Nur wenige Hoster bieten VDS-Tarife mit einer hohen Prozessortaktrate an, obwohl anscheinend alles einfach ist: Ich habe einen leistungsstärkeren i9 in den Server eingefügt, die Abrechnung eingerichtet und fertig.
Bei der Vorbereitung der Hi-CPU-Tarife haben wir Folgendes festgestellt:
- i9-Server verbrauchen Tonnen Strom
- Es ist nicht einfach, ein Gleichgewicht zu finden und einen profitablen Tarif für hochwertige Hardware zu erzielen
- Rechenzentren ziehen es vor, sich nicht damit herumzuschlagen
Wir erzählen Ihnen, wie wir damit umgegangen sind und haben Hi CPU gestartet.

Warum brauche ich eine Hi-CPU?
Wir haben den perfekten Tarif für Bitrix vorbereitet. Warum?
Natürlich wegen des Geldes.
 Laut CMS iTrack
Laut CMS iTrack ist die Hälfte aller auf CMS erstellten Websites WordPress und nur 11,68% der Websites verwenden Bitrix.
Laut der Bewertung des CMS Magazine gibt es jedoch doppelt so viele kommerzielle Websites, die Bitrix verwenden wie WordPress. Die meisten Websites auf WordPress - Blogs, persönliche Websites und andere Visitenkarten.
Tausende russische Unternehmen nutzen Bitrix, um für qualitativ hochwertige VDS zu bezahlen. Und viele brauchen Hi-CPU-Lösungen, die auf dem Markt nicht ausreichen: Meistens bieten Hoster Tarife mit einer Prozessorfrequenz von 2-3 Gigahertz an - geeignet für alltägliche Aufgaben, aber für die Hochgeschwindigkeitsverarbeitung vieler kleiner Aufgaben reicht dies nicht mehr aus. Vor allem, wenn der Hoster nicht mit einem Überverkauf der Prozessorzeit zu kämpfen hat.
Der sichere Weg, um ein qualitativ hochwertiges Bitrix-Hosting zu werden, bestand darin, einen profitablen Hi-CPU-Tarif zu erstellen und ein vorgestellter Partner zu werden - um in die
Bewertung der empfohlenen Hosts einzusteigen, die Bitrix selbst ist.
Vorbereitung: Erstprüfung
Zunächst haben wir überprüft, wie viele Bitrix-Papageien die Baugruppe mit einer Standardrate produziert. Prozessor - Intel Scalable Xeon Silver 4116. 107 Papageien erhalten.
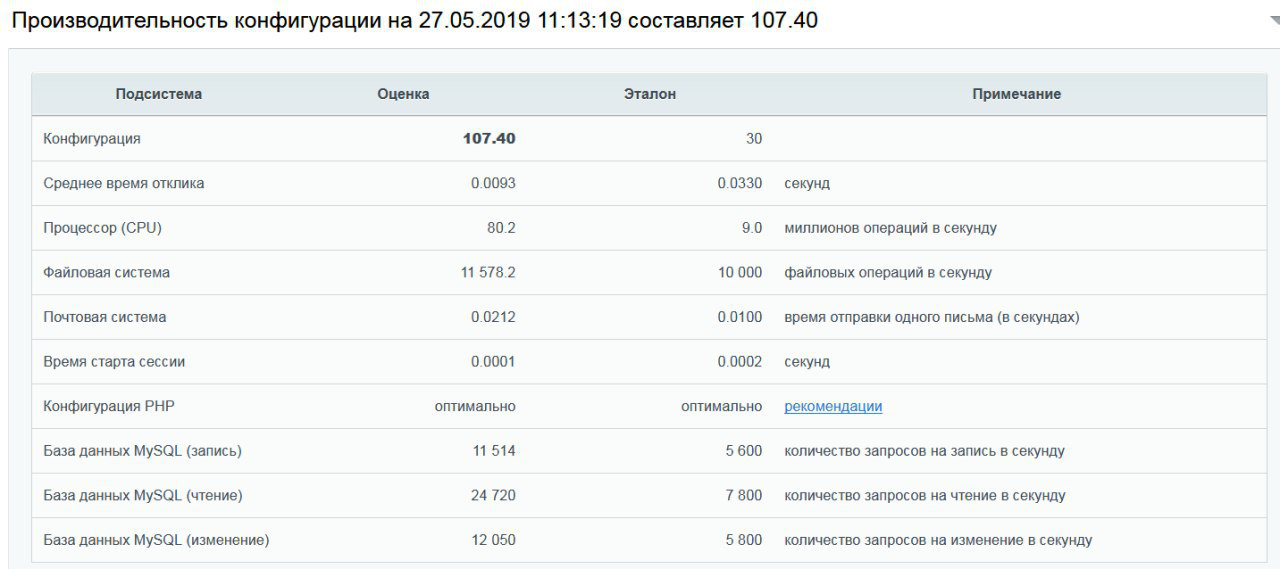 Eine ähnliche Baugruppe ist heute ab 2 Rubel pro Tag erhältlich .
