Hallo Habr.
Dieser Artikel ist eine logische Fortsetzung der Rangliste der
Artikel von
Best Habr für 2018 . Und obwohl das Jahr noch nicht zu Ende ist, gab es, wie Sie wissen, im Sommer Änderungen in den Regeln, und es wurde interessant zu sehen, ob sich dies auf irgendetwas auswirkte.

Zusätzlich zur Statistik werden eine aktualisierte Bewertung der Artikel sowie einige Quellcodes für diejenigen bereitgestellt, die daran interessiert sind, wie dies funktioniert.
Für diejenigen, die daran interessiert sind, was passiert ist, weiter unter dem Schnitt. Diejenigen, die an einer detaillierteren Analyse von Abschnitten der Website interessiert sind, können auch den
nächsten Teil sehen .
Ausgangsdaten
Diese Bewertung ist inoffiziell und ich habe keine Insiderdaten. Wie leicht zu erkennen ist, sind alle Artikel auf Habré in der Adressleiste des Browsers durchgehend nummeriert. Als nächstes ist eine technische Angelegenheit, wir lesen einfach alle Artikel in einer Reihe in einem Zyklus (in einem Thread und mit Pausen, um den Server nicht zu laden). Die Werte selbst wurden von einem einfachen Parser in Python (Quellcode ist
hier ) abgerufen und in einer CSV-Datei von ungefähr diesem Typ gespeichert:
2019-08-11T22:36Z,https://habr.com/ru/post/463197/,"Blazor + MVVM = Silverlight , ",votes:11,votesplus:17,votesmin:6,bookmarks:40,views:5300,comments:73
2019-08-11T05:26Z,https://habr.com/ru/news/t/463199/," NASA ",votes:15,votesplus:15,votesmin:0,bookmarks:2,views:1700,comments:7Verarbeitung
Zum Parsen verwenden wir Python, Pandas und Matplotlib. Wer sich nicht für Statistik interessiert, kann diesen Teil überspringen und sofort zu den Artikeln gehen.
Zuerst müssen Sie den Datensatz in den Speicher laden und Daten für das gewünschte Jahr auswählen.
import pandas as pd import datetime import matplotlib.dates as mdates from matplotlib.ticker import FormatStrFormatter from pandas.plotting import register_matplotlib_converters df = pd.read_csv("habr.csv", sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#') dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%MZ') df['datetime'] = dates year = 2019 df = df[(df['datetime'] >= pd.Timestamp(datetime.date(year, 1, 1))) & (df['datetime'] < pd.Timestamp(datetime.date(year+1, 1, 1)))] print(df.shape)
Es stellt sich heraus, dass für dieses Jahr (obwohl es noch nicht fertig ist) zum Zeitpunkt des Schreibens 12715 Artikel veröffentlicht wurden. Zum Vergleich für das gesamte Jahr 2018 - 15904. Im Allgemeinen viel - das sind ungefähr 43 Artikel pro Tag (und dies ist nur bei einer positiven Bewertung, wie viele Artikel heruntergeladen werden, die negativ oder gelöscht sind, können Sie nur die Auslassungen unter erraten oder grob herausfinden Kennungen).
Wählen Sie die erforderlichen Felder aus dem Datensatz aus. Als Metriken verwenden wir die Anzahl der Ansichten, Kommentare, Bewertungswerte und die Anzahl der hinzugefügten Lesezeichen.
def to_float(s):
Jetzt wurden die Daten zum Datensatz hinzugefügt, und wir können sie verwenden. Gruppieren Sie die Daten nach Tag und nehmen Sie die gemittelten Werte.
g = df.groupby(['date']) days_count = g.size().reset_index(name='counts') year_days = days_count['date'].values grouped = g.median().reset_index() grouped['counts'] = days_count['counts'] counts_per_day = grouped['counts'].values counts_per_day_avg = grouped['counts'].rolling(window=20).mean() view_per_day = grouped['views'].values view_per_day_avg = grouped['views'].rolling(window=20).mean() votes_per_day = grouped['votes'].values votes_per_day_avg = grouped['votes'].rolling(window=20).mean() bookmarks_per_day = grouped['bookmarks'].values bookmarks_per_day_avg = grouped['bookmarks'].rolling(window=20).mean()
Nun zum lustigen Teil können wir uns die Diagramme ansehen.
Sehen wir uns die Anzahl der Veröffentlichungen zu Habré im Jahr 2019 an.
import matplotlib.pyplot as plt plt.rcParams["figure.figsize"] = (16, 8) fig, ax = plt.subplots() plt.bar(year_days, counts_per_day, label='Articles/day') plt.plot(year_days, counts_per_day_avg, 'g-', label='Articles avg/day') plt.xticks(rotation=45) ax.xaxis.set_major_formatter(mdates.DateFormatter("%d-%m-%Y")) ax.xaxis.set_major_locator(mdates.MonthLocator(interval=1)) plt.legend(loc='best') plt.tight_layout() plt.show()
Das Ergebnis ist interessant. Wie Sie sehen können, "Wurst" Habr im Laufe des Jahres leicht. Ich kenne den Grund nicht.

