In mobilen Anwendungen ist die Suchfunktion sehr beliebt. Und wenn dies bei kleinen Produkten vernachlässigt werden kann, können Sie in Anwendungen, die Zugriff auf eine große Menge an Informationen bieten, nicht auf eine Suche verzichten. Heute werde ich Ihnen erklären, wie Sie diese Funktion in Programmen für Android korrekt implementieren.

Ansätze zur Implementierung der Suche in einer mobilen Anwendung
- Suche als Datenfilter
Normalerweise sieht es aus wie eine Suchleiste über einer Liste. Das heißt, wir filtern nur die fertigen Daten. - Serversuche
In diesem Fall geben wir die gesamte Implementierung an den Server weiter, und die Anwendung fungiert als Thin Client, von dem aus nur die Daten in der richtigen Form angezeigt werden müssen. - Integrierte Suche
- Die Anwendung enthält eine große Menge von Daten verschiedener Typen.
- Die Anwendung funktioniert offline.
- Die Suche wird als einzelner Zugriffspunkt auf Abschnitte / Inhalte der Anwendung benötigt.
Im letzteren Fall hilft die in SQLite integrierte Volltextsuche. Mit dieser Funktion können Sie sehr schnell Übereinstimmungen in einer großen Menge an Informationen finden, sodass wir mehrere Abfragen an verschiedene Tabellen durchführen können, ohne die Leistung zu beeinträchtigen.
Betrachten Sie die Implementierung einer solchen Suche anhand eines bestimmten Beispiels.
Datenaufbereitung
Angenommen , wir müssen eine Anwendung implementieren, die eine Liste der Filme von
themoviedb.org anzeigt . Nehmen Sie zur Vereinfachung (um nicht online zu gehen) eine Liste von Filmen und erstellen Sie daraus eine JSON-Datei, legen Sie sie in Assets ab und füllen Sie unsere Datenbank lokal.
Beispiel für eine JSON-Dateistruktur:
[ { "id": 278, "title": " ", "overview": " ..." }, { "id": 238, "title": " ", "overview": " , ..." }, { "id": 424, "title": " ", "overview": " ..." } ]
Datenbank füllen
SQLite verwendet virtuelle Tabellen, um die Volltextsuche zu implementieren. Äußerlich sehen sie wie normale SQLite-Tabellen aus, aber jeder Zugriff auf sie erledigt einige Backstage-Arbeiten.
Mit virtuellen Tabellen können wir die Suche beschleunigen. Neben den Vorteilen haben sie aber auch Nachteile:
- Sie können keinen Trigger für eine virtuelle Tabelle erstellen.
- Sie können die Befehle ALTER TABLE und ADD COLUMN nicht für eine virtuelle Tabelle ausführen.
- Jede Spalte in der virtuellen Tabelle ist indiziert. Dies bedeutet, dass Ressourcen für die Indizierung von Spalten verschwendet werden können, die nicht an der Suche beteiligt sein sollten.
Um das letztere Problem zu lösen, können Sie zusätzliche Tabellen verwenden, die einen Teil der Informationen enthalten, und Links zu Elementen einer regulären Tabelle in einer virtuellen Tabelle speichern.
Das Erstellen einer Tabelle unterscheidet sich geringfügig vom Standard. Wir haben die Schlüsselwörter
VIRTUAL und
fts4 :
CREATE VIRTUAL TABLE movies USING fts4(id, title, overview);
Kommentar zur fts5-VersionEs wurde bereits zu SQLite hinzugefügt. Diese Version ist produktiver, genauer und enthält viele neue Funktionen. Aufgrund der großen Fragmentierung von Android können wir fts5 (verfügbar mit API24) nicht auf allen Geräten verwenden. Sie können unterschiedliche Logik für verschiedene Versionen des Betriebssystems schreiben, dies erschwert jedoch die weitere Entwicklung und Unterstützung erheblich. Wir haben uns für den einfacheren Weg entschieden und fts4 verwendet, das auf den meisten Geräten unterstützt wird.
