Hallo Habr.
Im
vorherigen Teil wurde Habrs Anwesenheit anhand der Hauptparameter analysiert - der Anzahl der Artikel, ihrer Ansichten und Bewertungen. Die Frage nach der Beliebtheit der Abschnitte der Website wurde jedoch nicht berücksichtigt. Es wurde interessant, dies genauer zu untersuchen und die beliebtesten und unbeliebtesten Hubs zu finden. Abschließend werde ich den „Geektimes-Effekt“ genauer untersuchen und am Ende erhalten die Leser eine neue Auswahl der besten Artikel zu den neuen Bewertungen.
Wen kümmert es, was passiert ist, fuhr unter dem Schnitt fort.
Ich erinnere Sie noch einmal daran, dass Statistiken und Bewertungen nicht offiziell sind, ich habe keine Insiderinformationen. Es kann auch nicht garantiert werden, dass ich mich nicht irgendwo geirrt habe oder etwas nicht verpasst habe. Trotzdem finde ich es interessant. Wir beginnen zuerst mit dem Code, für den dies irrelevant ist. Die ersten Abschnitte können übersprungen werden.
Datenerfassung
In der ersten Version des Parsers wurden nur die Anzahl der Aufrufe, Kommentare und die Bewertung der Artikel berücksichtigt. Dies ist bereits gut, ermöglicht jedoch keine komplexeren Abfragen. Es ist an der Zeit, die thematischen Abschnitte der Website zu analysieren. Auf diese Weise können wir interessante Studien durchführen, um beispielsweise festzustellen, wie sich die Popularität des Abschnitts "C ++" über mehrere Jahre verändert hat.
Der Artikel-Parser wurde verbessert und gibt nun die Hubs zurück, zu denen der Artikel gehört, sowie den Spitznamen des Autors und seine Bewertung (hier können Sie auch viele interessante Dinge tun, aber dies später). Die Daten werden in einer CSV-Datei vom ungefähr folgenden Typ gespeichert:
2018-12-18T12:43Z,https://habr.com/ru/post/433550/," Slack — , , ",votes:7,votesplus:8,votesmin:1,bookmarks:32, views:8300,comments:10,user:ReDisque,karma:5,subscribers:2,hubs:productpm+soft ...
Holen Sie sich eine Liste der wichtigsten thematischen Hubs der Website.
def get_as_str(link: str) -> Str: try: r = requests.get(link) return Str(r.text) except Exception as e: return Str("") def get_hubs(): hubs = [] for p in range(1, 12): page_html = get_as_str("https://habr.com/ru/hubs/page%d/" % p)
Die find_between-Funktion und die Str-Klasse markieren eine Linie zwischen zwei Tags, die ich
zuvor verwendet habe. Thematische Hubs sind mit "*" gekennzeichnet, damit sie leicht hervorgehoben werden können. Sie können auch die entsprechenden Zeilen auskommentieren, um Abschnitte anderer Kategorien zu erhalten.
Am Ausgang der Funktion get_hubs erhalten wir eine ziemlich beeindruckende Liste, die wir als Wörterbuch speichern. Ich zitiere speziell die gesamte Liste, damit das Volumen geschätzt werden kann.
