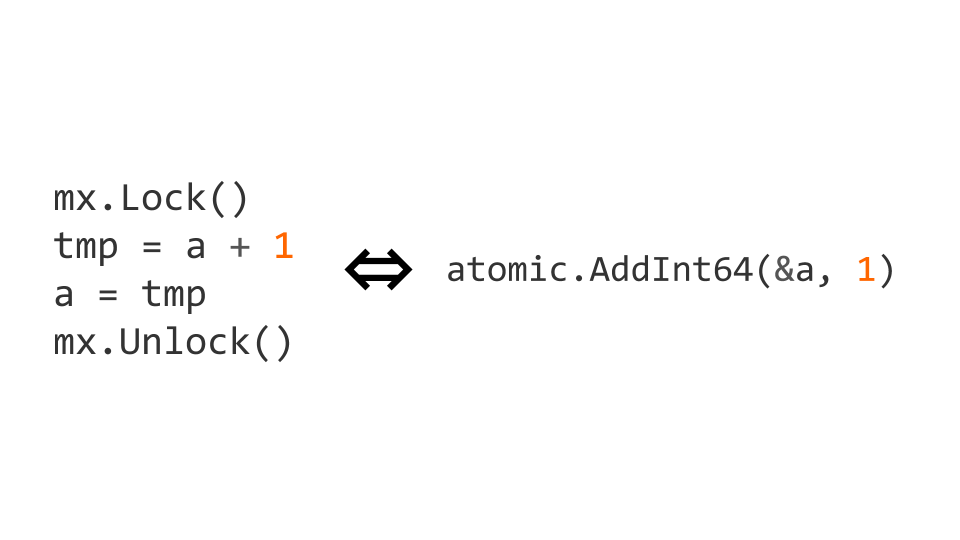
Wenn wir anfangen, mit atomaren Anweisungen zu arbeiten, müssen wir nicht nur atomar schreiben, sondern auch atomar lesen. Wenn wir dies nicht tun, können Probleme auftreten.
Optimierung - Was könnte möglicherweise schief gehen?
Schlösser sind gut, können aber teuer sein. Atomics sind billig genug, um sich keine Sorgen um die Leistung zu machen.
Wir haben also gelernt, dass Synchronisationsprimitive Overhead verursachen, und beschlossen, eine Optimierung hinzuzufügen. Wir werden das Flag ohne Rücksicht auf Multithreading überprüfen und dann mithilfe von Synchronisationsprimitiven überprüfen. Alles sieht gut aus und sollte funktionieren.

Alles ist in Ordnung, außer dass der Compiler versucht, unseren Code zu optimieren. Was macht er? Er tauscht die Zuweisungsanweisungen aus, und wir erhalten ein ungültiges Verhalten, da unser done true wird true bevor der Wert der Variablen "
Versuchen Sie nicht, solche Optimierungen vorzunehmen - aufgrund dieser Probleme treten viele Probleme auf. Ich rate Ihnen, die Spezifikation des Go-Speichermodells und einen Artikel von Dmitry Vyukova ( @dvyukov ) zu lesen. Benigne Datenrennen : Was könnte möglicherweise schief gehen? um die Probleme besser zu verstehen.
Wenn Sie sich wirklich auf die Leistung von Sperren verlassen, schreiben Sie sperrenfreien Code, müssen jedoch keinen nicht synchronisierten Zugriff auf den Speicher ausführen.
Deadlock
Das nächste Problem ist Deadlock. Es mag scheinen, dass hier alles ziemlich trivial ist. Es gibt zwei Ressourcen, zum Beispiel zwei Mutex . Im ersten Thread erfassen wir zuerst den ersten Mutex und im zweiten Thread erfassen wir zuerst den zweiten Mutex . Weiter wollen wir den zweiten Mutex im ersten Thread nehmen, aber wir werden dies nicht tun können, da er bereits blockiert ist. Im zweiten Thread werden wir versuchen, jeweils den ersten Mutex und auch den Block zu nehmen. Da ist er, Deadlock.
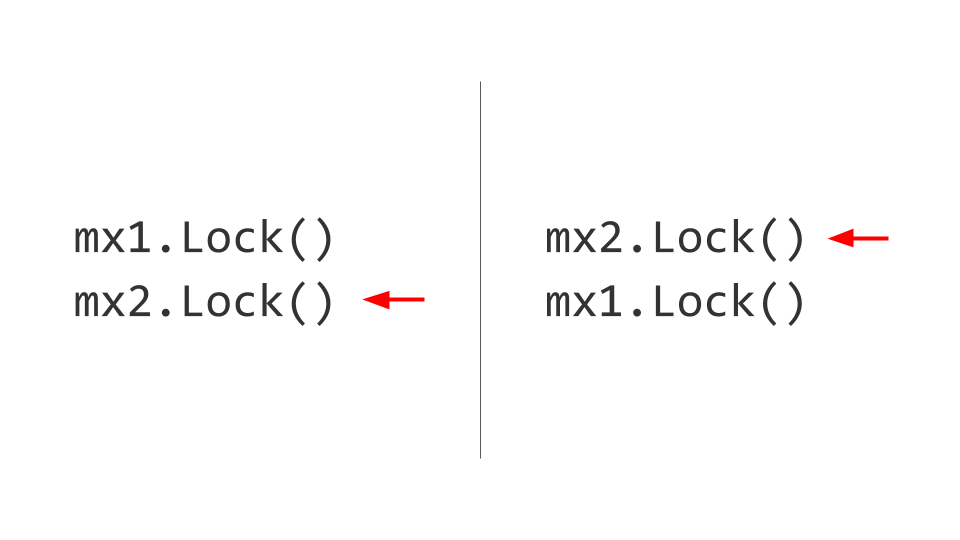
Keiner dieser beiden Threads kann sich weiterentwickeln, da beide auf die Ressource warten. Wie wird das gelöst? Wir tauschen Schlösser aus und dann entstehen keine Probleme. Natürlich ist es leicht zu sagen, aber die Einhaltung dieser Regel während der gesamten Lebensdauer des Produkts ist nicht einfach. Wenn möglich, mach es - nimm und gib die Schlösser in der gleichen Reihenfolge .
Es mag den Anschein haben, dass erfahrene Entwickler nicht auf solche Fehler stoßen, aber hier ist ein Beispiel für einen Deadlock aus dem Projektcode etcd.

