Das Material, dessen erster Teil der Übersetzung wir heute veröffentlichen, ist einem großen Problem gewidmet, das bei gitlab.com aufgetreten ist. Hier werden wir darüber sprechen, wie sie sie gefunden haben, wie sie mit ihr gekämpft haben und wie sie sie schließlich gelöst haben. Angesichts dieses Problems fand das Team von gitlab.com heraus, was die Tyrannei der Uhren ist.

→
Der zweite Teil .
Das Problem
Wir haben angefangen, Nachrichten von Clients zu erhalten, die bei der Arbeit mit gitlab.com regelmäßig auf Fehler bei der Ausführung von Pull-Anforderungen stoßen. Fehler traten normalerweise bei der Ausführung von CI-Aufgaben oder beim Betrieb anderer ähnlicher automatisierter Systeme auf. Die Fehlermeldungen sahen ungefähr so aus:
ssh_exchange_identification: connection closed by remote host fatal: Could not read from remote repository
Die Situation wurde durch die Tatsache weiter erschwert, dass Fehlermeldungen unregelmäßig und, wie es schien, unvorhersehbar erschienen. Wir konnten sie nicht nach Belieben reproduzieren, konnten keine offensichtlichen Anzeichen dafür erkennen, was in den Diagrammen oder in den Protokollen geschah. Die Fehlermeldungen selbst brachten ebenfalls keinen großen Nutzen. Der SSH-Client wurde darüber informiert, dass die Verbindung unterbrochen wurde. Der Grund dafür kann jedoch alles sein: ein ausgefallener Client oder eine instabile virtuelle Maschine, eine Firewall, die wir nicht steuern, seltsame Provideraktionen oder ein Problem mit unserer Anwendung.
Wir arbeiten am GIT-over-SSH-Programm und haben es mit einer sehr großen Anzahl von Verbindungen zu tun - etwa 26 Millionen pro Tag. Dies sind durchschnittlich 300 Verbindungen pro Sekunde. Daher versprach der Versuch, eine kleine Anzahl fehlgeschlagener Verbindungen aus dem vorhandenen Datenstrom auszuwählen, eine schwierige Aufgabe. Das Gute an dieser Situation war, dass wir gerne komplexe Probleme lösen.
Erster Hinweis
Wir haben einen unserer Kunden kontaktiert (danke an Hubert Holtz von Atalanda), der mehrmals am Tag auf ein Problem gestoßen ist. Dies gab uns einen Halt. Hubert konnte uns eine geeignete öffentliche IP-Adresse zur Verfügung stellen. Dies bedeutete, dass wir Pakete auf unseren HAProxy-Front-End-Knoten erfassen konnten, um zu versuchen, das Problem zu isolieren, indem wir uns auf ein Dataset stützten, das kleiner ist als der sogenannte „gesamte SSH-Verkehr“. Noch besser war, dass das Unternehmen einen
alternativen SSH-Port verwendete . Dies bedeutete, dass wir den Stand der Dinge nur auf zwei HAProxy-Servern und nicht auf sechzehn analysieren mussten.
Die Analyse der Pakete hat jedoch keinen besonderen Spaß gemacht. Trotz Einschränkungen in ungefähr 6,5 Stunden wurden ungefähr 500 MB Pakete gesammelt. Wir fanden kurzlebige Verbindungen. Die TCP-Verbindung wurde hergestellt, der Client hat die Kennung gesendet, wonach unser HAProxy-Server sofort die Verbindung mit der richtigen TCP-FIN-Sequenz getrennt hat. Als Ergebnis hatten wir den ersten ausgezeichneten Hinweis zur Verfügung. Sie erlaubte uns zu dem Schluss zu kommen, dass die Verbindung auf Initiative von gitlab.com definitiv geschlossen wurde und nicht wegen etwas zwischen uns und dem Kunden. Dies bedeutete, dass wir mit einem Problem konfrontiert waren, das wir untersuchen und korrigieren können.
Lektion Nummer 1. Das Statistik-Menü des Wireshark-Tools enthält eine Menge nützlicher Tools, denen ich vor diesem Fall nicht viel Aufmerksamkeit geschenkt habe.