Eine ähnliche Baugruppe ist heute ab 2 Rubel pro Tag erhältlich .Intel Scalable Xeon Silver 4116 leistet gute Arbeit mit typischen VDS-Aufgaben, aber für Bitrix benötigen Sie etwas Stärkeres, insbesondere wenn das Ziel darin besteht, die Spitze der Bewertung zu erreichen.

Kraftvolles Eisen für Papageien finden
Das erste, was zu tun ist, ist, den Prozessor mit einer höheren Frequenz zu nehmen: Es ist die Prozessorfrequenz, die hauptsächlich Papageien wachsen lässt.
Zunächst wurde eine Selbstorganisation auf Basis des Intel Core i9-9900K S1151 in Betracht gezogen. Einige Kollegen tun genau das und es kommen noch mehr Papageien aus ihnen heraus als auf Serverprozessoren. Wie bereits erwähnt, verbrauchen die auf ihnen basierenden Top-End-i9s und -Baugruppen jedoch so viel Energie, dass sie entweder den Preis in die Höhe treiben oder die Stromrechnungen kaputt machen müssten. Ja, und das Rechenzentrum war nicht begeistert: Er forderte die Organisation einer zusätzlichen Kühlung von Racks und Ingenieuren, um die Selbstorganisation (und zusätzliche Kühlung von Ingenieuren) zu konfigurieren und aufrechtzuerhalten.
Angesichts der Risiken, des Fehlens einer Garantie und der gesamten Desktop-Füllung erwies sich die Selbstorganisation eher als Problem als als Vorteil.
Wir haben nach dem Besten gesucht, was offizielle Lieferanten anbieten. Neben Leistung und Energieeffizienz haben wir uns den Platz im Rack angesehen: Sie müssen Geld für die Wartung jeder Einheit bezahlen, dies erhöht auch die Kosten des Tarifs.
Die beste Option schien MicroCloud in 3U zu finden. Tatsächlich sind dies 12 Server in einem, wodurch viermal Rack-Speicherplatz bei gleicher Leistung gespart werden kann. Die Server wurden im November 2018 ausgewählt und dann gab es nicht so viele Lösungen in 3U, die Wahl fiel fast sofort auf den
Supermicro SuperServer 5039MS-H12TRF .
 Es besteht aus zwölf separaten Knoten
Es besteht aus zwölf separaten Knoten Jeder Knoten ist im Wesentlichen ein separater Server. Wir haben eine andere Baugruppe als auf dem Bild, aber das Prinzip ist dasselbe.
Jeder Knoten ist im Wesentlichen ein separater Server. Wir haben eine andere Baugruppe als auf dem Bild, aber das Prinzip ist dasselbe.Das Herz wählte Intel Xeon E3-1270 v6. Wir haben uns auf Erfahrung verlassen: Wir haben diesen Prozessor bereits auf der Dell R330-Plattform für andere hoch ausgelastete Projekte verwendet. E3-1270 hat nie versagt, der Preis und die Qualität passten zu uns.
Für den Anfang kauften sie nur eine Mikrowolke: Sie kostet ungefähr 20.000 Dollar, und es gab nicht viel kostenloses Geld. Es ist zum Besseren: Es erscheinen ständig neue, effektivere und kostengünstigere Lösungen auf dem Markt. Als auf dem neuen Server Geld erschien, analysierten wir den Markt erneut.
Erstes Installationsproblem
Die erste MicroCloud wurde eine Woche nach der Bestellung geliefert. Bereits im Rechenzentrum stellte sich heraus, dass es nicht in ein Rack passt. Wir wollten es auf die 1U-Server stellen, aber die Schienen im Rack befinden sich so, dass Microcloud nicht eintreten konnte. Um es zu platzieren, müssten Sie eine Ausfallzeit für andere Server vereinbaren und die Hilfslinien verschieben.
Wir haben beschlossen, den Start zu verschieben und Microcloud in ein neues Rack einzubauen. Dies stellte sich als optimale Lösung heraus: Der Stromverbrauch und die Wärmeableitung von MicroCloud unterscheiden sich von normalen Servern. Und Netzwerkgeräte mit eigenen Eigenschaften.
