Es gibt viele Artikel im Internet mit einer Beschreibung des Gradientenabstiegsalgorithmus. Es wird noch einen geben.
Am 8. Juli 1958 schrieb die New York Times : „Ein Psychologe zeigt einen Embryo eines Computers, der darauf ausgelegt ist, zu lesen und klüger zu werden. Von der Marine entwickelt ... lernte der 704-Computer, der 2 Millionen Dollar kostete, nach fünfzig Versuchen, zwischen links und rechts zu unterscheiden ... Nach Angaben der Marine bauen sie nach diesem Prinzip die erste Denkmaschine der Perceptron-Klasse, die lesen und schreiben kann. Die Entwicklung soll in einem Jahr abgeschlossen sein, mit Gesamtkosten von 100.000 US-Dollar ... Wissenschaftler sagen voraus, dass Perceptrons später Menschen erkennen und beim Namen nennen und mündliche und schriftliche Reden sofort von einer Sprache in eine andere übersetzen können. Herr Rosenblatt sagte, dass es im Prinzip möglich ist, „Gehirne“ zu bauen, die sich am Fließband reproduzieren können und sich ihrer eigenen Existenz bewusst sind “(zitiert und übersetzt aus dem Buch von S. Nikolenko,„ Tiefes Lernen, Eintauchen in die Welt der neuronalen Netze “).
Ah, diese Journalisten wissen, wie man fasziniert. Es ist sehr interessant herauszufinden, was eine Denkmaschine der Perceptron-Klasse wirklich ist.
Binäre (binäre) Klassifikation von Objekten, künstliches Neuron der Perceptron-Klasse
Hier ist unser künstliches Neuron, das Objekte in zwei Klassen unterteilt (führt eine binäre Klassifizierung von Objekten durch):

Also haben wir:
- Eingabe: Abtastobjekt - m-dimensionaler Raumvektor x = ( x 1 , . . . , x m )
- Gewichte w = ( w 1 , . . . , w m ) eine für jedes Merkmal des Probenobjekts (auch ein m-dimensionaler Vektor)
- Innen: Addierer S U M = w 1 × 1 + . . . + w m x m = s u m m j = 1 w j x j - gewichtete Summe der Neuroneneingaben
- Weiter: Aktivierung Φ(x,w)=Φ(SUMME)
- Noch weiter: Quantisierer (Schwelle) - θ [Theta]
- Aktivierung + Schwelle - Vorhersage der Klassenbezeichnung eines Objekts basierend auf der gewichteten Summe der Neuroneneingaben (Objektattribute). Dieser Teil definiert die spezifische Architektur des Neurons.
- Ausgabe: Objektklassenbezeichnung (eine von zwei) \ hat {y} = \ {1, -1 \}\ hat {y} = \ {1, -1 \}
Klassifizierung - weil ein Neuron einem Objekt eine Klasse zuweist, binär ( binär ) - weil es nur zwei mögliche Klassen gibt.
haty [Spiel mit Deckel] - Wir bezeichnen den vorhergesagten (berechneten) Klassenwert für das Objekt x
y [reguläres Spiel ohne Deckel] - wahre (bekannte) Klassenwerte für ein Objekt x aus dem Trainingsset.
Werte x (im Folgenden x und w - Dies sind keine Einheitswerte, sondern Vektoren.) variieren von Objekt zu Objekt, Gewichtskoeffizienten w (einmal ausgewählt) bleiben unverändert. Für das Trainingsset für jedes Objekt x Klassenlabel bekannt y . In der Trainingsphase müssen Sie Gewichte auswählen w damit das Modell den richtigen Wert erzeugt haty (fällt mit zusammen y ) für die maximale Anzahl von Objekten im Trainingssatz. Die Annahme der Nützlichkeit eines auf diese Weise trainierten Neurons basiert auf der Hoffnung, dass es mit den ausgewählten Koeffizienten den richtigen Wert erzeugt haty für neue Objekte x wahrer Klassenwert y für die es nicht im Voraus bekannt ist.
Die intuitive Bedeutung der gewichteten Summe der Eingaben eines Neurons besteht darin, dass alle Attribute eines Objekts (jedes der Zeichen ist eine der Eingaben eines Neurons) das Ergebnis der Klassifizierung des Objekts beeinflussen, jedoch nicht alle Zeichen gleichermaßen betroffen sind. Inwieweit - bestimmen Sie das Gewicht; Das Nullstellen eines bestimmten Gewichtungskoeffizienten hebt den Beitrag des entsprechenden Attributs zum Gesamtbetrag auf, d.h. Dies ist gleichbedeutend mit dem Entfernen des Features aus dem Objekt.
Adaptives lineares Neuron ADALINE
Das ADALINE-Neuron (adaptives lineares Neuron) ist ein gewöhnliches künstliches Neuron mit dieser Aktivierungsfunktion:
Φ(x,w)=Φ(SUM)=SUM
Phi(x(i),w)= Phi( summj=1wjx(i)j)= summj=1wjx(i)j
Im Folgenden hochgestellt i in Klammern wird angegeben i Element des Trainingssatzes x(i) oder wahrer Klassenwert y(i) oder vorhergesagter Klassenwert haty(i) für ihn.
Wir können sagen, dass ein solches Neuron einfach keine Aktivierungsfunktion hat und der Wert der gewichteten Summe der Eingaben dem Eingang des Quantisierers (Schwelle) zugeführt wird. Aus Gründen der Konsistenz ist es jedoch bequemer anzunehmen, dass der Wert der gewichteten Summe als Aktivierung verwendet wird.
Schwellenwert (Quantisierer) - sagt eine Klassenbezeichnung voraus:
\ hat {y} ^ {(i)} = \ left \ {\ begin {matrix} 1, \ Phi (x ^ {(i)}, w) \ ge \ theta \\ - 1, \ Phi (x ^ {(i)}, w) <\ theta \ end {matrix} \ right.
\ hat {y} ^ {(i)} = \ left \ {\ begin {matrix} 1, \ Phi (x ^ {(i)}, w) \ ge \ theta \\ - 1, \ Phi (x ^ {(i)}, w) <\ theta \ end {matrix} \ right.
Wenn der Aktivierungswert größer als ein Schwellenwert & thgr; [Theta] ist, weist der Quantisierer dem Objekt die Bezeichnung "1" zu, wenn der Aktivierungswert kleiner als der Schwellenwert & thgr; ist, erhält das Objekt die Bezeichnung "-1".
Hier können wir das Problem in erster Näherung formulieren : Wir müssen die Parameter des Neurons auswählen
- Gewichtungsfaktoren wj,j=1,..,m
- und Schwelle θ [Theta]
so dass Klassenwerte haty , die das Neuron den Objekten der Trainingsprobe zuordnet, stimmte mit den wahren Werten der Klassen überein y für die gleichen Elemente (oder gab zumindest die richtige Bedeutung für die Mehrheit).
Wir transformieren die Schwellenwertfunktion ein wenig, nehmen den Fall für die Klasse haty=1 und übertragen Sie die Schwelle auf die linke Seite der Ungleichung:
beginversammelte Phi(x(i),w) ge theta hfill summj=1wjx(i)j ge theta hfill− theta+ summj=1wjx(i)j ge0 hfill endgesammelt
bezeichnen w0=− theta und x0=1
beginversammeltew0x(i)0+ summj=1wjx(i)j ge0,w0=− theta,x0=1 hfill summj=0wjx(i)j ge0,x0=1 hfill endversammelte
Wie wir sehen, ist es uns gelungen, einen separaten Parameter θ zu entfernen und ihn unter dem Deckmantel eines neuen Gewichtskoeffizienten einzuführen w0 unter dem Vorzeichen der Summe, während der Beschreibung des Objekts ein neues Dummy-Einheitszeichen hinzugefügt wird x0=1 .
Wir werden die Formulierung des Problems unter Berücksichtigung der neuen Notation korrigieren.
Aufgabe ' : Wählen Sie die Parameter der Neuronengewichtungsfaktoren aus wj,j=0,..,m ,
x0=1 (Vorzeichenkonstante) - fiktives Neuron ( Verdrängungsneuron )
Ausgehend von dieser Stelle nummerieren wir die Vorzeichen und Gewichte c 0, nicht 1. Über den Vektor w wir werden sagen, dass es ungefähr (m + 1) -dimensional und nicht m-dimensional ist. Vektor x Abhängig vom Kontext können wir (m + 1) -dimensional betrachten (größtenteils in Formeln), aber denken Sie daran, dass es tatsächlich m-dimensional ist.
Warum ein Neuron ( in unserem Fall ist dies jedoch kein Neuron, sondern ein Zeichen eines Objekts oder nur eine Eingabe, aber im Fall eines mehrschichtigen Netzwerks verwandelt es sich in ein Neuron und wird normalerweise so genannt ) ist fiktiv - es ist derzeit klar. Warum er auch Verschiebung hat, wird später klar.
Die Aktivierung mit der Summe sieht nun folgendermaßen aus:
Phi(x(i),w)= Phi( summj=0wjx(i)j)= summj=0wjx(i)j,x(i)0=1 foralli
Der Schwellenwert ist jetzt immer 0 (Null) (der reale Wert wird in den Parameter verschoben w0 ):
\ hat {y} ^ {(i)} = \ left \ {\ begin {matrix} 1, \ Phi (x ^ {(i)}, w) \ ge 0 \\ - 1, \ Phi (x ^ {(i)}, w) <0 \ end {matrix} \ right.
Noch einmal formulieren wir das Problem mit anderen Worten (die geometrische Bedeutung des Problems)
Wenn wir uns die Formel für die Aktivierungsfunktion genau ansehen, werden wir sehen, dass es sich um eine parametrische Hyperebene im (m + 1) -dimensionalen Raum handelt, während sie in den ersten m Dimensionen mit den Punkten der Beispielelemente koexistiert und (m + 1) - Die E-Dimension ist der von den Elementen getrennte Wertebereich der Funktion.
Wenn wir nun den Aktivierungswert mit Null (Schwellenwert) gleichsetzen, ist dies auch eine Hyperebene, nur bereits im m-dimensionalen Raum, d. H. vollständig im Elementwertraum x . Diese Hyperebene trennt die Elemente. x in zwei disjunkte Gruppen.
Normalerweise sagen sie an dieser Stelle, dass unsere Aufgabe darin besteht, die Parameterwerte auszuwählen w d.h. Konstruieren Sie eine m-dimensionale Hyperebene im Raum der Elemente, sodass sich die Elemente des Trainingssatzes mit dem wahren Wert der Klasse "1" auf einer Seite der Ebene und Elemente mit der wahren Klasse "-1" auf der anderen Seite befinden.
Für diejenigen, die nicht ganz verstehen, was hier geschrieben steht, lesen Sie weiter - jetzt werden wir alle sehen, dies ist zuerst. Zweitens werden wir auch sehen, dass eine solche Erklärung des Problems, obwohl sie gültig ist, nicht vollständig ist.
Eindimensionaler Raum (m = 1)
Hier beginnt der Code zu erscheinen. Wir erstellen alle Diagramme mit der üblichen Matplotlib-Bibliothek, aber hier verwende ich auch die Seaborn-Bibliothek in einer Zeile, um den Bereich des Diagramms anzupassen, weil Ich mag, wie sie es macht, aber im Prinzip kann man ohne sie auskommen.
Wir nehmen viele eindimensionale Punkte und beantworten sie:
import numpy as np import math
Hier haben wir jedes i-te Element des Arrays X1 - dies ist das i-te Element (i-ter Punkt) des Trainingsmusters (genauer gesagt sein erstes und einziges Attribut): x(i)=(X1[i]) , x(i)1=X1[i]
Jedes i-te Element des Arrays y ist die richtige Antwort, eine wahre Bezeichnung, die dem i-ten Element der Trainingsprobe mit einem einzelnen Attribut X1 [i] entspricht.
Wir nehmen nur 5 Punkte, die ersten beiden sind der Klasse "-1" zugeordnet, die restlichen drei sind der Klasse "1" zugeordnet.
Zeichnen Sie diese Punkte auf die Linie:
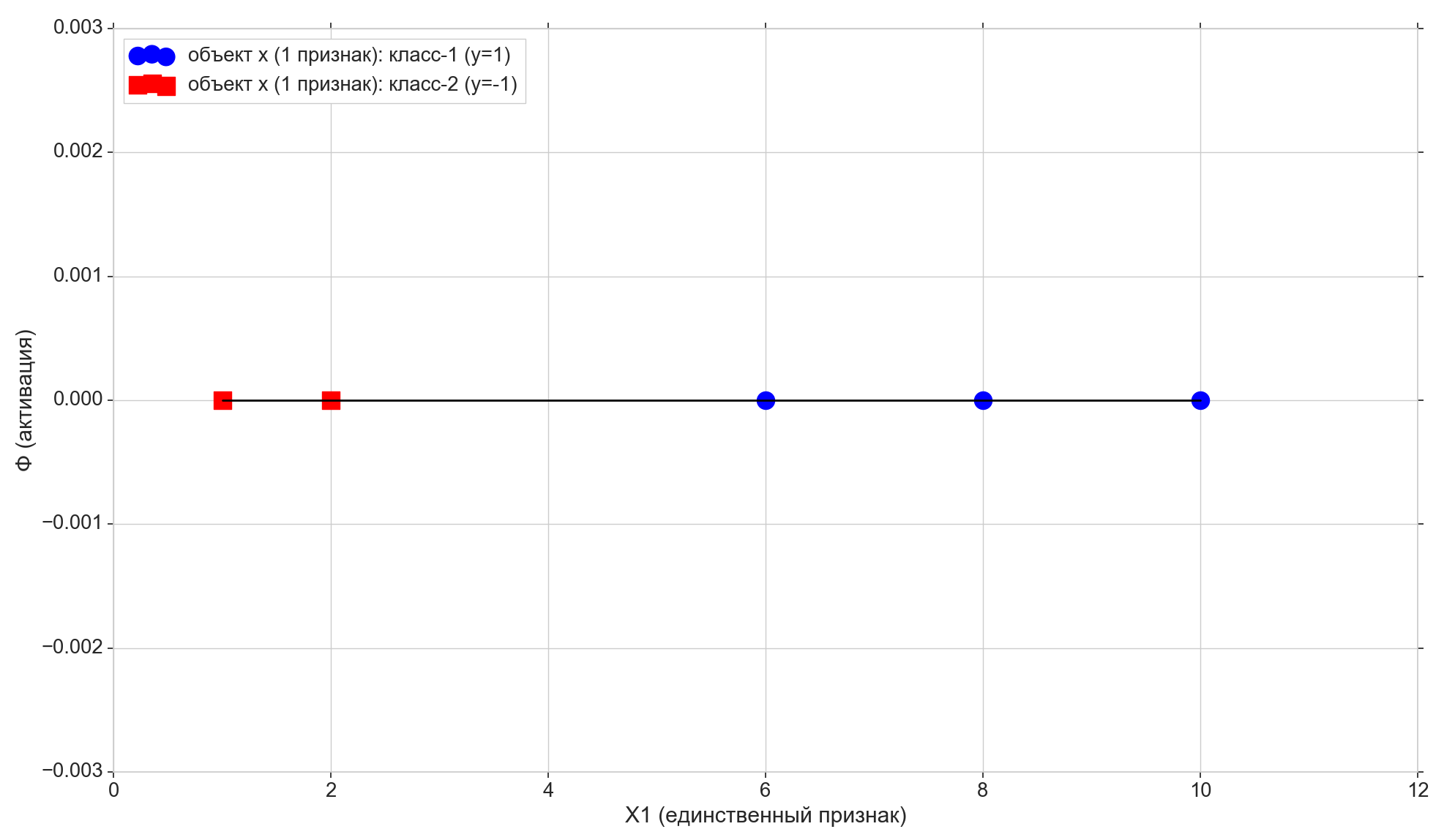
Schauen wir uns nun die Aktivierungsfunktion an:
Phi=w0+w1x1
Wie Sie sehen können, ist dies eine gewöhnliche Parameterlinie in der Ebene (im zweidimensionalen, d. H. (M + 1) -dimensionalen Raum):
- Auf der horizontalen Achse haben wir die Punkte der Elemente (sie sind auch die Werte des Attributs X1).
- auf der Vertikalen - Aktivierungswerte für jedes Element
- Parameter w1 - legt den Neigungswinkel fest,
- aber w0 - Verschiebung entlang der vertikalen Achse (hier ist die Antwort auf das Scherneuron).
w0 = -1.1 w1 = 0.4

Denken Sie auch daran, dass unsere Aktivierungsschwelle nach einer kleinen Konvertierung auf Null gesetzt wurde. Wenn also die Projektion des i-ten Elements auf die Aktivierungslinie kleiner als Null ist, weisen wir dem Element die Klasse -1 zu ( haty=−1 ), wenn es höher als Null ist, weisen wir die Klasse "1" zu ( haty=1 )
Lila Punkt - Schnittpunkt der Aktivierungslinie mit der Achse Phi=0 Dies ist die sehr trennende Hyperebene (für den eindimensionalen Raum ist der Punkt die Hyperebene), die im eindimensionalen (d. h. m-dimensionalen) Merkmalsraum aufgebaut ist. Wie Sie sehen, reicht es nicht aus, die Elemente in Gruppen zu unterteilen, aber um Klassen Gruppen zuzuweisen, reicht dies nicht mehr aus. Um Elementen Klassen zuzuweisen, benötigen wir eine direkte (zweidimensionale Hyperebenen-) Aktivierung, die im 2D-Raum (dh im (m + 1) -d) -Raum „Zeichen + Aktivierung“ aufgebaut ist: die Richtung der Aktivierungsabweichung von der Vertikalen Achse bestimmt die Klasse für Gruppen von Elementen, weil Dies hängt davon ab, ob die Projektionen der Elemente bei der Aktivierung höher oder niedriger als Null sind.
Parameter ändern w0 und w1 Wir erhalten verschiedene Aktivierungslinien. Wir müssen eine solche Aktivierungslinie bauen, d.h. Finden Sie eine solche Kombination von Parametern w bei dem die Projektion der ersten beiden Punkte des Trainingsmusters auf die Aktivierungslinie unter Null liegt (für sie der Wert haty=y=−1 ), und die Projektion der verbleibenden 3 Punkte wird über Null liegen (für sie haty=y=1 )
Es ist ziemlich offensichtlich, dass es in unserem speziellen Fall nichts Kompliziertes gibt, eine solche Linie zu konstruieren, außerdem können solche Linien im Allgemeinen in einer unendlichen Anzahl konstruiert werden. Wir werden jedoch versuchen, es so zu erstellen, dass ein Optimalitätskriterium erfüllt ist (es kann die Qualität zukünftiger Vorhersagen beeinflussen), und es sollte die Möglichkeit bestehen, den Algorithmus auf den mehrdimensionalen Fall auszudehnen.
Hier stellen wir auch fest, dass wir speziell den anfänglichen Satz von Punkten ausgewählt haben, so dass er durch eine solche Linie geteilt werden kann (für 1-e: alle Elemente der ersten Gruppe sind kleiner, alle Elemente der zweiten Gruppe sind größer als ein fester Wert), d.h. Viele Trainingspunkte sind linear trennbar .
Fügen Sie dem Diagramm zwei weitere horizontale Linien hinzu, die den Klassen {1, -1} entsprechen, und projizieren Sie die Elemente darauf.

