Kürzlich bin ich
auf einen Kaggle-Datensatz mit Daten zu 45.000 Filmen aus dem Full MovieLens-
Datensatz gestoßen. Die Daten enthielten nicht nur Informationen über die Schauspieler, die Crew, die Handlung usw., sondern auch die Bewertungen der Benutzer der Filme für Filme (26 Millionen Bewertungen von 270.000 Benutzern).
Eine Standardaufgabe für solche Daten ist ein Empfehlungssystem. Aus irgendeinem Grund kam mir der
Gedanke, die Bewertung eines Films anhand der vor seiner Veröffentlichung verfügbaren Informationen vorherzusagen . Ich bin kein Kenner des Kinos und konzentriere mich daher normalerweise auf Rezensionen und wähle aus den Nachrichten aus, was ich sehen möchte. Die Rezensenten sind aber auch etwas voreingenommen - sie sehen viel mehr verschiedene Filme als der durchschnittliche Zuschauer. Daher schien es interessant vorherzusagen, wie der Film von der Öffentlichkeit geschätzt wird.
Der Datensatz enthält also die folgenden Informationen:
- Informationen zum Film: Erscheinungszeit, Budget, Sprache, Firma und Herkunftsland usw. Sowie die durchschnittliche Bewertung (und wir werden es vorhersagen)
- Schlüsselwörter (Tags) zum Plot
- Namen der Schauspieler und der Crew
- Tatsächlich Bewertungen (Schätzungen)
Der im Artikel verwendete Code (Python) ist auf
Github verfügbar.
Datenvorfilterung
Das gesamte Array enthält Daten zu mehr als 45.000 Filmen. Da die Aufgabe jedoch darin besteht, die Bewertung vorherzusagen, müssen Sie sicherstellen, dass die Bewertungen eines bestimmten Films objektiv sind. Zum Beispiel in der Tatsache, dass ziemlich viele Leute es schätzten.
Die meisten Filme haben nur sehr wenige Bewertungen:

Der Film mit der größten Anzahl von Bewertungen (14075) hat mich übrigens überrascht - das ist
„Inception“ . Aber die nächsten drei - "The Dark Knight", "Avatar" und "Avengers" - sehen ziemlich logisch aus.
Es wird erwartet, dass die Anzahl der Bewertungen und das Budget des Films miteinander verbunden sind (niedrigeres Budget - niedrigere Bewertungen). Das Entfernen von Filmen mit einer geringen Anzahl von Bewertungen macht das voreingenommene Modell daher zu teureren Filmen:
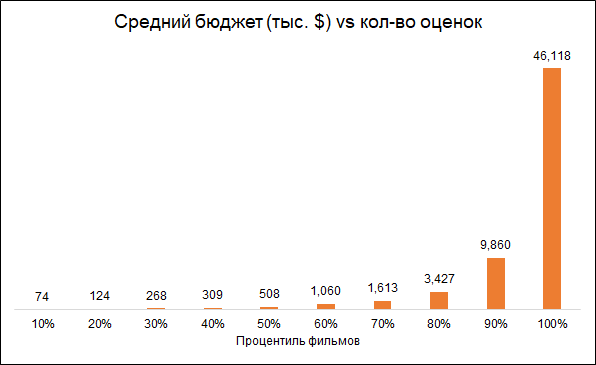
Wir gehen zu Analysefilmen mit mehr als 50 Bewertungen.
Außerdem werden wir Filme entfernen, die vor dem Start des Bewertungsdienstes (1996) veröffentlicht wurden. Hier besteht das Problem darin, dass moderne Filme im Durchschnitt schlechter bewertet werden als alte, einfach weil sie unter alten Filmen die besten sehen und bewerten, und unter modernen Filmen ist das alles.
Infolgedessen enthält das endgültige Array etwa 6.000 Filme.
Verwendete Funktionen
Wir werden verschiedene Gruppen von Funktionen verwenden:
- Filmmetadaten: ob der Film zur „Sammlung“ (Filmreihe) gehört, Land der Veröffentlichung, Produktionsfirma, Sprache des Films, Budget, Genre, Jahr und Monat der Veröffentlichung des Films, Dauer
- Schlüsselwörter: Für jeden Film gibt es eine Liste von Tags, die seine Handlung beschreiben. Da es viele Wörter gibt, wurden sie wie folgt verarbeitet: Gruppiert in Ähnlichkeitsgruppen (z. B. Unfall und Autounfall), basierend auf diesen Gruppen und einzelnen Wörtern, wurde eine PCA-Analyse durchgeführt und die wichtigsten Komponenten aus den Ergebnissen ausgewählt. Dies reduzierte die Dimension des Merkmalsraums.