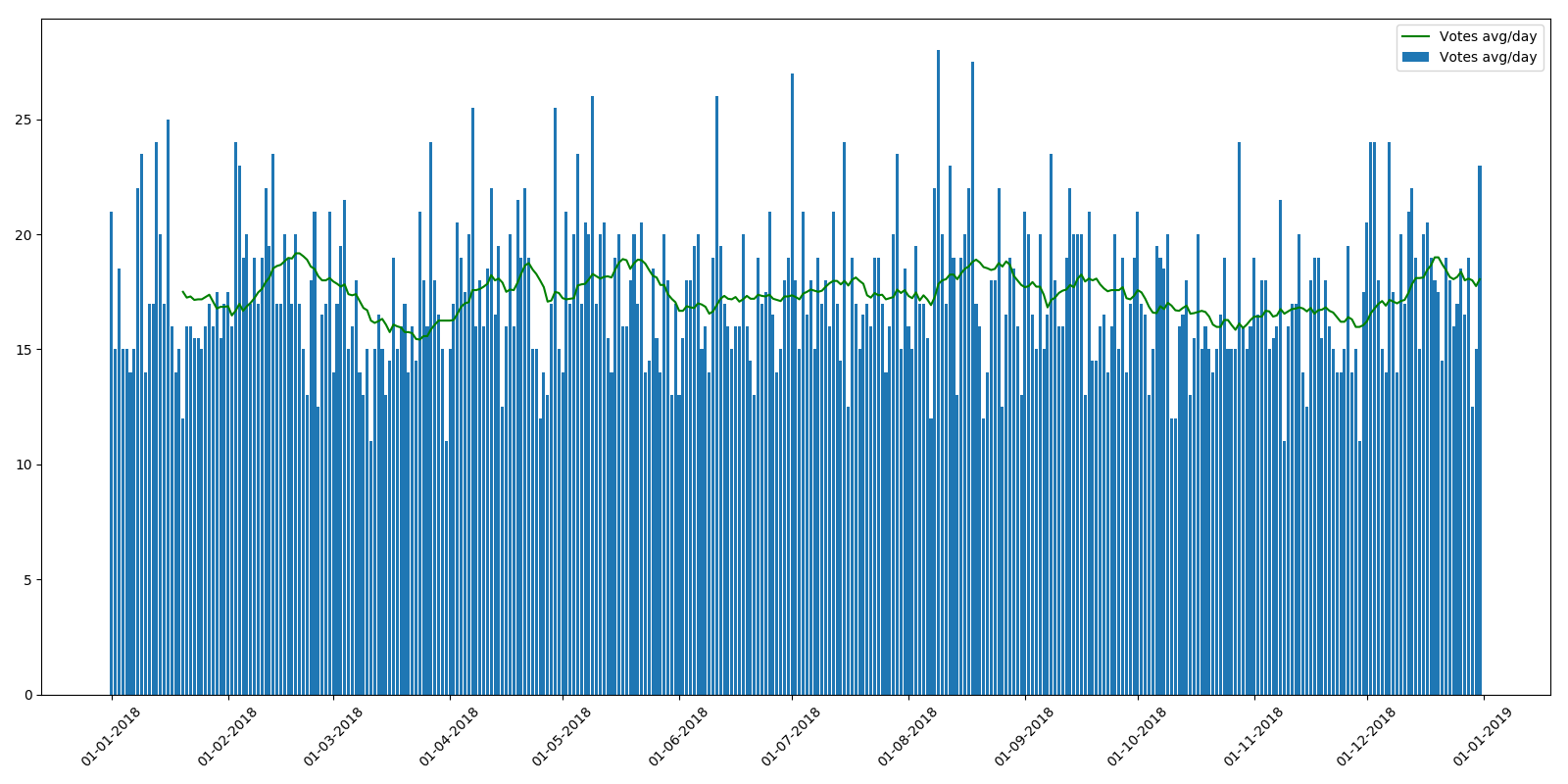
Zum Vergleich: 2018 sieht etwas „glatter“ aus:

Im Allgemeinen konnte ich keinen drastischen Rückgang der Anzahl der veröffentlichten Artikel im Jahr 2019 in der Grafik feststellen. Im Gegenteil, es scheint seit dem Sommer sogar leicht gewachsen zu sein.
Aber die folgenden zwei Grafiken bedrücken mich ein bisschen mehr.
