Der IaC-Ansatz (Infrastructure as Code) besteht nicht nur aus dem im Repository gespeicherten Code, sondern auch aus den Personen und Prozessen, die diesen Code umgeben. Ist es möglich, Ansätze von der Softwareentwicklung bis zur Verwaltung und Beschreibung der Infrastruktur wiederzuverwenden? Es ist nicht überflüssig, diese Idee beim Lesen des Artikels zu berücksichtigen.
Russische Version
Dies ist eine Abschrift meiner Leistung bei DevopsConf 2019-05-28 .
Infrastruktur als Bash-Geschichte

Angenommen, Sie kommen zu einem neuen Projekt und sie sagen Ihnen: "Wir haben Infrastruktur als Code ." In Wirklichkeit stellt sich heraus, Infrastruktur als Bash-Verlauf oder zum Beispiel Dokumentation als Bash-Verlauf . Dies ist eine sehr reale Situation, zum Beispiel wurde ein ähnlicher Fall von Denis Lysenko in seiner Rede beschrieben. Wie man die gesamte Infrastruktur ersetzt und friedlich zu schlafen beginnt , erzählte er, wie sie aus der Bash-Geschichte eine schlanke Infrastruktur für das Projekt bekommen haben.
Wenn Sie möchten, können Sie sagen, dass Infrastruktur als Bash-Verlauf wie Code ist:
- Reproduzierbarkeit : Sie können den Bash-Verlauf aufnehmen und Befehle von dort ausführen. Vielleicht erhalten Sie übrigens eine funktionierende Konfiguration am Ausgang.
- versionierung : Sie wissen, wer hereingekommen ist und was wiederum getan hat, nicht die Tatsache, dass dies zu einer funktionierenden Konfiguration der Ausgabe führt.
- Geschichte : Geschichte, wer was getan hat. Nur Sie können es nicht verwenden, wenn Sie den Server verlieren.
Was tun?
Infrastruktur als Code
Selbst ein so seltsamer Fall wie Infrastruktur als Bash-Verlauf kann von Infrastruktur als Code in die Ohren gezogen werden. Wenn wir jedoch etwas Komplizierteres als den guten alten LAMP-Server tun möchten, werden wir zu dem Schluss kommen, dass dieser Code irgendwie modifiziert, modifiziert, modifiziert werden muss . Darüber hinaus möchten wir Parallelen zwischen Infrastruktur als Code und Softwareentwicklung betrachten.
TROCKEN
Bei dem Projekt zur Entwicklung von Speichersystemen gab es eine Unteraufgabe zur regelmäßigen Konfiguration von SDS : Wir veröffentlichen eine neue Version - sie muss für weitere Tests eingeführt werden. Die Aufgabe ist sehr einfach:
- Komm her von ssh und führe den Befehl aus.
- Kopieren Sie die Datei dort.
- Hier ist die Optimierung der Konfiguration.
- Starten Sie den Dienst dort
- ...
- GEWINN!
Bash ist mehr als genug für die beschriebene Logik, insbesondere in den frühen Phasen eines Projekts, wenn es gerade erst beginnt. Es ist nicht schlecht, dass Sie Bash verwenden , aber im Laufe der Zeit werden Sie aufgefordert, etwas Ähnliches, aber etwas anderes bereitzustellen. Das erste, was mir in den Sinn kommt: Kopieren und Einfügen. Und jetzt haben wir zwei sehr ähnliche Skripte, die fast dasselbe tun. Im Laufe der Zeit hat die Anzahl der Skripte zugenommen, und wir sind mit der Tatsache konfrontiert, dass es eine Art Geschäftslogik für die Bereitstellung der Installation gibt, die zwischen verschiedenen Skripten synchronisiert werden muss. Dies ist ziemlich schwierig.
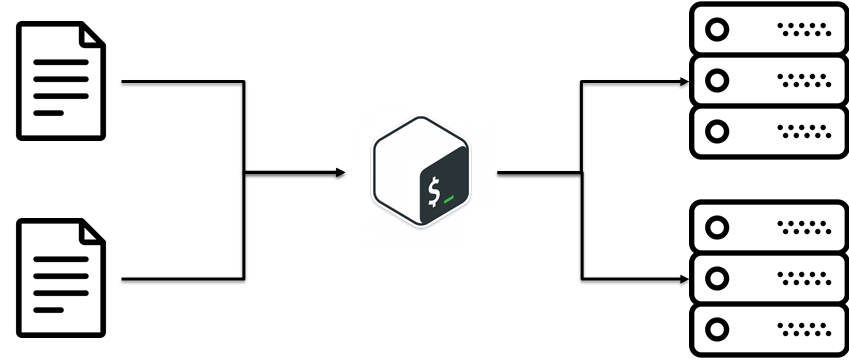
Es stellt sich heraus, dass es eine solche Praxis gibt. TROCKEN (Wiederholen Sie sich nicht). Die Idee ist, vorhandenen Code wiederzuverwenden. Es klingt einfach, ist aber nicht sofort dazu gekommen. In unserem Fall war es eine alltägliche Idee: Konfigurationen von Skripten zu trennen. Das heißt, Geschäftslogik, wie die Installation separat bereitgestellt wird, wird separat konfiguriert.
FEST für CFM

