Hallo! Aus der Überschrift haben Sie bereits verstanden, worüber ich sprechen werde. Es wird viel Hardcore geben:
Wir werden Java, C, C ++, Assembler, ein bisschen Linux, ein bisschen Kernel des Betriebssystems diskutieren. Wir werden auch einen praktischen Fall analysieren, sodass der Artikel aus drei großen Teilen besteht (ziemlich umfangreich).
Im ersten Schritt werden wir versuchen, alles aus den vorhandenen Profilern herauszuholen.
Im zweiten Teil erstellen wir unseren eigenen kleinen Profiler, und im dritten Teil erfahren Sie, wie Sie Profile erstellen, die für Profile nicht üblich sind, da vorhandene Tools dafür nicht sehr geeignet sind. Wenn Sie bereit sind, diesen Weg zu gehen - ich warte unter dem Schnitt auf Sie :)
Inhalt
Zeit und Mittel zum Verständnis - Profiler
Aus alltäglicher Sicht ist 1 Sekunde sehr klein. Aber wir wissen, dass 1 Sekunde eine ganze Milliarde Nanosekunden ist. Und lassen Sie es in nur 1 Nanosekunde ungefähr 4 Prozessorzyklen dauern. In 1 Sekunde werden im Computer viele Dinge erledigt, die unser Leben verbessern oder verschlechtern können.
Angenommen, wir entwickeln eine Anwendung, die an sich kritisch genug ist, um zu beschleunigen, und für einige Codefragmente ist dies im Allgemeinen kritisch. Diese Teile werden beispielsweise Hunderte von Mikrosekunden ausgeführt - schnell genug, aber sie [
Codeabschnitte ] wirken sich direkt auf den Erfolg unserer Anwendung und den Betrag des verdienten oder verlorenen Geldes aus. Zum Beispiel
Beim Senden von Aufträgen zum Abschluss von Umtauschtransaktionen kann eine Verzögerung von 100 Mikrosekunden den Umtausch 1 Million Rubel oder mehr für jede Transaktion kosten, die von einem, nicht zwei oder sogar nicht hundert abgeschlossen wird.
Und die
Aufgabe war für mich gestellt: Einerseits müssen Sie alle Bestellungen gleichzeitig senden und andererseits müssen Sie sie senden, damit die Abweichung zwischen der ersten und der letzten minimal ist. Das heißt, es war notwendig, eine Funktion zu profilieren, die Bestellungen an die Börse sendet. Eine typische Aufgabe, abgesehen von einer kleinen Nuance: Die charakteristische Ausführungszeit dieser Funktion beträgt
deutlich weniger als 100 μs .
Lassen Sie uns darüber nachdenken, wie wir diese 100 μs profilieren, um zu verstehen, was im Inneren geschieht.
Was ist bei der Auswahl dieses Tools zu beachten?
- Der Codeabschnitt, der uns interessiert, wird selten ausgeführt, dh 100 Mikrosekunden werden irgendwo einmal pro Sekunde ausgeführt. Und das auf dem Prüfstand und in der Produktion noch weniger.
- Es wird schwierig sein, diesen Code in ein Mikrobenchmark zu isolieren, da er einen wesentlichen Teil des Projekts und sogar die Eingabe / Ausgabe über das Netzwerk betrifft.
- Und schließlich möchte ich vor allem, dass das resultierende Profil dem Verhalten auf unseren Produktionsservern entspricht.
Wie berücksichtigen wir all diese Nuancen und profilieren die interessierende Methode korrekt?
Konzeptionell können alle Profiler in zwei Gruppen von Profilern unterteilt werden, die
instrumentieren oder
abtasten . Betrachten wir jede Gruppe einzeln.
Werkzeugprofiler verursachen einen erheblichen Aufwand, da sie unseren Bytecode ändern und einen Zeitdatensatz einfügen. Daher der Hauptnachteil solcher Profiler: Sie können den ausführbaren Code erheblich beeinflussen. Infolgedessen ist es schwierig zu sagen, inwieweit das resultierende Profil dem Verhalten auf Produktionsservern entspricht: Einige Optimierungen funktionieren möglicherweise anders, andere passieren und andere nicht. Vielleicht erhalten wir auf anderen Zeitskalen - Sekunden, Minuten, Stunden - repräsentative Daten. Auf einer Skala von 100 μs kann eine ausgelöste oder fehlgeschlagene Optimierung dazu führen, dass das Profil völlig nicht repräsentativ ist. Schauen wir uns also eine andere Gruppe von Profilern genauer an.