- Frühere "Verdienste" der Schauspieler, die in dem Film mitgespielt haben. Für jeden Schauspieler wurde eine Liste von Filmen erstellt, in der er zuvor die Hauptrolle spielte, und die Bewertung dieser Filme wurde berechnet. Daher wurde für jeden Film ein Indikator gebildet, der den Erfolg von Filmen zusammenfasst, in denen die Schauspieler zuvor die Hauptrolle gespielt haben.
- Oscars. Wenn die Schauspieler, Regisseure, Produzenten, Drehbuchautoren oder Kameramänner zuvor an einem Film teilgenommen haben, der für den besten Film, die beste Regie oder das beste Drehbuch nominiert oder mit einem Oscar ausgezeichnet wurde, wurde dies im Modell berücksichtigt. Wenn die Schauspieler Nominierte oder Gewinner des Oscar für den besten Nebendarsteller oder die Nebendarstellerrolle waren, wurde dies ebenfalls berücksichtigt. Informationen zu den Oscars von Wikipedia erhalten.
Einige interessante Statistiken
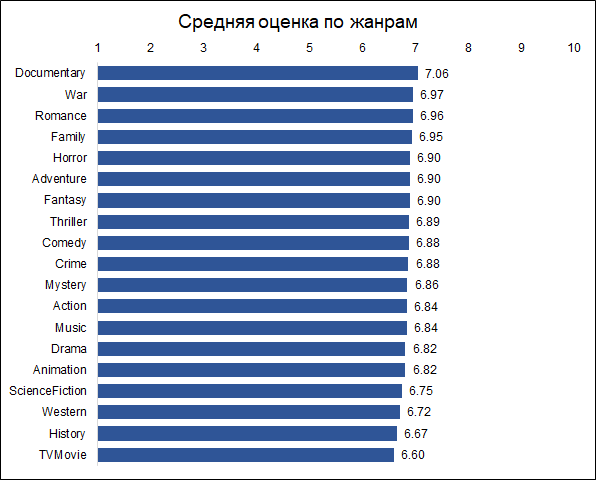
Dokumentarfilme erhalten die höchsten Bewertungen. Dies ist ein guter Grund zu beachten, dass verschiedene Filme von verschiedenen Personen bewertet werden. Wenn Dokumentarfilme von Actionfans bewertet werden, können die Ergebnisse unterschiedlich sein. Das heißt, die Schätzungen sind aufgrund der anfänglichen Präferenzen der Öffentlichkeit voreingenommen. Für unsere Aufgabe ist dies jedoch nicht wichtig, da wir eine nicht bedingt objektive Bewertung vorhersagen möchten (als ob jeder Zuschauer alle Filme gesehen hätte), nämlich diejenige, die dem Film vom Publikum gegeben wird.
Interessant ist übrigens, dass historische Filme viel niedriger bewertet werden als Dokumentarfilme.
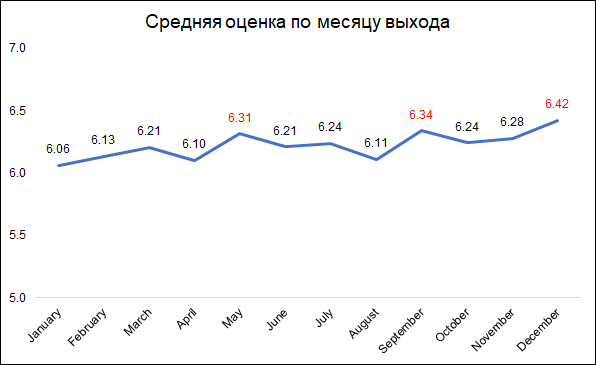
 Die höchsten Bewertungen erhalten Filme, die im Dezember, September und Mai veröffentlicht wurden.
Die höchsten Bewertungen erhalten Filme, die im Dezember, September und Mai veröffentlicht wurden.Dies kann wahrscheinlich wie folgt erklärt werden:
- Im Dezember veröffentlichen Unternehmen die besten Filme, um in den Weihnachtsferien an den Kinokassen zu sammeln
- Im September werden Filme veröffentlicht, die am Kampf um den Oscar teilnehmen werden
- Mai ist die Release-Zeit für Sommer-Blockbuster.