Punkte mit der Klasse "-1" projizieren in die untere Zeile Phi=−1 zeigt mit dem Projekt der Klasse "1" auf die oberste Zeile Phi=1 .
Achten wir auf eine weitere kleine Nuance. Wir zeichnen die Aktivierungswerte entlang der vertikalen Achse auf, der Raum der Aktivierungswerte ist kontinuierlich. Das Ergebnis des Klassifikators (die Aktivierungsfunktion, die den Schwellenwert durchläuft) ist jedoch eine diskrete Menge von zwei Elementen {-1, 1} und keine kontinuierliche Skala. Hier nehmen wir eine diskrete Reihe von Klassen y und stellen Sie es auf eine kontinuierliche Aktivierungsskala Phi so dass diskrete Klassenwerte zu gewöhnlichen Punkten auf der Aktivierungsskala werden - Sonderfälle von Aktivierungswerten, die sie direkt akzeptieren oder sich ihnen annähern können. Genau genommen könnten wir zunächst nicht die numerischen Werte als Klassen verwenden, sondern die Zeichenfolgenbezeichnungen „Klasse 1“ und „Klasse 2“. In diesem Fall müssten wir die Zeichenfolgenbezeichnungen den numerischen Werten auf der Aktivierungsskala zuordnen. Daher sollten in unserem Fall die Werte der Klassen "-1" und "1" nicht als Klassenbezeichnungen verwendet werden, sondern als Zuordnung markierter Klassen zur Aktivierungsskala.
Es ist Zeit, die Fehlermetrik einzugeben

Es ist natürlich zu akzeptieren, dass die Aktivierungsklasse für dieses Element umso besser vorhersagt, je näher der Aktivierungswert für das ausgewählte Element am Klassenwert für dasselbe Element liegt. Für den Fehler für das ausgewählte Element können Sie also den Abstand zwischen den Punkten nehmen - die vertikale Projektion des Elements auf die Aktivierungslinie und die Projektion des Elements auf die horizontale Linie seiner bekannten (wahren) Klasse. In der Grafik: Fehler - vertikale orange Linien.
Kosten- (Verlust-) Funktion
Wir haben eine Fehlermetrik für jeden einzelnen Artikel. Wir können daraus eine Qualitätsmetrik für die gesamte Aktivierungslinie erhalten. Es ist ganz natürlich zu akzeptieren, dass wir umso besser eine Aktivierungslinie aufgebaut haben, je kleiner die Summe der Fehler aller Elemente des Trainingsmusters ist. Für jedes einzelne Element ist der Fehler nicht minimal, aber für das gesamte Trainingsbeispiel als Ganzes können Sie Kompromisse eingehen.
Sie können jedoch nicht eine einfache Summe von Fehlern nehmen, sondern die Summe der quadratischen Fehler ( Summe der quadratischen Fehler, Summe der quadratischen Fehler, SSE ). Es ist ziemlich offensichtlich, dass, wie im Fall der Summe gewöhnlicher Fehler, je näher die Aktivierungslinie an den Punkten mit wahren Klassen von Elementen liegt, desto kleiner die Summe quadratischer Fehler ist, aber im Fall eines quadratischen Fehlers erhalten die entferntesten Elemente eine schwerere Strafe.
Was uns hier interessiert, ist nicht die Größe der Geldbuße für entfernte Elemente, sondern die Tatsache, dass die quadratische Funktion ein Minimum hat und überall differenzierbar ist (die übliche Summe hat ein Minimum, aber bei diesem Minimum ist sie nicht differenzierbar). Sehen Sie, warum dies notwendig ist. etwas später.
Also:
- Fehler - Abstand vom Klassenbeschriftungswert zur Aktivierungshyperebene
- SSE - die Summe der quadratischen Fehler aller Elemente der Trainingsstichprobe
- Kostenfunktion J(w) - Qualitätsmetrik für die ausgewählte Aktivierungslinie. Je niedriger der Wert, desto besser die Aktivierung.
Nehmen Sie als Funktion des Wertes 1 über2 SSE sieht im allgemeinen Fall für ein lineares Neuron folgendermaßen aus:
beginversammelteJ(w)=1 über2SSE=1 über2 sumni=1( Phi( sum)j=0mwjx(i)j)−y(i))2=1 over2 sumni=1( summj=0wjx(i)j−y(i))2 endversammelte
( 1 über2 Erstens stört es SSE nicht und zweitens wird es der Einfachheit halber weiter reduziert.
Hier i - Elementnummer und n - die Anzahl der Elemente im Trainingssatz. Ich möchte Sie daran erinnern y(i) - wahre Klasse i Element der Trainingsprobe, d.h. bekannte richtige Antwort im Voraus.
Wie wir uns erinnern, wird die Position der Aktivierungslinie durch die Parameter - Gewichtungsfaktoren - bestimmt w daher Vektor w wirkt als Parameter der Verlustfunktion.
Für eindimensionalen Fall
J(w)=1 über2SSE=1 über2 sumni=1(w0+w1x(i)1−y(i))2
Werte x und y sind im Voraus bekannt (dies ist ein Trainingssatz), daher sind sie behoben. Wir wählen die Parameter aus w d.h. w0 und w1 damit der Wert J(w) Es stellte sich als minimal heraus. Versuchen wir, das Diagramm als Wert darzustellen J(w) hängt von den Parametern ab w0 und w1

Im Allgemeinen ist hier bereits sichtbar, dass die Verlustfunktion ein Minimum hat und wo sie sich ungefähr befindet. Aber lassen Sie uns noch einen Trick machen und dasselbe Diagramm erstellen, nur mit einer logarithmischen vertikalen Skala .

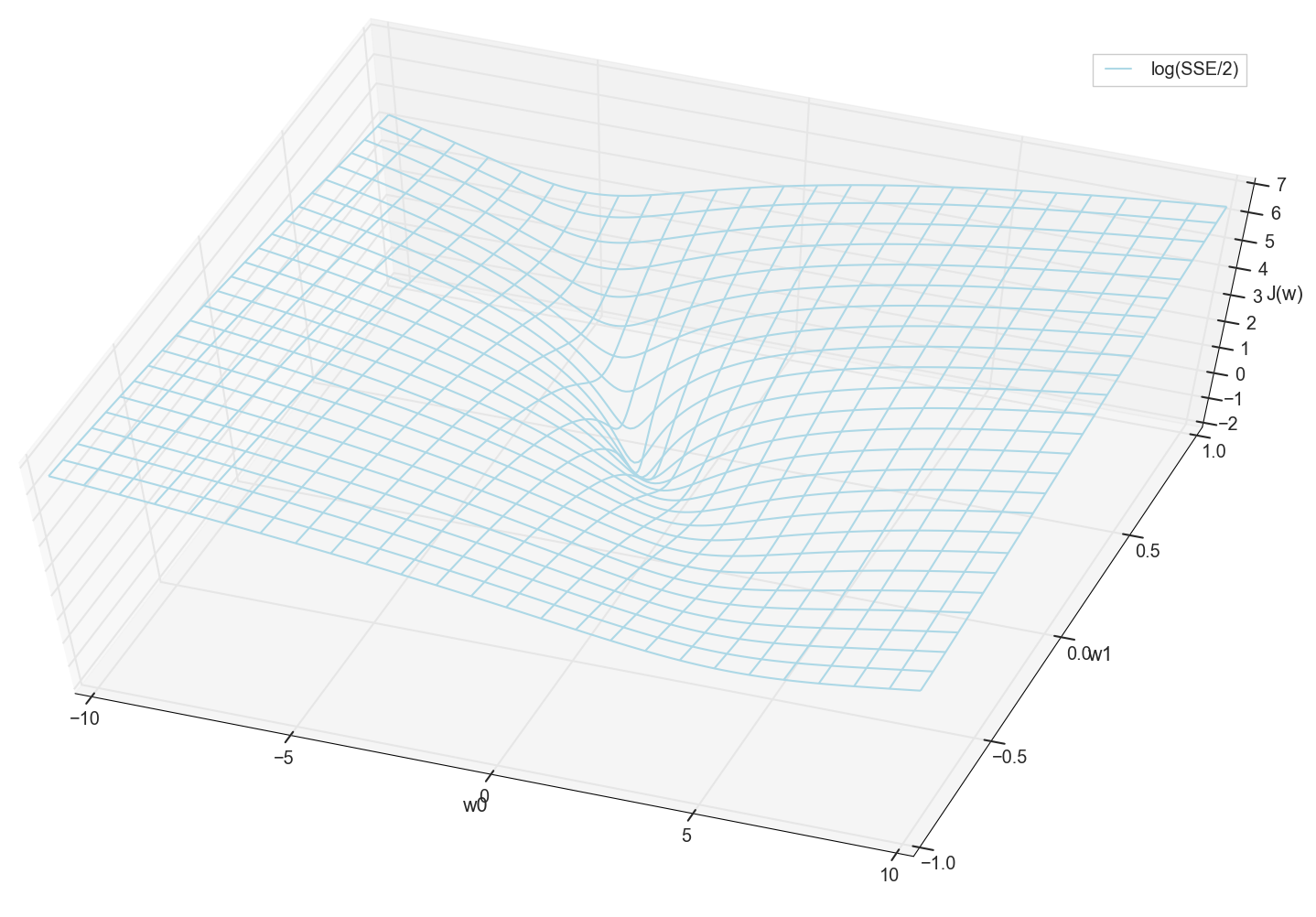
Ich weiß nichts über dich, aber als ich dieses Diagramm zum ersten Mal sah, erlebte ich Erleuchtung. Diese natürliche Höhle ist nicht nur eine figurative Visualisierung mehrdimensionaler Hügel aus einem beliebten Artikel über neuronale Netze, sondern eine echte Grafik.
Unsere Aufgabe ist es, solche Werte auszuwählen w0 und w1 um dieser Grube auf den Grund zu gehen. Wir bekommen die Werte von Gewichten - wir bekommen ein trainiertes Neuron.
Da wir alle gleich einen Graphen gezeichnet haben und sein Minimum persönlich beobachten, wird uns niemand verbieten, seine Koordinaten durch eine einfache Aufzählung im Raster "manuell" zu finden:

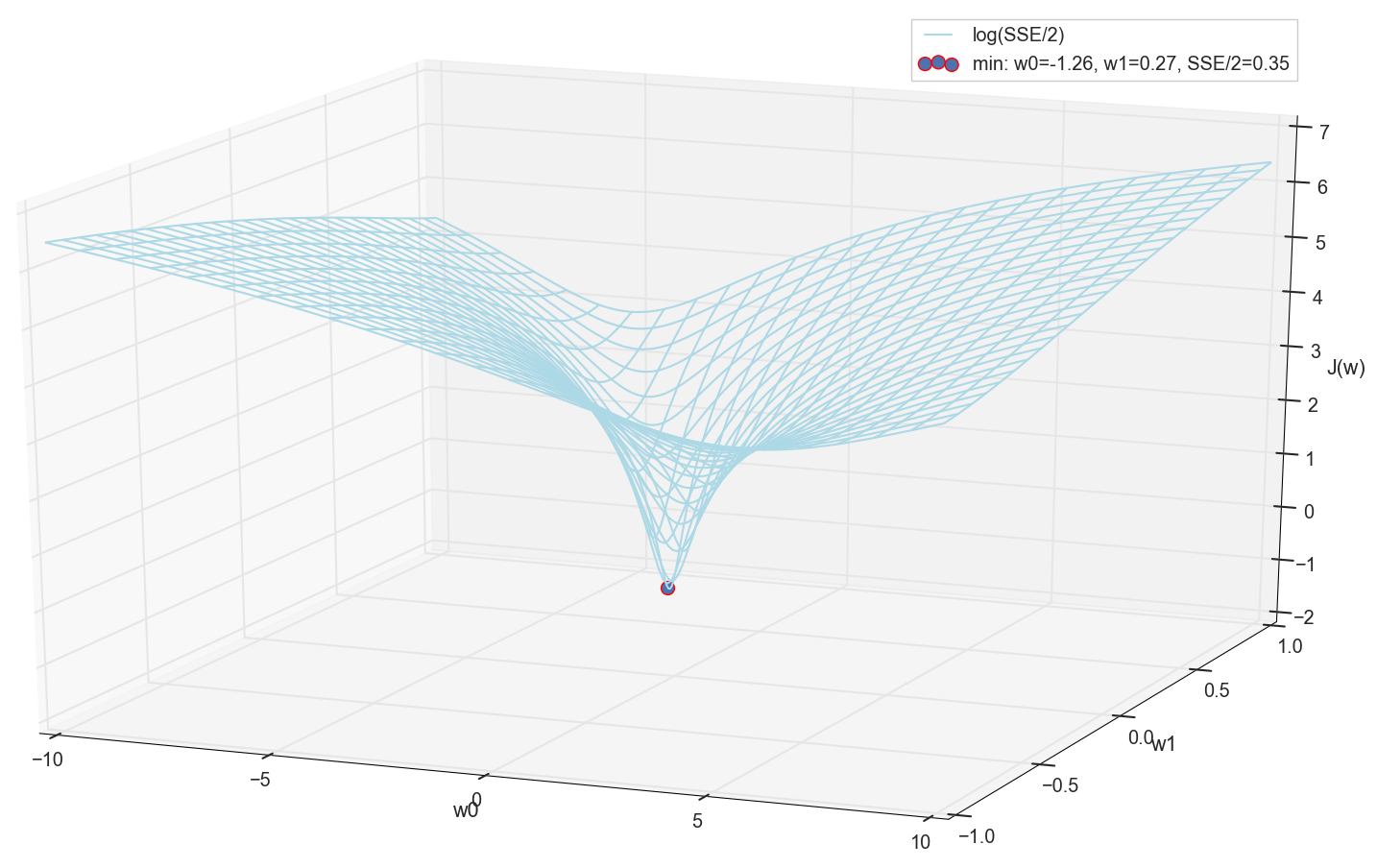
Dies sind die Werte: w0=−1,26 und w1=0,27 beträgt die Summe der quadratischen Fehler der SSE 0,69, die Kostenfunktion J(w)=SSE/2=0,35 (genauer: 0,3456478371758288).
Mal sehen, wie die Aktivierung mit diesen Parametern aussieht:

