Einführung
Vor einigen Jahren haben wir beschlossen, den SIMD-Code in .NET zu unterstützen . Wir haben den System.Numerics Namespace mit den Typen Vector2 , Vector3 , Vector4 und Vector<T> . Diese Typen stellen eine universelle API zum Erstellen, Zugreifen auf und Bearbeiten von Vektoranweisungen dar, wann immer dies möglich ist. Sie bieten auch Softwarekompatibilität für Fälle, in denen die Hardware keine geeigneten Anweisungen unterstützt. Dies ermöglichte es mit minimalem Refactoring, eine Reihe von Algorithmen zu vektorisieren. Wie dem auch sei, die Allgemeingültigkeit dieses Ansatzes macht es schwierig, ihn anzuwenden, um den vollen Vorteil aller verfügbaren Vektoranweisungen auf moderner Hardware zu erhalten. Darüber hinaus bietet moderne Hardware eine Reihe spezialisierter Anweisungen, die keine Vektoren sind und die Leistung erheblich verbessern können. In diesem Artikel werde ich darüber sprechen, wie wir diese Einschränkungen in .NET Core 3.0 umgangen haben.

Hinweis: Es gibt noch keinen festgelegten Begriff für die Übersetzung von Intrisics . Am Ende des Artikels wird über die Übersetzungsoption abgestimmt. Wenn wir eine gute Option wählen, werden wir den Artikel ändern
Was sind die eingebauten Funktionen
In .NET Core 3.0 haben wir neue Funktionen hinzugefügt, die als hardwarespezifische integrierte Funktionen (Far WF) bezeichnet werden. Diese Funktionalität bietet Zugriff auf viele spezifische Hardwareanweisungen, die nicht einfach durch allgemeinere Mechanismen dargestellt werden können. Sie unterscheiden sich von vorhandenen SIMD-Anweisungen darin, dass sie keinen allgemeinen Zweck haben (neue WFs sind nicht plattformübergreifend und ihre Architektur bietet keine Softwarekompatibilität). Stattdessen bieten sie .NET-Entwicklern direkt plattform- und hardwarespezifische Funktionen. Bestehende SIMD-Funktionen, z. B. plattformübergreifend, bieten Softwarekompatibilität und sind geringfügig von der zugrunde liegenden Hardware abstrahiert. Diese Abstraktion kann teuer sein und außerdem die Offenlegung einiger Funktionen verhindern (wenn beispielsweise Funktionen nicht vorhanden sind oder auf allen Zielplattformen schwer zu emulieren sind).
Neue integrierte Funktionen und unterstützte Typen befinden sich im System.Runtime.Intrinsics . Für .NET Core 3.0 gibt es System.Runtime.Intrinsics.X86 einen System.Runtime.Intrinsics.X86 . Wir arbeiten an der Unterstützung integrierter Funktionen für andere Plattformen wie System.Runtime.Intrinsics.Arm .
Unter plattformspezifischen Namespaces werden WFs in Klassen gruppiert, die Gruppen logisch integrierter Hardwareanweisungen darstellen (häufig als Befehlssatzarchitektur (ISA) bezeichnet). Jede Klasse stellt eine IsSupported Eigenschaft IsSupported angibt, ob die Hardware, auf der der Code ausgeführt wird, diese Anweisungen unterstützt. Ferner enthält jede solche Klasse einen Satz von Methoden, die einem entsprechenden Satz von Anweisungen zugeordnet sind. Manchmal gibt es eine zusätzliche Unterklasse, die einem Teil desselben Befehlssatzes entspricht, der möglicherweise durch bestimmte Hardware eingeschränkt (unterstützt) wird. Beispielsweise bietet die Lzcnt Klasse Zugriff auf Anweisungen zum Zählen führender Nullen . Er hat eine Unterklasse namens X64 , die die Form dieser Anweisungen enthält, die nur auf Computern mit 64-Bit-Architektur verwendet werden.