Stichprobenprofiler tragen entweder zu einem minimalen oder moderaten Overhead bei. Diese Tools wirken sich nicht direkt auf den ausführbaren Code aus, und ihre Verwendung erfordert etwas mehr Aufmerksamkeit von Ihnen. Daher werden wir uns mit den Samping-Profilern befassen. Mal sehen, welche Daten und in welcher Form wir von ihnen erhalten.
Wie funktionieren Sampling-Profiler?
Betrachten Sie das folgende Beispiel, um zu verstehen, wie ein Stichprobenprofiler funktioniert: Die
sendToMoex- Methode ruft mehrere andere Methoden auf. Wir schauen:
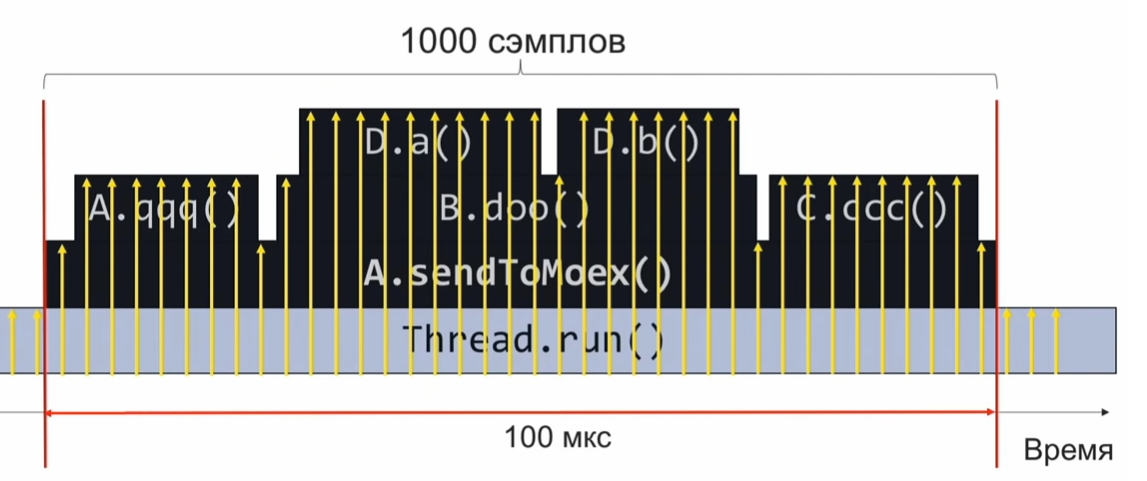
void sendToMoex() { a.qqq(); b.doo(); c.ccc() } void doo() { da(); db(); }
Wenn wir den Status des Aufrufstapels zum Zeitpunkt der Ausführung dieses Programmabschnitts überwachen und regelmäßig aufzeichnen, erhalten wir Informationen in folgender Form:

Dies ist eine Reihe von Call-Stacks. Unter der Annahme, dass die Samples gleichmäßig verteilt sind, gibt die Anzahl identischer Stapel die relative Ausführungszeit der Methode an, die sich oben auf dem Stapel befindet.
In diesem Beispiel wurde die Da-Methode genauso oft durchgeführt wie die C.ccc-Methode, und dies ist das Zweifache der Db-Methode. Die Annahme, dass die Verteilung der Stichproben sogar gleichmäßig ist, ist jedoch möglicherweise nicht vollständig korrekt, und dann ist die Schätzung der Ausführungszeit falsch.
Wie oft müssen wir probieren?
Angenommen, wir möchten 1000 Samples in 100 Mikrosekunden aufnehmen, um zu verstehen, was im Inneren abgespielt wurde. Als nächstes berechnen wir mit einem einfachen Anteil, dass wenn wir 1000 Proben in 100 μs machen müssen, es 10 Millionen Proben in 1 Sekunde oder 10.000.000 Proben / s sind.
Wenn wir mit dieser Geschwindigkeit abtasten, werden wir in einer Ausführung des Codes 1000 Beispiele sammeln, aggregieren und verstehen, was schnell oder langsam funktioniert hat. Danach werden wir die Leistung analysieren und den Code anpassen.
