
TL; DR
- Um eine hohe Beobachtbarkeit von Containern und Mikrodiensten zu erreichen, reichen Magazine und Primärmetriken nicht aus.
- Für eine schnellere Wiederherstellung und eine erhöhte Fehlertoleranz müssen Anwendungen das High Observability Principle (HOP) anwenden.
- Auf Anwendungsebene erfordert die NRB: ordnungsgemäße Protokollierung, sorgfältige Überwachung, Integritätsprüfungen und Leistungs- / Übergangsverfolgung.
- Verwenden Sie die Prüfungen readinessProbe und livenessProbe Kubernetes als HOP- Element.
Was ist eine Health Check-Vorlage?
Beim Entwerfen einer geschäftskritischen und hochverfügbaren Anwendung ist es sehr wichtig, über Fehlertoleranz nachzudenken. Eine Anwendung gilt als fehlertolerant, wenn sie nach einem Fehler schnell wiederhergestellt wird. Eine typische Cloud-Anwendung verwendet eine Microservice-Architektur, wenn jede Komponente in einem separaten Container abgelegt wird. Und um sicherzustellen, dass die Anwendung auf k8s gut zugänglich ist, müssen Sie beim Entwerfen eines Clusters bestimmten Mustern folgen. Darunter befindet sich die Health Check-Vorlage. Es bestimmt, wie die Anwendung k8s über ihre Leistung meldet. Dies ist nicht nur eine Information darüber, ob der Pod funktioniert, sondern auch darüber, wie er Anfragen akzeptiert und auf diese reagiert. Je mehr Kubernetes über die Leistung eines Pods weiß, desto intelligenter werden Entscheidungen über das Routing des Datenverkehrs und den Lastausgleich getroffen. Somit ist das Prinzip der hohen Beobachtbarkeit der Anwendung zeitnah, um auf Anfragen zu reagieren.
Das Prinzip der hohen Beobachtbarkeit (NRA)
Das Prinzip der hohen Beobachtbarkeit ist eines der Prinzipien bei der Gestaltung von Anwendungen in Containern . In der Microservice-Architektur ist es den Diensten egal, wie ihre Anfrage verarbeitet wird (und das zu Recht), aber es ist wichtig, wie sie Antworten vom Empfang von Diensten erhalten. Um beispielsweise einen Benutzer zu authentifizieren, sendet ein Container eine weitere HTTP-Anfrage und wartet auf eine Antwort in einem bestimmten Format - das ist alles. PythonJS kann auch die Anfrage bearbeiten und Python Flask kann antworten. Die Container füreinander sind wie Blackboxen mit verstecktem Inhalt. Das Prinzip der NRB erfordert jedoch, dass jeder Dienst mehrere API-Endpunkte offenlegt, die zeigen, wie effizient er ist, wie bereit er ist und wie fehlertolerant er ist. Kubernetes fordert diese Metriken auf, die nächsten Schritte für das Routing und den Lastausgleich zu überdenken.
Eine gut gestaltete Cloud-Anwendung protokolliert ihre wichtigsten Ereignisse mithilfe der Standard-E / A-Streams STDERR und STDOUT. Es folgt ein Hilfsdienst, z. B. Filebeat, Logstash oder Fluentd, der die Protokolle an ein zentrales Überwachungssystem (z. B. Prometheus) und das Protokollsammelsystem (ELK Software Suite) liefert. Das folgende Diagramm zeigt, wie die Cloud-Anwendung gemäß der Health Check-Vorlage und dem Prinzip der hohen Beobachtbarkeit funktioniert.