Hier ist der Hauptfang, dass das Schreiben in einen ungepufferten Kanal blockiert; zum Schreiben benötigen Sie dagegen einen Leser. Mit dem Mutex wartet der erste Thread darauf, dass der Leser erscheint. Der zweite Thread kann den Mutex nicht mehr erfassen. Deadlock
Ich rate Ihnen, das aufregende Spiel The Deadlock Empire auszuprobieren. In diesem Spiel fungieren Sie als Scheduler, der den Kontext wechseln muss, um zu verhindern, dass der Code korrekt ausgeführt wird.
Art von Problemen
Welche Probleme gibt es noch? Wir haben mit den Rennbedingungen begonnen . Als nächstes haben wir uns Deadlock angesehen (es gibt immer noch eine Variante von Livelock . In diesem Fall können wir die Ressource nicht erfassen, aber es gibt keine expliziten Sperren). Es gibt Hunger , wenn wir zum Drucker gehen, um ein Stück Papier zu drucken, und es gibt eine Warteschlange, und wir können nicht auf die Ressource zugreifen. Wir haben uns das Verhalten des Programms mit False Sharing angesehen . Es gibt immer noch ein Problem - Lock Contention , wenn sich die Leistung aufgrund des starken Wettbewerbs um eine Ressource verschlechtert (z. B. ein Mutex, den eine große Anzahl von Threads benötigt).

Rennerkennung
Go ist leistungsstark mit der sofort bereitgestellten Toolbox. Race Detector ist ein solches Tool. Die Verwendung ist einfach: Wir schreiben Tests oder führen sie mit einer Kampflast aus und fangen Fehler ab.
Weitere Informationen zur Verwendung des Race Detector finden Sie in der Dokumentation . Beachten Sie jedoch, dass er Einschränkungen aufweist. Lassen Sie uns näher darauf eingehen.

Erstens wird der Code, der nicht ausgeführt wurde, nicht vom Race Detector überprüft. Daher sollte die Testabdeckung hoch sein. Darüber hinaus merkt sich der Race Detector den Verlauf von Anrufen für jedes Wort im Speicher, aber dieser Verlauf von Anrufen hat Tiefe. In Go beträgt diese Tiefe beispielsweise vier - vier Elemente, vier Zugriffe. Wenn der Race Detector kein Rennen in dieser Tiefe gefangen hat, glaubt er, dass es kein Rennen gibt. Obwohl der Race Detector niemals falsch ist, werden daher nicht alle Fehler abgefangen. Sie können auf den Race Detector hoffen, müssen sich aber an seine Grenzen erinnern. Separat können Sie über den Arbeitsalgorithmus lesen.
Blockprofil
Das Blockprofil ist ein weiteres Tool, mit dem wir Blockierungsprobleme finden und beheben können.

Es kann sowohl auf der Benchmark-Testebene als auch während der Kampflast verwendet werden. Wenn Sie nach Problemen im Zusammenhang mit der Datenzugriffssynchronisierung suchen, starten Sie den Race Detector und verwenden Sie das Blockprofil weiter.
Programmbeispiel
Schauen wir uns den echten Code an, über den wir stolpern können. Wir werden eine Funktion schreiben, die einfach ein Array von Anforderungen aufnimmt und versucht, sie auszuführen: jede Anforderung nacheinander. Wenn eine der Anforderungen einen Fehler zurückgibt, beendet die Funktion die Ausführung.

Wenn wir in Go schreiben, müssen wir die volle Kraft der Sprache nutzen. Wir versuchen es. Wir bekommen dreimal so viel Code.

