Wir stellen Ihnen den zweiten Teil der Übersetzung des Materials zum Kampf des gitlab.com-Teams gegen die Tyrannei der Zeit vor.

→ Hier ist übrigens der
erste Teil .
Verarbeitungsgeschwindigkeitsbegrenzung anfordern
Zu diesem Zeitpunkt waren wir nicht daran interessiert, die Werte des
MaxStartups Parameters einfach zu erhöhen. Obwohl sich eine 50% ige Erhöhung dieses Parameters als gut erwies, schien seine weitere Erhöhung ohne ausreichenden Grund eine ziemlich grobe Lösung des Problems zu sein. Sicherlich konnten wir noch etwas anderes tun.
Die Suche brachte mich auf die HAProxy-Ebene, die sich vor den SSH-Servern befand. HAProxy hat eine nette Option für
rate-limit sessions Ratenbegrenzung, die sich auf den Teil des Systems auswirkt, der eingehende Anforderungen akzeptiert. Wenn diese Option konfiguriert ist, wird sie verwendet, um die Anzahl neuer TCP-Anforderungen pro Sekunde zu begrenzen, die das Frontend an die Backends sendet, während zusätzliche eingehende Verbindungen zum TCP-Socket verbleiben. Wenn die Geschwindigkeit eingehender Anforderungen den Grenzwert überschreitet (jede Millisekunde änderbar), werden neue Verbindungen einfach verzögert. Der TCP-Client (in diesem Fall SSH) sieht einfach die Verzögerung, bevor eine TCP-Verbindung hergestellt wird. Dies ist meiner Meinung nach ein sehr schöner Schachzug. Bis die Geschwindigkeit, mit der Anfragen über einen zu langen Zeitraum empfangen werden, den Grenzwert zu stark überschreitet, funktioniert das System einwandfrei.
Die nächste Frage war die Auswahl des Werts der Option für
rate-limit sessions , die wir verwenden sollten. Die Beantwortung dieser Frage wurde durch die Tatsache erschwert, dass wir 27 SSH-Backends und 18 HAProxy-Frontends (16 Haupt- und 2 Alt-SSH) haben, sowie durch die Tatsache, dass die Frontends hinsichtlich der Geschwindigkeit der Anforderungsverarbeitung nicht miteinander koordinieren . Außerdem mussten wir berücksichtigen, wie lange der Authentifizierungsschritt der neuen SSH-Sitzung dauert. Angenommen, der erste Wert von
MaxStartups ist 150. Wenn die Authentifizierungsphase zwei Sekunden dauert, können wir für jedes Backend nur 75 neue Sitzungen pro Sekunde übertragen.
Hier finden Sie Details zur Berechnung des Werts von
rate-limit sessions . Ich werde hier nicht auf Details eingehen. Ich stelle nur fest, dass zur Berechnung dieses Wertes vier Parameter berücksichtigt werden müssen. Der erste und der zweite sind die Anzahl der Server beider Typen. Der dritte ist der Wert von
MaxStartups . Der vierte ist
T - wie lange dauert die Authentifizierung einer SSH-Sitzung? Der Wert von
T äußerst wichtig, kann jedoch nur annähernd abgeleitet werden. Wir haben genau das getan und das Ergebnis bei 2 Sekunden belassen. Als Ergebnis haben wir den
rate-limit für die Frontends erhalten, der 112,5 betrug. Wir haben es auf 110 gerundet.
Und jetzt wurden die neuen Einstellungen wirksam. Vielleicht denkst du, dass danach alles glücklich endete? Es muss gewesen sein, dass die Anzahl der Fehler auf Null gestiegen ist und alle um uns herum sehr glücklich waren? Nun, eigentlich war es alles andere als gut. Diese Änderung führte zu keinen sichtbaren Änderungen der Fehlerrate. Ehrlich gesagt war ich ziemlich verärgert. Wir haben etwas Wichtiges übersehen oder die Essenz des Problems missverstanden.