 MicroClouds befinden sich jetzt in einem separaten Rack
MicroClouds befinden sich jetzt in einem separaten RackMicroCloud plante die Installation von 10-Gigabit-Netzwerkkarten, um die Migration von VDS-Containern ordnungsgemäß zu verteilen. Wir haben diesen Trick bereits mit 1U-Servern gemacht, aber mit MicroCloud stellte sich heraus, dass alles komplizierter war.
Zehn-Gigabit-Netzwerkkarten für MicroCloud-Server waren eine Seltenheit. Wir bestellten das Low Profile AOM-CTGS-i2TM MicroLP, warteten einige Monate und erhielten die Antwort: „Entschuldigung, der Hersteller stößt selten auf solche Bestellungen. Die Karten werden in sechs Monaten fertig sein. “ Ich musste die Idee aufgeben: Es gibt zwar genug Standard-Gigabit-Karten, aber in Zukunft werden wir erneut versuchen, Zehn-Gigabit-Karten zu kaufen.
Ein bisschen Hickporno: So werden MicroClouds zusammengesetztVorlagenanpassung und Anwendung in Bitrix
Zunächst haben wir eine Vorlage mit einer Tendenz zu Bitrix erstellt, die aber auch für den Rest des CMS von Vorteil ist: Beispielsweise haben wir eine nicht standardmäßige Konfiguration für Vesta mit einer Auswahl der PHP-Version hinzugefügt. Die gesamte Konfiguration und Optimierung erfolgte nach dem Schema apache + mod_fcgi. Die Parameter wurden so ausgewählt, dass sie für alle Tarife das beste Durchschnittsergebnis ergaben.
Die Leistung von Bitrix hängt direkt von der Taktrate des Prozessors ab. Im Durchschnitt war die Prozessorfrequenz für Hi-CPU-Tarife 40-50% höher als die von Prozessoren, die reguläre Tarife bedienen. Die Messergebnisse korrelierten: Mindestens 30% mehr Leistung bei hoher Auslastung des Servers, ca. 60% - bei „gutem Wetter“.
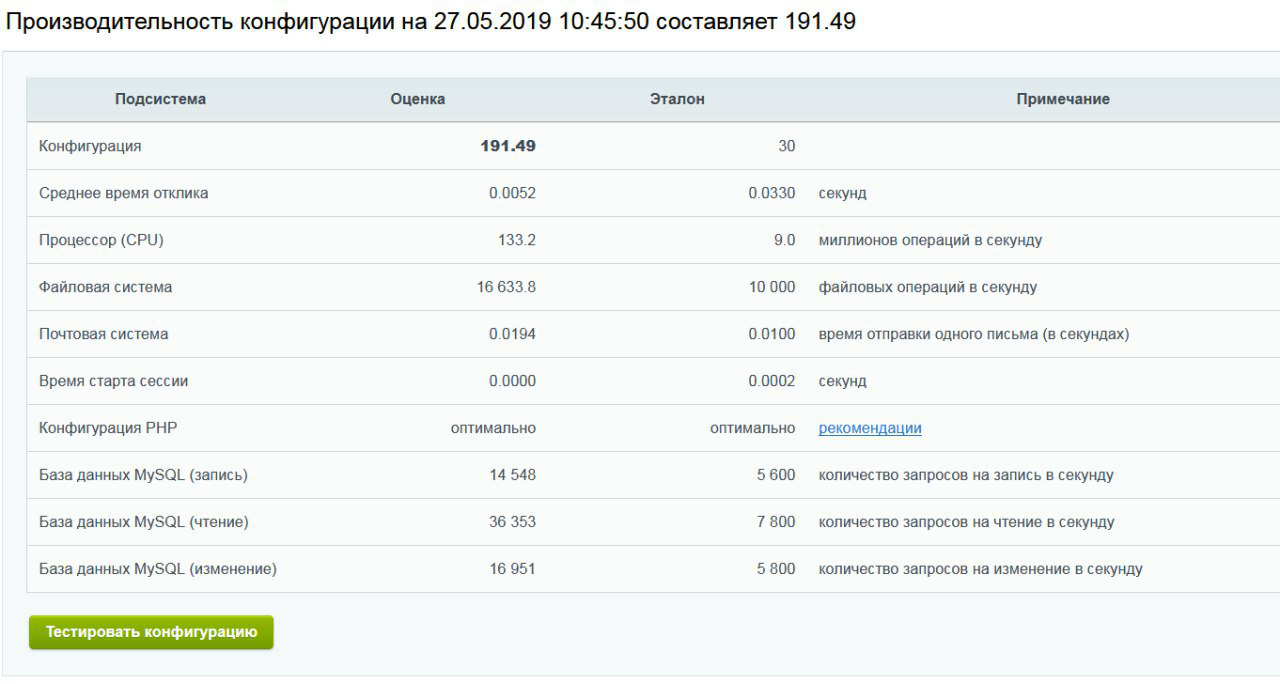
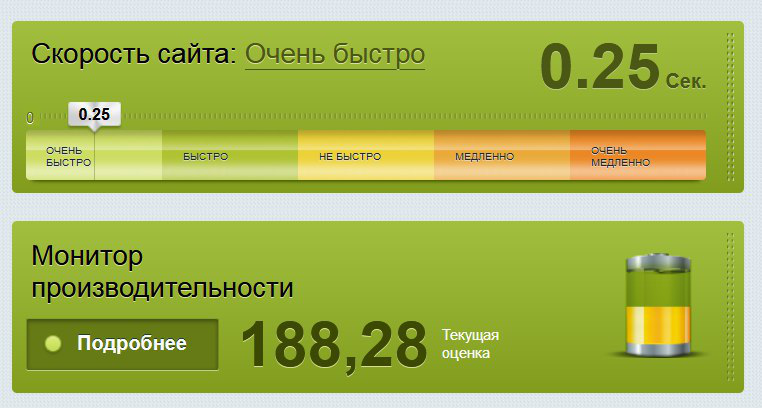 Wir haben diese Zahlen zu einem Tarif erhalten, der 26,6 Rubel pro Tag kostet
Wir haben diese Zahlen zu einem Tarif erhalten, der 26,6 Rubel pro Tag kostetAls alles debuggt war, haben wir uns auf der Website für Bitrix-Partner registriert und eine Anwendung ausgefüllt, an die wir Daten von VDS mit einer für Bitrix optimierten Vorlage angehängt haben.
