Fortsetzung der Übersetzung eines kleinen Buches:
"Message Brokers verstehen",
Autor: Jakub Korab, Herausgeber: O'Reilly Media, Inc., Erscheinungsdatum: Juni 2017, ISBN: 9781492049296.
Übersetzung abgeschlossen: tele.gg/middle_javaVorheriger Teil:
Grundlegendes zu Message Brokern. Erlernen der Mechanismen des Messaging über ActiveMQ und Kafka. Kapitel 2. ActiveMQKAPITEL 3
Kafka
Kafka wurde auf LinkedIn entwickelt, um einige der Einschränkungen herkömmlicher Nachrichtenbroker zu umgehen und die Notwendigkeit zu vermeiden, mehrere Nachrichtenbroker für unterschiedliche Punkt-zu-Punkt-Interaktionen zu konfigurieren. Dies wird im Abschnitt „Vertikale und horizontale Skalierung“ auf Seite 28 in diesem Buch beschrieben. LinkedIn stützte sich stark auf die unidirektionale Absorption sehr großer Datenmengen wie Seitenklicks und Zugriffsprotokolle, während mehrere Systeme diese Daten verwenden konnten. Uhr, ohne die Leistung anderer Hersteller oder konsyumerov zu beeinflussen. Der Grund, warum Kafka existiert, besteht darin, die von der Universal Data Pipeline beschriebene Messaging-Architektur abzurufen.
Angesichts dieses Endziels ergaben sich natürlich andere Anforderungen. Kafka muss:
- Sei extrem schnell
- Bieten Sie einen höheren Messaging-Durchsatz
- Unterstützt Publisher-Subscriber- und Point-to-Point-Modelle
- Verlangsamen Sie nicht mit dem Hinzufügen von Verbrauchern. Beispielsweise verschlechtert sich die Leistung von Warteschlangen und Themen in ActiveMQ mit zunehmender Anzahl von Verbrauchern am Ziel.
- Horizontal skalierbar sein; Wenn eine einzelne persistierende Nachricht dies nur mit maximaler Festplattengeschwindigkeit tun kann, ist es zur Leistungssteigerung sinnvoll, die Grenzen einer Brokerinstanz zu überschreiten
- Beschreiben Sie den Zugriff auf das Speichern und Abrufen von Nachrichten
Um all dies zu erreichen, hat Kafka eine Architektur eingeführt, die die Rollen und Verantwortlichkeiten von Kunden und Messaging-Brokern neu definiert. Das JMS-Modell konzentriert sich sehr auf den Broker, bei dem er für die Verteilung von Nachrichten verantwortlich ist, und Kunden müssen sich nur um das Senden und Empfangen von Nachrichten kümmern. Kafka hingegen ist kundenorientiert, wobei der Kunde viele Funktionen eines traditionellen Brokers übernimmt, beispielsweise die gerechte Verteilung relevanter Nachrichten unter den Verbrauchern, und im Gegenzug einen extrem schnellen und skalierbaren Broker erhält. Für Menschen, die mit traditionellen Nachrichtensystemen arbeiten, erfordert die Arbeit mit Kafka eine grundlegende Änderung der Einstellung.
Diese technische Ausrichtung hat zur Schaffung einer Messaging-Infrastruktur geführt, die den Durchsatz im Vergleich zu einem herkömmlichen Broker um viele Größenordnungen steigern kann. Wie wir sehen werden, ist dieser Ansatz mit Kompromissen behaftet, was bedeutet, dass Kafka für bestimmte Arten von Lasten und installierter Software nicht geeignet ist.
Einheitliches Zielmodell
Um die oben beschriebenen Anforderungen zu erfüllen, kombinierte Kafka das Publikationsabonnement und das Punkt-zu-Punkt-Messaging in einem Adressatentyp -
Thema . Dies ist verwirrend für Personen, die mit Nachrichtensystemen arbeiten, bei denen sich das Wort "Thema" auf den Übertragungsmechanismus bezieht, von dem (vom Thema) das Lesen nicht zuverlässig ist (nicht haltbar ist). Kafka-Themen sollten als hybrider Zieltyp betrachtet werden, wie in der Einleitung zu diesem Buch definiert.
Im Rest dieses Kapitels bezieht sich der Begriff Thema, sofern nicht ausdrücklich anders angegeben, auf das Kafka-Thema.
Um zu verstehen, wie sich Themen verhalten und welche Garantien sie bieten, müssen wir zunächst überlegen, wie sie in Kafka implementiert werden.
Jedes Thema in Kafka hat ein eigenes Tagebuch.Produzenten, die Nachrichten an Kafka senden, fügen diese Zeitschrift hinzu, und Verbraucher lesen aus der Zeitschrift mit Zeigern, die sich ständig weiterentwickeln. Kafka löscht regelmäßig die ältesten Teile des Journals, unabhängig davon, ob Nachrichten in diesen Teilen gelesen wurden oder nicht. Ein zentraler Bestandteil von Kafkas Design ist, dass es dem Broker egal ist, ob Nachrichten gelesen werden oder nicht - dies liegt in der Verantwortung des Kunden.
Die Begriffe "Journal" und "Index" sind in der Kafka-Dokumentation nicht enthalten . Diese bekannten Begriffe werden hier zum besseren Verständnis verwendet.
Dieses Modell unterscheidet sich grundlegend von ActiveMQ, bei dem Nachrichten aus allen Warteschlangen in einem Journal gespeichert werden und der Broker Nachrichten nach dem Lesen als gelöscht markiert.
Gehen wir jetzt etwas tiefer und schauen uns das Themenmagazin genauer an.
Das Kafka Magazine besteht aus mehreren Partitionen (
Abbildung 3-1 ). Kafka garantiert eine strikte Reihenfolge in jeder Partition. Dies bedeutet, dass Nachrichten, die in einer bestimmten Reihenfolge auf die Partition geschrieben wurden, in derselben Reihenfolge gelesen werden. Jede Partition wird als fortlaufende (Protokoll-) Protokolldatei implementiert, die eine
Teilmenge aller Nachrichten enthält, die von ihren Produzenten an das Thema gesendet wurden. Das erstellte Thema enthält standardmäßig eine Partition. Partitionierung ist Kafkas zentrale Idee für die horizontale Skalierung.
