Es ist einfach zu berechnen, wie viel Verkehr vom YouTube-Kanal kam. Wechseln Sie beispielsweise zum Zähler für Yandex-Metriken oder Google Analytics. Und Sie versuchen herauszufinden, was mit Ihrem Video auf dem Kanal passiert ist. Wer sah ihn an, wer fügte zu den Favoriten hinzu und wer mochte nicht. Zum Entladen solcher Daten benötigen Sie jedoch ein Python-Skript.
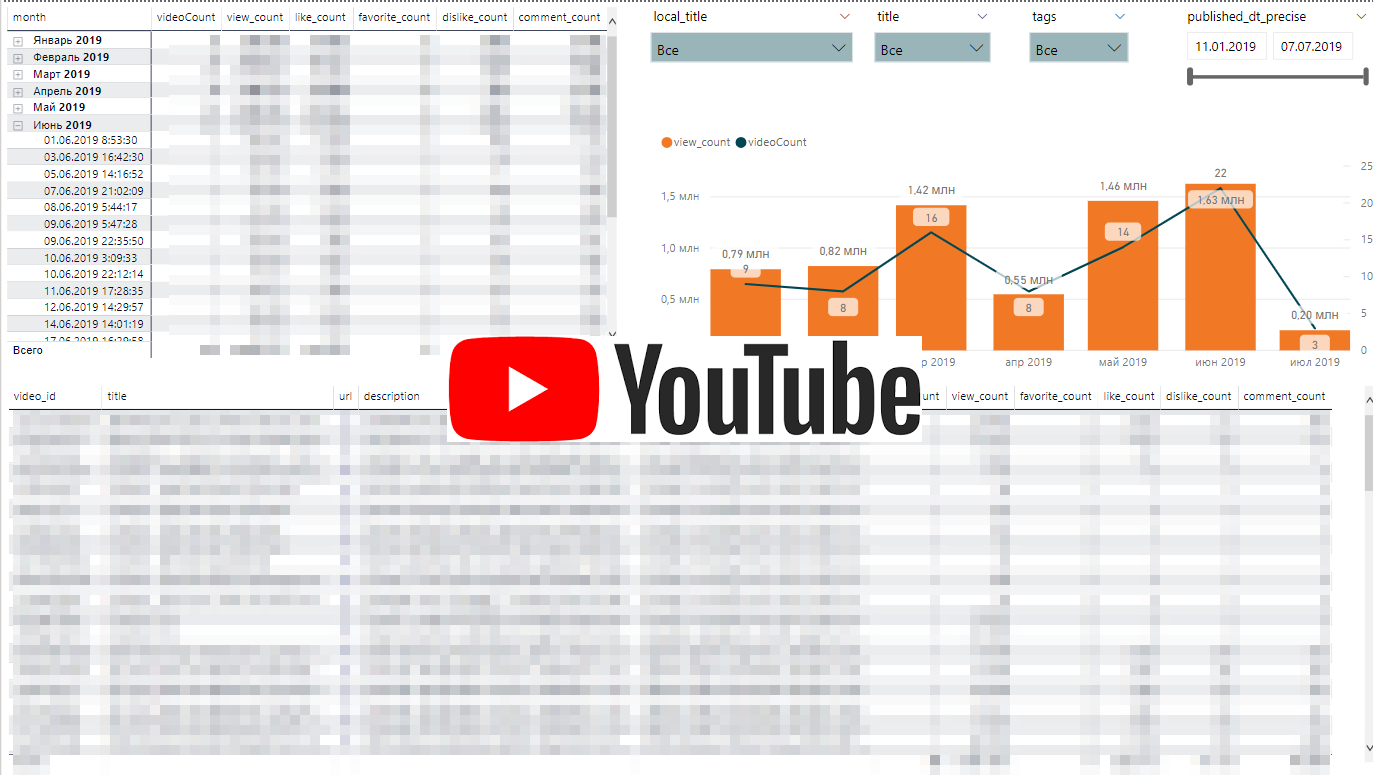 Die Dynamik von Youtube-Aktivitäten
Die Dynamik von Youtube-AktivitätenDie Youtube-API ist recht einfach. Wir werden eine Liste mit Wiedergabelisten hochladen und für jede Wiedergabeliste Statistiken zum Video hochladen.
YOUTUBE_API_URL = 'https://www.googleapis.com/youtube/v3' YOUTUBE_API_KEY = '...' YOUTUBE_CHANNEL_ID = '...'