Für mich ist das ganz normal. Der Schnittpunkt der Aktivierung mit einem Schwellenwert von Null trennt Elemente aus verschiedenen Klassen, und die Aktivierung selbst weist ihnen die richtigen Werte zu. Gleichzeitig scheint die Aktivierung in einer optimalen Position zu sein.
Bevor wir fortfahren, bewundern wir noch einmal die Grafik im Raster weiter:
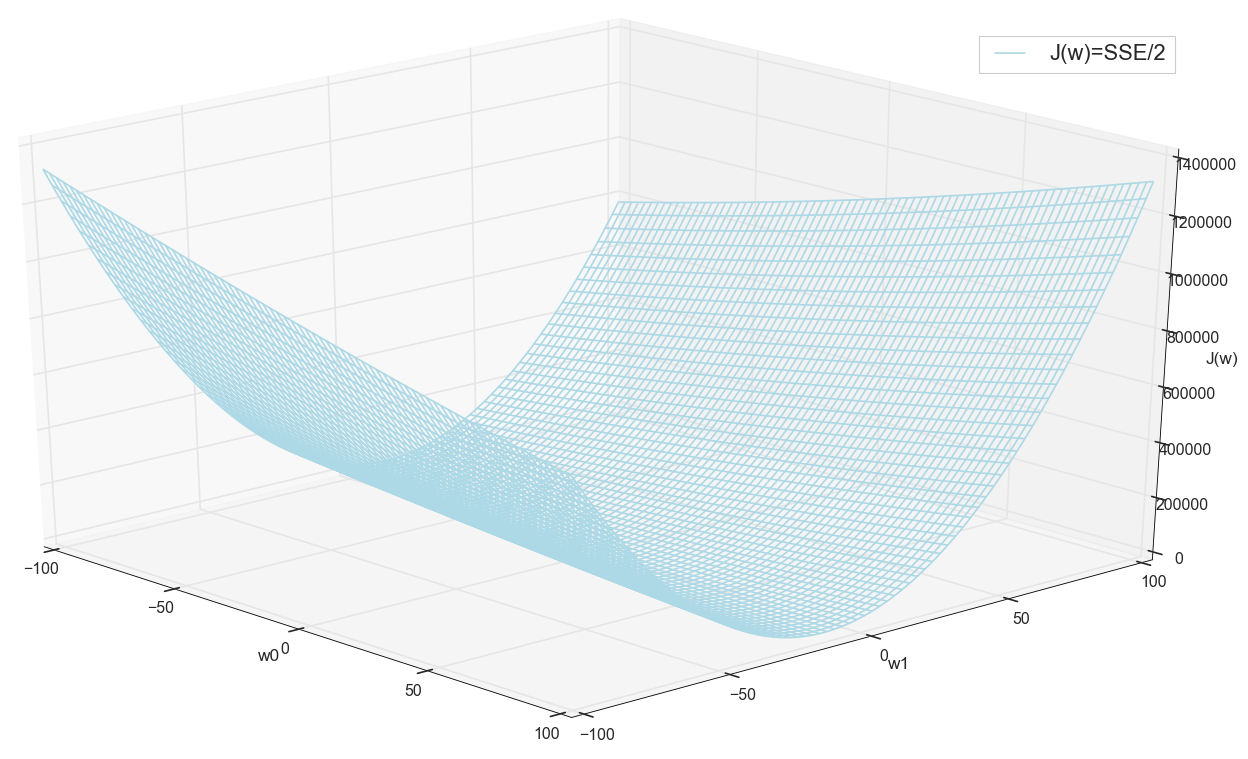
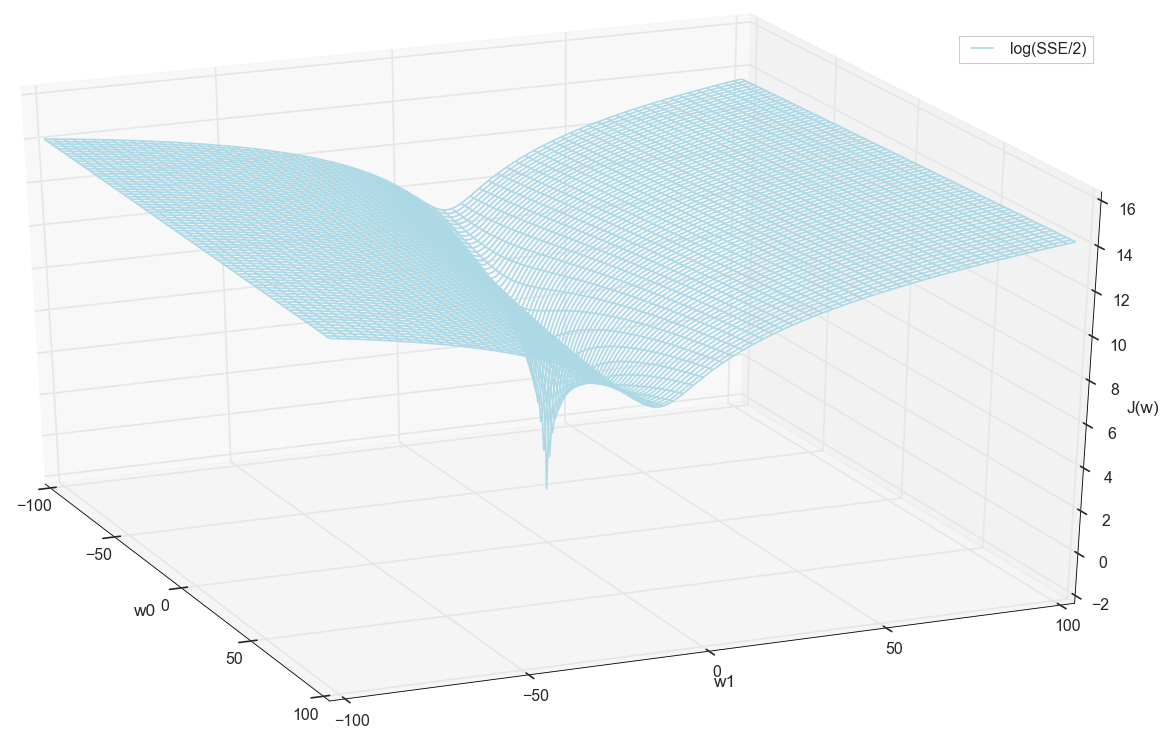
Es scheint, dass es keine anderen Tiefs in der Nähe gibt, die gedacht hätten.
Minimale Suche
Wir haben also Gewichte - die Koordinaten des minimalen Fehlerwerts. Dies ist der optimale Wert der Gewichte auf dem Trainingsmuster. Im Allgemeinen ist dies genau das, was wir brauchen. Wir können sagen, dass das Neuron trainiert ist. Vielleicht kann dies abgeschlossen werden?
Suche nach einem Minimum: Suche nach Raster
- Die Option auf den ersten Blick funktioniert ziemlich gut (wie wir sehen)
- Sie müssen im Voraus wissen, in welchem Bereich Sie nach einem Minimum suchen müssen (Sie können ziemlich große Ränder nehmen und dann den Suchbereich eingrenzen - dies ist nur mit dem Auge möglich).
- Um die Genauigkeit zu erhöhen, müssen Sie den Schritt → noch mehr Punkte verringern (Lösung: Sie können den Suchbereich iterativ eingrenzen).
- Zu viele Punkte (für 2d mag es in Ordnung sein, aber für mehrdimensionale Fälle stoßen wir sehr schnell auf Ressourcen)
- Für MNIST (28 x 28 = 784 Pixel - dieselbe Anzahl von Eingaben, dieselben Gewichtungsfaktoren plus Versatz, ein Raster von 100 Schritten pro Dimension): 100 ^ 785 = 10 ^ 1570.
Wenn wir also ein einzelnes Neuron (nicht einmal ein neuronales Netzwerk) in einem Bild von 28 x 28 = 784 Pixel trainieren möchten, indem wir durch direkte Aufzählung in einem Raster von 100 Punkten für jede Messung nach einem Minimum suchen, müssen wir 10 ^ 1570 Kombinationen aussortieren. Dies ist ziemlich viel für die Speicherung und Suche (im sichtbaren Teil des Universums gibt es nur 10 ^ 80 Atome, das Universum existiert für ungefähr 4 * 10 ^ 17 Sekunden = 4 * 10 ^ 26 Nanosekunden).
Versuchen wir, schneller eine Option zu finden.
Minimale Suche: Konstanter Abstieg
Schauen wir uns das Diagramm der Verlustfunktion an J(w) im Flugzeug: fix w0 ändern w1
def sse_(X, y, w0, w1): return ((w0+w1*X - y)**2).sum()
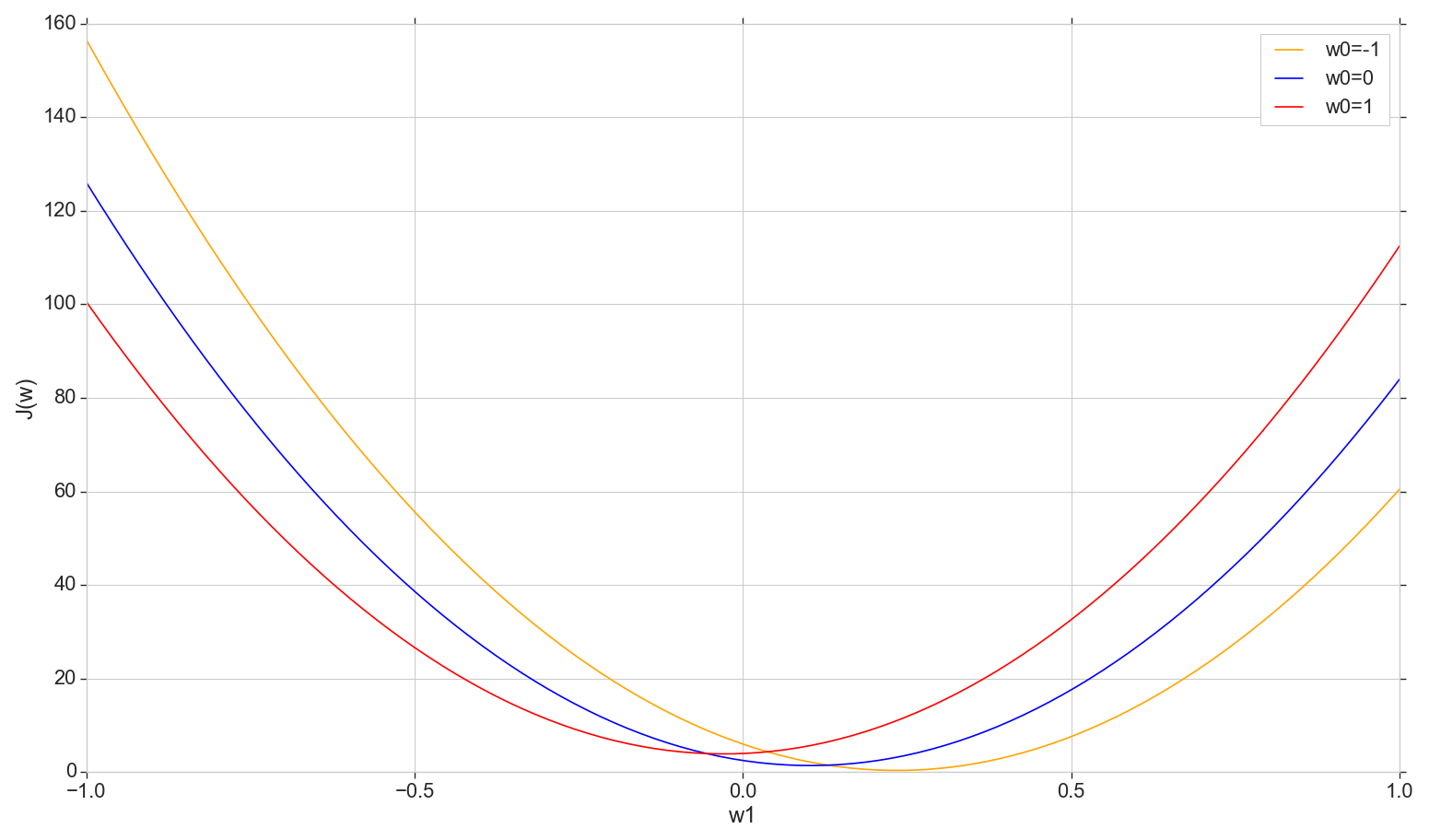
Dies ist eine gewöhnliche Parabel (genauer gesagt eine Familie von Parabeln - sie unterscheiden sich geringfügig, je nachdem, auf welchen Wert sie festgelegt ist w0 ) Um die minimale Parabel zu finden, müssen nicht alle Punkte sortiert werden. Wir können einen beliebigen Punkt auf der horizontalen Achse wählen und uns mit einem Schritt zum Minimum bewegen.
Betrachten Sie eine Option mit konstanter Tonhöhe
- Wenn der Schritt zu groß ist, können Sie ihn verfehlen und das Minimum nicht erreichen (der Schritt kann reduziert werden).
- Wenn es zu klein ist, gibt es zu viele Schritte (mehr als es sein könnte)
- In jedem Fall werden wir nicht das genaue Minimum erreichen, aber wir können es mit willkürlicher Genauigkeit erreichen, indem wir den Schritt in der Nähe des gefundenen ungenauen Minimums ändern (der Schritt hört auf, konstant zu sein).
- Wir kennen die Abstiegsrichtung nicht (es ist möglich, algorithmisch zu lösen: Gehen Sie nicht in Richtung zunehmender Fehler).
- Das Problem beim Auffinden der Reichweite wurde behoben (Sie können von überall aus nach unten gehen - früher oder später werden wir sowieso nach unten gehen).
- Im Prinzip funktioniert die Option, aber vielleicht gibt es eine bessere Option?
Hinweis: Als ich über eine solche Möglichkeit des Abstiegs zu einer Vorlesung sprach, fragte ein Student, warum Sie schrittweise vorgehen müssen, wenn Sie anhand der Formel sofort eine Mindestparabel finden können. Zuerst habe ich etwas in dem Sinne beantwortet, dass wir jetzt daran interessiert sind, die Iterationsoption in Betracht zu ziehen, damit wir sie später nicht nur mit einer Parabel, sondern auch in anderen Situationen verwenden können. Außerdem benötigen wir in diesem Abschnitt nicht mindestens eine Parabel - wir werden uns nicht in einer Dimension, sondern in allen Dimensionen auf ein Minimum bewegen, sodass bei jeder neuen Iteration ein neuer Schritt nicht entlang dieser Parabel, sondern weiter stattfindet Parabel mit einer neuen Scheibe mit einem verschobenen Wert w0 . Aber später dachte ich, dass im Prinzip nichts falsch ist, wenn wir uns bei jedem Slice bewegen, nicht in Schritten, sondern sofort auf das Minimum des aktuellen Slice herunterrollen. Also müssen wir immer wieder, Messung für Messung, immer noch auf ein globales Minimum rutschen, und es scheint schneller als die Schritte zu sein. Für ein einzelnes Neuron sollte es funktionieren und nicht nur mit einer Parabel. Aber ich habe noch nicht angefangen, Zeit damit zu verschwenden, diese Theorie zu testen, also gehen wir hier einfach weiter - ich habe versprochen, über Gradientenabstieg zu sprechen.
Suche nach einem Minimum: Gefälle
Im Allgemeinen gehen wir die Stufen hinunter, aber wir machen es klüger. Wir verwenden die Ableitung der Kostenkurve, um den Schritt auszuwählen (hier nicht die Kostenkurve , sondern die Kostenkurve ).
- Wir haben mehrere Dimensionen und jede hat ihre eigene Kurve: Wir reparieren alles wj außer wk ,
- J(wk) es wird eine Fehlerkurve in geben k th Dimension
- Alle von ihnen sind (in unserem Fall) Parabeln, aber im Allgemeinen ist es nur wichtig, dass sie überall differenzierbar sind und ein Minimum haben
- Um den Schritt in jeder Messung anzupassen, verwenden wir die partielle Ableitung der Fehlerfunktion in Bezug auf diese Messung (einen variierenden Koeffizienten) wk )
- Ein Vektor solcher partiellen Ableitungen wird als Gradient bezeichnet.
Das ist alles gut, aber woher kommt die Ableitung? Jetzt lass es uns herausfinden.
Die geometrische Bedeutung der Ableitung
Für mich blieb das Derivat lange Zeit eine Reihe spezieller Formeln und Regeln für seine Berechnung sowie etwas über die Zunahme, Abnahme und Extreme. Es ist hier angebracht, sich daran zu erinnern oder herauszufinden, was das Derivat tatsächlich ist.
Ableitungsfunktion y(x) an diesem Punkt x0 Ist die Grenze des Verhältnisses des Inkrements der Funktion Deltay zum Argumentinkrement Deltax beim Inkrementieren eines Arguments Deltax gegen Null tendieren:
y′(x0)= lim Deltax bis0 Deltay über Deltax, Deltay=y(x0+ Deltax)−y(x0)