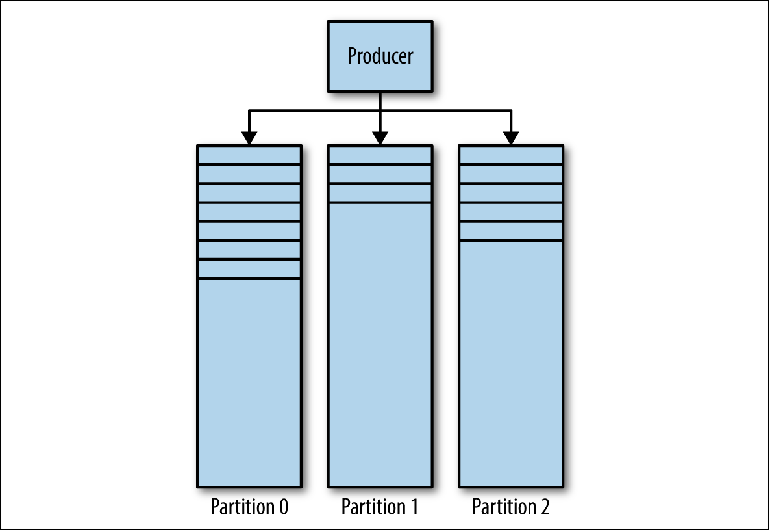 Abbildung 3-1. Trennwände Kafka
Abbildung 3-1. Trennwände KafkaWenn der Produzent eine Nachricht an das Kafka-Thema sendet, entscheidet er, an welche Partition die Nachricht gesendet werden soll. Wir werden dies später genauer betrachten.
Nachrichten lesen
Ein Client, der Nachrichten lesen möchte, steuert einen benannten Zeiger, der als
Verbrauchergruppe bezeichnet wird und den
Versatz einer Nachricht in einer Partition angibt. Ein Offset ist eine Position mit zunehmender Zahl, die am Anfang der Partition bei 0 beginnt. Diese Gruppe von Verbrauchern, auf die in der API über eine benutzerdefinierte Kennung group_id verwiesen wird, entspricht einem
einzelnen logischen Verbraucher oder System .
Die meisten Nachrichtensysteme lesen Daten vom Empfänger über mehrere Instanzen und Threads, um Nachrichten parallel zu verarbeiten. Daher wird es normalerweise viele Fälle von Verbrauchern geben, die dieselbe Verbrauchergruppe teilen.
Das Leseproblem kann wie folgt dargestellt werden:
- Das Thema hat mehrere Partitionen
- Mehrere Verbrauchergruppen können das Thema gleichzeitig verwenden.
- Eine Gruppe von Verbrauchern kann mehrere separate Instanzen haben.
Dies ist ein nicht triviales Viele-zu-Viele-Problem. Um zu verstehen, wie Kafka mit den Beziehungen zwischen Verbrauchergruppen, Instanzen von Verbrauchern und Partitionen umgeht, werfen wir einen Blick auf eine Reihe immer komplexer werdender Leseskripte.
Verbraucher und Verbrauchergruppen
Nehmen wir ein Thema mit einer einzelnen Partition als Ausgangspunkt (
Abbildung 3-2 ).
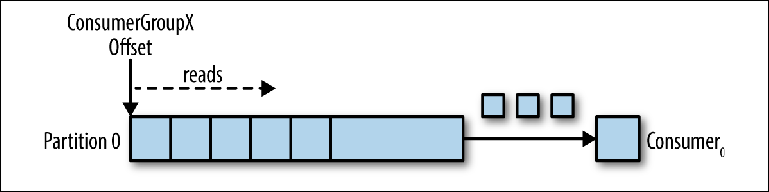 Abbildung 3-2. Der Verbraucher liest von der Partition
Abbildung 3-2. Der Verbraucher liest von der PartitionWenn eine Consumer-Instanz mit ihrer eigenen group_id zu diesem Thema verbunden ist, wird ihr eine zu lesende Partition und ein Offset in dieser Partition zugewiesen. Die Position dieses Versatzes wird im Client als Zeiger auf die letzte Position (die neueste Nachricht) oder die früheste Position (die älteste Nachricht) konfiguriert. Der Verbraucher fordert (Abfragen) Nachrichten zum Thema an, was zu deren sequentiellem Lesen aus dem Journal führt.
Die Versatzposition wird regelmäßig an Kafka zurückgeschrieben und als Nachrichten im internen Thema
_consumer_offsets gespeichert . Gelesene Nachrichten werden im Gegensatz zu einem normalen Broker immer noch nicht gelöscht, und der Client kann den Offset zurückspulen, um bereits angezeigte Nachrichten erneut zu verarbeiten.
Wenn ein zweiter logischer Consumer über eine andere group_id verbunden ist, steuert er einen zweiten Zeiger, der vom ersten unabhängig ist (
Abbildung 3-3 ). Somit fungiert das Kafka-Thema als Warteschlange, in der sich ein Verbraucher befindet, und als reguläres Thema als Herausgeber-Abonnent (Pub-Sub), bei dem mehrere Verbraucher abonniert sind, mit dem zusätzlichen Vorteil, dass alle Nachrichten gespeichert werden und mehrmals verarbeitet werden können.
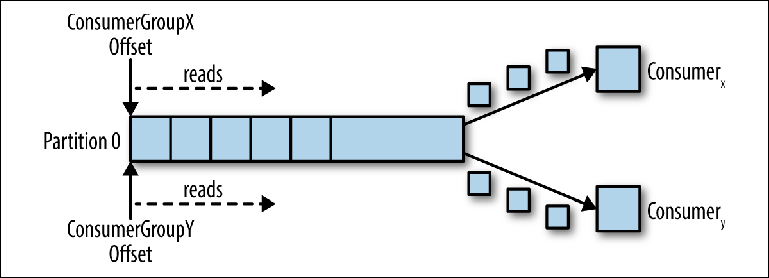 Abbildung 3-3. Zwei Verbraucher in verschiedenen Verbrauchergruppen lesen von derselben Partition
Abbildung 3-3. Zwei Verbraucher in verschiedenen Verbrauchergruppen lesen von derselben PartitionVerbraucher in der Verbrauchergruppe
Wenn eine Instanz des Verbrauchers Daten von der Partition liest, steuert sie den Zeiger vollständig und verarbeitet die Nachrichten, wie im vorherigen Abschnitt beschrieben.
