
Willkommen zum nächsten Artikel in einer
Reihe von Rätseln, die ich bei Google-Interviews gefragt habe, bevor sie nach dem Leck verboten wurden. Seitdem habe ich aufgehört, als Softwareentwickler bei Google zu arbeiten, und bin zum Entwicklungsleiter bei Reddit gewechselt, aber ich habe immer noch ein paar großartige Themen. Bisher haben wir die
dynamische Programmierung untersucht
und Matrizen zur Leistungsfähigkeit und
Synonymie von Abfragen erhoben . Diesmal eine völlig neue Frage.
Aber zuerst zwei Punkte. Zunächst einmal war die Arbeit bei Reddit großartig. In den letzten acht Monaten habe ich das neue Team für Anzeigenrelevanz aufgebaut und geleitet und ein neues Entwicklungsbüro in New York eingerichtet. Egal wie lustig es auch sein mag, leider stellte ich fest, dass ich bis vor kurzem keine Zeit oder Energie mehr für einen Blog hatte. Ich fürchte, ich habe diese Serie ein bisschen aufgegeben. Entschuldigen sie für die Verzögerung.
Zweitens, wenn Sie den Artikeln gefolgt sind, könnten Sie nach der letzten Ausgabe denken, dass ich anfangen würde, mich mit den synonymischen Optionen der Abfragen zu befassen. Obwohl ich irgendwann darauf zurückkommen möchte, muss ich zugeben, dass ich aufgrund eines Arbeitswechsels das Interesse an diesem Problem verloren habe und mich bisher entschlossen habe, es zu verschieben. Bleiben Sie jedoch in Kontakt! Ich schulde mir etwas und beabsichtige, es zurückzugeben. Nur ein bisschen später ...
Kurzer Haftungsausschluss: Obwohl das Befragen von Kandidaten eine meiner beruflichen Aufgaben ist, präsentiert dieser Blog meine persönlichen Beobachtungen, persönlichen Geschichten und persönlichen Meinungen. Bitte nehmen Sie dies nicht für eine offizielle Erklärung von Google, Alphabet, Reddit oder einer anderen Person oder Organisation.Suchen Sie nach einer neuen Frage
In einem
früheren Artikel habe ich eine meiner Lieblingsfragen beschrieben, die ich lange Zeit vor dem unvermeidlichen Leck verwendet habe. Die vorherigen Fragen waren aus theoretischer Sicht faszinierend, aber ich wollte ein Problem auswählen, das für Google als Unternehmen etwas relevanter ist. Als diese Frage verboten wurde, wollte ich unter Berücksichtigung der neuen Einschränkung einen Ersatz finden: um die Frage
einfacher zu machen.
Dies mag angesichts des berüchtigten Interviewprozesses bei Google etwas überraschend erscheinen. Aber zu dieser Zeit machte ein einfacheres Problem Sinn. Meine Argumentation bestand aus zwei Teilen. Das erste ist pragmatisch: Die Kandidaten haben frühere Fragen trotz zahlreicher Hinweise und Vereinfachungen normalerweise nicht sehr gut gemeistert, und ich war mir nicht immer ganz sicher, warum. Die zweite theoretische: Der Interviewprozess sollte die Kandidaten in die Kategorien „es lohnt sich, eingestellt zu werden“ und „es lohnt sich nicht, eingestellt zu werden“ einteilen, und ich war gespannt, ob dies mit der Frage etwas einfacher gemacht werden könnte.
Bevor ich diese beiden Punkte klarstelle, möchte ich darauf hinweisen, was sie
nicht bedeuten. "Ich bin nicht immer sicher, warum eine Person Probleme hat" bedeutet nicht, dass die Fragen nutzlos sind und dass ich das Interview aus diesem Grund vereinfachen wollte. Selbst die schwierigste Frage haben viele gut gemeistert. Ich meine, wenn Kandidaten Probleme hatten, war es für mich schwer zu verstehen, was ihnen fehlte.
Gute Interviews geben ein umfassendes Bild der Stärken und Schwächen des Kandidaten. Es reicht nicht aus, wenn das Einstellungskomitee einfach sagt, dass es „gescheitert“ ist: Das Komitee bestimmt, ob der Kandidat unternehmensspezifische Eigenschaften hat, die er sucht. Ebenso helfen die Worte „er ist cool“ dem Ausschuss nicht, sich für einen Kandidaten zu entscheiden, der in einigen Bereichen stark, in anderen jedoch zweifelhaft ist. Ich habe festgestellt, dass komplexere Themen die Kandidaten zu oft in diese beiden Kategorien einteilen. In diesem Licht bedeutet "Ich bin nicht immer sicher, warum eine Person Probleme hat", "die Unfähigkeit, in diesem Bereich voranzukommen, zeichnet an sich kein Bild der Fähigkeiten dieses Kandidaten."
Die Einstufung von Kandidaten als „einstellungswürdig“ und „nicht einstellungswürdig“
bedeutet nicht , dass der Interviewprozess dumme Kandidaten von intelligenten trennen sollte. Ich kann mich nicht an einen einzigen Kandidaten erinnern, der nicht klug, talentiert und motiviert war. Viele kamen von exzellenten Universitäten, und der Rest war eindeutig äußerst motiviert. Das Durchlaufen von Telefoninterviews ist bereits ein gutes Sieb, und selbst das Ablehnen in dieser Phase ist kein Zeichen für mangelnde Fähigkeiten.