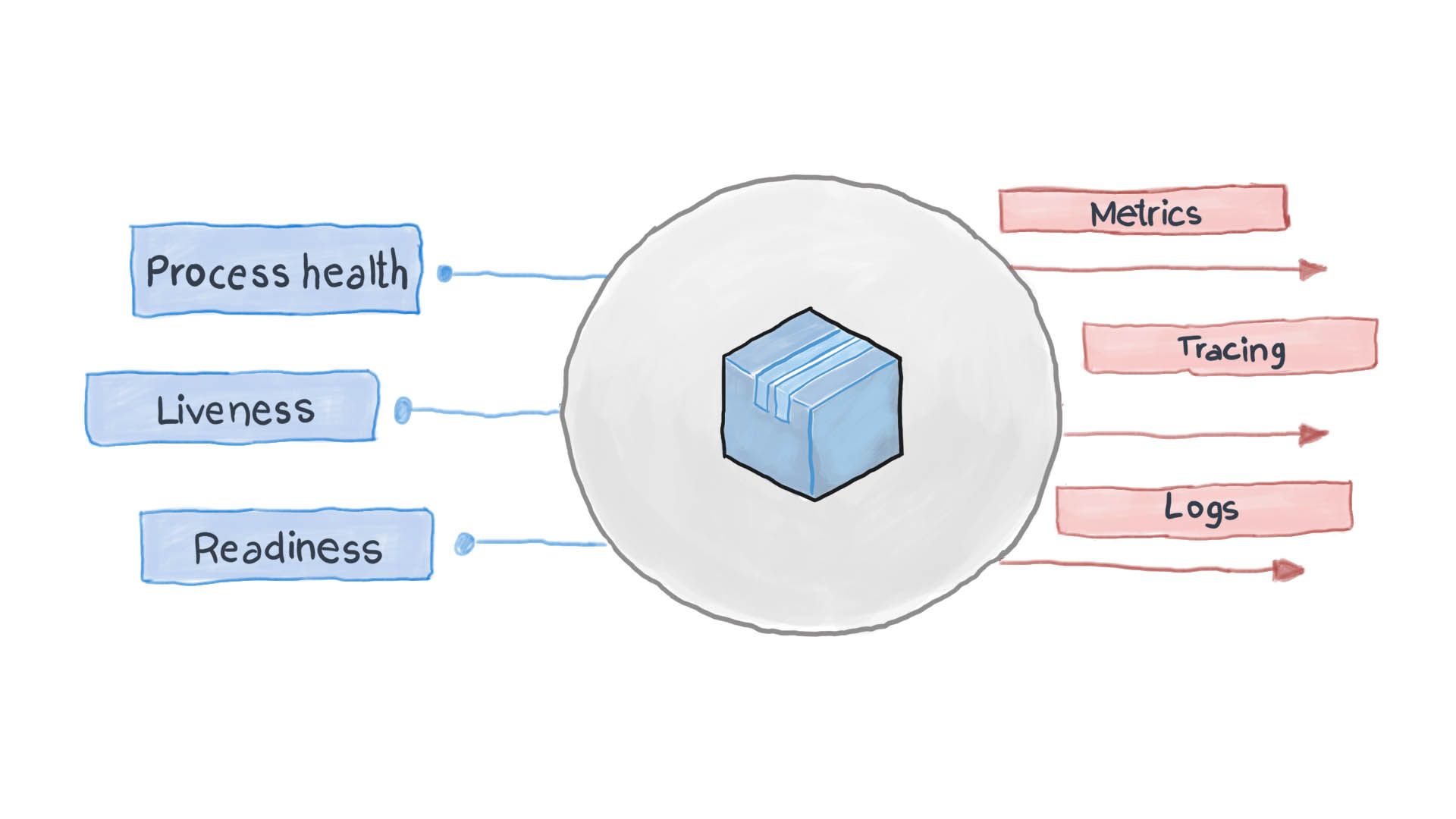
Wie wende ich ein Health Check Pattern in Kubernetes an?