Wenn mehrere Instanzen der Konsumenten mit derselben Gruppe_ID mit einer Partition mit dem Thema verbunden waren, erhält die zuletzt verbundene Instanz die Kontrolle über den Zeiger und erhält von da an alle Nachrichten (
Abbildung 3-4 ).
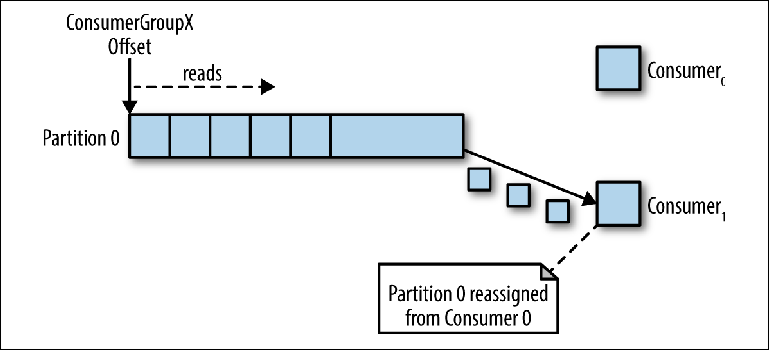 Abbildung 3-4. Zwei Verbraucher in derselben Gruppe von Verbrauchern lesen von derselben Partition
Abbildung 3-4. Zwei Verbraucher in derselben Gruppe von Verbrauchern lesen von derselben PartitionDieser Verarbeitungsmodus, bei dem die Anzahl der Verbraucherinstanzen die Anzahl der Partitionen überschreitet, kann als eine Art Monopolverbraucher betrachtet werden. Dies kann nützlich sein, wenn Sie ein "Aktiv-Passiv" - (oder "Heiß-Warm") - Clustering Ihrer Instanzen von Verbrauchern benötigen, obwohl der parallele Betrieb mehrerer Verbraucher ("Aktiv-Aktiv" oder "Heiß-Heiß") viel typischer ist als Verbraucher im Standby-Modus.
Dieses oben beschriebene Nachrichtenverteilungsverhalten kann im Vergleich zum Verhalten einer regulären JMS-Warteschlange überraschend sein. In diesem Modell werden an die Warteschlange gesendete Nachrichten gleichmäßig zwischen den beiden Verbrauchern verteilt.
Wenn wir mehrere Instanzen von Compilern erstellen, tun wir dies meistens entweder zur parallelen Verarbeitung von Nachrichten oder um die Lesegeschwindigkeit zu erhöhen oder um die Stabilität des Leseprozesses zu erhöhen. Wie wird dies in Kafka erreicht, da nur eine Instanz eines Verbrauchers Daten von einer Partition lesen kann?
Eine Möglichkeit, dies zu tun, besteht darin, eine Instanz des Verbrauchers zu verwenden, um alle Nachrichten zu lesen und sie an den Thread-Pool zu senden. Obwohl dieser Ansatz den Verarbeitungsdurchsatz erhöht, erhöht er die Komplexität der Logik der Verbraucher und trägt nicht zur Erhöhung der Stabilität des Lesesystems bei. Wenn eine Instanz des Verbrauchers aufgrund eines Stromausfalls oder eines ähnlichen Ereignisses ausgeschaltet wird, wird das Korrekturlesen gestoppt.
Der kanonische Weg, um dieses Problem in Kafka zu lösen, besteht darin, mehr Partitionen zu verwenden.
Partitionierung
Partitionen sind der Hauptmechanismus für die Parallelisierung des Lesens und Skalierens des Themas über die Bandbreite einer Instanz des Brokers hinaus. Um dies besser zu verstehen, betrachten wir eine Situation, in der es ein Thema mit zwei Partitionen gibt und ein Verbraucher dieses Thema abonniert (
Abbildung 3-5 ).
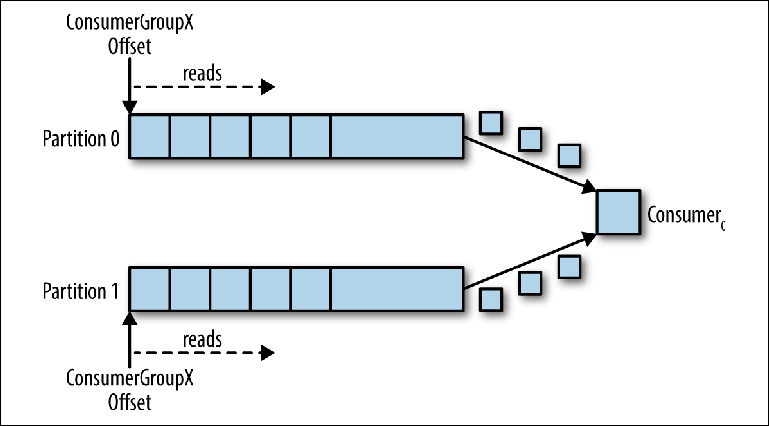 Abbildung 3-5. Ein Verbraucher liest von mehreren Partitionen
Abbildung 3-5. Ein Verbraucher liest von mehreren PartitionenIn diesem Szenario erhält der Berater die Kontrolle über die Zeiger, die seiner group_id in beiden Partitionen entsprechen, und das Lesen von Nachrichten von beiden Partitionen beginnt.
Wenn diesem Thema ein zusätzlicher Compurator für dieselbe group_id hinzugefügt wird, weist Kafka eine der Partitionen von der ersten zur zweiten neu zu (ordnet sie neu zu). Danach wird jede Instanz des Verbrauchers von einer Partition des Themas abgezogen (
Abbildung 3-6 ).
