CQM sieht beim Deep Learning anders aus, um die Suche in natürlicher Sprache zu optimieren
Kurzbeschreibung: Calibrated Quantum Mesh (CQM) ist der nächste Schritt von RNN / LSTM (Recurrent Neural Networks) / Long Short-Term Memory (LSTM). Es gibt einen neuen Algorithmus namens Calibrated Quantum Mesh (CQM), der verspricht, die Genauigkeit der Suche in natürlicher Sprache ohne die Verwendung gekennzeichneter Trainingsdaten zu erhöhen.
Es wurde ein völlig neuer Algorithmus für die Suche nach natürlicher Sprache (NLS) und das Verständnis der natürlichen Sprache (NLU) entwickelt, der nicht nur die traditionellen RNN / LSTM- oder sogar CNN-Algorithmen übertrifft, sondern auch selbstlernend ist und keine markierten Daten für das Training erfordert.
Es klingt zu schön um wahr zu sein, aber die ersten Ergebnisse sind beeindruckend. CQM - entwickelt von Praful Krishna und seinem Team in Coseer (San Francisco).
Obwohl das Unternehmen noch klein ist, arbeiten sie mit mehreren Fortune 500-Unternehmen zusammen und haben begonnen, technische Konferenzen abzuhalten.
Hier wollen sie sich beweisen:
Genauigkeit: Laut Krishna hat die durchschnittliche NLS-Funktion in einem weniger seriösen Chatbot in der Regel eine Genauigkeit von nur etwa 70%.
Die ersten Anwendungen von Coseer erreichten eine Genauigkeit von mehr als 95% bei der Rückgabe der korrekten relevanten Informationen. Schlüsselwörter sind nicht erforderlich.
Beschriftete Trainingsdaten sind nicht erforderlich: Wir alle wissen, dass beschriftete Trainingsdaten einen finanziellen und zeitlichen Aufwand darstellen, der die Genauigkeit unserer Chat-Bots einschränkt.
Vor einigen Jahren hat M.D. Anderson gab sein teures und jahrelanges Experiment mit IBM Watson für die Onkologie wegen der Genauigkeit auf.
Was die Genauigkeit beeinträchtigte, war die Notwendigkeit für sehr erfahrene Krebsforscher, Dokumente im Gehäuse zu kommentieren. Sie hätten dies tun sollen, anstatt ihre Forschung zu betreiben.
Geschwindigkeit der Implementierung: Laut Coseer können die meisten Bereitstellungen ohne Schulungsdaten innerhalb von 4 bis 12 Wochen gestartet werden. Dies ist viel weniger als wenn der Benutzer beginnt, ein vorab geschultes System zu verwenden, dessen Betrieb mit dem vorläufigen Laden markierter Dokumente beginnt.
Im Gegensatz zu aktuellen großen Anbietern, die herkömmliche Deep-Learning-Algorithmen verwenden, zieht Coseer es außerdem vor, diese sowohl in einer sicheren als auch in einer privaten Cloud bereitzustellen, um die Datensicherheit zu gewährleisten.
Alle „Beweise“, die verwendet werden, um zu einer Schlussfolgerung zu gelangen, werden in einem Journal gespeichert, das zum Nachweis der Transparenz und Einhaltung von Datensicherheitsregeln wie der DSGVO verwendet werden kann.
Wie funktioniert es?
Coseer spricht über die drei Prinzipien, die CQM definieren:
1. Wörter (Variablen) haben unterschiedliche Bedeutungen.
Betrachten Sie das Wort "Ofen", das ein Substantiv oder ein Verb sein kann. Zum Beispiel "Vers", was "Gedicht" oder das Verb "Vers Wind" bedeuten kann - das sind die Wörter Homonyme.
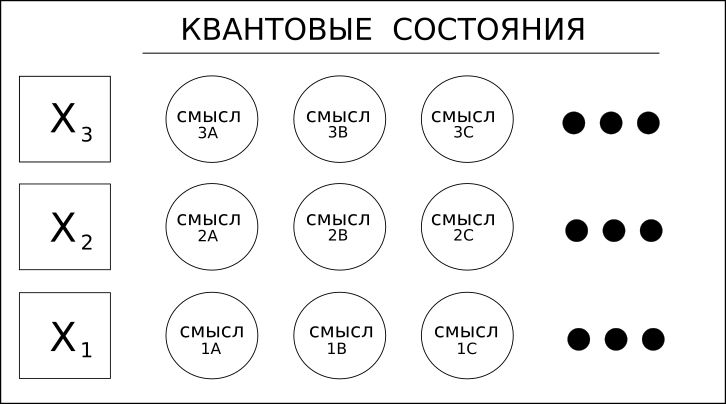
Deep-Learning-Lösungen, einschließlich RNN / LSTM oder sogar CNN für Text, können nur vorwärts oder rückwärts schauen, um den „Kontext“ eines Wortes und damit seine Bedeutung zu bestimmen.
Coseer berücksichtigt alle möglichen Bedeutungen des Wortes und wendet statistische Wahrscheinlichkeit auf jede von ihnen basierend auf dem gesamten Dokument oder Korpus an.
Die Verwendung des Begriffs "Quanten" bezieht sich in diesem Fall nur auf die Möglichkeit mehrerer Werte und nicht auf eine exotischere Überlagerung des Quantencomputers.