Das Befüllen unterscheidet sich nicht von üblich:
fun populate(context: Context) { val movies: MutableList<Movie> = mutableListOf() context.assets.open("movies.json").use { val typeToken = object : TypeToken<List<Movie>>() {}.type movies.addAll(Gson().fromJson(InputStreamReader(it), typeToken)) } try { writableDatabase.beginTransaction() movies.forEach { movie -> val values = ContentValues().apply { put("id", movie.id) put("title", movie.title) put("overview", movie.overview) } writableDatabase.insert("movies", null, values) } writableDatabase.setTransactionSuccessful() } finally { writableDatabase.endTransaction() } }
Basisversion
Bei der Ausführung der Abfrage wird anstelle von
LIKE das Schlüsselwort
MATCH verwendet:
fun firstSearch(searchString: String): List<Movie> { val query = "SELECT * FROM movies WHERE movies MATCH '$searchString'" val cursor = readableDatabase.rawQuery(query, null) val result = mutableListOf<Movie>() cursor?.use { if (!cursor.moveToFirst()) return result while (!cursor.isAfterLast) { val id = cursor.getInt("id") val title = cursor.getString("title") val overview = cursor.getString("overview") result.add(Movie(id, title, overview)) cursor.moveToNext() } } return result }
Um die Verarbeitung von Texteingaben in der Benutzeroberfläche zu implementieren, verwenden wir
RxJava :
RxTextView.afterTextChangeEvents(findViewById(R.id.editText)) .debounce(500, TimeUnit.MILLISECONDS) .map { it.editable().toString() } .filter { it.isNotEmpty() && it.length > 2 } .map(dbHelper::firstSearch) .subscribeOn(Schedulers.computation()) .observeOn(AndroidSchedulers.mainThread()) .subscribe(movieAdapter::updateMovies)
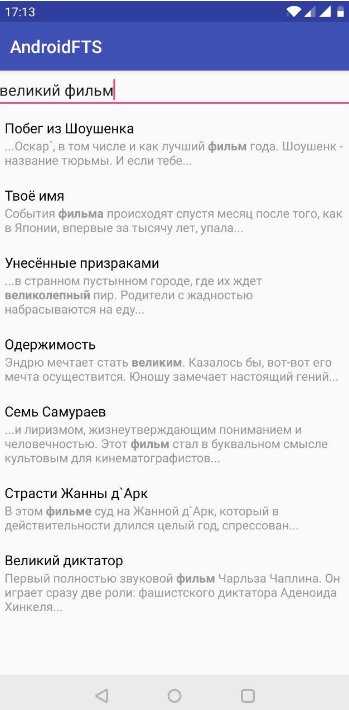
Das Ergebnis ist eine grundlegende Suchoption. Im ersten Element wurde das gewünschte Wort in der Beschreibung und im zweiten Element sowohl im Titel als auch in der Beschreibung gefunden. Offensichtlich ist in dieser Form nicht ganz klar, was wir gefunden haben. Lass es uns reparieren.
Akzente setzen
Um die Offensichtlichkeit der Suche zu verbessern, verwenden wir die Hilfsfunktion
SNIPPET . Es wird verwendet, um ein formatiertes Textfragment anzuzeigen, in dem eine Übereinstimmung gefunden wird.
snippet(movies, '<b>', '</b>', '...', 1, 15)
- Filme - Tabellenname;
- <b & gt und </ b> - Diese Argumente werden verwendet, um einen Textabschnitt hervorzuheben, der durchsucht wurde.
- ... - für die Gestaltung des Textes, wenn das Ergebnis ein unvollständiger Wert war;
- 1 - Spaltennummer der Tabelle, aus der Textstücke zugewiesen werden;
- 15 ist eine ungefähre Anzahl von Wörtern, die im zurückgegebenen Textwert enthalten sind.
Der Code ist identisch mit dem ersten, wobei die Anforderung nicht berücksichtigt wird:
SELECT id, snippet(movies, '<b>', '</b>', '...', 1, 15) title, snippet(movies, '<b>', '</b>', '...', 2, 15) overview FROM movies WHERE movies MATCH ''
Wir versuchen es erneut:
Es stellte sich deutlicher heraus als in der vorherigen Version. Dies ist jedoch nicht das Ende. Lassen Sie uns unsere Suche "vollständiger" machen. Wir werden die lexikalische Analyse verwenden und die wesentlichen Teile unserer Suchanfrage hervorheben.
Beende die Verbesserung
SQLite verfügt über integrierte Token, mit denen Sie eine lexikalische Analyse durchführen und die ursprüngliche Suchabfrage transformieren können. Wenn wir beim Erstellen der Tabelle keinen bestimmten Tokenizer angegeben haben, wird "einfach" ausgewählt. Tatsächlich konvertiert es nur unsere Daten in Kleinbuchstaben und verwirft unlesbare Zeichen. Es passt nicht ganz zu uns.
Für eine qualitative Verbesserung der Suche müssen wir
Stemming verwenden - den Prozess, bei dem die Basis eines Wortes für ein bestimmtes Quellwort gefunden wird.
