Bei der Arbeit am nächsten Projekt stritt sich das Team über die Verwendung des XML- oder SQL-Formats in Liquibase. Natürlich wurden bereits viele Artikel über Liquibase geschrieben, aber wie immer möchte ich meine Beobachtungen hinzufügen. Der Artikel enthält ein kleines Tutorial zum Erstellen einer einfachen Anwendung mit einer Datenbank und berücksichtigt den Unterschied in den Metainformationen für diese Typen.
Liquibase ist eine datenbankunabhängige Bibliothek zum Verfolgen, Verwalten und Anwenden von Datenbankschemaänderungen. Um Änderungen an der Datenbank vorzunehmen, wird eine Migrationsdatei (* Änderungssatz *) erstellt, die mit der Hauptdatei (* changeLog *) verbunden ist, die die Versionen steuert und alle Änderungen verwaltet.
XML- ,
YAML- ,
JSON- und
SQL- Formate werden verwendet, um die Struktur und Änderungen der Datenbank zu beschreiben.
Das Grundkonzept der Datenbankmigration lautet wie folgt:
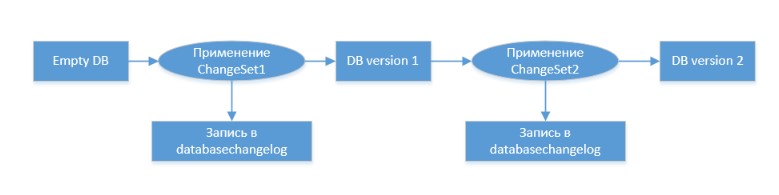
Weitere Informationen zu Liquibase finden Sie
hier oder
hier . Ich hoffe, das Gesamtbild ist klar, also fahren wir mit der Erstellung des Projekts fort.
Das Testprojekt verwendet
- Java 8
- Frühlingsstiefel
- Maven
- H2
- gut liquibase selbst
Projekterstellung und Abhängigkeiten
Die Verwendung von Spring-Boot ist hier nicht bedingt, Sie können nur ein Maven-Plugin für rollierende Skripte erstellen. Also fangen wir an.
1. Erstellen Sie ein Maven-Projekt in der IDE und fügen Sie der POM-Datei die folgenden Abhängigkeiten hinzu:
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.liquibase</groupId> <artifactId>liquibase-core</artifactId> <version>3.6.3</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope> </dependency> </dependencies>
2. Erstellen Sie im Ressourcenordner die Datei application.yml und fügen Sie die folgenden Zeilen hinzu:
spring: liquibase: change-log: classpath:/db/changelog/db.changelog-master.yaml datasource: url: jdbc:h2:mem:test; platform: h2 username: sa password: driverClassName: org.h2.Driver h2: console: enabled: true
Liquibase-Zeile: Änderungsprotokoll: Klassenpfad: /db/changelog/db.changelog-master.yaml - gibt an, wo sich die Liquibase-Skriptdatei befindet.
3. Erstellen Sie im Ressourcenordner entlang des Pfads db.changelog-master die folgenden Dateien:
- xmlSchema.xml - Skript im XML-Format ändern
- sqlSchema.sql - Skript für Änderungen im SQL-Format
- data.xml - Daten zur Tabelle hinzufügen
- db.changelog-master.yml - Liste der changeSets
4. Hinzufügen von Daten zu Dateien:
Für den Test müssen Sie zwei nicht verwandte t erstellen
Tabellen und der minimale Datensatz.
In der Datei sqlSchema.sql fügen wir jedem die bekannte SQL-Syntax hinzu:
Die Verwendung von SQL als Changeet wird durch einfaches Scripting vorangetrieben. In den Dateien versteht jeder das übliche SQL.
Ein Kommentar wird verwendet, um das Änderungsset zu trennen:
--changeset TestUsers_sql: 1 mit der Änderungsnummer und dem Nachnamen
(Parameter finden Sie
hier .)