Krieg um den ersten Platz in der Rangliste
Die Leistungsergebnisse wurden bestätigt, aber die endgültige Bewertung war niedriger als erwartet: Die Bewertung berücksichtigt nicht nur die Leistung, sondern auch die absoluten Kosten des Tarifs und die Verfügbarkeit des Testzeitraums.

Und wir haben den Kampf um den ersten Platz in der Rangliste aus zwei Gründen bewusst aufgegeben.
Preis und gesunder Menschenverstand
Andere Hosting-Unternehmen haben Anwendungen mit ihren günstigsten Tarifen gesendet, die weniger RAM, Speicherplatz auf der SSD und weniger Datenverkehr als unsere haben. Wir haben einen Antrag mit einem teureren Tarif gesendet, der jedoch für den normalen Betrieb von Bitrix besser geeignet ist.
Warum eine kostenlose Testphase abgelehnt
Das Fehlen einer kostenlosen Testphase ermöglichte es uns nicht, in die erste Zeile der Bewertung zu gelangen, aber wir hatten einen ernsthaften Grund, diese abzulehnen. Warum? Weil wir serviceorientiert sind.
Bei der Erstellung von VDSina setzen wir auf Bequemlichkeit: Die Registrierung sollte im laufenden Betrieb ohne Captcha (wir haben Sodbrennen von ihr), Überprüfung der Passdaten und Bestätigung der Telefonnummer erfolgen. Ich habe Post eingegeben, den Restbetrag um 30 Rubel aufgefüllt und VDS in 60 Sekunden entfaltet - für uns ist dies eine Grundsatzfrage.
Hostings erschweren die Registrierung, um mit Betrügern umzugehen, die in der kostenlosen Testphase Minen abbauen, und erstellen Hunderte von kostenlosen Konten.
Mit diesem Schema des Umgangs mit Freeloadern leiden normale Kunden und wir möchten sie grundsätzlich nicht mit unserem Problem im Allgemeinen beladen.
Um das Hosting testen zu können, haben wir eine tägliche Abrechnung und eine Mindestzahlung von 30 Rubel vorgenommen - für Kunden, die wirklich nach einem bequemen VDS für die Arbeit suchen, kostet dies praktisch nichts.
Bisher sind unsere Kunden mit dieser Situation zufrieden, und wir auch.
