Im Internet bleiben Captchas weiterhin relevant. Optional können Sie den Text aus dem Bild durch Klicken auf die entsprechende Schaltfläche anhören. Wenn jemand mit dem Bild unten vertraut ist und / oder daran interessiert ist, wie man es mit einem Offline-Tonerkennungssystem umgehen kann, wird empfohlen, es zu lesen.
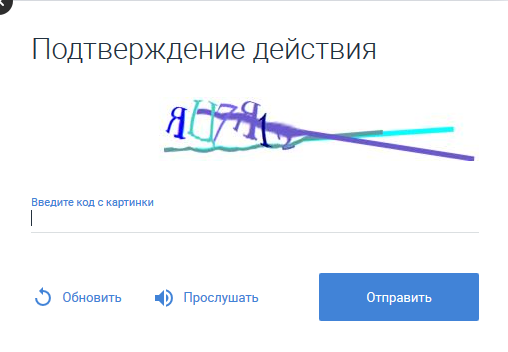
Wir werden die Intrigen von Experten auf dem Gebiet der Spracherkennung nicht quälen und sofort feststellen, dass kein proprietäres Spracherkennungssystem für die angegebenen Zwecke entwickelt wurde. Der Artikel verwendet die gute alte Pocketsphinx, jedoch mit einem gewissen Grad an Anpassung.
Vorbereitung
"Sie laufen in das Büro von Konkurrenten, die über Sprachsteuerung auf Computern verfügen, rufen" Sudo Era minus Eref Home "und rennen weg." Aus den Kommentaren.
Das Captcha bietet also an, sich selbst anzuhören, indem Sie auf die entsprechende Schaltfläche klicken. Wenn Sie die resultierende Sounddatei speichern, können Sie in .mp3 herausfinden, wie es sich um ein kurzes Stück Audio handelt. Gleichzeitig werden, wie sich herausstellte, Captchas mit weiblicher oder männlicher Stimme angeboten. Das "Zeichnen" der gleichen Geräusche, die von einem Mann und einer Frau gemacht werden, ist unterschiedlich:
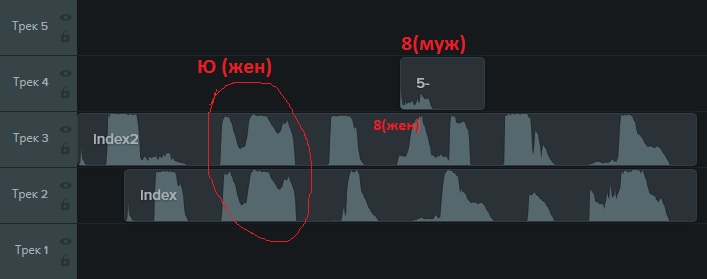
Sie klingen sowohl Buchstaben (und Russisch) als auch Zahlen.
Auf den ersten Blick ist alles traurig. Aber es gibt einen positiven Punkt darin, dass die Töne für die gleichen Buchstaben zusammenfallen.
Bisher hilft dieses Wissen nicht viel. Wie kann man das alles in das Paket der Sphinx schieben?
Installieren Sie Pocketsphinx, ein russisches Soundmodell
* Es gibt
einen Artikel über Habré, in dem der Ton über die Umleitung der Tonausgabe online an den Google Übersetzer weitergeleitet wird. Und dies könnte diesen Beitrag beenden, wenn all dies für diesen Fall funktioniert.
Die Installation von Pocketsphinx selbst unter Windows (und auch unter Linux) ist nicht sehr kompliziert -
herunterladen , installieren.
Da Pocketsphinx standardmäßig mit einer englischen Sprache, akustischen Modellen und einem Wörterbuch geliefert wird, benötigen Sie für die russische Sprache alle gleich.
Laden Sie die russische Version herunter -
Link .
Nachdem Sie das russische Modell in die Dateistruktur entpackt haben, können Sie die Test-WAV-Datei decoder-text.wav mit dem folgenden Python-Code testen:
import os from pocketsphinx import AudioFile, get_model_path, get_data_path
Der Inhalt der Audiodatei sollte in der Zeile "Ilya Ilf Evgeny Petrov Golden Calf" angezeigt werden.
Wenn es nicht ausgegeben wird (wie in meiner Situation), müssen Sie decoder-test.wav in ein anderes Audioformat konvertieren.
Dafür benötigen Sie ffmpeg.
Ffmpeg
Fügen Sie nach dem Herunterladen des Dienstprogramms ffmpeg decoder-test.wav in C: \ python3 \ ffmpeg \ bin ein.
Konvertieren Sie als Nächstes die Befehlszeile:
ffmpeg -i decoder-test.wav -ar 16000 decoder-test-.wav
Korrigieren Sie als Nächstes den Link zur Quell-Audiodatei im Python-Code:
'audio_file': os.path.join(data_path, 'C://python3//decoder-test-.wav'),
Nun, nachdem Sie den Code ausgearbeitet haben:

Es stimmt, Sie müssen bis zum zweiten Mal warten, der Code arbeitet sehr langsam - ungefähr 20 Sekunden.
Wir konvertieren Audio-Captcha nach dem gleichen Prinzip von MP3 in WAV und füttern Audio von Captcha. Schauen Sie sich den Code an:

Eine Art Unwissenheit, aber es gibt ein Ergebnis. Es wäre viel schlimmer gewesen, wenn nichts herausgebracht worden wäre. Wie bei einer Frauenstimme:

Mal sehen, wie man das Ergebnis verbessert und gleichzeitig beschleunigt.
Wortschatz
Sie benötigen Ihr eigenes Wörterbuch. In diesem Fall besteht es aus allen Buchstaben des russischen Alphabets (außer b, s, b) und Zahlen.
Alle Zeichen müssen in einer einfachen Textdatei platziert werden, eines in jeder Zeile in UTF-8-Codierung.
Jetzt müssen Sie das Wörterbuch konvertieren.
Sie müssen Perl installieren (es ist erforderlich, damit der Konverter funktioniert).
Laden Sie als Nächstes das Projekt zum Konvertieren von
ru4sphinx herunter .
Und konvertieren Sie das zuvor erstellte Wörterbuch:
C:\ru4sphinx-master\ru4sphinx-master\text2dict> perl dict2transcript.pl my_dictionary.txt my_dictionary_out.txt.
Die Ausgabe ist ein Wörterbuch für die Arbeit:

Die Wörterbucherweiterung muss vom TXT- in das DIC-Format umbenannt werden, und die Datei selbst sollte an einem zugänglichen Ort abgelegt werden.
Im Python-Code geben wir den Speicherort des Wörterbuchs an, indem wir das alte Wörterbuch auskommentieren:
Führen Sie das Programm durch und sehen Sie das Ergebnis:

Besser, aber genauso langsam, und nicht alle Buchstaben sind korrekt identifiziert.
Erstellen Sie Ihr eigenes Modell
Dies erhöht die Arbeitsgeschwindigkeit und die Genauigkeit des Ergebnisses erheblich.
Lassen Sie uns einen kurzen Weg von den
Anweisungen gehen .
Folgen Sie dem
Link und laden Sie unser zuvor im TXT-Format (nicht .dic!) Erstelltes Wörterbuch auf die Website hoch:
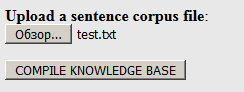
Klicken Sie auf "Kompilieren ...". Bei der Ausgabe können Sie das resultierende Paket im .tgz-Archiv herunterladen (es enthält alle erforderlichen Dateien):
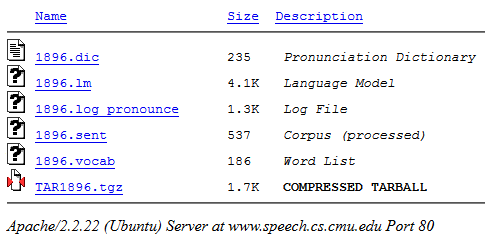
Als nächstes nehmen wir eine Datei mit der Erweiterung .lm (unser Modell) aus dem Archiv.
Korrigieren wir das Python-Erkennungsskript, indem wir das Modell durch ein neu erstelltes ersetzen:
Wir versuchen:

Es funktioniert viel schneller - weniger als eine Sekunde, außerdem sind alle Buchstaben definiert.
Aber hier ist eine kleine Bemerkung nötig.
Nicht alle Zeichen werden korrekt erkannt. Wenn anstelle des richtigen Buchstabens ein anderes Zeichen angezeigt wird, können Sie das zuvor erstellte .dic-Wörterbuch manuell korrigieren, indem Sie die Entsprechung des Buchstabens abgleichen.
Beispielsweise wird anstelle des Buchstabens a e angezeigt. Es ist notwendig, eine Zeile aus dem Wörterbuch e zu nehmen:
ryund
übertragen (löschen Sie den alten), ändern Sie den Buchstaben:
ryDa der Buchstabe "a" bereits im Wörterbuch enthalten ist, müssen Sie dem Buchstaben im Allgemeinen eine Seriennummer "(2)" (oder 3,4) hinzufügen, je nachdem, wie viele Töne bereits im Wörterbuch enthalten sind:
a(2) ryEine erneute Konvertierung des Wörterbuchs ist nicht erforderlich. Auf so einfache Weise können Sie fast Phoneme aller Buchstaben "aufnehmen".
Cherchez la femme
Modell- und Wortschatzarbeit, aber nicht mit weiblicher Stimme. Wenn die Stimme des Captcha weiblich ist, erhalten wir am Ausgang nichts. Das ist gleichzeitig gut und schlecht. Zuerst über das Gute.
Wenn Sie beim Starten des Programms nichts erkannt haben, handelt es sich um eine weibliche Stimme, sodass Sie "weibliche" Captchas filtern können.
Aber was soll man mit ihnen machen?
Hier müssen Sie mit Konvertierung arbeiten.
Beispielsweise betrug die Häufigkeit bei einem „männlichen“ Captcha 16000 und bei einem weiblichen „Captcha“ 24000:
ffmpeg -i acap(3).mp3 -ar 24000 acap(3)2.wav

Alle Töne werden definiert (in jeder Zeile nach Tönen), aber ihre Entsprechung ist lahm.
Es ist besser, ein separates Wörterbuch für das weibliche Modell zu erstellen und es dann zu bearbeiten.
Dies ist jedoch zum Selbststudium.
Nützliche Links:
1.home-smart-home.ru/raspberry-pi-pocketsphinx-offlajn-raspoznavanie-rechi-i-upravlenie-golosom2.https: //itnan.ru/post.php? C = 1 & p = 351376
3.
ru.wikipedia.org/wiki/Cherchez_la_femmeDateien:
1.
Das Programm .
2.
Das Modell .
3. Das
russische Modell .
4.
Wörterbuch .
5.
Captcha testen .
6.
ffmpeg .
7.
Eine Packung Captcha .