2. Alles ist in einem Wertegitter miteinander verbunden:
Das zweite Prinzip besteht darin, aus allen verfügbaren Wörtern (Variablen) alle möglichen Beziehungen zu extrahieren.
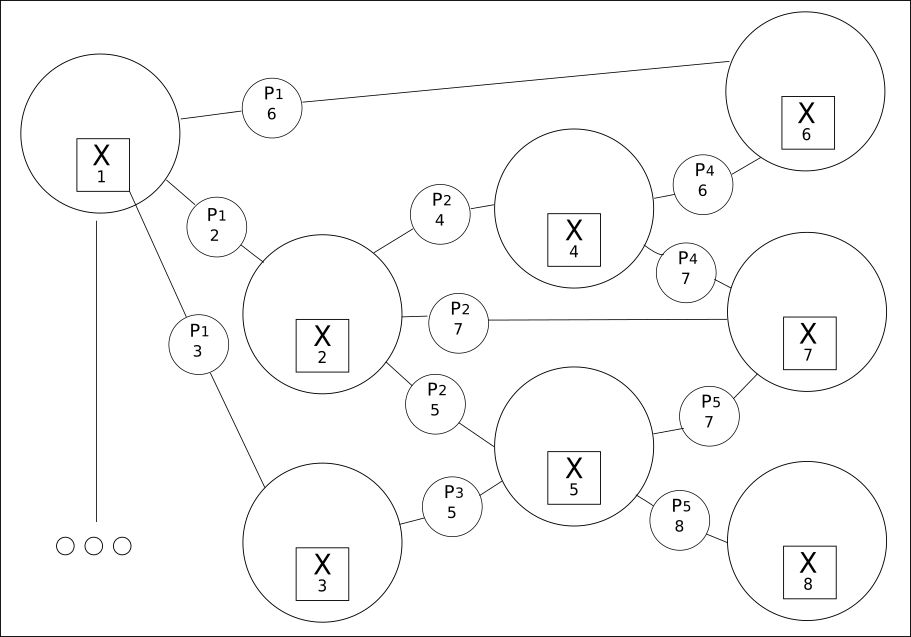
CQM erstellt ein Raster möglicher Werte, unter denen ein realer Wert gefunden wird. Die Verwendung dieses Ansatzes zeigt eine viel breitere Beziehung zwischen vorherigen oder nachfolgenden Phrasen, als dies mit herkömmlichem Deep Learning möglich ist.
Obwohl die Anzahl der Wörter begrenzt sein kann, können ihre Beziehungen Hunderttausende betragen.
3. Alle verfügbaren Informationen werden nacheinander verwendet , um das Raster zu einem einzigen Wert zu kombinieren. Dieser Kalibrierungsprozess erkennt fehlende Wörter oder Konzepte schnell und bietet ein sehr schnelles und genaues Training.
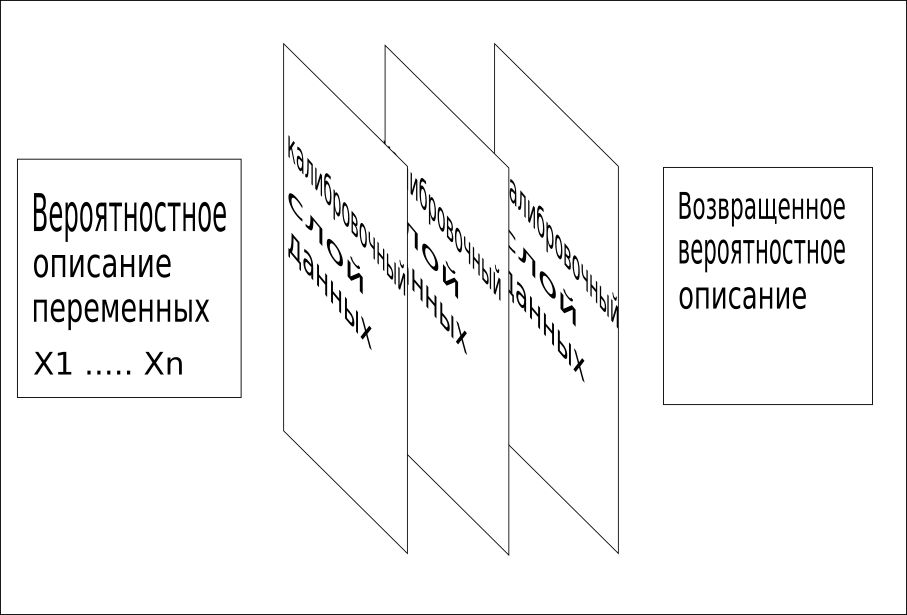
CQM-Modelle verwenden Trainingsdaten, Kontextdaten, Referenzdaten und andere über das Problem bekannte Fakten, um diese Kalibrierungsdatenschichten zu identifizieren.
Leider hat Coseer nur sehr wenig öffentlich veröffentlicht, um die technischen Aspekte des Algorithmus zu erläutern.
Jeder Durchbruch bei der Beseitigung markierter Daten während des Trainings sollte begrüßt werden. Eine Verbesserung der Genauigkeit führt natürlich dazu, dass viel zufriedenere Kunden Ihren Chat-Bot verwenden.