Wenn jemand über OSM spricht, erscheint normalerweise einer der Webdienste in Ihrem Kopf oder eine Anwendung wie Maps.me, die auf OSM-
Daten basiert. Tatsächlich handelt es sich bei dem OSM-Projekt in erster Linie um Daten, alles andere ist im Wesentlichen ein Sonderfall ihrer Verwendung. Dienste stellen normalerweise nur einen Teil der Informationen bereit, die gemäß ihren Regeln erstellt wurden.
Zunächst ist OSM eine Sammlung von Punkten, Verknüpfungen zwischen Punkten und Tags für diese. Community-Quellen haben zwei Formate. Ursprünglich wurde
XML als vorrangige Methode zur Verteilung von Daten verwendet, aber die Planet.osm-Datei hat in unkomprimierter Form bereits Terabyte überschritten, und ich sehe keinen Grund, sie für relativ umfangreiche Informationen zu verwenden.
PBF hat einen großen Vorteil: Es ist binär und die gesamte Erddatei hat eine Größe von ca. 50 GB (XML-komprimiert ca. 80 GB).
Es geht darum, OSM-Daten mit dem Osmosis-Tool aus dem „nativen“ Format zu importieren.
Wir benötigen auch PostgreSql mit der Postgis-Erweiterung, in die wir OSM-Daten importieren.
Dadurch ist es möglich, Informationen zu Objekten
mit den hier in ihrer Datenbank
aufgeführten Tags abzurufen
.
DB Vorbereitung.
Erstellen Sie zunächst eine Datenbank in Postgresql, der Name spielt keine Rolle.
psql -c "CREATE DATABASE map;"
Fügen Sie als Nächstes die Erweiterungen hinzu, die für die weitere Arbeit erforderlich sind.
psql -d map -c "CREATE EXTENSION postgis; CREATE EXTENSION hstore; "
Die Postgis-Erweiterung "verbindet" das eigentliche Modul für die Arbeit mit Geodaten mit der Datenbank (ich erinnere Sie daran, dass Sie Postgis selbst installieren müssen). Die hstore-Erweiterung ist für die Verwendung mit Schlüssel- / Wertesätzen ausgelegt, z In OSM-Tags sind viele Informationen enthalten.
Laden Sie
Osmosis herunter. Kurz gesagt, es ist eine Software für eine Vielzahl von Operationen mit OSM-Daten. Es gibt einige gute Dokumentationen zum Arbeiten mit der Befehlszeile. Quellen in Java. Unten werden wir die Kommandozeile verwenden. Ich habe Osmosis auch als Java-Bibliothek verwendet, der Quellcode (verfügbar auf GitHub) schien mir klar genug zu sein und die API war einfach zu bedienen.
Jetzt bereiten wir die Datenbank für den Import vor. Die erforderlichen Tabellen und Funktionen können mithilfe von Skripten erstellt werden, die sich im Ordner osmosis / script befinden. Zusätzlich zum Hauptskript führen wir SQL-Code aus, der ein Feld zum Speichern der Geometrie der Linien erstellt. Dies liegt an der Tatsache, dass OSM-Daten eher als Punktverbindungen als als Satz geometrischer Formen dargestellt werden.
psql -d map -fc:\osmosis\script\pgsnapshot_schema_0.6.sql psql -d map -fc:\osmosis\script\pgsnapshot_schema_0.6_linestring.sql
Importieren Sie OSM-Daten in eine Datenbank
Nun ist fast alles fertig. Sie können den Import sogar ausführen. Es ist notwendig zu entscheiden, was wir als Quelle nehmen. Sie müssen nämlich das Format und die Quelle auswählen. Anfänglich verwendete (und verwendet) die OSM-Community das XML-Format. Die Datenmenge wächst und wächst, so dass das Textformat allmählich verdrängt wird. Die Verwendung von PBF ist etwas bequemer. Die zentrale Quelle
planet.openstreetmap.org enthält Daten für den gesamten Globus. Mit einer Datei können Sie die gesamte Wissensdatenbank des Projekts herunterladen, die bereits 40 Gigabyte in binärer Form überschritten hat. In den Fällen, in denen ich ein Datenelement von dort ausschneiden wollte, ließ ich den Laptop normalerweise die ganze Nacht arbeiten und stellte ihm mehr als 100 GB freien Speicherplatz auf der SSD für temporäre Dateien zur Verfügung.