Eine Frequenz von 10 Millionen Abtastungen pro Sekunde ist jedoch viel. Und wenn wir von Anfang an eine solche Geschwindigkeit der Profilerstellung nicht erreichen? Angenommen, wir haben für 10 μs nur 10 Proben gesammelt, nicht 1000. In diesem Fall müssen wir auf die nächste Ausführung des Profilcodes warten, die nach 1 Sekunde erfolgt (schließlich wird der Profilcode einmal pro Sekunde ausgeführt). Also werden wir 10 weitere Proben sammeln. Da sie bei uns gleichmäßig verteilt sind, können sie zu einem gemeinsamen Satz zusammengefasst werden. Es reicht zu warten, bis der Profilcode 1000/10 = 100 Mal ausgeführt wird, und wir werden die erforderlichen 1000 Proben (jeweils 10 Proben von 100 Mal) sammeln.
Wählen Sie einen Profiler
Mit diesem theoretischen Wissen können wir weiter üben.
Nehmen Sie den
Async-Profiler. Ein großartiges Tool (verwendet den Aufruf der virtuellen Maschine AsyncGetCallTrace), das den Aufrufstapel bis zur Anweisung des Bytecodes der virtuellen Java-Maschine sammelt. Die native Async-Profiler-Abtastrate beträgt
1000 Abtastungen pro Sekunde .
Wir werden ein einfaches Verhältnis lösen: 10.000.000 Proben / Sek. - 1 Sekunde, 1000 Proben / Sek. - X Sekunden.
Wir erhalten, dass bei der Standardabtastfrequenz des Async-Profilers die Profilerstellung etwa 3 Stunden dauert. Das ist lang. Idealerweise möchte ich das Profil so schnell wie möglich mit der Superluminalgeschwindigkeit zusammenbauen.
Versuchen wir, den
Async-Profiler zu übertakten. Dazu finden wir in der Readme-
-i Flag
-i , das das Abtastintervall festlegt. Versuchen wir, das Flag
-i1 (1 Nanosekunde) oder
-i0 im Allgemeinen zu setzen, damit der Profiler ohne Unterbrechung
-i0 . Ich habe eine Frequenz von ungefähr 2,5 Tausend Proben pro Sekunde. In diesem Fall beträgt die Gesamtdauer der Profilerstellung ca. 1 Stunde. Natürlich nicht 3 Stunden, aber auch nicht sehr schnell. Es scheint, dass Sie, um die erforderlichen Profilierungsgeschwindigkeiten zu erreichen, etwas qualitativ anderes tun müssen, um ein neues Niveau zu erreichen.
Um deutlich höhere Frequenzen zu erreichen, müssen Sie den AsyncGetCallTrace-Aufruf abbrechen und
perf verwenden , den Vollzeit-Linux-Profiler, der in jeder Linux-Distribution enthalten ist. Perf weiß jedoch nichts über Java, und wir müssen perf noch trainieren, um mit Java zu arbeiten. Lassen Sie uns in der Zwischenzeit versuchen, Perf auf diese beängstigende Weise auszuführen:
$ perf record –F 10000 -p PID -g -- sleep 1 [ perf record: Woken up 1 times to write data ] [ perf record: .. 0.215 MB perf.data (4032 samples) ]
Mehr zur Notation- perf record bedeutet, dass wir ein Profil aufnehmen möchten.
- Das
-F Flag und das Argument 10.000 sind die Abtastrate. - Das Flag
-p gibt an, dass wir nur die spezifische PID unseres Java-Prozesses profilieren möchten. - Das Flag
-g ist für das Sammeln von Anrufstapeln verantwortlich. - Schließlich beschränken wir mit Schlaf 1 den Profileintrag auf 1 Sekunde.
Warum müssen wir Call Stacks sammeln? Wir profilieren alles in einer Reihe und extrahieren dann aus den gesammelten Daten den Teil, der uns interessiert (die Methode, die für die Bildung und den Versand von Bestellungen verantwortlich ist). Der Marker, dass die gesammelte Stichprobe zu den Daten gehört, an denen wir interessiert sind, ist das Vorhandensein des
Stapelrahmens des Methodenaufrufs
sendToMoex .
