Gruß, Chabrowiten! Herzlichen Glückwunsch an alle am Tag des Programmierers und teilen Sie die Übersetzung des Artikels, der speziell für Studenten des Kurses "High Load Architect" vorbereitet wurde. "Scherben. Oder nicht scherben. Ohne es zu versuchen. "
"Scherben. Oder nicht scherben. Ohne es zu versuchen. "
- YodaHeute werden wir uns mit der Trennung von Daten zwischen mehreren MySQL-Servern befassen. Wir haben das Sharding Anfang 2012 beendet und dieses System wird immer noch zum Speichern unserer Basisdaten verwendet.
Bevor wir uns mit dem Teilen von Daten befassen, sollten wir sie besser kennenlernen. Stellen Sie ein schönes Licht auf, holen Sie sich Erdbeeren in Schokolade, erinnern Sie sich an Zitate aus Star Trek ...
Pinterest ist eine Suchmaschine für alles, was Sie interessiert. In Bezug auf Daten ist Pinterest die weltweit größte Grafik menschlicher Interessen. Es enthält über 50 Milliarden Pins, die von Benutzern auf mehr als einer Milliarde Boards gespeichert wurden. Die Leute behalten einige Pins für sich und abonnieren wie andere Pins andere Pins, Boards und Interessen, sehen sich den Home-Feed aller Pins, Boards und Interessen an, die sie abonniert haben. Großartig! Jetzt machen wir es skalierbar!
Schmerzhaftes Wachstum
Im Jahr 2011 haben wir begonnen, an Dynamik zu gewinnen. Nach einigen
Schätzungen sind wir schneller gewachsen als jedes damals bekannte Startup. Um den September 2011 herum war jede Komponente unserer Infrastruktur überlastet. Wir hatten mehrere NoSQL-Technologien zur Verfügung, die alle katastrophal versagten. Wir hatten auch viele MySQL-Slaves, die wir gelesen haben, was viele außergewöhnliche Fehler verursachte, insbesondere beim Caching. Wir haben unser gesamtes Speichermodell umgebaut. Um effizient zu arbeiten, haben wir uns sorgfältig mit der Entwicklung der Anforderungen befasst.
Anforderungen
- Das gesamte System sollte sehr stabil, einfach zu bedienen und von der Größe eines kleinen Kastens bis zur Größe des Mondes skalierbar sein, wenn der Standort wächst.
- Alle vom Pinner generierten Inhalte sollten jederzeit auf der Website verfügbar sein.
- Das System sollte die Anforderung von N Pins auf der Karte in einer deterministischen Reihenfolge unterstützen (z. B. in umgekehrter Reihenfolge der Erstellungszeit oder in der vom Benutzer angegebenen Reihenfolge). Das gleiche gilt für Pinner, deren Pins usw.
- Der Einfachheit halber sollten Sie auf jede mögliche Weise nach Updates streben. Um die erforderliche Konsistenz zu erzielen, werden zusätzliche Spielzeuge benötigt, z. B. ein verteiltes Transaktionsjournal . Es macht Spaß und ist (nicht zu) einfach!
Architekturphilosophie und Notizen
Da diese Daten mehrere Datenbanken umfassen sollen, können wir nicht nur einen Join, Fremdschlüssel und Indizes verwenden, um alle Daten zu erfassen, obwohl sie für Unterabfragen verwendet werden können, die sich nicht über die Datenbank erstrecken.
Wir mussten auch den Lastausgleich für die Daten aufrechterhalten. Wir haben beschlossen, dass das Verschieben von Daten Element für Element das System unnötig komplex macht und viele Fehler verursacht. Wenn wir Daten verschieben mussten, war es besser, den gesamten virtuellen Knoten auf einen anderen physischen Knoten zu verschieben.
Damit unsere Implementierung schnell in Umlauf gebracht werden konnte, benötigten wir die einfachste und bequemste Lösung und sehr stabile Knoten in unserer verteilten Datenplattform.
Alle Daten mussten auf den Slave-Computer repliziert werden, um ein Backup mit hoher Verfügbarkeit zu erstellen und für MapReduce auf S3 zu sichern. Wir interagieren mit dem Meister nur in der Produktion. In der Produktion möchten Sie nicht in Slave schreiben oder lesen. Slave Lag, und es verursacht seltsame Fehler. Wenn das Sharding durchgeführt wird, macht es keinen Sinn, mit einem Slave in der Produktion zu interagieren.
Schließlich brauchen wir eine gute Möglichkeit, universelle eindeutige Kennungen (UUIDs) für alle unsere Objekte zu generieren.
Wie wir Scherben gemacht haben
Was wir schaffen wollten, musste die Anforderungen erfüllen, stabil arbeiten, im Allgemeinen funktionsfähig und wartbar sein. Aus diesem Grund haben wir die bereits recht ausgereifte MySQL-
Technologie als zugrunde liegende Technologie ausgewählt. Wir sind absichtlich vorsichtig mit neuen Technologien für die automatische Skalierung von MongoDB, Cassandra und Membase, weil sie weit genug von der Reife entfernt waren (und in unserem Fall auf beeindruckende Weise kaputt gingen!).
Außerdem: Ich empfehle immer noch Startups, um neue bizarre Dinge zu vermeiden - versuchen Sie einfach, MySQL zu verwenden. Vertrau mir. Ich kann es mit Narben beweisen.
MySQL - die Technologie ist bewährt, stabil und einfach - es funktioniert. Wir verwenden es nicht nur, es ist auch bei anderen Unternehmen beliebt, deren Waage noch beeindruckender ist. MySQL erfüllt unsere Anforderungen an die Optimierung von Datenabfragen, die Auswahl bestimmter Datenbereiche und Transaktionen auf Zeilenebene. Tatsächlich gibt es in seinem Arsenal viel mehr Möglichkeiten, aber wir alle brauchen sie nicht. Da MySQL jedoch eine "Boxed" -Lösung ist, mussten Daten gesplittet werden. Hier ist unsere Lösung:
Wir haben mit acht EC2-Servern begonnen, jeweils eine Instanz von MySQL:
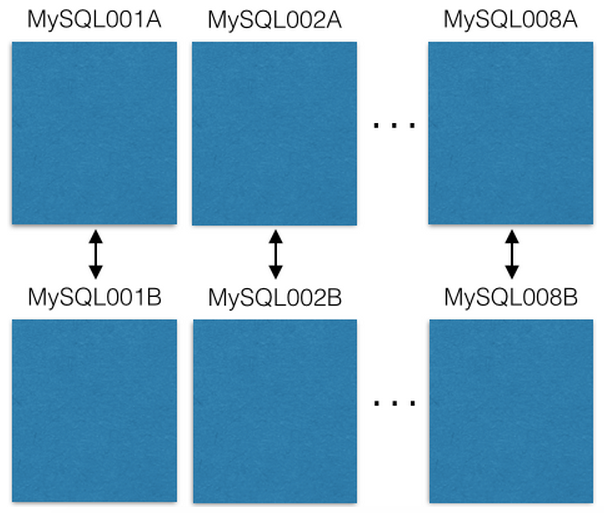
Jeder MySQL-Master-Master-Server wird im Falle eines primären Fehlers auf den Sicherungshost repliziert. Unsere Produktionsserver lesen oder schreiben nur an den Master. Ich empfehle Ihnen, dies auch zu tun. Dies vereinfacht und vermeidet Fehler mit Replikationsverzögerungen erheblich.
Jede MySQL-Entität verfügt über viele Datenbanken:

Beachten Sie, dass jede Datenbank eindeutig benannt ist: db00000, db00001 bis dbNNNNN. Jede Datenbank ist ein Splitter unserer Daten. Wir haben eine architektonische Entscheidung getroffen, auf deren Grundlage nur ein Teil der Daten in den Shard fällt und der nie über diesen Shard hinausgeht. Sie können jedoch mehr Kapazität erhalten, indem Sie Shards auf andere Computer verschieben (darüber werden wir später sprechen).