In unserem Fall können wir zunächst Uploads von Community-Mitgliedern verwenden. Es gibt Ressourcen, mit denen Daten nur für eine bestimmte Region heruntergeladen werden können. Zum Beispiel
download.geofabrik.de . Nehmen Sie die Region Woronesch. Dort ist es in einer Datei enthalten, die Daten für den gesamten zentralen Bundesbezirk enthält. Sie können central-fed-District-latest.osm.pbf herunterladen und dann das gewünschte „Stück“ beim Import in die Datenbank in eine separate Datei schneiden oder nach Koordinaten filtern. Ich würde die erste Option vorschlagen:
c:\osmosis\bin\osmosis.bat --read-pbf file="c:\downloads\central-fed-district-latest.osm.pbf" --bounding-box top=52.059564 left=37.92290 bottom=49.612297 right=43.225858 --write-pbf file="c:\map\voronezh.osm.pbf"
Hier ist alles einfach. Wir lesen die PBF-Datei, filtern die Leseergebnisse nach dem Rechteck der Koordinaten und schreiben die Ergebnisse nach dem Filtern in die Ausgabedatei. Sie können genauer nach Koordinaten filtern, indem Sie kein Rechteck verwenden, sondern ein Polygon, dessen Koordinaten sich in einer separaten Datei befinden.
Die resultierende Datei voronezh.osm.pbf wird dann in die Datenbank importiert. Erstellen Sie zum Herstellen einer Verbindung eine Eigenschaftendatei mit Datenbankzugriffsparametern:
host=localhost database=map user=pguser password=pgpassword dbType=postgresql
Nun, der Import selbst:
c:\osmosis\bin\osmosis.bat --read-pbf c:\map\voronezh.osm.pbf --write-pgsql authFile=c:\map\databaseinfo.properties
Importierte Daten
Jetzt können Sie bereits anfangen zu studieren, was wir in der Datenbank haben. Der erste Gedanke ist, dass es eine Reihe von Zahlen gibt, aber das ist nicht ganz richtig. Wie gesagt, das Hauptelement ist der Punkt. Alles andere wird durch Erstellen von Verknüpfungen (Beziehungen) zwischen Punkten erstellt. Wir werden noch nicht tief gehen, zumal die Hände bereits darauf aus sind, eine eigene „flache“ Tabelle mit einigen Daten zu erstellen. Nun, für Linien und Punkte ist alles fertig, Sie müssen nur eine Tabelle mit den erforderlichen Feldern erstellen und dort die erforderlichen Einträge einfügen. Und welche Felder haben wir? Hier, um dem Wiki zu helfen.
Nehmen Sie zum Beispiel
das Schlüssel / Wert-Paar power = line . Wählen Sie eine Liste der Felder aus, die wir verwenden möchten, z. B. Name, Spannung, Operator, Kabel. Es stellt sich heraus, dass wir die Leitungen auswählen möchten, die notwendigerweise die Eigenschaft power = line haben, zusammen mit den Feldern Name, Spannung, Operator, Kabel. Erstellen Sie eine Tabelle:
CREATE TABLE power_lines ( name varchar, voltage varchar, operator varchar, cables varchar, geom geometry )
Und die Bitte selbst, unsere neue Tabelle auszufüllen:
INSERT INTO power_lines SELECT ways.tags -> 'name' as name, ways.tags -> 'voltage' as voltage, ways.tags -> 'operator' as operator, ways.tags -> 'cables' as cables, ways.linestring as geom FROM ways WHERE ways.tags -> 'power' IN ( 'line' )
Fertig, wir haben eine Tabelle mit Stromleitungen, in der in einigen Leitungen sogar einige Felder ausgefüllt sind! Nun, die Tabelle ist sicherlich interessant, aber es wäre auch schön, die Daten zu visualisieren, um die Geometrie anzuzeigen. Der schnellste Weg, dies zu tun, ist mit QGIS, außer dass dieses leistungsstarke GIS zuerst installiert werden muss. Dort fügen wir bereits eine Postgis-Ebene hinzu, verwenden eine beliebige Karte als Substrat (Sie können das OpenLayers-Plugin verwenden). Konfiguriert, schauen Sie:

Hurra! Sogar der Wahrheit sehr ähnlich, dachte ich und schaute aus dem Fenster auf die Stromleitungen.
Und Polygone?