Um sicherzustellen, dass Nachrichten in 20 Threads parallel verarbeitet werden, benötigen Sie mindestens 20 Partitionen. Wenn weniger Partitionen vorhanden sind, haben Sie immer noch Konsumenten, an denen Sie nicht arbeiten müssen, wie bereits in der Diskussion über exklusive Monitore beschrieben.
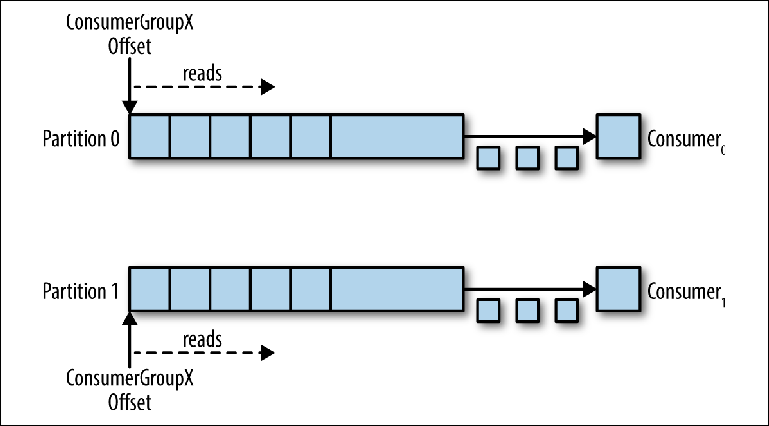 Abbildung 3-6. Zwei Verbraucher in derselben Verbrauchergruppe lesen von verschiedenen Partitionen
Abbildung 3-6. Zwei Verbraucher in derselben Verbrauchergruppe lesen von verschiedenen PartitionenDieses Schema reduziert die Komplexität des Kafka-Brokers im Vergleich zur Nachrichtenverteilung, die zur Unterstützung der JMS-Warteschlange erforderlich ist, erheblich. Folgende Punkte müssen nicht beachtet werden:
- Welcher Verbraucher die nächste Nachricht basierend auf der Round-Robin-Verteilung, der aktuellen Prefetch-Pufferkapazität oder früheren Nachrichten (wie bei JMS-Nachrichtengruppen) erhalten soll?
- Welche Nachrichten wurden an welche Verbraucher gesendet und sollten sie im Falle eines Fehlers erneut gesendet werden?
Der Kafka-Broker sollte lediglich konsistent Nachrichten an den Berater senden, wenn dieser diese anfordert.
Die Anforderungen für die Parallelisierung des Korrekturlesens und das erneute Senden nicht erfolgreicher Nachrichten verschwinden jedoch nicht - die Verantwortung dafür geht einfach vom Broker auf den Client über. Dies bedeutet, dass sie in Ihren Code einbezogen werden müssen.
Nachrichten senden
Die Verantwortung für die Entscheidung, an welche Partition die Nachricht gesendet werden soll, liegt beim Hersteller der Nachricht. Um den Mechanismus zu verstehen, mit dem dies geschieht, müssen Sie zunächst überlegen, was genau wir tatsächlich senden.
Während wir in JMS eine Nachrichtenstruktur mit Metadaten (Headern und Eigenschaften) und einem Text verwenden, der Nutzdaten enthält, ist die Nachricht in Kafka
ein Schlüssel-Wert-Paar . Die Nachrichtennutzdaten werden als Wert gesendet. Ein Schlüssel wird dagegen hauptsächlich für die Partitionierung verwendet und muss einen
geschäftslogikspezifischen Schlüssel enthalten , um verwandte Nachrichten in dieselbe Partition zu stellen.
In Kapitel 2 haben wir das Online-Wett-Szenario erörtert, bei dem verwandte Ereignisse in der Reihenfolge von einem einzelnen Verbraucher verarbeitet werden sollten:
- Das Benutzerkonto ist konfiguriert.
- Geld wird dem Konto gutgeschrieben.
- Es wird eine Wette abgeschlossen, die Geld vom Konto abhebt.
Wenn jedes Ereignis eine Nachricht ist, die an das Thema gesendet wird, ist in diesem Fall die Kontokennung der natürliche Schlüssel.
Wenn eine Nachricht mit der Kafka Producer-API gesendet wird, wird sie an die Partitionsfunktion übergeben, die angesichts der Nachricht und des aktuellen Status des Kafka-Clusters die Kennung der Partition zurückgibt, an die die Nachricht gesendet werden soll. Diese Funktion wird in Java über die Partitioner-Oberfläche implementiert.
Diese Schnittstelle ist wie folgt:
interface Partitioner { int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); }
Die Partitioner-Implementierung verwendet den Standard-Allzweck-Hashing-Algorithmus für den Schlüssel oder das Round-Robin, wenn der Schlüssel nicht zur Bestimmung der Partition angegeben ist. Dieser Standardwert funktioniert in den meisten Fällen gut. In Zukunft möchten Sie jedoch Ihre eigenen schreiben.
Schreiben Sie Ihre eigene Partitionierungsstrategie
Schauen wir uns ein Beispiel an, in dem Sie Metadaten zusammen mit der Nachrichtennutzlast senden möchten. Die Nutzlast in unserem Beispiel ist eine Anweisung zum Einzahlen auf ein Spielkonto. Eine Anweisung möchten wir garantieren, dass sie während der Übertragung nicht geändert wird, und wir möchten sicherstellen, dass nur ein vertrauenswürdiges übergeordnetes System diese Anweisung initiieren kann. In diesem Fall vereinbaren die sendenden und empfangenden Systeme die Verwendung der Signatur zur Authentifizierung der Nachricht.
In einem regulären JMS definieren wir einfach die Nachrichtensignatur-Eigenschaft und fügen sie der Nachricht hinzu. Kafka bietet uns jedoch keinen Mechanismus zur Übertragung von Metadaten - nur den Schlüssel und den Wert.