Erfahren Sie, wie Sie ein Java-Anwendungsprofil erstellen.
Wir führen den Befehl perf record ... aus, warten 1 Sekunde und führen das perf-Skript aus, um zu sehen, was profiliert wurde. Und wir werden etwas sehen, das nicht sehr klar ist:
$ perf script java 8079 2008793.746571: 3745505 cycles:uppp: 7fa1e88b53f8 [unknown] (/tmp/perf-11038.map) java 8079 2008793.747565: 3728336 cycles:uppp: 7fa1e88b5372 [unknown] (/tmp/perf-11038.map) java 8079 2008793.748613: 3731147 cycles:uppp: 7fa1e88b53ef [unknown] (/tmp/perf-11038.map)
Es scheinen Adressen zu sein, aber es gibt keine Namen von Java-Methoden. Sie müssen also perf lehren, um diese Adressen mit den Namen der Methoden abzugleichen.
In der Welt von C und C ++ werden sogenannte Debugging-Informationen verwendet, um Adressen und Funktionsnamen abzugleichen. Eine Korrespondenz wird in einem speziellen Abschnitt der ausführbaren Datei gespeichert: Eine Methode liegt an solchen Adressen, eine andere Methode liegt an anderen Adressen. Perf ruft diese Informationen auf und führt ein Mapping durch.
Offensichtlich generiert der JIT-Compiler der virtuellen Maschine keine Debugging-Informationen in diesem Format. Wir haben noch eine andere Möglichkeit - Daten über die Entsprechung von Adressen und Namen von Methoden in eine spezielle Perf-Map-Datei zu schreiben, die perf als Ergänzung zu den gelesenen Debugging-Informationen behandelt. Diese Perf-Map-Datei muss sich im Ordner tmp befinden und die folgende Datenstruktur aufweisen:
Die erste Spalte ist die Adresse des Anfangs des Methodencodes, die zweite ist seine Länge, die dritte Spalte ist der Name der Methode.
Wir müssen also eine ähnliche Datei generieren. Dies kann natürlich nicht manuell erfolgen (woher wissen wir, an welchen Adressen der JIT-Compiler den Code ablegt), daher verwenden wir das Skript create-java-perf-map.sh aus dem perf-map-agent-Projekt und übergeben ihm die PID unseres Java-Prozesses . Die Datei ist fertig, überprüfen Sie ihren Inhalt und führen Sie das Perf-Skript erneut aus.
$ perf script java 8080 1895245.867498: cycles:uppp: 7fb2dd10f527 Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868176: 2127960 cycles:uppp: 7fb2dd10f57f Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868737: 1959990 cycles:uppp: 7fb2dd10f627 Loop3.doRecursiveCall (/tmp/perf-8079.map)
Voila! Wir sehen die Namen der Java-Methoden! Was gerade passiert ist: Wir haben dem Perf Profiler, der nichts über Java weiß, beigebracht, eine reguläre Java-Anwendung zu profilieren und die heißen Java-Methoden dieser Anwendung zu sehen!
Um jedoch die Leistung des von uns abgefragten Programmteils zu analysieren, verfügen wir nicht über genügend Aufrufstapel, um die interessierenden Daten aus allen gesammelten Stichproben herauszufiltern.
Wie bekomme ich einen Call Stack?Jetzt müssen Sie etwas anderes mit perf oder einer virtuellen Maschine tun, um Call Stacks zu erhalten. Um zu verstehen, was zu tun ist, gehen wir einen Schritt zurück und sehen, wie der Stapel im Allgemeinen funktioniert. Stellen Sie sich vor, wir haben drei Funktionen f1, f2, f3. Außerdem ruft f1 f2 und f2 f3 auf.
void f1() { f2(); } void f2() { f3(); } void f3() { ... }
Lassen Sie uns zum Zeitpunkt der Ausführung der Funktion
f3 sehen, in welchem Zustand sich der Stapel befindet. Wir sehen das
rsp Register, das auf die Oberseite des Stapels zeigt. Wir wissen auch, dass der Stapel die Adresse des vorherigen Stapelrahmens hat. Und wie kann ich einen Call-Stack bekommen?
Wenn wir irgendwie die Adresse dieses Bereichs erhalten könnten, könnten wir uns den Stapel als einfach verbundene Liste vorstellen und die Reihenfolge der Aufrufe verstehen, die uns zum aktuellen Ausführungspunkt gebracht haben.
