Ich war immer daran interessiert, wie ich Bücher in meiner elektronischen Bibliothek besser verteilen kann. Als Ergebnis kam ich zu dieser Option mit automatischer Berechnung der Anzahl der Seiten und anderer Extras. Ich frage alle Interessierten unter Katze.
Teil 1. Dropbox
Alle Bücher, die ich habe, befinden sich in der Dropbox. Es gibt 4 Kategorien, in die ich alles unterteilt habe: Lehrbuch, Referenz, Künstlerisch, Nicht-Künstlerisch. Ich füge dem Tablet jedoch keine Nachschlagewerke hinzu.
Die meisten Bücher sind .epub, der Rest ist .pdf. Das heißt, die endgültige Lösung sollte irgendwie beide Optionen abdecken.
Die Wege zu Büchern sind ungefähr so:
///// / .epub
Wenn es sich bei dem Buch um eine Fiktion handelt, wird die Kategorie (im obigen Fall "Design") entfernt.
Ich habe beschlossen, mich nicht mit der Dropbox-API zu beschäftigen, zum Glück habe ich ihre Anwendung, die den Ordner synchronisiert. Das heißt, der Plan lautet wie folgt: Nehmen Sie Bücher aus einem Ordner, führen Sie jedes Buch durch einen Wortzähler und fügen Sie es Notion hinzu.
Teil 2. Fügen Sie eine Zeile hinzu
Der Tisch selbst sollte ungefähr so aussehen. ACHTUNG: Spaltennamen werden am besten in lateinischen Buchstaben geschrieben.
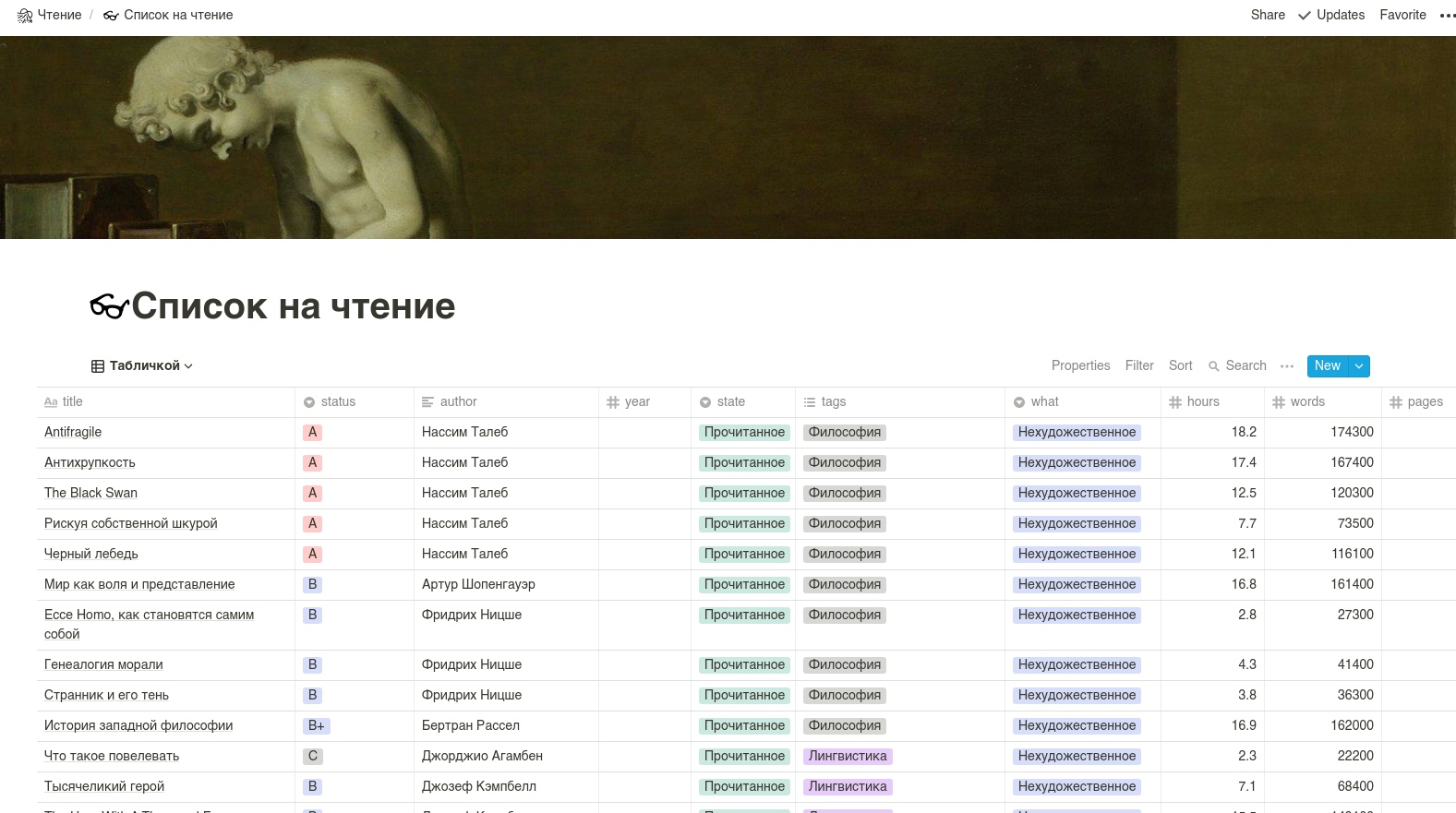
Wir werden die inoffizielle Notion-API verwenden, da die offizielle noch nicht ausgeliefert wurde.