Ich
kann mich
jedoch an viele erinnern, die nicht ausreichend auf das Interview vorbereitet waren oder zu langsam arbeiteten oder zu viel Aufsicht benötigten, um das Problem zu lösen, oder auf unklare Weise kommunizierten oder ihre Ideen nicht in Code übersetzen konnten oder eine Position innehatten, die einfach nicht führen würde Sein Erfolg auf lange Sicht usw. Die Definition von „eine Einstellung wert“ ist vage und variiert je nach Unternehmen. Der Interviewprozess besteht darin, festzustellen, ob jeder Kandidat die Anforderungen eines bestimmten Unternehmens erfüllt.
Ich habe viele reddit-Kommentare gelesen, in denen ich mich über zu komplexe Interviewfragen beschwert habe. Ich war neugierig, ob es noch möglich ist, eine würdige / unwürdige Empfehlung für eine einfachere Aufgabe abzugeben. Ich vermutete, dass dies ein nützliches Signal geben würde, ohne die Nerven des Kandidaten unnötig zu schreien. Ich werde Ihnen am Ende des Artikels von meinen Schlussfolgerungen erzählen ...
Mit diesen Gedanken suchte ich nach einer neuen Frage. In einer idealen Welt ist diese Frage einfach genug, um sie in 45 Minuten zu lösen, aber mit zusätzlichen Fragen, damit leistungsfähigere Kandidaten ihre Fähigkeiten unter Beweis stellen. Die Implementierung sollte auch kompakt sein, da viele Kandidaten immer noch an die Tafel schreiben. Ein großes Plus, wenn das Thema irgendwie mit Google-Produkten zusammenhängt.
Schließlich entschied ich mich für eine Frage, die ein wunderbarer Googler sorgfältig beschrieben und in unsere Fragendatenbank eingefügt hatte. Jetzt habe ich mich mit ehemaligen Kollegen beraten und sichergestellt, dass die Frage noch verboten ist, so dass Sie beim Interview definitiv nicht gefragt werden. Ich präsentiere es in der Form, in der es mir am effektivsten erscheint, mit einer Entschuldigung an den ursprünglichen Autor.
Frage
Sprechen Sie über Entfernungsmessungen.
Hand ist eine 4-Zoll-Maßeinheit, die im englischsprachigen Raum häufig zur Messung der Pferdehöhe verwendet wird.
Ein Lichtjahr ist eine weitere Maßeinheit, die der Entfernung entspricht, die ein Lichtteilchen (oder eine Welle?) In einer bestimmten Anzahl von Sekunden zurücklegt, ungefähr gleich einem Erdjahr. Auf den ersten Blick haben sie wenig miteinander zu tun, außer dass sie zur Entfernungsmessung verwendet werden. Es stellt sich jedoch heraus, dass Google sie ganz einfach konvertieren kann:

Dies mag offensichtlich erscheinen: Am Ende messen beide die Entfernung, sodass klar ist, dass es eine Transformation gibt. Aber wenn Sie darüber nachdenken, ist es etwas seltsam: Wie haben sie diese Conversion-Rate berechnet? Es ist klar, dass niemand wirklich die Anzahl der Hände in einem Lichtjahr gezählt hat. Eigentlich müssen Sie dies nicht direkt übernehmen. Sie können einfach bekannte Konvertierungen verwenden:
- 1 Hand = 4 Zoll
- 4 Zoll = 0,33333 Fuß
- 0,33333 ft = 6,3125e - 5 Meilen
- 6,3125e - 5 Meilen = 1,0737e - 17 Lichtjahre
Ziel der Aufgabe ist es, ein System zu entwickeln, das diese Transformation durchführt. Insbesondere:
Am Eingang haben Sie eine Liste von Umrechnungsfaktoren (in der von Ihnen gewählten Sprache formatiert) in Form einer Reihe von anfänglichen Maßeinheiten, endgültigen Einheiten und Faktoren, zum Beispiel:
ft 12
Fußhof 0,3333333
usw.
Damit ORIGIN * MULTIPLIER = DESTINATION. Entwickeln Sie einen Algorithmus, der zwei beliebige Einheitswerte verwendet und den Umrechnungsfaktor zwischen ihnen zurückgibt.
Die Diskussion
Ich mag dieses Problem, weil es eine intuitive und offensichtliche Antwort hat: Konvertieren Sie einfach von einer Einheit zur anderen und dann zur nächsten, bis Sie das Ziel gefunden haben! Ich kann mich nicht an einen einzelnen Kandidaten erinnern, der auf dieses Problem gestoßen ist und völlig verwirrt war, wie man es löst. Dies passt gut zu der Anforderung eines „einfacheren“ Problems, da die vorherigen normalerweise lange Studien und Überlegungen erforderten, bevor zumindest ein grundlegender Lösungsansatz gefunden wurde.
Trotzdem haben viele Kandidaten ihre Intuition als funktionierende Lösung ohne offensichtliche Hinweise nicht verwirklicht. Einer der Vorteile dieser Frage besteht darin, dass sie die Fähigkeit des Kandidaten testet, das Problem so zu formulieren (Framing zu erstellen), dass es sich für Analyse und Codierung eignet. Wie wir sehen werden, gibt es hier eine sehr interessante Erweiterung, die einen neuen konzeptionellen Sprung erfordert.
Für den Kontext ist Framing der Vorgang des Übersetzens eines Problems mit einer nicht offensichtlichen Lösung in ein äquivalentes Problem, bei dem die Lösung auf natürliche Weise abgeleitet wird. Wenn dies völlig abstrakt und uneinnehmbar klingt, tut es mir leid, aber es ist. Ich werde erklären, was ich meine, wenn ich die erste Lösung für dieses Problem vorstelle. Der erste Teil der Lösung wird eine Übung zur Entwicklung und Anwendung von algorithmischem Wissen sein. Der zweite Teil wird eine Übung zur Manipulation dieses Wissens sein, um zu einer neuen und nicht offensichtlichen Optimierung zu gelangen.
Teil 0. Intuition
Bevor wir tiefer graben, wollen wir die „offensichtliche“ Lösung vollständig untersuchen. Die meisten erforderlichen Konvertierungen sind einfach und unkompliziert. Jeder Amerikaner, der außerhalb der USA gereist ist, weiß, dass der größte Teil der Welt die mysteriöse Einheit „Kilometer“ verwendet, um Entfernungen zu messen. Zum Konvertieren müssen Sie nur die Anzahl der Meilen mit etwa 1,6 multiplizieren.
Wir sind fast unser ganzes Leben lang auf solche Dinge gestoßen. Für die meisten Einheiten gibt es bereits eine vorberechnete Umrechnung, sodass Sie sie nur in der entsprechenden Tabelle betrachten müssen. Wenn es jedoch keine direkte Konvertierung gibt (z. B. von Händen zu Lichtjahren), ist es sinnvoll, einen Konvertierungspfad wie oben angegeben zu erstellen:
- 1 Hand = 4 Zoll
- 4 Zoll = 0,33333 Fuß
- 0,33333 ft = 6,3125e - 5 Meilen
- 6,3125e - 5 Meilen = 1,0737e - 17 Lichtjahre
Es war sehr einfach, ich habe mir gerade eine solche Transformation mit meiner Fantasie und einer Standard-Transformationstabelle ausgedacht! Es bleiben jedoch einige Fragen offen. Gibt es einen kürzeren Weg? Wie genau ist der Koeffizient? Ist eine Konvertierung immer möglich? Ist es möglich, es zu automatisieren? Leider bricht hier der naive Ansatz zusammen.
Teil 1. Naive Entscheidung
Es ist schön, dass das Problem eine intuitive Lösung hat, aber tatsächlich ist diese Einfachheit ein Hindernis für die Lösung des Problems. Es gibt nichts Schwierigeres, als zu versuchen, auf neue Weise zu verstehen, was Sie bereits verstehen - nicht zuletzt, weil Sie oft weniger wissen, als Sie denken. Stellen Sie sich zur Veranschaulichung vor, Sie wären zu einem Interview gekommen - und Sie haben diese intuitive Methode im Kopf. Es erlaubt jedoch nicht, eine Reihe wichtiger Probleme zu lösen.
Was
ist zum Beispiel, wenn
keine Konvertierung erfolgt ? Der offensichtliche Ansatz sagt nichts aus, ist es wirklich möglich, von einer Einheit zur anderen zu konvertieren. Wenn sie mir tausend Umrechnungskurse geben, wird es für mich sehr schwierig sein festzustellen, ob dies im Prinzip möglich ist. Wenn ich gebeten werde, eine Konvertierung zwischen unbekannten (oder erfundenen) Einheiten eines
Zeigers und eines
Stoßes vorzunehmen , habe ich keine Ahnung, wo ich anfangen soll. Wie hilft hier ein intuitiver Ansatz?
Ich muss zugeben, dass dies eine Art erfundenes Szenario ist, aber es gibt auch ein realistischeres. Sie sehen, dass meine Erklärung des Problems nur Entfernungseinheiten enthält. Dies geschieht absichtlich. Was ist, wenn ich das System auffordere, von Zoll in Kilogramm umzurechnen? Sowohl Sie als auch ich wissen, dass dies nicht möglich ist, weil sie unterschiedliche Typen messen, aber die Eingabe sagt nichts über den „Typ“ aus, den jede Einheit misst.
Hier ermöglicht eine sorgfältige Formulierung der Frage starken Kandidaten, sich zu beweisen.
Bevor sie den Algorithmus entwickeln, denken sie über die Extremfälle des Systems nach. Und eine solche Erklärung des Problems gibt ihnen absichtlich die Möglichkeit, mich zu fragen, ob wir verschiedene Einheiten übersetzen werden. Dies ist kein so großes Problem, wenn es in einem frühen Stadium auftritt, aber es ist immer ein gutes Zeichen, wenn mich jemand im Voraus fragt: "Was soll das Programm zurückgeben, wenn eine Konvertierung nicht möglich ist?" Wenn ich die Frage so stelle, bekomme ich eine Vorstellung von den Fähigkeiten des Kandidaten, bevor er mindestens eine Codezeile schreibt.
DiagrammansichtOffensichtlich ist der naive Ansatz nicht geeignet, also müssen wir uns überlegen, wie wir eine solche Konvertierung durchführen können. Die Antwort besteht darin, Einheiten als Grafik zu betrachten. Dies ist der erste Sprung zum Verständnis, der zur Lösung dieses Problems erforderlich ist.