hubs_profile = {'infosecurity', 'programming', 'webdev', 'python', 'sys_admin', 'it-infrastructure', 'devops', 'javascript', 'open_source', 'network_technologies', 'gamedev', 'cpp', 'machine_learning', 'pm', 'hr_management', 'linux', 'analysis_design', 'ui', 'net', 'hi', 'maths', 'mobile_dev', 'productpm', 'win_dev', 'it_testing', 'dev_management', 'algorithms', 'go', 'php', 'csharp', 'nix', 'data_visualization', 'web_testing', 's_admin', 'crazydev', 'data_mining', 'bigdata', 'c', 'java', 'usability', 'instant_messaging', 'gtd', 'system_programming', 'ios_dev', 'oop', 'nginx', 'kubernetes', 'sql', '3d_graphics', 'css', 'geo', 'image_processing', 'controllers', 'game_design', 'html5', 'community_management', 'electronics', 'android_dev', 'crypto', 'netdev', 'cisconetworks', 'db_admins', 'funcprog', 'wireless', 'dwh', 'linux_dev', 'assembler', 'reactjs', 'sales', 'microservices', 'search_technologies', 'compilers', 'virtualization', 'client_side_optimization', 'distributed_systems', 'api', 'media_management', 'complete_code', 'typescript', 'postgresql', 'rust', 'agile', 'refactoring', 'parallel_programming', 'mssql', 'game_promotion', 'robo_dev', 'reverse-engineering', 'web_analytics', 'unity', 'symfony', 'build_automation', 'swift', 'raspberrypi', 'web_design', 'kotlin', 'debug', 'pay_system', 'apps_design', 'git', 'shells', 'laravel', 'mobile_testing', 'openstreetmap', 'lua', 'vs', 'yii', 'sport_programming', 'service_desk', 'itstandarts', 'nodejs', 'data_warehouse', 'ctf', 'erp', 'video', 'mobileanalytics', 'ipv6', 'virus', 'crm', 'backup', 'mesh_networking', 'cad_cam', 'patents', 'cloud_computing', 'growthhacking', 'iot_dev', 'server_side_optimization', 'latex', 'natural_language_processing', 'scala', 'unreal_engine', 'mongodb', 'delphi', 'industrial_control_system', 'r', 'fpga', 'oracle', 'arduino', 'magento', 'ruby', 'nosql', 'flutter', 'xml', 'apache', 'sveltejs', 'devmail', 'ecommerce_development', 'opendata', 'Hadoop', 'yandex_api', 'game_monetization', 'ror', 'graph_design', 'scada', 'mobile_monetization', 'sqlite', 'accessibility', 'saas', 'helpdesk', 'matlab', 'julia', 'aws', 'data_recovery', 'erlang', 'angular', 'osx_dev', 'dns', 'dart', 'vector_graphics', 'asp', 'domains', 'cvs', 'asterisk', 'iis', 'it_monetization', 'localization', 'objectivec', 'IPFS', 'jquery', 'lisp', 'arvrdev', 'powershell', 'd', 'conversion', 'animation', 'webgl', 'wordpress', 'elm', 'qt_software', 'google_api', 'groovy_grails', 'Sailfish_dev', 'Atlassian', 'desktop_environment', 'game_testing', 'mysql', 'ecm', 'cms', 'Xamarin', 'haskell', 'prototyping', 'sw', 'django', 'gradle', 'billing', 'tdd', 'openshift', 'canvas', 'map_api', 'vuejs', 'data_compression', 'tizen_dev', 'iptv', 'mono', 'labview', 'perl', 'AJAX', 'ms_access', 'gpgpu', 'infolust', 'microformats', 'facebook_api', 'vba', 'twitter_api', 'twisted', 'phalcon', 'joomla', 'action_script', 'flex', 'gtk', 'meteorjs', 'iconoskaz', 'cobol', 'cocoa', 'fortran', 'uml', 'codeigniter', 'prolog', 'mercurial', 'drupal', 'wp_dev', 'smallbasic', 'webassembly', 'cubrid', 'fido', 'bada_dev', 'cgi', 'extjs', 'zend_framework', 'typography', 'UEFI', 'geo_systems', 'vim', 'creative_commons', 'modx', 'derbyjs', 'xcode', 'greasemonkey', 'i2p', 'flash_platform', 'coffeescript', 'fsharp', 'clojure', 'puppet', 'forth', 'processing_lang', 'firebird', 'javame_dev', 'cakephp', 'google_cloud_vision_api', 'kohanaphp', 'elixirphoenix', 'eclipse', 'xslt', 'smalltalk', 'googlecloud', 'gae', 'mootools', 'emacs', 'flask', 'gwt', 'web_monetization', 'circuit-design', 'office365dev', 'haxe', 'doctrine', 'typo3', 'regex', 'solidity', 'brainfuck', 'sphinx', 'san', 'vk_api', 'ecommerce'}
Zum Vergleich sehen Geektimes-Abschnitte bescheidener aus:
hubs_gt = {'popular_science', 'history', 'soft', 'lifehacks', 'health', 'finance', 'artificial_intelligence', 'itcompanies', 'DIY', 'energy', 'transport', 'gadgets', 'social_networks', 'space', 'futurenow', 'it_bigraphy', 'antikvariat', 'games', 'hardware', 'learning_languages', 'urban', 'brain', 'internet_of_things', 'easyelectronics', 'cellular', 'physics', 'cryptocurrency', 'interviews', 'biotech', 'network_hardware', 'autogadgets', 'lasers', 'sound', 'home_automation', 'smartphones', 'statistics', 'robot', 'cpu', 'video_tech', 'Ecology', 'presentation', 'desktops', 'wearable_electronics', 'quantum', 'notebooks', 'cyberpunk', 'Peripheral', 'demoscene', 'copyright', 'astronomy', 'arvr', 'medgadgets', '3d-printers', 'Chemistry', 'storages', 'sci-fi', 'logic_games', 'office', 'tablets', 'displays', 'video_conferencing', 'videocards', 'photo', 'multicopters', 'supercomputers', 'telemedicine', 'cybersport', 'nano', 'crowdsourcing', 'infographics'}
Ebenso wurden die verbleibenden Hubs gespeichert. Jetzt ist es einfach, eine Funktion zu schreiben, die das Ergebnis zurückgibt. Der Artikel bezieht sich auf Geektimes oder auf einen Profil-Hub.