 Die Filmbewertung hängt wenig vom Budget ab
Die Filmbewertung hängt wenig vom Budget ab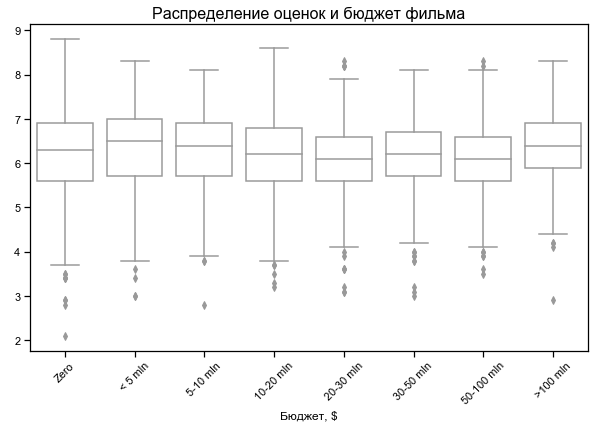
Kein Budget für einige Filme - wahrscheinlich keine Daten
Bestbewertete kürzeste und längste Filme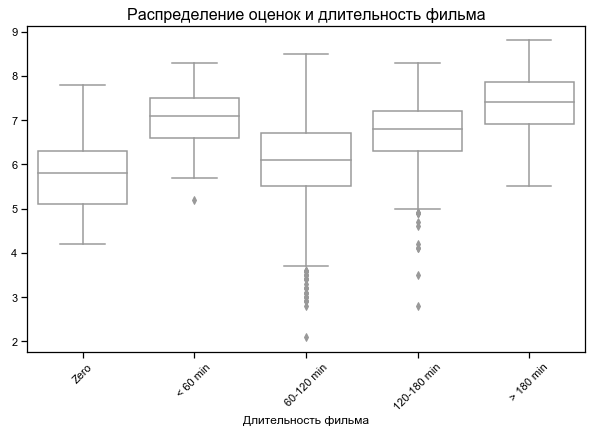
Bei einigen Filmen wird eine Dauer von Null angegeben - wahrscheinlich keine Daten
Ergebnisse zu verschiedenen Funktionssätzen
Unsere Aufgabe - Prognose des Ratings - Aufgabe der Regression. Wir werden drei Modelle testen - lineare Regression (wie Baseline), SVM und XGB. Als Qualitätsmetrik wählen wir RMSE. Die folgende Grafik zeigt die RMSE-Werte im Validierungssatz für verschiedene Modelle und verschiedene Funktionssätze (ich wollte verstehen, ob es sich lohnt, mit Schlüsselwörtern und Oscars zu spielen). Alle Modelle sind mit grundlegenden Hyperparametern ausgestattet.
Wie Sie sehen können, erzielt XGB das beste Ergebnis mit einer Reihe von Funktionen (Filmmetadaten + Schlüsselwörter + Oscars).
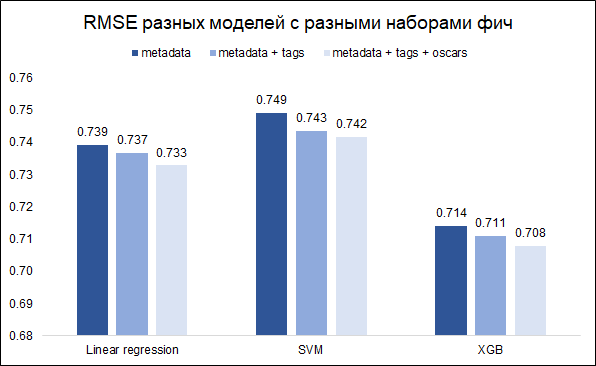
Durch Einstellen der Hyperparameter konnte der RMSE von 0,708 auf 0,706 reduziert werden
Fehleranalyse und abschließende Kommentare
Wir gehen davon aus, dass Fehler von weniger als 5% klein sind (ungefähr ein Drittel) und Fehler von mehr als 20% groß sind (ungefähr 10%). In anderen Fällen (etwas mehr als die Hälfte) wird der Fehlerdurchschnitt berücksichtigt.
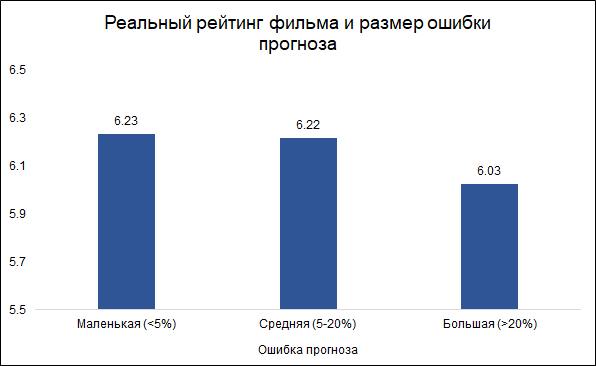
Interessanterweise hängen die Größe des Fehlers und die Bewertung des Films zusammen: Es
ist weniger wahrscheinlich, dass das
Modell Fehler bei guten Filmen macht, und häufiger bei schlechten. Es sieht logisch aus: Gute Filme werden wie jede andere Arbeit eher von erfahreneren und professionelleren Leuten gemacht. Über den Tarantino-Film unter Beteiligung von Brad Pitt kann man im Voraus sagen, dass er höchstwahrscheinlich gut ausfallen wird. Gleichzeitig kann ein Low-Budget-Film mit wenig bekannten Schauspielern sowohl gut als auch schlecht sein, und es ist schwer zu beurteilen, ohne ihn zu sehen.