Der Punkt im Bild M(x0,y(x0))=(x0,y0) Ist der Punkt, an dem wir die Ableitung bestimmen wollen. Punkt N(x0+ Deltax,y(x0+ Deltax))=(x0+ Deltax,y0+ Deltay) - Punkt, der durch Inkrementieren des Arguments erhalten wird Deltax . Direkt Mn - Sekante durch diese beiden Punkte.
Punkt A - Schnittpunkt der Sekante Mn mit horizontaler Achse y=0 .
Betrachten Sie zwei rechtwinklige Dreiecke: ein Dreieck DreieckNPM mit Abschnitt Sekante Mn als Hypotenuse und Dreieck triangleMBA mit der Fortsetzung der Sekante zur Achse y=0 - Segment AM als Hypotenuse. Aus dem Grafik- und Schulgeometriekurs geht hervor, dass die Winkel angleNMP und angleMAB sind gleich, und deshalb sind ihre Tangenten gleich:
tan angleMAB= tan angleNMP=MB überAB=NP überMP= Deltay über Deltax
Zum Bild hinzufügen: MD - Tangente an die Anfangskurve am Punkt M kreuzt eine Achse y=0 an der Stelle D . Dreieck triangleMBD - ein rechtwinkliges Dreieck mit Hypotenuse - Kassettenabschnitt, Segment MD .
Wir zielen auf das Inkrement Deltax auf Null:
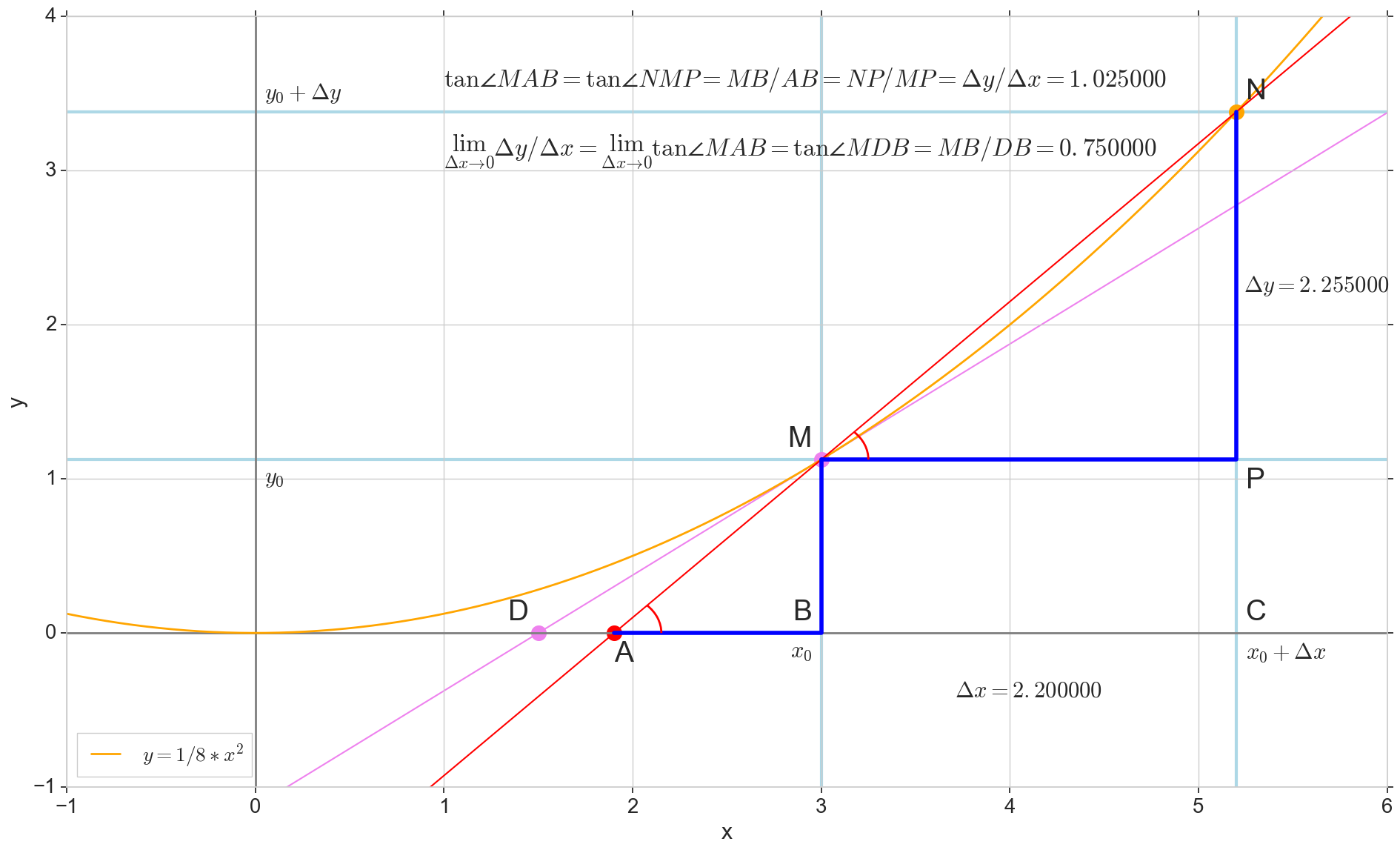
Punkt N auf den Punkt bewegen M nach Funktion Punkt A schleicht sich zu einem Punkt D entlang der Achse y Sekante Mn verwandelt sich in eine Tangente MD mit Berührungspunkt M . Quellendreieck DreieckNPM mit Beinen Deltax und Deltay schrumpft auf einen Punkt, aber ein Dreieck wie es triangleMBA verwandelt sich in ein Dreieck triangleMBD Erhalt nicht nur makroskopischer Dimensionen, sondern auch Winkelgleichheit angleMAB und angleNMP .
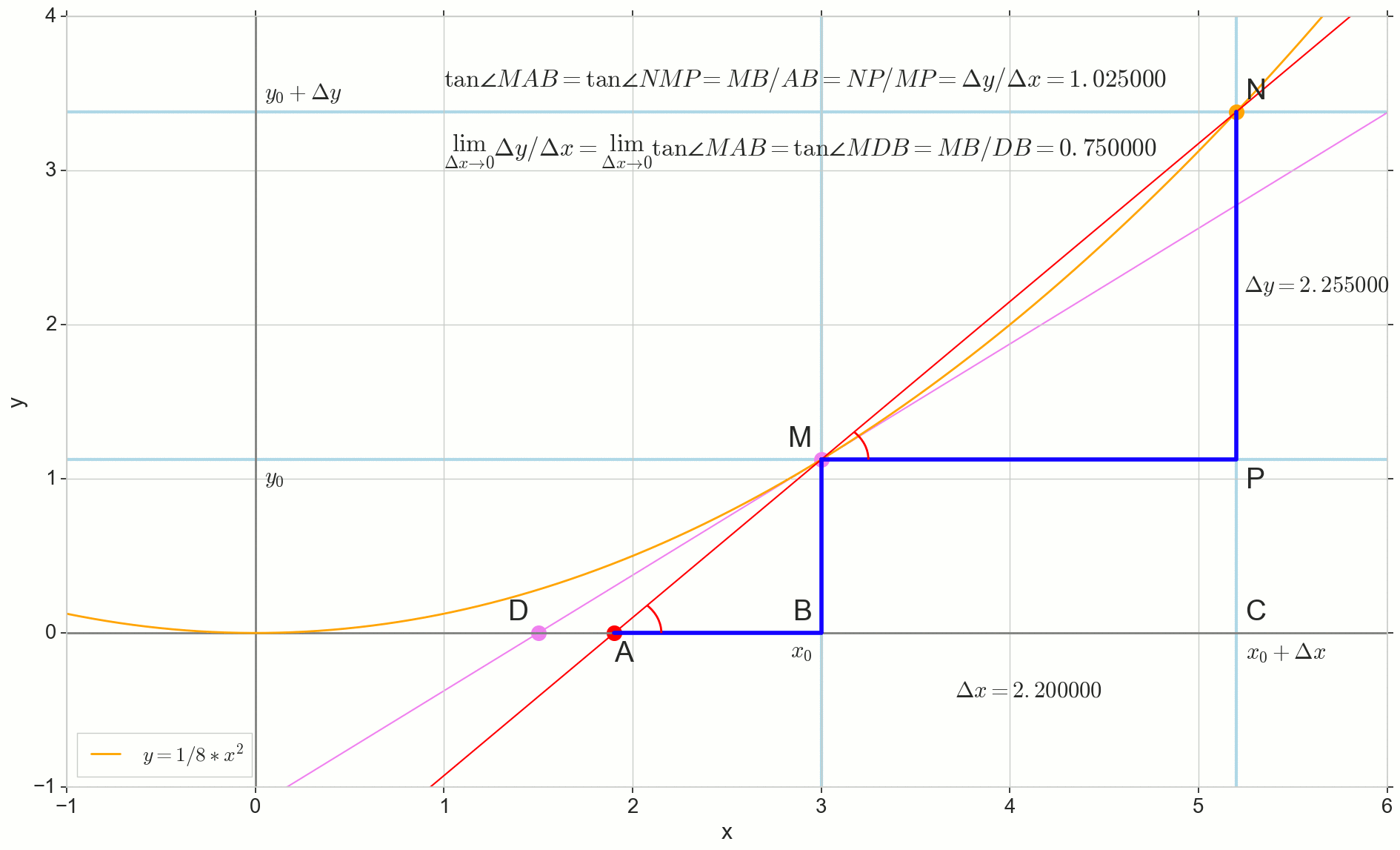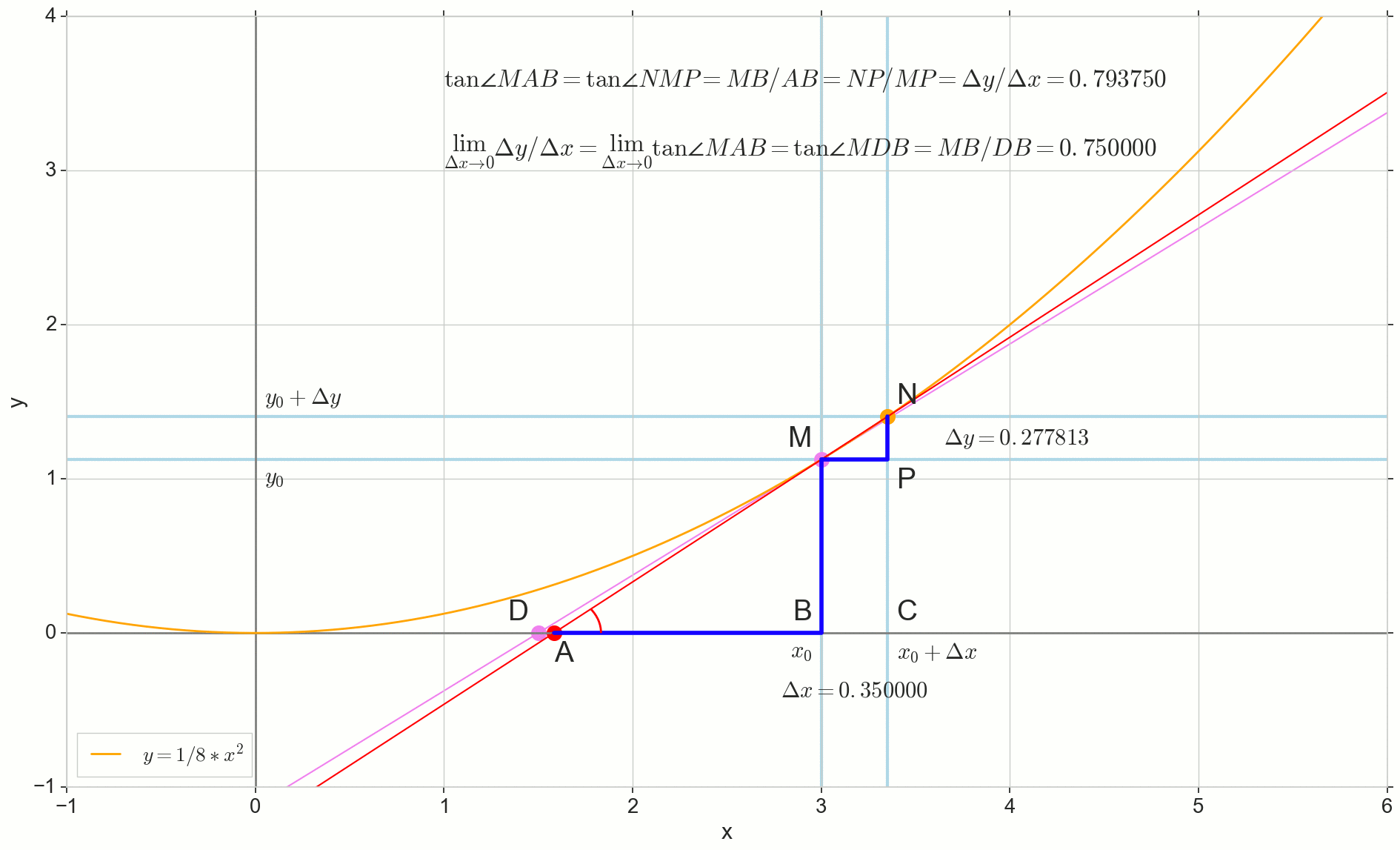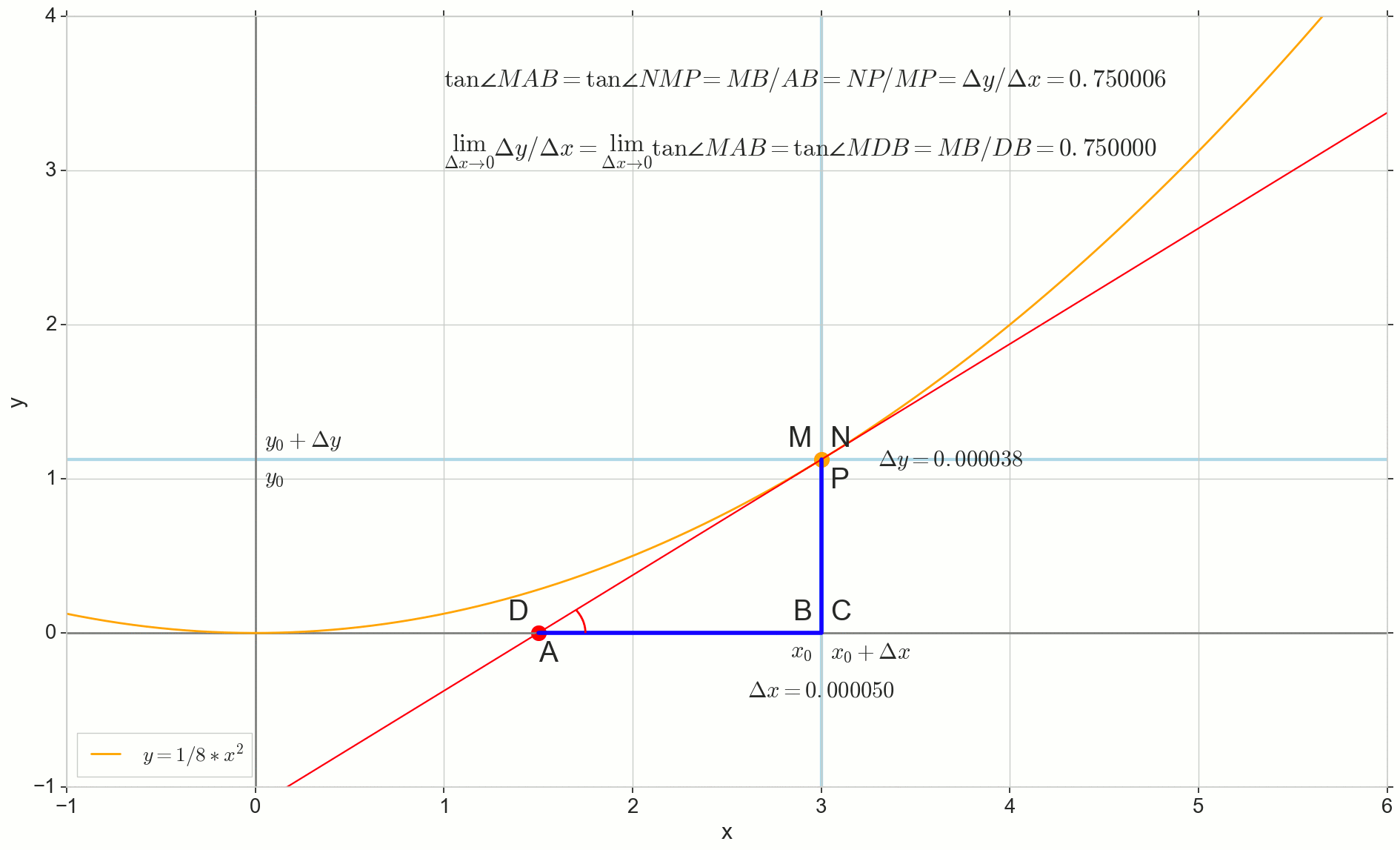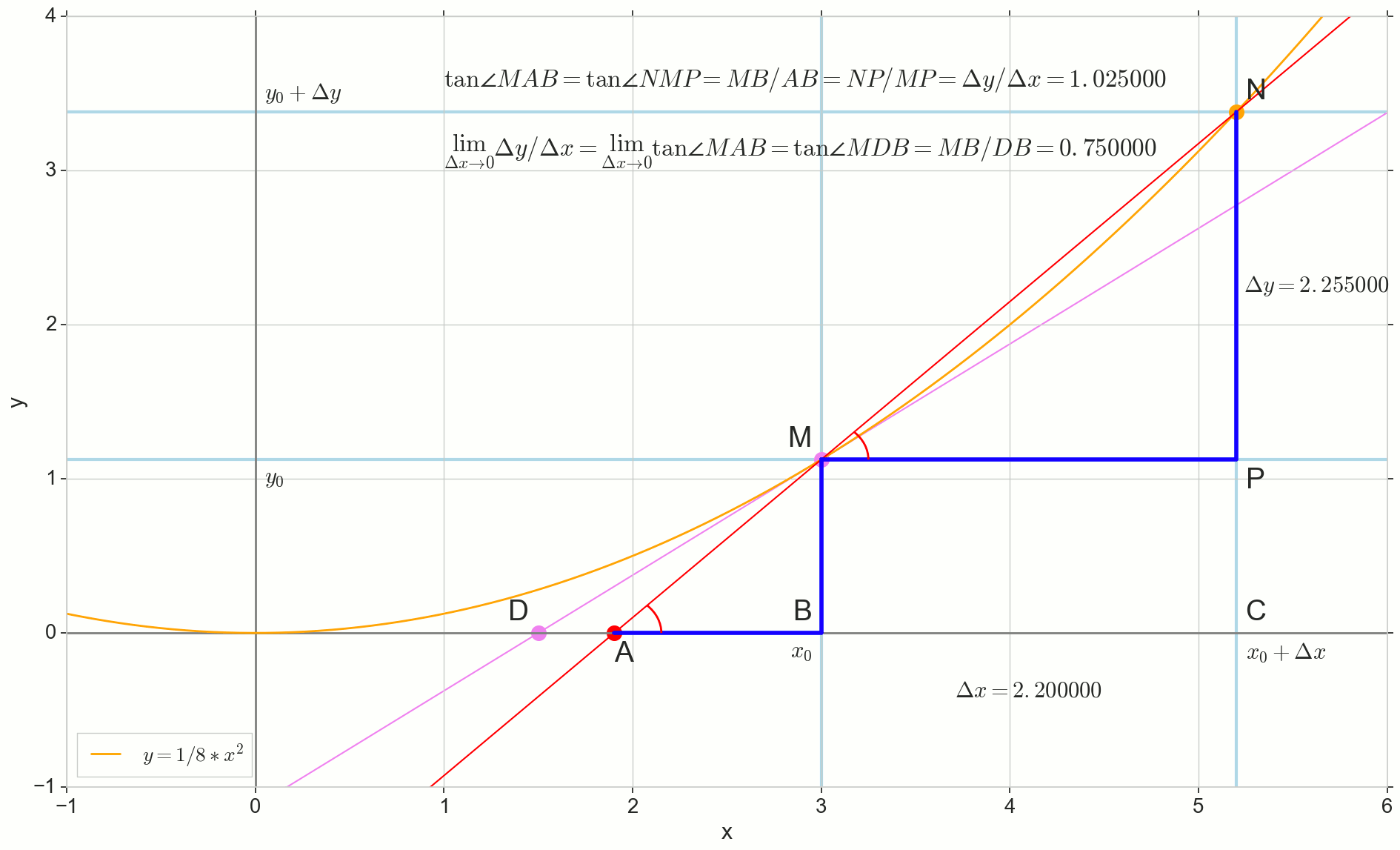
Wie inkrementieren Deltax , unendlich nahe Null, wird niemals Null erreichen, also der Punkt N Komme nie genau an die Stelle M Punkt A wird den Punkt nicht erreichen D Dreieck triangleMBA wird nicht in triangleMBD . Glücklicherweise können wir das genaue Ziel für all diese Bewegungen mit dem magischen mathematischen Operator "limit" festlegen. lim .
△MBA — △MBD , :
limΔx→0ΔyΔx=limΔx→0tan∠NMP=limΔx→0tan∠MAB=limΔx→0MBAB=MBDB=tan∠MDB
:
limΔx→0ΔyΔx=tan∠MDB
, , :
y′(x0)=limΔx→0ΔyΔx=tan∠MDB
, y=0 . .
, , , , , . , , , , .. ( , , ). : , (, — tangent line , , — ).
:
- x0 y=0
- — y(x0) — x0 y=0 y=0
- «» , ,
- — : — , —
- ( , , , Δy )
, , :

— , — x0 , — . — — . — y=0 , — .

, , , , . ( , ) (: y=0 , ).