Durchschnittliche Aufrufe pro Artikel:

Durchschnittliche Bewertung pro Artikel:
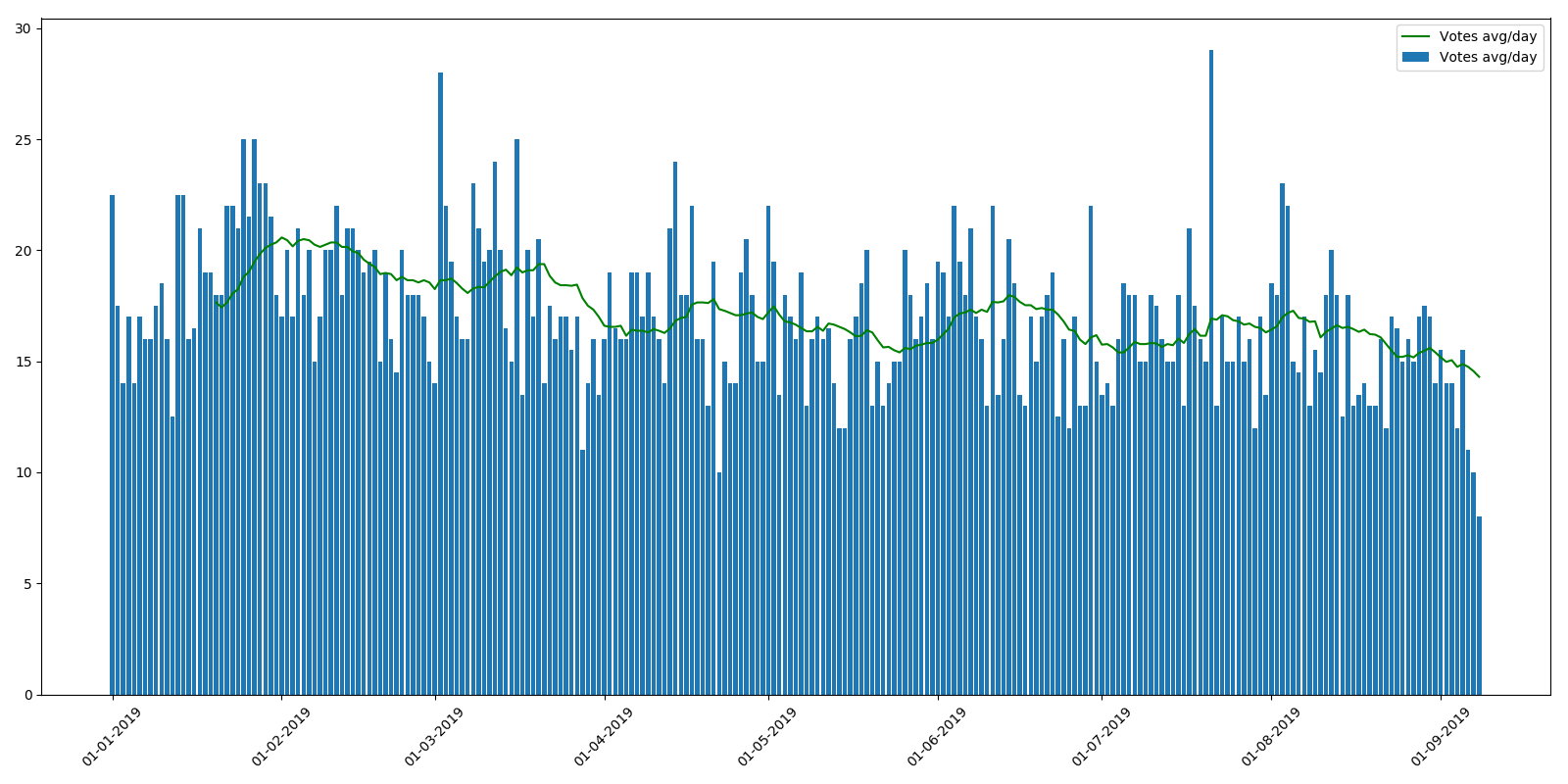
Wie Sie sehen können, ist die durchschnittliche Anzahl der Aufrufe während des Jahres leicht reduziert. Dies kann durch die Tatsache erklärt werden, dass neue Artikel noch nicht von Suchmaschinen indiziert wurden und nicht so oft gefunden werden. Der Rückgang der durchschnittlichen Bewertung pro Artikel ist jedoch unverständlicher. Das Gefühl ist, dass die Leser entweder einfach keine Zeit haben, so viele Artikel zu durchsuchen, oder die Bewertungen nicht beachten. Aus Sicht des Belohnungsprogramms der Autoren ist dieser Trend sehr unangenehm.
Dies war übrigens 2018 nicht der Fall, und der Zeitplan ist mehr oder weniger gleichmäßig.
Im Allgemeinen müssen Ressourcenbesitzer über etwas nachdenken.
Aber reden wir nicht über traurige Dinge. Im Allgemeinen können wir sagen, dass Habr die Sommeränderungen recht erfolgreich "überlebt" hat und die Anzahl der Artikel auf der Website nicht abgenommen hat.
Bewertung
Nun eigentlich die Bewertung. Herzlichen Glückwunsch an diejenigen, die ihn geschlagen haben. Ich möchte Sie noch einmal daran erinnern, dass die Bewertung inoffiziell ist. Vielleicht habe ich etwas verpasst. Wenn ein Artikel definitiv hier sein sollte, aber nicht, schreibe ich, ich füge ihn manuell hinzu. Als Bewertung verwende ich berechnete Metriken, die sich meiner Meinung nach als sehr interessant erwiesen haben.