Im Laufe der Zeit wuchs das Projekt und eine natürliche Erweiterung war die Entstehung von Ansible. Der Hauptgrund für sein Auftreten ist das Vorhandensein von Fachwissen im Team und diese Bash ist nicht für komplexe Logik gedacht. Ansible begann auch komplexe Logik zu enthalten. Damit sich komplexe Logik nicht in Chaos verwandelt, gibt es Grundsätze für die Organisation von SOLID- Code in der Softwareentwicklung. Beispielsweise stellte Grigory Petrov in seinem Bericht „Warum braucht IT eine persönliche Marke ? “ Die Frage, dass eine Person so konzipiert ist, dass es einfacher ist, mit einigen zu arbeiten soziale Einheiten, in der Softwareentwicklung sind dies Objekte. Wenn Sie diese beiden Ideen kombinieren und weiterentwickeln, werden Sie feststellen, dass Sie SOLID auch in der Beschreibung der Infrastruktur verwenden können, damit diese Logik in Zukunft leichter gewartet und geändert werden kann.
Das Prinzip der Einzelverantwortung

Jede Klasse führt nur eine Aufgabe aus.
Keine Notwendigkeit, Code zu mischen und monolithische göttliche Pasta-Monster herzustellen. Die Infrastruktur sollte aus einfachen Bausteinen bestehen. Es stellt sich heraus, dass wenn Sie Ansible-Playbooks in kleine Teile aufteilen und Ansible-Rollen lesen, diese einfacher zu warten sind.
Die offenen geschlossenen Prinzipien
Das Prinzip der Offenheit / Nähe.
- Zur Erweiterung öffnen: bedeutet, dass das Verhalten einer Entität durch Erstellen neuer Entitätstypen erweitert werden kann.
- Wegen Änderung geschlossen: Aufgrund der Erweiterung des Verhaltens einer Entität sollten keine Änderungen am Code vorgenommen werden, der diese Entitäten verwendet.
Ursprünglich haben wir die Testinfrastruktur auf virtuellen Maschinen bereitgestellt. Aufgrund der Tatsache, dass die Geschäftsbereitstellungslogik von der Implementierung getrennt war, haben wir Bare-Metall problemlos um ein Rolling erweitert.
Das Liskov-Substitutionsprinzip