Hier sind die wichtigsten Merkmale des Modells (PCA-Variablen beziehen sich auf verarbeitete Schlüsselwörter, die die Handlung des Films beschreiben):

Zwei dieser Features gehören zu den Oscars, die zuvor entweder von Teammitgliedern (Regisseur, Produzent, Drehbuchautor, Kameramann) oder von Filmen, in denen die Schauspieler die Hauptrolle spielten, nominiert wurden. Wie oben erwähnt, ist der Prognosefehler mit der Bewertung des Films verbunden, und in diesem Sinne können frühere Nominierungen für die Oscars ein guter Begrenzer für das Modell sein. In der Tat haben Filme mit mindestens einer Oscar-Nominierung (unter Schauspielern oder Teams) einen durchschnittlichen Prognosefehler von 8,3% und Filme ohne solche Nominierungen - 9,8%. Von den Top-10-Merkmalen des Modells sind es die Oscar-Nominierungen, die den besten Zusammenhang mit der Größe des Fehlers herstellen.
Daher kam die Idee auf, zwei separate Modelle zu bauen: eines für Filme, in denen die Schauspieler oder das Team für einen Oscar nominiert wurden, und das zweite für den Rest. Die Idee war, dass dies den Gesamtfehler reduzieren könnte. Das Experiment schlug jedoch fehl: Das allgemeine Modell ergab RMSE 0,706, und zwei separate Modelle ergaben 0,715.
Daher werden wir das Originalmodell verlassen. Die Ergebnisse seiner Genauigkeit sind wie folgt: RMSE in der Trainingsprobe - 0,688, in der Validierungsprobe - 0,706 und in der Testprobe - 0,732.
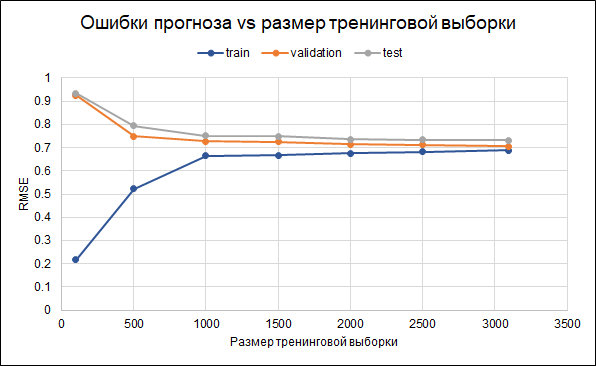
Das heißt, es gibt einige Überanpassungen. Regularisierungsparameter wurden bereits im Modell selbst festgelegt. Eine andere Möglichkeit, die Überanpassung zu reduzieren, könnte darin bestehen, mehr Daten zu sammeln. Um zu verstehen, ob dies hilfreich ist, erstellen wir ein Diagramm mit Fehlern für verschiedene Größen der Trainingsstichprobe - von 100 bis zu maximal 3.000. Das Diagramm zeigt, dass sich ab etwa 2,5 Tausend Punkten im Trainingssatz Fehler im Training, in der Validierung und im Testsatz ändern klein, dh eine Erhöhung der Stichprobe hat keinen signifikanten Effekt.
 Was können Sie sonst noch versuchen, um das Modell zu verfeinern:
Was können Sie sonst noch versuchen, um das Modell zu verfeinern:- Anfangs werden Filme unterschiedlich ausgewählt (unterschiedliche Begrenzung der Stimmenzahl, zusätzliche Begrenzung anderer Variablen)
- Nicht alle Bewertungen werden zur Berechnung der Bewertung verwendet. Es ist möglich, aktivere Benutzer auszuwählen oder diejenigen zu entfernen, die nur schlechte Bewertungen abgeben
- Probieren Sie verschiedene Möglichkeiten aus, um fehlende Daten zu ersetzen
Interessanterweise hatte der Film „Batman and Robin“ von 1997 den größten Prognosefehler (7 Prognosepunkte anstelle von 4,2 realen). Der Film mit Arnold Schwarzenegger, George Clooney und Uma Thurman erhielt
11 Golden Raspberry Award-
Nominierungen (und einen Sieg) , führte die
Liste der 50 schlechtesten Filme der Geschichte aus der Empire-Wochenschau an und führte zur
Absage der Fortsetzung und zum Neustart der gesamten Serie . Nun, hier hat sich das Modell vielleicht wie ein Mann geirrt :)