Infolgedessen kehrten wir zu den Protokollen (und schließlich zu den HAProxy-Informationen) zurück und konnten sicherstellen, dass die Geschwindigkeitsbegrenzung für die Abfrageverarbeitung zumindest funktioniert, indem wir wie erwartet auf die Abfragen reagierten. Zuvor waren die entsprechenden Indikatoren höher, sodass wir den Schluss ziehen konnten, dass wir die Geschwindigkeit, mit der eingehende Anforderungen zur Verarbeitung gesendet werden, erfolgreich begrenzt haben. Es war jedoch klar, dass die Rate, mit der die Anfragen eintrafen, immer noch zu hoch war. Obwohl auch klar war, dass es nicht einmal an diese Werte heranrückte, wenn es spürbare Auswirkungen auf das System haben könnte. Als wir den Prozess der Auswahl von Backends (gemäß den HAProxy-Protokollen) analysierten, stellten wir dort eine Verrücktheit fest. Zu Beginn der Stunde waren die Backend-Verbindungen ungleichmäßig auf die SSH-Server verteilt. In dem für die Analyse ausgewählten Zeitintervall variierte die Anzahl der Verbindungen pro Sekunde auf verschiedenen Servern zwischen 30 und 121. Dies bedeutete, dass unser Lastausgleich seine Aufgabe nicht gut erledigte. Die Analyse der Konfiguration ergab, dass wir die Option
balance source , sodass ein Client mit einer bestimmten IP-Adresse immer mit demselben Backend verbunden ist. Dies kann als positives Phänomen in Fällen angesehen werden, in denen eine Sitzungsbindung erforderlich ist. Aber wir haben es mit SSH zu tun, also brauchen wir das nicht. Diese Option wurde einmal von uns konfiguriert, aber wir haben keine Hinweise gefunden, warum dies getan wurde. Wir konnten keinen würdigen Grund finden, es weiter zu verwenden. Aus diesem Grund haben wir uns entschlossen, auf
leastconn . Dank dieser Option bieten neue eingehende Verbindungen Backends mit der minimalen Anzahl aktueller Verbindungen. Dies wirkte sich auf die Verwendung von Prozessorressourcen durch unsere SSH (Git) -Server aus. Hier ist der entsprechende Zeitplan.
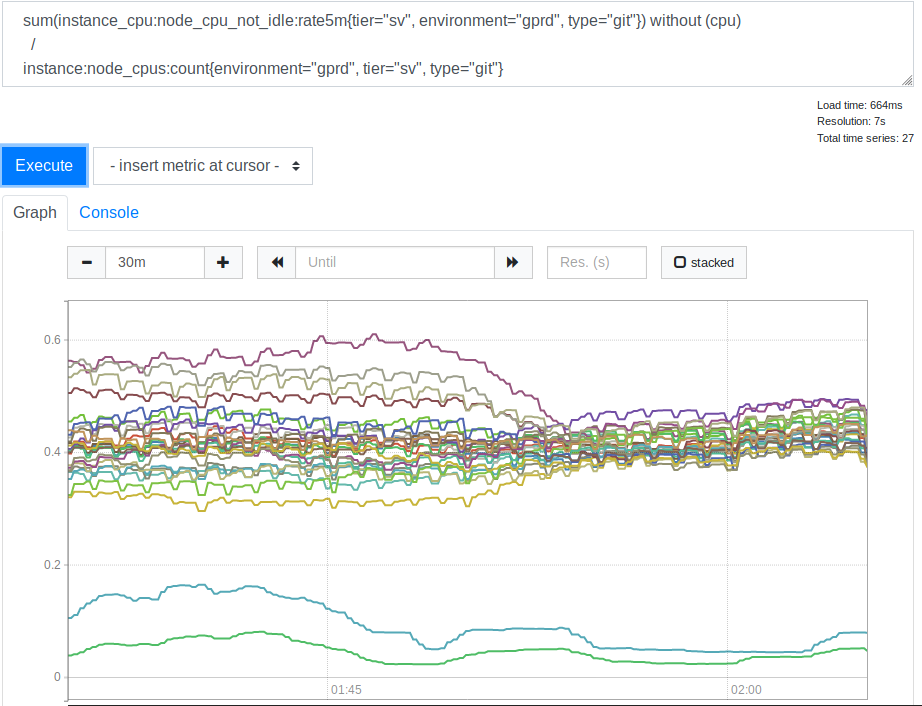 CPU-Verbrauch durch Server vor und nach Anwendung der Option "Leastconn"
CPU-Verbrauch durch Server vor und nach Anwendung der Option "Leastconn"Nachdem wir dies gesehen hatten, stellten wir fest, dass die Verwendung von