Leistungstests unserer Hi-CPUs


TestdetailsBYTE UNIX reguläres VDS
================================================== =================
BYTE UNIX-Benchmarks (Version 5.1.3)
System: v148399.hosted-by-vdsina.ru: GNU / Linux
Betriebssystem: GNU / Linux - 3.10.0-957.5.1.el7.x86_64 - # 1 SMP Fr 1. Februar 14:54:57 UTC 2019
Maschine: x86_64 (x86_64)
Sprache: en_US.utf8 (charmap = "UTF-8", collate = "UTF-8")
CPU 0: Gemeinsamer KVM-Prozessor (4394,9 Bogomips)
x86-64, MMX, physikalische Adresse ext, SYSENTER / SYSEXIT, SYSCALL / SYSRET
CPU 1: Gemeinsamer KVM-Prozessor (4394,9 Bogomips)
x86-64, MMX, physikalische Adresse ext, SYSENTER / SYSEXIT, SYSCALL / SYSRET
10:42:54 bis 21 min, 1 Benutzer, Lastdurchschnitt: 0,07, 0,21, 0,21; Runlevel 3
- Benchmark-Lauf: Mi 11. September 2019 10:42:54 - 11:10:59
2 CPUs im System; 1 parallele Kopie der Tests ausführen
Dhrystone 2 unter Verwendung der Registervariablen 26770638,9 lps (10,0 s, 7 Proben)
Doppelpräziser Schleifstein 4222,7 MWIPS (9,8 s, 7 Proben)
Execl Throughput 1763,2 lps (30,0 s, 2 Proben)
Dateikopie 1024 Bufsize 2000 Maxblocks 226998,4 KBit / s (30,0 s, 2 Beispiele)
Dateikopie 256 Bufsize 500 Maxblocks 60299,3 KBit / s (30,0 s, 2 Beispiele)
Dateikopie 4096 bufsize 8000 maxblocks 702987.3 KBps (30,0 s, 2 Beispiele)
Rohrdurchsatz 315773,1 lps (10,0 s, 7 Proben)
Pipe-based Context Switching 85613,2 lps (10,0 s, 7 Samples)
Prozesserstellung 5140,5 lps (30,0 s, 2 Proben)
Shell-Skripte (1 gleichzeitig) 3570,0 lpm (60,0 s, 2 Beispiele)
Shell-Skripte (8 gleichzeitig) 730,3 l / min (60,1 s, 2 Beispiele)
Systemaufruf-Overhead 293013,8 lps (10,0 s, 7 Proben)
Systembenchmarks Indexwerte BASELINE RESULT INDEX
Dhrystone 2 unter Verwendung der Registervariablen 116700.0 26770638.9 2294.0
Double-Precision Whetstone 55.0 4222.7 767.8
Execl Throughput 43.0 1763.2 410.1
Dateikopie 1024 bufsize 2000 maxblocks 3960.0 226998.4 573.2
Dateikopie 256 Bufsize 500 Maxblocks 1655.0 60299.3 364.3
Dateikopie 4096 bufsize 8000 maxblocks 5800.0 702987.3 1212.0
Rohrdurchsatz 12440.0 315773.1 253.8
Rohrbasierte Kontextumschaltung 4000.0 85613.2 214.0
Prozesserstellung 126.0 5140.5 408.0
Shell-Skripte (1 gleichzeitig) 42.4 3570.0 842.0
Shell-Skripte (8 gleichzeitig) 6.0 730.3 1217.2
Systemaufruf-Overhead 15000.0 293013.8 195.3
========
System Benchmarks Index Score 552.6
- Benchmark Run: Mi Sep 11 2019 11:10:59 - 11:39:17
2 CPUs im System; Ausführen von 2 parallelen Kopien von Tests
Dhrystone 2 unter Verwendung der Registervariablen 50497275.9 lps (10,0 s, 7 Proben)
Doppelpräziser Schleifstein 8233,3 MWIPS (9,8 s, 7 Proben)
Execl Throughput 3435,3 lps (29,8 s, 2 Samples)
Dateikopie 1024 Bufsize 2000 Maxblocks 386580,4 KBit / s (30,0 s, 2 Beispiele)
Dateikopie 256 Bufsize 500 Maxblocks 102199,5 KBit / s (30,0 s, 2 Beispiele)
Dateikopie 4096 bufsize 8000 maxblocks 1187846.7 KBps (30,0 s, 2 Beispiele)
Rohrdurchsatz 614216.9 lps (10,0 s, 7 Proben)
Pipe-based Context Switching 168877,2 lps (10,0 s, 7 Samples)
Prozesserstellung 11055,3 lps (30,0 s, 2 Proben)
Shell-Skripte (1 gleichzeitig) 5620,2 lpm (60,0 s, 2 Beispiele)
