
Deep Learning-Anwendungen haben viele Dinge verändert. Einige geben Hoffnung auf eine bessere Zukunft, andere erwecken Verdacht. Für Entwickler hat das Wachstum von Deep-Learning-Anwendungen sie jedoch verwirrter gemacht, die besten unter so vielen Deep-Learning-Frameworks auszuwählen.
TensorFlow ist eines der Deep-Learning-Frameworks, die in den Sinn kommen. Es ist wohl das beliebteste Deep-Learning-Framework da draußen. Nichts rechtfertigt die Aussage besser als die Tatsache, dass Tensorflow von Uber, Nvidia, Gmail und anderen großen Unternehmen für die Entwicklung modernster Deep-Learning-Anwendungen verwendet wird.
Aber im Moment bin ich auf der Suche, ob es tatsächlich das beste Deep-Learning-Framework ist. Oder vielleicht finden Sie heraus, was es aus allen anderen Frameworks, gegen die es konkurriert, am besten macht.
Hier erfahren Sie alles über TensorFlow 2.0
Die meisten Entwickler und Datenwissenschaftler bevorzugen die Verwendung von Python mit TensorFlow. TensorFlow läuft nicht nur auf Windows, Linux und Mac, sondern auch auf iOS- und Android-Betriebssystemen.
TF verwendet ein statisches Berechnungsdiagramm für Operationen. Dies bedeutet, dass Entwickler zuerst das Diagramm definieren, alle Berechnungen ausführen, bei Bedarf Änderungen an der Architektur vornehmen und dann das Modell neu trainieren. Im Allgemeinen können viele Konzepte des maschinellen Lernens und des Tiefenlernens mithilfe mehrdimensionaler Matrizen gelöst werden. Mit Tensorflow 2.0 können lineare Beziehungen zwischen geometrischen Objekten beschrieben werden. Tensor ist eine primitive Einheit, in der wir Matrixoperationen einfach und effektiv anwenden können.
import tensorflow as TF const1 = TF.constant([[05,04,03], [05,04,03]]); const2 = TF.constant([[01,02,00], [01,02,00]]); result = TF.subtract(const1, const2); print(result)
Die Ausgabe des obigen Codes sieht folgendermaßen aus: TF.Tensor([[04 02 03] [04 02 03]])
Wie Sie sehen können, habe ich hier zwei Konstanten angegeben und einen Wert vom anderen subtrahiert und durch Subtrahieren von zwei Werten ein Tensor-Objekt erhalten. Mit Tensorflow 2.0 müssen keine Sitzungen erstellt werden, bevor der Code ausgeführt wird.
Bevor Sie mit TensorFlow 2.0 arbeiten, sollten Sie wissen, dass Sie viel codieren müssen und nicht nur arithmetische Operationen mit TensorFlow ausführen müssen. Es geht mehr darum, Deep-Learning-Forschung zu betreiben, KI-Prädiktoren, Klassifikatoren, generative Modelle, neuronale Netze usw. zu erstellen. Sicher, TF hilft bei letzterem, aber wichtige Aufgaben wie das Definieren der Architektur des neuronalen Netzwerks, das Definieren eines Volumens für Ausgabe- und Eingabedaten müssen alle mit sorgfältigen menschlichen Überlegungen erledigt werden.
Der schnellste Weg, um diese KI-Modelle zu trainieren, ist die Tensor Processing Unit (TPUs), die Google 2016 eingeführt hat. TPU behandelt das Problem des neuronalen Netzwerktrainings auf verschiedene Weise.
Quantisierung - Es ist ein leistungsstarkes Tool, das eine 8-Bit-Ganzzahl verwendet, um eine Vorhersage des neuronalen Netzwerks zu berechnen. Wenn Sie beispielsweise ein Bilderkennungsmodell wie Inception v3 quantisieren, wird es von der ursprünglichen Größe von 91 MB auf 23 MB um etwa ein Viertel komprimiert.
Parallele Verarbeitung - Die parallele Verarbeitung auf der Matrix-Multiplikatoreinheit ist eine bekannte Methode, um die Leistung großer Matrixoperationen durch Vektorverarbeitung zu verbessern. Maschinen mit Vektorverarbeitungsunterstützung können bis zu Hunderte und Tausende von Operationselementen in einem einzigen Taktzyklus verarbeiten.
CISC - TPU arbeitet an einem CISC-Design, das sich auf die Implementierung von Anweisungen auf hoher Ebene konzentriert, die Aufgaben auf hoher Ebene ausführen, z. B. Multiplizieren und mehrfaches Hinzufügen usw. TPU verwendet die folgenden Ressourcen zur Ausführung komplexer Aufgaben:
- Matrix Multiplier Unit (MXU): 65.536 8-Bit-Multiplikations- und Additionseinheiten für Matrixoperationen.
- Unified Buffer (UB): 24 MB SRAM, der als Register fungiert.
- Aktivierungseinheit (AU): Festverdrahtete Aktivierungsfunktionen.
Systolisches Array - Das systolische Array basiert auf der neuen Architektur der MXU, die auch als Herz der TPU bezeichnet wird. Die MXU hat den Wert einmal gelesen, ihn jedoch für viele verschiedene Vorgänge verwendet, ohne ihn in einem Register zu speichern. Die Eingabe wird viele Male zur Erzeugung der Ausgabe wiederverwendet. Dieses Array wird als systolisch bezeichnet, da die Daten in Wellen auf die gleiche Weise durch den Chip fließen, wie unser Herz Blut pumpt. Es verbessert die betriebliche Flexibilität bei der Codierung und bietet eine viel höhere Betriebsdichterate.