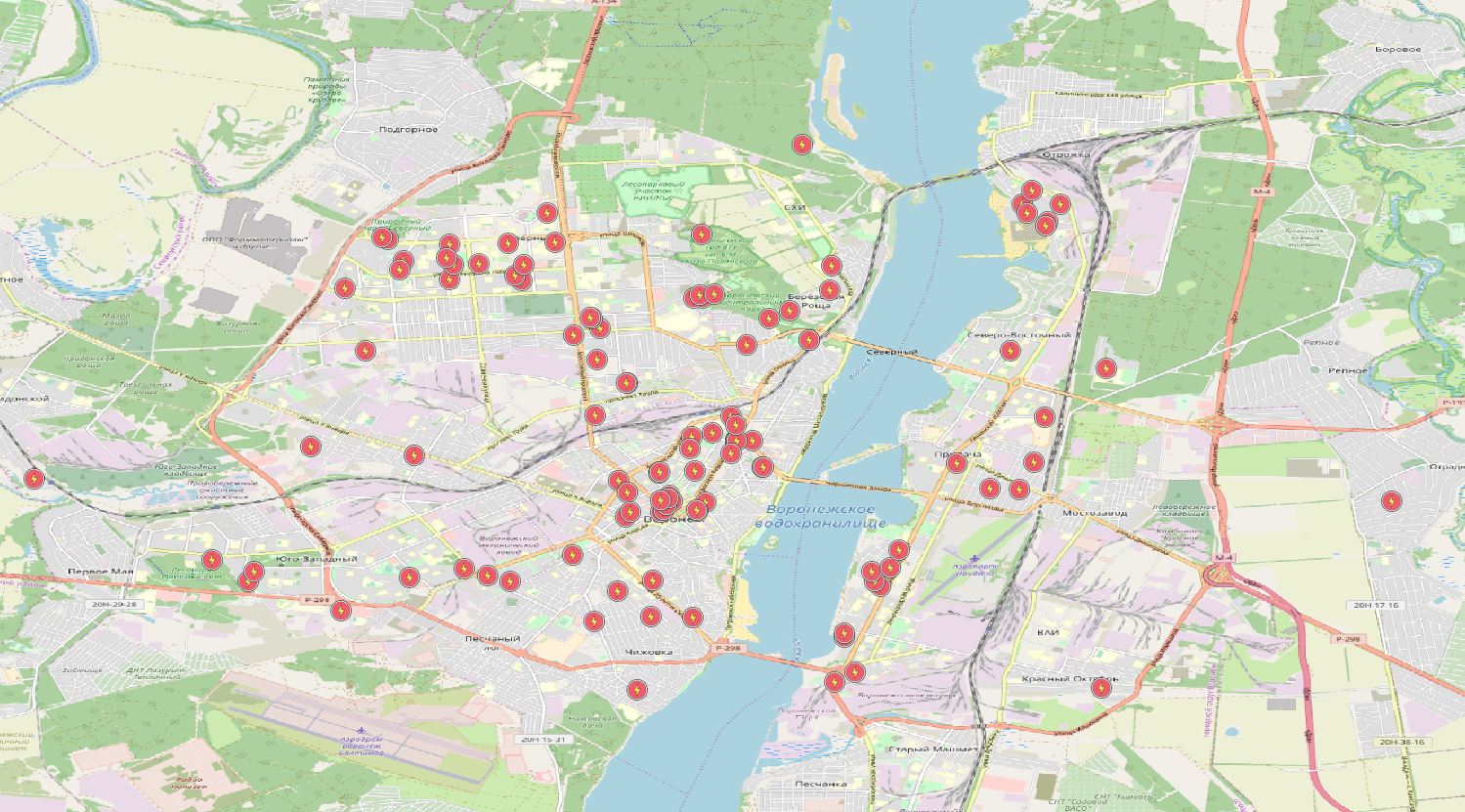
Bei Punkten ist die Situation fast dieselbe, es sei denn, Sie verwenden die Knotentabelle. KDPV enthält nur
Daten zu Unterstationen . Und was ist mit den Polygonen? Polygone bestehen auch aus Linien (geschlossen). Es scheint, dass Sie einfach die Zeilen schließen und das Ergebnis genießen können, aber es funktioniert nicht so. Es gibt viele Fallstricke. Polygone können aus mehreren geschlossenen Linien bestehen.