Shell-Skripte (8 gleichzeitig) 804,7 l / min (60,1 s, 2 Beispiele)
Systemaufruf-Overhead 561793,2 lps (10,0 s, 7 Proben)
Systembenchmarks Indexwerte BASELINE RESULT INDEX
Dhrystone 2 unter Verwendung der Registervariablen 116700.0 50497275.9 4327.1
Double-Precision Whetstone 55.0 8233.3 1497.0
Execl Throughput 43.0 3435.3 798.9
Dateikopie 1024 bufsize 2000 maxblocks 3960.0 386580.4 976.2
Dateikopie 256 Bufsize 500 Maxblocks 1655.0 102199.5 617.5
Dateikopie 4096 bufsize 8000 maxblocks 5800.0 1187846.7 2048.0
Rohrdurchsatz 12440.0 614216.9 493.7
Rohrbasierte Kontextumschaltung 4000.0 168877.2 422.2
Prozesserstellung 126.0 11055.3 877.4
Shell-Skripte (1 gleichzeitig) 42.4 5620.2 1325.5
Shell-Skripte (8 gleichzeitig) 6.0 804.7 1341.2
Systemaufruf-Overhead 15000.0 561793.2 374.5
========
System Benchmarks Index Score 979.3
BYTE UNIX Altes Hi-CPU-VDS
================================================== =================
BYTE UNIX-Benchmarks (Version 5.1.3)
System: v148401.hosted-by-vdsina.ru: GNU / Linux
Betriebssystem: GNU / Linux - 3.10.0-957.5.1.el7.x86_64 - # 1 SMP Fr 1. Februar 14:54:57 UTC 2019
Maschine: x86_64 (x86_64)
Sprache: en_US.utf8 (charmap = "UTF-8", collate = "UTF-8")
CPU 0: Gemeinsamer KVM-Prozessor (6624.1 Bogomips)
x86-64, MMX, physikalische Adresse ext, SYSENTER / SYSEXIT, SYSCALL / SYSRET
CPU 1: Gemeinsamer KVM-Prozessor (6624.1 Bogomips)
x86-64, MMX, physikalische Adresse ext, SYSENTER / SYSEXIT, SYSCALL / SYSRET
14:01:52 bis 3:40, 1 Benutzer, Lastdurchschnitt: 0,00, 0,07, 0,07; Runlevel 3
- Benchmark-Lauf: Mi 11. September 2019 14:01:52 - 14:30:53
2 CPUs im System; 1 parallele Kopie der Tests ausführen
Dhrystone 2 unter Verwendung der Registervariablen 41165945.1 lps (10,0 s, 7 Proben)
Doppelpräziser Schleifstein 3454,8 MWIPS (15,4 s, 7 Proben)
Execl Throughput 2102,9 lps (29,6 s, 2 Samples)
Dateikopie 1024 bufsize 2000 maxblocks 323989.0 KBps (30,0 s, 2 Beispiele)
Dateikopie 256 Bufsize 500 Maxblocks 88536.1 KBps (30,0 s, 2 Samples)
Dateikopie 4096 Bufsize 8000 Maxblocks 1090490,9 KBit / s (30,0 s, 2 Beispiele)
Rohrdurchsatz 456730,9 lps (10,0 s, 7 Proben)
Pipe-based Context Switching 126170,4 lps (10,0 s, 7 Samples)
Prozesserstellung 6282,5 lps (30,0 s, 2 Proben)
Shell-Skripte (1 gleichzeitig) 5172,3 lpm (60,0 s, 2 Beispiele)
Shell-Skripte (8 gleichzeitig) 1122,8 l / min (60,0 s, 2 Beispiele)
Systemaufruf-Overhead 426422,9 lps (10,0 s, 7 Proben)
Systembenchmarks Indexwerte BASELINE RESULT INDEX
Dhrystone 2 unter Verwendung der Registervariablen 116700.0 41165945.1 3527.5
Double-Precision Whetstone 55.0 3454.8 628.1
Execl Throughput 43.0 2102.9 489.1
Dateikopie 1024 bufsize 2000 maxblocks 3960.0 323989.0 818.2
Dateikopie 256 Bufsize 500 Maxblocks 1655.0 88536.1 535.0
Dateikopie 4096 bufsize 8000 maxblocks 5800.0 1090490.9 1880.2
Rohrdurchsatz 12440.0 456730.9 367.1
Rohrbasierte Kontextumschaltung 4000.0 126170.4 315.4
Prozesserstellung 126.0 6282.5 498.6
Shell-Skripte (1 gleichzeitig) 42.4 5172.3 1219.9
Shell-Skripte (8 gleichzeitig) 6.0 1122.8 1871.4
Systemaufruf-Overhead 15000.0 426422.9 284.3
========