Insbesondere handelt es sich um den Menüpunkt
Conversations , der grundlegende Informationen zu erfassten Daten zu TCP-Verbindungen enthalten kann. Es gibt Informationen über Zeit, Pakete, Bytes. Die im entsprechenden Fenster angezeigten Daten können sortiert werden. Ich sollte dieses Tool von Anfang an verwenden, anstatt manuell mit den erfassten Daten herumzuspielen. Dann wurde mir klar, dass ich nach Verbindungen mit einer kleinen Anzahl von Paketen suchen musste. Im
Conversations konnten Sie sofort darauf achten. Danach konnte ich andere ähnliche Verbindungen finden und sicherstellen, dass die erste derartige Verbindung kein abnormales Phänomen war.
Log Immersion
Was hat dazu geführt, dass HAProxy die Verbindung zum Client getrennt hat? Der Server tat dies natürlich nicht auf willkürliche Weise, was geschah, hätte einen tieferen Grund haben müssen; wenn du magst - "eine andere Stufe von
Schildkröten ." Es bestand das Gefühl, dass das nächste Untersuchungsobjekt die HAProxy-Protokolle sein sollten. Unsere Protokolle wurden in GCP BigQuery gespeichert. Dies ist praktisch, da wir viele Protokolle haben und diese umfassend analysieren mussten. Aber zuerst konnten wir den Protokolleintrag für einen der Vorfälle identifizieren, der in den erfassten Paketen gefunden wurde. Wir haben uns auf die Zeit und den TCP-Port verlassen, was eine wichtige Leistung in unserer Studie war. Das interessanteste Detail im gefundenen Datensatz war das
t_state (Termination State) mit dem Wert
SD . Hier ist ein Auszug aus der HAProxy-Dokumentation:
S: , . D: DATA.
Die Bedeutung der Bedeutung von
D wird sehr einfach erklärt. Die TCP-Verbindung wurde korrekt hergestellt, Daten wurden gesendet. Dies stimmte mit Beweisen überein, die aus erfassten Paketen erhalten wurden. Ein Wert von
S bedeutet, dass der HAProxy eine RST- oder ICMP-Fehlermeldung vom Backend empfangen hat. Aber wir konnten nicht sofort einen Hinweis darauf finden, warum dies geschah. Der Grund dafür kann alles sein - von einem instabilen Netzwerk (z. B. einem Fehler oder einer Überlastung) bis zu einem Problem auf Anwendungsebene. Bei der Verwendung von BigQuery zum Aggregieren von Daten in Git-Backends haben wir festgestellt, dass das Problem nicht an eine bestimmte virtuelle Maschine gebunden ist. Wir brauchten mehr Informationen.
Ich möchte darauf hinweisen, dass die Protokolleinträge mit dem
SD Wert nichts Besonderes waren, sondern nur für unser Problem charakteristisch waren. Auf dem Alternate-SSH-Port haben wir viele Anfragen bezüglich des Scannens nach HTTPS erhalten. Dies führte dazu, dass der
SD Wert in die Protokolle fiel, als der SSH-Server die
TLS ClientHello Nachricht sah, während er eine SSH-Begrüßung erwartete. Dies führte unsere Untersuchung kurz auf Umwegen.
Nachdem wir den Datenverkehr zwischen dem HAProxy und dem Git-Server erfasst und erneut Wireshark-Tools verwendet hatten, stellten wir schnell fest, dass die SSHD auf dem Git-Server unmittelbar nach dem Drei-Wege-Handshake von TCP vom TCP FIN-ACK getrennt wird. HAProxy hat immer noch nicht das erste Datenpaket gesendet, war aber dabei, dies zu tun. Als er das Paket sendete, antwortete ihm der Git-Server mit TCP RST. Infolgedessen haben wir jetzt den Grund entdeckt, warum HAProxy mit dem
SD Wert in die Protokolle über den Verbindungsfehler geschrieben hat. SSH hat die Verbindung absichtlich und korrekt geschlossen, und RST war nur ein Artefakt der Tatsache, dass der SSH-Server das Paket nach FIN-ACK empfangen hat. Es bedeutete nichts mehr.
Beredter Zeitplan
Beim Betrachten und Analysieren von Protokollen mit
SD Werten in BigQuery haben wir festgestellt, dass Fehler einen ausgeprägten Bezug zur Zeit haben. Wir haben nämlich Spitzenwerte in der Anzahl fehlgeschlagener Verbindungen innerhalb der ersten 10 Sekunden jeder Minute gefunden. Sie wurden 5-6 Sekunden lang beobachtet.