Top Viewed Artikel- LED-Lügen von beispiellosem Ausmaß 241.000 Aufrufe, 569 Kommentare, Bewertung + 364,0 / -1,0
- 'Blowjob-Artikel': Wissenschaftler verarbeiteten 109 Stunden Oralsex, um eine KI zu entwickeln, die einem Mitglied 236.000 Aufrufe, 361 Kommentare und eine Bewertung von + 240,0 / -68,0 bietet
- Was der Designer geraucht hat: eine ungewöhnliche Waffe 235.000 Aufrufe, 123 Kommentare, Bewertung + 119.0 / -9.0
- Wie ich ein Jahr lang nicht bei Sberbank gearbeitet habe 233.000 Aufrufe, 580 Kommentare, Bewertung + 449.0 / -14.0
- Wissenschaftler haben das älteste lebende Wirbeltier der Erde gefunden. 221000 Aufrufe, 211 Kommentare, Bewertung + 82,0 / -14,0
- Intelligente Glühbirnen, die in den Papierkorb geworfen werden, sind eine wertvolle Quelle für persönliche Informationen. 219.000 Aufrufe, 147 Kommentare, Bewertung + 73,0 / -11,0
- Development King 178.000 Aufrufe, 668 Kommentare, Bewertung + 315.0 / -60.0
- Betrüger und EDS - alles ist sehr schlecht 175.000 Aufrufe, 778 Kommentare, Bewertung + 356.0 / -0.0
- Die Serie 'Tschernobyl': 172.000 Aufrufe, 803 Kommentare, Bewertung + 164.0 / -25.0
- Die schlechteste Lautstärkeregelung der Benutzeroberfläche 166.000 Aufrufe, 176 Kommentare, Bewertung + 292.0 / -30.0
- Ein ehrlicher Lebenslauf eines Programmierers 165.000 Aufrufe, 283 Kommentare, Bewertung + 410.0 / -40.0
- Ich ruiniere das Leben der Entwickler mit meinen Code-Bewertungen und es tut mir leid, 164.000 Aufrufe, 12 Kommentare, Bewertung + 33.0 / -3.0
- Wie Megafon auf Mobilabonnements geschlafen hat 162.000 Aufrufe, 676 Kommentare, Bewertung + 624.0 / -2.0
- Aufstand auf der Picaba. Benutzer gehen zu Reddit en masse 160.000 Aufrufe, 484 Kommentare, Bewertung + 215.0 / -41.0
- Günstige und teure AAA-Batterien 159.000 Aufrufe, 382 Kommentare, Bewertung + 363.0 / -6.0
- Bei 22.156.000 Ansichten, 922 Kommentaren, Bewertung + 259.0 / -100.0 in den Ruhestand getreten
- Mann ohne Smartphone 152000 Aufrufe, 736 Kommentare, Bewertung + 173.0 / -25.0
- Willst du ewige LEDs? Lötkolben und Feilen aufdecken. Oder hausgemachte hausgemachte Beleuchtung 149.000 Aufrufe, 262 Kommentare, Bewertung + 94.0 / -6.0
- Was Sie nicht tun müssen, wenn Ihr Telefon gestohlen wird 144.000 Aufrufe, 638 Kommentare, Bewertung + 259.0 / -27.0
- 1. Februar 2019 Ihre Website funktioniert möglicherweise nicht mehr 143.000 Aufrufe, 162 Kommentare, Bewertung + 89.0 / -8.0
Top-Artikel zum Verhältnis von Bewertungen zu Ansichten- Schwächen Sie die Nüsse, Teil 2: Die Frist für die Abstimmung für Veröffentlichungen und andere Änderungen beträgt 14000 Aufrufe, Bewertung + 238,0 / -3,0
- Ziemlich phantasievolle 'Anfänge' von Euklid in den TeX-e 10.800 Ansichten, Bewertung + 136.0 / -0.0
- Benutzerbelohnung für Autoren von Habr 26400 Ansichten, Bewertung + 320.0 / -0.0
- Senden von Druckfehlernachrichten in Veröffentlichungen 18.900 Aufrufe, Bewertung + 179.0 / -2.0
- Hallo Welt! Oder Habr in Englisch, v1.0 21.000 Aufrufe, Bewertung + 178.0 / -2.0
- Leben auf Partikeln 34.000 Aufrufe, Bewertung + 267,0 / -2,0
- Civilization of Springs, 5/5 25800 Aufrufe, Bewertung + 201.0 / -1.0
- Wir spielen Tetris auf dem elektromechanischen Bildschirm mit 16300 Ansichten, Bewertung + 124,0 / -0,0
- Wiederherstellen von Schriftarten von einem CRT-Bildschirm 13.400 Aufrufe, Bewertung + 101,0 / -0,0
- Das mathematische Modell des Spiels ist Dobble 14600 Aufrufe, Bewertung + 110.0 / -0.0
- Eine wichtige Nachricht zu Einladungen im Profil sind 18300 Aufrufe mit einer Bewertung von + 137,0 / -8,0
- Schwächen Sie die Nüsse in den Habr-Regeln 48300 Ansichten, Bewertung + 338,0 / -13,0
- Street Magic Codec Vergleich. Wir enthüllen die Geheimnisse von 21.700 Ansichten mit einer Bewertung von + 144,0 / -0,0