Einige dieser Klassen sind natürlich hierarchischer Natur. Wenn beispielsweise Lzcnt.X64.IsSupported true Lzcnt.IsSupported sollte Lzcnt.IsSupported auch true zurückgeben, da dies eine explizite Unterklasse ist. Wenn beispielsweise Sse2.IsSupported true Sse.IsSupported sollte Sse.IsSupported true zurückgeben, da Sse2 explizit von Sse erbt. Es ist jedoch anzumerken, dass die Ähnlichkeit von Klassennamen kein Indikator für ihre Zugehörigkeit zu derselben Vererbungshierarchie ist. Beispielsweise wird Bmi2 nicht von Bmi1 geerbt, sodass die von IsSupported für diese beiden Befehlssätze zurückgegebenen Werte unterschiedlich sind. Das Grundprinzip bei der Entwicklung dieser Klassen war die explizite Darstellung der ISA-Spezifikationen. SSE2 erfordert Unterstützung für SSE1, sodass die Klassen, die sie darstellen, durch Vererbung verbunden sind. Gleichzeitig benötigt BMI2 keine Unterstützung für BMI1, sodass wir keine Vererbung verwendet haben. Das Folgende ist ein Beispiel für die obige API.
namespace System.Runtime.Intrinsics.X86 { public abstract class Sse { public static bool IsSupported { get; } public static Vector128<float> Add(Vector128<float> left, Vector128<float> right); // Additional APIs public abstract class X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<float> value); // Additional APIs } } public abstract class Sse2 : Sse { public static new bool IsSupported { get; } public static Vector128<byte> Add(Vector128<byte> left, Vector128<byte> right); // Additional APIs public new abstract class X64 : Sse.X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<double> value); // Additional APIs } } }
Weitere Informationen finden Sie im Quellcode unter den folgenden Links source.dot.net oder dotnet / coreclr auf GitHub
IsSupported Prüfungen IsSupported vom JIT-Compiler als Laufzeitkonstanten verarbeitet (wenn die Optimierung aktiviert ist), sodass Sie keine IsSupported benötigen, um mehrere ISAs, Plattformen oder Architekturen zu unterstützen. Stattdessen müssen Sie den Code nur mit if Ausdrücken schreiben, wodurch nicht verwendete Codeverzweigungen (d. H. Diejenigen Verzweigungen, die aufgrund des Werts der Variablen in der bedingten Anweisung nicht erreichbar sind) verworfen werden, wenn der native Code generiert wird.
Es ist wichtig, dass die Überprüfung des entsprechenden IsSupported der Verwendung der integrierten Hardwarebefehle vorausgeht. Wenn es keine solche Prüfung gibt, löst Code mit plattformspezifischen Befehlen, die auf Plattformen / Architekturen ausgeführt werden, auf denen diese Befehle nicht unterstützt werden, eine Laufzeitausnahme von PlatformNotSupportedException .
Welche Vorteile bieten sie?
Natürlich sind hardwarespezifische integrierte Funktionen nicht jedermanns Sache, aber sie können verwendet werden, um die Leistung bei Operationen zu verbessern, die mit Berechnungen geladen sind. Die CoreFX und ML.NET verwenden diese Methoden, um Vorgänge wie das Kopieren im Speicher, das Suchen nach dem Index eines Elements in einem Array oder einer Zeichenfolge, das Ändern der Bildgröße oder das Arbeiten mit Vektoren / Matrizen / Tensoren zu beschleunigen. Die manuelle Vektorisierung von Code, der sich als Engpass herausstellte, kann auch einfacher sein, als es sich anhört. Die Vektorisierung des Codes besteht in der Tat darin, im Allgemeinen mehrere Operationen gleichzeitig unter Verwendung von SIMD-Befehlen (ein Befehlsstrom, mehrere Datenströme) auszuführen.