Stellen Sie sich insbesondere vor, dass jede Einheit ein Knoten in einem Diagramm ist und es eine Kante von Knoten
A zu Knoten
B wenn
A in
B konvertiert werden kann:
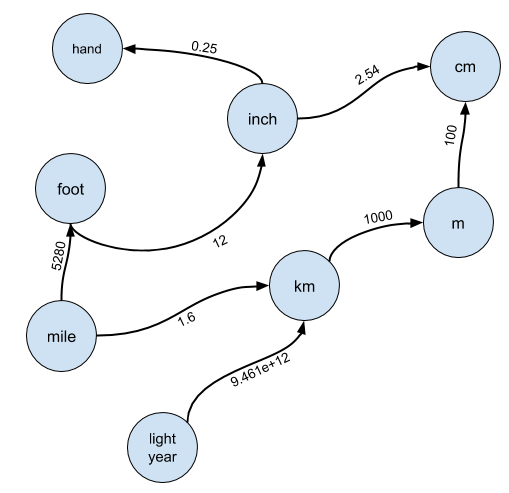
Die Kanten sind mit einer Conversion-Rate gekennzeichnet, mit der Sie
A multiplizieren müssen, um
B zu erhalten
BIch hatte fast immer erwartet, dass der Kandidat einen solchen Rahmen finden würde, und gab ihm selten ernsthafte Hinweise. Ich kann dem Kandidaten vergeben, der die Lösung des Problems der Verwendung disjunkter Mengen nicht bemerkt oder mit der linearen Algebra nicht allzu vertraut ist, um eine Lösung zu realisieren, die sich darauf reduziert, die Potenz der Adjazenzmatrix wieder zu erhöhen, aber Grafiken werden in jedem Lehrplan oder Programmierkurs unterrichtet. Wenn der Kandidat nicht über die entsprechenden Kenntnisse verfügt, handelt es sich um ein Signal „Keine Einstellung“.
Auf jeden FallEine Diagrammdarstellung reduziert die Lösung des klassischen Problems der Diagrammsuche. Insbesondere sind hier zwei Algorithmen nützlich: Wide Search (BFS) und Deep Search (DFS). Bei der Suche in der Breite untersuchen wir die Knoten nach ihrem Abstand vom Ursprung:
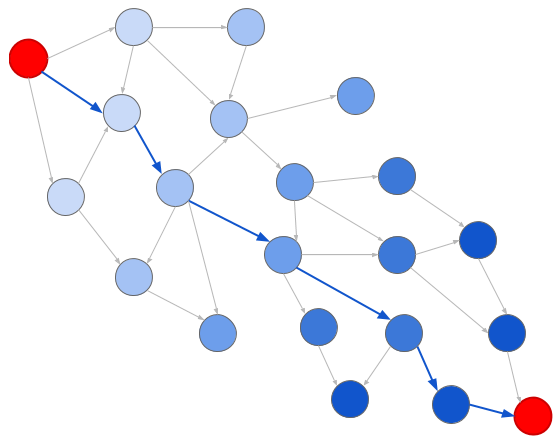 Dunklerer Blues bedeutet spätere Generationen
Dunklerer Blues bedeutet spätere GenerationenUnd bei der eingehenden Suche untersuchen wir die Knoten in der Reihenfolge, in der sie auftreten:
 Dunklerer Blues bedeutet auch spätere Generationen. Bitte beachten Sie, dass wir nicht alle Websites besuchen
Dunklerer Blues bedeutet auch spätere Generationen. Bitte beachten Sie, dass wir nicht alle Websites besuchenJeder der Algorithmen bestimmt leicht, ob eine Konvertierung von einer Einheit in eine andere erfolgt. Es reicht aus, einfach die Grafik zu durchsuchen. Wir starten von der Quelleneinheit und suchen, bis wir die Zieleinheit finden. Wenn Sie Ihr Ziel nicht finden können (als würden Sie versuchen, Zoll in Kilogramm umzurechnen), wissen wir, dass es keinen Weg gibt.
Aber warte, etwas fehlt. Wir wollen nicht nach einem Weg suchen, wir wollen eine Conversion-Rate finden! Hier muss der Kandidat den Sprung machen: Es stellt sich heraus, dass Sie jeden Suchalgorithmus ändern können, um die Conversion-Rate zu berechnen, indem Sie einfach den zusätzlichen Status speichern, während Sie fortfahren. Hier machen Illustrationen keinen Sinn mehr, also lasst uns direkt in den Code eintauchen.
Zuerst müssen Sie die Datenstruktur des Diagramms bestimmen, damit wir Folgendes verwenden:
class RateGraph(object): def __init__(self, rates): 'Initialize the graph from an iterable of (start, end, rate) tuples.' self.graph = {} for orig, dest, rate in rates: self.add_conversion(orig, dest, rate) def add_conversion(self, orig, dest, rate): 'Insert a conversion into the graph.' if orig not in self.graph: self.graph[orig] = {} self.graph[orig][dest] = rate def get_neighbors(self, node): 'Returns an iterable of the nodes neighboring the given node.' if node not in self.graph: return None return self.graph[node].items() def get_nodes(self): 'Returns an iterable of all the nodes in the graph.' return self.graph.keys()
Dann fangen wir mit DFS an. Es gibt viele Möglichkeiten, es zu implementieren, aber die bei weitem häufigste ist eine rekursive Lösung. Beginnen wir damit:
from collections import deque def __dfs_helper(rate_graph, node, end, rate_from_origin, visited): if node == end: return rate_from_origin visited.add(node) for unit, rate in rate_graph.get_neighbors(node): if unit not in visited: rate = __dfs_helper(rate_graph, unit, end, rate_from_origin * rate, visited) if rate is not None: return rate return None def dfs(rate_graph, node, end): return __dfs_helper(rate_graph, node, end, 1.0, set())
Kurz gesagt, dieser Algorithmus beginnt mit einem Knoten, iteriert über seine Nachbarn und besucht jeden sofort, wobei die Funktion rekursiv aufgerufen wird. Jeder Funktionsaufruf auf dem Stapel speichert den Status seiner eigenen Iteration. Wenn also ein rekursiver Besuch zurückgegeben wird, setzt das übergeordnete Element die Iteration sofort fort. Wir vermeiden es, dieselbe Site erneut zu besuchen, indem wir bei allen Anrufen eine Reihe von besuchten Sites verwalten. Wir berechnen den Koeffizienten auch, indem wir jedem Knoten und der Quelle einen Umrechnungsfaktor zuweisen. Wenn wir also auf den Zielknoten / -block stoßen, haben wir bereits den Konvertierungskoeffizienten aus dem Quellknoten erstellt und können ihn einfach zurückgeben.