- Intelligenter Parser für Zahlen, die in Worten mit 20.500 Ansichten aufgezeichnet wurden , Bewertung + 136,0 / -1,0
- Generische und Metaprogrammiermodelle: Go, Rust, Swift, D und andere 17000 Ansichten, Bewertung + 110.0 / -2.0
- Ich erstelle eine globale Wissensbasis für Batterien mit 22.200 Ansichten und einer Bewertung von + 139,0 / -0,0
- Als ich ein Buch über die Moskauer Staatsuniversität schrieb und veröffentlichte, oder 12 kritische Fehler, 21.600 Aufrufe, Bewertung + 134,0 / -0,0
- Über Kote, Frau, zwei Söhne, die Idee ... und nicht nur. Eine Geschichte mit einer Fortsetzung von 43.000 Ansichten, Bewertung + 269.0 / -8.0
- Computervideo in 755 Megapixeln: Plenoptik gestern, heute und morgen 41.500 Aufrufe, Bewertung + 244,0 / -0,0
- Die Grundstücksdichte im Einzelhandel 27.500 Aufrufe, Bewertung + 160,0 / -1,0
Top-Artikel zum Verhältnis von Kommentaren zu Ansichten- Github hat damit begonnen, Benutzer-Repositories auf der Krim, in Kuba, im Iran, in Nordkorea und in Syrien zu blockieren. 44.500 Aufrufe, 1.309 Kommentare, Bewertung + 115,0 / -6,0
- Ukrainischunterricht 60400 Aufrufe, 1672 Kommentare, Bewertung + 285.0 / -41.0
- Schwächen Sie die Nüsse in den Habr-Regeln 48300 Aufrufe, 1285 Kommentare, Bewertung + 338.0 / -13.0
- Die Rallye gegen die Isolation von Runet 50.900 Aufrufe, 923 Kommentare, Bewertung + 204.0 / -32.0
- Wie man zwei Räder fährt, um zu arbeiten 47100 Ansichten, 781 Kommentare, Bewertung + 113.0 / -10.0
- Flugzeugabsturz in Sheremetyevo: historische Analogien 82.400 Aufrufe, 1211 Kommentare, Bewertung + 147.0 / -11.0
- Ingenieure retten Menschen, die im Wald verloren gegangen sind, aber der Wald hat 28.900 Aufrufe, 423 Kommentare, Bewertung + 132.0 / -1.0 noch nicht abgegeben
- Rallye gegen die Isolation der Runet 63.300 Aufrufe, 820 Kommentare, Bewertung + 182.0 / -20.0
- Wie der Schutz von Kindern vor Informationen angeordnet ist - und die bezaubernde Geschichte darüber, woher sie zuerst kamen (18+) 65.400 Aufrufe, 811 Kommentare, Bewertung + 175.0 / -2.0
- Hallo Welt! Oder Habr in Englisch, v1.0 21.000 Aufrufe, 249 Kommentare, Bewertung + 178.0 / -2.0
- So kaufen Sie Kartoffeln richtig, wenn Sie farbenblind sind 51.800 Aufrufe, 607 Kommentare, Bewertung + 135.0 / -3.0
- Wie es sich anfühlt, ein freier Software-Betreuer zu sein 22.900 Aufrufe, 259 Kommentare, Bewertung + 129.0 / -3.0
- Schwächen Sie die Nüsse, Teil 2: Abstimmungszeitraum für Veröffentlichungen und andere Änderungen 14000 Aufrufe, 158 Kommentare, Bewertung + 238.0 / -3.0
- Pilotproduktion von Elektronik für einen Mindestpreis von 34.200 Ansichten, 382 Kommentare, Bewertung + 165,0 / -3,0
- Wie statten wir Megaphone 39800 Aufrufe, 405 Kommentare, Bewertung + 140.0 / -6.0 aus?
- Atomkriege der fernen Vergangenheit? 83.400 Aufrufe, 843 Kommentare, Bewertung + 133.0 / -5.0
- Hallo Welt! Oder englischsprachiger Habr, v1.0 60.300 Aufrufe, 591 Kommentare, Bewertung + 268.0 / -7.0
- Raum als vage Erinnerung 43200 Aufrufe, 402 Kommentare, Bewertung + 190.0 / -7.0
- Benutzerbelohnung an die Autoren von Habr 26.400 Aufrufe, 245 Kommentare, Bewertung + 320.0 / -0.0
- Die Prinzipien des freien Marktes im Verständnis der Vereinigten Staaten 56.300 Ansichten, 502 Kommentare, Rating + 160.0 / -44.0
Top umstrittensten Artikel- State and T-Killers 752 Kommentare, Bewertung + 83.0 / -80.0, 15100 Aufrufe
- Diese giftigen Typen: Sie vergiften Projekte mit 120 Kommentaren, Bewertung + 67,0 / -51,0, 50.300 Ansichten
- Warum unterrichten Sie Go 70 Kommentare, Bewertung + 76.0 / -57.0, 23100 Aufrufe
- Ich habe 80 Lebensläufe gelesen, ich habe Fragen 635 Kommentare, Bewertung + 135.0 / -94.0, 90700 Aufrufe
- Warum es eigentlich unmöglich ist, Vegetarier zu sein 940 Kommentare, Bewertung + 76.0 / -52.0, 51.600 Aufrufe