Was brauchen wir dafür? Wir brauchen ein zusätzliches rbp-Register, das auf den gelben Bereich zeigt. Es stellt sich heraus, dass das rbp-Register es perf ermöglicht, den Aufrufstapel abzurufen und die Sequenz zu verstehen, die uns zum aktuellen Punkt gebracht hat. Ich empfehle, diese Details in der
System V Application Binary Interface zu lesen. Es beschreibt, wie Methoden unter Linux aufgerufen werden.

Wir haben verstanden, was unser Problem ist. Wir müssen die virtuelle Maschine zwingen, das rbp-Register für seinen ursprünglichen Zweck zu verwenden - als Zeiger auf den Anfang des Stapelrahmens. So sollte der JIT-Compiler das rbp-Register verwenden. Hierfür gibt es in der virtuellen Maschine ein Flag PreserveFramePointer. Wenn wir dieses Flag an die virtuelle Maschine übergeben, beginnt die virtuelle Maschine, das rbp-Register für ihren traditionellen Zweck zu verwenden. Und dann kann Perf den Stapel drehen. Und wir bekommen einen echten Call-Stack im Profil. Die Flagge wurde von dem berüchtigten Brendan Gregg in nur JDK8u60 beigesteuert.
Wir starten die virtuelle Maschine mit einem neuen Flag. Führen Sie
create-java-perf-map und anschließend
perf record und
perf script . Jetzt können wir mit Call Stacks ein genaues Profil erstellen:
$ perf script java 18657 1901247.601878: 979583 cycles:uppp: 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7f285d007b10 Interpreter (...) 7f285d0004e7 call_stub (...) 67d0db [unknown] (... libjvm.so) ... 708c start_thread (... libpthread-2.26.so)
Wir haben dem Perf Profiler, der in den meisten Linux-Distributionen enthalten ist, beigebracht, mit Java-Anwendungen zu arbeiten. Daher können wir jetzt nicht nur die Hot-Abschnitte des Codes sehen, sondern auch die Reihenfolge der Aufrufe, die zum aktuellen Hotspot geführt haben. Eine großartige Leistung, da der Perf Profiler nichts über Java weiß. Wir haben das alles einfach gelehrt!
Erhöhen Sie die Perf-Abtastrate
Versuchen wir, die Leistung auf 10 Millionen Samples pro Sekunde zu übertakten. Jetzt haben wir eine deutlich niedrigere Frequenz.
Um alle Aufgaben zu automatisieren, die wir gerade ausgeführt haben, können Sie das Skript
perf-java-record-stack aus dem Projekt perf-map-agent verwenden. Er hat einen wunderbaren Stift - die Umgebungsvariable
perf_record-freq , mit der Sie die Abtastfrequenz einstellen können. Lassen Sie uns zunächst 100.000 Samples pro Sekunde einstellen und versuchen, sie auszuführen. In der Konsole wird eine schreckliche Meldung angezeigt, dass wir die maximal zulässige Abtastfrequenz überschritten haben:
$ PERF_RECORD_FREQ=100000 ./bin/perf-java-record-stack PID ... Maximum frequency rate (30000) reached. Please use -F freq option with lower value or consider tweaking /proc/sys/kernel/perf_event_max_sample_rate. ...
In meinem Fall lag die Grenze bei 30.000 Proben pro Sekunde. Perf sagt sofort, welches Kernel-Argument behoben werden muss, was wir entweder mit echo sudo tee für die gewünschte Datei oder direkt über
sysctl tun werden. Also:
$ echo '1000000' | sudo tee /proc/sys/kernel/perf_event_max_sample_rate
oder so:
$ sudo sysctl kernel.perf_event_max_sample_rate=1000000
Jetzt teilen wir dem Kernel mit, dass die Obergrenze der Frequenz jetzt 1 Million Samples pro Sekunde beträgt. Wir starten den Profiler erneut und geben die Häufigkeit von 200.000 Abtastungen pro Sekunde an. Der Profiler arbeitet 15 Sekunden lang und gibt uns 1 Million Proben. Alles scheint in Ordnung zu sein. Zumindest keine gewaltigen Fehlermeldungen. Aber welche Frequenz haben wir tatsächlich bekommen? Es stellt sich heraus, dass nur 70.000 Proben pro Sekunde. Was ist schief gelaufen?