Dies ist eine großartige Implementierung, die jedoch zwei Hauptmängel aufweist. Erstens ist es rekursiv. Wenn sich herausstellt, dass der gewünschte Weg aus mehr als tausend Sprüngen besteht, fliegen wir mit einer Panne aus. Dies ist natürlich unwahrscheinlich, aber wenn für einen langfristigen Dienst etwas inakzeptabel ist, ist dies ein Fehler. Zweitens hat die Antwort, selbst wenn wir sie erfolgreich abschließen, einige unerwünschte Eigenschaften.
Ich habe eigentlich schon am Anfang des Beitrags einen Hinweis gegeben. Haben Sie bemerkt, wie Google die Conversion-Rate von
1.0739e-17 , aber meine manuelle Berechnung ergibt
1.0737e-17 ? Es stellt sich heraus, dass all diese Gleitkomma-Multiplikationen dazu führen, dass man bereits daran denkt, den Fehler zu verbreiten. Es gibt zu viele Nuancen für diesen Artikel, aber unter dem Strich müssen Sie die Gleitkomma-Multiplikation minimieren, um Fehler zu vermeiden, die sich ansammeln und Probleme verursachen.
DFS ist ein großartiger Suchalgorithmus. Wenn eine Lösung existiert, wird sie gefunden. Aber ihm fehlt eine Schlüsseleigenschaft: Er findet nicht unbedingt den kürzesten Weg. Dies ist für uns wichtig, da ein kürzerer Pfad weniger Sprünge und weniger Fehler aufgrund von Gleitkomma-Multiplikationen bedeutet. Um das Problem zu lösen, wenden wir uns an BFS.
Teil 2. BFS-Lösung
Wenn ein Kandidat zu diesem Zeitpunkt eine rekursive DFS-Lösung erfolgreich implementiert und damit aufhört, gebe ich normalerweise zumindest eine schwache Empfehlung zur Einstellung dieses Kandidaten. Er verstand das Problem, wählte den geeigneten Rahmen und implementierte eine funktionierende Lösung. Dies ist eine naive Entscheidung, daher bestehe ich nicht darauf, ihn einzustellen, aber wenn er mit anderen Interviews gut zurechtkommt, werde ich nicht empfehlen, dies abzulehnen.
Dies ist es wert, wiederholt zu werden: Schreiben Sie im Zweifelsfall eine naive Lösung! Auch wenn es nicht ganz optimal ist, ist das Vorhandensein von Code auf der Platine bereits eine Errungenschaft, und oft kann die richtige Lösung auf ihrer Grundlage gefunden werden. Ich werde anders sagen: Niemals für nichts arbeiten. Höchstwahrscheinlich haben Sie an eine naive Lösung gedacht, wollten sie aber nicht anbieten, weil Sie wissen, dass sie nicht optimal ist. Wenn Sie jetzt bereit sind, die beste Lösung zu finden, ist das in Ordnung. Wenn nicht, zeichnen Sie die erzielten Fortschritte auf, bevor Sie mit komplexeren Dingen fortfahren.
Lassen Sie uns von nun an über die Verbesserungen des Algorithmus sprechen. Die Hauptnachteile einer rekursiven DFS-Lösung bestehen darin, dass sie rekursiv ist und die Anzahl der Multiplikationen nicht minimiert. Wie wir bald sehen werden, minimiert BFS die Anzahl der Multiplikationen und es ist auch sehr schwierig, sie rekursiv zu implementieren. Leider müssen wir die rekursive DFA-Lösung aufgeben, da wir den Code zur Verbesserung vollständig neu schreiben müssen.
Ohne weiteres präsentiere ich einen iterativen Ansatz basierend auf BFS:
from collections import deque def bfs(rate_graph, start, end): to_visit = deque() to_visit.appendleft( (start, 1.0) ) visited = set() while to_visit: node, rate_from_origin = to_visit.pop() if node == end: return rate_from_origin visited.add(node) for unit, rate in rate_graph.get_neighbors(node): if unit not in visited: to_visit.appendleft((unit, rate_from_origin * rate)) return None
Diese Implementierung unterscheidet sich funktional stark von der vorherigen, aber wenn Sie genau hinschauen, funktioniert sie mit einer wesentlichen Änderung ungefähr gleich: Während rekursives DFS den Status der weiteren Route im Aufrufstapel speichert und den LIFO-Stapel effektiv implementiert, speichert die iterative Lösung ihn in der Warteschlange FIFO
Dies impliziert die Eigenschaft "kürzester Weg / geringste Anzahl von Multiplikationen". Wir besuchen Knoten in der Reihenfolge, in der sie auftreten, und auf diese Weise erhalten wir Generationen von Knoten. Der erste Knoten fügt seine Nachbarn ein, und dann besuchen wir diese Nachbarn der Reihe nach und halten ihre Nachbarn die ganze Zeit fest und so weiter. Die Eigenschaft des kürzesten Pfades ergibt sich aus der Tatsache, dass die Knoten in der Reihenfolge ihrer Entfernung von der Quelle besucht werden. Wenn wir also auf ein Ziel stoßen, wissen wir, dass es keine frühere Generation gibt, die dazu führen könnte.