( ): , (: y=0 , ).
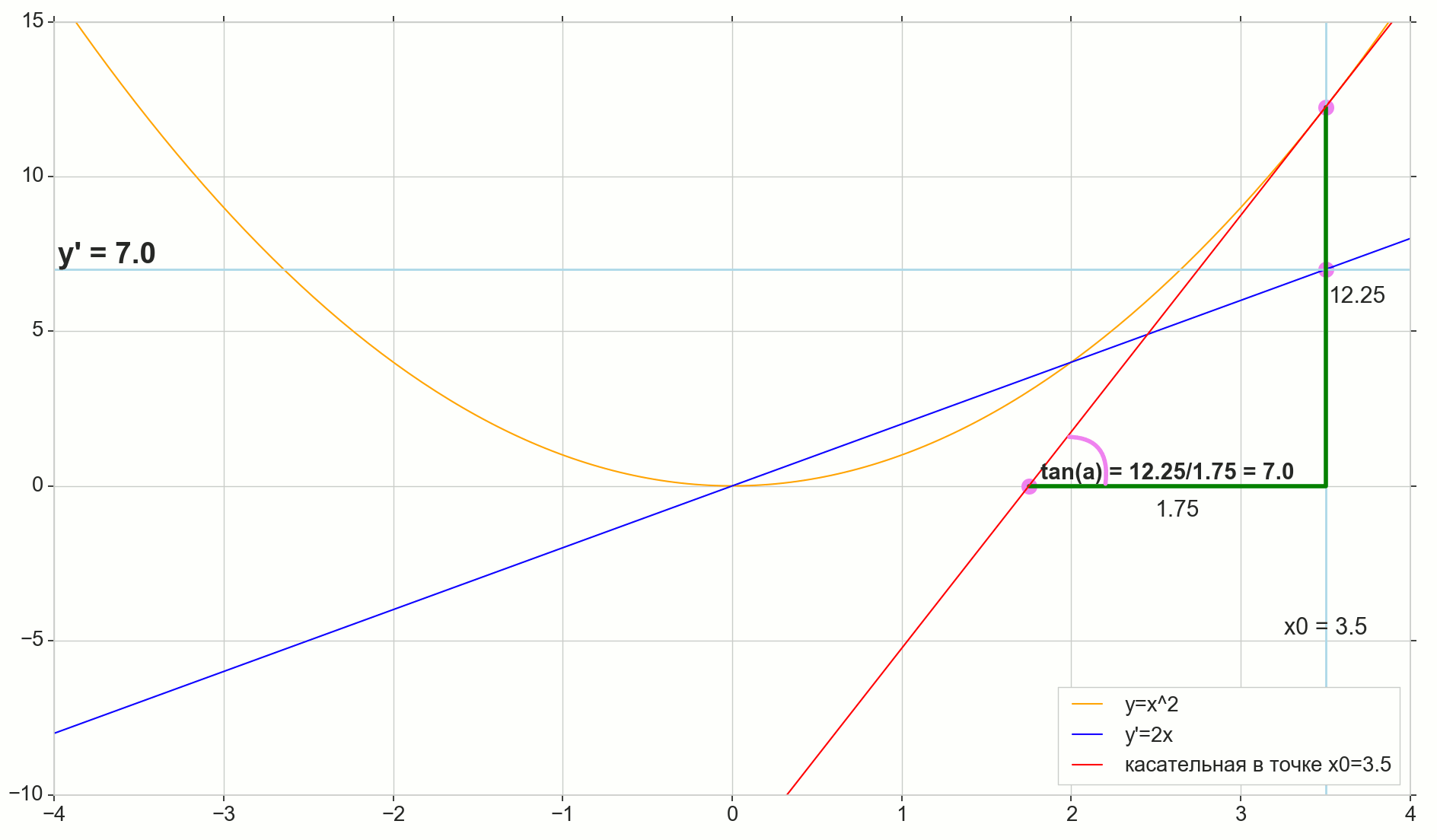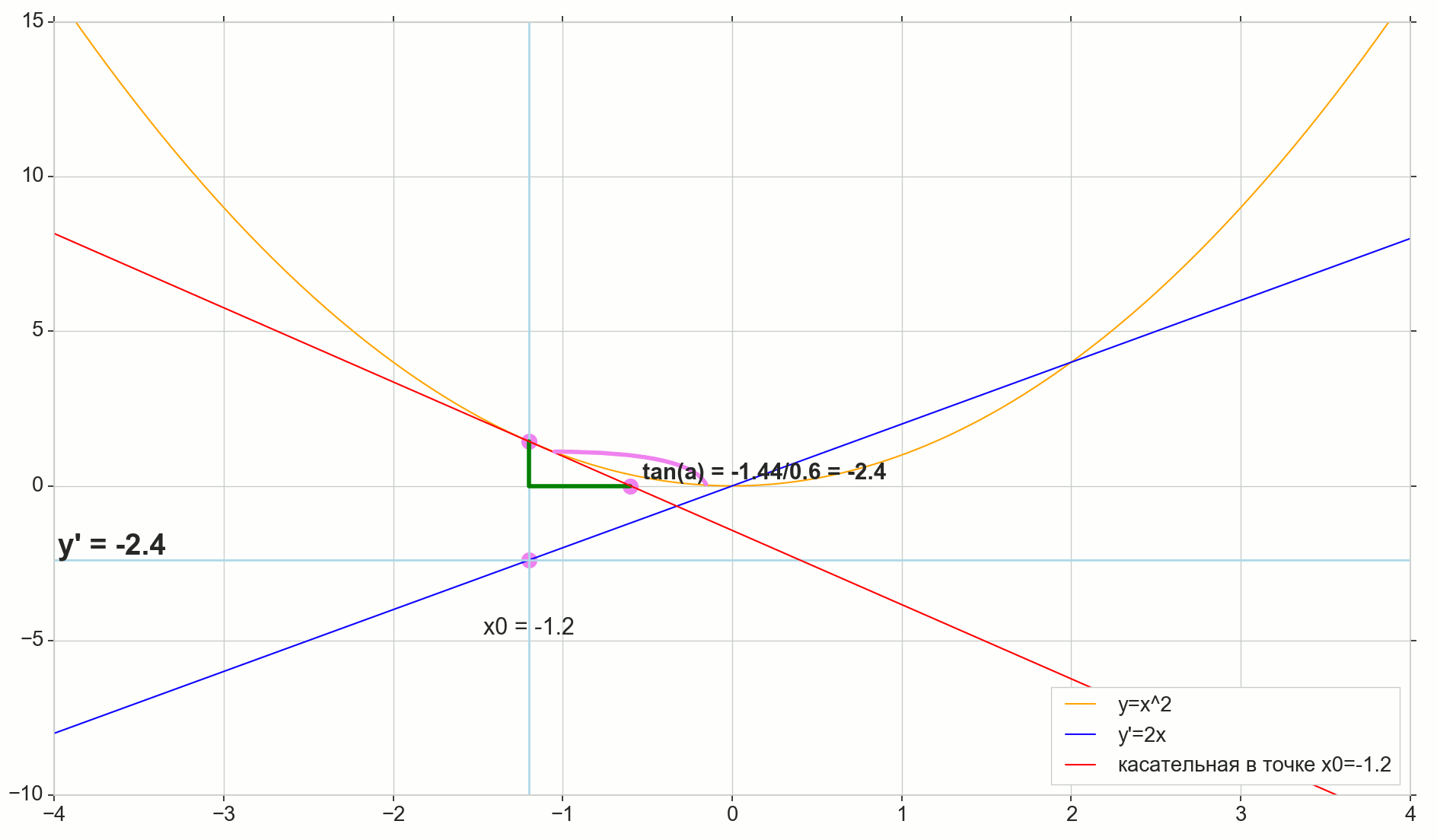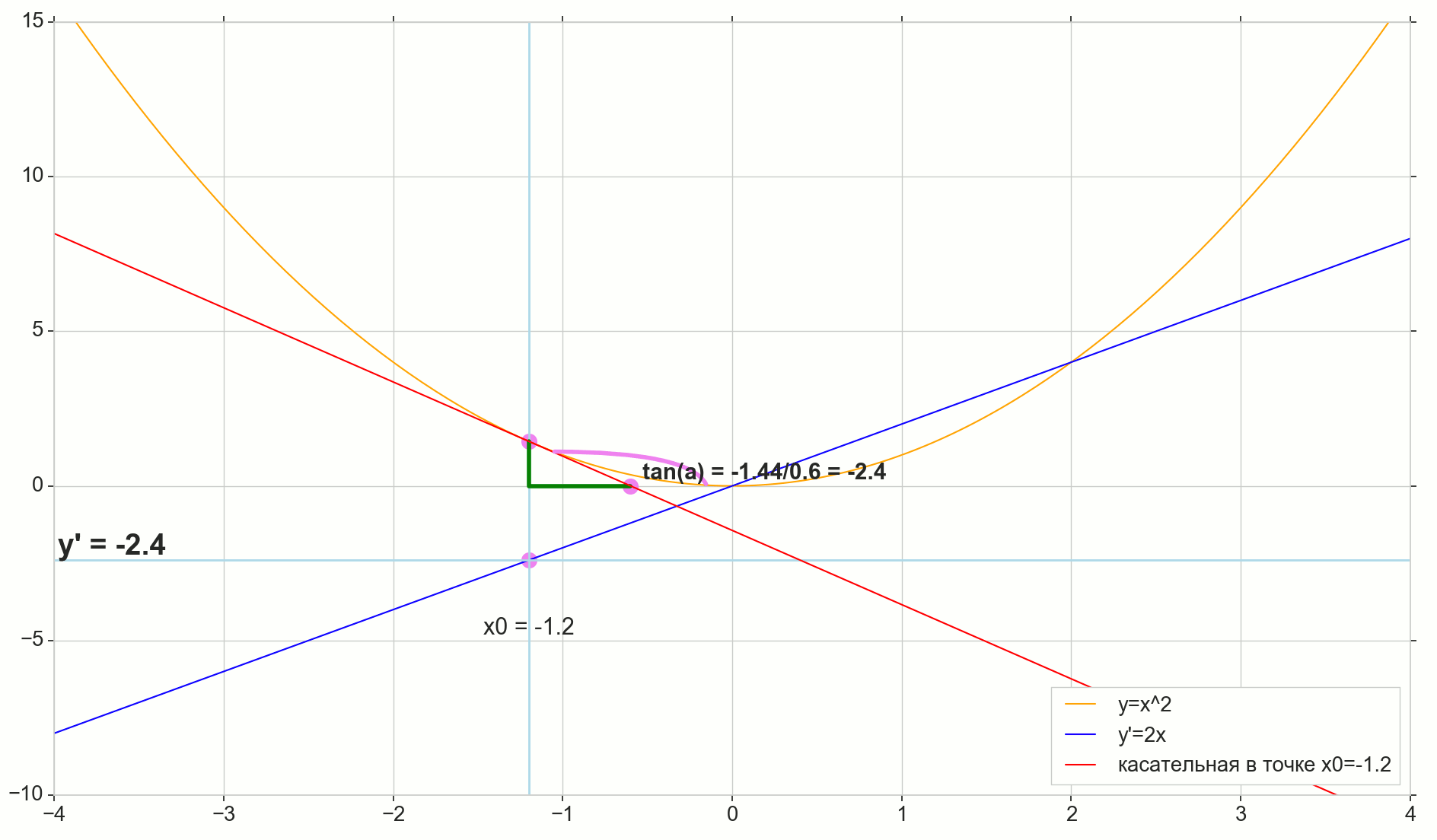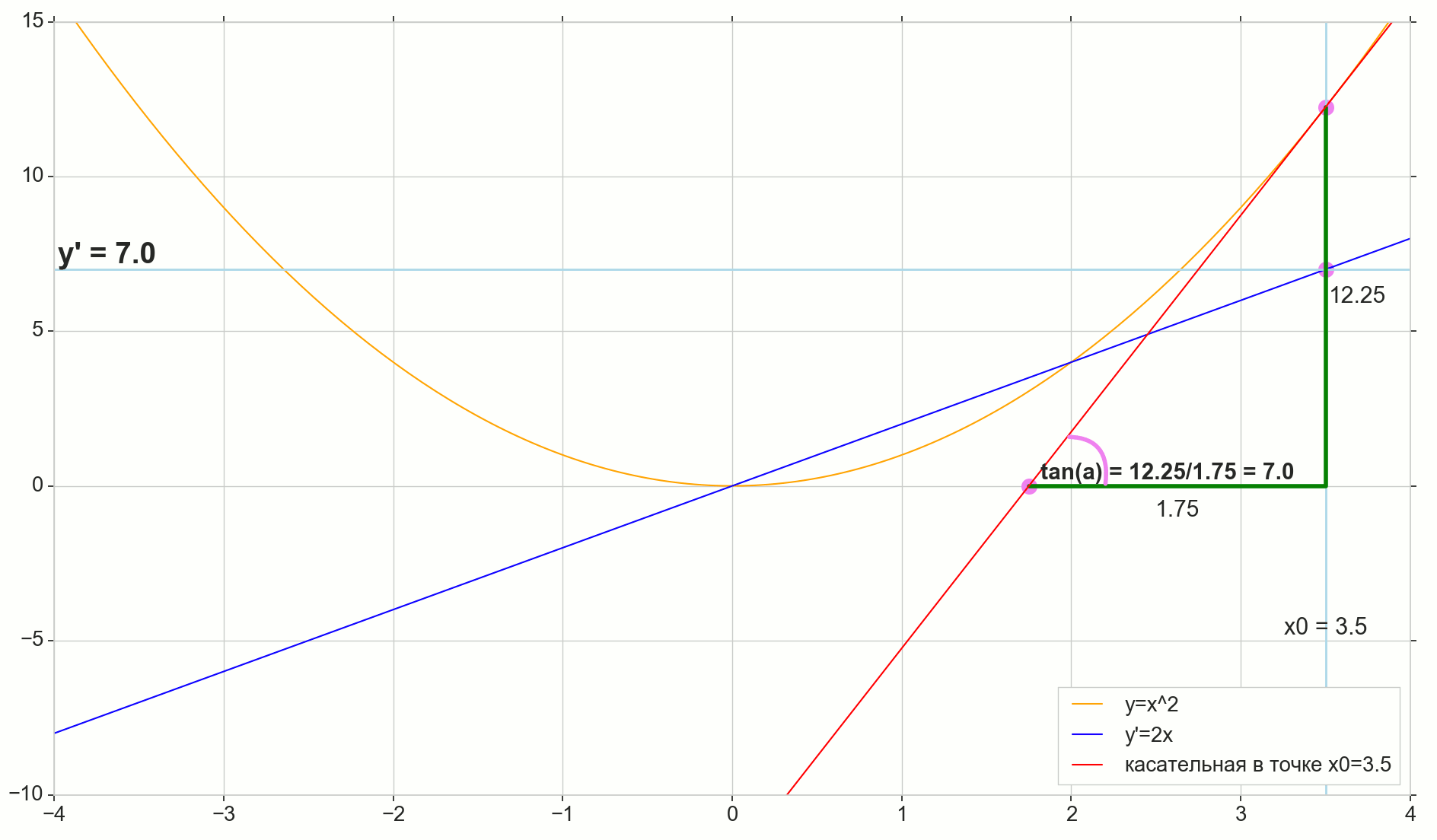
, : (), «»/«» , . — . , , ? .
J(w) . , , , .
J(w)=12SSE=12n∑i=1(m∑j=0wjx(i)j−y(i))2
∂J(w)∂wk=∂∂wk12n∑i=1(m∑j=0wjx(i)j−y(i))2=12n∑i=1∂∂wk(m∑j=0wjx(i)j−y(i))2=12n∑i=12(m∑j=0wjx(i)j−y(i))∂∂wk(m∑j=0wjx(i)j−y(i))=122n∑i=1(m∑j=0wjx(i)j−y(i))∂∂wk((w0x(i)0+...+wkx(i)k+...+wmx(i)m)−y(i))=n∑i=1(m∑j=0wjx(i)j−y(i))x(i)k
, : , , , ( ) . , wk ( , ), . , , , 1/2 SSE .
:
∂J(w)∂wk=n∑i=1(m∑j=0wjx(i)j−y(i))x(i)k
— ( ∇ [], , .. []):
∇J(w)=(∂J(w)∂w0,...,∂J(w)∂wm),w=(w0,...,wm)
:
w:=w+Δw,Δw=−η∇J(w)
k - :
wk:=wk+Δwk,Δwk=−η∂J(w)∂wk
:
, , , . , .
1- :
Φ(x,w)=w0+w1x1
( ):
∂J(w)∂w0=n∑i=1(w0+w1x(i)1−y(i))x(i)0=n∑i=1(w0+w1x(i)1−y(i))
∂J(w)∂w1=n∑i=1(w0+w1x(i)1−y(i))x(i)1
:
Δw0=−η∂J(w)∂w0=−ηn∑i=1(w0+w1x(i)1−y(i))
Δw1=−η∂J(w)∂w1=−ηn∑i=1(w0+w1x(i)1−y(i))x(i)1
, . .
( w1 )
w0=1 , J(w1)
X ( ) y w0 und w1 ( ):
def sse_(X, y, w0, w1): return ((w0+w1*X - y)**2).sum()
w1 -1.5 1.5.
, ( , , ):
plt.subplot(3,1,1)

, , δJ(w)δw1 — :
grad_w1 = [] for i in range(len(w1)): grad = ((w0 + w1[i]*X1 - y)*X1).sum() grad_w1.append(grad) plt.subplot(3,1,3) plt.plot(w1, grad_w1, label=u' ∂J(w)/∂w1') plt.xlim(-1.2, 1.2) plt.xlabel(u'w1') plt.ylabel(u'∂J(w)/∂w1') plt.legend(loc='upper left')

Δw1(w1) (, Δw1 w1 , .. , ):
eta = 0.001 delta_w1 = [] for i in range(len(w1)): grad = ((w0 + w1[i]*X1 - y)*X1).sum() delta = -eta*grad delta_w1.append(delta) plt.subplot(3,1,2) plt.plot(w1, delta_w1, color='orange', label=u'Δw1, η=%s'%eta) plt.xlim(-1.2, 1.2) plt.xlabel(u'w1') plt.ylabel(u'Δw1=-η*∂J(w)/∂w1') plt.legend(loc='upper right')

plt.show()

- : ,
- : — «» ( , «» ),
- : — ( ), η [] ( ),
: , 1000 .
, ,
w — - - . w0=1 , w1=0.9 . η=0.001 ( , ) 12:
:
w1 J(w1,w0=1) ::
Δw1(w1)
plt.scatter(w1_epochs, delta_w1_epochs, color='blue', marker='o', s=size_epochs, label=u' , η=%s'%eta) plt.plot([w1_epochs, w1_epochs], [delta_w1_epochs, np.zeros(len(delta_w1_epochs))], color='orange')

, , ( ), . , , , .
: , , , «» , — , .
- — w1 , —
- , w1
- — : , —
- , —
- , ( ), , ( ) — , —
- ( , — ).
- : — , —
- ? — . .
- . w1 , . , «»/«» . , , . , , , « ». , : w1=0.9 200, , , , 1. , , , . — η . , 200 1. η=0.001 , w1=0.9 200*0.001=0.2 ( -1, -0.2) — .
- J(w1=0.9)=92.43 , 12 (, ) J(w1=0.03)=8.54
- , ,
, . , . , ( , ). η , .
: , , , .
, , , .
η
- η [] — ()
- ,
- «»: , , ,
- , J(w)
- : wk , η , wk
η=0.01

. , . 3- , 3- , , .. , .. . , , [] .
η J(w) η

: , , . , — , , .
:

:

.
η . , , .

, .
:
, ( ) w , , . , , , . , , .
,
, .
, :

— :
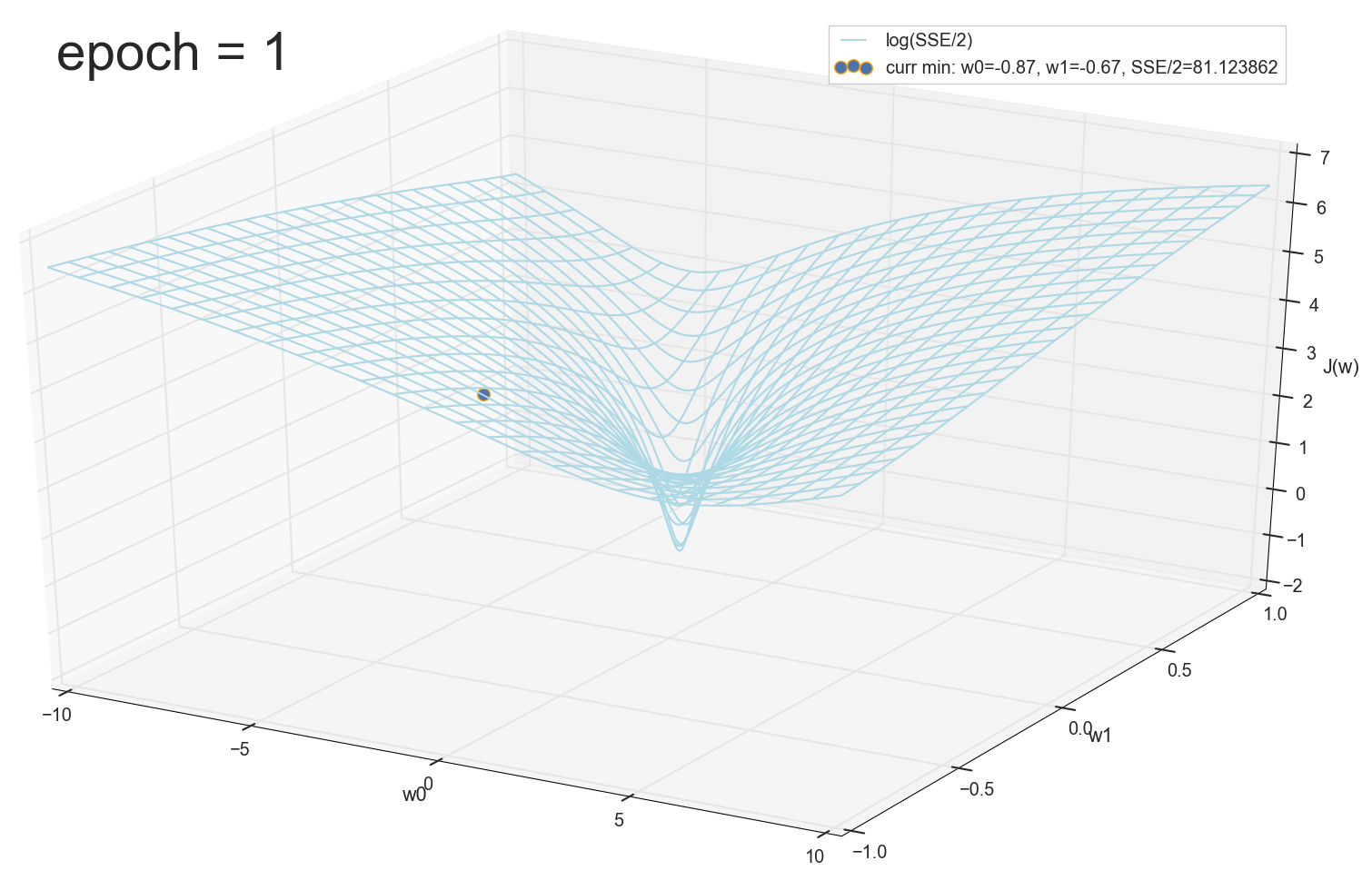
12 — , :

50 :

1767 — , :

, 62000 :

:
. , : , , . , , , , , , . , , - .
, , - , - : , , , , , — . , , , , , , , — . ?
, . :
, , ( ). : , . , , .
. , .
. , , . , — .

— :

11- : , ; :

12- : , , :

50- : , 12-

1766: . J(w)=0.3456480221 — , , ( J(w)=0.3456478372 : 6- , , )

1767: J(w)=0.34564503 — , ( 6- , ). w0=−1.184831 , w1=0.258455 ( w0 2- : w0=−1.27 , w1=0.26 )

62000: J(w)=0.3445945 — , ( 2- ). :