- Funktionale Programmierung: Ein verrücktes Spielzeug, das die Arbeitsproduktivität beeinträchtigt. Teil 1 394 Kommentare, Bewertung + 100.0 / -68.0, 54000 Aufrufe
- Wir haben den nützlichsten Code in unserem Leben geschrieben, ihn aber in den Papierkorb geworfen. Zusammen mit uns 259 Kommentare, Bewertung + 101.0 / -63.0, 62900 Aufrufe
- Appell in Apple 96 Kommentare, Bewertung + 90.0 / -52.0, 39.300 Aufrufe
- Warum steuert Windows 2019 nicht oder CHYDNT? 881 Kommentare, Bewertung + 123.0 / -70.0, 75.000 Aufrufe
- Ich bin nicht echt 246 Kommentare, Bewertung + 105.0 / -59.0, 63900 Aufrufe
- Fünf beängstigende Trends der modernen Entwicklung 262 Kommentare, Bewertung + 95,0 / -52,0, 77400 Aufrufe
- Je schneller Sie OOP vergessen , desto besser für Sie und Ihre Programme 1271 Kommentare, Bewertung + 131,0 / -63,0, 128000 Aufrufe
- Ein Jahr hinter dem Lenkrad eines Elektrofahrzeugs 1098 Kommentare, Bewertung + 131.0 / -58.0, 71800 Aufrufe
- Ich werde aufhören, gut zu treten , um 179 Kommentare zu werfen , Bewertung + 147,0 / -62,0, 34.400 Aufrufe
- Fangen Sie mich, wenn Sie 215 Kommentare, Bewertung + 141.0 / -58.0, 65.400 Aufrufe können
- Bei 22.922 Kommentaren im Ruhestand, Bewertung + 259.0 / -100.0, 156.000 Aufrufe
- Antwort des Psychiaters auf den Artikel 'Krank und gesund' 272 Kommentare, Bewertung + 154,0 / -55,0, 43.400 Aufrufe
- Neue Programmiersprachen zerstören unmerklich unsere Verbindung zur Realität. 764 Kommentare, Bewertung + 164,0 / -52,0, 106.000 Aufrufe
- Alkoholismus im letzten Stadium 597 Kommentare, Bewertung + 208.0 / -60.0, 123.000 Aufrufe
- 'Blowjob-Artikel': Wissenschaftler verarbeiteten 109 Stunden Oralsex, um eine KI zu entwickeln, die einem Mitglied 361 Kommentare mit einer Bewertung von + 240,0 / -68,0 und 236.000 Ansichten entlockt
Bestbewertete Artikel- Wie Megafon auf Mobilabonnements geschlafen hat , 676 Kommentare, Bewertung + 624,0 / -2,0, 162.000 Aufrufe
- 'Mobile Inhalte' kostenlos, ohne SMS und Registrierung. Details zum Megaphon-Betrug , 474 Kommentare, Bewertung + 488.0 / -8.0, 112.000 Aufrufe
- Innovationen in russischer Sprache , 612 Kommentare, Bewertung + 480.0 / -33.0, 127.000 Aufrufe
- Wie ich ein Jahr lang nicht bei Sberbank gearbeitet habe , 580 Kommentare, Bewertung + 449,0 / -14,0, 233.000 Aufrufe
- Wie Protonmail in Russland blockiert wird , 398 Kommentare, Bewertung + 418.0 / -7.0, 102.000 Aufrufe
- 10 Jahre in der IT mit einer Diagnose von Schizophrenie, Überlebenstipps , 281 Kommentaren, Bewertung + 403,0 / -8,0, 122.000 Aufrufe
- Ein ehrlicher Lebenslauf eines Programmierers , 283 Kommentare, Bewertung + 410.0 / -40.0, 165.000 Aufrufe
- Wenn 'a' nicht gleich 'a' ist. Nach einem Hack 64 Kommentare, Bewertung + 374,0 / -5,0, 74.600 Aufrufe
- Erhöhen Sie es! Erhöhung der modernen Auflösung , 214 Kommentare, Bewertung + 366,0 / -1,0, 104000 Aufrufe
- LED-Lügen von beispiellosem Ausmaß , 569 Kommentare, Bewertung + 364,0 / -1,0, 241.000 Aufrufe
- Günstige und teure AAA-Batterien , 382 Kommentare, Bewertung + 363,0 / -6,0, 159.000 Aufrufe
- Betrüger und EDS - alles ist sehr schlecht , 778 Kommentare, Bewertung + 356.0 / -0.0, 175000 Aufrufe
- Japan: ein Land mit so gesundem Menschenverstand, dass es an einigen Stellen für uns irrational ist , 483 Kommentare, Bewertung + 365,0 / -12,0, 138.000 Aufrufe
- Schwächen Sie die Nüsse in den Habr-Regeln , 1285 Kommentare, Bewertung + 338.0 / -13.0, 48300 Aufrufe
- Benutzerbelohnung an die Autoren von Habr , 245 Kommentare, Bewertung + 320.0 / -0.0, 26.400 Aufrufe
- Wie ich einen Hacker erwischt habe , 273 Kommentare, Bewertung + 305.0 / -6.0, 110.000 Aufrufe
- Mythen der modernen Populärphysik , 556 Kommentare, Bewertung + 304.0 / -6.0, 99.600 Aufrufe