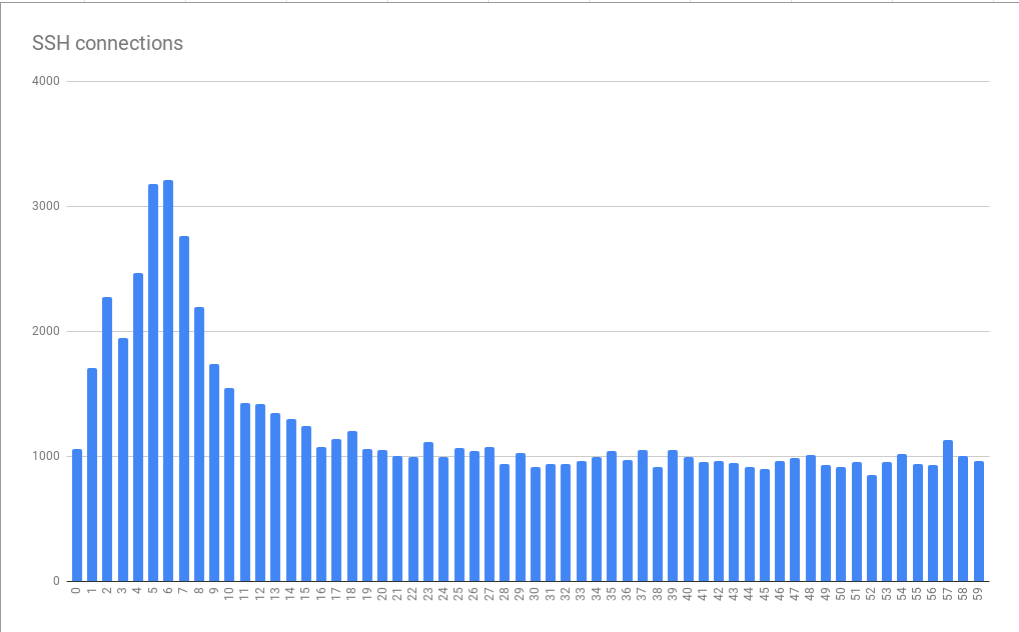 Verbindungsfehler innerhalb von Minuten bis Sekunden gruppiert
Verbindungsfehler innerhalb von Minuten bis Sekunden gruppiertDieses Diagramm basiert auf Daten, die über viele Stunden gesammelt wurden. Die Tatsache, dass sich das erkannte Muster der Fehlerverteilung als stabil herausstellte, zeigt, dass sich die Fehlerursache innerhalb einzelner Minuten und Stunden stabil manifestiert und, möglicherweise noch schlimmer, zu verschiedenen Tageszeiten stabil auftritt. Es ist sehr interessant, dass die durchschnittliche Peakgröße ungefähr dreimal größer ist als die Grundlast. Dies bedeutete, dass wir mit einem nicht trivialen Problem der Skalierung konfrontiert waren. Infolgedessen könnte es theoretisch inakzeptabel teuer sein, einfach „mehr Ressourcen“ in Form zusätzlicher virtueller Maschinen anzuschließen, die uns bei der Bewältigung von Spitzenlasten helfen sollen. Dies deutete auch darauf hin, dass wir eine ernsthafte Einschränkung erreichen. Als Ergebnis erhielten wir den ersten Hinweis auf das grundlegende systemische Problem, das Fehler verursacht. Ich nannte es die Tyrannei der Stunden.
Cron oder ähnliche Planungssysteme unterscheiden sich häufig nicht in der Fähigkeit, die Ausführung von Aufgaben auf die nächste Sekunde anzupassen. Wenn solche Systeme über solche Fähigkeiten verfügen, werden sie nicht sehr oft verwendet, da die Menschen es vorziehen, die Zeit in Intervallen zu betrachten, die durch schöne runde Zahlen ausgedrückt werden. Infolgedessen beginnen Aufgaben am Anfang einer Minute oder Stunde oder zu anderen ähnlichen Zeitpunkten. Wenn die Aufgaben einige Sekunden brauchten, um den Befehl
git fetch zum Herunterladen von Materialien von gitlab.com vorzubereiten, könnte dies das Muster erklären, das wir gefunden haben, wenn die Belastung des Systems jede Minute einige Sekunden lang stark ansteigt. In solchen Momenten nimmt die Anzahl der Fehler zu.
Lektion Nummer 2. Anscheinend verwenden viele Leute die korrekt konfigurierte Zeitsynchronisation (über NTP oder andere Mechanismen).
Wenn niemand die Zeit synchronisiert hätte, hätte sich unser Problem nicht so deutlich manifestiert. Guten Tag, NTP!
Aber was bewirkt, dass SSH die Verbindung trennt?
Dem Kern des Problems näher kommen
Beim Studium der
MaxStartups Dokumentation haben wir den Parameter
MaxStartups entdeckt. Es steuert die maximale Anzahl nicht authentifizierter Verbindungen. Es erscheint plausibel, dass das Verbindungslimit erschöpft ist, wenn das System zu Beginn der Minute der Last ausgesetzt ist, die durch eine Vielzahl von Aufrufen geplanter Aufgaben aus dem gesamten Internet entsteht. Der Parameter
MaxStartups besteht aus drei Zahlen. Die erste ist die Untergrenze (die Anzahl der Verbindungen bei Erreichen, bei denen Verbindungsunterbrechungen beginnen). Der zweite ist der Prozentsatz der Verbindungen, die die untere Grenze der Verbindungen überschreiten, die zufällig gebrochen werden müssen. Der dritte Wert ist die absolute maximale Anzahl von Verbindungen, nach der alle neuen Verbindungen abgelehnt werden. Der Standardwert von MaxStartups sieht wie folgt aus: 10: 30: 100, unsere Einstellungen sehen dann wie 100: 30: 200 aus. Dies deutet darauf hin, dass wir in der Vergangenheit die Standardverbindungsgrenzen erhöht haben. Vielleicht - es ist Zeit, sie wieder zu erhöhen.
Es stellte sich als etwas unangenehm heraus, dass seit der Installation von OpenSSH 7.2 auf unseren Servern die in
MaxStartups festgelegten
MaxStartups nur
MaxStartups auf die
Debug Debugging-Ebene
MaxStartups wurde. Bei diesem Ansatz fällt eine Datenlawine in die Protokolle. Daher haben wir diesen Modus auf einem der Server kurz aktiviert. Glücklicherweise wurde in wenigen Minuten klar, dass die Anzahl der Verbindungen die in
MaxStartups festgelegten Grenzwerte
MaxStartups , wodurch eine frühzeitige Trennung erfolgte.
Es stellte sich heraus, dass in OpenSSH 7.6 (diese Version wird mit Ubuntu 18.04
MaxStartups ) ein bequemerer Ansatz zum Protokollieren von
MaxStartups . Hier müssen Sie nur in den
Verbose Protokollierungsmodus wechseln. Obwohl nicht ideal, ist es immer noch besser als auf die
Debug Ebene zu wechseln.
Lektion Nummer 3. Es wird als gute Form angesehen, interessante Informationen in Standardprotokollierungsstufen in die Protokolle zu schreiben, und Informationen über eine absichtliche Trennung aus irgendeinem Grund sind für Systemadministratoren sicherlich interessant.
Nachdem wir die Ursache des Problems herausgefunden haben, stellte sich die Frage, wie es gelöst werden kann. Wir könnten die Werte im
MaxStartups Parameter
MaxStartups , aber was würde uns das kosten? Dies würde zwar etwas zusätzlichen Speicher erfordern, aber würde dies zu nachteiligen Konsequenzen in den Teilen des Systems führen, in denen Anforderungen verarbeitet werden? Wir konnten nur darüber nachdenken und beschlossen, die neuen
MaxStartups Einstellungen
MaxStartups . Wir haben sie nämlich gegen Folgendes ausgetauscht: 150: 30: 300. Früher sahen sie wie 100: 30: 200 aus, das heißt - wir haben die Anzahl der Verbindungen um 50% erhöht. Dies hat sich stark positiv auf das System ausgewirkt. Gleichzeitig wurden einige negative Auswirkungen, wie z. B. eine Erhöhung der Belastung der Prozessoren, nicht beobachtet.
