Im
ersten Artikel der Reihe habe ich aktiv für die Idee geworben, dass die Codeentwicklung für Redd zweitrangig und das Hauptprojekt primär ist. Redd ist ein Hilfsprogramm, daher ist es falsch, viel Zeit damit zu verbringen. Das heißt, die Entwicklung dafür sollte schnell gehen. Dies bedeutet jedoch keineswegs, dass die resultierenden Programme nicht optimal sein sollten. Wenn sie überhaupt nicht optimiert sind, reicht die Leistung des Geräts nicht aus, um das gewünschte Testsystem zu implementieren. Daher sollte der Prozess, wie gesagt, schnell und einfach sein, aber der Entwickler sollte immer einige Optimierungsprinzipien berücksichtigen.
Es wurden dicke Bücher über Optimierung veröffentlicht. Einige dieser Bücher sind nützlich, andere sind bereits veraltet, da die darin beschriebenen Prinzipien beim Erstellen von Code lange Zeit in die Phase der automatischen Optimierung übergegangen sind. Es gibt jedoch einige Dinge, die bei der Entwicklung gewöhnlicher Programme für gewöhnliche Prozessoren keinen Wert haben, sodass typische Bücher normalerweise nicht beschrieben werden . Wir werden jetzt anfangen, sie zu betrachten.
Einführung
Bisher habe ich nach dem Prinzip "Ein Problem - ein Artikel" geschrieben. Und die Artikel wurden im Format von Vorlesungen erhalten, die mehrere Themen gleichzeitig betrafen und durch ein gemeinsames Problem verbunden waren. Einige Leser sagten jedoch, dass solche Artikel nicht auf einmal gelesen werden könnten. Daher werden wir jetzt versuchen, in einem Artikel nur über ein Thema zu sprechen. Es fällt mir auch leichter, so zu schreiben. Mal sehen, es wird plötzlich bequemer für alle.
Genießen Sie auch die mysteriösen Minuspunkte. Wenn ein Artikel am Morgen veröffentlicht wird, kommt das erste Minus dafür nach einer Zeitspanne an, in der es unmöglich ist, den gesamten Text zu lesen. Jemand tut dies rein prinzipiell und spart nur Themen über UDB und Balalaika. Wenn die Veröffentlichung nicht am Morgen, sondern am Nachmittag erfolgte, wirft er mit Verzögerung ein Minus. Das zweite Minus kommt tagsüber (und dieser Freund hat übrigens auch Themen über UDB und Balalaika verschont). Es wird mehr Artikel im neuen Format geben, was bedeutet, dass es für dieses Paar angenehmere Momente geben wird (obwohl es für mich als Autor persönlich traurig und beleidigend wird, wenn sie handeln).
Frühere Artikel in der Reihe:
- Entwicklung der einfachsten „Firmware“ für in Redd installierte FPGAs und Debugging am Beispiel des Speichertests.
- Entwicklung der einfachsten „Firmware“ für in Redd installierte FPGAs. Teil 2. Programmcode.
- Entwicklung eines eigenen Kerns zur Einbettung in ein FPGA-basiertes Prozessorsystem.
- Entwicklung von Programmen für den Zentralprozessor Redd am Beispiel des Zugriffs auf das FPGA.
- Die ersten Experimente am Streaming-Protokoll am Beispiel der Verbindung von CPU und Prozessor im FPGA des Redd-Komplexes.
- Merry Quartusel oder wie der Prozessor zu einem solchen Leben gekommen ist.
Geheimnisvolles Verhalten eines typischen Systems
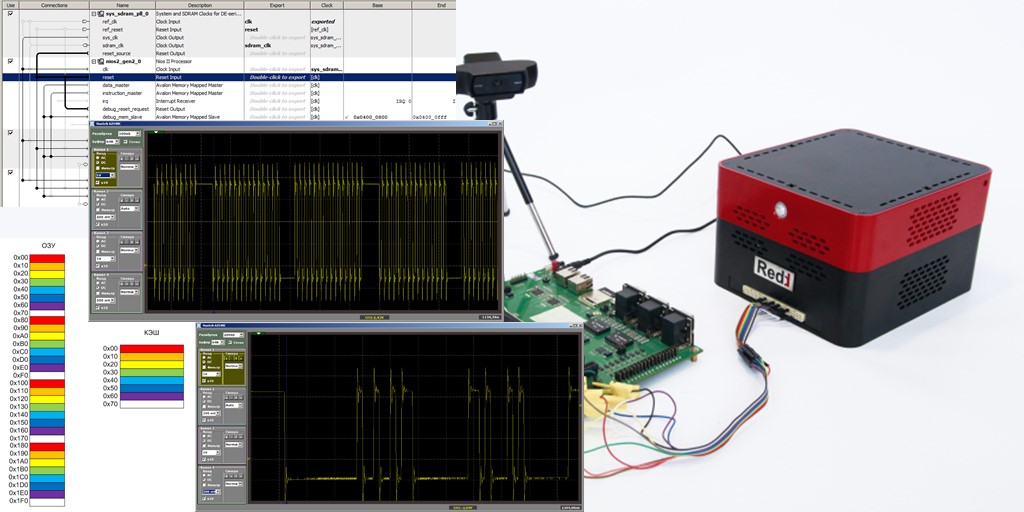
Lassen Sie uns das einfachste Prozessorsystem ausführen, indem wir einen Takt, einen Nios II / f-Prozessor, einen SDRAM-Controller und einen Ausgangsport einschließen. So spartanisch sieht dieses System in Platform Designer aus
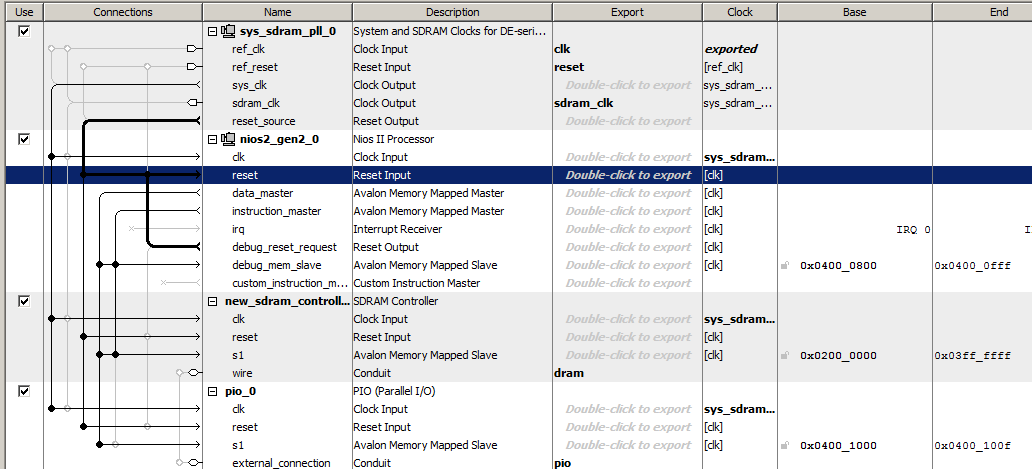
Der Programmcode dafür enthält nur eine Funktion, deren Hauptteil etwas seltsam aussieht, da er viele sich wiederholende Zeilen enthält, aber dies wird für uns nützlich sein.