Das Substitutionsprinzip von Barbara Liskov. Objekte im Programm müssen durch Instanzen ihrer Untertypen ersetzt werden können, ohne die Richtigkeit des Programms zu ändern
Wenn Sie allgemeiner schauen, ist es keine Funktion eines bestimmten Projekts, dass Sie SOLID anwenden können . Es geht im Allgemeinen um CFM. Beispielsweise müssen Sie in einem anderen Projekt eine Java-Box-Anwendung auf verschiedenen Java-, Anwendungsservern, Datenbanken, Betriebssystemen usw. bereitstellen. In diesem Beispiel werde ich weitere SOLID- Prinzipien betrachten.
In unserem Fall besteht als Teil des Infrastrukturteams eine Vereinbarung, dass wir eine binäre ausführbare Java-Datei haben, wenn wir die Rolle von Imbjava oder Orakeljava installiert haben. Dies ist notwendig, weil Höhere Rollen hängen von diesem Verhalten ab und erwarten, dass Java vorhanden ist. Gleichzeitig können wir so eine Implementierung / Version von Java durch eine andere ersetzen, ohne die Anwendungsbereitstellungslogik zu ändern.
Das Problem liegt hier in der Tatsache, dass es in Ansible unmöglich ist, solche zu implementieren, so dass einige Vereinbarungen innerhalb des Teams erscheinen.
Das Prinzip der Schnittstellentrennung
Das Prinzip der Schnittstellentrennung „Viele speziell für Kunden entwickelte Schnittstellen sind besser als eine einzige Allzweckschnittstelle.
Anfangs haben wir versucht, alle Variationen bei der Bereitstellung der Anwendung in einem Ansible-Playbook zusammenzufassen, aber es war schwierig zu unterstützen, und der Ansatz, wenn wir eine Schnittstelle haben (der Client erwartet Port 443), wird angegeben. Für eine bestimmte Implementierung können Sie die Infrastruktur aus separaten Bausteinen erstellen.
Das Prinzip der Abhängigkeitsinversion

Das Prinzip der Abhängigkeitsinversion. Module der oberen Ebene sollten nicht von Modulen der unteren Ebene abhängen. Beide Modultypen sollten von Abstraktionen abhängen. Abstraktionen sollten nicht von den Details abhängen. Details sollten von Abstraktionen abhängen.
Hier basiert das Beispiel auf Antipattern.
- Einer der Kunden hatte eine private Cloud.
- Innerhalb der Cloud haben wir virtuelle Maschinen bestellt.
- Angesichts der Funktionen der Cloud war die Bereitstellung der Anwendung jedoch an den Hypervisor gebunden, auf dem sich die VM befand.
Das heißt, Übergeordnete Anwendungsbereitstellungslogik, Abhängigkeiten flossen auf die unteren Ebenen des Hypervisors, und dies bedeutete Probleme bei der Wiederverwendung dieser Logik. Nicht so.
Interaktion

Bei der Infrastruktur als Code geht es nicht nur um Code, sondern auch um die Beziehung zwischen Code und einer Person, um Interaktionen zwischen Entwicklern der Infrastruktur.
Busfaktor
Angenommen, Sie haben Vasya im Projekt. Vasya weiß alles über Ihre Infrastruktur. Was passiert, wenn Vasya plötzlich verschwindet? Dies ist eine sehr reale Situation, da sie von einem Bus angefahren werden kann. Manchmal passiert das. Wenn dies geschieht und das Wissen über den Code, seine Struktur, seine Funktionsweise, Erscheinungsbilder und Kennwörter nicht im Team verteilt wird, kann es zu einer Reihe unangenehmer Situationen kommen. Verschiedene Ansätze können verwendet werden, um diese Risiken zu minimieren und Wissen innerhalb des Teams zu verteilen.
Paar devopsing