Bevor Sie sich für die Vektorisierung von Code entscheiden, müssen Sie eine Profilerstellung durchführen, um sicherzustellen, dass dieser Code wirklich Teil des "Hot Spots" ist (und Ihre Optimierung daher zu einer erheblichen Leistungssteigerung führt). Es ist auch wichtig, in jeder Phase der Vektorisierung eine Profilerstellung durchzuführen, da die Vektorisierung nicht des gesamten Codes zu einer erhöhten Produktivität führt.
Vektorisierung eines einfachen Algorithmus
Um die Verwendung integrierter Funktionen zu veranschaulichen , verwenden wir den Algorithmus zum Summieren aller Elemente eines Arrays oder Bereichs. Diese Art von Code ist ein idealer Kandidat für die Vektorisierung, weil Bei jeder Iteration wird dieselbe triviale Operation ausgeführt.
Eine beispielhafte Implementierung eines solchen Algorithmus kann wie folgt aussehen:
public int Sum(ReadOnlySpan<int> source) { int result = 0; for (int i = 0; i < source.Length; i++) { result += source[i]; } return result; }
Dieser Code ist recht einfach und unkompliziert, aber gleichzeitig langsam genug für große Eingabedaten führt nur eine triviale Operation pro Iteration aus.
BenchmarkDotNet=v0.11.5, OS=Windows 10.0.18362 AMD Ryzen 7 1800X, 1 CPU, 16 logical and 8 physical cores .NET Core SDK=3.0.100-preview9-013775 [Host] : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT [AttachedDebugger] DefaultJob : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT
Steigern Sie die Produktivität durch Bereitstellungszyklen
Moderne Prozessoren bieten verschiedene Möglichkeiten zur Verbesserung der Codeleistung. Für Single-Threaded-Anwendungen besteht eine solche Option darin, mehrere primitive Operationen in einem einzelnen Prozessorzyklus auszuführen.
Die meisten modernen Prozessoren können vier Additionsoperationen in einem Taktzyklus (unter optimalen Bedingungen) ausführen, wodurch Sie mit dem richtigen "Layout" des Codes manchmal die Leistung verbessern können, selbst in einer Single-Threaded-Implementierung.
Obwohl JIT das Abrollen von Schleifen selbst durchführen kann, ist JIT aufgrund der Größe des generierten Codes bei dieser Art von Entscheidung konservativ. Daher kann es vorteilhaft sein, eine Schleife im Code manuell bereitzustellen.
Sie können die Schleife im obigen Code wie folgt erweitern:
public unsafe int SumUnrolled(ReadOnlySpan<int> source) { int result = 0; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); // Pin source so we can elide the bounds checks fixed (int* pSource = source) { while (i < lastBlockIndex) { result += pSource[i + 0]; result += pSource[i + 1]; result += pSource[i + 2]; result += pSource[i + 3]; i += 4; } while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
Dieser Code ist etwas komplizierter, nutzt jedoch die Hardwarefunktionen besser aus.
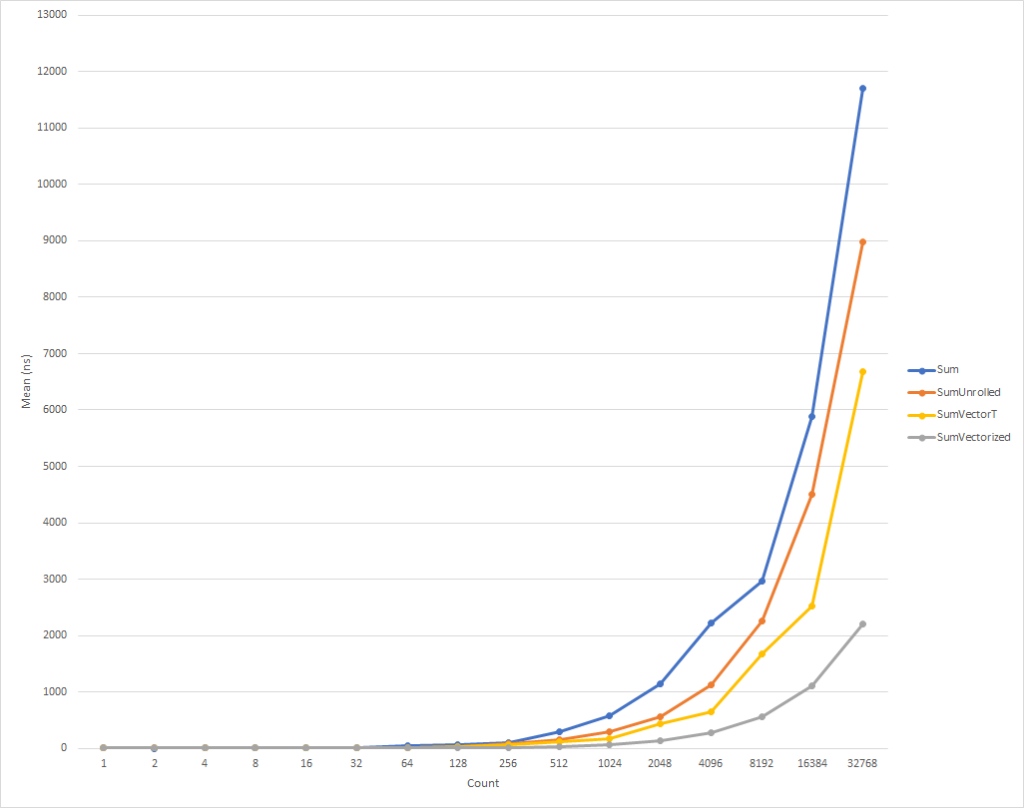
Bei sehr kleinen Schleifen läuft dieser Code etwas langsamer. Dieser Trend ändert sich jedoch bereits für Eingabedaten von acht Elementen, wonach die Ausführungsgeschwindigkeit zu steigen beginnt (die Ausführungszeit des optimierten Codes für 32.000 Elemente ist 26% kürzer als die Zeit der Originalversion). Es ist erwähnenswert, dass eine solche Optimierung nicht immer die Produktivität erhöht. Wenn Sie beispielsweise mit Sammlungen mit Elementen vom Typ float "bereitgestellte" Version des Algorithmus fast die gleiche Geschwindigkeit wie die ursprüngliche. Daher ist es sehr wichtig, eine Profilerstellung durchzuführen.

Steigern Sie die Produktivität durch Schleifenvektorisierung
Wie dem auch sei, wir können diesen Code dennoch leicht optimieren. SIMD-Anweisungen sind eine weitere Option moderner Prozessoren, um die Leistung zu verbessern. Mit einem einzigen Befehl können Sie mehrere Operationen in einem einzigen Taktzyklus ausführen. Dies ist möglicherweise besser als das Entfalten einer direkten Schleife, da tatsächlich dasselbe getan wird, jedoch mit einer geringeren Menge an generiertem Code.
Zur Verdeutlichung benötigt jede Additionsoperation in einem bereitgestellten Zyklus 4 Bytes. Somit benötigen wir 16 Bytes für 4 Additionsoperationen in der erweiterten Form. Gleichzeitig führt der SIMD-Additionsbefehl 4 Additionsoperationen aus, benötigt jedoch nur 4 Bytes. Dies bedeutet, dass wir weniger Anweisungen für die CPU haben. Darüber hinaus kann die CPU im Fall eines SIMD-Befehls Annahmen treffen und Optimierungen durchführen, was jedoch den Rahmen dieses Artikels sprengt. Was noch besser ist, ist, dass moderne Prozessoren mehr als einen SIMD-Befehl gleichzeitig ausführen können, d. H. In einigen Fällen können Sie eine gemischte Strategie anwenden und gleichzeitig einen Teilzyklus-Scan und eine Vektorisierung durchführen.
Im Allgemeinen müssen Sie zunächst die Allzweckklasse Vector<T> für Ihre Aufgaben betrachten. Er wird wie die neuen WFs SIMD-Anweisungen einbetten, kann aber angesichts der Vielseitigkeit dieser Klasse gleichzeitig die Anzahl der „manuellen“ Codierungen reduzieren.
Der Code könnte folgendermaßen aussehen:
public int SumVectorT(ReadOnlySpan<int> source) { int result = 0; Vector<int> vresult = Vector<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % Vector<int>.Count); while (i < lastBlockIndex) { vresult += new Vector<int>(source.Slice(i)); i += Vector<int>.Count; } for (int n = 0; n < Vector<int>.Count; n++) { result += vresult[n]; } while (i < source.Length) { result += source[i]; i += 1; } return result; }
Dieser Code funktioniert schneller, aber wir müssen bei der Berechnung des Endbetrags auf jedes Element separat verweisen. Außerdem hat Vector<T> keine genau definierte Größe und kann je nach Gerät, auf dem der Code ausgeführt wird, variieren. Hardwarespezifische integrierte Funktionen bieten zusätzliche Funktionen, die diesen Code geringfügig verbessern und etwas schneller machen können (auf Kosten zusätzlicher Codekomplexität und Wartungsanforderungen).

HINWEIS In diesem Artikel habe ich die Größe des Vector<T> mithilfe des internen Konfigurationsparameters ( COMPlus_SIMD16ByteOnly=1 ) mit COMPlus_SIMD16ByteOnly=1 auf 16 Byte festgelegt. Diese Optimierung normalisierte die Ergebnisse beim Vergleich von SumVectorT mit SumVectorizedSse und ermöglichte es uns, den Code einfach zu halten. Insbesondere wurde vermieden, einen bedingten Sprung zu schreiben, if (Avx2.IsSupported) { } . Dieser Code ist fast identisch mit dem Code für Sse2 , behandelt jedoch Vector256<T> (32 Byte) und verarbeitet noch mehr Elemente in einer Iteration der Schleife.
Mit den neuen integrierten Funktionen kann der Code daher wie folgt umgeschrieben werden:
public int SumVectorized(ReadOnlySpan<int> source) { if (Sse2.IsSupported) { return SumVectorizedSse2(source); } else { return SumVectorT(source); } } public unsafe int SumVectorizedSse2(ReadOnlySpan<int> source) { int result; fixed (int* pSource = source) { Vector128<int> vresult = Vector128<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); while (i < lastBlockIndex) { vresult = Sse2.Add(vresult, Sse2.LoadVector128(pSource + i)); i += 4; } if (Ssse3.IsSupported) { vresult = Ssse3.HorizontalAdd(vresult, vresult); vresult = Ssse3.HorizontalAdd(vresult, vresult); } else { vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0x4E)); vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0xB1)); } result = vresult.ToScalar(); while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
Dieser Code ist wiederum etwas komplizierter, aber für alle außer den kleinsten Eingabesätzen erheblich schneller. Bei 32.000 Elementen wird dieser Code 75% schneller als der erweiterte Zyklus und 81% schneller als der Quellcode des Beispiels ausgeführt.
Sie haben festgestellt, dass wir einige IsSupported Schecks ausgestellt haben. Der erste prüft, ob die aktuelle Hardware den erforderlichen Satz integrierter Funktionen unterstützt. Wenn nicht, wird die Optimierung durch eine Kombination aus Sweep und Vector<T> . Die letztere Option wird für Plattformen wie ARM / ARM64 ausgewählt, die den erforderlichen Befehlssatz nicht unterstützen oder wenn der Satz für die Plattform deaktiviert wurde. Der zweite IsSupported Test in der SumVectorizedSse2 Methode wird zur zusätzlichen Optimierung verwendet, wenn die Hardware den Ssse3 Befehlssatz unterstützt.
Ansonsten ist der größte Teil der Logik im Wesentlichen derselbe wie für die erweiterte Schleife. Vector128<T> ist ein 128-Bit-Typ, der Vector128<T>.Count Elemente enthält. In diesem Fall kann uint , das selbst 32-Bit ist, 4 (128/32) Elemente enthalten. Auf diese Weise haben wir die Schleife gestartet.
Fazit
Neue integrierte Funktionen bieten Ihnen die Möglichkeit, die hardwarespezifischen Funktionen des Computers zu nutzen, auf dem Sie den Code ausführen. Es gibt ungefähr 1.500 APIs für X86 und X64, die auf 15 Sätze verteilt sind. Es gibt zu viele, um sie in einem Artikel zu beschreiben. Durch Profilerstellung von Code zur Identifizierung von Engpässen können Sie den Teil des Codes bestimmen, der von der Vektorisierung profitiert, und einen ziemlich guten Leistungsschub beobachten. Es gibt viele Szenarien, in denen eine Vektorisierung angewendet werden kann und das Entfalten von Schleifen nur der Anfang ist.
Jeder, der weitere Beispiele sehen möchte, kann nach der Verwendung integrierter Funktionen im Framework (siehe Dotnet und Aspnet ) oder in anderen Community-Artikeln suchen . Und obwohl die aktuellen WFs sehr umfangreich sind, müssen noch viele Funktionen eingeführt werden. Wenn Sie über die Funktionen verfügen, die Sie einführen möchten, können Sie Ihre API-Anfrage über dotnet / corefx auf GitHub registrieren. Der API-Überprüfungsprozess wird hier beschrieben und es gibt ein gutes Beispiel für eine in Schritt 1 angegebene API-Anforderungsvorlage.
Besonderer Dank
Mein besonderer Dank gilt den Mitgliedern unserer Community Fei Peng (@fiigii) und Jacek Blaszczynski (@ 4creators) für ihre Hilfe bei der Implementierung des WF sowie allen Mitgliedern der Community für wertvolles Feedback zur Entwicklung, Implementierung und Benutzerfreundlichkeit dieser Funktionalität.
Nachwort zur Übersetzung
Ich beobachte gerne die Entwicklung der .NET-Plattform und insbesondere der C # -Sprache. Ich kam aus der Welt von C ++ und hatte wenig Erfahrung mit der Entwicklung in Delphi und Java. Ich war sehr zufrieden damit, Programme in C # zu schreiben. Im Jahr 2006 erschien mir diese Programmiersprache (die Sprache selbst) in der Welt der verwalteten Speicherbereinigung und plattformübergreifenden Arbeit prägnanter und praktischer als Java. Daher fiel meine Wahl auf C # und ich bereute es nicht. Die erste Stufe in der Entwicklung einer Sprache war einfach ihr Aussehen. Bis 2006 hat C # das Beste aus dieser Zeit in den besten Sprachen und Plattformen aufgenommen: C ++ / Java / Delphi. Im Jahr 2010 ging F # an die Börse. Es war eine experimentelle Plattform zur Untersuchung des Funktionsparadigmas mit dem Ziel, es in die Welt von .NET einzuführen. Das Ergebnis der Experimente war die nächste Stufe in der Entwicklung von C # - die Erweiterung seiner Fähigkeiten in Richtung FP durch die Einführung anonymer Funktionen, Lambda-Ausdrücke und letztendlich LINQ. Diese Erweiterung der Sprache machte C # aus meiner Sicht zur fortschrittlichsten Allzwecksprache. Der nächste Evolutionsschritt betraf die Unterstützung von Parallelität und Asynchronität. Task / Task <T>, das gesamte Konzept von TPL, die Entwicklung von LINQ - PLINQ und schließlich async / await. , - , .NET C# — . Span<T> Memory<T>, ValueTask/ValueTask<T>, IAsyncDispose, ref readonly struct in, foreach, IO.Streams. GC . , — . , .NET C#, , . ( ) .