In diesem Moment sind wir
fast fertig. Zuerst müssen Sie einige Fragen beantworten, und sie sind gezwungen, zur ursprünglichen Formulierung des Problems zurückzukehren.
Erstens, das Trivialste, wenn die ursprüngliche Einheit nicht existiert? Das heißt, wir können den Knoten mit dem angegebenen Namen nicht finden. In der Praxis müssen Sie die Zeichenfolgen normalisieren, damit Pound, Pound und lb auf denselben "Pound" -Knoten (oder eine andere kanonische Darstellung) zeigen. Dies geht jedoch über den Rahmen unserer Frage hinaus.
Zweitens, was ist, wenn zwischen den beiden Einheiten keine Umrechnung erfolgt? Denken Sie daran, dass es in den Anfangsdaten nur Umrechnungen zwischen Einheiten gibt und es keine Hinweise darauf gibt, ob es möglich ist, eine andere von einer bestimmten Einheit zu erhalten. Dies läuft darauf hinaus, dass Transformationen und Pfade direkt gleichwertig sind. Wenn also kein Pfad zwischen zwei Knoten vorhanden ist, gibt es keine Transformation. In der Praxis erhalten Sie nicht verwandte Einheiteninseln: eine für Entfernungen, eine für Gewichte, eine für Währungen usw.
Wenn Sie sich die obige Grafik genauer ansehen, stellt sich heraus, dass Sie mit dieser Lösung nicht zwischen Händen und Lichtjahren konvertieren können. Die Richtung der Verbindungen zwischen Knoten bedeutet, dass es keinen Weg von Hand zu Lichtjahren gibt. Dies ist jedoch recht einfach zu beheben, da die Transformationen umgekehrt werden können. Wir können unseren Graphinitialisierungscode wie folgt ändern:
def add_conversion(self, orig, dest, rate): 'Insert a conversion into the graph. Note we insert its inverse also.' if orig not in self.graph: self.graph[orig] = {} self.graph[orig][dest] = rate if dest not in self.graph: self.graph[dest] = {} self.graph[dest][orig] = 1.0 / rate
Teil 3. Bewertung
Fertig! Wenn der Kandidat diesen Punkt erreicht hat, werde ich ihn höchstwahrscheinlich zur Einstellung empfehlen. Wenn Sie Informatik studiert oder einen Kurs in Algorithmen belegt haben, fragen Sie sich vielleicht: "Reicht das wirklich aus, um ein Interview mit diesem Typen zu bekommen?", Worauf ich antworten werde: "Im Wesentlichen ja."
Bevor Sie entscheiden, dass die Frage zu einfach ist, schauen wir uns an, was ein Kandidat tun muss, um diesen Punkt zu erreichen:
- Verstehe die Frage
- Erstellen Sie ein Netzwerk von Transformationen in Form eines Diagramms
- Verstehen Sie, dass die Koeffizienten mit den Kanten des Diagramms verglichen werden können
- Sehen Sie die Möglichkeit, Suchalgorithmen zu verwenden, um dies zu erreichen.
- Wählen Sie Ihren bevorzugten Algorithmus und ändern Sie ihn, um die Gewinnchancen zu verfolgen
- Wenn er DFS als naive Lösung implementiert hat, erkennen Sie seine Schwächen.
- Implementieren Sie BFS
- Um zurückzutreten und Extremfälle zu untersuchen:
- Was ist, wenn wir nach einem Knoten gefragt werden, der nicht existiert?
- Was ist, wenn der Umrechnungsfaktor nicht vorhanden ist?
- Erkennen Sie, dass inverse Transformationen möglich und wahrscheinlich notwendig sind
Diese Frage ist einfacher als die vorherigen, aber auch schwierig. Wie bei allen vorherigen Fragen muss der Kandidat einen mentalen Sprung von einer abstrakt formulierten Frage zu einem Algorithmus oder einer Datenstruktur machen, die den Weg zu einer Lösung ebnet. Das einzige ist, dass der endgültige Algorithmus weniger fortgeschritten ist als in anderen Fragen. Außerhalb dieses algorithmischen Materials gelten die gleichen Anforderungen, insbesondere in Bezug auf Extremfälle und Korrektheit.
"Aber warte!" Sie können fragen. - Ist Google nicht besessen von der Komplexität der Laufzeit? Sie haben nicht einmal nach der zeitlichen oder räumlichen Komplexität dieses Problems gefragt. Ach was!" Sie können auch fragen: "Warten Sie eine Minute, Sie gaben die Bewertung" sehr zu empfehlen zu mieten "? Wie bekomme ich es? " Beides sehr gute Fragen. Dies bringt uns zu unserer letzten zusätzlichen Bonusrunde ...
Teil 4. Kann man es besser machen?
An dieser Stelle möchte ich dem Kandidaten zu einer guten Antwort gratulieren und klarstellen, dass alles weitere nur ein Bonus ist. Wenn der Druck verschwindet, können wir anfangen zu schaffen.
Was ist die Schwierigkeit, BFS auszuführen? Im schlimmsten Fall müssen wir jeden einzelnen Knoten und jede einzelne Kante berücksichtigen, was eine lineare Komplexität
O(N+E) ergibt. Dies kommt zu der gleichen Komplexität der
O(N+E) -Graphenkonstruktion hinzu. Für eine Suchmaschine ist dies wahrscheinlich gut: Tausend Maßeinheiten reichen für die meisten vernünftigen Anwendungen aus, und eine Speichersuche für jede Abfrage ist keine Überlastung.