leastconn eine gute Idee ist. Die beiden Linien am unteren Rand des Diagramms sind unsere kanarischen Server. Sie können sie ignorieren. Zuvor wurde die Verteilung der CPU-Lastwerte für verschiedene Server jedoch mit 2: 1 (von 30% auf 60%) korreliert. Dies zeigte deutlich, dass einige unserer Backends früher aufgrund der Verbindung von Clients mehr als andere geladen wurden. Es war eine Überraschung für mich. Es schien zu erwarten, dass ein breiter Bereich von Client-IP-Adressen ausreichte, um unsere Server viel gleichmäßiger zu laden. Um jedoch die Serverlastindikatoren zu verzerren, reichten anscheinend mehrere große Clients aus, deren Verhalten sich von einer durchschnittlichen Option unterscheidet.
Lektion Nummer 4. Wenn Sie bestimmte Einstellungen auswählen, die von den Standardeinstellungen abweichen, kommentieren Sie diese oder hinterlassen Sie einen Link zu den Materialien, in denen die Änderungen erläutert werden. Jeder, der sich in Zukunft mit diesen Einstellungen befassen muss, wird Ihnen dafür dankbar sein.
Diese Transparenz ist
einer der Grundwerte von GitLab .
Durch Aktivieren der Option "
leastconn " konnten auch die Fehlerquoten reduziert werden. Und genau das haben wir angestrebt. Aus diesem Grund haben wir uns entschlossen, diese Option zu verlassen. Während sie weiter experimentierten, reduzierten sie die Geschwindigkeitsbegrenzungen für die Anforderungsverarbeitung auf 100, was dazu beitrug, die Fehlerquote weiter zu reduzieren. Dies zeigte an, dass die anfängliche Auswahl des Wertes von
T wahrscheinlich falsch durchgeführt wurde. Wenn ja, war dieser Indikator zu klein, was zu einem zu starken Tempolimit führte, und sogar 100 Anfragen pro Sekunde wurden als sehr niedriger Wert angesehen, und wir waren nicht bereit, ihn weiter zu reduzieren. Leider waren diese beiden Änderungen aus irgendeinem internen Grund nur ein Experiment. Wir mussten wieder die Option
balance source und die Verarbeitungsgeschwindigkeit von Anforderungen auf 100 Anforderungen pro Sekunde begrenzen.
Da die Verarbeitungsgeschwindigkeit für Abfragen auf ein für uns
leastconn niedriges Niveau eingestellt wurde und wir
leastconn nicht verwenden
leastconn , haben wir versucht, den Parameter
MaxStartups zu erhöhen. Zuerst haben wir es auf 200 erhöht, dies ergab einen gewissen Effekt. Dann - bis zu 250. Fehler sind fast vollständig verschwunden und nichts Schlimmes ist passiert.
Lektion Nummer 5. Hohe MaxStartups sehen zwar einschüchternd aus, haben jedoch nur geringe Auswirkungen auf die Leistung, selbst wenn sie viel höher als die Standardwerte sind.
Vielleicht ist dies so etwas wie ein großer und leistungsfähiger Hebel, den wir bei Bedarf in Zukunft verwenden können. Vielleicht werden wir auf Probleme stoßen, wenn wir über Zahlen in der Größenordnung von mehreren Tausend oder mehreren Zehntausend sprechen, aber davon sind wir noch weit entfernt.