Der Code ist ausgeblendet, weil er zu eng ist.extern "C" { #include "sys/alt_stdio.h" #include <system.h> #include <io.h> } void MagicFunction() { while (1) { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } } int main() { MagicFunction(); /* Event loop never exits. */ while (1); return 0; }
Setzen Sie einen Haltepunkt in die letzte Zeile:
IOWR (PIO_0_BASE,0,0);
in der
MagicFunction und führen Sie das Programm aus. Was haben wir am Ausgang des Hafens bekommen? Sehr zerlumpte Impulse:
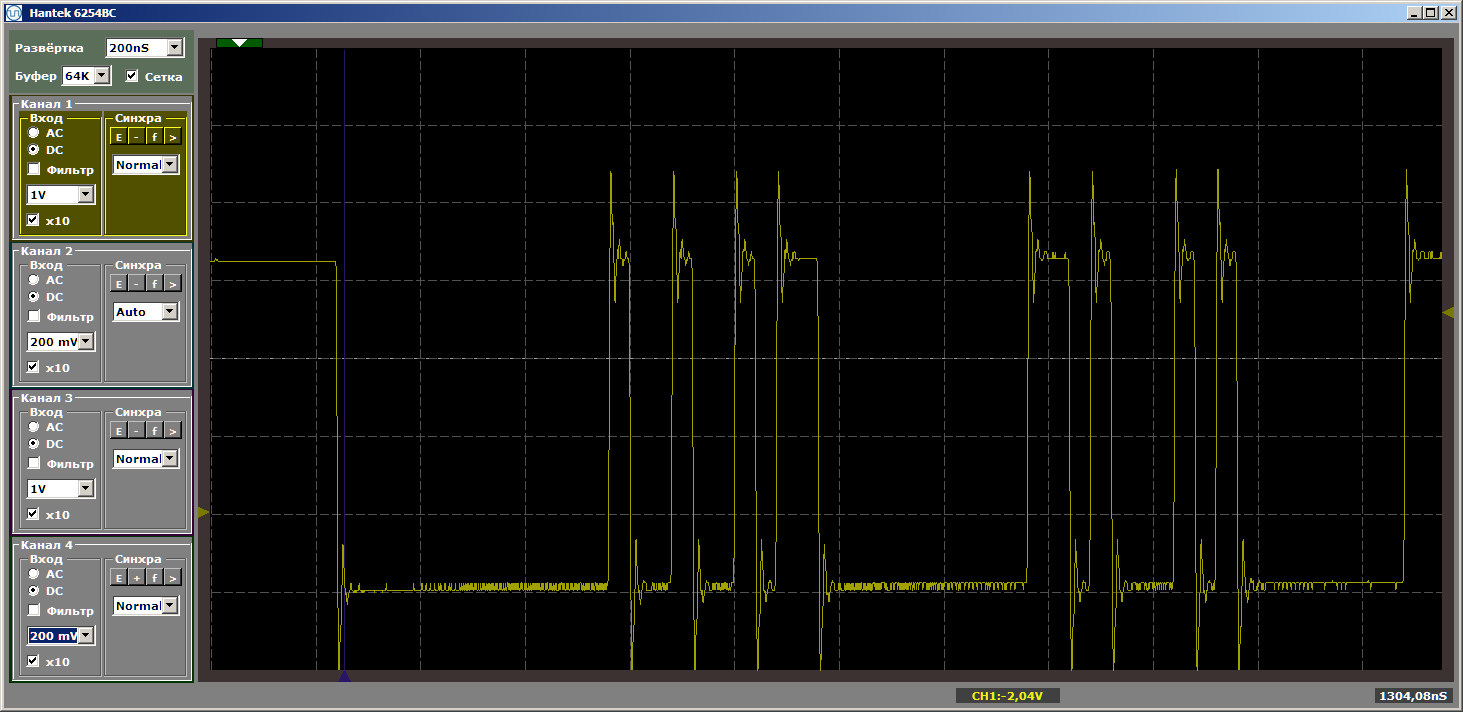
Das Grauen Na ja. Klicken Sie jedoch erneut auf "Start", um eine weitere Iteration der Schleife abzuschließen. Und jetzt sehen wir am Ausgang einen schönen glatten Mäander:
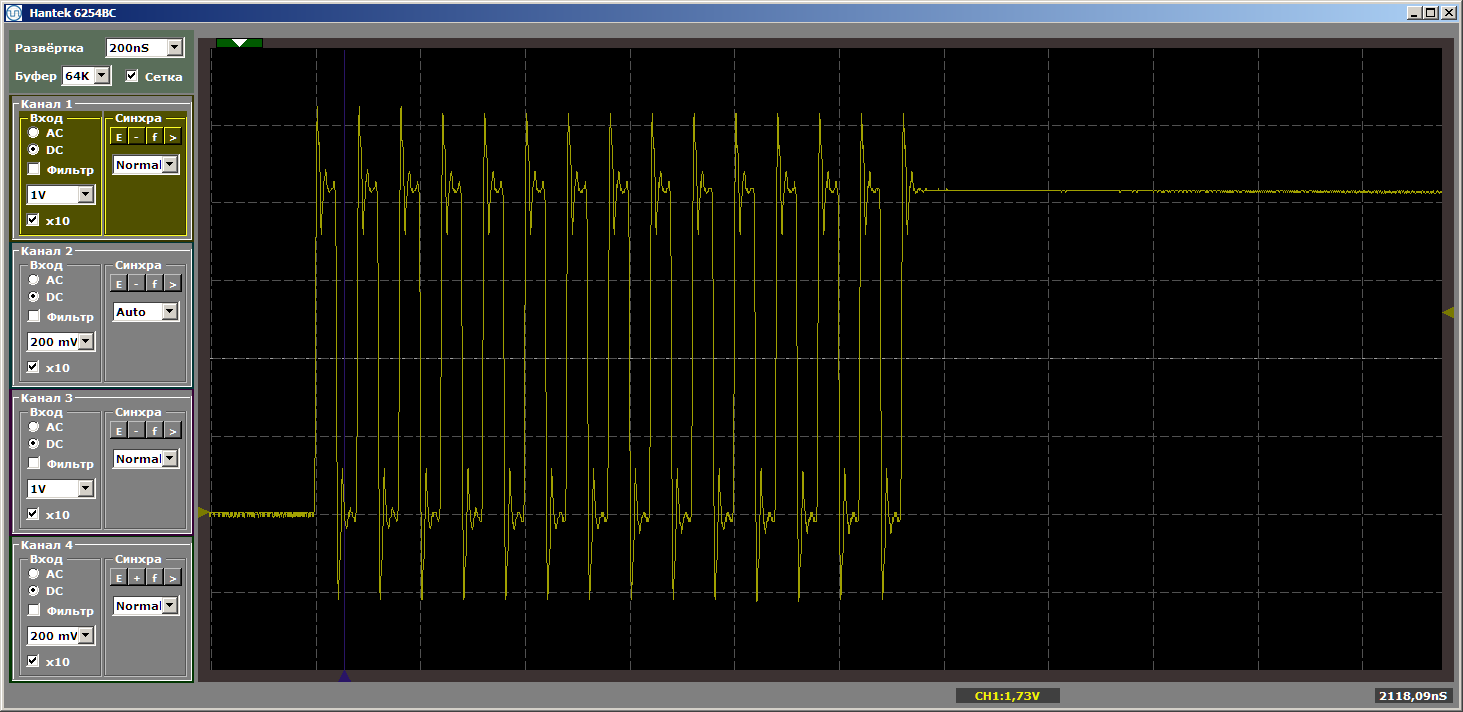
Eine weitere Iteration. Und noch einer ... Stabiler Mäander. Wir entfernen den Haltepunkt und beobachten die Arbeit in der Dynamik - es gibt keine solchen Unterbrechungen mehr. Es gibt endlose Impulsausbrüche.
Warum haben wir beim ersten Durchgang Impulse gerissen? Ein Unfall? Nein. Wir beenden das Debuggen und starten es erneut. Und wieder bekommen wir zerrissene Impulse. Lücken entstehen immer am Eingang des Programms.
Der Hinweis liegt im Cache
Tatsächlich liegt die Lösung für dieses Verhalten im Cache. Unser Programm ist im SDRAM gespeichert. Das Abrufen von Code aus dem SDRAM ist nicht schnell. Es ist notwendig, einen Lesebefehl zu geben, es ist notwendig, eine Adresse zu geben, und die Adresse besteht aus zwei Teilen. Du musst ein bisschen warten. Nur dann gibt die Mikroschaltung die Daten aus. Um solche Verzögerungen jedes Mal zu vermeiden, kann die Mikroschaltung nicht ein, sondern mehrere aufeinanderfolgende Wörter ausgeben. Wir werden Zeitdiagramme heute nicht berücksichtigen, wir werden sie für die folgenden Artikel verschieben.
Auf der Seite des Prozessorkerns wurde standardmäßig ein Cache erstellt. Hier sind seine Einstellungen:
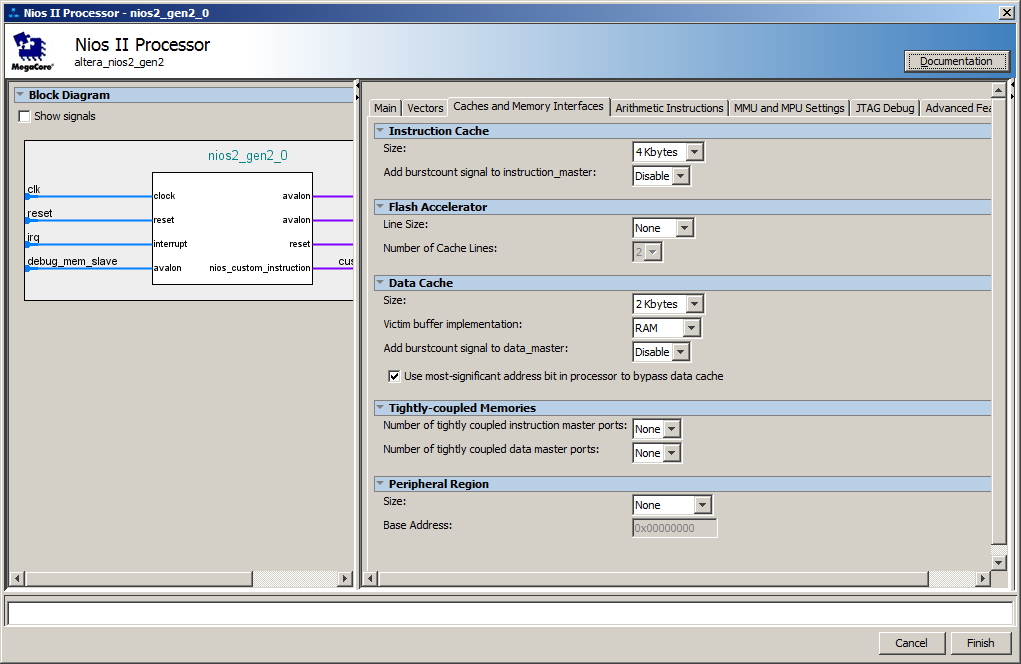
Tatsächlich treten Verzögerungen in dem Moment auf, in dem das Batch-Laden von Anweisungen vom SDRAM in den Cache ausgeführt wird. Bei den nächsten Iterationen befindet sich der Code bereits im Cache, sodass das Laden nicht mehr erforderlich ist.
Das Oszillogramm zeigt durchschnittlich 8 Einträge pro Port (eine Einheit wird viermal und null viermal geschrieben) pro Ladevorgang. Ein Datensatz - ein Assembler-Befehl, den Sie über den Menüpunkt Fenster-> Ansicht anzeigen-> Andere auswählen können:
und dann Debug-> Disassembly:
Hier sind unsere Zeichenfolgen und der entsprechende Assembler-Code:
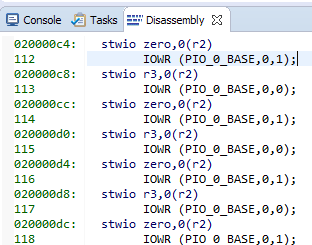
8 Teams mit jeweils 4 Bytes. Wir erhalten 32 Bytes pro Cache-Zeile ... Wir sehen uns unsere bevorzugte Hilfedatei C: \ Work \ CachePlay \ software \ CachePlay_bsp \ system.h an und sehen:
#define ALT_CPU_ICACHE_LINE_SIZE 32 #define ALT_CPU_ICACHE_LINE_SIZE_LOG2 5
Die praktisch berechneten Daten stimmten mit der Theorie überein. Darüber hinaus folgt aus der Dokumentation, dass die Größe der Zeichenfolge nicht geändert werden kann. Es ist immer gleich zweiunddreißig Bytes.
Ein etwas komplizierteres Experiment
Versuchen wir, einen Cache zu provozieren, der während der festgelegten Arbeit neu gestartet werden soll. Lassen Sie uns das Testprogramm ein wenig ändern. Wir machen zwei Funktionen und rufen sie von der
main () - Funktion aus auf und platzieren eine Schleife darin. Ich werde keinen Haltepunkt setzen. Übrigens, wenn Sie die Funktionen vollständig identisch machen, wird der Optimierer dies bemerken und eine davon entfernen, also mindestens eine Zeile, und sie sollten sich unterscheiden ... Dies ist, was ich am Anfang geschrieben habe: Optimierer sind jetzt sehr klug.
Geänderter Testprogrammcode. extern "C" { #include "sys/alt_stdio.h" #include <system.h> #include <io.h> } void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); } int main() { while (1) { MagicFunction1(); MagicFunction2(); } /* Event loop never exits. */ while (1); return 0; }
Wir erhalten ein ziemlich schönes Ergebnis, das bereits im etablierten Programmmodus aufgenommen wurde.
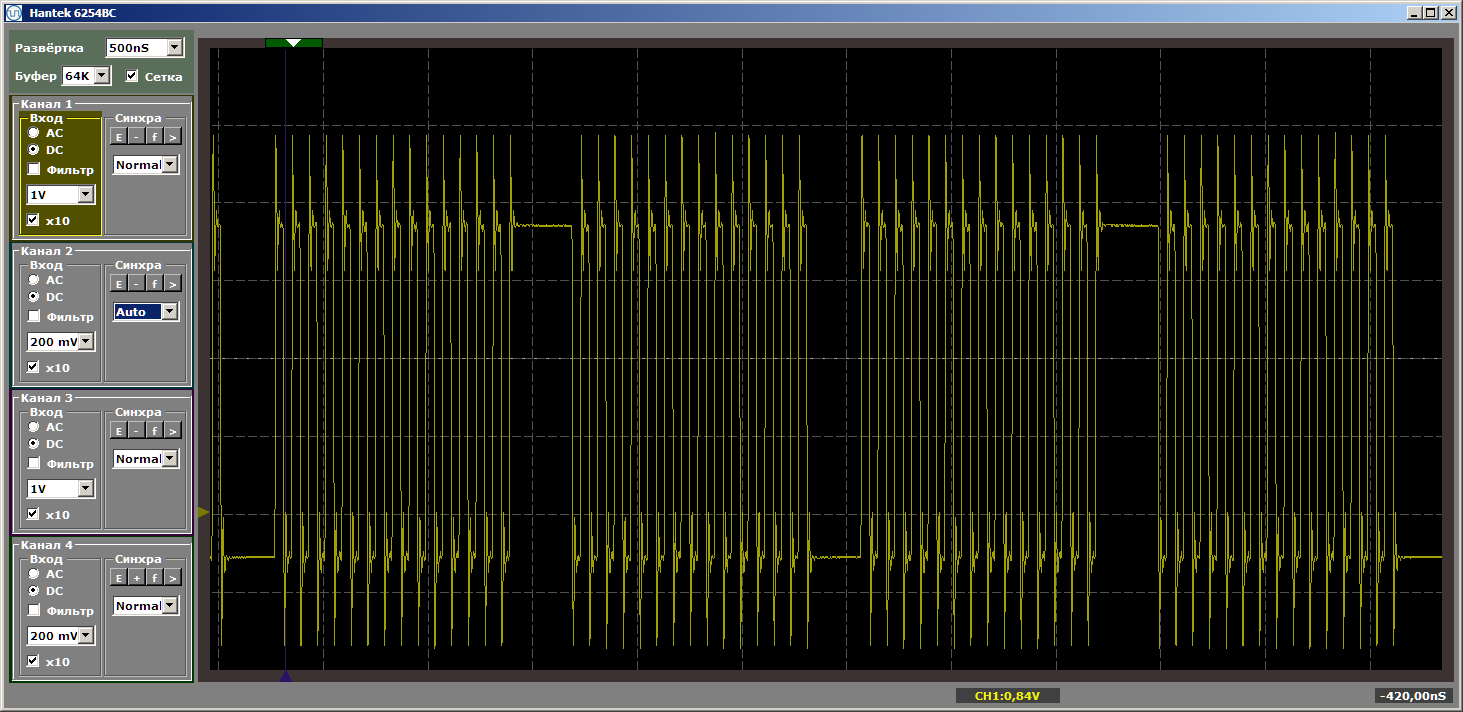
Und jetzt werden wir eine neue Funktion zwischen dieses Funktionspaar einfügen, und wir werden es nicht aufrufen, es wird nur zwischen ihnen im Speicher abgelegt. Jetzt werde ich versuchen, mehr Speicherplatz in Anspruch zu nehmen ... Der Cache hat eine Größe von 4 Kilobyte, sodass er vier Kilobyte entspricht. Fügen Sie einfach 1024 NOPs ein, von denen jede 4 Byte groß ist. Ich werde das Ende der ersten Funktion, die neue Funktion und den Anfang der zweiten zeigen, damit klar ist, wie sich das Programm ändert:
... IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } #define Nops4 __asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop"); #define Nops16 Nops4 Nops4 Nops4 Nops4 #define Nops64 Nops16 Nops16 Nops16 Nops16 #define Nops256 Nops64 Nops64 Nops64 Nops64 #define Nops1024 Nops256 Nops256 Nops256 Nops256 volatile void FuncBetween() { Nops1024 } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); ...
Die Logik des Programms hat sich nicht geändert, aber wenn es jetzt ausgeführt wird, erhalten wir zerrissene Impulse
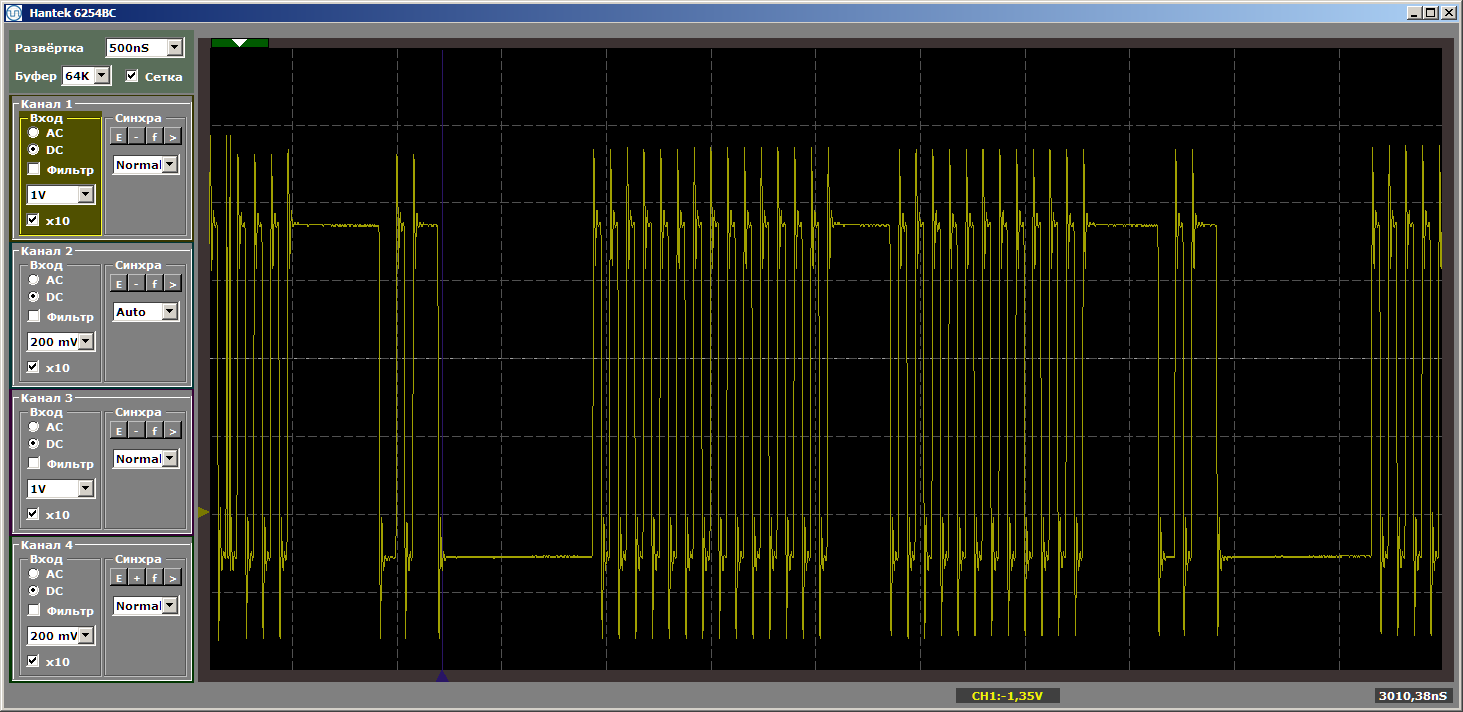
Ich werde eine naive Frage stellen: Wir sind aus dem Cache geflogen, und jetzt, wenn sich die Lücke vergrößert, wird immer geladen? Überhaupt nicht! Ändern Sie die Größe der "schlechten" Funktion so, dass sie beispielsweise fünf Kilobyte entspricht. Fünf mehr als vier, fliegen wir noch raus? Oder nicht? Ersetzen Sie den Einsatz durch:
volatile void FuncBetween() { Nops1024 Nops256 }
Und wieder bekommen wir die Schönheit:
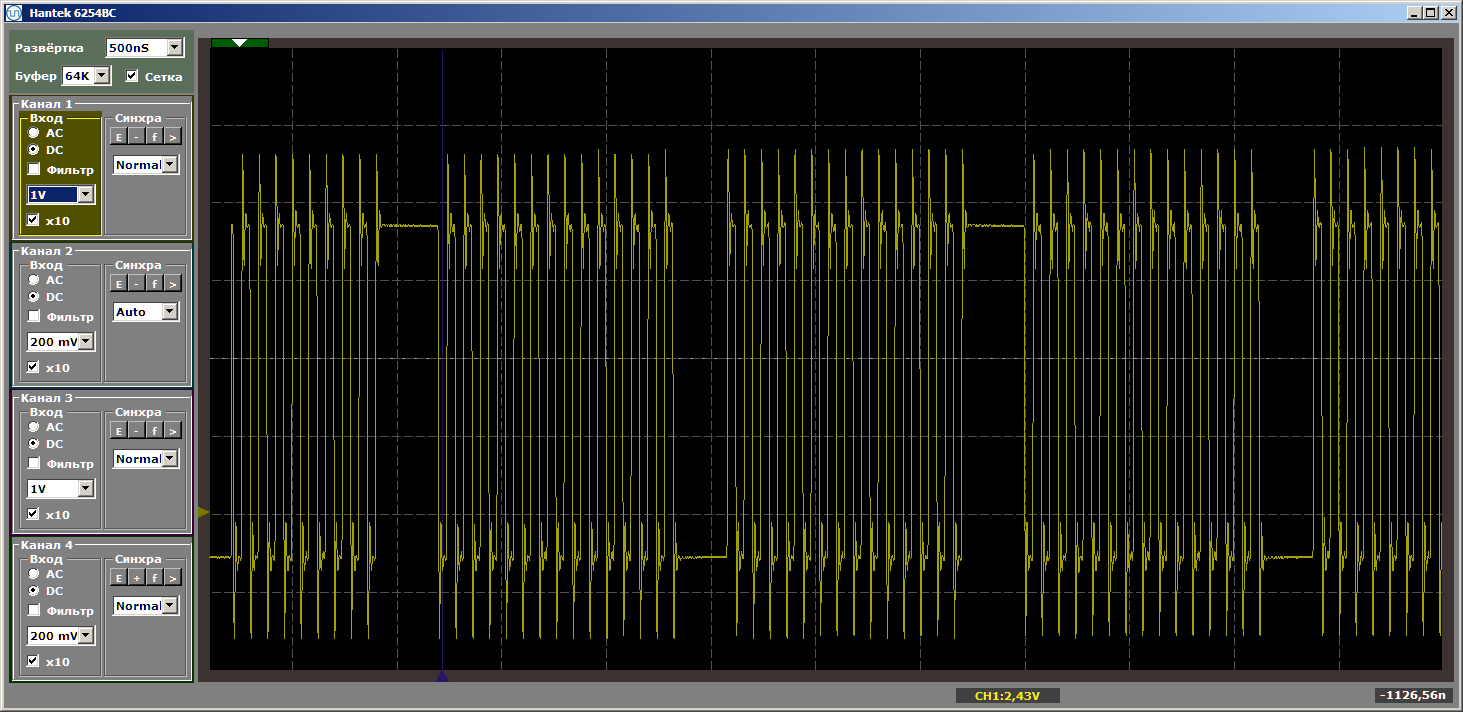
Was bestimmt also die Notwendigkeit, Code in den Cache zu laden? Können wir etwas vorhersagen oder jedes Mal müssen wir uns die Tatsache ansehen? Lassen Sie uns in die Theorie eintauchen, bei der uns das
Nios II Processor Reference Guide hilft.
Ein bisschen Theorie
So teilt sich das Adressfeld im Prozessor auf:
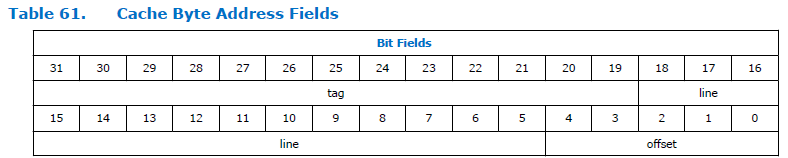
Wie Sie sehen können, ist die Adresse in drei Teile unterteilt. Tag, Linie und Offset. Die Dimension des Versatzfeldes ist für den Nios II-Prozessor konstant und beträgt immer fünf Bits, dh es können 32 Bytes adressiert werden. Die Dimension des Felds "Zeile" hängt von der Größe des Caches ab, der bei der Konfiguration des Prozessors angegeben wurde. In der obigen Abbildung ist es ziemlich groß. Ich weiß nicht, warum das Dokument eine so große Dimension hat. Wir haben eine Cache-Größe von 4 Kilobyte, was bedeutet, dass die Gesamtbittiefe und der Offset 12 Bit betragen. 5 Bits nehmen einen Offset, für eine Zeile bleiben 12-5 = 7 Bits.