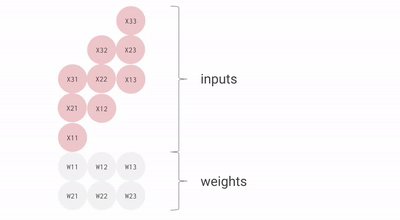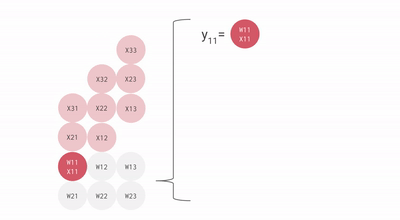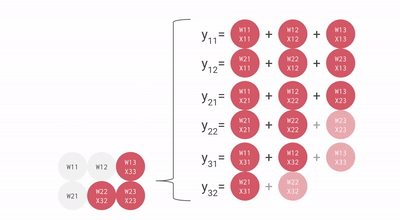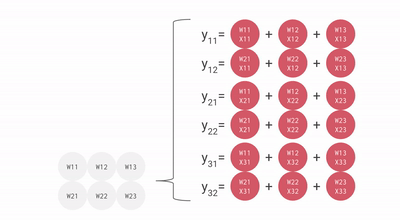
Wie Sie sehen, helfen all diese wichtigen Punkte der TPU dabei, die Daten effektiv zu analysieren und zu verarbeiten. Darüber hinaus bietet es TensorFlow-Datensätze, mit denen Entwickler einige benutzerdefinierte KI-Lösungen trainieren und weitere Forschungsarbeiten durchführen können.
Ebenfalls nach dem neuesten Update stellt Cerebras Systems (ein neues Unternehmen für künstliche Intelligenz) den größten Halbleiterchip vor, der auf dem TPU-Modell basiert. In diesem Chip finden Sie den größten Prozessor, der jemals gebaut wurde, um die KI-Anwendungen zu verarbeiten, zu trainieren und zu handhaben. Der riesige Chip entspricht der Größe eines iPad und fasst 1,2 Billionen Transistoren.Einer der größten Vorteile von TensorFlow gegenüber anderen Deep-Learning-Frameworks liegt in der Skalierbarkeit. Im Gegensatz zu anderen Frameworks wie PyTorch wurde TensorFlow für umfangreiche Inferenzen und verteiltes Training entwickelt. Es kann jedoch auch verwendet werden, um mit neuen Modellen für maschinelles Lernen und deren Optimierung zu experimentieren. Diese Flexibilität ermöglicht es Entwicklern auch, Deep-Learning-Modelle mit TensorFlow auf mehr als einer einzelnen CPU / GPU bereitzustellen.
Plattformübergreifende Kompatibilität
TensorFlow 2.0 ist mit allen wichtigen Betriebssystemplattformen wie Windows, Linux, MacOS, iOS und Android kompatibel. Darüber hinaus kann Keras auch mit TensorFlow als Schnittstelle verwendet werden.
Hardware-Skalierbarkeit
TensorFlow 2.0 kann auf einer Vielzahl von Hardwaremaschinen eingesetzt werden, von Mobilfunkgeräten bis hin zu Großcomputern mit komplexen Setups. Es kann auf einer Reihe von Hardwaremaschinen wie Mobilfunkgeräten und Computern mit komplexen Setups bereitgestellt werden. Es kann verschiedene APIs enthalten, um maßstabsgetreue Deep-Learning-Architekturen wie CNN oder RNN zu erstellen.
Visualisierung
Das TensorFlow-Framework basiert auf der Diagrammberechnung und bietet ein praktisches Visualisierungstool für Schulungszwecke. Mit diesem Visualisierungstool namens TensorBoard können Entwickler den Aufbau eines neuronalen Netzwerks visualisieren, was wiederum eine einfache Visualisierung und Problemlösung ermöglicht.
Debuggen
Mit Tensorflow können Benutzer die Unterteile eines Diagramms ausführen, um diskrete Daten am Rand einzuführen und abzurufen, und so eine übersichtliche Debugging-Methode bereitstellen.
Dynamische Grafikfunktion für einfache Bereitstellung
TensorFlow verwendet eine Funktion namens "Eifrige Ausführung", die die dynamische Grafikfunktion für eine einfache Bereitstellung erleichtert. Es ermöglicht das Speichern des Diagramms als Protokollpuffer, der dann auf etwas anderem als Python-Beziehungsinfrastrukturen, beispielsweise Java, bereitgestellt werden kann.
Warum wächst TensorFlow weiter?
TensorFlow weist unter allen anderen heute existierenden Deep-Learning-Frameworks die schnellste Wachstumsrate auf. Es hat die höchste GitHub-Aktivität unter allen anderen Repositories im Bereich Deep Learning und die höchste Anzahl an Starts.
In der jährlichen Stack Overflow-Entwicklerumfrage 2019 wurde TensorFlow zum beliebtesten Deep-Learning-Framework gewählt, das zweitbeliebteste Framework, Torch / PyTorch, war weit, weit entfernt.
Diese Statistiken reichen aus, um die Dominanz von TensorFlow zu beweisen. Aber wie lange wird es dieses Wachstum aufrechterhalten? würde es am Ende seine derzeitige Popularität übertreffen? Mit der Einführung und dem großartigen Empfang von TensorFlow 2.0 scheint letzteres möglich zu sein.