Man kann es jedoch besser machen. Überlegen Sie zur Motivation, wie dieser Code in die Suchzeichenfolge eingefügt wird. Umrechnungen einiger nicht standardmäßiger Einheiten sind etwas häufiger, daher werden wir sie immer wieder berechnen. Jedes Mal, wenn eine Suche durchgeführt wird, werden Zwischenwerte berechnet und so weiter.
Es wird oft empfohlen, die Berechnungsergebnisse einfach zwischenzuspeichern. Wenn eine Einheitenumrechnung berechnet wird, können wir immer nur eine Kante zwischen den beiden Umrechnungen hinzufügen. Als Bonus erhalten wir die inverse Transformation und das kostenlos! Bist du fertig
Dies gibt uns zwar eine asymptotisch konstante Suchzeit, kostet jedoch die Speicherung zusätzlicher Kanten. Dies wird tatsächlich ziemlich teuer: Im Laufe der Zeit werden wir uns um einen vollständigen Graphen bemühen, da alle Transformationspaare nach und nach berechnet und gespeichert werden. Die Anzahl der möglichen Kanten im Diagramm ist das halbe Quadrat der Anzahl der Knoten. Für tausend Knoten benötigen wir also eine halbe Million Kanten. Für zehntausend Knoten, ungefähr fünfzig Millionen usw.
Über den Rahmen der Suchmaschine hinaus streben wir für eine Grafik von einer Million Knoten eine halbe Billion Kanten an. Es ist einfach unangemessen, diesen Betrag zu speichern, und wir verbringen Zeit damit, Kanten in das Diagramm einzufügen. Wir müssen es besser machen.
Glücklicherweise gibt es eine Möglichkeit, eine konstante Zeit für die Suche nach Koeffizienten ohne quadratisches Raumwachstum zu erreichen. Tatsächlich ist fast alles, was wir brauchen, direkt vor unserer Nase.
Teil 4. Konstante Zeit
Das vollständige Caching ist also tatsächlich nahe an der optimalen Lösung. Bei diesem Ansatz erhalten wir (letztendlich) Kanten zwischen allen Knoten, dh unsere Transformation wird darauf reduziert, eine Kante zu finden. Aber ist es wirklich notwendig, Conversions von jedem Knoten zu jedem Knoten zu speichern? Was ist, wenn wir nur die Umrechnungsfaktoren von
einem Knoten auf alle anderen speichern?
Schauen Sie sich die BFS-Lösung noch einmal an:
from collections import deque def bfs(rate_graph, start, end): to_visit = deque() to_visit.appendleft( (start, 1.0) ) visited = set() while to_visit: node, rate_from_origin = to_visit.pop() if node == end: return rate_from_origin visited.add(node) for unit, rate in rate_graph.get_neighbors(node): if unit not in visited: to_visit.appendleft((unit, rate_from_origin * rate)) return None
Mal sehen, was hier passiert: Wir beginnen am Quellknoten und berechnen für jeden Knoten, auf den wir stoßen, den Umrechnungskoeffizienten von der Quelle zu diesem Knoten. Sobald wir am Ziel ankommen, geben wir den Koeffizienten zwischen dem Start- und dem Endpunkt zurück und verwerfen die Zwischenkoeffizienten.
Diese Zwischenverhältnisse sind entscheidend. Aber was ist, wenn wir sie nicht wegwerfen? Was ist, wenn wir sie stattdessen aufschreiben? Alle komplexesten und unverständlichsten Suchvorgänge werden einfach: Um das Verhältnis von A zu B zu ermitteln, müssen Sie zuerst das Verhältnis von X zu B ermitteln und dann durch das Verhältnis von X zu A dividieren. Fertig! Optisch sieht es so aus:
 Beachten Sie, dass zwischen zwei beliebigen Knoten nicht mehr als zwei Kanten liegen
Beachten Sie, dass zwischen zwei beliebigen Knoten nicht mehr als zwei Kanten liegenEs stellt sich heraus, dass wir zur Berechnung dieser Tabelle die BFS-Lösung fast nicht ändern müssen:
from collections import deque def make_conversions(graph): def conversions_bfs(rate_graph, start, conversions): to_visit = deque() to_visit.appendleft( (start, 1.0) ) while to_visit: node, rate_from_origin = to_visit.pop() conversions[node] = (start, rate_from_origin) for unit, rate in rate_graph.get_neighbors(node): if unit not in conversions: to_visit.append((unit, rate_from_origin * rate)) return conversions conversions = {} for node in graph.get_nodes(): if node not in conversions: conversions_bfs(graph, node, conversions) return conversions
Die Transformationsstruktur wird durch ein Wörterbuch der Einheit A in zwei Werten dargestellt: der Wurzel für die zugehörige Komponente der Einheit A und dem Umrechnungskoeffizienten zwischen der Wurzeleinheit und der Einheit A. Da wir bei jedem Besuch eine Einheit in dieses Wörterbuch einfügen, können wir den Schlüsselraum dieses Wörterbuchs als eine Reihe von Besuchen verwenden, anstatt ihn zu verwenden eine spezielle Reihe von Besuchen. Beachten Sie, dass wir keinen endgültigen Knoten haben und stattdessen die Knoten durchlaufen, bis wir fertig sind.
Außerhalb dieses BFS gibt es eine Hilfsfunktion, die über Knoten in einem Diagramm iteriert. Immer wenn es auf einen Knoten außerhalb des Übersetzungswörterbuchs trifft, startet es BFS ab diesem Knoten.
Somit ist garantiert, dass wir alle Knoten in ihre zugehörigen Komponenten zusammenfassen.Wenn Sie die Beziehung zwischen den Einheiten finden müssen, verwenden wir einfach die gerade berechnete Transformationsstruktur: def convert(conversions, start, end): 'Given a conversion structure, performs a constant-time conversion' try: start_root, start_rate = conversions[start] end_root, end_rate = conversions[end] except KeyError: return None if start_root != end_root: return None return end_rate / start_rate
Die Situation „Es gibt keine solche Einheit“ wird behandelt, indem beim Zugriff auf die Struktur von Transformationen auf eine Ausnahme gewartet wird. Die Situation „Es gibt keine solchen Transformationen“ wird durch Vergleichen der Wurzeln zweier Größen behandelt: Wenn sie unterschiedliche Wurzeln haben, werden sie durch zwei verschiedene BFS-Aufrufe erkannt, dh sie befinden sich in zwei verschiedenen verbundenen Komponenten, und daher gibt es keinen Weg zwischen ihnen. Schließlich führen wir die Konvertierung durch.So! Die aktuelle Lösung weist eine Vorverarbeitungskomplexität aufO(V+E)(nicht schlechter als frühere Lösungen), aber sie sucht auch mit konstanter Zeit. Theoretisch verdoppeln wir den Platzbedarf, aber meistens benötigen wir das ursprüngliche Diagramm nicht mehr, sodass wir es einfach löschen und nur dieses verwenden können. Darüber hinaus ist die räumliche Komplexität tatsächlich geringer als beim ursprünglichen Diagramm: Sie erfordert, O(V+E)weil alle Kanten und Eckpunkte gespeichert werden müssen, und diese Struktur erfordert nur, O(V)weil wir keine Kanten mehr benötigen.Ergebnisse
, , , , - . - , . , .
( , , , ), « ». , : , , .
Dies ist sofort ein nützliches Signal. Ich kann verstehen, wenn eine Person keine fortgeschrittenen oder undurchsichtigen Datenstrukturen kennt, weil wir ehrlich sind, müssen Sie selten disjunkte Mengen implementieren. Grafiken sind jedoch eine grundlegende Datenstruktur und werden im Rahmen fast aller Einführungskurse zu diesem Thema vermittelt. Wenn der Kandidat Schwierigkeiten hat, sie zu verstehen, oder sie nicht einfach anwenden kann, wird es für ihn wahrscheinlich schwierig sein, bei Google erfolgreich zu sein (zumindest in meiner Zeit dort weiß ich heute nicht, wie).Andererseits war die Wahl des Algorithmus keine besonders nützliche Signalquelle. Leute, die die Framing-Phase durchlaufen haben, sind normalerweise ohne Probleme zum Algorithmus gekommen. Ich vermute, dass dies auf die Tatsache zurückzuführen ist, dass Suchalgorithmen fast immer zusammen mit den Diagrammen selbst gelehrt werden. Wenn also jemand mit einem vertraut ist, kennt er den anderen.Die Implementierung war nicht einfach. Viele Leute hatten keine Probleme mit der rekursiven Implementierung von DFS, aber wie oben erwähnt, ist diese Implementierung nicht für die Produktion geeignet. Zu meiner Überraschung scheinen die iterativen Implementierungen von BFS und DFS den Menschen nicht sehr vertraut zu sein, und selbst nach offensichtlichen Hinweisen schwebten sie oft im Thema.Meiner Meinung nach hat mir jeder, der die Implementierungsphase durchlaufen hat, bereits die Empfehlung „Einstellung“ eingebracht, und die Diskussion über die konstante Vorlaufzeit ist einfach ein Bonus. Obwohl wir uns die Lösung im Artikel ausführlich angesehen haben, ist in der Praxis eine mündliche Diskussion anstelle des Schreibens von Code in der Regel produktiver. Nur sehr wenige Kandidaten konnten sofort eine Entscheidung treffen. Ich musste oft wesentliche Hinweise geben, und selbst dann konnten viele Leute ihn nicht finden. Dies ist normal: Wie erwartet ist es schwierig, eine sehr empfohlene Bewertung zu erhalten.Aber warte, das ist noch nicht alles!
, , , , . :
-, : , , . , , . , - , - . , , .
-, , , . — : — , A B — / . : , , , , , . .
Endlich ein echtes Juwel: Einige Einheiten werden als Kombination verschiedener Basiseinheiten ausgedrückt. Beispielsweise wird ein Watt im SI-System als kg • m² / s³ definiert. Die letzte Aufgabe besteht darin, dieses System zu erweitern, um die Konvertierung zwischen diesen Einheiten zu unterstützen, wobei nur die Definitionen der grundlegenden SI-Einheiten berücksichtigt werden.Wenn Sie Fragen haben, können Sie mich gerne über reddit kontaktieren .Fazit
, , . : , , , . , , , , : , . , , , .
Ich hoffe, Sie fanden diesen Artikel hilfreich. Ich verstehe, dass es mit Algorithmen möglicherweise nicht so viele Abenteuer gibt wie in einigen früheren Artikeln. Bei den Interviews mit Entwicklern ist es üblich, Algorithmen ausführlich zu diskutieren. Die Wahrheit ist jedoch, dass erhebliche Schwierigkeiten auftreten, wenn selbst eine einfache, bekannte Methode angewendet wird. Der gesamte Code befindet sich im Repository dieser Artikelserie .