Wir arbeiten mit einer Konfigurationstabelle, die angibt, welche Maschinen Shards haben:
[{“range”: (0,511), “master”: “MySQL001A”, “slave”: “MySQL001B”}, {“range”: (512, 1023), “master”: “MySQL002A”, “slave”: “MySQL002B”}, ... {“range”: (3584, 4095), “master”: “MySQL008A”, “slave”: “MySQL008B”}]
Diese Konfiguration ändert sich nur, wenn Shards verschoben oder der Host ersetzt werden muss. Wenn der
master stirbt, können wir den vorhandenen
slave und dann einen neuen aufnehmen. Die Konfiguration befindet sich in
ZooKeeper und wird bei Aktualisierung an Dienste gesendet, die MySQL-Shard bereitstellen.
Jeder Shard hat den gleichen Satz von Tabellen:
pins ,
boards ,
users_has_pins ,
users_likes_pins ,
pin_liked_by_user usw. Ich werde etwas später darüber sprechen.
Wie verteilen wir Daten für diese Shards?
Wir erstellen eine 64-Bit-ID, die die ID des Shards, den darin enthaltenen Datentyp und die Stelle enthält, an der sich diese Daten in der Tabelle befinden (lokale ID). Die Shard-ID besteht aus 16 Bit, die Typ-ID beträgt 10 Bit und die lokale ID beträgt 36 Bit. Fortgeschrittene Mathematiker werden feststellen, dass es nur 62 Bit gibt. Meine Erfahrung als Compiler und Leiterplattenentwickler hat mich gelehrt, dass Backup-Bits Gold wert sind. Wir haben also zwei solche Bits (auf Null gesetzt).
ID = (shard ID << 46) | (type ID << 36) | (local ID<<0)
Nehmen wir diesen Pin:
https://www.pinterest.com/pin/241294492511762325/ , analysieren wir seine ID 241294492511762325:
Shard ID = (241294492511762325 >> 46) & 0xFFFF = 3429 Type ID = (241294492511762325 >> 36) & 0x3FF = 1 Local ID = (241294492511762325 >> 0) & 0xFFFFFFFFF = 7075733
Somit lebt das Stiftobjekt in 3429 Shard. Sein Typ ist "1" (dh "Pin") und er steht in Zeile 7075733 in der Pin-Tabelle. Stellen wir uns zum Beispiel vor, dieser Shard befindet sich in MySQL012A. Wir können es wie folgt erreichen:
conn = MySQLdb.connect(host=”MySQL012A”) conn.execute(“SELECT data FROM db03429.pins where local_id=7075733”)
Es gibt zwei Arten von Daten: Objekte und Zuordnungen. Objekte enthalten Teile wie Pin-Daten.
Objekttabellen
Objekttabellen wie Pins, Benutzer, Boards und Kommentare haben eine ID (lokale ID mit einem automatisch ansteigenden Primärschlüssel) und einen Blob, der JSON mit allen Objektdaten enthält.
CREATE TABLE pins ( local_id INT PRIMARY KEY AUTO_INCREMENT, data TEXT, ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) ENGINE=InnoDB;
Pin-Objekte sehen beispielsweise folgendermaßen aus:
{“details”: “New Star Wars character”, “link”: “http://webpage.com/asdf”, “user_id”: 241294629943640797, “board_id”: 241294561224164665, …}
Um einen neuen Pin zu erstellen, sammeln wir alle Daten und erstellen einen JSON-Blob. Dann wählen wir die Shard-ID aus (wir bevorzugen es, dieselbe Shard-ID wie die Karte zu wählen, auf der sie platziert ist, dies ist jedoch nicht erforderlich). Für Pin-Typ 1. Wir stellen eine Verbindung zu dieser Datenbank her und fügen JSON in die Pin-Tabelle ein. MySQL gibt eine automatisch erhöhte lokale ID zurück. Jetzt haben wir einen Shard, einen Typ und eine neue lokale ID, damit wir eine vollständige 64-Bit-ID kompilieren können!
Um den Pin zu bearbeiten, lesen, ändern und schreiben wir JSON mithilfe der
MySQL-Transaktion :
> BEGIN > SELECT blob FROM db03429.pins WHERE local_id=7075733 FOR UPDATE [Modify the json blob] > UPDATE db03429.pins SET blob='<modified blob>' WHERE local_id=7075733 > COMMIT
Um einen Pin zu entfernen, können Sie seine Zeile in MySQL löschen. Es ist jedoch besser, das Feld
"aktiv" in JSON hinzuzufügen und auf
"falsch" zu setzen sowie die Ergebnisse auf der Clientseite zu filtern.
Zuordnungstabellen
Die Zuordnungstabelle verknüpft ein Objekt mit einem anderen, z. B. einer Karte mit Stiften. Die MySQL-Tabelle für Zuordnungen enthält drei Spalten: 64-Bit für die ID "from", 64-Bit für die ID "where" und die Sequenz-ID. In diesem Tripel (von wo, wo, Sequenz) gibt es Indexschlüssel, und sie befinden sich auf dem Shard des Bezeichners "von".
CREATE TABLE board_has_pins ( board_id INT, pin_id INT, sequence INT, INDEX(board_id, pin_id, sequence) ) ENGINE=InnoDB;
Zuordnungstabellen sind beispielsweise unidirektional, wie die Tabelle
board_has_pins . Wenn Sie die entgegengesetzte Richtung benötigen, benötigen Sie eine separate
pin_owned_by_board Tabelle. Die Sequenz-ID definiert die Sequenz (unsere IDs können nicht zwischen Shards verglichen werden, da die neuen lokalen IDs unterschiedlich sind). Normalerweise fügen wir neue Pins auf einer neuen Karte mit einer Sequenz-ID ein, die der Zeit in Unix (Unix-Zeitstempel) entspricht. Eine beliebige Anzahl kann in der Sequenz enthalten sein, aber die Unix-Zeit ist eine gute Möglichkeit, neue Materialien nacheinander zu speichern, da dieser Indikator monoton ansteigt. Sie können sich die Daten in der Zuordnungstabelle ansehen:
SELECT pin_id FROM board_has_pins WHERE board_id=241294561224164665 ORDER BY sequence LIMIT 50 OFFSET 150
Dadurch erhalten Sie mehr als 50 pin_id, mit denen Sie dann nach Pin-Objekten suchen können.
Was wir gerade gemacht haben, ist ein Join auf Anwendungsebene (board_id -> pin_id -> pin-Objekte). Eine der erstaunlichen Eigenschaften von Verbindungen auf Anwendungsebene besteht darin, dass Sie das Bild getrennt vom Objekt zwischenspeichern können. Wir speichern pin_id im Cache des Pin-Objekts im Memcache-Cluster, speichern jedoch board_id in pin_id im Redis-Cluster. Auf diese Weise können wir die richtige Technologie auswählen, die am besten zum zwischengespeicherten Objekt passt.
Kapazität erhöhen
Es gibt drei Möglichkeiten, um die Kapazität in unserem System zu erhöhen. Der einfachste Weg, die Maschine zu aktualisieren (um den Speicherplatz zu vergrößern, schnellere Festplatten zu installieren, mehr RAM).
Der nächste Weg, um die Kapazität zu erhöhen, besteht darin, neue Bereiche zu erschließen. Zunächst haben wir insgesamt 4096 Shards erstellt, obwohl die Shard-ID aus 16 Bit bestand (insgesamt 64.000 Shards). Neue Objekte können nur in diesen ersten 4k-Shards erstellt werden. Irgendwann beschlossen wir, neue MySQL-Server mit Shards von 4096 bis 8191 zu erstellen und diese zu füllen.
Der letzte Weg, die Kapazität zu erhöhen, besteht darin, einige Scherben auf neue Maschinen zu verlagern. Wenn wir die Kapazität von MySQL001A (mit Shards von 0 auf 511) erhöhen möchten, erstellen wir ein neues Master-Master-Paar mit den folgenden möglichen Namen (z. B. MySQL009A und B) und starten die Replikation von MySQL001A.
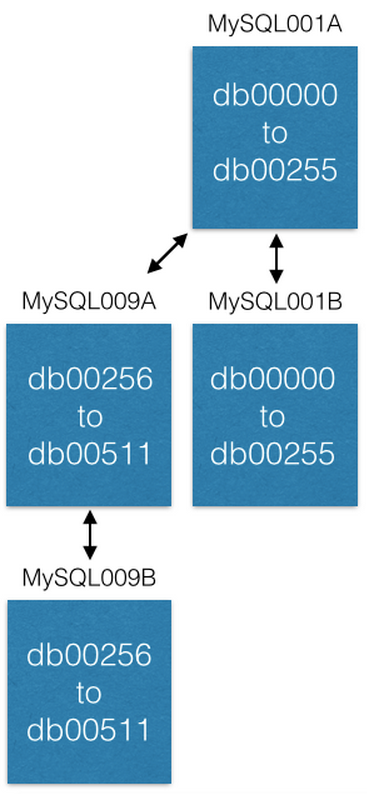
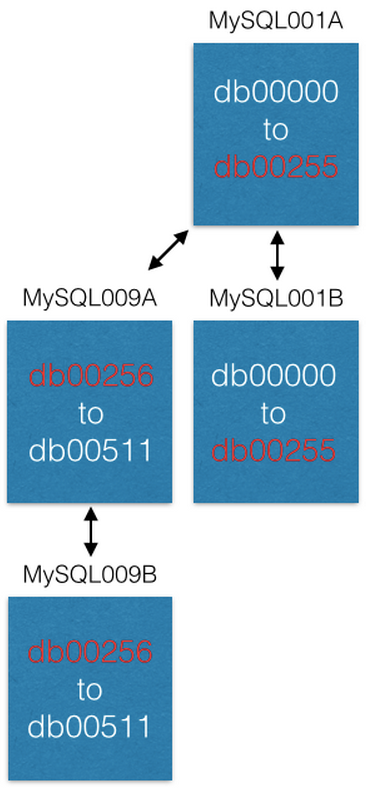
Sobald die Replikation abgeschlossen ist, ändern wir unsere Konfiguration so, dass in MySQL001A nur Shards von 0 bis 255 und in MySQL009A von 256 bis 511 vorhanden sind. Jetzt sollte jeder Server nur die Hälfte der zuvor verarbeiteten Shards verarbeiten.
Einige coole Features
Diejenigen, die bereits Systeme zur Generierung neuer
UUIDs hatten, werden verstehen, dass wir sie in diesem System kostenlos erhalten! Wenn Sie ein neues Objekt erstellen und in die Objekttabelle einfügen, wird eine neue lokale Kennung zurückgegeben. Diese lokale ID gibt Ihnen in Kombination mit der Shard-ID und der Typ-ID eine UUID.
Diejenigen unter Ihnen, die ALTERs ausgeführt haben, um MySQL-Tabellen weitere Spalten hinzuzufügen, wissen, dass sie extrem langsam arbeiten und zu einem großen Problem werden können. Unser Ansatz erfordert keine Änderungen der MySQL-Ebene. Auf Pinterest haben wir in den letzten drei Jahren wahrscheinlich nur einen ALTER gemacht. Um Objekten neue Felder hinzuzufügen, teilen Sie Ihren Diensten einfach mit, dass das JSON-Schema mehrere neue Felder enthält. Sie können den Standardwert so ändern, dass Sie beim Deserialisieren von JSON von einem Objekt ohne neues Feld den Standardwert erhalten. Wenn Sie eine Zuordnungstabelle benötigen, erstellen Sie eine neue Zuordnungstabelle und füllen Sie sie, wann immer Sie möchten. Und wenn Sie fertig sind, können Sie senden!
Mod Shard
Es ist fast wie bei einem
Mod-Team , nur völlig anders.
Einige Objekte müssen ohne ID gefunden werden. Wenn sich ein Benutzer beispielsweise mit einem Facebook-Konto anmeldet, muss die Zuordnung von der Facebook-ID zur Pinterest-ID erfolgen. Für uns sind Facebook-IDs nur Bits, daher speichern wir sie in einem separaten Shard-System namens Mod Shard.
Andere Beispiele sind IP-Adressen, Benutzername und E-Mail-Adresse.
Mod Shard ist dem im vorherigen Abschnitt beschriebenen Sharding-System sehr ähnlich. Der einzige Unterschied besteht darin, dass Sie mit beliebigen Eingabedaten nach Daten suchen können. Diese Eingabe wird gehasht und entsprechend der Gesamtzahl der Shards im System geändert. Als Ergebnis wird ein Shard erhalten, auf dem sich die Daten befinden oder bereits befinden. Zum Beispiel:
shard = md5(“1.2.3.4") % 4096
In diesem Fall ist der Shard gleich 1524. Wir verarbeiten die Konfigurationsdatei entsprechend der Shard-ID:
[{“range”: (0, 511), “master”: “msdb001a”, “slave”: “msdb001b”}, {“range”: (512, 1023), “master”: “msdb002a”, “slave”: “msdb002b”}, {“range”: (1024, 1535), “master”: “msdb003a”, “slave”: “msdb003b”}, …]
Um Daten auf der IP-Adresse 1.2.3.4 zu finden, müssen wir daher Folgendes tun:
conn = MySQLdb.connect(host=”msdb003a”) conn.execute(“SELECT data FROM msdb001a.ip_data WHERE ip='1.2.3.4'”)
Sie verlieren einige gute Eigenschaften der Shard-ID, z. B. die räumliche Lokalität. Sie müssen mit allen am Anfang erstellten Shards beginnen und den Schlüssel selbst erstellen (er wird nicht automatisch generiert). Es ist immer besser, Objekte auf Ihrem System mit unveränderlichen IDs darzustellen. So müssen Sie nicht viele Links aktualisieren, wenn der Benutzer beispielsweise seinen "Benutzernamen" ändert.
Letzte Gedanken
Dieses System läuft seit 3,5 Jahren auf Pinterest und wird wahrscheinlich für immer dort bleiben. Die Implementierung war relativ einfach, aber die Inbetriebnahme und das Verschieben aller Daten von alten Maschinen war schwierig. Wenn Sie beim Erstellen eines neuen Shards auf ein Problem stoßen, sollten Sie einen Cluster von Hintergrunddatenverarbeitungsmaschinen erstellen (Hinweis: Verwenden Sie
Pyren ), um Ihre Daten mit Skripten aus alten Datenbanken in Ihren neuen Shard zu verschieben. Ich garantiere, dass einige der Daten verloren gehen, egal wie sehr Sie es versuchen (es sind alles Gremlins, ich schwöre), also wiederholen Sie die Datenübertragung immer wieder, bis die Menge an neuen Informationen im Shard sehr gering oder gar nicht mehr wird.
Es wurden alle Anstrengungen unternommen, um dieses System zu erreichen. Aber es bietet in keiner Weise Atomizität, Isolation oder Kohärenz. Wow! Das hört sich schlecht an! Aber mach dir keine Sorgen. Sicherlich werden Sie sich ohne sie ausgezeichnet fühlen. Sie können diese Ebenen bei Bedarf jederzeit mit anderen Prozessen / Systemen erstellen, aber standardmäßig und kostenlos erhalten Sie bereits eine Menge: Arbeitskapazität. Zuverlässigkeit durch Einfachheit erreicht und arbeitet sogar schnell!
Aber was ist mit Fehlertoleranz? Wir haben einen Dienst für die Wartung von MySQL-Shards erstellt und die Shard-Konfigurationstabelle in ZooKeeper gespeichert. Wenn der Master-Server abstürzt, heben wir den Slave-Computer an und dann den Computer, der ihn ersetzen wird (immer auf dem neuesten Stand). Wir verwenden bis heute keine automatische Fehlerbearbeitung.