def is_geektimes(hubs: List) -> bool: return len(set(hubs) & hubs_gt) > 0 def is_geektimes_only(hubs: List) -> bool: return is_geektimes(hubs) is True and is_profile(hubs) is False def is_profile(hubs: List) -> bool: return len(set(hubs) & hubs_profile) > 0
Ähnliche Funktionen wurden für andere Abschnitte ("Entwicklung", "Verwaltung" usw.) erstellt.
Verarbeitung
Es ist Zeit, mit der Analyse zu beginnen. Wir laden den Datensatz und verarbeiten die Daten der Hubs.
def to_list(s: str) -> List[str]:
Jetzt können wir die Daten nach Tag gruppieren und die Anzahl der Veröffentlichungen nach verschiedenen Hubs anzeigen.
g = df.groupby(['date']) days_count = g.size().reset_index(name='counts') year_days = days_count['date'].values grouped = g.sum().reset_index() profile_per_day_avg = grouped['is_profile'].rolling(window=20, min_periods=1).mean() geektimes_per_day_avg = grouped['is_geektimes'].rolling(window=20, min_periods=1).mean() geektimesonly_per_day_avg = grouped['is_geektimes_only'].rolling(window=20, min_periods=1).mean() admin_per_day_avg = grouped['is_admin'].rolling(window=20, min_periods=1).mean() develop_per_day_avg = grouped['is_develop'].rolling(window=20, min_periods=1).mean()
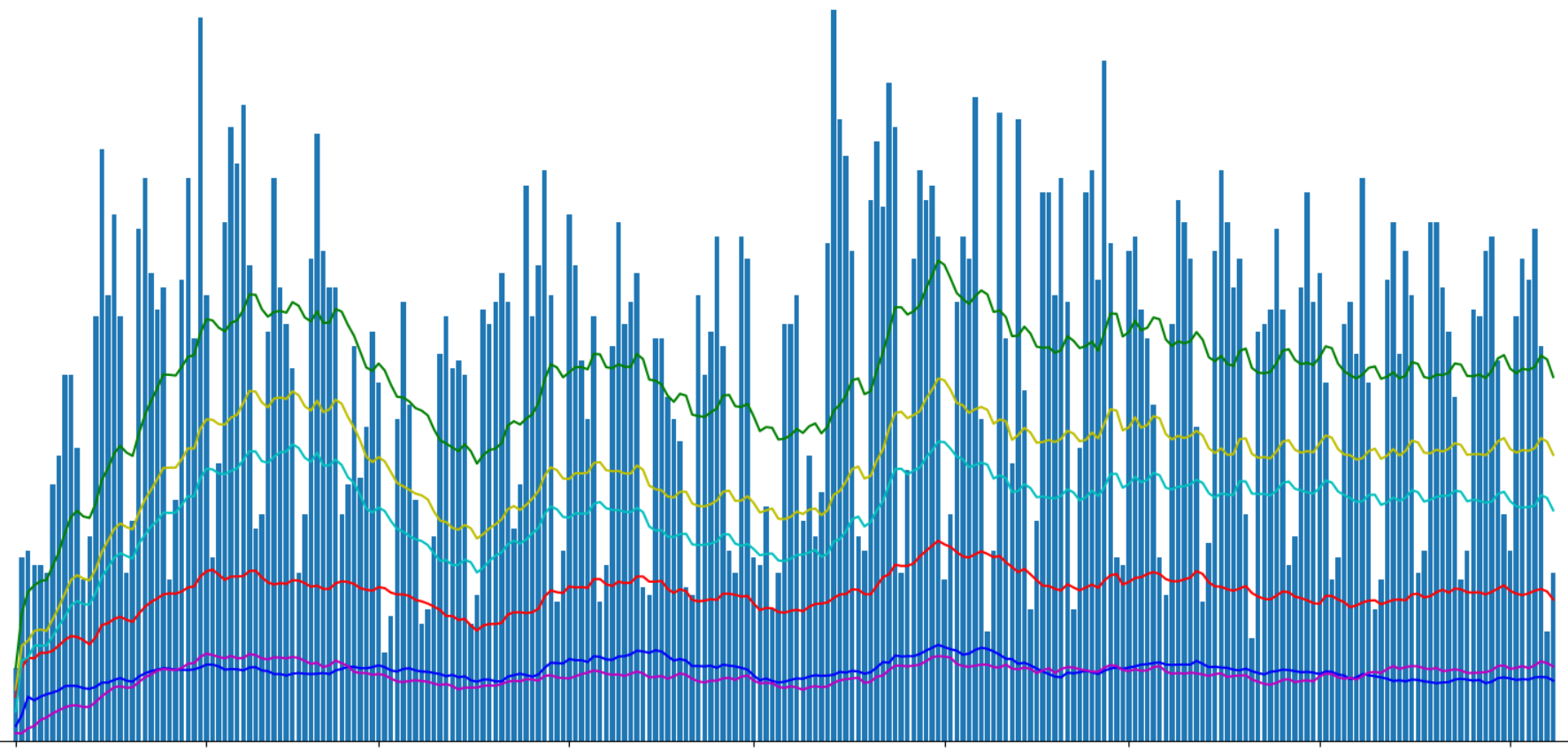
Zeigen Sie die Anzahl der veröffentlichten Artikel mit Matplotlib an:

Ich habe die Artikel "Geektimes" und "Nur Geektimes" in der Grafik unterteilt, weil Ein Artikel kann gleichzeitig zu beiden Abschnitten gehören (z. B. „DIY“ + „Mikrocontroller“ + „C ++“). Mit der Bezeichnung „Profil“ habe ich die Profilartikel der Website hervorgehoben, obwohl es möglich ist, dass der englische Begriff Profil dafür nicht ganz korrekt ist.
Im vorherigen Teil haben wir nach dem "Geektimes-Effekt" gefragt, der mit der Änderung der Regeln für die Bezahlung von Artikeln für Geektimes ab diesem Sommer verbunden ist. Wir leiten separate Geektimes-Artikel ab:
df_gt = df[(df['is_geektimes_only'] == True)] group_gt = df_gt.groupby(['date']) days_count_gt = group_gt.size().reset_index(name='counts') grouped = group_gt.sum().reset_index() year_days_gt = days_count_gt['date'].values view_gt_per_day_avg = grouped['views'].rolling(window=20, min_periods=1).mean()
Das Ergebnis ist interessant. Das ungefähre Verhältnis der Ansichten von Artikeln geektimes zur Gesamtzahl liegt irgendwo bei 1: 5. Wenn jedoch die Gesamtzahl der Aufrufe merklich schwankte, wurde die Anzeige von "unterhaltsamen" Artikeln ungefähr auf dem gleichen Niveau gehalten.

Sie können auch feststellen, dass die Gesamtzahl der Aufrufe von Artikeln im Abschnitt "Geektimes" nach Änderung der Regeln immer noch gesunken ist, jedoch "per Auge" nicht mehr als 5% der Gesamtwerte.
Es ist interessant, die durchschnittliche Anzahl der Aufrufe pro Artikel zu sehen:

Für "unterhaltsame" Artikel sind es etwa 40% über dem Durchschnitt. Dies ist wahrscheinlich nicht überraschend. Der Fehler Anfang April ist mir nicht klar, vielleicht war es das, oder ist es eine Art Analysefehler, oder vielleicht hat einer der Autoren geektimes Urlaub gemacht;).
Übrigens sind in der Grafik zwei weitere auffällige Spitzen in der Anzahl der Artikelansichten zu sehen - Neujahrs- und Mai-Feiertage.
Hubs
Fahren wir mit der versprochenen Analyse der Hubs fort. Wir werden die Top 20 Hubs nach Anzahl der Aufrufe anzeigen:
hubs_info = [] for hub_name in hubs_all: mask = df['hubs'].apply(lambda x: hub_name in x) df_hub = df[mask] count, views = df_hub.shape[0], df_hub['views'].sum() hubs_info.append((hub_name, count, views))
Ergebnis:

Überraschenderweise erwies sich der Hub „Informationssicherheit“ als der beliebteste in Bezug auf die Anzeige. Auch „Programmierung“ und „Populärwissenschaft“ gehören zu den Top 5 der führenden Unternehmen.
Antitop nimmt Gtk und Kakao.

Ich werde Ihnen ein Geheimnis verraten, die Top-Hubs sind auch hier zu sehen, obwohl die Anzahl der Ansichten dort nicht angezeigt wird.
Bewertung
Und schließlich die versprochene Bewertung. Mit den Daten aus der Analyse von Hubs können wir die beliebtesten Artikel zu den beliebtesten Hubs für dieses Jahr 2019 anzeigen.
Informationssicherheit- Wie ich ein Jahr lang nicht bei Sberbank gearbeitet habe 304000 Aufrufe, 599 Kommentare, Bewertung + 457.0 / -14.0
- Intelligente Glühbirnen, die in den Papierkorb geworfen werden, sind eine wertvolle Quelle für persönliche Informationen. 232.000 Aufrufe, 147 Kommentare, Bewertung + 75,0 / -11,0
- Betrüger und EDS - alles ist sehr schlecht 176.000 Aufrufe, 778 Kommentare, Bewertung + 356.0 / -0.0
- Wie Megafon auf Mobilabonnements geschlafen hat 166.000 Aufrufe, 676 Kommentare, Bewertung + 624.0 / -2.0
- Durch das Hacken von VK und der Zwei-Faktor-Authentifizierung werden 148.000 Aufrufe, 332 Kommentare und eine Bewertung von + 124,0 / -17,0 nicht gespeichert
- Wie der Browser Genosse Major hilft 132.000 Aufrufe, 321 Kommentare, Bewertung + 246.0 / -19.0
- Der größte Dump in der Geschichte: 2,7 Milliarden Konten, davon 773 Millionen eindeutige 123.000 Aufrufe, 154 Kommentare, Bewertung + 86,0 / -5,0
- Schatz, wir töten das Internet 121.000 Aufrufe, 933 Kommentare, Bewertung + 392.0 / -83.0
- 'Mobile Inhalte' kostenlos, ohne SMS und Registrierung. Megafon-Betrugsdetails 114.000 Aufrufe, 478 Kommentare, Bewertung + 488.0 / -8.0
- Port-Scanner im persönlichen Konto von Rostelecom 111.000 Aufrufe, 194 Kommentare, Bewertung + 300.0 / -8.0
Programmierung- Über einen Mann 167.000 Aufrufe, 249 Kommentare, Bewertung + 239.0 / -33.0
- Je schneller Sie OOP vergessen, desto besser für Sie und Ihre Programme 129.000 Aufrufe, 1271 Kommentare, Bewertung + 131,0 / -63,0
- Warum Senior-Entwickler keinen Job bekommen können 119.000 Aufrufe, 901 Kommentare, Bewertung + 151.0 / -14.0
- Alte Leute gehören nicht hierher? Wir programmieren nach fünfunddreißig 116.000 Ansichten, 649 Kommentaren, Bewertung + 222,0 / -16,0
- Neue Programmiersprachen zerstören unmerklich unsere Verbindung zur Realität 106.000 Aufrufe, 764 Kommentare, Bewertung + 164.0 / -52.0
- Was ich aus meiner bitteren Erfahrung (über 30 Jahre in der Softwareentwicklung) gelernt habe 101.000 Aufrufe, 128 Kommentare, Bewertung + 178.0 / -9.0
- Die seltensten und teuersten Programmiersprachen 82900 Aufrufe, 119 Kommentare, Bewertung + 38.0 / -10.0
- Vorlesung in JavaScript und Node.js in den KPI 80300-Ansichten, 14 Kommentare, Bewertung + 34.0 / -2.0
- IT-Begriffe am Beispiel des Kartoffelanbaus 78000 Aufrufe, 86 Kommentare, Bewertung + 84,0 / -14,0
- 256 Zeilen nacktes C ++: Schreiben eines Raytracers von Grund auf in wenigen Stunden 77600 Aufrufe, 124 Kommentare, Bewertung + 241.0 / -0.0
Populärwissenschaft- Was der Designer geraucht hat: eine ungewöhnliche Waffe 236.000 Aufrufe, 123 Kommentare, Bewertung + 119.0 / -9.0
- Wissenschaftler haben das älteste lebende Wirbeltier auf der Erde gefunden 234.000 Aufrufe, 212 Kommentare, Bewertung + 82,0 / -14,0
- Die Serie 'Tschernobyl': 173.000 Aufrufe, 803 Kommentare, Bewertung + 164.0 / -25.0
- Ein 12-jähriger Teenager führte in seinem Heimlabor eine Kernfusionsreaktion durch. 145.000 Aufrufe, 280 Kommentare, Bewertung + 126,0 / -29,0
- Die Geschichte der Rosenlegierung und der gefallenen Krenka 134.000 Aufrufe, 244 Kommentare, Bewertung + 217.0 / -1.0
- Erhöhen Sie es! Moderne Erhöhung der Auflösung 134000 Aufrufe, 235 Kommentare, Bewertung + 377.0 / -1.0
- Die Software für die Boeing-737 Max wurde von Outsourcern geschrieben, die 9 US-Dollar pro Stunde , 126.000 Aufrufe, 560 Kommentare und eine Bewertung von + 153,0 / -6,0 verdienten
- Seien Sie nicht nervös, beeilen Sie sich nicht, unterbrechen Sie nicht: Die Geschichte einer Tragödie 121.000 Aufrufe, 384 Kommentare, Bewertung + 242.0 / -4.0
- Mathematiker haben den perfekten Weg gefunden, um Zahlen mit 108.000 Ansichten, 222 Kommentaren und einer Bewertung von + 173,0 / -10,0 zu multiplizieren
- Neue Programmiersprachen zerstören unmerklich unsere Verbindung zur Realität 106.000 Aufrufe, 764 Kommentare, Bewertung + 164.0 / -52.0
Karriere- Wie ich ein Jahr lang nicht bei Sberbank gearbeitet habe 304000 Aufrufe, 599 Kommentare, Bewertung + 457.0 / -14.0
- Ich ruiniere das Leben der Entwickler mit meinen Code-Bewertungen und es tut mir leid, 187.000 Aufrufe, 21 Kommentare, Bewertung + 37.0 / -3.0
- Development King 179.000 Aufrufe, 668 Kommentare, Bewertung + 315.0 / -60.0
- Über einen Mann 167.000 Aufrufe, 249 Kommentare, Bewertung + 239.0 / -33.0
- Bei 22.158.000 Aufrufe, 927 Kommentare, Bewertung + 259.0 / -100.0 im Ruhestand
- Wie ersetze ich eine Glühbirne am Arbeitsplatz, damit Sie nicht gefeuert werden? 139000 Aufrufe, 762 Kommentare, Bewertung + 200.0 / -20.0
- Innovation in Russisch 128.000 Aufrufe, 612 Kommentare, Bewertung + 480.0 / -33.0
- Warum Senior-Entwickler keinen Job bekommen können 119.000 Aufrufe, 901 Kommentare, Bewertung + 151.0 / -14.0
- 'Verbrannte' Mitarbeiter: Gibt es einen Ausweg? 117000 Aufrufe, 398 Kommentare, Bewertung + 210.0 / -14.0
- Alte Leute gehören nicht hierher? Wir programmieren nach fünfunddreißig 116.000 Ansichten, 649 Kommentaren, Bewertung + 222,0 / -16,0
Gesetzgebung in der IT- Betrüger und EDS - alles ist sehr schlecht 176.000 Aufrufe, 778 Kommentare, Bewertung + 356.0 / -0.0
- Wie Megafon auf Mobilabonnements geschlafen hat 166.000 Aufrufe, 676 Kommentare, Bewertung + 624.0 / -2.0
- Innovation in Russisch 128.000 Aufrufe, 612 Kommentare, Bewertung + 480.0 / -33.0
- 'Mobile Inhalte' kostenlos, ohne SMS und Registrierung. Megafon-Betrugsdetails 114.000 Aufrufe, 478 Kommentare, Bewertung + 488.0 / -8.0
- Während die kasachischen Behörden versuchen, ihr Versagen mit der Einführung des Zertifikats zu vertuschen, 111.000 Aufrufe, 77 Kommentare, Bewertung + 122,0 / -14,0
- Wie Protonmail in Russland blockiert wird 102000 Aufrufe, 398 Kommentare, Bewertung + 418.0 / -7.0
- Das Gesetz zur Isolierung der Runen wurde von der Staatsduma in drei Lesungen mit 88.200 Ansichten, 878 Kommentaren und einer Bewertung von + 73,0 / -18,0 verabschiedet
- Als Programmierer wählte und las die Bank den Vertrag mit 87.200 Ansichten, 611 Kommentaren und einem Rating von + 166,0 / -9,0
- Das Ministerium für Kommunikation und Massenmedien hat den Gesetzesentwurf zur Isolierung von Runet 83600-Ansichten, 364 Kommentaren und einer Bewertung von + 79,0 / -9,0 gebilligt
- Eine ausführliche Antwort auf den Kommentar sowie ein wenig über das Leben der Anbieter in der Russischen Föderation, 74700 Aufrufe, 389 Kommentare, Bewertung + 290,0 / -1,0
Webentwicklung- Alte Leute gehören nicht hierher? Wir programmieren nach fünfunddreißig 116.000 Ansichten, 649 Kommentaren, Bewertung + 222,0 / -16,0
- So erstellen Sie Websites im Jahr 2019 110.000 Aufrufe, 278 Kommentare, Bewertung + 233.0 / -11.0
- Learning Docker, Teil 1: Grundlagen 91300 Ansichten, 24 Kommentare, Bewertung + 52.0 / -10.0
- Vorlesung in JavaScript und Node.js in den KPI 80300-Ansichten, 14 Kommentare, Bewertung + 34.0 / -2.0
- Trainee Vasya und seine Geschichten über Idempotenz API 68900 Aufrufe, 160 Kommentare, Bewertung + 216.0 / -3.0
- Das Verständnis von Joins ist gebrochen. Dies ist definitiv nicht der Schnittpunkt von Kreisen, ehrlich gesagt 65.900 Aufrufe, 223 Kommentare, Bewertung + 138.0 / -41.0
- Warum Sie Ihre Zeit nicht damit verbringen müssen, thematische Nischen-Websites zu erstellen 62700 Aufrufe, 243 Kommentare, Bewertung + 179,0 / -13,0
- Wir machen eine moderne Webanwendung von Grund auf neu 62200 Aufrufe, 122 Kommentare, Bewertung + 56.0 / -8.0
- Ein dunkler Tag für Vue.js 60.800 Aufrufe, 133 Kommentare, Bewertung + 77.0 / -6.0
- Warum ist moderne Webentwicklung so kompliziert? Teil 1.577.700 Aufrufe, 319 Kommentare, Bewertung + 101.0 / -6.0
GTKUnd schließlich, um niemanden zu beleidigen, gebe ich Ihnen die Bewertung des am wenigsten besuchten Hubs "gtk". Darin wurde im Laufe des Jahres
ein Artikel veröffentlicht, der auch „automatisch“ die erste Zeile der Bewertung belegt.
Fazit
Es wird keine Schlussfolgerung geben. Viel Spaß beim Lesen für alle.