Zum Beispiel kann sich eine Insel an einem See befinden. Daher bekommen wir ein "Loch" in der Deponie. Ich musste auch etwas über die Bedeutung des Wortes „Exklave“ lernen (zu meiner Schande wusste ich nur über die „Enklave“ Bescheid). Polygone werden ebenfalls gruppiert. Zum Beispiel kann ein Wald aus mehreren „Stücken“ bestehen. Was wir als ein Objekt darstellen sollten. Um das Ganze abzurunden, müssen wir Polygone aufschneiden, wenn sich einige Daten außerhalb der Karte befinden. Ich habe diese und einige andere Probleme im SQL-Skript gelöst, die ich sicher in das Regal gestellt habe, nachdem es funktioniert hat. Das
Osmose-Multypolygon- Projekt wurde auf GitHub gefunden. Widerwillig entschied ich, dass die Verwendung dieser Lösung eine bessere Option ist als meine Skripte, die in ein paar Tagen auf meinem Knie geschrieben wurden. Wir tun, was in README gesagt wird, nämlich wir führen die Liste der Skripte aus und wir haben die Multipolygontabelle, die mit der Anweisung von assemble.sql gefüllt ist. Nachdem wir die Tabelle mit Polygonen ausgefüllt haben, können Sie sich überlegen, was wir bekommen möchten. Lassen Sie uns das
Gebiet der Parks wählen?
Wir schauen uns das Wiki an und schreiben ein Skript:
CREATE TABLE parks ( name varchar, geom geometry ); INSERT INTO parks SELECT m.tags -> 'name' as name, m.geom FROM multipolygons m WHERE m.tags -> 'leisure' IN ( 'park' )
Jetzt visualisieren wir:
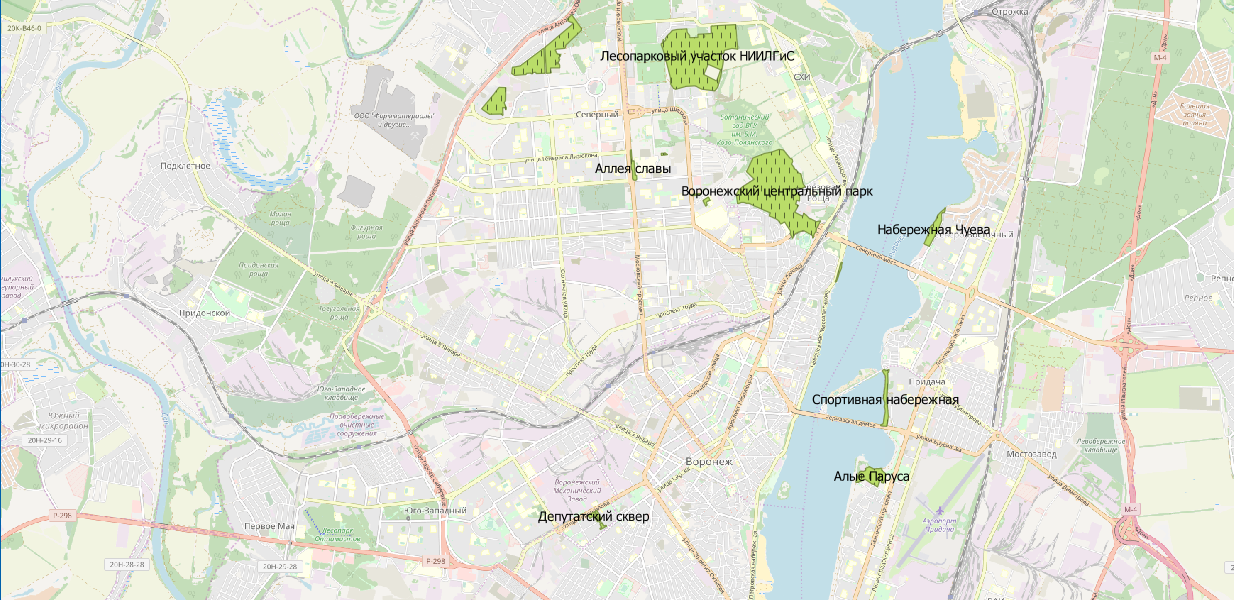
Um ehrlich zu sein, können Sie hier über die Relevanz der Daten streiten. Dies ist jedoch ein Thema für eine andere Diskussion.