Da der Wert die Nutzlast einer Banküberweisung (Banküberweisungsnutzlast) ist, deren Integrität wir beibehalten möchten, haben wir keine andere Wahl, als die Datenstruktur für die Verwendung im Schlüssel zu bestimmen. Angenommen, wir benötigen eine Kontokennung für die Partitionierung, da alle Nachrichten, die sich auf das Konto beziehen, der Reihe nach verarbeitet werden müssen, werden wir die folgende JSON-Struktur erstellen:
{ "signature": "541661622185851c248b41bf0cea7ad0", "accountId": "10007865234" }
Da der Signaturwert abhängig von der Nutzlast variiert, gruppiert die Standard-Hash-Strategie der Partitioner-Schnittstelle verwandte Nachrichten nicht zuverlässig. Daher müssen wir unsere eigene Strategie schreiben, die diesen Schlüssel analysiert und den Wert von accountId teilt.
Kafka enthält Prüfsummen zum Erkennen von Nachrichtenbeschädigungen im Repository und verfügt über einen vollständigen Satz von Sicherheitsfunktionen. Selbst dann treten manchmal branchenspezifische Anforderungen auf, wie die oben genannten.
Die Benutzerpartitionierungsstrategie sollte sicherstellen, dass alle zugehörigen Nachrichten auf derselben Partition landen. Obwohl dies einfach erscheint, kann die Anforderung kompliziert sein, da wichtige Nachrichten bestellt werden müssen und die Anzahl der Partitionen im Thema festgelegt ist.
Die Anzahl der Partitionen im Thema kann sich im Laufe der Zeit ändern, da sie hinzugefügt werden können, wenn der Datenverkehr die ursprünglichen Erwartungen übertrifft. Somit können Nachrichtenschlüssel der Partition zugeordnet werden, an die sie ursprünglich gesendet wurden, was einen Teil des Status impliziert, der zwischen Produzenteninstanzen verteilt werden muss.
Ein weiterer zu berücksichtigender Faktor ist die gleichmäßige Verteilung von Nachrichten zwischen Partitionen. In der Regel sind Schlüssel nicht gleichmäßig auf Nachrichten verteilt, und Hash-Funktionen garantieren keine faire Verteilung von Nachrichten für einen kleinen Schlüsselsatz.
Es ist wichtig zu beachten, dass das Trennzeichen selbst möglicherweise wiederverwendet werden muss, unabhängig davon, wie Sie die Nachrichten aufteilen.
Berücksichtigen Sie die Anforderung für die Datenreplikation zwischen Kafka-Clustern an verschiedenen geografischen Standorten. Zu diesem Zweck wird Kafka mit einem Befehlszeilentool namens MirrorMaker geliefert, mit dem Nachrichten von einem Cluster gelesen und an einen anderen übertragen werden können.
MirrorMaker muss die Schlüssel des replizierten Themas verstehen, um die relative Reihenfolge zwischen Nachrichten während der Replikation zwischen Clustern beizubehalten, da die Anzahl der Partitionen für dieses Thema in zwei Clustern möglicherweise nicht übereinstimmt.
Benutzerdefinierte Partitionierungsstrategien sind relativ selten, da Standard-Hashes oder Round-Robin in den meisten Szenarien erfolgreich funktionieren. Wenn Sie jedoch strenge Bestellgarantien benötigen oder Metadaten aus den Nutzdaten extrahieren müssen, sollten Sie sich die Partitionierung genauer ansehen.
Die Skalierbarkeits- und Leistungsvorteile von Kafka ergeben sich aus der Übertragung einiger Verantwortlichkeiten eines traditionellen Brokers auf einen Kunden. In diesem Fall wird eine Entscheidung über die Verteilung potenziell verwandter Nachrichten an mehrere parallel arbeitende Verbraucher getroffen.
JMS-Broker müssen sich ebenfalls mit solchen Anforderungen befassen. Interessanterweise erfordert der Mechanismus zum Senden verwandter Nachrichten an dasselbe Konto, der über die JMS-Nachrichtengruppen implementiert wurde (eine Art SLB-Ausgleichsstrategie (Sticky Load Balancing)), dass der Absender auch Nachrichten als verwandt markiert. Im Fall von JMS ist der Broker dafür verantwortlich, diese Gruppe verwandter Nachrichten an einen der vielen Kunden zu senden und das Eigentum an der Gruppe zu übertragen, wenn der Kunde abgefallen ist.
Herstellervereinbarung
Partitionierung ist nicht das einzige, was beim Senden von Nachrichten berücksichtigt werden muss. Schauen wir uns die send () -Methoden der Producer-Klasse in der Java-API an:
Future < RecordMetadata > send(ProducerRecord < K, V > record); Future < RecordMetadata > send(ProducerRecord < K, V > record, Callback callback);
Es ist sofort zu beachten, dass beide Methoden Future zurückgeben, was darauf hinweist, dass der Sendevorgang nicht sofort ausgeführt wird. Als Ergebnis stellt sich heraus, dass die Nachricht (ProducerRecord) für jede aktive Partition in den Sendepuffer geschrieben und im Hintergrundstrom in der Kafka-Clientbibliothek an den Broker übertragen wird. Dies macht die Arbeit zwar unglaublich schnell, bedeutet jedoch, dass eine unerfahrene Anwendung Nachrichten verlieren kann, wenn ihr Prozess gestoppt wird.
Wie immer gibt es eine Möglichkeit, den Sendevorgang aufgrund der Leistung zuverlässiger zu gestalten. Die Größe dieses Puffers kann auf 0 gesetzt werden, und der Thread der sendenden Anwendung muss wie folgt warten, bis die Nachricht an den Broker gesendet wird:
RecordMetadata metadata = producer.send(record).get();
Noch einmal über das Lesen von Nachrichten
Das Lesen von Nachrichten hat zusätzliche Schwierigkeiten, die berücksichtigt werden müssen. Im Gegensatz zur JMS-API, mit der ein Nachrichtenlistener als Antwort auf eine Nachricht gestartet werden kann, werden von der
Consumer Kafka-Schnittstelle nur Abfragen durchgeführt. Schauen wir uns die zu diesem Zweck verwendete
poll () -Methode genauer an:
ConsumerRecords < K, V > poll(long timeout);
Der Rückgabewert der Methode ist eine Container-Struktur, die mehrere
ConsumerRecord- Objekte von möglicherweise mehreren Partitionen enthält.
Ein ConsumerRecord selbst ist ein Inhaberobjekt für ein Schlüssel-Wert-Paar mit zugehörigen Metadaten, z. B. der Partition, von der es abgeleitet ist.
Wie in Kapitel 2 erläutert, müssen wir uns ständig daran erinnern, was mit Nachrichten geschieht, nachdem sie erfolgreich oder erfolglos verarbeitet wurden, z. B. wenn der Client die Nachricht nicht verarbeiten kann oder die Arbeit unterbricht. In JMS wurde dies im Bestätigungsmodus behandelt. Der Broker löscht entweder die erfolgreich verarbeitete Nachricht oder übermittelt die unformatierte oder gespiegelte Nachricht erneut (sofern Transaktionen verwendet wurden).
Kafka arbeitet ganz anders. Nachrichten werden nach dem Korrekturlesen nicht im Broker gelöscht, und die Verantwortung für das, was bei einem Fehler passiert, liegt beim Code selbst.
Wie bereits erwähnt, ist eine Gruppe von Verbrauchern mit einem Offset in der Zeitschrift verbunden. Die dieser Verzerrung zugeordnete Protokollposition entspricht der nächsten Nachricht, die als Antwort auf
poll () ausgegeben wird. Entscheidend beim Lesen ist der Zeitpunkt, zu dem dieser Versatz zunimmt.
Zurück zum zuvor diskutierten Lesemodell besteht die Nachrichtenverarbeitung aus drei Schritten:
- Rufen Sie eine Nachricht zum Lesen ab.
- Verarbeiten Sie die Nachricht.
- Nachricht bestätigen.
Der Kafka Consumer Advisor wird mit der Konfigurationsoption
enable.auto.commit geliefert . Dies ist eine häufig verwendete Standardeinstellung, wie dies normalerweise bei Einstellungen der Fall ist, die das Wort „auto“ enthalten.
Vor Kafka 0.10 hat der Client, der diesen Parameter verwendet, den Offset der zuletzt gelesenen Nachricht beim nächsten Aufruf von
poll () nach der Verarbeitung gesendet. Dies bedeutete, dass alle Nachrichten, die bereits abgerufen wurden, erneut verarbeitet werden konnten, wenn der Client sie bereits verarbeitet hatte, aber vor dem Aufruf von
poll () unerwartet zerstört wurden. Da der Broker keinen Status darüber behält, wie oft die Nachricht gelesen wurde, weiß der nächste Verbraucher, der diese Nachricht abruft, nicht, dass etwas Schlimmes passiert ist. Dieses Verhalten war pseudotransaktional. Der Offset wurde nur bei erfolgreicher Verarbeitung der Nachricht festgeschrieben. Wenn der Client jedoch unterbrochen wurde, hat der Broker dieselbe Nachricht erneut an einen anderen Client gesendet. Dieses Verhalten stimmte mit der Garantie für die Zustellung von Nachrichten "
mindestens einmal " überein.
In Kafka 0.10 wurde der Clientcode so geändert, dass das Commit gemäß der Einstellung
auto.commit.interval.ms regelmäßig von der
Clientbibliothek gestartet wurde . Dieses Verhalten liegt irgendwo zwischen den Modi JMS AUTO_ACKNOWLEDGE und DUPS_OK_ACKNOWLEDGE. Bei Verwendung der automatischen Festschreibung können Nachrichten bestätigt werden, unabhängig davon, ob sie tatsächlich verarbeitet wurden. Dies kann bei einem langsamen Verbraucher der Fall sein. Wenn der Compurator unterbrochen wurde, wurden Nachrichten vom nächsten Compurator ab einer gesicherten Position abgerufen, was zum Überspringen von Nachrichten führen konnte. In diesem Fall hat Kafka keine Nachrichten verloren, der Lesecode hat sie einfach nicht verarbeitet.
Dieser Modus hat die gleichen Aussichten wie in Version 0.9: Nachrichten können verarbeitet werden, aber im Falle eines Fehlers wird der Offset möglicherweise nicht geschlossen, was möglicherweise zu einer doppelten Zustellung führen kann. Je mehr Nachrichten Sie bei
poll () abrufen, desto größer ist dieses Problem.
Wie im
Abschnitt „Subtrahieren von Nachrichten von der Warteschlange“ in
Kapitel 2 erläutert, gibt es im Nachrichtensystem angesichts der Fehlermodi keine einmalige Nachrichtenübermittlung.
In Kafka gibt es zwei Möglichkeiten, einen Offset (Offset) zu korrigieren (festzuschreiben): automatisch und manuell. In beiden Fällen können Nachrichten mehrmals verarbeitet werden, falls die Nachricht verarbeitet wurde, aber vor dem Festschreiben fehlgeschlagen ist. Sie können die Nachricht auch überhaupt nicht verarbeiten, wenn das Festschreiben im Hintergrund erfolgt ist und Ihr Code vor Beginn der Verarbeitung abgeschlossen wurde (möglicherweise in Kafka 0.9 und früheren Versionen).
Sie können den Prozess des manuellen
Festschreibens von Offsets in der Kafka
Consumer- API
steuern , indem Sie
enable.auto.commit auf false setzen und eine der folgenden Methoden explizit aufrufen:
void commitSync(); void commitAsync();
Wenn Sie die Nachricht "mindestens einmal" verarbeiten möchten, müssen Sie den Offset manuell mit
commitSync () festschreiben, indem Sie diesen Befehl unmittelbar nach der Verarbeitung der Nachrichten ausführen.
Mit diesen Methoden können bestätigte Nachrichten nicht verarbeitet werden, bevor sie verarbeitet werden. Sie tragen jedoch nicht dazu bei, potenzielle Verarbeitungsduplikationen zu beseitigen und gleichzeitig den Anschein von Transaktionsfähigkeit zu erwecken. Kafka hat keine Transaktionen. Der Kunde hat nicht die Möglichkeit, Folgendes zu tun:
- Rollback einer Rollback-Nachricht automatisch. Verbraucher selbst müssen Ausnahmen behandeln, die sich aus problematischen Nutzdaten und Backend-Trennungen ergeben, da sie sich nicht darauf verlassen können, dass der Broker Nachrichten erneut übermittelt.
- Senden Sie Nachrichten an mehrere Themen innerhalb einer atomaren Operation. Wie wir gleich sehen werden, kann die Kontrolle über verschiedene Themen und Partitionen auf verschiedenen Computern im Kafka-Cluster erfolgen, die beim Senden keine Transaktionen koordinieren. Zum Zeitpunkt dieses Schreibens wurden einige Arbeiten durchgeführt, um dies mit dem KIP-98 zu ermöglichen.
- Verknüpfen Sie das Lesen einer Nachricht aus einem Thema mit dem Senden einer anderen Nachricht an ein anderes Thema. Auch hier hängt die Architektur von Kafka von vielen unabhängigen Maschinen ab, die als ein Bus arbeiten, und es wird kein Versuch unternommen, ihn zu verbergen. Beispielsweise gibt es keine API-Komponenten, mit denen der Verbraucher und der Produzent in einer Transaktion verknüpft werden können. In JMS wird dies durch das Sitzungsobjekt bereitgestellt, aus dem MessageProducers und MessageConsumers erstellt werden.
Wenn wir uns nicht auf Transaktionen verlassen können, wie können wir eine Semantik bereitstellen, die der von herkömmlichen Messagingsystemen näher kommt?
Wenn die Möglichkeit besteht, dass sich der Offset des Verbrauchers erhöht, bevor die Nachricht verarbeitet wurde, z. B. während des Ausfalls des Kunden, kann der Kunde nicht herausfinden, ob die Kundengruppe die Nachricht übergeben hat, als ihr eine Partition zugewiesen wurde. Daher besteht eine Strategie darin, den Versatz auf die vorherige Position zurückzuspulen. Die Kafka Consumer Advisor-API bietet hierfür folgende Methoden:
void seek(TopicPartition partition, long offset); void seekToBeginning(Collection < TopicPartition > partitions);
Die Methode
seek () kann mit der Methode verwendet werden
offsetsForTimes (Map <TopicPartition, Long> timestampsToSearch) , um zu einem bestimmten Zeitpunkt in der Vergangenheit in einen Zustand zurückzuspulen.
Die Verwendung dieses Ansatzes bedeutet implizit, dass es sehr wahrscheinlich ist, dass einige Nachrichten, die zuvor verarbeitet wurden, gelesen und erneut verarbeitet werden. Um dies zu vermeiden, können wir, wie in Kapitel 4 beschrieben, idempotentes Lesen verwenden, um zuvor angezeigte Nachrichten zu verfolgen und Duplikate zu beseitigen.
Alternativ kann der Code Ihres Verbrauchers einfach sein, wenn der Verlust oder die Vervielfältigung von Nachrichten zulässig ist. Wenn wir uns Nutzungsszenarien ansehen, für die Kafka normalerweise verwendet wird, z. B. die Verarbeitung von Protokollereignissen, Metriken, Klickverfolgung usw., verstehen wir, dass der Verlust einzelner Nachrichten wahrscheinlich keine wesentlichen Auswirkungen auf die umgebenden Anwendungen hat. In solchen Fällen sind die Standardwerte akzeptabel. Wenn Ihre Anwendung jedoch Zahlungen überweisen muss, müssen Sie sich sorgfältig um jede einzelne Nachricht kümmern. Es kommt alles auf den Kontext an.
Persönliche Beobachtungen zeigen, dass mit zunehmender Nachrichtenintensität der Wert jeder einzelnen Nachricht abnimmt. Nachrichten mit hohem Volumen werden in der Regel wertvoll, wenn sie in aggregierter Form angezeigt werden.
Hochverfügbarkeit
Der Hochverfügbarkeitsansatz von Kafka unterscheidet sich stark von ActiveMQ. Kafka basiert auf horizontal skalierbaren Clustern, in denen alle Instanzen des Brokers gleichzeitig Nachrichten empfangen und verteilen.
Der Kafka-Cluster besteht aus mehreren Brokerinstanzen, die auf verschiedenen Servern ausgeführt werden. Kafka wurde für die Arbeit mit einer herkömmlichen eigenständigen Hardware entwickelt, bei der jeder Knoten über einen eigenen dedizierten Speicher verfügt. Die Verwendung von Network Attached Storage (SAN) wird nicht empfohlen, da mehrere Rechenknoten um Speicherzeitschlitze konkurrieren und Konflikte verursachen können.
Kafka ist ein
ständig laufendes System. Viele große Kafka-Benutzer löschen ihre Cluster nie und die Software bietet Updates immer durch einen konsistenten Neustart. Dies wird erreicht, indem die Kompatibilität mit der vorherigen Version für Nachrichten und Interaktionen zwischen Brokern gewährleistet wird.
Broker sind mit einem
ZooKeeper -
Servercluster verbunden , der als vorgegebene Konfigurationsregistrierung fungiert und zur Koordinierung der Rollen der einzelnen Broker verwendet wird. ZooKeeper selbst ist ein verteiltes System, das durch Informationsreplikation durch Einrichtung eines
Quorums eine hohe Verfügbarkeit bietet.
Im Basisfall wird das Thema im Kafka-Cluster mit den folgenden Eigenschaften erstellt:
- Die Anzahl der Partitionen. Wie bereits erwähnt, hängt der hier verwendete genaue Wert von der gewünschten Stufe des gleichzeitigen Lesens ab.
- Der Replikationskoeffizient (Faktor) bestimmt, wie viele Brokerinstanzen im Cluster die Protokolle für diese Partition enthalten sollen.
Mit ZooKeepers zur Koordination versucht Kafka, neue Partitionen fair zwischen den Brokern im Cluster zu verteilen. Dies erfolgt durch eine Instanz, die als Controller fungiert.