Was sagt dies über meine Schätzungen des
T Parameters aus, wie lange es dauert, eine SSH-Sitzung zu installieren und zu authentifizieren? Wenn Sie mit der Formel zur Berechnung der Geschwindigkeitsbegrenzungsanzeige für die Verbindungsverarbeitung arbeiten und wissen, dass 200 für die
MaxStartups Anzeige nicht ausreicht und 250 ausreicht, können Sie feststellen, dass
T wahrscheinlich einen Wert zwischen 2,7 und 3,4 Sekunden hat. Infolgedessen war ein geschätzter Wert von 2 Sekunden nicht weit von der Wahrheit entfernt, aber der tatsächliche Wert war natürlich höher als erwartet. Wir werden etwas später darauf zurückkommen.
Letzte Schritte
Wir haben uns die Protokolle noch einmal angesehen und dabei berücksichtigt, was wir bereits wussten, und nach einiger Überlegung herausgefunden, dass das Problem, mit dem alles begann, durch die folgenden Zeichen identifiziert werden kann. Erstens ist dies ein
t_state Wert gleich
SD . Zweitens ist dies der Wert von
b_read (vom Client gelesene Bytes) gleich 0. Wie bereits erwähnt, verarbeiten wir ungefähr
b_read bis 28 Millionen SSH-Verbindungen pro Tag. Es war unangenehm zu erfahren, dass mitten in der Katastrophe ungefähr 1,5% dieser Verbindungen grob unterbrochen waren. Offensichtlich war das Ausmaß des Problems viel größer als wir am Anfang dachten. Gleichzeitig gab es nichts, was wir früher nicht erkennen konnten (selbst als wir feststellten, dass
t_state="SD" das Problem in den Protokollen anzeigte), aber wir haben nicht darüber
t_state="SD" , wie dies zu tun ist, obwohl wir und du solltest darüber nachdenken. Wahrscheinlich haben wir deshalb viel mehr Zeit und Mühe darauf verwendet, das Problem zu lösen, als wir hätten aufwenden können.
Lektion Nummer 6. Messen Sie die tatsächlichen Fehlerwerte so früh wie möglich.
Wenn wir uns zunächst des Ausmaßes des Problems bewusst wären, könnten wir ihm mehr Aufmerksamkeit schenken. Wie man es wahrnimmt, hängt jedoch immer noch von der Kenntnis der Merkmale ab, die es uns ermöglichen, die Probleme zu beschreiben.
Wenn wir über die Vorteile sprechen, die sich ergeben haben, nachdem wir die Werte von
MaxStartups und die Geschwindigkeit der Verarbeitungsanforderungen
MaxStartups , können wir sagen, dass die Fehlerquote auf 0,001% gesunken ist. Das heißt - bis zu mehreren tausend pro Tag. Diese Situation sah viel besser aus, aber eine ähnliche Fehlerquote war immer noch höher als die, die wir erreichen möchten. Nachdem wir einige Dinge herausgefunden hatten, konnten wir wieder die Option "
leastconn " verwenden und die Fehler verschwanden vollständig. Danach konnten wir erleichtert aufatmen.
Zukünftige Arbeit
Offensichtlich nimmt die SSH-Authentifizierungsphase noch viel Zeit in Anspruch. Vielleicht bis zu 3,4 Sekunden. GitLab kann
AuthorizedKeysCommand verwenden, um direkt nach einem SSH-Schlüssel in einer Datenbank zu suchen. Dies ist sehr wichtig für schnelle Vorgänge, wenn eine große Anzahl von Benutzern vorhanden ist. Andernfalls muss SSHD nacheinander eine sehr große Datei "
authorized_keys lesen, um den öffentlichen Schlüssel des Benutzers zu finden. Diese Aufgabe lässt sich nicht gut skalieren. Wir haben eine Suche mit einer bestimmten Menge Ruby-Code implementiert, die Aufrufe einer externen HTTP-API ausführt.