System Benchmarks Index Score 753.4
- Benchmark Run: Mi Sep 11 2019 14:30:53 - 15:00:04
2 CPUs im System; Ausführen von 2 parallelen Kopien von Tests
Dhrystone 2 unter Verwendung der Registervariablen 73510146.2 lps (10,0 s, 7 Proben)
Double-Precision Whetstone 6546,6 MWIPS (16,2 s, 7 Proben)
Ausführungsdurchsatz 5306,0 lps (30,0 s, 2 Proben)
Dateikopie 1024 Bufsize 2000 Maxblocks 580128,9 KBit / s (30,0 s, 2 Beispiele)
Dateikopie 256 Bufsize 500 Maxblocks 149810,9 KBit / s (30,0 s, 2 Beispiele)
Dateikopie 4096 bufsize 8000 maxblocks 1896766.5 KBps (30,0 s, 2 Samples)
Rohrdurchsatz 891359,8 lps (10,0 s, 7 Proben)
Pipe-based Context Switching 245363,7 lps (10,0 s, 7 Samples)
Prozesserstellung 17811,2 lps (30,0 s, 2 Proben)
Shell-Skripte (1 gleichzeitig) 8446,7 l / min (60,0 s, 2 Beispiele)
Shell-Skripte (8 gleichzeitig) 1147,3 l / min (60,0 s, 2 Beispiele)
Systemaufruf-Overhead 831002,3 lps (10,0 s, 7 Proben)
Systembenchmarks Indexwerte BASELINE RESULT INDEX
Dhrystone 2 unter Verwendung der Registervariablen 116700.0 73510146.2 6299.1
Double-Precision Whetstone 55.0 6546.6 1190.3
Execl Throughput 43.0 5306.0 1234.0
Dateikopie 1024 bufsize 2000 maxblocks 3960.0 580128.9 1465.0
Dateikopie 256 Bufsize 500 Maxblocks 1655.0 149810.9 905.2
Dateikopie 4096 bufsize 8000 maxblocks 5800.0 1896766.5 3270.3
Rohrdurchsatz 12440.0 891359.8 716.5
Rohrbasierte Kontextumschaltung 4000.0 245363.7 613.4
Prozesserstellung 126.0 17811.2 1413.6
Shell-Skripte (1 gleichzeitig) 42.4 8446.7 1992.1
Shell-Skripte (8 gleichzeitig) 6.0 1147.3 1912.1
Systemaufruf-Overhead 15000.0 831002.3 554.0
========
System Benchmarks Index Score 1391.3
BYTE UNIX Hi-CPU VDS
================================================== =================
BYTE UNIX-Benchmarks (Version 5.1.3)
System: v148401.hosted-by-vdsina.ru: GNU / Linux
Betriebssystem: GNU / Linux - 3.10.0-957.5.1.el7.x86_64 - # 1 SMP Fr 1. Februar 14:54:57 UTC 2019
Maschine: x86_64 (x86_64)
Sprache: en_US.utf8 (charmap = "UTF-8", collate = "UTF-8")
CPU 0: Gemeinsamer KVM-Prozessor (6624.1 Bogomips)
x86-64, MMX, physikalische Adresse ext, SYSENTER / SYSEXIT, SYSCALL / SYSRET
CPU 1: Gemeinsamer KVM-Prozessor (6624.1 Bogomips)
x86-64, MMX, physikalische Adresse ext, SYSENTER / SYSEXIT, SYSCALL / SYSRET
10:42:58 bis 21 min, 1 Benutzer, Lastdurchschnitt: 0,03, 0,07, 0,06; Runlevel 3
- Benchmark-Lauf: Mi Sep 11 2019 10:42:58 - 11:12:20
2 CPUs im System; 1 parallele Kopie der Tests ausführen
Dhrystone 2 unter Verwendung der Registervariablen 50496763.2 lps (10,0 s, 7 Proben)
Doppelpräziser Schleifstein 3290,3 MWIPS (18,2 s, 7 Proben)
Execl Throughput 3416,6 lps (30,0 s, 2 Samples)
Dateikopie 1024 bufsize 2000 maxblocks 419298.9 KBps (30,0 s, 2 Beispiele)
Dateikopie 256 Bufsize 500 Maxblocks 105903,4 KBit / s (30,0 s, 2 Beispiele)
Dateikopie 4096 bufsize 8000 maxblocks 1417343.7 KBps (30,0 s, 2 Beispiele)
Rohrdurchsatz 539629.9 lps (10,0 s, 7 Proben)
Pipe-based Context Switching 152917,5 lps (10,0 s, 7 Samples)
Prozesserstellung 10424,5 lps (30,0 s, 2 Proben)
Shell-Skripte (1 gleichzeitig) 7237,0 l / min (60,0 s, 2 Beispiele)