Zur Laufzeit
für jede Partition des Themas weist der Controller dem Broker die Rollen von
Leader (Leader, Master, Leader) und
Followern (Follower, Slaves, Subordinates) zu. Der Broker, der als Leiter dieser Partition fungiert, ist dafür verantwortlich, alle von den Herstellern an ihn gesendeten Nachrichten zu empfangen und Nachrichten an die Verbraucher zu verteilen. Wenn Sie Nachrichten an eine Themenpartition senden, werden diese auf alle Brokerknoten repliziert, die als Follower für diese Partition fungieren. Jeder Knoten, der die Protokolle für die Partition enthält, wird als
Replikat bezeichnet . Ein Broker kann für einige Partitionen als Leader und für andere als Follower fungieren.
Ein Follower, der alle vom Leader gespeicherten Nachrichten enthält, wird als
synchronisiertes Replikat bezeichnet (ein Replikat in einem synchronisierten Zustand, synchrones Replikat). Wenn der Broker, der als Leader für die Partition fungiert, nicht verbunden ist, kann jeder Broker, der sich für diese Partition im aktualisierten oder synchronisierten Zustand befindet, die Rolle des Leader übernehmen. Dies ist ein unglaublich nachhaltiges Design.
Teil der Konfiguration des Herstellers ist der Parameter
acks , der bestimmt, wie viele Replikate den Empfang einer Nachricht bestätigen sollen, bevor der Anwendungsstrom weiter sendet: 0, 1 oder alle. Wenn der Wert auf
all gesetzt ist, sendet der Leiter beim Empfang der Nachricht eine Bestätigung an den Produzenten zurück, sobald er eine Bestätigung von den verschiedenen Replikaten (einschließlich sich selbst) erhält, die in der
Themeneinstellung min.insync.replicas (standardmäßig 1) definiert sind. Wenn die Nachricht nicht erfolgreich repliziert werden kann,
löst der Hersteller eine Ausnahme für die Anwendung aus (
NotEnoughReplicas oder
NotEnoughReplicasAfterAppend ).
In einer typischen Konfiguration wird ein Thema mit einem Replikationskoeffizienten von 3 (1 Leader, 2 Follower für jede Partition) erstellt und der Parameter min.insync.replicas auf 2 gesetzt. In diesem Fall kann einer der Broker, die die Partition verwalten, vom Cluster getrennt werden ohne Auswirkungen auf Client-Anwendungen.Dies bringt uns zurück zu dem bereits bekannten Kompromiss zwischen Leistung und Zuverlässigkeit. Die Replikation erfolgt aufgrund der zusätzlichen Wartezeit für Bestätigungen (Bestätigungen) von Followern. Da die Replikation von mindestens drei Knoten parallel ausgeführt wird, hat sie dieselbe Leistung wie zwei (ohne Berücksichtigung der Zunahme der Netzwerkbandbreitennutzung).Mit diesem Replikationsschema vermeidet Kafka geschickt die Notwendigkeit, jede Nachricht mithilfe der Operation sync () physisch auf die Festplatte zu schreiben . Jede vom Produzenten gesendete Nachricht wird in das Partitionsprotokoll geschrieben. Wie in Kapitel 2 erläutert, wird das Schreiben in die Datei zunächst im Betriebssystempuffer ausgeführt. Wenn diese Nachricht auf eine andere Instanz von Kafka repliziert wird und sich in seinem Speicher befindet, bedeutet der Verlust eines Anführers nicht, dass die Nachricht selbst verloren gegangen ist - eine synchronisierte Replik kann sie auf sich nehmen.Deaktivieren Sie den Betrieb von sync ()bedeutet, dass Kafka Nachrichten mit der Geschwindigkeit empfangen kann, mit der sie in den Speicher geschrieben werden können. Umgekehrt ist es umso besser, je länger Sie vermeiden können, Speicher auf die Festplatte zu leeren. Aus diesem Grund ist es für Kafka-Broker nicht ungewöhnlich, 64 GB oder mehr Speicher zuzuweisen. Diese Speichernutzung bedeutet, dass eine Instanz von Kafka problemlos mit einer Geschwindigkeit arbeiten kann, die viele tausend Mal schneller ist als ein herkömmlicher Nachrichtenbroker.Kafka kann auch für die Verwendung von sync () konfiguriert werden.zu Nachrichtenpaketen. Da alles bei Kafka paketorientiert ist, funktioniert es für viele Anwendungsfälle ziemlich gut und ist ein nützliches Werkzeug für Benutzer, die sehr starke Garantien benötigen. Der größte Teil der reinen Leistung von Kafka bezieht sich auf Nachrichten, die in Form von Paketen an den Broker gesendet werden, und auf die Tatsache, dass diese Nachrichten in aufeinanderfolgenden Blöcken mithilfe von Nullkopiervorgängen vom Broker gelesen werden (Vorgänge, bei denen keine Daten aus einem Speicherbereich kopiert werden) ein anderer). Letzteres ist ein großer Gewinn in Bezug auf Leistung und Ressourcen und nur durch die Verwendung der zugrunde liegenden Protokolldatenstruktur möglich, die das Partitionsschema definiert.In einem Kafka-Cluster ist eine viel höhere Leistung möglich als bei Verwendung eines einzelnen Kafka-Brokers, da die Themenpartitionen auf vielen separaten Computern horizontal skaliert werden können.Zusammenfassung
In diesem Kapitel haben wir untersucht, wie die Kafka-Architektur die Beziehung zwischen Clients und Brokern neu interpretiert, um eine unglaublich robuste Messaging-Pipeline bereitzustellen, deren Bandbreite um ein Vielfaches höher ist als bei einem normalen Nachrichtenbroker. Wir haben die Funktionen erörtert, mit denen dieses Ziel erreicht wird, und kurz die Architektur der Anwendungen überprüft, die diese Funktionen bereitstellen. Im nächsten Kapitel werden wir allgemeine Probleme diskutieren, die Messaging-Anwendungen lösen müssen, und Strategien zu ihrer Lösung diskutieren. Wir schließen das Kapitel mit einer Beschreibung der allgemeinen Beschreibung von Messaging-Technologien ab, damit Sie deren Eignung für Ihre Anwendungsfälle bewerten können.Übersetzung abgeschlossen: tele.gg/middle_javaFortsetzung folgt...