Es ist nicht wie ein Witz, dass Administratoren Bier tranken, Passwörter änderten, sondern ein Analogon der Paarprogrammierung. Das heißt, Zwei Ingenieure setzen sich an einen Computer und eine Tastatur und beginnen gemeinsam mit der Konfiguration Ihrer Infrastruktur: Konfigurieren Sie den Server, schreiben Sie die Ansible-Rolle usw. Es hört sich gut an, hat aber bei uns nicht funktioniert. Aber die Sonderfälle dieser Praxis haben funktioniert. Ein neuer Mitarbeiter ist gekommen, sein Mentor nimmt eine echte Aufgabe mit sich, arbeitet, überträgt Wissen.
Ein weiterer Sonderfall ist ein Incident Call. Während des Problems versammelt sich eine Gruppe von diensthabenden und beteiligten Personen, ein Führer wird ernannt, der seinen Bildschirm teilt und den Gedankengang äußert. Andere Teilnehmer folgen den Gedanken des Leiters, spionieren Tricks von der Konsole aus aus, überprüfen, ob sie keine Zeile im Protokoll verpasst haben, und lernen neue Dinge über das System. Dieser Ansatz hat eher funktioniert als nicht.
Codeüberprüfung
Subjektiv und effizienter wurde die Verbreitung von Wissen über die Infrastruktur und deren Organisation mithilfe der Codeüberprüfung durchgeführt:
- Die Infrastruktur wird durch Code im Repository beschrieben.
- Änderungen treten in einem separaten Zweig auf.
- Mit einer Zusammenführungsanforderung können Sie das Delta der Änderungen in der Infrastruktur sehen.
Das Highlight hier war, dass die Gutachter der Reihe nach gemäß dem Zeitplan ausgewählt wurden, d. H. Mit einiger Wahrscheinlichkeit werden Sie in eine neue Infrastruktur einsteigen.
Codestil

Im Laufe der Zeit traten während der Überprüfung Streitigkeiten auf, als Die Rezensenten hatten ihren eigenen Stil und ihre Rotationsfähigkeit. Die Rezensenten stapelten sie mit verschiedenen Stilen: 2 Leerzeichen oder 4, camelCase oder snake_case. Die Implementierung funktionierte nicht sofort.
- Die erste Idee war, die Verwendung von Linter zu empfehlen, weil alle die gleichen Ingenieure, alle klug. Aber verschiedene Editoren, Betriebssystem, nicht bequem
- Dies entwickelte sich zu einem Bot, der für jedes Commit Commit auf das Problem in Slack schrieb und die Ausgabe von Linter anwendete. In den meisten Fällen wurden jedoch wichtigere Angelegenheiten gefunden, und der Code blieb nicht festgelegt.
Grüner Baumeister
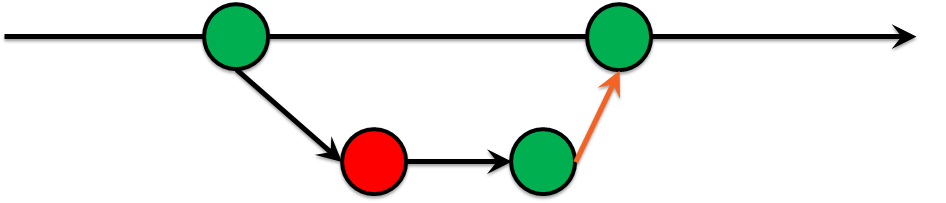
Die Zeit vergeht und wir kamen zu dem Schluss, dass Sie keine Commits zulassen sollten, die bestimmte Tests nicht an den Master weitergeben. Voila! Wir haben den Green Build Master erfunden, der seit langem in der Softwareentwicklung praktiziert wird:
- Die Entwicklung erfolgt in einem separaten Zweig.
- Tests werden für diesen Thread ausgeführt.
- Wenn die Tests fehlschlagen, gelangt der Code nicht in den Assistenten.
Diese Entscheidung zu treffen war sehr schmerzhaft, weil verursachte viele Kontroversen, aber es hat sich gelohnt, weil Anträge auf Fusionen kamen ohne Meinungsverschiedenheiten in die Überprüfung, und im Laufe der Zeit nahm die Anzahl der Problembereiche ab.
IaC-Tests