Shell-Skripte (8 gleichzeitig) 1502,7 l / min (60,0 s, 2 Beispiele)
Systemaufruf-Overhead 495647,5 lps (10,0 s, 7 Proben)
Systembenchmarks Indexwerte BASELINE RESULT INDEX
Dhrystone 2 unter Verwendung der Registervariablen 116700.0 50496763.2 4327.1
Double-Precision Whetstone 55.0 3290.3 598.2
Execl Throughput 43.0 3416.6 794.6
Dateikopie 1024 bufsize 2000 maxblocks 3960.0 419298.9 1058.8
Dateikopie 256 Bufsize 500 Maxblocks 1655.0 105903.4 639.9
Dateikopie 4096 bufsize 8000 maxblocks 5800.0 1417343.7 2443.7
Rohrdurchsatz 12440.0 539629.9 433.8
Rohrbasierte Kontextumschaltung 4000.0 152917.5 382.3
Prozesserstellung 126.0 10424.5 827.3
Shell-Skripte (1 gleichzeitig) 42.4 7237.0 1706.8
Shell-Skripte (8 gleichzeitig) 6.0 1502.7 2504.5
Systemaufruf-Overhead 15000.0 495647.5 330.4
========
System Benchmarks Index Score 966.0
- Benchmark Run: Mi Sep 11 2019 11:12:20 - 11:41:45
2 CPUs im System; Ausführen von 2 parallelen Kopien von Tests
Dhrystone 2 unter Verwendung der Registervariablen 101242206.9 lps (10,0 s, 7 Proben)
Double-Precision Whetstone 6543,9 MWIPS (18,3 s, 7 Proben)
Ausführungsdurchsatz 7095,4 lps (30,0 s, 2 Proben)
Dateikopie 1024 Bufsize 2000 Maxblocks 793174,9 KBit / s (30,0 s, 2 Beispiele)
Dateikopie 256 Bufsize 500 Maxblocks 203939,8 KBit / s (30,0 s, 2 Beispiele)
Dateikopie 4096 bufsize 8000 maxblocks 2721785.9 KBps (30,0 s, 2 Beispiele)
Rohrdurchsatz 1072159,2 lps (10,0 s, 7 Proben)
Pipe-based Context Switching 307924,6 lps (10,0 s, 7 Samples)
Prozesserstellung 23097,3 lps (30,0 s, 2 Proben)
Shell-Skripte (1 gleichzeitig) 11354,9 l / min (60,0 s, 2 Beispiele)
Shell-Skripte (8 gleichzeitig) 1585.1 lpm (60,1 s, 2 Beispiele)
Systemaufruf-Overhead 979658.1 lps (10,0 s, 7 Proben)
Systembenchmarks Indexwerte BASELINE RESULT INDEX
Dhrystone 2 unter Verwendung der Registervariablen 116700.0 101242206.9 8675.4
Double-Precision Whetstone 55.0 6543.9 1189.8
Execl Throughput 43.0 7095.4 1650.1
Dateikopie 1024 bufsize 2000 maxblocks 3960.0 793174.9 2003.0
Dateikopie 256 Bufsize 500 Maxblocks 1655.0 203939.8 1232.3
Dateikopie 4096 bufsize 8000 maxblocks 5800.0 2721785.9 4692.7
Rohrdurchsatz 12440.0 1072159.2 861.9
Rohrbasierte Kontextumschaltung 4000.0 307924.6 769.8
Prozesserstellung 126.0 23097.3 1833.1
Shell-Skripte (1 gleichzeitig) 42.4 11354.9 2678.1
Shell-Skripte (8 gleichzeitig) 6.0 1585.1 2641.9
Systemaufruf-Overhead 15000.0 979658.1 653.1
========
System Benchmarks Index Score 1793.6
Zukunftspläne
Vor kurzem ist der vierte Server zu uns gekommen. Diesmal Supermicro MicroCloud mit 12 x Xeon E-2136, 48 x DDR4 16 GB und 12 x 1 TB NVME P4510.
Im Durchschnitt liegt die Leistung der neuen MicroCloud um 8-10% über der der Rack-Brüder
Die neue MicroCloud wurde bereits in Betrieb genommen, und jetzt planen wir, Hi-CPU auf die Niederlande und andere Länder auszudehnen. Wir haben Server für reguläre Tarife in zwei niederländischen Rechenzentren, aber wenn die Frage nach etwas Komplizierterem als einem 1U-Server auftaucht, müssen Sie 9 Koordinierungsrunden durchlaufen.
Aber das ist eine andere Geschichte.

Abonnieren Sie unseren Instagram-Entwickler
