
Intel erkennt die Bedeutung der künstlichen Intelligenz und unternimmt einen weiteren Schritt in diese Richtung. Vor einem Monat stellte das Unternehmen auf der Hot Chips 2019-Konferenz offiziell zwei spezialisierte Chips vor, die für das Training und die Inferenz neuronaler Netze entwickelt wurden. Die Chips wurden als Intel Nervana NNP-
T (Prozessor für neuronale Netze) bzw. Intel Nervana NNP-
I bezeichnet. Unter dem Schnitt finden Sie die Eigenschaften und Schemata neuer Produkte.
Intel Nervana NNP-T (Frühlingswappen)
Die Trainingszeit für neuronale Netze ist neben der Energieeffizienz einer der Schlüsselparameter des KI-Systems, der den Umfang seiner Anwendung bestimmt. Die in den größten Modellen und Trainingssätzen verwendete Rechenleistung verdoppelt sich alle drei Monate. Gleichzeitig wird in neuronalen Netzen eine begrenzte Anzahl von Berechnungen verwendet, hauptsächlich Faltungen und Matrixmultiplikation, was einen großen Spielraum für Optimierungen eröffnet. Idealerweise sollte das Gerät, das wir benötigen, in Bezug auf Verbrauch, Kommunikation, Rechenleistung und Skalierbarkeit ausgewogen sein.
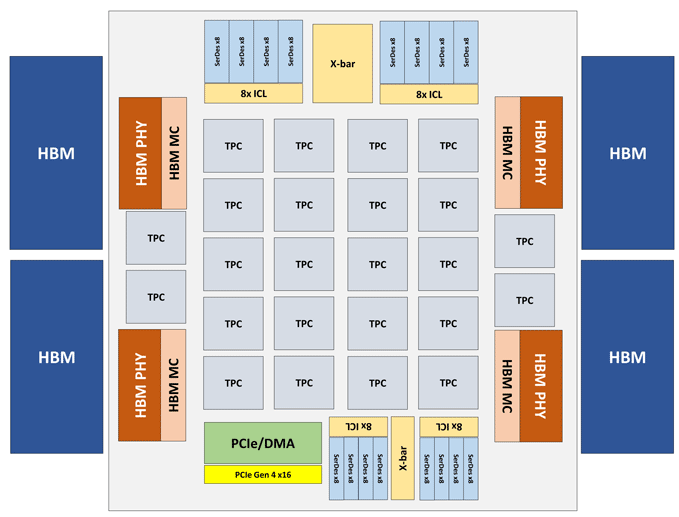
Das Intel Nervana NNP-T-Modul besteht aus einer PCIe 4.0 x16- oder OAM-Karte. Das wichtigste NNP-T-Computerelement ist der 24-teilige Tensor Processing Cluster (TPC), der eine Leistung von bis zu 119 TOPS bietet. Insgesamt 32 GB HBM2-2400-Speicher sind über 4 HBM-Ports verbunden. An Bord befindet sich auch eine Serialisierungs- / Deserialisierungseinheit für 64 Leitungen, SPI-, I2C- und GPIO-Schnittstellen. Die Menge des verteilten Speichers auf dem Chip beträgt 60 MB (2,5 MB pro TPC).
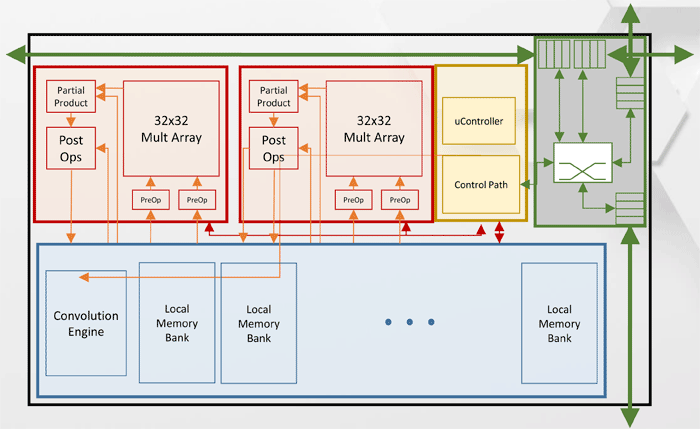 Tensor Processing Cluster (TPC) -Architektur
Tensor Processing Cluster (TPC) -ArchitekturAndere Leistungsspezifikationen für Intel Nervana NNP-T.
Wie Sie dem Diagramm entnehmen können, verfügt jeder TPC über zwei 32x32-Matrixmultiplikationskerne mit BFloat16-Unterstützung. Andere Vorgänge werden im BFloat16- oder FP32-Format ausgeführt. Insgesamt können bis zu 8 Karten auf einem Host installiert werden, die maximale Skalierbarkeit - bis zu 1024 Knoten.
Intel Nervana NNP-I (Spring Hill)
Bei der Entwicklung von Intel Nervana NNP-I war es das Ziel, maximale Energieeffizienz mit Rückschluss auf die Größe großer Rechenzentren zu erzielen - etwa 5 TOP / W.
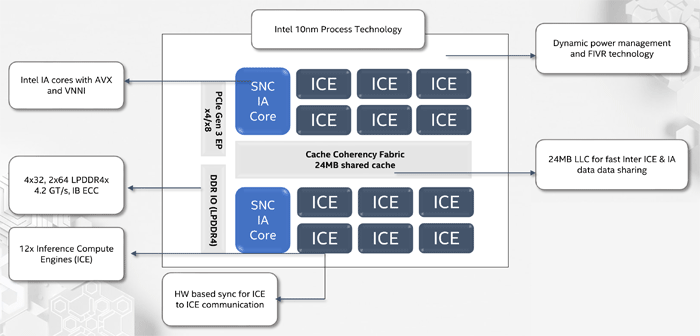
NNP-I ist ein SoC, der gemäß der 10-nm-Prozesstechnologie hergestellt wurde und zwei Standard-x86-Kerne mit Unterstützung für AVX und VNNI sowie 12 spezialisierte ICE-Kerne (Inference Compute Engine) enthält. Die maximale Leistung beträgt 92 TORS, TDP - 50 Watt. Der interne Speicher beträgt 75 MB. Strukturell ist das Gerät in Form einer Erweiterungskarte M.2 hergestellt.
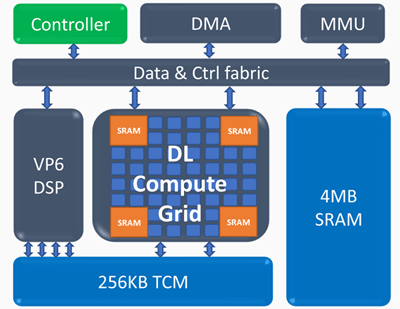 ICE-Architektur (Inference Compute Engine)
ICE-Architektur (Inference Compute Engine)Schlüsselelemente der Inference Compute Engine:
Deep Learning Compute Grid- 4k MAC (int8) pro Zyklus
- skalierbare Unterstützung für FP16, INT8, INT 4/2/1
- große Menge an internem Speicher
- nichtlineare Operationen und Pooling
Programmierbarer Vektorprozessor- hohe Leistung - 5 VLIW 512 b
- erweiterte NN-Unterstützung - FP16 / 16b / 8b
Die folgenden Leistungsindikatoren für Intel Nervana NNP-I wurden erhalten: In einem 50-lagigen ResNet-Netzwerk wurde eine Geschwindigkeit von 3600 Inferenzen pro Sekunde bei einem Energieverbrauch von 10 W erreicht, dh die Energieeffizienz beträgt 360 Bilder pro Sekunde in Watt.