SQLite verfügt über einen zusätzlichen integrierten Tokenizer, der den Porter Stemmer-Algorithmus verwendet. Dieser Algorithmus wendet nacheinander eine Reihe bestimmter Regeln an und hebt wichtige Teile eines Wortes hervor, indem Endungen und Suffixe abgeschnitten werden. Wenn wir beispielsweise nach "Schlüsseln" suchen, können wir eine Suche erhalten, bei der die Wörter "Schlüssel", "Schlüssel" und "Schlüssel" enthalten sind. Ich werde am Ende einen Link zu einer detaillierten Beschreibung des Algorithmus hinterlassen.
Leider funktioniert der in SQLite integrierte Tokenizer nur mit Englisch. Für die russische Sprache müssen Sie daher Ihre eigene Implementierung schreiben oder vorgefertigte Entwicklungen verwenden. Wir werden die fertige Implementierung von der
algorithmist.ru- Site übernehmen.
Wir wandeln unsere Suchanfrage in die erforderliche Form um:
- Entfernen Sie zusätzliche Zeichen.
- Brechen Sie die Phrase in Wörter.
- Überspringen Sie den Stemmer.
- Sammeln Sie in einer Suchabfrage.
Porter-Algorithmus object Porter { private val PERFECTIVEGROUND = Pattern.compile("((|||||)|((<=[])(||)))$") private val REFLEXIVE = Pattern.compile("([])$") private val ADJECTIVE = Pattern.compile("(|||||||||||||||||||||||||)$") private val PARTICIPLE = Pattern.compile("((||)|((?<=[])(||||)))$") private val VERB = Pattern.compile("((||||||||||||||||||||||||||||)|((?<=[])(||||||||||||||||)))$") private val NOUN = Pattern.compile("(|||||||||||||||||||||||||||||||||||)$") private val RVRE = Pattern.compile("^(.*?[])(.*)$") private val DERIVATIONAL = Pattern.compile(".*[^]+[].*?$") private val DER = Pattern.compile("?$") private val SUPERLATIVE = Pattern.compile("(|)$") private val I = Pattern.compile("$") private val P = Pattern.compile("$") private val NN = Pattern.compile("$") fun stem(words: String): String { var word = words word = word.toLowerCase() word = word.replace('', '') val m = RVRE.matcher(word) if (m.matches()) { val pre = m.group(1) var rv = m.group(2) var temp = PERFECTIVEGROUND.matcher(rv).replaceFirst("") if (temp == rv) { rv = REFLEXIVE.matcher(rv).replaceFirst("") temp = ADJECTIVE.matcher(rv).replaceFirst("") if (temp != rv) { rv = temp rv = PARTICIPLE.matcher(rv).replaceFirst("") } else { temp = VERB.matcher(rv).replaceFirst("") if (temp == rv) { rv = NOUN.matcher(rv).replaceFirst("") } else { rv = temp } } } else { rv = temp } rv = I.matcher(rv).replaceFirst("") if (DERIVATIONAL.matcher(rv).matches()) { rv = DER.matcher(rv).replaceFirst("") } temp = P.matcher(rv).replaceFirst("") if (temp == rv) { rv = SUPERLATIVE.matcher(rv).replaceFirst("") rv = NN.matcher(rv).replaceFirst("") } else { rv = temp } word = pre + rv } return word } }
Algorithmus, bei dem wir die Phrase in Wörter zerlegen val words = searchString .replace("\"(\\[\"]|.*)?\"".toRegex(), " ") .split("[^\\p{Alpha}]+".toRegex()) .filter { it.isNotBlank() } .map(Porter::stem) .filter { it.length > 2 } .joinToString(separator = " OR ", transform = { "$it*" })
Nach dieser Konvertierung sieht der Ausdruck "Innenhöfe und Geister" wie "Hof
* ODER Geist
* " aus.
Das Symbol "
* " bedeutet, dass die Suche durch das Auftreten eines bestimmten Wortes mit anderen Worten durchgeführt wird. Der Operator "
ODER " bedeutet, dass Ergebnisse angezeigt werden, die mindestens ein Wort aus der Suchphrase enthalten. Wir schauen:
Zusammenfassung
Die Volltextsuche ist nicht so kompliziert, wie es auf den ersten Blick erscheinen mag. Wir haben ein spezielles Beispiel analysiert, das Sie schnell und einfach in Ihr Projekt implementieren können. Wenn Sie etwas Komplizierteres benötigen, sollten Sie sich an die Dokumentation wenden, da es eine gibt und diese ziemlich gut geschrieben ist.
Referenzen: