Hallo! Ich heiße Nikita Uchetelev. Ich vertrete Lamoda Research & Development. Wir sind mehr als 20 Mitarbeiter und arbeiten an verschiedenen Empfehlungen auf der Website und in Anwendungen. Wir entwickeln eine Suche, bestimmen die Sortierung von Waren in Katalogen, bieten die Möglichkeit, verschiedene Funktionen von AB zu testen, und unterstützen verschiedene interne Entwicklungen, z. B. ein System zur Vorhersage der Nachfrageelastizität und zur Optimierung der Lieferlogistik.
Eine der wichtigsten Entwicklungsrichtungen des gesamten Unternehmens für die kommenden Jahre ist die Personalisierung unserer Produkte und Dienstleistungen. Solche Initiativen werden überall getestet und umgesetzt - von der Zusammenstellung persönlicher Produktauswahlen bis zur Auswahl eines bestimmten Vertriebsmitarbeiters, der unsere Waren an Sie liefert. Im Rahmen des Personalisierungsprozesses von F & E-Produkten fungiere ich als Teamleiter. In diesem Artikel möchte ich über die Plattform sprechen, die ich und mein Team im letzten Jahr entworfen und entwickelt haben, sowie über die ersten personalisierten F & E-Produkte, die derzeit AB-Tests unterzogen werden.
Ideologie der Produktempfehlungen
Das Attribut eines jeden bekannten Online-Shops ist die Produktseite. Es enthält normalerweise eine detaillierte Beschreibung, mehrere große Fotos, Kundenbewertungen, die Schaltfläche "In den Warenkorb" und andere bekannte Navigationselemente. Am Ende solcher Seiten befinden sich ein oder mehrere Regale mit anderen Produkten, die als "Verwandte Produkte", "Kaufen mit diesem Produkt" oder etwas anderes bezeichnet werden. Jedes Regal hat seinen eigenen Zweck.
Beispielsweise soll ein Regal mit ähnlichen Produkten dem Benutzer eine zusätzliche Produktvielfalt im aktuellen Kontext der Wahl bieten. Dies kann nützlich sein, wenn sich keine Benutzergröße im Bestand befindet oder wenn er sich in der Auswahlphase befindet und dasselbe Produkt möchte, jedoch „mit Perlenknöpfen“. Gleichzeitig entfernt das Regal den Käufer von der Produktseite, zu der er möglicherweise nicht mehr zurückkehrt, und kauft sie dementsprechend nicht.
Auf der Website und in Lamoda-Anwendungen gibt es ein zweites Regal, das wir als empfehlungsübergreifendes Regal bezeichnen . Es befindet sich unmittelbar unter dem Regal mit ähnlichen Waren, und wir versuchen, unterschiedliche Waren darauf zu platzieren, die am häufigsten in Einkaufswagen zusammen mit der aktuellen SKU (Stock Keeping Unit oder einfacher Artikel) zu finden sind. So werden beispielsweise Hosen und Schuhe für Jacken, Schals und Hüte für Pullover empfohlen. Es gibt eine Gruppe preiswerter Waren, die am häufigsten gekauft werden. In der Regel handelt es sich dabei um Socken und Unterwäsche, sodass sie häufig in diesem Regal zu sehen sind.
Diese Verkaufstechnik ähnelt dem Upsale . Wir versuchen, einige große Ergänzungswaren zu verkaufen, vorausgesetzt, der Benutzer mag das aktuelle Produkt. Gleichzeitig ist dies einer der wenigen Orte, an denen Kunden unser Sortiment kennenlernen können. Zum Beispiel, um eine Marke oder Unterkategorie zu sehen, deren Präsenz sie vorher nicht kannten. Wir nennen es Inspiration & Entdeckung - wenn wir Kunden zu neuen Einkäufen inspirieren und uns mitteilen, wie breit unser Sortiment ist, zeigen wir Preise und Rabatte.

In der Vergangenheit wird die Füllung dieser Regale offline berechnet (mit einer Marge, falls einige Produkte vor der nächsten Berechnung nicht mehr vorrätig sind), zusammen mit der Sortierung nach einer Ähnlichkeitsmetrik oder einer bedingten Konvertierung. Somit sehen alle Benutzer dort tagsüber ungefähr dasselbe. Wir haben uns entschlossen, Experimente mit Personalisierung von genau diesen Regalen aus zu starten, da wir auf den Produktseiten genügend Verkehr haben, um Qualitätsexperimente durchzuführen. Aus technischer Sicht erwies sich dies als einer der bequemsten Orte für die Implementierung in unserer Infrastruktur (im Diagramm rot markiert).

Die Idee ist folgende : Wir trainieren ein Modell, das den Paaren „Benutzer + Produkt“ die Conversion-Wahrscheinlichkeit oder nur einen Klick zuweisen kann, und zeigen sie dann in absteigender Reihenfolge dieser Wahrscheinlichkeit von links nach rechts im Regal an. Da auf dem ersten Bildschirm des Karussells je nach Bildschirmauflösung nur 4 bis 6 SKUs angezeigt werden und wir sie insgesamt berechnen können, beispielsweise bis zu Hunderten, wird eine durchaus akzeptable „Tiefe“ der Personalisierung erreicht.
Wir lösen das Problem vom Ende
Kommen wir zum technischen Teil. Wir haben Einschränkungen hinsichtlich der Antwortzeit der API. In Anwendungen muss der zukünftige Dienst beispielsweise rechtzeitig sein, um für 100 ms verantwortlich zu sein. Während dieser Zeit müssen Sie in verschiedenen Datenbanken nach Benutzer- und Produktdaten suchen und hundert Beispiele unter Last bis zu 100 QPS in der Spitze anordnen. Dies führt uns zu der Notwendigkeit, Frameworks für maschinelles Lernen im Submillisekundenbereich zu verwenden . Eines der bekanntesten ist Vowpal Wabbit.
Ein typisches Anwendungsgebiet für dieses Framework ist adtech, nämlich die Vorhersage der Klickrate einer Anzeige bei der Optimierung eines Angebots für eine RTB-Auktion. Aus mathematischer Sicht können wir ein ähnliches Problem aufwerfen. Angenommen, wir möchten die Wahrscheinlichkeit eines Klicks vorhersagen, indem wir ein Modell auf Produktanzeigen trainieren. Die Belastung des Modells mit bis zu 10.000 QPS ist vergleichbar mit der Werbeleistung und rechtfertigt im Allgemeinen die Notwendigkeit, sich auf nur lineare Algorithmen in der Prototyping-Phase und auf MVP zu beschränken.
Lassen Sie uns nun darüber nachdenken, welche Benutzerdaten das von uns benötigte Signal enthalten können, und zwischen Benutzern gut unterscheiden. Da es sich um Produktempfehlungen und die Produktseite handelt, die der Benutzer besucht, befindet er sich höchstwahrscheinlich in der Auswahlphase. Er hat ein bestimmtes Bild von „perfekten Schuhen“ im Kopf, mit dem er alle Waren vergleicht, die ihm auffallen. Lassen Sie ihn zuerst zum Warenkatalog der gewünschten Kategorie gehen und die Suche beginnen, indem Sie auf alles klicken, was seiner Präsentation mehr oder weniger ähnelt. Somit reserviert der Benutzer eine „digitale Spur“ der betrachteten Produkte. Basierend auf der Einheit auf diesem Trail werden wir eine Personalisierung durchführen.
Vektordarstellungen von Objekten
Alle Produkte unterscheiden sich untereinander durch Tabellenwerte einiger Attribute: Farbe, Materialien, Stoffe, Druckart, Ärmellänge, Vorhandensein einer Kapuze, Absatzhöhe usw. Dementsprechend ist es möglich, jede digitale Spur mit Bruchteilen des Auftretens jedes der Werte dieser Attribute zu codieren. Angenommen, wir haben Produkte in drei Farben und drei Marken, die Sie anzeigen und in den Warenkorb legen können. Anhand des Verlaufs der Aktionen eines Benutzers kann er dann einen Vektor der folgenden Form abgleichen:

In diesem Fall betrachtete der Benutzer 10 Produkte: 5 Gold, 2 Schwarz und 3 Rot. Und er fügte 2 rote und 2 schwarze zum Korb hinzu, er fügte kein Gold hinzu. Ähnliches gilt für die Marken A, B und C sowie für alle Attributwerte. Ferner kann ein solcher Vektor mit einem One-Hot-codierten Vektor von Attributwerten für ein bestimmtes Produkt verkettet werden.
Somit können wir ein bestimmtes Ereignis vektorisieren. Ein Benutzer, der im Rahmen der aktuellen Sitzung eine Reihe von Produkten mit einer bestimmten Farbverteilung betrachtet hat, bereitet sich darauf vor, ein neues Produkt zu sehen, z. B. Rot. Mithilfe historischer Daten zu Impressionen und Klicks können Sie ein Modell erstellen, das die Wahrscheinlichkeit eines Klicks auf ein rotes Produkt vorhersagt, sofern eine Farbverteilung für zuvor angezeigte Produkte vorhanden ist.
Wenn Sie sich den Raum ansehen, in dem wir gelernt haben, historische Cliquen darzustellen, können Sie sehen, dass ein Teil von einem binären Unterraum besetzt ist und der andere real ist und sie nicht miteinander verbunden sind. Unser lineares Modell ist in diesem Fall eine lineare Kombination (gewichtete Summe) der Koordinaten von Punkten in diesem Raum. Wenn sie aus solchen Beispielen lernt, lernt sie einfach a priori Wahrscheinlichkeiten. Beispielsweise ist das Gewicht vor der Koordinate, das der roten Farbe der Waren entspricht, ein Wert, der direkt proportional zur Klickrate der roten Waren ist. Daher werden bestimmte Benutzerkoordinaten mit den Häufigkeitseigenschaften von Klicks verschiedener Benutzer für Produkte aus dem Katalog gewichtet. Aber das ist nicht ganz das, was wir möchten.
Polynommerkmale helfen - das Ergebnis der Multiplikation aller binären Größen mit allen realen. Das Vowpal Wabbit-Framework verfügt über ein leistungsstarkes Tool zum Generieren von Leistungsmerkmalen aus Namespaces. Versuchen wir, für unser Beispiel eine Zeile im vw-Format zu erstellen, in der Benutzer- und Warenfunktionen auf verschiedene Namespaces verteilt werden.
|user_color :0.5 :0.2 :0.3 |product_color
Wenn wir nun während des Trainings den Schalter -q pu hinzufügen, werden solche quadratischen Merkmale ungleich Null angezeigt:
user_color^ * product_color^ = 0.5 user_color^ * product_color^ = 0.2 user_color^ * product_color^ = 0.3
Daher sucht das Modell nach einem Signal nicht nur, wie Benutzer mit einem hohen Anteil an angezeigten roten Produkten klicken, sondern auch, wie sie auf rote Produkte klicken. Das Gewicht eines solchen Merkmals im trainierten Modell sollte positiv und ziemlich groß sein.
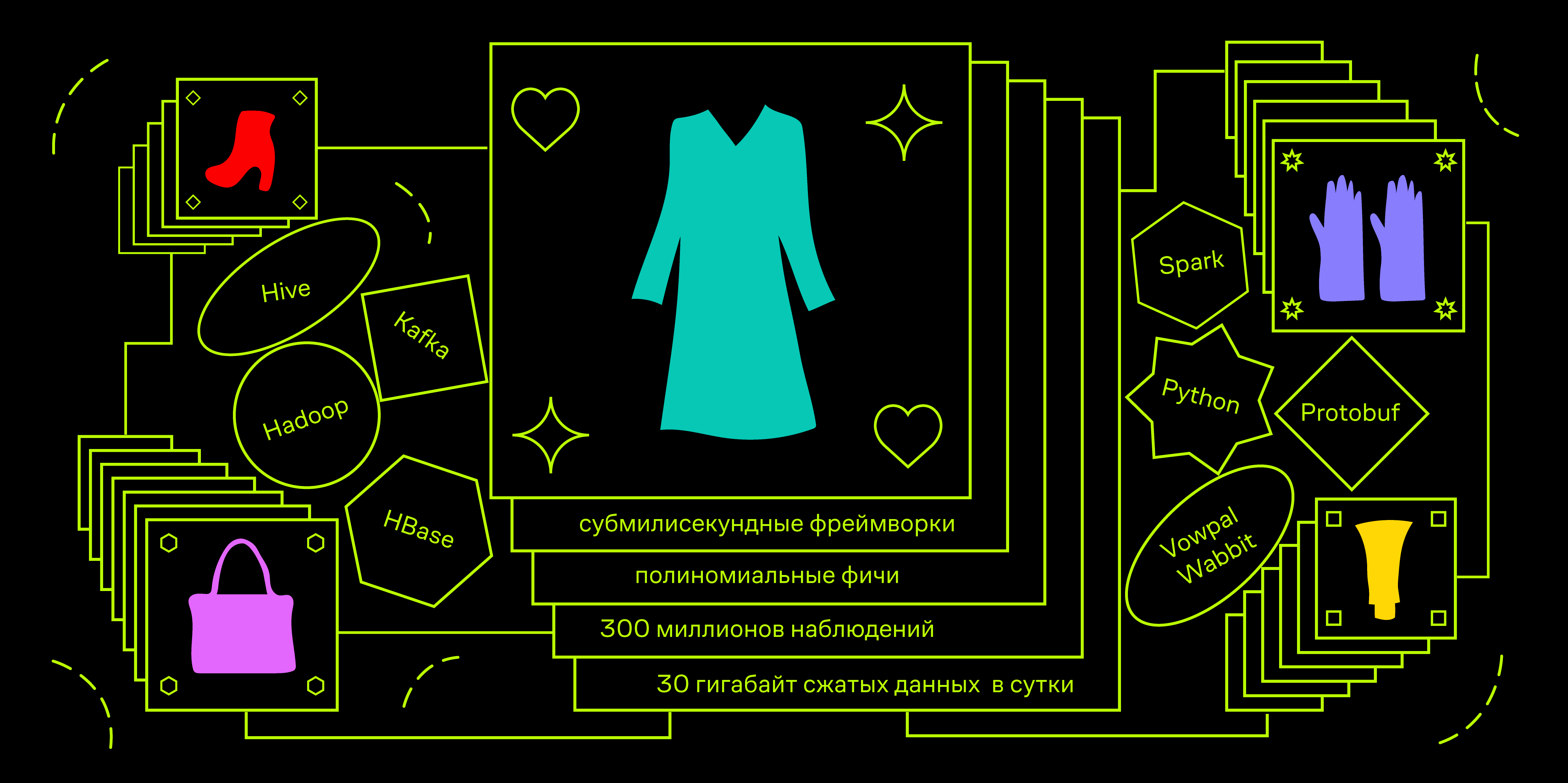
Dieser Ansatz für das Feature-Engineering vergrößert die Dimension des Raums, in dem das Training stattfindet, dramatisch. In einer Situation, in der wir nur 4 Farben haben, beträgt die Größe dieses Raums 8 (4 Farben für das Produkt und 4 für den Benutzer). Wenn 16 quadratische Attribute hinzugefügt werden, erhöht sich diese auf 24. In der Produktion verwenden wir zusätzlich zu den Farben 13 weitere Attribute der Waren, einschließlich beispielsweise der Marke. Daher kann die Gesamtdimension des Raums, in dem unsere Modelle arbeiten, bis zu 3 Millionen Merkmale betragen. Gleichzeitig wollen wir das Verhältnis der Anzahl der Trainingsbeispiele zur Raumdimension auf dem Niveau von 1: 100 halten. Dazu müssen wir insgesamt rund 300 Millionen Beobachtungen generieren.
Wir speichern den Clickstream unserer Benutzer in Hadoop (Spark-Streaming von Apache Kafka zu einer Hive-Tabelle). Normalerweise erhalten wir ungefähr 30 Gigabyte komprimierte Daten pro Tag - dies sind mehr als hundert verschiedene Arten von Aktionen, die Benutzer auf der Site und in Anwendungen ausführen können, einschließlich der Anzeige von Waren an verschiedenen Stellen.
Auch für die Regale der Empfehlungen gibt es Informationen darüber, welche Produkte gezeigt wurden und wo der Klick gemacht wurde. Unsere Aufgabe für jeden solchen Klick in der Vergangenheit ist es, den Status des Benutzers in Bezug auf das Verhältnis der Bruchteile der Werte der Attribute der angezeigten Produkte zum Zeitpunkt vor diesem Klick zu berechnen. Dann ergibt die Verkettung des Vektorpaars "Benutzer" + "Produkt, auf das geklickt wurde" ein positives Trainingsbeispiel, und ähnliche Paare mit Produkten, die daneben im Regal angezeigt werden, jedoch ohne Klicks, sind negative Beispiele. Es ist wichtig, dass Produkte in der Nähe gezeigt werden. Dann können wir sicher sein, dass der Benutzer sie gesehen hat, aber nicht geklickt hat. Als Bonus können wir mit solchen Mechaniken das Verhältnis der Klassen im Problem steuern.
Unsere Lösung ist die tägliche Aggregation von Benutzerdaten mithilfe von Spark und das schrittweise Laden dieser Daten in HBase. Betrachten Sie die Struktur eines solchen Aggregats.
Das Hauptobjekt in dieser Aufgabe ist also der Benutzer. Damit sind Sitzungen verbunden, die aus einer Folge von Aktionen bestehen, von denen jede je nach Art der Aktion bestimmte Merkmale aufweist. Wenn hier beispielsweise eine Produktseite angezeigt wird, gehören die Artikelnummer und die Anzeigezeit des Produkts zu den Attributen, die wir benötigen. Als Reserve für die Zukunft schreiben wir sofort die Verfügbarkeit von Waren auf Lager und zwei Preise in das Protokoll: den Basispreis und unter Berücksichtigung von Lagerbeständen und persönlichen Gutscheinen. Wir benötigen keine Impressionen separat, daher werden sie zum Zeitpunkt der Aggregation im laufenden Betrieb Klicks zugeordnet und generieren eine neue Art von Ereignis, bei dem neben dem Feld mit der Artikelnummer des Produkts, in das der Klick getätigt wurde, zum Zeitpunkt der Anzeige auch eine Reihe mehrerer Artikel vorhanden sind.
HBase ist eine versionierte Spaltendatenbank mit einer nativen Schnittstelle für die Verbindung mit Spark zur Batche-Verarbeitung und der Möglichkeit, per Schlüssel auf Daten zuzugreifen. Ein weiteres Merkmal ist, dass HBase das Konzept einer Schaltung fehlt. Es können nur Bytes bzw. Offsets in speziellen HFiles gespeichert werden, die an die HDFS-Blockstruktur angepasst sind.
Einige mögen es kontrovers finden, ein Repository auszuwählen, aber ich hatte gute Erfahrungen mit HBase in ähnlichen Projekten. Darüber hinaus wird diese Datenbank in Lamoda bereits aktiv verwendet, sodass die Verwendung eines bereits bereitgestellten Systems für MVP nichts kostet. Wir verwenden derzeit keine Versionsfunktionen, aber der Schlüsselzugriff schien nützlich für die Möglichkeit eines Multithread-Modelltrainings in der Zukunft und die Organisation der Lambda-Architektur zum Laden von Daten und anderen Echtzeitfällen.
Da es in HBase kein Schema gibt, benötigen wir einen eigenen Datencontainer. Sie könnten lambda x verwenden: json.dumps (x) .encode () , aber ich wollte etwas schneller. Eine völlig Standardlösung ist die Verwendung von Protobuf-Behältern. Da die Entwicklung des gesamten Projekts in Python erfolgt, ist es für mich üblicher, die benutzerdefinierte Pyrobuf-Bibliothek von AppNexus anstelle der offiziellen von Google zu verwenden. Nach Benchmarks ist die Leistung der Grundfunktionalität von Protobuffs um ein Vielfaches höher als die des Originals. Das ungefähre Schema unseres Protobuffs lautet wie folgt:
enum Location { ru = 1; by = 2; ua = 3; kz = 4; special = 5; } enum Platform { desktop = 1; mobile = 2; a_phone = 3; a_tablet = 4; iphone = 5; ipad = 6; } message Action { enum ActionType { pageview = 1; quickview = 2; rec_click = 3; catalog_click = 4; fav_add = 5; cart_add = 6; order_submit = 7; } required uint64 ts = 1; required ActionType action_type = 2; optional string sku = 3; required bool is_office = 4; repeated string skus = 5; optional uint32 delta = 6; optional string sku_source = 7; optional bool stock = 8; optional uint32 base_price = 9; optional uint32 price = 10; optional string type = 11; } message Session { required string session_id = 1; repeated Action actions = 2; required uint64 session_start = 3; required uint64 session_end = 4; optional uint32 actions_count = 5; } message LID { required string uid = 1; repeated Session sessions = 2; required Location location = 3; required Platform platform = 4; optional uint32 sessions_count = 5; }
Kurz gesagt, es gibt ein "Benutzer" -Objekt (LID, Lamoda ID). Darin befindet sich ein Array von "Session" -Objekten, von denen jedes ein Array von "Action" -Objekten ist. Wir haben die Aktionen nach Typ unterteilt und in verschiedenen Spaltenfamilien gespeichert, wodurch wir das Lesen ein wenig optimieren können, wenn wir nur Ereignisse bestimmter Typen benötigen (Produktansichten, zugeordnete Klicks auf verschiedene Arten von Empfehlungen usw.).
Testen
Drei Wochen lang haben wir auf der Desktop-Site lamoda.ru einen AB-Test in folgendem Design durchgeführt:
- Kontrolle: API-Empfehlungen beziehen sich auf den Personalisierungsservice, warten auf das Ergebnis, geben die Waren jedoch in der ursprünglichen Bestellung wieder, für alle gleich.
- Test: Produkte werden von links nach rechts in absteigender Reihenfolge der Klickwahrscheinlichkeitsprognose angezeigt.
Die Unterteilung in zwei Optionen basiert auf der LID des Benutzers - im Wesentlichen durch sein Cookie. Unsere experimentelle Plattform stellt sicher, dass die gesammelten Beobachtungen in zwei Versionen unabhängig und gleichmäßig verteilt sind und metrische Änderungen mit einem Signifikanzniveau von 5% (p-Wert 0,05) bewertet werden. Infolgedessen erhielten wir eine Klickrate von + 10% des gesamten Regals und eine signifikante positive Veränderung des Umsatzes. Letzte Woche haben wir diese Funktionalität für alle Benutzer der Website eingeführt.
Um die Personalisierung Ihrer Person zu überprüfen, schauen Sie sich einfach verschiedene Produkte an und vergleichen Sie die Sortierung der Empfehlungen in einem der Regale „Sie kaufen dieses Produkt“ in zwei verschiedenen Browsern oder verwenden Sie den „Inkognito“ -Modus. Wenn Sie unsere Website noch nicht besucht haben, sind auf der Plattform natürlich nur wenige Daten über Sie vorhanden. Wählen Sie eine Winterjacke und vergleichen Sie die Bestellung der Ware nach einer Weile erneut.
Wir haben also eine ganze Plattform erhalten - eine Reihe von Softwaretools, die Daten aggregieren und speichern, sowie ein Framework für die Vektorisierung von Geschäftsobjekten zu einem beliebigen Zeitpunkt in der Vergangenheit, mit dem Sie Bewertungsmodelle erstellen können, um die Wahrscheinlichkeit verschiedener Aktionen zu bewerten. Modellstörungen werden über einen Webdienst bereitgestellt, der relevante Vektoren aus verschiedenen Datenquellen sammeln und durch das Modell laufen lassen kann. Es akzeptiert eine LID (Benutzer-ID), eine Liste der zu öffnenden SKUs und verschiedene zusätzliche Informationen, wodurch dieselbe Produktliste an die erweiterten Klickwahrscheinlichkeitsprognosen zurückgegeben wird. Unten sehen Sie ein Diagramm der konzeptionellen Architektur unserer Plattform:

Das ML Core-Element besteht aus einer Reihe virtueller Maschinen, auf denen Hadoop-Clients und Airflow-Mitarbeiter installiert sind. Wir legen die Konfiguration fest, mit welchen Parametern das Modell trainiert werden soll, wo historische Daten abgerufen werden sollen und so weiter. Infolgedessen wird das Modell in künstlicher Form trainiert und veröffentlicht, und Informationen über den Lernprozess und die für uns interessanten Qualitätsmetriken werden im Meta-Repository gespeichert.
Bereits jetzt testen oder bereiten Sie Tests des Personalisierungssystems für Empfehlungen in den Mailinglisten, auf den Hauptseiten und im Regal mit Empfehlungen für ähnliche Produkte, ähnlichen Segmenten für die Ausrichtung auf interne und externe Werbung und vielem mehr vor.
Dies war ein Einführungsartikel. In weiteren Veröffentlichungen kann ich mich auf die technischen Aspekte der Architektur konzentrieren und über deren Entwicklung sprechen oder umgekehrt die Produktkomponente breiter erweitern und erläutern, wie wir ML in Produktaufgaben verwenden und bewerten. Schreiben Sie in die Kommentare Ihre Wünsche dazu.