Standardmäßig überwacht k8s den Status von Pods mithilfe eines der Controller ( Bereitstellungen , ReplicaSets , DaemonSets , StatefulSets usw. usw.). Nachdem der Controller festgestellt hat, dass der Pod aus irgendeinem Grund heruntergefallen ist, versucht er, ihn neu zu starten oder auf einen anderen Knoten zu verschieben. Der Pod meldet jedoch möglicherweise, dass er betriebsbereit ist, während er selbst nicht funktioniert. Hier ein Beispiel: Ihre Anwendung verwendet Apache als Webserver. Sie haben die Komponente auf mehreren Pods des Clusters installiert. Da die Bibliothek nicht korrekt konfiguriert wurde, antworten alle Anforderungen an die Anwendung mit Code 500 (interner Serverfehler). Bei der Überprüfung der Lieferung führt die Überprüfung des Status der Pods zu einem erfolgreichen Ergebnis. Kunden denken jedoch anders. Wir beschreiben diese unerwünschte Situation wie folgt:
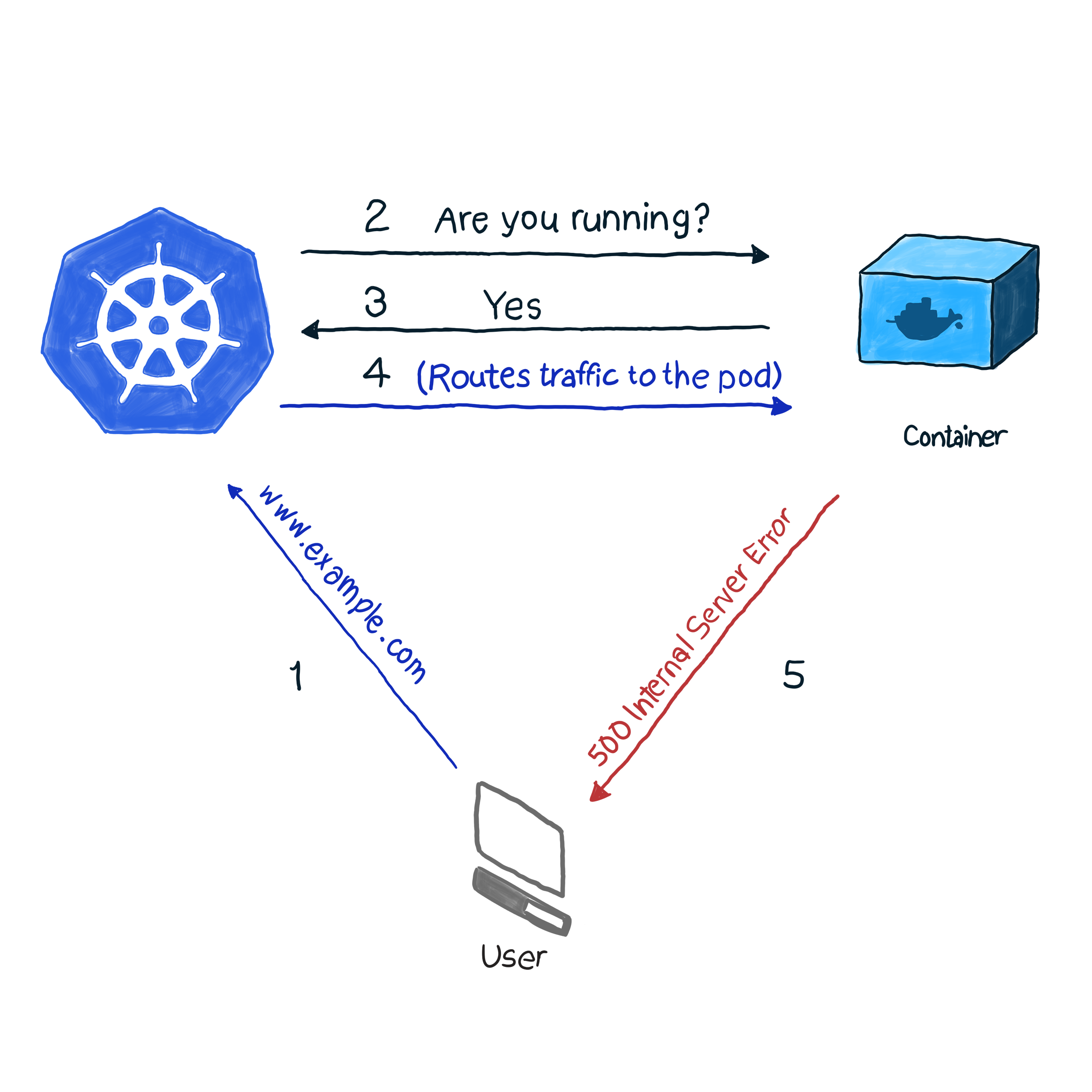
In unserem Beispiel führt k8s eine Integritätsprüfung durch . Bei dieser Art der Prüfung überprüft kubelet ständig den Status des Prozesses im Container. Sobald er versteht, dass der Prozess gestiegen ist, wird er ihn neu starten. Wenn der Fehler durch einfaches Neustarten der Anwendung behoben wird und das Programm so ausgeschaltet wird, dass ein Fehler auftritt, ist eine Überprüfung des Prozesszustands ausreichend, um der NRA und der Health Check-Vorlage zu folgen. Schade, dass nicht alle Fehler durch einen Neustart behoben werden. In diesem Fall bietet k8s zwei tiefere Möglichkeiten zur Fehlerbehebung bei einem Pod : livenessProbe und readinessProbe .