Gehen Sie zu Notion, drücken Sie Strg + Umschalt + J, gehen Sie zu Anwendung -> Cookies, kopieren Sie token_v2 und nennen Sie es TOKEN. Dann gehen wir zu der Seite, die wir mit dem Bibliotheksteller benötigen, und kopieren den Link. Rufen Sie NOTION an.
Dann schreiben wir den Code, um eine Verbindung zu Notion herzustellen.
database = client.get_collection_view(NOTION) current_rows = database.default_query().execute()
Als nächstes schreiben wir eine Funktion, um der Beschriftung eine Zeile hinzuzufügen.
def add_row(path, file, words_count, pages_count, hours): row = database.collection.add_row() row.title = file tags = path.split("/") if len(tags) >= 1: row.what = tags[0] if len(tags) >= 2: row.state = tags[1] if len(tags) >= 3: if tags[0] == "": row.author = tags[2] elif tags[0] == "": row.tags = tags[2] elif tags[0] == "": row.tags = tags[2] if len(tags) >= 4: row.author = tags[3] row.hours = hours row.pages = pages_count row.words = words_count
Was ist hier los? Wir nehmen und fügen der Tabelle in der ersten Zeile eine neue Zeile hinzu. Als nächstes teilen wir unseren Pfad durch "/" und erhalten die Tags. Tags - in Bezug auf "Künstlerisch", "Design", wer ist der Autor und so weiter. Dann setzen wir alle notwendigen Felder der Platte.
Teil 3. Wörter, Uhren und andere Freuden zählen
Dies ist eine kompliziertere Aufgabe. Wie wir uns erinnern, haben wir zwei Formate: epab und pdf. Wenn mit dem Epab alles klar ist - es gibt wahrscheinlich Wörter dort, dann ist was mit PDF nicht so einfach: Es kann einfach aus geklebten Bildern bestehen.
Die Funktion zum Zählen von Wörtern im PDF sieht also folgendermaßen aus: Wir nehmen die Anzahl der Seiten und multiplizieren sie mit einer bestimmten Konstante (durchschnittliche Anzahl der Wörter pro Seite).
Da ist sie:
def get_words_count(pages_number): return pages_number * WORDS_PER_PAGE
Dies ist WORDS_PER_PAGE für A4 Seite ca. 300.
Schreiben wir nun eine Funktion zum Zählen der Seiten. Wir werden PyPDF2 verwenden .
def get_pdf_pages_number(path, filename): pdf = PdfFileReader(open(os.path.join(path, filename), 'rb')) return pdf.getNumPages()
Als nächstes schreiben wir eine Kleinigkeit zum Zählen von Seiten in epaba. Wir verwenden epub_converter . Hier nehmen wir ein Buch, wandeln es in Zeilen um und zählen für jede Zeile Wörter.
def get_epub_pages_number(path, filename): book = open_book(os.path.join(path, filename)) lines = convert_epub_to_lines(book) words_count = 0 for line in lines: words_count += len(line.split(" ")) return round(words_count / WORDS_PER_PAGE)
Jetzt zählen wir die Zeit. Wir nehmen unsere Lieblingswörter und dividieren sie durch Ihre Lesegeschwindigkeit.
def get_reading_time(words_count): return round(((words_count / WORDS_PER_MINUTE) / 60) * 10) / 10
Teil 4. Alle Teile verbinden
Wir müssen alle möglichen Pfade in unserem Buchordner umgehen. Überprüfen Sie, ob in Notion bereits ein Buch vorhanden ist. Wenn dies der Fall ist, müssen Sie keine Zeile mehr erstellen.
Dann müssen wir den Dateityp bestimmen, abhängig davon die Anzahl der Wörter zählen. Fügen Sie am Ende ein Buch hinzu.
Hier ist der Code, den wir bekommen:
for root, subdirs, files in os.walk(BOOKS_DIR): if len(files) > 0 and check_for_excusion(root): for file in files: array = file.split(".") filetype = file.split(".")[len(array) - 1] filename = file.replace("." + filetype, "") local_root = root.replace(BOOKS_DIR, "") print("Dir: {}, file: {}".format(local_root, file)) if not check_for_existence(filename): print("Dir: {}, file: {}".format(local_root, file)) if filetype == "pdf": count = get_pdf_pages_number(root, file) else: count = get_epub_pages_number(root, file) words_count = get_words_count(count) hours = get_reading_time(words_count) print("Pages: {}, Words: {}, Hours: {}".format(count, words_count, hours)) add_row(local_root, filename, words_count, count, hours)
Die Funktion zum Überprüfen, ob das Buch hinzugefügt wurde, sieht folgendermaßen aus:
def check_for_existence(filename): for row in current_rows: if row.title in filename: return True elif filename in row.title: return True return False
Fazit
Vielen Dank an alle, die diesen Artikel gelesen haben. Ich hoffe sie hilft dir mehr zu lesen :)