Frage: Gibt es Fehler im Code?
Natürlich! Schauen wir uns welche an.
In der Schleife führen wir Goroutinen aus. Für die Goroutine-Orchestrierung verwenden wir sync.WaitGroup . Aber was machen wir falsch? Bereits in der laufenden Goroutine rufen wir wg.Add(1) , d. H. Wir fügen eine weitere Goroutine hinzu, um zu warten. Und mit wg.Wait() warten wir darauf, dass alle Goroutinen abgeschlossen sind. Es kann jedoch vorkommen, dass zum Zeitpunkt des wg.Wait() von wg.Wait() keine einzige Goroutine startet. In diesem Fall wird wg.Wait() berücksichtigen, dass alles erledigt ist. Wir werden den Kanal schließen und die Funktion fehlerfrei wg.Wait() , da wir glauben, dass alles in Ordnung ist.

Was wird als nächstes passieren? Dann starten die Goroutinen, der Code wird ausgeführt, und möglicherweise gibt eine der Anforderungen einen Fehler zurück. Ein Fehler wird in einen geschlossenen Kanal geschrieben, und das Schreiben in einen geschlossenen Kanal ist eine Panik. Unsere Anwendung wird abstürzen. Es ist unwahrscheinlich, dass ich das bekommen wollte, also korrigieren wir es, indem wir im Voraus angeben, wie viele Goroutinen wir starten werden.

Vielleicht gibt es noch einige Probleme?
Es liegt ein Fehler im Zusammenhang mit der req des req Objekts in der Funktion vor. Die Variable req fungiert als Iterator des Zyklus, und wir wissen nicht, welchen Wert sie zum Zeitpunkt des Starts der Goroutine haben wird.

In der Praxis entspricht der req in diesem Code höchstwahrscheinlich dem letzten Element des Arrays. Daher senden Sie dieselbe Anfrage nur N-mal. Fix: Übergeben Sie unsere Anfrage explizit als Argument an die Funktion.

Schauen wir uns genauer an, wie wir mit Fehlern umgehen. Wir deklarieren einen gepufferten Kanal in einem Slot. Wenn ein Fehler auftritt, senden wir ihn an diesen Kanal. Alles scheint in Ordnung zu sein: Ein Fehler ist aufgetreten - wir haben diesen Fehler von einer Funktion zurückgegeben.

Was aber, wenn alle Anfragen mit einem Fehler zurückgegeben werden?
Dann wird beim Schreiben in den Kanal nur der erste Fehler angezeigt, der Rest blockiert die Ausführung von Goroutinen. Da bis zum Beenden der Funktion keine Messwerte mehr vom Kanal angezeigt werden, tritt ein Goroutine-Leck auf. Das heißt, all jene Gorutins, die den Fehler nicht in den Kanal schreiben konnten, hängen einfach im Speicher.
Wir beheben das ganz einfach: Wir wählen im Slot-Kanal die Anzahl der Anfragen aus. Dies löst unser Problem nicht sehr speichereffizient, denn wenn wir eine Milliarde Anfragen haben, müssen wir eine Milliarde Slots zuweisen.

Wir haben die Probleme gelöst. Der Code ist jetzt wettbewerbsfähig. Das Problem liegt jedoch in der Lesbarkeit - im Vergleich zur synchronen Version des Codes gibt es viele. Und das ist nicht cool, weil die Entwicklung wettbewerbsfähiger Programme bereits schwierig ist. Warum komplizieren wir sie mit viel Code?

Errgroup
Ich schlage vor, die Lesbarkeit des Codes zu verbessern.
Ich verwende gerne das Errgroup- Paket anstelle von sync.WaitGroup . In diesem Paket muss nicht angegeben werden, wie viele Goroutinen zu erwarten sind, und Sie können die Fehlersammlung ignorieren. So sieht unsere Funktion bei Verwendung von errgroup :

Darüber errgroup können errgroup mit errgroup die Komponenten unseres Programms bequem mit context.Context orchestrieren . Was meine ich
Angenommen, wir haben mehrere Komponenten unseres Programms. Wenn mindestens eine davon fehlschlägt, möchten wir alle anderen sorgfältig abschließen. Wenn also ein Fehler errgroup , vervollständigt errgroup den context und somit erhalten alle Komponenten eine Benachrichtigung über die Notwendigkeit, die Arbeit abzuschließen.

Dies kann verwendet werden, um komplexe Mehrkomponentenprogramme zu erstellen, die sich vorhersehbar verhalten.
Schlussfolgerungen
Mach es so einfach wie möglich. Besser synchron. Die Entwicklung von Multithread-Programmen ist im Allgemeinen ein komplexer Prozess, der zum Auftreten unangenehmer Fehler führt.

Verwenden Sie keine implizite Synchronisation. Wenn Sie sich wirklich darin ausgeruht haben, überlegen Sie, wie Sie Sperren entfernen und einen sperrenfreien Algorithmus erstellen können.
Go ist eine gute Sprache zum Schreiben von Programmen, die effektiv mit einer großen Anzahl von Kernen arbeiten. Sie ist jedoch nicht besser als alle anderen Sprachen, und es treten immer Fehler auf. Versuchen Sie daher, auch mit Go bewaffnet, mehrere Abstraktionsebenen zu verstehen, die niedriger sind als Ihre Arbeit.