:
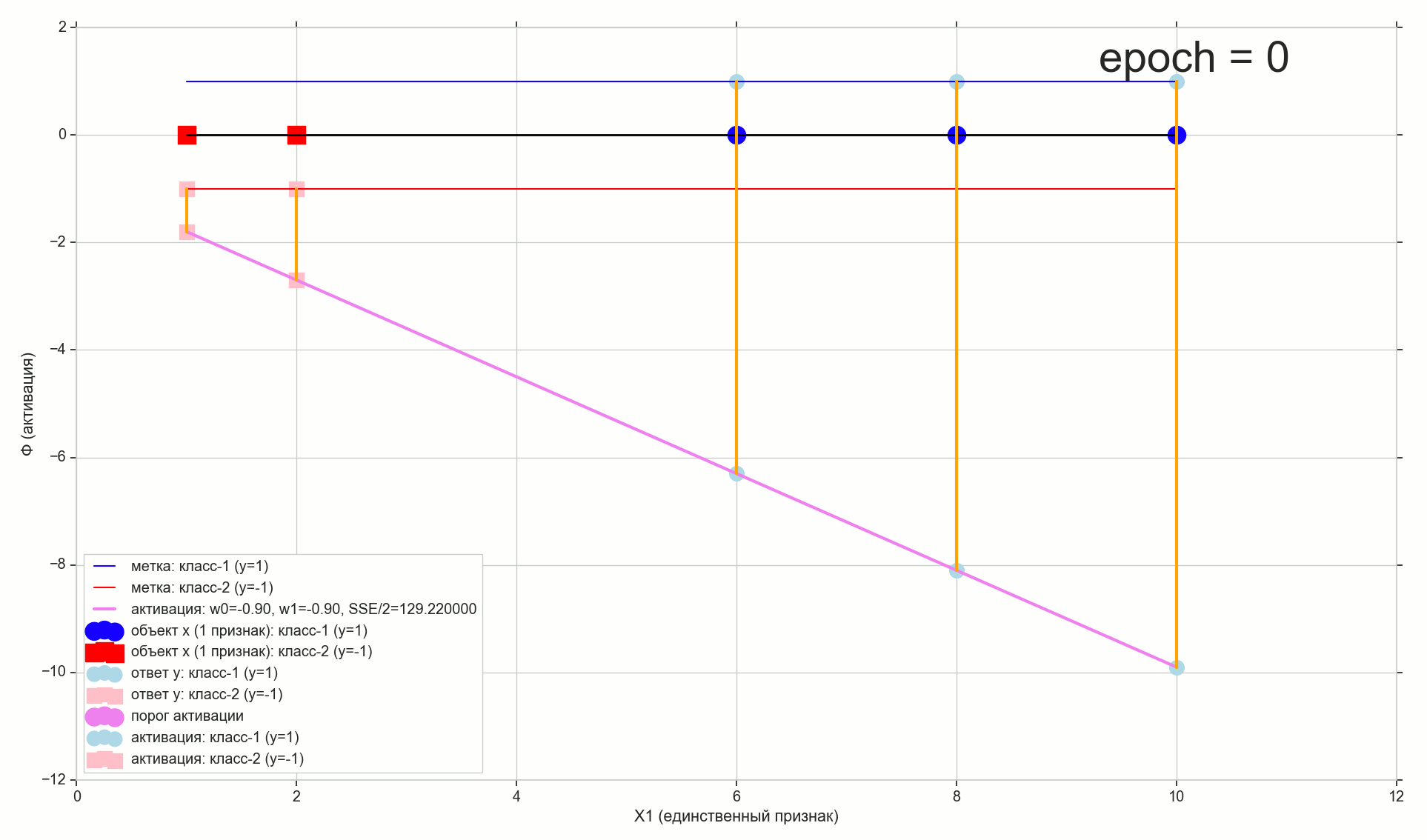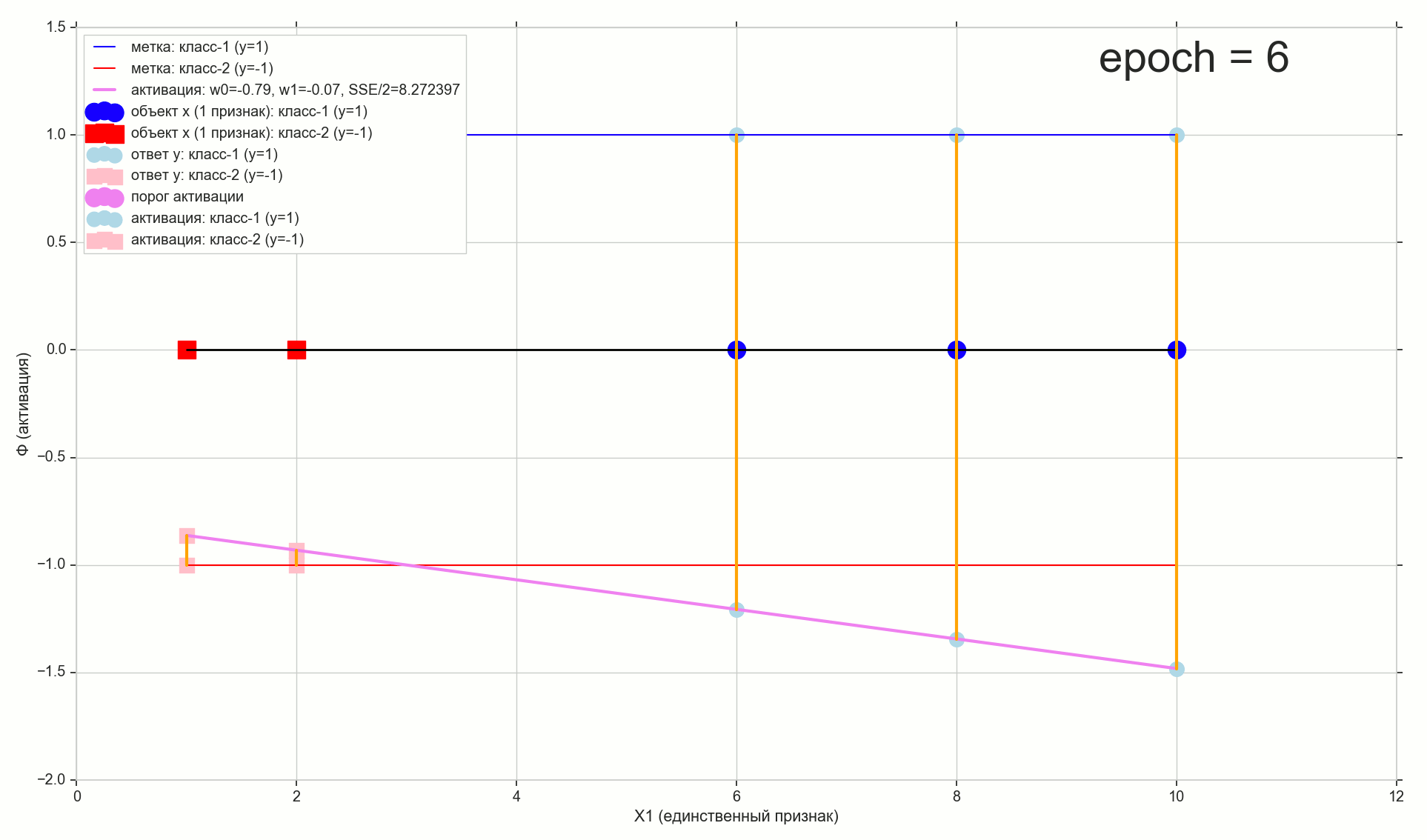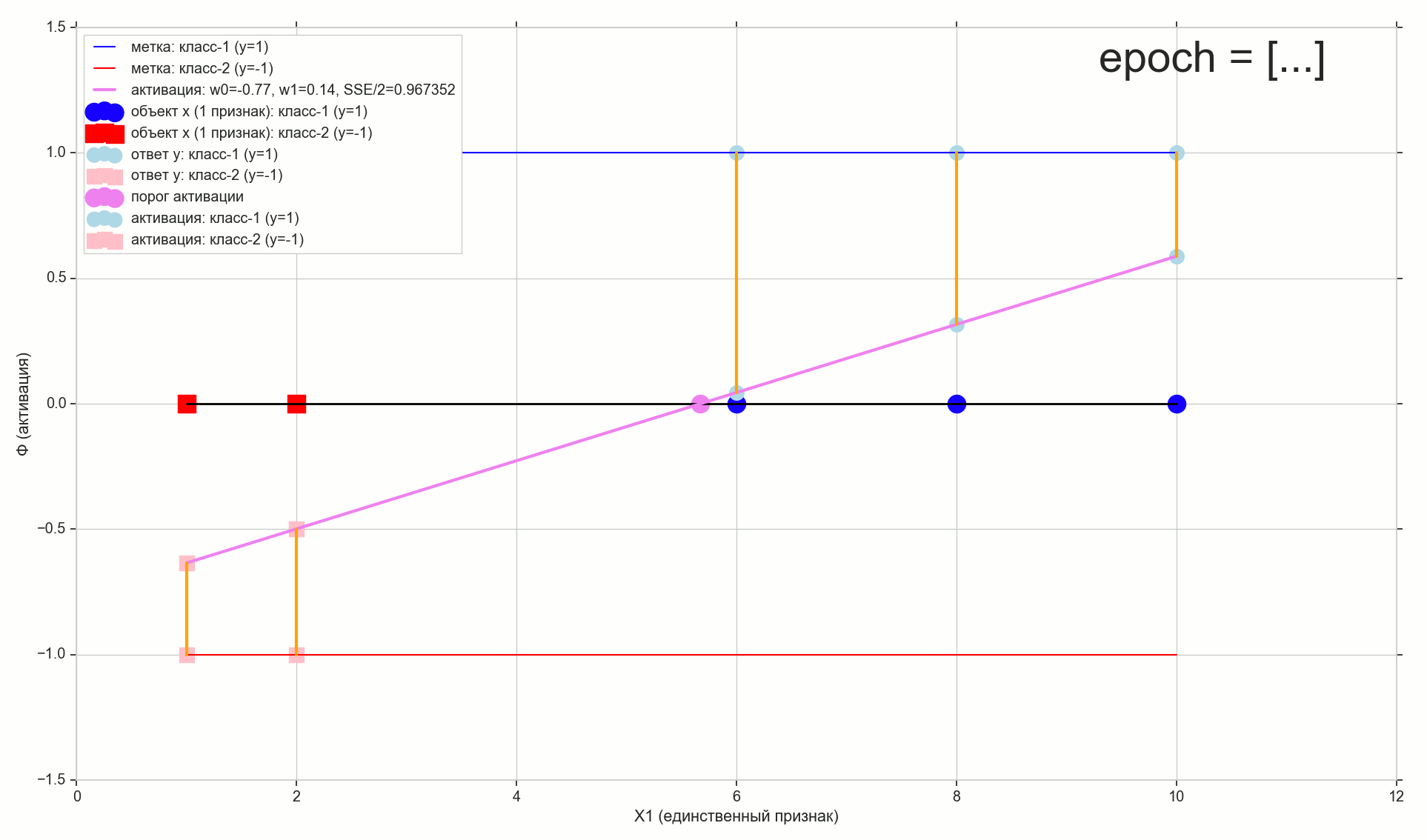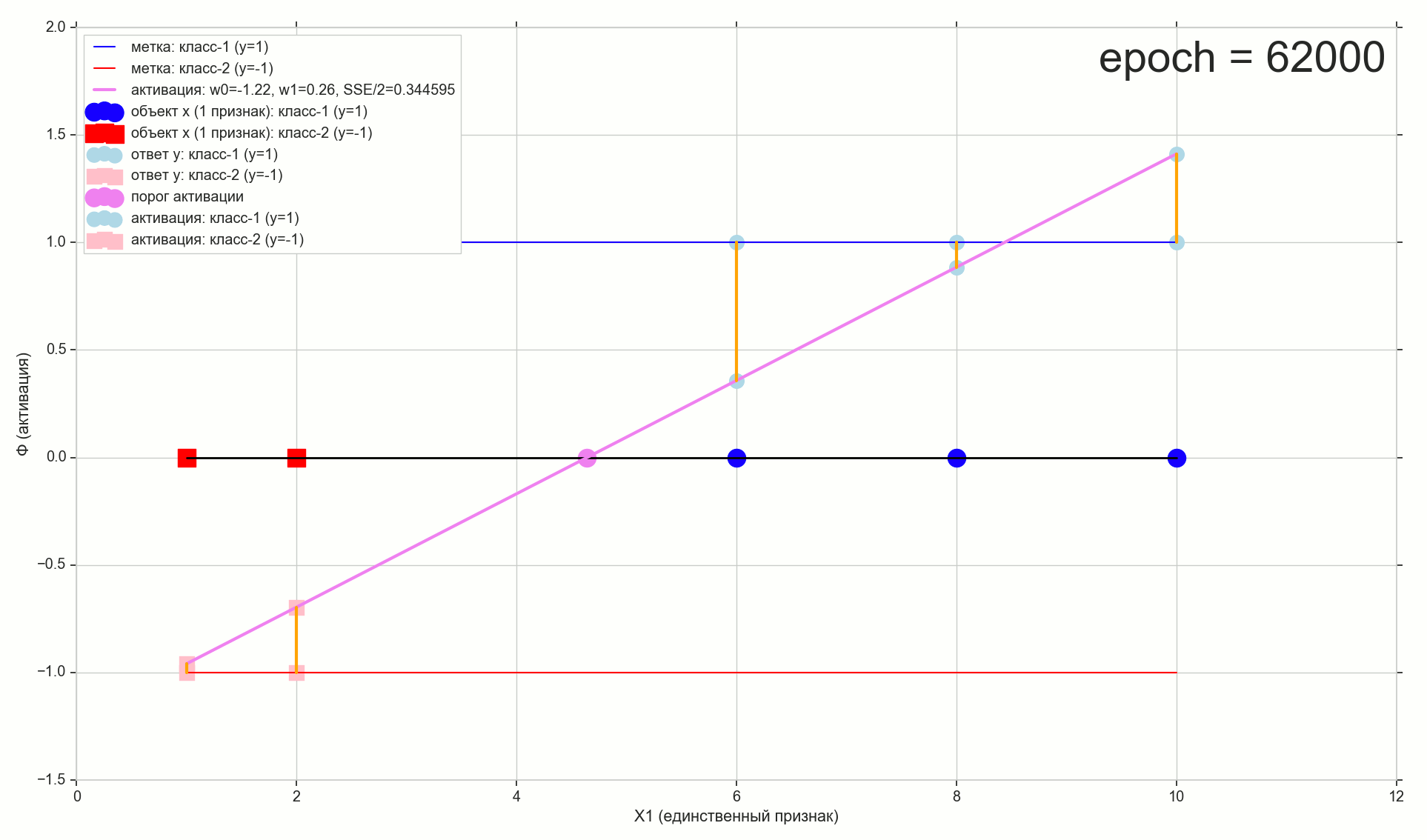
. , , , , .
- Bei η=0.001 , 10-12- ( )
- , , , (1767)
- — 60
- —
— ( , 1767): w0=−1.184831 , w1=0.258455 .
.
t(1)=(t(1)1)=(1.4) ( , t(i) — ). Aber weil , , ˆy=−1 , .. .
SUM=w0+w1∗t(1)1=−1.18+0.26∗1.4=−0.816
Φ(SUM)=SUM=−0.816
Quantisierer
Φ(SUM)=−0.816<0⟹ˆy=−1
, .
: t(2)=(t(2)1)=(7)
Φ(SUM)=SUM=−1.18+0.26∗7=0.64⩾0⟹ˆy=1
ˆy=1 , .. . .
, ( «» ) 12 . , !
(m=2)
, , , . . , , .
— ( ). 2- .
- x=(x1,x2) ( , , )
- y={−1,1} ( , )
plt.scatter(X1[y == -1], X2[y == -1], s=400, c='red', marker='*', label=u': -1') plt.scatter(X1[y == 1], X2[y == 1], s=200, c='blue', marker='s', label=u': 1')

, .
Φ(x,w)=w0+w1x1+w2x2
, — , , 1- , 3-:

:

:

— :

() Φ(w)=0 (-). :