Stan Hugh , der Leiter unserer technischen Abteilung und eine unerschöpfliche Wissensquelle über GitLab, stellte fest, dass Unicorn-Instanzen von Git / SSH-Servern aufgrund von Anfragen an sie ständig belastet werden. Dies könnte einen wesentlichen Beitrag zu den drei Sekunden leisten, die zur Authentifizierung von Anforderungen erforderlich sind. Infolgedessen haben wir erkannt, dass wir dieses Problem in Zukunft untersuchen sollten. Vielleicht erhöhen wir die Anzahl der Unicorn- (oder Puma-) Instanzen auf diesen Knoten, damit SSH-Server nicht warten müssen, um auf sie zuzugreifen. Da hier jedoch ein gewisses Risiko besteht, müssen wir vorsichtig sein und auf die Erfassung und Analyse von Systemindikatoren achten. Die Arbeit an der Produktivität geht weiter, aber jetzt, nachdem das Hauptproblem gelöst ist, geht es langsamer voran. Möglicherweise können wir den Wert von
MaxStartups reduzieren, aber da sein hohes Niveau nicht die negativen Auswirkungen auf das System hat, die es zu erzeugen scheint, ist dies nicht besonders notwendig. Es wird für alle viel einfacher zu leben sein, wenn OpenSSH uns jederzeit mitteilen kann, wie nahe wir den Grenzen von
MaxStartups . Es wird besser sein, wenn wir immer Bescheid wissen können. Dies ist viel schöner als zu lernen, dass die Grenzen bei unterbrochenen Verbindungen überschritten werden.
Darüber hinaus benötigen wir eine Art Benachrichtigungssystem, wenn HAProxy-Protokolleinträge angezeigt werden, die auf ein Problem mit getrennten Verbindungen hinweisen. Tatsache ist, dass dies in der Praxis überhaupt nicht passieren sollte. Wenn dies erneut geschieht, müssen wir die
MaxStartups Werte weiter erhöhen, oder wenn uns Ressourcen fehlen, müssen wir dem System weitere Git / SSH-Knoten hinzufügen.
Zusammenfassung
Teile komplexer Systeme interagieren in komplexen Mustern. Und um verschiedene Probleme zu lösen, findet man in ihnen oft weit entfernt von einem "Hebel". Im Umgang mit solchen Systemen ist es hilfreich, die darin enthaltenen Tools zu kennen. Tatsache ist, dass sie alle ihre Vor- und Nachteile haben. Darüber hinaus sollte beachtet werden, dass es riskant sein kann, bestimmte Einstellungen basierend auf Annahmen und geschätzten Werten vorzunehmen. Wenn ich nun den Weg betrachte, den wir zurückgelegt haben, würde ich versuchen, die Zeit, die erforderlich ist, um die Authentifizierung der Anfrage abzuschließen, so genau wie möglich zu messen, was dazu führen würde, dass der ungefähre Wert von
T , den ich abgeleitet habe, näher an der Wahrheit liegt.
Die wichtigste Lektion, die wir daraus gelernt haben, ist jedoch, dass wenn viele Leute Aufgaben auf der Grundlage einiger netter Zeitmetriken planen, dies für zentralisierte Dienstanbieter wie GitLab zu wirklich ungewöhnlichen Skalierungsproblemen führt.
Wenn Sie zu denjenigen gehören, die die geplanten Tools zum Starten von Aufgaben verwenden, müssen Sie möglicherweise die Zeit für das Starten Ihrer Aufgaben auf eine neue Weise festlegen. Sie können beispielsweise festlegen, dass die Aufgaben für eine Weile „einschlafen“ und erst 30 Sekunden nach dem Start richtig funktionieren. Sie können beispielsweise im Zeitplan für den Start der Aufgabe zufällige Zeiten innerhalb einer Stunde angeben (hier können Sie eine zufällige Wartezeit vor der tatsächlichen Ausführung der Aufgabe hinzufügen). Dies wird uns allen im Kampf gegen die Tyrannei der Uhren helfen.
Liebe Leser! Sind Sie auf ähnliche Probleme gestoßen wie die, deren Geschichte dieses Material gewidmet ist?