Wir erhalten eine bestimmte Tabelle mit 128 Zeilen, die jeweils 32 Byte lang sind. Ich werde zum Beispiel die ersten 6 Zeilen geben:
Und so wandten wir uns an die Adresse 0x123
004 . Wenn Sie den Teil "nicht wichtig" verwerfen, ist das Paar "Linie + Versatz" 0x004. Dies ist der Nullzeilenbereich. Daten werden in diese Zeile geladen. Weitere Arbeiten mit Daten im Bereich von 0x123
000 bis 0x123
01F werden über den Cache durchgeführt. Unter welchen Bedingungen wird der String überlastet? Beim Zugriff auf eine andere Adresse, die im Bereich von 0x000 bis 0x01F endet. Wenn wir uns also an die Adresse 0xABC
204 wenden, bleibt alles an Ort und Stelle, da sich der Bereich der niedrigeren Adressen nicht mit unserem überschneidet. Und 0xABC
804 wird nichts ruinieren. Wenn der Code jedoch von der Adresse 0xABC
004 ausgeführt wird, werden neue Inhalte in die Cache-Zeile geladen. Und schon der Übergang zur Adresse 0x123
004 führt wieder zu einer Überlastung. Wenn Sie ständig zwischen 0xABC
004 und 0x123
004 wechseln, tritt kontinuierlich eine Überlastung auf.
Versuchen wir, dies in Form eines Bildes darzustellen. Angenommen, wir haben nur 8 Zeilen im Cache. Es ist bequemer, sie in verschiedenen Farben einzufärben. Wenn ich die Zeilengröße auf 0 x 10 stelle, ist es bequemer, die Adressen im Bild zu malen (denken Sie daran, dass in echten Nios II die Zeilengröße immer 0 x 20 Byte beträgt). Der Speicher schlägt auf bedingten Seiten, die dieselbe Größe wie Cache-Zeilen haben. Die rote Seite des Speichers wird immer in die rote Zeile des Caches verschoben, die orange in die orange und so weiter. Dementsprechend wird der alte Inhalt entladen.

Nun, tatsächlich ist das Verhalten des Programms während des Experiments jetzt klar. Wenn die Funktionen streng durch 4 Kilobyte getrennt waren, trafen sie Seiten mit ähnlichen Farben. Daher der Code
while (1) { MagicFunction1(); MagicFunction2(); }
führte zum Laden des Caches für eine, dann für eine andere Funktion. Und wenn der Abstand nicht 4, sondern 5 Kilobyte betrug, wurden die Funktionen in Blöcke unterschiedlicher Farben unterteilt. Es gab keinen Konflikt, alles funktionierte ohne Verzögerung.
Schlussfolgerungen
Als ich vor vielen Jahren las, dass es Linien von Cortex A-, Cortex R- und Cortex M-Kernen gibt, die für produktive Dinge, für die Arbeit in Echtzeit bzw. für die Arbeit in billigen Systemen ausgelegt sind, habe ich zunächst nicht verstanden, aber was ist tatsächlich der Unterschied? . Nein, billige Systeme sind verständlich, aber was sind die ersten beiden Unterschiede? Nachdem ich jedoch den im Cyclone V SoC FPGA verfügbaren Cortex A9-Kern gespielt hatte, spürte ich alle Nachteile des Caches bei der Arbeit mit Eisen. Es gibt viele Caches im Kern von Cortex A ... und die Vorhersagbarkeit des Systemverhaltens ist nahezu Null. Der Cache verbessert jedoch die Leistung. Manchmal ist es besser, wenn alles nicht vorhersehbar genau im Takt arbeitet, sondern schnell als vorhersehbar langsam. Dies gilt insbesondere für das Rechnen oder Anzeigen von Grafiken.
Das Hauptproblem besteht jedoch nicht darin, dass die im Artikel beschriebenen Dinge auftreten, sondern dass sich das Verhalten des Systems von Baugruppe zu Baugruppe ändert, da niemand weiß, welche Adressen die Funktion nach dem Hinzufügen oder Entfernen von Code verlieren wird. Vor 15 Jahren mussten wir im Projekt des Sega-Spielekonsolen-Emulators für einen Kabelfernsehdecoder einen ganzen Präprozessor herstellen, der nach jeder Bearbeitung Funktionen, die Motorola-Assembler-Befehle auf dem SPARC-8-Kern emulierten, so verschob, dass ihre Ausführungszeit immer gleich war (dort) aufgrund des Caches schwamm sonst alles viel).
Aber wann brauchen wir Vorhersehbarkeit? Natürlich während der programmgesteuerten Erstellung von Zeitdiagrammen (denken Sie daran, dass es in FPGAs im Allgemeinen möglich ist, dies auch den Geräten anzuvertrauen, aber es gibt einige Details mit schneller Entwicklung). Bei der Arbeit mit Rechenalgorithmen ist dies jedoch nicht so wichtig. Sofern der Algorithmus nicht komplex ist, müssen Sie sicherstellen, dass kritische Abschnitte keine konstante Cache-Überlastung verursachen. In den meisten Fällen verursacht der Cache keine Probleme und die Produktivität steigt.