Fügen Sie in der Datei xmlSchema.sql das von liquibase bereitgestellte DSL hinzu: <?xml version="1.0" encoding="UTF-8"?> <databaseChangeLog xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.6.xsd"> <changeSet id="Create table test_xml_table" author="TestUsers_xml"> <createTable tableName="test_xml_table"> <column name="name" type="character varying"> <constraints primaryKey="true" nullable="false"/> </column> <column name="description" type="character varying"/> </createTable> </changeSet> <changeSet id="Create table test_xml_table_2" author="TestUsers_xml"> <createTable tableName="test_xml_table_2"> <column name="name" type="character varying"> <constraints primaryKey="true" nullable="false"/> </column> <column name="description" type="character varying"/> </createTable> </changeSet> </databaseChangeLog>
Dieses Format zur Beschreibung der Erstellung von Tabellen ist für verschiedene Datenbanken universell. Genau wie der Slogan von Java:
"Es ist einmal geschrieben, es funktioniert überall .
" Liquibase verwendet die XML-Beschreibung und kompiliert sie je nach ausgewählter Datenbank in spezifischen SQL-Code. Das ist sehr praktisch für allgemeine Parameter.
Jede Operation wird in einem separaten changeSet ausgeführt, das die ID und den Namen des Autors angibt. Ich denke, die in XML verwendete Sprache ist sehr einfach zu verstehen und muss nicht einmal erklärt werden.
5. Laden Sie die Daten auf unsere Platten hoch, dies ist nicht erforderlich, aber da die Platten hergestellt wurden, müssen Sie etwas in sie einfügen. Wir füllen die Datei data.xml mit folgenden Daten aus:
<?xml version="1.0" encoding="UTF-8"?> <databaseChangeLog xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.6.xsd"> <changeSet id="insert data to test_xml_table" author="TestUsers"> <insert tableName="test_xml_table"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_xml_table_2" author="TestUsers"> <insert tableName="test_xml_table_2"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_sql_table" author="TestUsers"> <insert tableName="test_sql_table"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_sql_table_2" author="TestUsers"> <insert tableName="test_sql_table_2"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> </databaseChangeLog>
Dateien für rollierende Tabellen werden erstellt, Daten für Tabellen werden erstellt. Es ist Zeit, all dies in einer gemeinsamen fortlaufenden Reihenfolge zu kombinieren und unsere Anwendung zu starten.
Fügen Sie unsere SQL- und XML-Dateien zur Datei db.changelog-master.yml hinzu:
databaseChangeLog: - include: # schema file: db/changelog/xmlSchema.xml - include: file: db/changelog/sqlSchema.sql # data - include: file: db/changelog/data.xml
Und jetzt, wo wir alles geschaffen haben. Führen Sie einfach unsere Anwendung aus. Sie können die Befehlszeile oder das Plugin zum Starten verwenden, aber wir erstellen nur die Hauptmethode und führen unsere SpringApplication aus.
Metadaten anzeigen
Nachdem wir unsere beiden Skripte ausgeführt haben, um die Tabellen zu erstellen und zu füllen, können wir uns die Tabelle databaseChangeLog ansehen und sehen, was zusammengerollt ist.

Das Ergebnis des Rollens von XML:
- Im ID-Feld aus den XML-Dateien wird eine Kopfzeile angezeigt, die der Entwickler auf changeSet verweist. Jedes einzelne changeSet ist eine separate Zeile in der Datenbank mit einem Titel und einer Beschreibung.
- Der Autor jeder Änderung wird angegeben.
SQL Roll Ergebnis:
- Es gibt keine detaillierten Informationen zu changeSet im ID-Feld von SQL-Dateien.
- Der Autor jeder Änderung wird nicht angegeben.
Eine weitere wichtige Schlussfolgerung zur Verwendung von XML ist das Rollback. Befehle wie "Tabelle erstellen", "Tabelle ändern" und "Spalte hinzufügen" werden bei Verwendung von XML automatisch zurückgesetzt. Bei SQL-Dateien muss jedes Rollback manuell geschrieben werden.
Fazit
Jeder wählt für sich selbst, was er verwenden möchte. Aber unsere Wahl fiel auf die XML-Seite. Detaillierte Metainformationen und der einfache Übergang zu anderen Datenbanken überwogen die Maßstäbe des beliebtesten SQL-Formats aller.