- Jetzt werden gute Entwickler an Ansichten und Abonnenten gemessen - und das ist schlecht , 486 Kommentare, Bewertung + 324,0 / -26,0, 74800 Ansichten
- Überlebe in einer Frontalkollision und warum Amnesie nicht das ist, was du denkst , 165 Kommentare, Bewertung + 297.0 / -4.0, 61800 Aufrufe
- Port-Scanner im persönlichen Konto von Rostelecom , 194 Kommentare, Bewertung + 300,0 / -8,0, 111.000 Aufrufe
Top Lesezeichen Artikel- 42 Google Advanced Search Operators (vollständige Liste) 47.100 Aufrufe, 917 Lesezeichen
- Wie man in 1,5 Jahren Java-Entwickler wird 88.500 Aufrufe, 894 Lesezeichen
- Sampler. Konsolen-Dienstprogramm zur Visualisierung des Ergebnisses von Shell-Befehlen 58.400 Ansichten, 801 Lesezeichen
- HBO, danke, dass Sie mich daran erinnert haben ... 'Tschernobyl-Erste-Hilfe-Kasten' eines belarussischen Apothekers 88.500 Aufrufe, 797 Lesezeichen
- Praktische Tipps, Beispiele und Tunnel SSH 40.000 Aufrufe, 787 Lesezeichen
- 256 Zeilen nacktes C ++: Schreiben eines Raytracers von Grund auf in wenigen Stunden 60.000 Aufrufe, 745 Lesezeichen
- Asynchrone Programmierung (vollständiger Kurs) 36.700 Aufrufe, 690 Lesezeichen
- 'Verbrannte' Mitarbeiter: Gibt es einen Ausweg? 116.000 Aufrufe, 688 Lesezeichen
- Ein umfassender Überblick über Python-Interviews. Tipps und Tricks 28.400 Aufrufe, 687 Lesezeichen
- 15 Bücher zum maschinellen Lernen für Anfänger 18.700 Aufrufe, 670 Lesezeichen
- Vorlesung über JavaScript und Node.js in KPI 52500-Ansichten, 656 Lesezeichen
- Wie ich mathematische Notizen zu LaTeX in Vim 58100-Ansichten und 652 Lesezeichen schreibe
- Was ich aus meiner bitteren Erfahrung (über 30 Jahre in der Softwareentwicklung) gelernt habe 100.000 Aufrufe, 651 Lesezeichen
- Eine Auswahl nützlicher Folien aus Julia Evans 41.000 Aufrufe, 587 Lesezeichen
- HTTP-Header für verantwortliche Entwickler 33.600 Aufrufe, 566 Lesezeichen
- N + 7 nützliche Bücher 42.700 Aufrufe, 563 Lesezeichen
- CAN-Bus automatisch hacken. Virtuelles Dashboard 60.700 Aufrufe, 562 Lesezeichen
- Sorgfältiger Umzug in die Niederlande mit seiner Frau und Hypothek. Teil 1: Jobsuche 76200 Aufrufe, 555 Lesezeichen
- TCP vs UDP oder die Zukunft der Netzwerkprotokolle 50.300 Aufrufe, 538 Lesezeichen
- Beste Linux-Distributionen für ältere Computer 66.000 Aufrufe, 523 Lesezeichen
Top by View Lesezeichenverhältnis- 15 Bücher zum maschinellen Lernen für Anfänger 670 Lesezeichen, 18.700 Aufrufe
- Musik für Ihre Projekte: 12 thematische Ressourcen mit Titeln, die unter Creative Commons 477-Lesezeichen lizenziert sind , 18.100 Aufrufe
- Ein umfassender Überblick über Python-Interviews. Tipps und Tricks 687 Lesezeichen, 28.400 Aufrufe
- Eine Auswahl von Datensätzen für maschinelles Lernen 455 Lesezeichen, 19.000 Aufrufe
- Dungeon-Generator basierend auf Knoten von Diagramm 304 Lesezeichen, 12.700 Ansichten
- Eine einfache Erklärung der Pfadsuchalgorithmen und A * 316-Lesezeichen, 13.500 Ansichten
- Web-Tools oder wo man einen Pentester startet? 421 Lesezeichen, 18800 Ansichten
- Learning Docker, Teil 2: Begriffe und Konzepte 341 Lesezeichen, 15.600 Aufrufe
- Docker erkunden, Teil 3: Dockerfile-Dateien 297 Lesezeichen, 13.800 Ansichten
- Tools zum Analysieren und Debuggen von .NET-Anwendungen 244 Lesezeichen, 11.600 Ansichten
- Debuggen von Umgebungsvariablen in Linux 322-Lesezeichen, 15.900 Aufrufe
- Wie mache ich die ersten Schritte in der Robotik? 224 Lesezeichen, 11.200 Aufrufe
- Labyrinthe: Klassifizierung, Generierung, Suche nach Lösungen 318 Lesezeichen, 16.000 Aufrufe
- Praktische Tipps, Beispiele und Tunnel SSH 787 Lesezeichen, 40.000 Aufrufe
- Vorlesung 'Grundlagen der digitalen Signalverarbeitung' 418 Lesezeichen, 21.400 Aufrufe