Im nächsten Artikel werden wir uns ansehen, wie kritische Funktionen in nicht zwischenspeicherbaren Speichern vorhergesagt werden können, die immer mit maximaler Geschwindigkeit ausgeführt werden, und die impliziten Vorteile von FPGAs gegenüber Standardsystemen diskutieren, die sich aus den in diesem Prozess verwendeten Technologien ergeben.
Für die aufmerksamsten
Ein ätzender Leser könnte fragen: "Warum wurde das Oszillogramm beim Einfügen von vier Kilobyte Code nicht ausreichend zerrissen?" Alles ist einfach. Wenn Sie genau 4 Kilobyte einfügen, erhalten wir die folgenden Adressen zum Platzieren von Funktionen im Speicher:
MagicFunction1(): 0200006c: movhi r2,1024 02000070: movi r4,1 02000074: addi r2,r2,4096 02000078: stwio r4,0(r2) 92 IOWR (PIO_0_BASE,0,0); 0200007c: mov r3,zero 02000080: stwio r3,0(r2) 93 IOWR (PIO_0_BASE,0,1); ... 120 IOWR (PIO_0_BASE,0,0); 020000f0: stwio r3,0(r2) 020000f4: ret 131 Nops1024 FuncBetween(): 020000f8: nop 020000fc: nop 02000100: nop 02000104: nop ... 020010ec: nop 020010f0: nop 020010f4: nop 020010f8: ret 135 IOWR (PIO_0_BASE,0,0); MagicFunction2(): 020010fc: movhi r2,1024 02001100: mov r4,zero 02001104: addi r2,r2,4096
Für eine vollkommen schlechte Wellenform müssen Sie NOPs einfügen, sodass 4 Kilobyte ihr Volumen zusammen mit der Länge der
MagicFunction1 () -Funktion sind. Egal was Sie für ein schönes Bild gehen! Ändern Sie den Einsatz in diesen:
volatile void FuncBetween() { Nops256 Nops256 Nops256 Nops64 Nops64 Nops64 Nops16 Nops16 }
Immer wieder achte ich darauf, dass der Einsatz keine Kontrolle erhält. Es ändert einfach die Position der Funktionen im Speicher relativ zueinander. Mit dieser Beilage bekommen wir den gewünschten schrecklichen Horror:
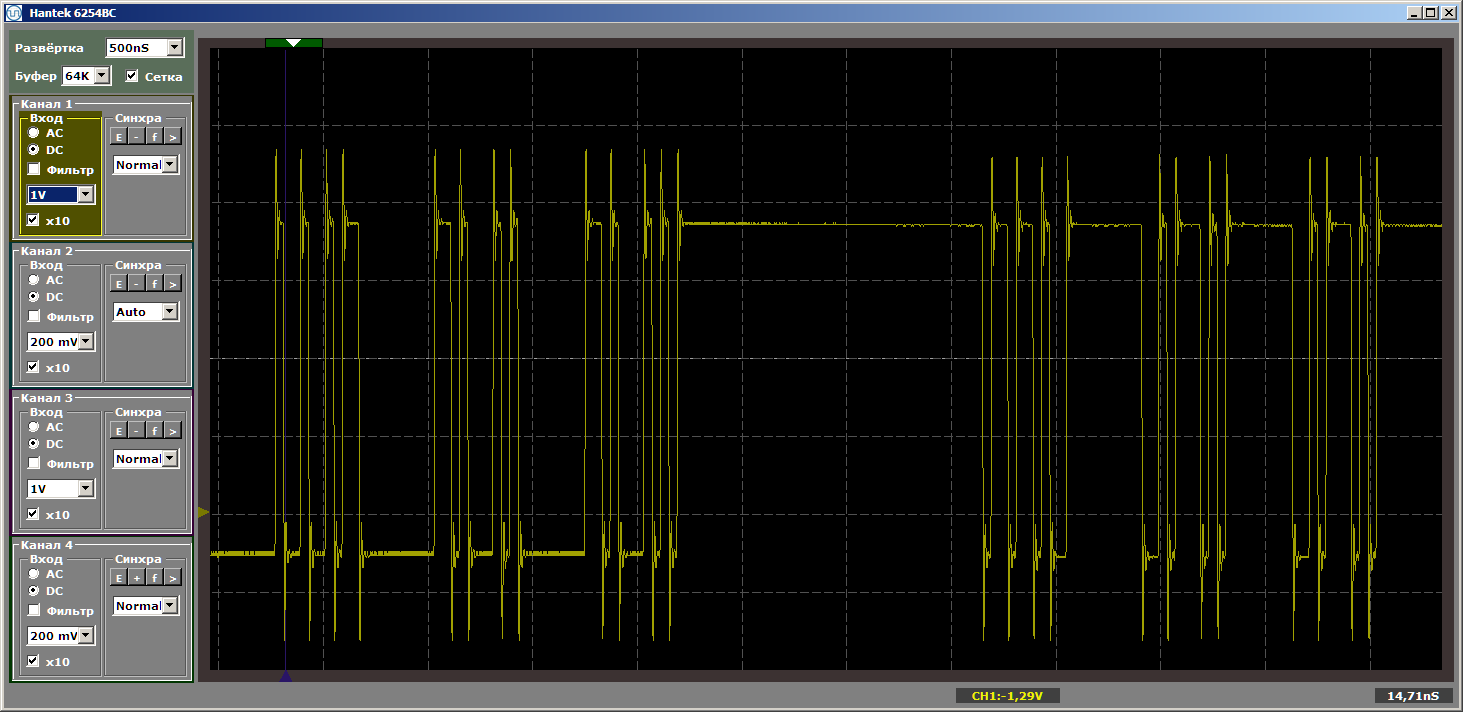
Es schien mir, dass solche Details, die in den Haupttext eingefügt wurden, jeden vom Haupttext ablenken würden, also habe ich sie in ein Postskriptum eingefügt.