LivenessProbe
Während livenessProbe führt kubelet drei Arten von Überprüfungen durch: Es stellt nicht nur fest, ob der Pod funktioniert, sondern auch, ob er bereit ist, Anfragen zu empfangen und angemessen darauf zu reagieren:
- Setzen Sie eine HTTP-Anfrage auf pod. Die Antwort sollte einen HTTP-Antwortcode im Bereich von 200 bis 399 enthalten. Daher zeigen die Codes 5xx und 4xx an, dass der Pod Probleme hat, selbst wenn der Prozess ausgeführt wird.
- Um Pods mit Nicht-HTTP-Diensten (z. B. Postfix-Mailserver) zu überprüfen, müssen Sie eine TCP-Verbindung herstellen.
- Ausführung eines beliebigen Befehls für den Pod (intern). Die Überprüfung wird als erfolgreich angesehen, wenn der Befehlsexitcode 0 ist.
Ein Beispiel dafür, wie das funktioniert. Die Definition des folgenden Pods enthält eine NodeJS-Anwendung, die für HTTP-Anforderungen einen Fehler von 500 ausgibt. Um sicherzustellen, dass der Container nach Erhalt eines solchen Fehlers neu gestartet wird, verwenden wir den Parameter livenessProbe:
apiVersion: v1 kind: Pod metadata: name: node500 spec: containers: - image: magalix/node500 name: node500 ports: - containerPort: 3000 protocol: TCP livenessProbe: httpGet: path: / port: 3000 initialDelaySeconds: 5
Dies unterscheidet sich nicht von anderen .spec.containers.livenessProbe Definitionen, wir fügen jedoch ein .spec.containers.livenessProbe Objekt hinzu. Der Parameter httpGet akzeptiert den Pfad, an den die HTTP-GET-Anforderung gesendet wird (in unserem Beispiel ist dies / , aber in Kampfszenarien kann es auch so etwas wie /api/v1/status ). Dennoch akzeptiert initialDelaySeconds Parameter initialDelaySeconds , der die Validierungsoperation anweist, auf eine bestimmte Anzahl von Sekunden zu warten. Die Verzögerung ist erforderlich, da der Container zum Starten Zeit benötigt und beim Neustart für eine Weile nicht verfügbar ist.
Verwenden Sie Folgendes, um diese Einstellung auf einen Cluster anzuwenden:
kubectl apply -f pod.yaml
Nach einigen Sekunden können Sie den Inhalt des Pods mit dem folgenden Befehl überprüfen:
kubectl describe pods node500
Suchen Sie am Ende der Ausgabe Folgendes.
Wie Sie sehen können, hat livenessProbe eine HTTP-GET-Anforderung initiiert. Der Container hat einen Fehler 500 generiert (für den programmiert wurde). Kubelet hat ihn neu gestartet.
Wenn Sie daran interessiert sind, wie die NideJS-Anwendung programmiert wurde, finden Sie hier die verwendeten app.js und Dockerfile:
app.js.
var http = require('http'); var server = http.createServer(function(req, res) { res.writeHead(500, { "Content-type": "text/plain" }); res.end("We have run into an error\n"); }); server.listen(3000, function() { console.log('Server is running at 3000') })
Dockerfile
FROM node COPY app.js / EXPOSE 3000 ENTRYPOINT [ "node","/app.js" ]
Beachten Sie dies unbedingt: livenessProbe startet den Container nur im Fehlerfall neu. Wenn der Neustart den Fehler nicht behebt, der den Betrieb des Containers beeinträchtigt, kann kubelet keine Maßnahmen ergreifen, um die Fehlfunktion zu beseitigen.
ReadinessProbe
readinessProbe funktioniert ähnlich wie livenessProbes (GET-Anforderungen, TCP-Kommunikation und Befehlsausführung), mit Ausnahme von Aktionen zur Fehlerbehebung. Der Container, in dem der Fehler aufgezeichnet wird, wird nicht neu gestartet, sondern vom eingehenden Datenverkehr isoliert. Stellen Sie sich vor, einer der Container führt viele Berechnungen durch oder ist stark ausgelastet, was die Antwortzeit für Anforderungen verlängert. Bei livenessProbe wird eine Antwortverfügbarkeitsprüfung ausgelöst (über den Parameter timeoutSeconds check), wonach kubelet den Container neu startet. Beim Start beginnt der Container mit der Ausführung ressourcenintensiver Aufgaben und wird erneut gestartet. Dies kann für Anwendungen von entscheidender Bedeutung sein, bei denen die Reaktionsgeschwindigkeit im Vordergrund steht. Zum Beispiel wartet ein Auto direkt auf dem Weg auf eine Antwort vom Server, die Antwort wird verzögert - und das Auto stürzt ab.
Schreiben wir eine ReadinessProbe-Definition, die die Antwortzeit für eine GET-Anforderung auf nicht mehr als zwei Sekunden festlegt. Die Anwendung antwortet in 5 Sekunden auf eine GET-Anforderung. Die Datei pod.yaml sollte folgendermaßen aussehen:
apiVersion: v1 kind: Pod metadata: name: nodedelayed spec: containers: - image: afakharany/node_delayed name: nodedelayed ports: - containerPort: 3000 protocol: TCP readinessProbe: httpGet: path: / port: 3000 timeoutSeconds: 2
Erweitern Sie den Pod mit kubectl:
kubectl apply -f pod.yaml
Warten Sie ein paar Sekunden und sehen Sie sich dann an, wie ReadinessProbe funktioniert hat:
kubectl describe pods nodedelayed
Am Ende der Schlussfolgerung können Sie sehen, dass einige der Ereignisse ähnlich sind.
Wie Sie sehen können, hat kubectl den Pod nicht neu gestartet, als die Scan-Zeit 2 Sekunden überschritten hat. Stattdessen stornierte er die Anfrage. Eingehende Verbindungen werden zu anderen funktionierenden Pods umgeleitet.
Hinweis: Nachdem die zusätzliche Last aus dem Pod entfernt wurde, sendet kubectl erneut Anforderungen an den Pod: Die Antworten auf die GET-Anforderung werden nicht länger verzögert.
Zum Vergleich: Folgendes ist die geänderte Datei app.js:
var http = require('http'); var server = http.createServer(function(req, res) { const sleep = (milliseconds) => { return new Promise(resolve => setTimeout(resolve, milliseconds)) } sleep(5000).then(() => { res.writeHead(200, { "Content-type": "text/plain" }); res.end("Hello\n"); }) }); server.listen(3000, function() { console.log('Server is running at 3000') })
TL; DR
Vor dem Aufkommen von Cloud-basierten Anwendungen waren Protokolle das Hauptmittel zur Überwachung und Überprüfung des Status von Anwendungen. Es gab jedoch keine Möglichkeit, Schritte zur Fehlerbehebung durchzuführen. Protokolle sind heute nützlich. Sie müssen gesammelt und an das Protokollassemblierungssystem gesendet werden, um Notfallsituationen zu analysieren und Entscheidungen zu treffen. [ all dies könnte zum Beispiel ohne Cloud-Anwendungen mit monit gemacht werden, aber mit k8s ist es viel einfacher geworden :) - Ed. ]]
Heutzutage müssen Korrekturen fast in Echtzeit vorgenommen werden, sodass Anwendungen keine Black Box mehr sein sollten. Nein, sie sollten Endpunkte anzeigen, mit denen Überwachungssysteme wertvolle Daten zum Status von Prozessen anfordern und sammeln können, damit sie bei Bedarf sofort reagieren können. Dies wird als Health Check Design Template bezeichnet, die dem High Observability Principle (NRA) folgt.
Kubernetes bietet standardmäßig zwei Arten von Gesundheitsprüfungen an: ReadinessProbe und LivenessProbe. Beide verwenden dieselben Überprüfungsarten (HTTP-GET-Anforderungen, TCP-Kommunikation und Befehlsausführung). Sie unterscheiden sich darin, welche Entscheidungen als Reaktion auf Probleme in Pods getroffen werden. livenessProbe startet den Container neu in der Hoffnung, dass der Fehler nicht erneut auftritt, und readinessProbe isoliert den Pod vom eingehenden Datenverkehr, bis die Ursache des Problems behoben ist.
Das ordnungsgemäße Anwendungsdesign sollte beide Validierungsarten umfassen und genügend Daten erfassen, insbesondere wenn eine Ausnahme erstellt wird. Es sollte auch die erforderlichen API-Endpunkte anzeigen, die wichtige Gesundheitsstatusmetriken an das Überwachungssystem (auch Prometheus genannt) übertragen.