, , , , , ( , ). , . , , m=2, (m+1)=3: , — , , — , ( ).
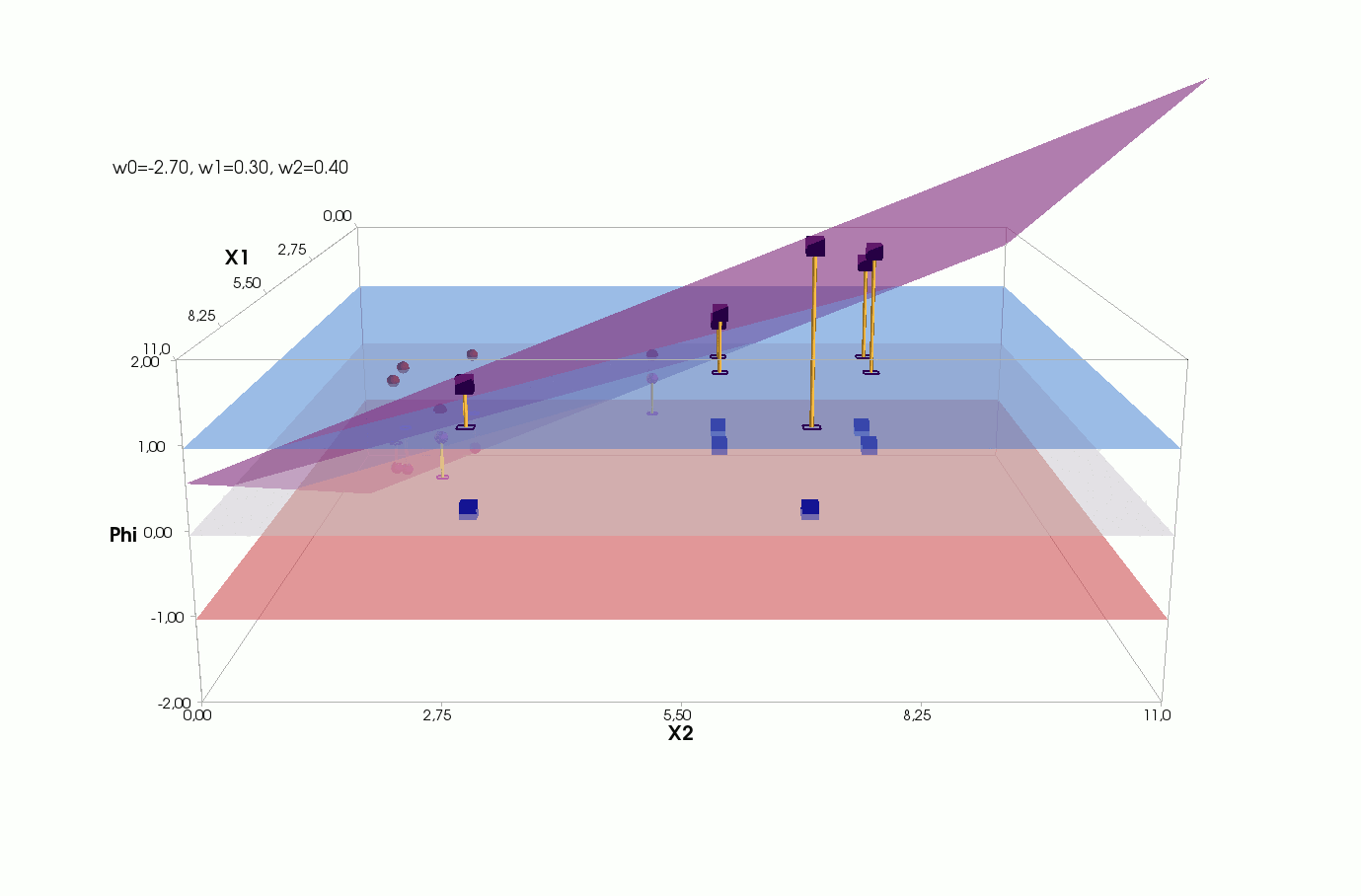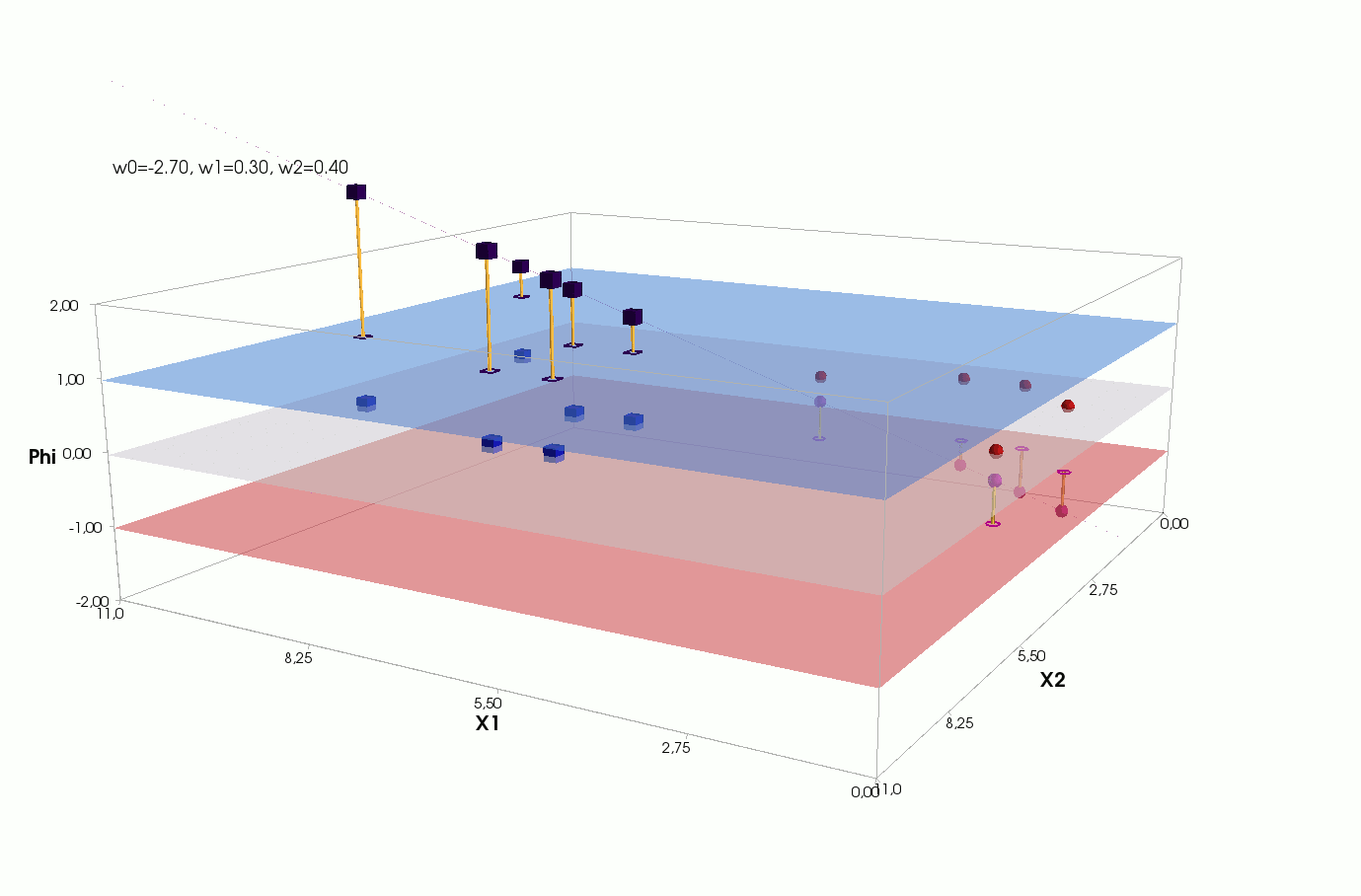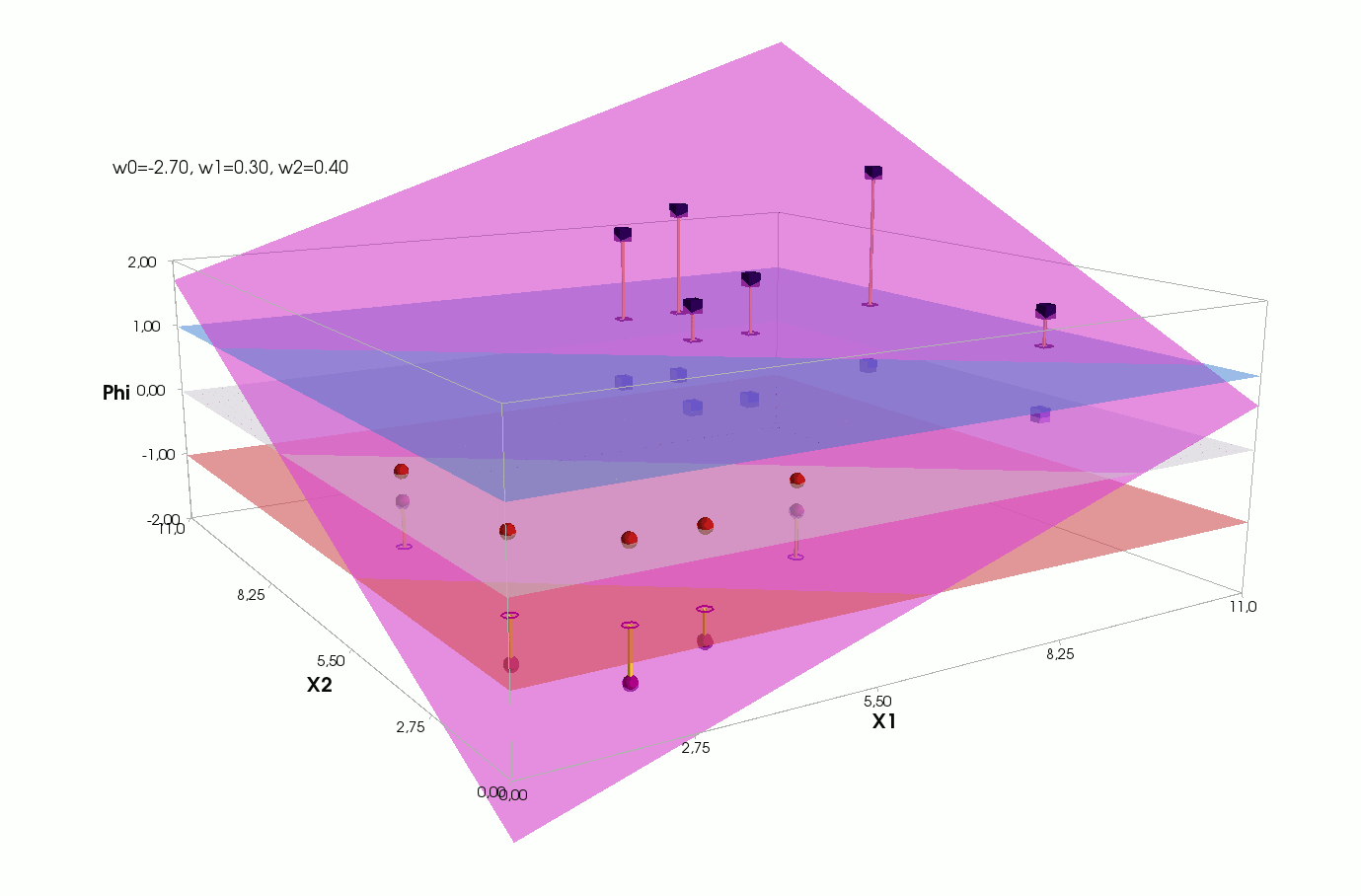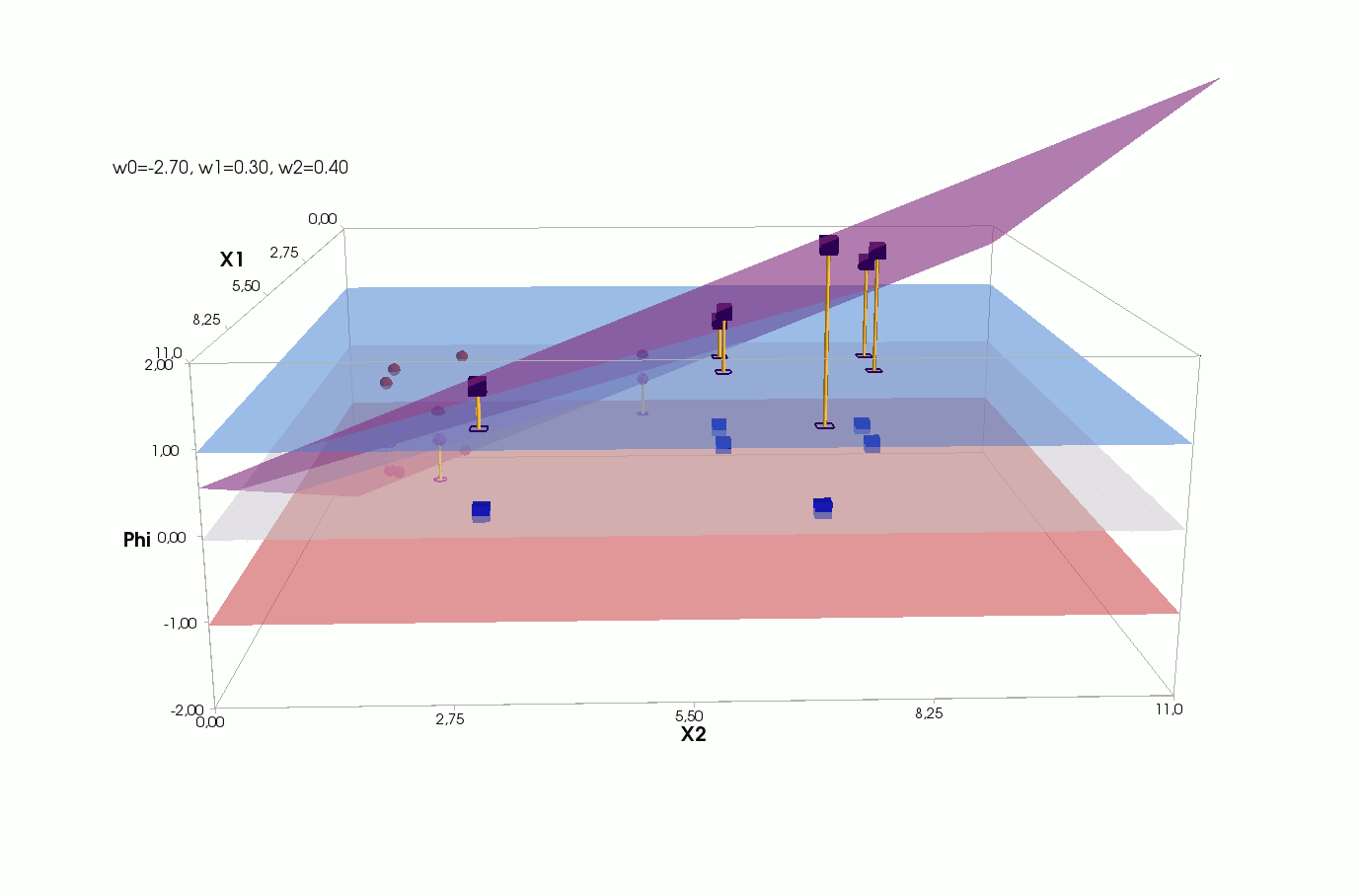
Fehler
J(w)=12SSE=12n∑i=1(w0+w1x(i)1+w2x(i)2−y(i))2
() , .., , 3 + — 4 . , 2- 3- - 3-, , - 4- 3-, .
2- . , , 1- 2-.
Farbverlauf
∇J(w)=(∂J(w)∂w0,∂J(w)∂w1,∂J(w)∂w1),w=(w0,w1,w2)
( ):
∂J(w)∂w0=n∑i=1(w0+w1x(i)1+w2x(i)2−y(i))
∂J(w)∂w1=n∑i=1(w0+w1x(i)1+w2x(i)2−y(i))x(i)1
∂J(w)∂w2=n∑i=1(w0+w1x(i)1+w2x(i)2−y(i))x(i)2
:
Δw0=−η∂J(w)∂w0=−ηn∑i=1(w0+w1x(i)1+w2x(i)2−y(i))
Δw1=−η∂J(w)∂w1=−ηn∑i=1(w0+w1x(i)1+w2x(i)2−y(i))x(i)1
Δw2=−η∂J(w)∂w2=−ηn∑i=1(w0+w1x(i)1+w2x(i)2−y(i))x(i)2
3- ( 3- ), η=0.001 , w0=−0.9 , w1=−0.9 , w2=−0.9 .
— , , :


:

:

3- - :

4- :

60- — , :

70- , , :

200- — :

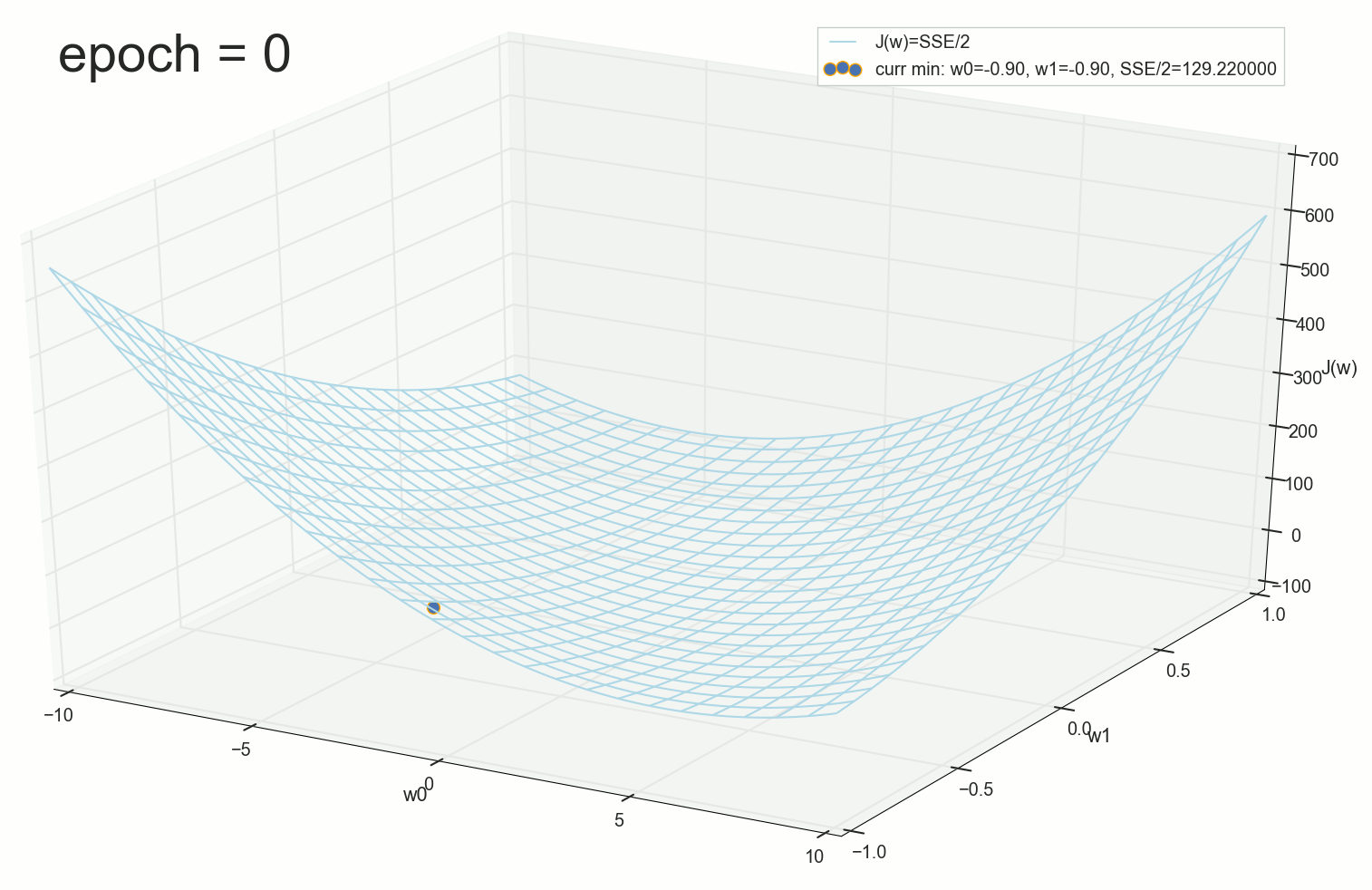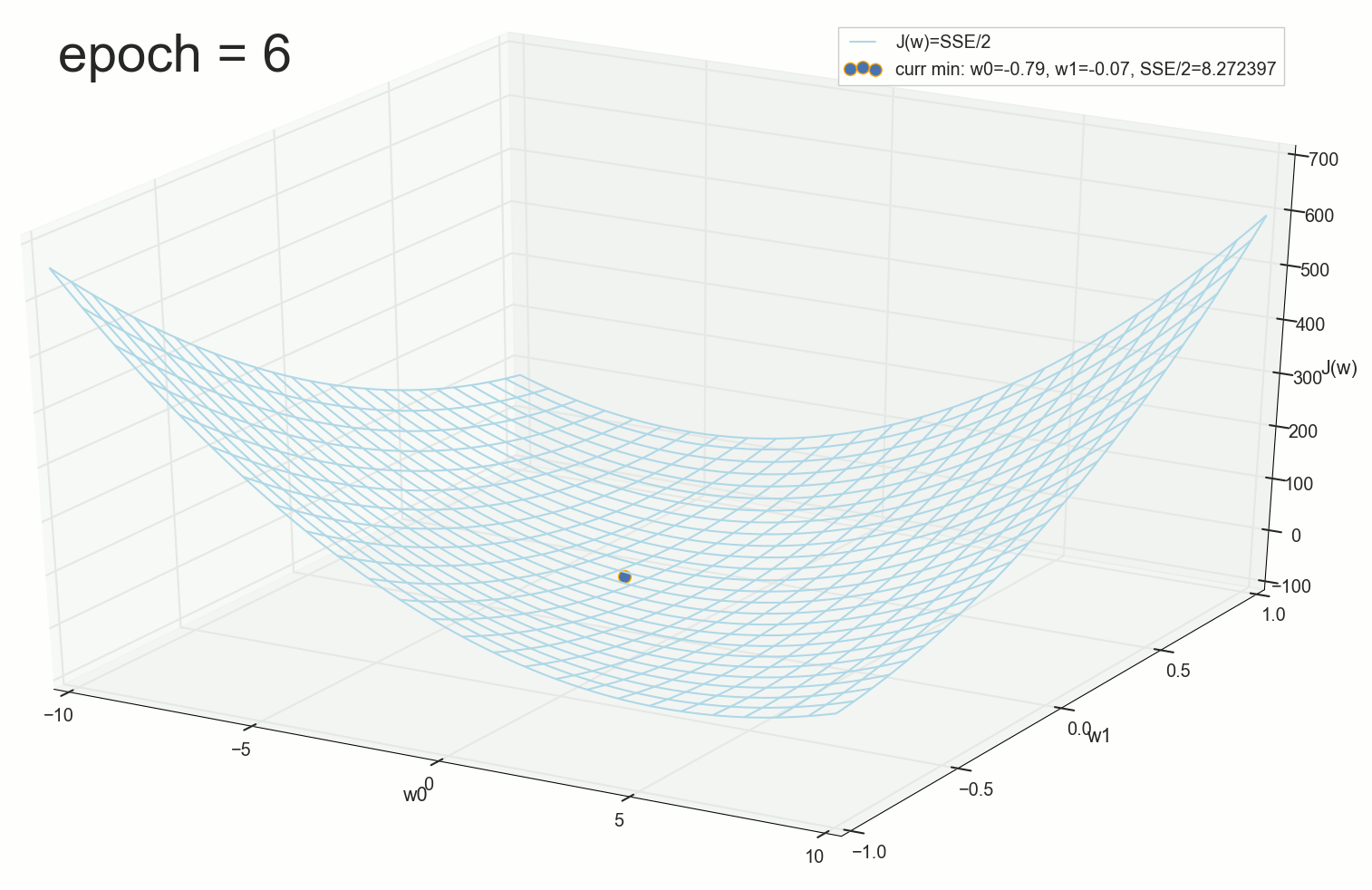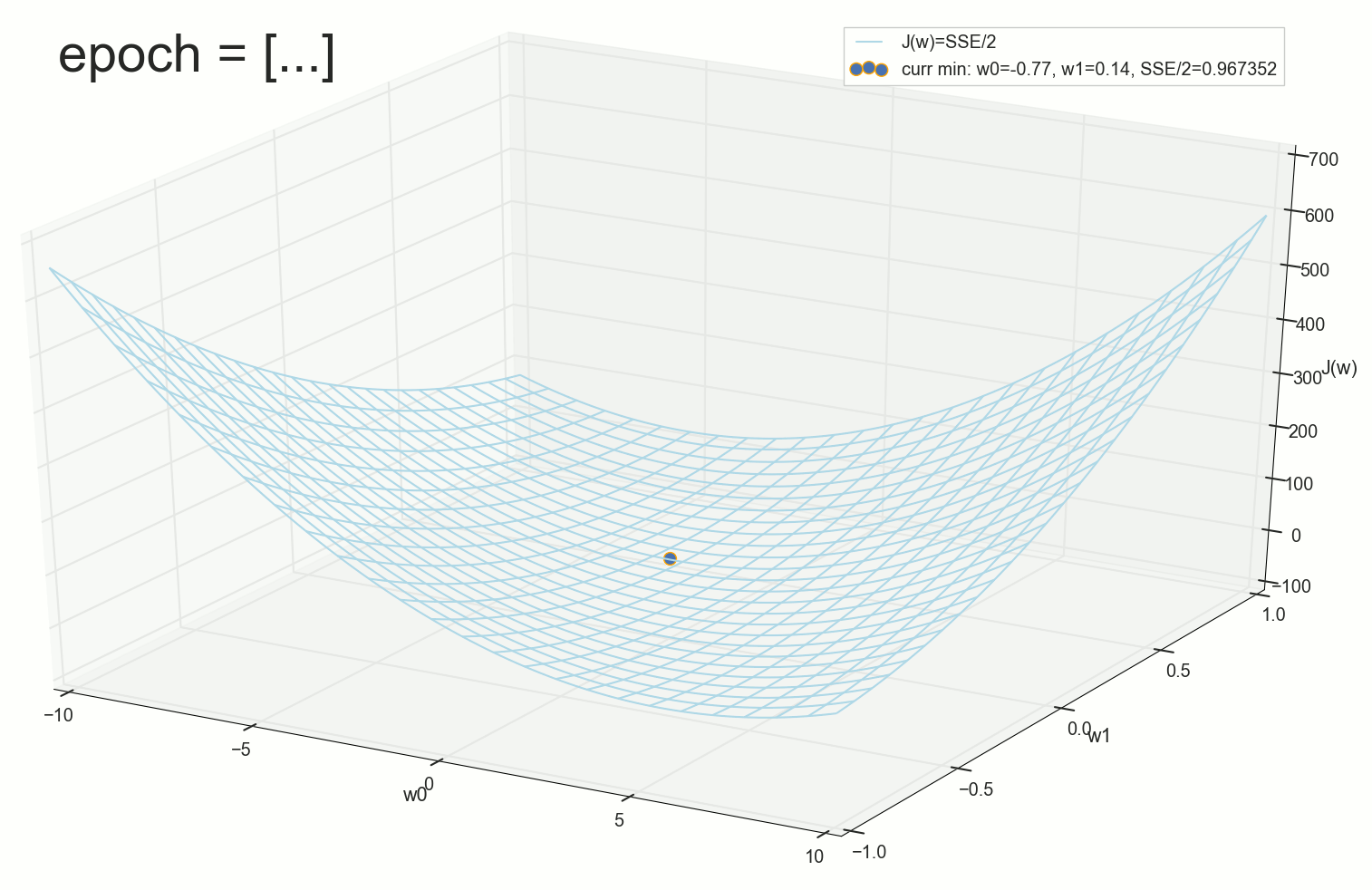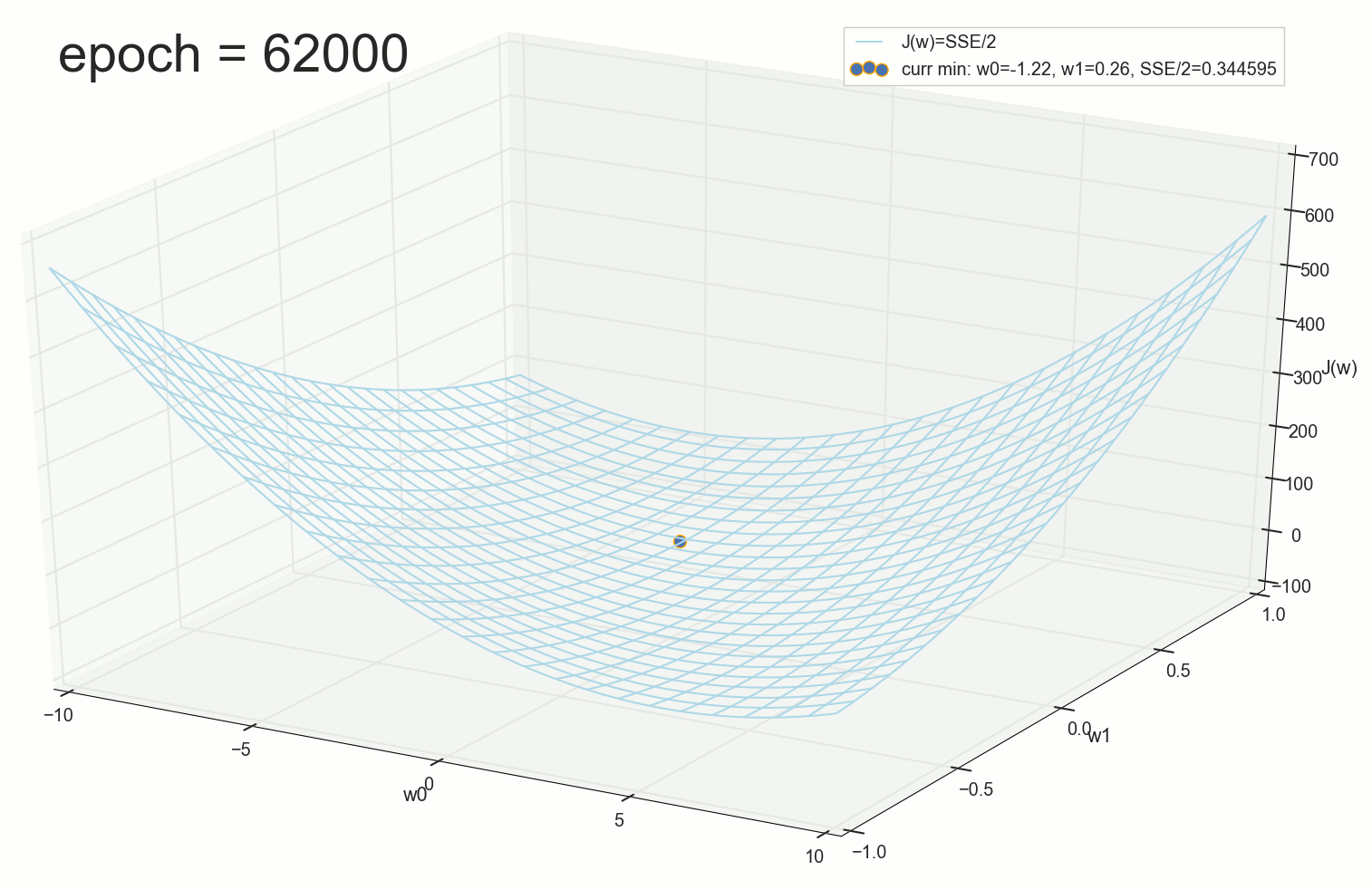
400- — :