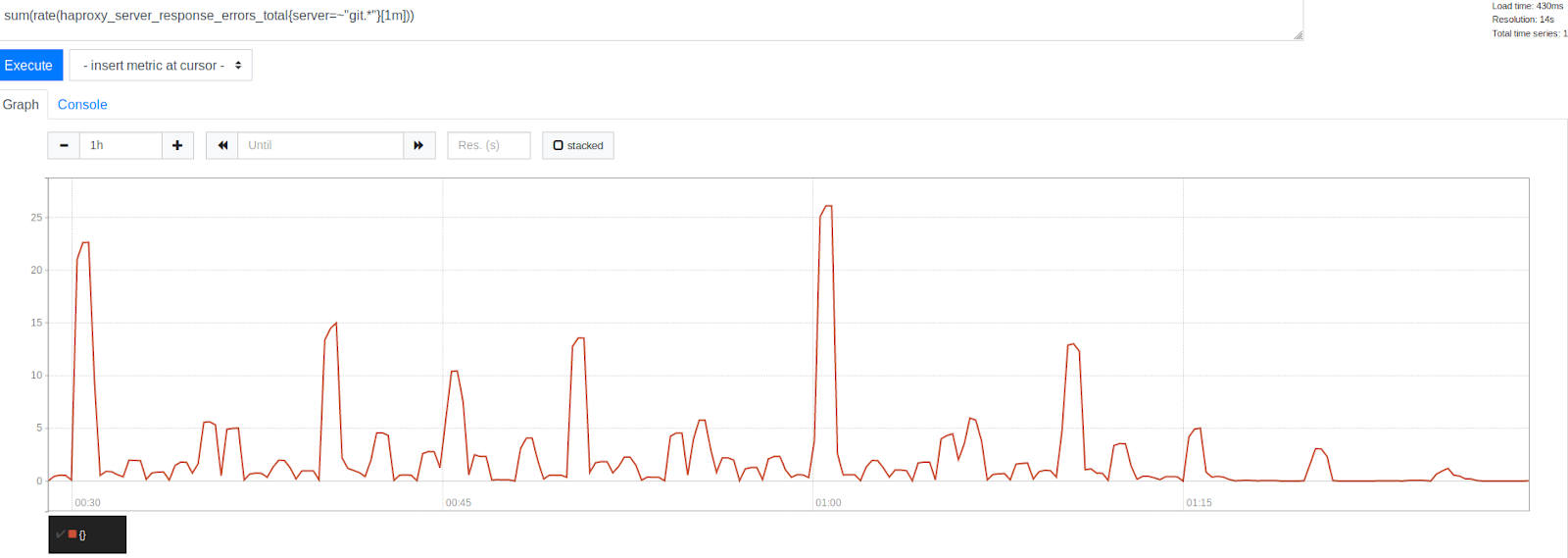 Die Anzahl der Fehler vor und nach dem Erhöhen von MaxStartups um 50%
Die Anzahl der Fehler vor und nach dem Erhöhen von MaxStartups um 50%Beachten Sie die signifikante Reduzierung der Fehler nach dem Zeitstempel 1:15. Dies zeigt deutlich, dass wir einen erheblichen Teil der Fehler beseitigen konnten, obwohl einige noch vorhanden waren. Es ist interessant festzustellen, dass Fehler um Zeitstempel gruppiert sind, die durch schöne runde Zahlen dargestellt werden. Dies ist der Beginn der Stunde, alle 30, 15 und 10 Minuten. Zweifellos ging die Tyrannei der Uhr weiter. Zu Beginn jeder Stunde wird der höchste Fehlerpeak beobachtet. Dies erscheint angesichts dessen, was wir bereits herausgefunden haben, ziemlich verständlich. Viele Leute planen einfach, Aufgaben jede Stunde auszuführen, die 0 Minuten nach Beginn der Stunde ausgeführt wird. Diese Tatsache bestätigte unsere Theorie, dass Fehlerspitzen durch den Start geplanter Aufgaben verursacht werden. Dies zeigte, dass wir bei der Lösung des Problems auf dem richtigen Weg waren, indem wir die Systemgrenzen anpassten.
Zu unserer Freude führte die Änderung des
MaxStartups Limits nicht zu spürbaren negativen Auswirkungen. Die CPU-Auslastung auf SSH-Servern blieb in etwa auf dem gleichen Niveau wie zuvor, die Belastung unserer Systeme stieg ebenfalls nicht an. Es war sehr schön, wenn man bedenkt, dass wir jetzt mehr Verbindungen akzeptiert haben, von denen, die vorher einfach unterbrochen worden wären. Darüber hinaus hat sich die Situation nicht dadurch verschlechtert, dass wir dies zu einer Zeit getan haben, als unsere Systeme sehr stark ausgelastet waren. Es sah alles vielversprechend aus.
Fortsetzung folgt…
Liebe Leser! Mit welchen Tools analysieren Sie Datenverkehr und Protokolle?