- 42 Google Advanced Search Operators (vollständige Liste) 917 Lesezeichen, 47.100 Aufrufe
- 3D Game Shader für Anfänger 239 Lesezeichen, 12.400 Aufrufe
- Punktumgehung PKH sperrt einen Router mit OpenWrt mithilfe von WireGuard- und DNSCrypt 302-Lesezeichen, 15.700 Aufrufe
- Entwicklung der Fähigkeit zur Verwendung von Gruppierung und Datenvisualisierung in Python 192-Lesezeichen, 10.000 Ansichten
- Ein weiterer Github 2: Maschinelles Lernen, Datensätze und Jupyter-Notizbücher 265 Lesezeichen, 13.900 Aufrufe
Top kommentierte Artikel- Ukrainischunterricht 1672 Kommentare, 60.400 Aufrufe
- Rakete 9M729. Ein paar Worte zum „Verstoß“ gegen den INF-Vertrag 1371 Kommentare, 83.000 Aufrufe
- Github hat damit begonnen, Benutzer-Repositories auf der Krim, in Kuba, im Iran, in Nordkorea und in Syrien zu blockieren. 1.309 Kommentare, 44.500 Aufrufe
- Schwächen Sie Nüsse in Habr Regeln 1285 Kommentare, 48300 Ansichten
- Je schneller Sie OOP vergessen , desto besser für Sie und Ihre Programme 1271 Kommentare, 128000 Aufrufe
- Flugzeugabsturz in Sheremetyevo: historische Analogien 1211 Kommentare, 82.400 Aufrufe
- Wie wurde aus der Generation Y eine ausgebrannte Generation? 1122 Kommentare, 81.500 Aufrufe
- Elektroauto ist nicht für mich 1116 Kommentare, 50.700 Aufrufe
- 1098 , 71800
- 1021 , 27500
- 999 , 62100
- 997 , 7700
- 940 , 51600
- , 933 , 120000
- 923 , 50900
- 22 922 , 156000
- Auswahl eines Autos für einen IT-Spezialisten oder Tipps für Teekannen aus einer Teekanne 914 Kommentare, 43.400 Aufrufe
- Warum ältere Entwickler keinen Job bekommen können 901 Kommentare, 119.000 Aufrufe
- Der Plan kehrte zur Wirtschaft zurück 892 Kommentare, 27.800 Aufrufe
- Persönlicher Stadt-Teleportator 889 Kommentare, 40.800 Aufrufe
Und schließlich der letzte Anti-Stop durch die Anzahl der Abneigungen- Bei 22.922 Kommentaren im Ruhestand, Bewertung + 259.0 / -100.0
- Ich habe 80 Lebensläufe gelesen, habe Fragen , 635 Kommentare, Bewertung + 135.0 / -94.0
- Schatz, wir töten das Internet , 933 Kommentare, Bewertung + 392.0 / -83.0
- Staat und T-Killer , 752 Kommentare, Bewertung + 83.0 / -80.0
- Windows 2019 , ? , 881 , +123.0/-70.0
- : , . 1 , 394 , +100.0/-68.0
- ' ': 109 , , , 361 , +240.0/-68.0
- , . , 259 , +101.0/-63.0
- , , 1271 , +131.0/-63.0
- - , 179 , +147.0/-62.0
- , 668 , +315.0/-60.0
- , 597 , +208.0/-60.0
- , 246 , +105.0/-59.0
- , , 215 , +141.0/-58.0
- , 1098 , +131.0/-58.0
- Go , 70 , +76.0/-57.0
- '-' , 272 , +154.0/-55.0
- Apple , 96 , +90.0/-52.0
- , 764 , +164.0/-52.0
- Fünf beängstigende Trends der modernen Entwicklung , 262 Kommentare, Bewertung + 95,0 / -52,0
Uff. Ich habe einige interessantere Beispiele, aber ich werde die Leser nicht langweilen.Fazit
Bei der Erstellung der Bewertung habe ich auf zwei Punkte hingewiesen, die interessant erschienen.Erstens sind immerhin 60% der Top-Artikel im Geektimes-Genre. Ob es nächstes Jahr weniger davon geben wird und wie Habr ohne Artikel über Bier, Weltraum, Medizin usw. aussehen wird - weiß ich nicht. Die Leser werden definitiv etwas verlieren. Mal sehen.
Zweitens erwies sich die Lesezeichenoberseite als unerwartet hochwertig. Dies ist psychologisch verständlich, die Leser achten möglicherweise nicht auf die Bewertung, und wenn ein Artikel benötigt wird, fügen sie ihn Lesezeichen hinzu. Und hier ist nur die größte Konzentration nützlicher und seriöser Artikel. Ich denke, dass die Eigentümer der Website die Beziehung zwischen der Anzahl der Lesezeichen und dem Incentive-Programm in Betracht ziehen sollten, wenn sie diese bestimmte Kategorie von Artikeln hier auf Habré erweitern möchten.Irgendwie so.
Ich hoffe es war informativ.Die Liste der Artikel ist lang, aber wahrscheinlich die beste. Viel Spaß beim Lesen für alle.