Sehen wir uns die Ausgabe des
dmesg :
[84430.412898] perf: interrupt took too long (1783 > 200), lowering kernel.perf_event_max_sample_rate to 89700 ... [84431.618452] perf: interrupt took too long (2229 > 2228), lowering kernel.perf_event_max_sample_rate to 71700
Dies ist die Ausgabe des Linux-Kernels. Es wurde festgestellt, dass wir zu oft abtasten und es zu lange dauert, sodass der Kernel die Frequenz senkt. Es stellt sich heraus, dass wir ein anderes Handle im Kernel abschrauben müssen - es heißt
kernel.perf_cpu_time_max_percent und steuert die Zeit, die der Kernel für Interrupts von perf
kernel.perf_cpu_time_max_percent kann.
Wir werden eine Abtastfrequenz von 200.000 Abtastungen pro Sekunde bestellen. Und nach 15 Sekunden erhalten wir 3 Millionen Proben - 200.000 Proben pro Sekunde.
$ PERF_RECORD_FREQ=200000 ./bin/perf-java-record-stack PID Recording events for 15 seconds ... ... [ perf record: Captured ... (2.961.252 samples) ]
Nun sehen wir uns das Profil an. Führen Sie das
perf script :
$ perf script ... java ... native_write_msr (/.../vmlinux) java ... Loop2.main (/tmp/perf-29621.map) java ... native_write_msr (/.../vmlinux) ...
Wir sehen seltsame Funktionen und das ausführbare vmlinux-Modul - den Linux-Kernel. Dies ist definitiv nicht unser Code. Was ist passiert? Die Frequenz war so hoch, dass der Kernel-Code in die Samples fiel. Das heißt, je höher wir die Frequenz erhöhen, desto mehr Beispiele gibt es, die sich nicht auf unseren Code, sondern auf den Linux-Kernel beziehen.
Sackgasse.
Wir verwenden (explizit) Hardware-PMU / PEBS-Ereignisse
Dann entschied ich mich für die Verwendung der PMU / PEBS-Hardwaretechnologie - Performance Monitoring Unit, Precise Event Based Sampling. Sie können Benachrichtigungen erhalten, dass ein Ereignis eine bestimmte Anzahl von Malen aufgetreten ist. Dies wird als "Periode" bezeichnet. Beispielsweise können wir Benachrichtigungen über die Ausführung jeder 20. Anweisung durch den Prozessor erhalten. Schauen wir uns ein Beispiel an. Lassen Sie den xor-Befehl jetzt ausgeführt werden, und der PMU-Zähler erhält den Wert 18; dann kommt die mov-Anweisung - der Zähler ist 19; und die nächste Anweisung,
% r14,% r13 hinzufügen , PMU wird als "heiß"
angezeigt .
Dann beginnt ein neuer Zyklus:
inc wird ausgeführt - die PMU wird auf 1 zurückgesetzt. Einige weitere Iterationen des Zyklus werden durchlaufen. Am Ende halten wir bei der
mov Anweisung an, die PMU schnappt 19. Die nächste add-Anweisung, und wieder markieren wir sie als heiß. Siehe die Auflistung:
mov aaa, bbbb xor %rdx, %rdx L_START: mov $0x0(%rbx, %rdx),%r14 add %r14, %r13 ; (PMU "") cmp %rdx,100000000 jne L_START
Bemerken Sie nicht die Kuriositäten? Ein Zyklus von fünf Anweisungen, aber jedes Mal markieren wir dieselbe Anweisung als heiß. Offensichtlich ist dies nicht wahr: Alle Anweisungen sind "heiß". Sie verbringen auch Zeit, und wir markieren nur eine. Tatsache ist, dass wir zwischen der Periode und dem Zähler der Anzahl der Anweisungen in der Iteration einen gemeinsamen Faktor 4 haben. Es stellt sich heraus, dass wir bei jeder vierten Iteration dieselbe Anweisung als "heiß" markieren. Um dieses Verhalten zu vermeiden, müssen Sie eine Zahl als Zeitraum auswählen, in dem die Wahrscheinlichkeit eines gemeinsamen Teilers zwischen der Anzahl der Iterationen in der Schleife und dem Zähler selbst minimiert wird. Idealerweise sollte die Periode eine Primzahl sein, d.h. Teilen Sie nur auf sich selbst und auf dem Gerät. Für das obige Beispiel: Sie sollten einen Zeitraum von 23 wählen. Dann würden wir alle Anweisungen in diesem Zyklus gleichmäßig als „heiß“ markieren.
Die PMU / PEBS-Technologie wird seit mindestens 2009 in ihrer modernen Form unterstützt, dh auf fast jedem Computer. Um es explizit anzuwenden, ändern wir das Skript
perf-java-record-stack . Ersetzen Sie das
-F Flag durch
-e , das die Verwendung von PMU / PEBS explizit angibt.
... sudo perf record -F $PERF_RECORD_FREQ ... ...
Das Skript transformieren:
... sudo perf record -e cycles –c 10007 ... ...
Sie wissen bereits, welche Eigenschaften eine Periode haben sollte - wir brauchen eine Primzahl. In unserem Fall wird es der Zeitraum 10007 sein.
Wir haben das modifizierte Perf-Java-Record-Stack-Skript gestartet und in 15 Sekunden 4,5 Millionen Samples empfangen - das sind fast 300.000 pro Sekunde, ein Sample alle 3 μs. Das heißt, für eine Ausführung unseres Profilcodes werden für 100 μs 33 Proben gesammelt. Bei dieser Frequenz beträgt die gesamte Profilerfassungszeit nur 30 Sekunden. Trinken Sie nicht einmal eine Tasse Kaffee! In Wirklichkeit ist alles etwas komplizierter. Was passiert, wenn unser Code nicht einmal pro Sekunde, sondern alle 5 Sekunden ausgeführt wird? Dann wird die Dauer der Profilerstellung auf 2,5 Minuten anwachsen, was ebenfalls ein anständiges Ergebnis ist.
So erhalten Sie in 30 Sekunden ein Profil, das alle unsere Forschungsbedürfnisse vollständig abdeckt. Sieg
Aber das Gefühl eines schmutzigen Tricks ließ mich nicht los. Kehren wir zu der Situation zurück, in der unser Code alle 5 Sekunden ausgeführt wird. Die Profilerstellung dauert dann 150 Sekunden. In dieser Zeit werden etwa 45 Millionen Proben gesammelt. Von diesen benötigen wir nur 1000, dh 0,002% der gesammelten Daten. Alles andere ist Müll, der die Arbeit anderer Werkzeuge verlangsamt und zusätzlichen Aufwand verursacht. Ja, das Problem ist gelöst, aber es ist in der Stirn gelöst, schmutzige, stumpfe Kraft.
Und an diesem Abend, als ich mit Hilfe von Perf zum ersten Mal ein so detailliertes Profil bekam, hatte ich einen Traum. Ich ging von der Arbeit nach Hause und dachte nach, aber es wäre schön, wenn das Eisen das Profil selbst und sogar die Genauigkeit von Mikrostrukturen und Mikrosekunden zusammensetzen könnte, und wir würden nur die Ergebnisse analysieren. Wird mein Traum wahr? Was meinen Sie?
Kurze Zusammenfassung:
- Um ein Profil einer Java-Anwendung mit perf zu erstellen, müssen Sie mithilfe von Skripten aus dem perf-map-agent-Projekt eine Datei mit Informationen zu Zeichen generieren
- Um Informationen nicht nur über wichtige Codeabschnitte, sondern auch über Stapel zu sammeln, müssen Sie eine virtuelle Maschine mit dem Flag -XX: + PreserveFramePointer ausführen
- Wenn Sie die Abtastfrequenz erhöhen möchten, sollten Sie auf sysctl'i und kernel.perf_cpu_time_max_percent und kernel.perf_event_max_sample_rate achten.
- Wenn Beispiele aus dem Kernel, die sich nicht auf die Anwendung beziehen, in das Profil aufgenommen werden, sollten Sie überlegen, den PMU / PEBS-Zeitraum explizit anzugeben.
Dieser Artikel (und seine nachfolgenden Teile) ist eine Abschrift des Berichts, die in Textform angepasst wurde. Wenn Sie nicht nur lesen, sondern auch über die Profilerstellung hören möchten,
verweisen Sie auf die Präsentation.