Neben der Stilprüfung können Sie auch andere Dinge verwenden, um beispielsweise zu überprüfen, ob Ihre Infrastruktur wirklich bereitgestellt werden kann. Oder prüfen Sie, ob Änderungen in der Infrastruktur nicht zu Geldverlusten führen. Warum könnte dies erforderlich sein? Die Frage ist komplex und philosophisch. Es ist besser, sie mit der Geschichte zu beantworten, dass es auf Powershell einen Auto-Scaler gab, der die Randbedingungen nicht überprüfte => Es wurden mehr VMs erstellt als erforderlich => Der Kunde gab mehr Geld aus als geplant. Es ist nicht angenehm genug, aber es wäre ziemlich realistisch, diesen Fehler in früheren Stadien zu erkennen.
Man könnte sich fragen, warum komplexe Infrastrukturen noch schwieriger werden. Bei Tests für die Infrastruktur sowie für den Code geht es nicht um Vereinfachung, sondern darum zu wissen, wie Ihre Infrastruktur funktionieren sollte.
IaC-Testpyramide

IaC-Test: Statische Analyse
Wenn Sie sofort die gesamte Infrastruktur bereitstellen und überprüfen, ob sie funktioniert, kann sich herausstellen, dass dies viel Zeit in Anspruch nimmt und viel Zeit erfordert. Daher sollte die Basis etwas sein, das schnell funktioniert, es ist viel und es deckt viele primitive Orte ab.
Bash ist schwierig
Hier ist ein triviales Beispiel. Wählen Sie alle Dateien im aktuellen Verzeichnis aus und kopieren Sie sie an einen anderen Speicherort. Das erste, was mir in den Sinn kommt:
for i in * ; do cp $i /some/path/$i.bak done
Was aber, wenn der Dateiname ein Leerzeichen enthält? Na gut, wir sind schlau, wir können Anführungszeichen verwenden:
for i in * ; do cp "$i" "/some/path/$i.bak" ; done
Gut gemacht? Nein! Was ist, wenn sich nichts im Verzeichnis befindet, d. H. Globbing wird nicht funktionieren.
find . -type f -exec mv -v {} dst/{}.bak \;
Jetzt gut gemacht? nicht ... Ich habe vergessen, dass der Dateiname \n .
touch x mv x "$(printf "foo\nbar")" find . -type f -print0 | xargs -0 mv -t /path/to/target-dir
Das Problem aus dem vorherigen Schritt könnte auftreten, wenn wir die Anführungszeichen vergessen haben. Dafür gibt es in der Natur viele Shellcheck-Tools , viele davon, und höchstwahrscheinlich finden Sie unter Ihrer IDE einen Liner für Ihren Stack.
IaC-Tests: Unit-Tests
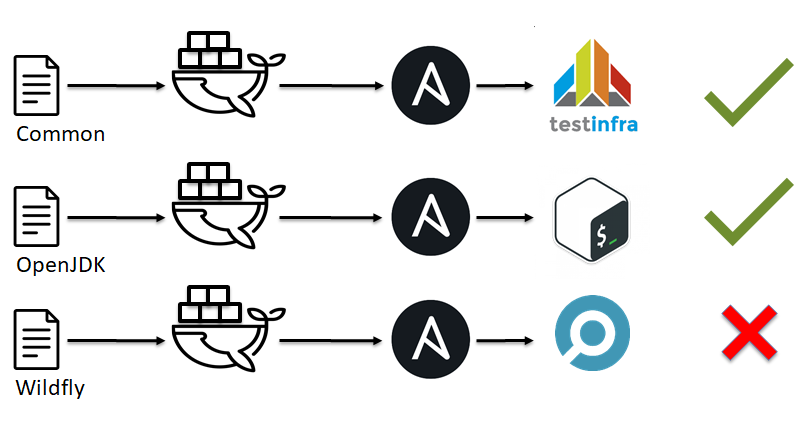
Wie wir im vorherigen Beispiel gesehen haben, ist Linter nicht allmächtig und kann nicht auf alle Problembereiche verweisen. In Analogie zu Tests in der Softwareentwicklung können wir uns außerdem an Unit-Tests erinnern. Dann kommen mir sofort Shunit , Junit , Rspec , Pytest in den Sinn. Aber was tun mit Ansible, Chef, Saltstack und anderen wie ihnen?
Ganz am Anfang haben wir über SOLID und die Tatsache gesprochen, dass unsere Infrastruktur aus kleinen Bausteinen bestehen sollte. Ihre Zeit ist gekommen.
- Die Infrastruktur wird in kleine Bausteine zerlegt, z. B. Ansible-Rollen.
- Es entwickelt sich eine Art Umgebung, sei es Docker oder VM.
- Wir wenden unsere Ansible-Rolle auf diese Testumgebung an.
- Wir überprüfen, ob alles wie erwartet funktioniert hat (führen Sie die Tests durch).
- Wir entscheiden ok oder nicht ok.
Die Frage ist, was sind Tests für CFM? Sie können das Skript kitschig ausführen oder dafür vorgefertigte Lösungen verwenden:
Beispiel für testinfra: Wir überprüfen, ob die Benutzer test1 , test2 vorhanden sind und sich in der Gruppe sshusers :
def test_default_users(host): users = ['test1', 'test2' ] for login in users: assert host.user(login).exists assert 'sshusers' in host.user(login).groups
Was soll ich wählen? Die Frage ist komplex und mehrdeutig. Hier ist ein Beispiel für eine Änderung der Projekte auf Github für 2018-2019:

IaC-Test-Frameworks
Wie kann man alles zusammenfügen und rennen? Sie können alles selbst übernehmen, wenn Sie über eine ausreichende Anzahl von Ingenieuren verfügen. Und Sie können vorgefertigte Lösungen wählen, obwohl es nicht sehr viele davon gibt:
Ein Beispiel für eine Änderung der Projekte auf Github für 2018-2019:

Molekül vs. Testküche

Anfangs haben wir versucht, testkitchen zu verwenden :
- Erstellen Sie parallel VMs.
- Wenden Sie Ansible Roles an.
- Fahren Sie die Inspektion weg.
Bei 25-35 Rollen funktionierte dies 40-70 Minuten, was eine lange Zeit war.
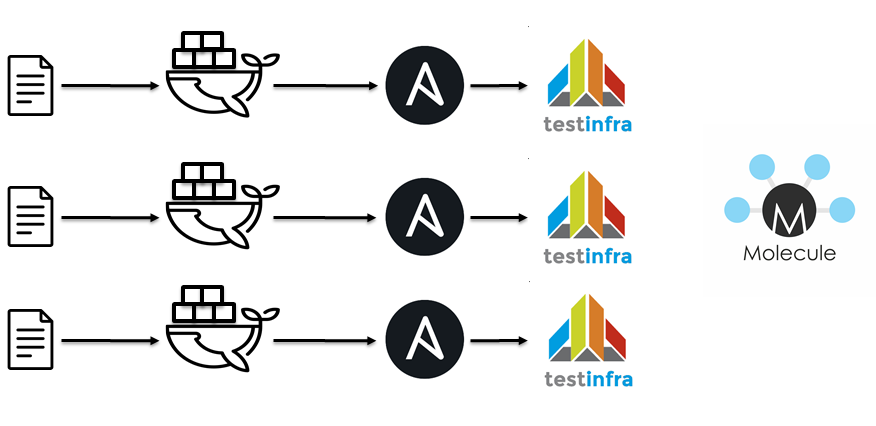
Der nächste Schritt war der Wechsel zu Jenkins / Docker / Ansible / Molekül. Idiologisch ist alles gleich
- Fusselspielbücher.
- Rollen verschütten.
- Container ausführen
- Wenden Sie Ansible Roles an.
- Testinfra wegfahren.
- Überprüfen Sie die Idempotenz.
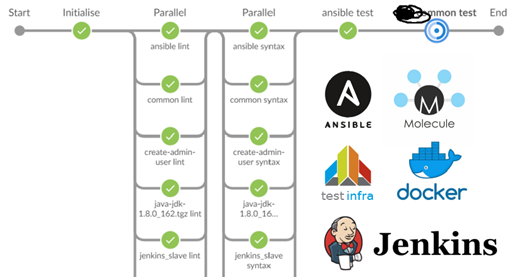
Ein Lineal für 40 Rollen und Tests für ein Dutzend dauerte ungefähr 15 Minuten.

Die Auswahl hängt von vielen Faktoren ab, wie dem verwendeten Stack, dem Fachwissen im Team usw. Hier entscheidet jeder, wie das Thema Unit-Test geschlossen werden soll
IaC-Tests: Integrationstests
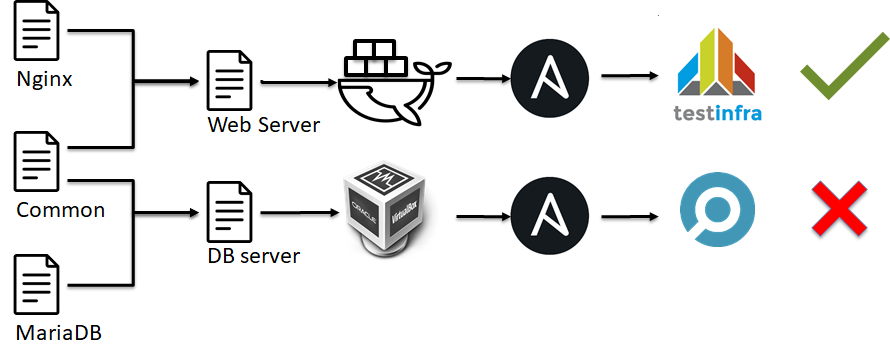
In der nächsten Phase der Pyramide der Infrastrukturtests werden Integrationstests angezeigt. Sie ähneln Unit-Tests:
- Die Infrastruktur wird in kleine Bausteine wie Ansible-Rollen zerlegt.
- Es entwickelt sich eine Art Umgebung, sei es Docker oder VM.
- Auf diese Testumgebung werden viele Ansible-Rollen angewendet.
- Wir überprüfen, ob alles wie erwartet funktioniert hat (führen Sie die Tests durch).
- Wir entscheiden ok oder nicht ok.
Grob gesagt überprüfen wir nicht die Funktionsfähigkeit eines einzelnen Elements des Systems wie bei Komponententests, sondern die Konfiguration des Servers als Ganzes.
IaC-Tests: End-to-End-Tests
An der Spitze der Pyramide treffen wir auf End-to-End-Tests. Das heißt, Wir überprüfen nicht den Betrieb eines separaten Servers, eines separaten Skripts oder eines separaten Bausteins unserer Infrastruktur. Wir überprüfen, ob viele Server miteinander kombiniert sind. Unsere Infrastruktur funktioniert wie erwartet. Leider habe ich keine fertigen Box-Lösungen gesehen, wahrscheinlich weil Die Infrastruktur ist oft einzigartig und schwer zu erstellen und ein Framework zum Testen zu erstellen. Als Ergebnis erstellt jeder seine eigene Lösung. Es gibt Nachfrage, aber keine Antwort. Deshalb werde ich Ihnen sagen, was da ist, um andere dazu zu bewegen, Gedanken zu machen oder meine Nase zu stechen, dass alles lange vor uns erfunden wurde.
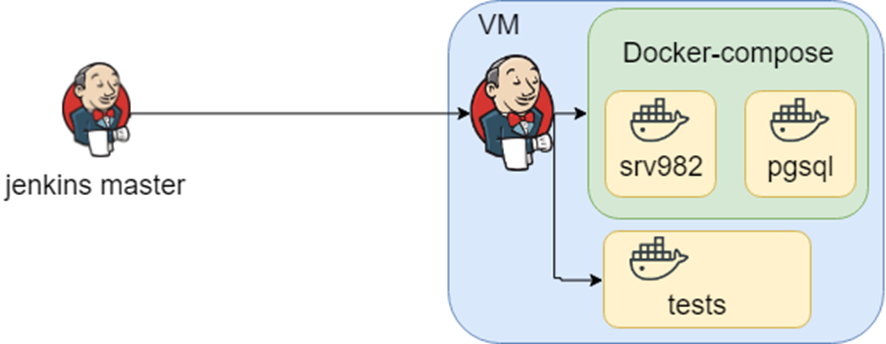
Ein Projekt mit einer reichen Geschichte. Wird in großen Organisationen verwendet und wahrscheinlich hat sich jeder von Ihnen indirekt überschnitten. Die Anwendung unterstützt viele Datenbanken, Integrationen usw. usw. Zu wissen, wie die Infrastruktur so aussehen kann, besteht aus vielen Docker-Compose-Dateien, und zu wissen, welche Tests in welcher Umgebung ausgeführt werden sollen, ist Jenkins.
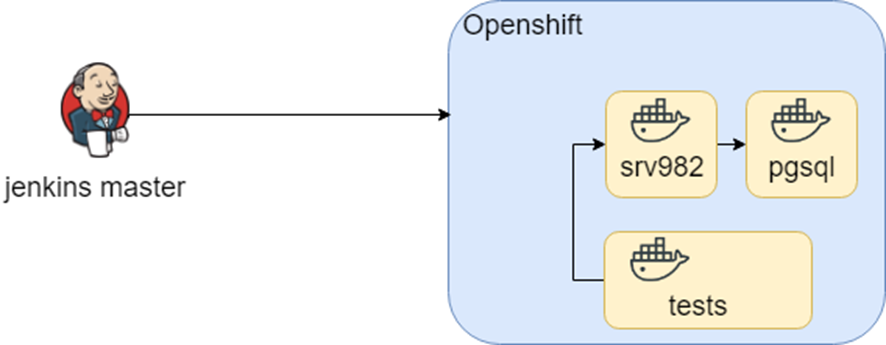
Dieses Schema hat lange funktioniert, bis wir im Rahmen der Studie versucht haben, es auf Openshift zu übertragen. Die Container blieben gleich, aber die Startumgebung hat sich geändert (hallo wieder TROCKEN).
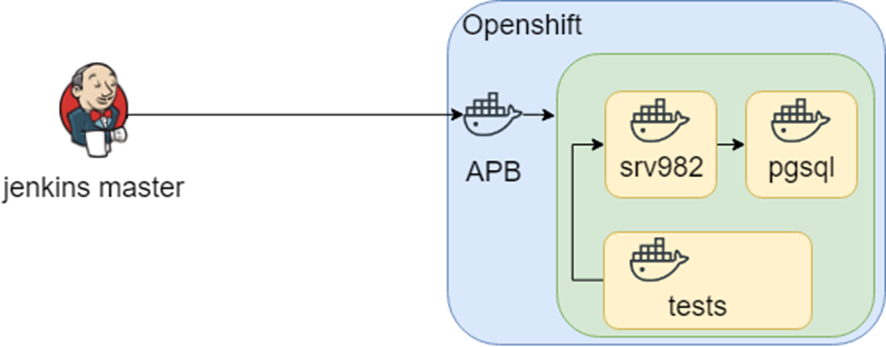
Die Idee der Forschung ging weiter und in OpenShift gab es eine solche APB-Sache (Ansible Playbook Bundle), mit der Sie Wissen in einen Container packen können, wie die Infrastruktur bereitgestellt wird. Das heißt, Es gibt einen reproduzierbaren, überprüfbaren Wissenspunkt zur Bereitstellung der Infrastruktur.

Das klang alles gut, bis wir uns in einer heterogenen Infrastruktur vergruben: Wir brauchten Windows für Tests. Infolgedessen ist das Wissen darüber, wo bereitgestellt und getestet werden soll, in Jenkins enthalten.
Fazit
Infrastruktur wie Code ist
- Der Code im Repository.
- Das Zusammenspiel von Menschen.
- Infrastrukturtests.