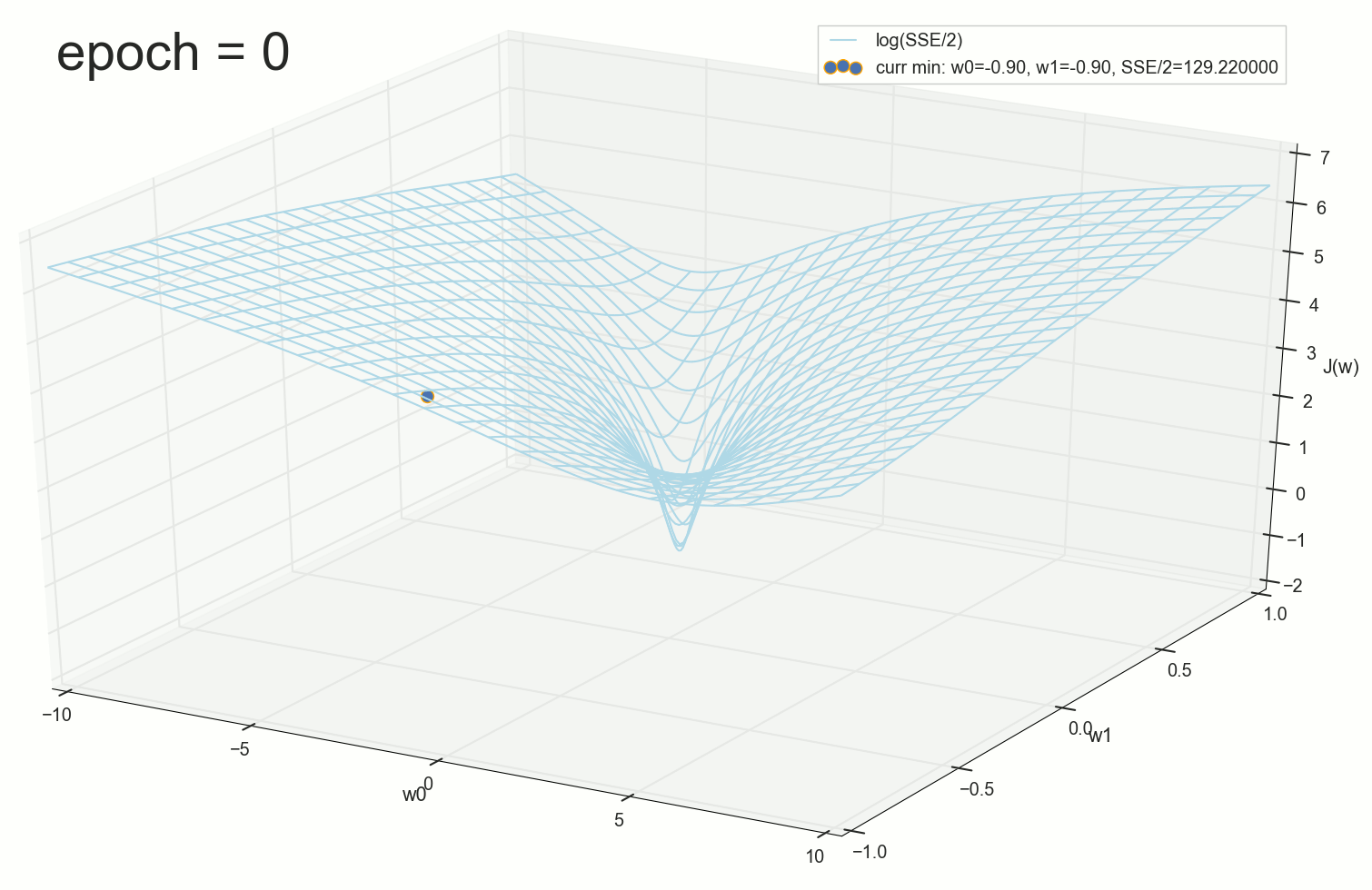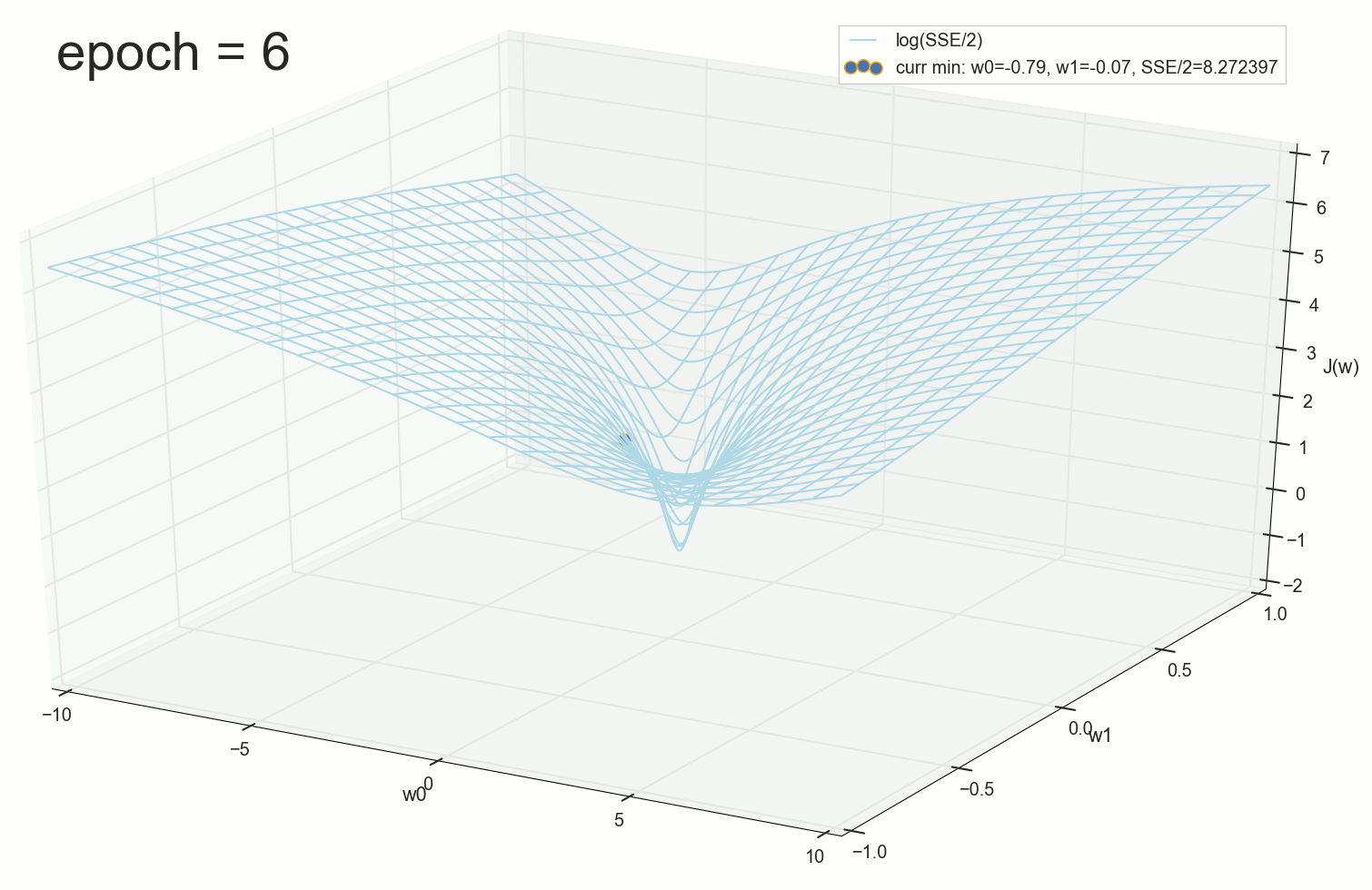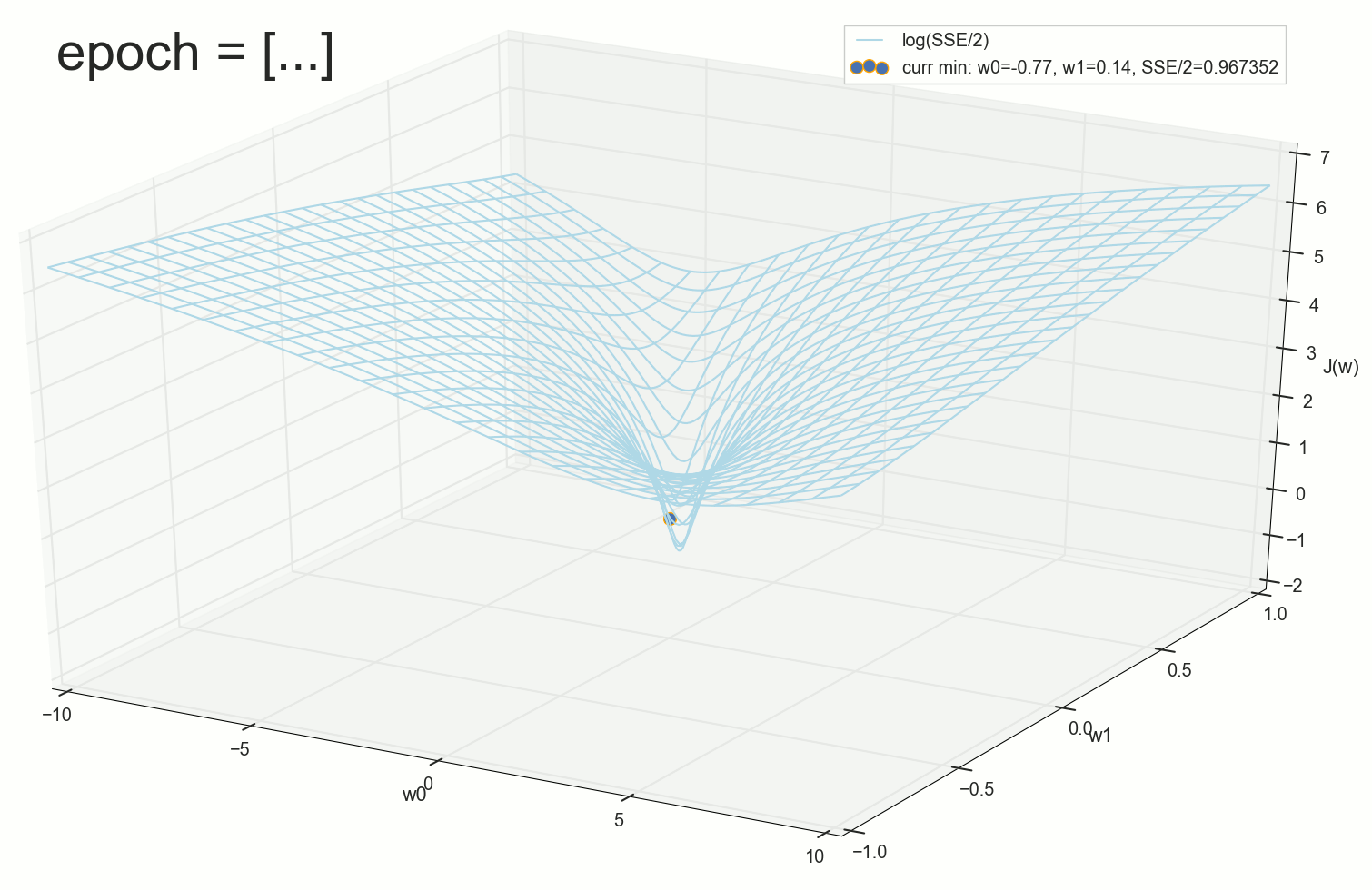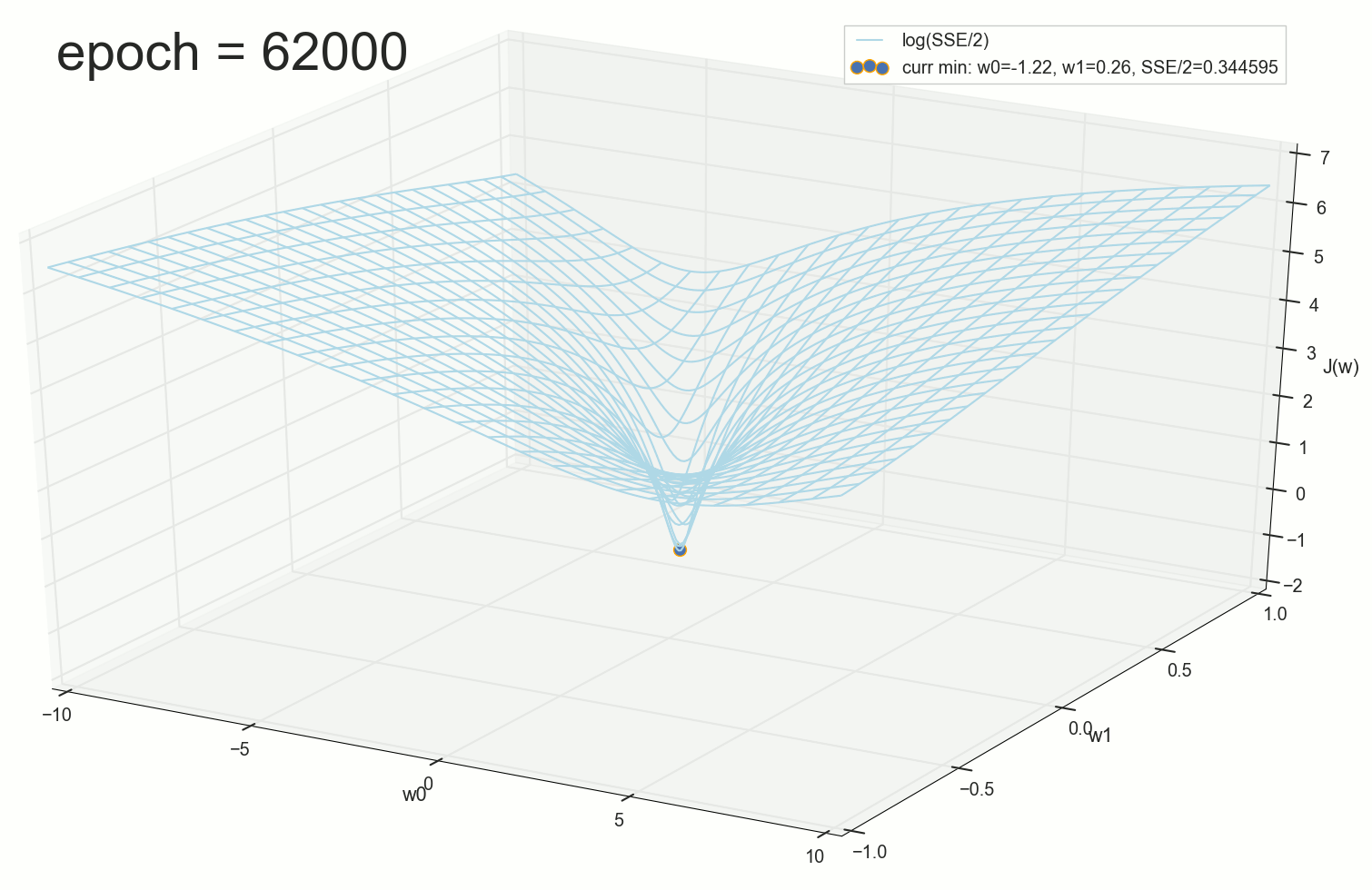
:

, , w0 .
Code
matplotlib ( mpl_toolkits.mplot3d.axis3d) ( , , 3). Mayavi .
import numpy from mayavi import mlab
, Mayavi , . , , , .
Mayavi, Matplotlib/axes3d, 3- OpenGL. , ( ) , Qt. mayavi . pip PyQt5 python-qt (, - , 'qt'). , , , , , :
env QT_API=pyqt python3 gradient-2d.py
— J(w)
def sse_(X1, X2, y, w0, w1, w2): return ((w0+w1*X1+w2*X2 - y)**2).sum()
12 :

70 :

, , : 6-12- , 70- — 70- , 30-, 40- 200-, , , , .
Fazit
ADALINE (adaptive linear neuron — ) — . scikit-learn ADALINE ( - , ) , , - « 80-» (ADALINE 60-), .
«Python » ( scikit-learn) , - .
ADALINE .
-, — , : , , , .
-, () , , , ( , , y ) — , scikit-learn.
PS , ADALINE . , , , , ADALINE - , . , ADALINE . , - .