Die Kanal-ID finden Sie im Seitencode. Informationen zum Erhalt des Zugangsschlüssels finden Sie
hier . Erstellen Sie eine report_client-Klasse und definieren Sie darin Prozeduren.
class report_client: def __init__(self, api_url, api_key, proxies): self._url = api_url self._key = api_key self._proxies = proxies def req_video(self, channel_id = YOUTUBE_CHANNEL_ID): url = ('{0}/activities?channelId={1}&key={2}&part=snippet%2CcontentDetails&maxResults=50') r = requests.get(url.format(self._url, channel_id,self._key) , proxies = self._proxies) parsed = json.loads(r.text) res_df = pd.DataFrame(columns=['video_id']) for i in parsed['items']: temp = {} if 'upload' in i['contentDetails']: temp['video_id'] = i['contentDetails']['upload']['videoId'] res_df = res_df.append(temp, ignore_index=True) return res_df def req_playlist(self, channel_id = YOUTUBE_CHANNEL_ID): url = ('{0}/playlists?channelId={1}&key={2}&part=snippet%2CcontentDetails&maxResults=50') r = requests.get(url.format(self._url, channel_id, self._key) , proxies = self._proxies) parsed = json.loads(r.text) res_df = pd.DataFrame(columns=['playlist_id', 'playlist_name']) for i in parsed['items']: temp = {} temp['playlist_id'] = i['id'] temp['playlist_name'] = i['snippet']['title'] res_df = res_df.append(temp, ignore_index=True) return res_df def req_playlist_stat(self, playlist_id, channel_id = YOUTUBE_CHANNEL_ID): res_df = pd.DataFrame(columns=['video_id', 'playlist_id', 'playlist_name']) for i,k in playlist_id.iterrows(): url = ('{0}/playlistItems?playlistId={1}&key={2}&part=snippet&maxResults=50') r = requests.get(url.format(self._url, k['playlist_id'],self._key) , proxies = self._proxies) parsed = json.loads(r.text) for j in parsed['items']: temp = {} temp['video_id'] = j['snippet']['resourceId']['videoId'] temp['playlist_id'] = k['playlist_id'] temp['playlist_name'] = k['playlist_name'] res_df = res_df.append(temp, ignore_index=True) stop = 0 while 'nextPageToken' in parsed: url = ('{0}/playlistItems?playlistId={1}&key={2}&part=snippet&maxResults=50&pageToken={3}') r = requests.get(url.format(self._url, k['playlist_id'],self._key,parsed['nextPageToken']) , proxies = self._proxies) parsed = json.loads(r.text) for j in parsed['items']: temp = {} temp['video_id'] = j['snippet']['resourceId']['videoId'] temp['playlist_id'] = k['playlist_id'] temp['playlist_name'] = k['playlist_name'] res_df = res_df.append(temp, ignore_index=True) stop = stop + 1 if stop == 1: break return res_df def req_stat(self, video_id): res_df = pd.DataFrame(columns=['video_id','publishedAt','title','description',\ 'tags','local_title','viewCount','likeCount',\ 'dislikeCount','favoriteCount','commentCount'\ , 'playlist_id', 'playlist_name']) for i,k in video_id.iterrows(): url = ('{0}/videos?id={1}&key={2}&part=snippet,contentDetails,statistics,status&maxResults=50') r = requests.get(url.format(self._url, k['video_id'], self._key) , proxies = self._proxies) parsed = json.loads(r.text) if 'error' in parsed.keys(): break temp = {} if 'items' in parsed: if parsed['items']: temp['video_id'] = parsed['items'][0]['id'] temp['publishedAt'] = parsed['items'][0]['snippet']['publishedAt'] temp['title'] = parsed['items'][0]['snippet']['title'] temp['description'] = parsed['items'][0]['snippet']['description'] temp['playlist_id'] = k['playlist_id'] temp['playlist_name'] = k['playlist_name'] if 'tags' in parsed['items'][0]['snippet']: temp['tags'] = parsed['items'][0]['snippet']['tags'] if 'title' in parsed['items'][0]['snippet']['localized']: temp['local_title'] = parsed['items'][0]['snippet']['localized']['title'] if 'viewCount' in parsed['items'][0]['statistics']: temp['viewCount'] = parsed['items'][0]['statistics']['viewCount'] if 'likeCount' in parsed['items'][0]['statistics']: temp['likeCount'] = parsed['items'][0]['statistics']['likeCount'] if 'dislikeCount' in parsed['items'][0]['statistics']: temp['dislikeCount'] = parsed['items'][0]['statistics']['dislikeCount'] if 'favoriteCount' in parsed['items'][0]['statistics']: temp['favoriteCount'] = parsed['items'][0]['statistics']['favoriteCount'] if 'commentCount' in parsed['items'][0]['statistics']: temp['commentCount'] = parsed['items'][0]['statistics']['commentCount'] res_df = res_df.append(temp, ignore_index=True) return res_df
Als nächstes müssen wir die Klasse initialisieren und das Entladen starten, um das Entladen zu erhalten.
def youtube_reports(): a = report_client(YOUTUBE_API_URL,YOUTUBE_API_KEY,{}) method_rep = getattr(a, "req_playlist") playlist_id = method_rep() method_rep = getattr(a, "req_playlist_stat") video_id = method_rep(playlist_id) report_list = ["req_stat"] for rep in report_list: result_local_file_name = 'df_{0}.csv'.format(rep) method_rep = getattr(a, rep) df = method_rep(video_id) df.to_csv(r'C:\\Users\\User\\Desktop\\youtube.csv', index=False, header=True, sep='\t', quoting = csv.QUOTE_ALL, encoding="utf-8") to_sql_server(df, 'youtube_{0}'.format(rep)) youtube_reports()
Artikel aus dem Zyklus: