Der vorherige Artikel befasste sich mit der Architektur eines virtualisierten Netzwerks, Underlay-Overlay, dem Paketpfad zwischen VMs und mehr.
Roman Gorge ließ sich von ihr inspirieren und beschloss, ein Review-Thema zur Virtualisierung im Allgemeinen zu schreiben.
In diesem Artikel werden wir uns mit den Fragen befassen (oder versuchen, sie zu berühren): Wie erfolgt die Virtualisierung von Netzwerkfunktionen tatsächlich, wie wird das Backend der Hauptprodukte zum Starten und Verwalten von VMs implementiert und wie funktioniert das virtuelle Switching (OVS- und Linux-Bridge)?
Das Thema Virtualisierung ist breit und tief, es ist unmöglich, alle Details der Arbeit des Hypervisors zu erklären (und es ist nicht notwendig). Wir beschränken uns auf das Mindestmaß an Wissen, das erforderlich ist, um den Betrieb einer virtualisierten Lösung zu verstehen, nicht unbedingt auf Telco.

Inhalt
- Einführung und eine kurze Geschichte der Virtualisierung
- Arten von virtuellen Ressourcen - Rechnen, Speichern, Netzwerk
- Virtuelles Schalten
- Virtualisierungstools - libvirt, virsh und mehr
- Fazit
Einführung und eine kurze Geschichte der Virtualisierung
Die Geschichte der modernen Virtualisierungstechnologien reicht bis ins Jahr 1999 zurück, als das junge Unternehmen VMware ein Produkt namens VMware Workstation herausbrachte. Dies war ein Virtualisierungsprodukt für Desktop- / Client-Anwendungen. Die serverseitige Virtualisierung erfolgte etwas später in Form des ESX Server-Produkts, das sich später zu ESXi entwickelte (i bedeutet integriert). Dies ist das gleiche Produkt, das sowohl in der IT als auch in Telco als Hypervisor für Serveranwendungen universell verwendet wird.
Auf der Opensource-Seite haben zwei große Projekte die Virtualisierung auf Linux gebracht:
- KVM (Kernel-based Virtual Machine) ist ein Linux-Kernelmodul, mit dem der Kernel als Hypervisor arbeiten kann (erstellt die erforderliche Infrastruktur zum Starten und Verwalten von VMs). Es wurde 2007 in der Kernel-Version 2.6.20 hinzugefügt.
- QEMU (Quick Emulator) - emuliert direkt Hardware für eine virtuelle Maschine (CPU, Festplatte, RAM, alles einschließlich eines USB-Anschlusses) und wird in Verbindung mit KVM verwendet, um eine nahezu "native" Leistung zu erzielen.
Tatsächlich ist derzeit die gesamte Funktionalität von KVM in QEMU verfügbar, dies ist jedoch nicht wichtig, da die meisten Linux-Virtualisierungsbenutzer KVM / QEMU nicht direkt verwenden, sondern über mindestens eine Abstraktionsebene auf sie zugreifen, aber dazu später mehr.
Heute sind VMware ESXi und Linux QEMU / KVM die beiden wichtigsten Hypervisoren, die den Markt dominieren. Sie sind auch Vertreter von zwei verschiedenen Arten von Hypervisoren:
- Typ 1 - Der Hypervisor läuft direkt auf der Hardware (Bare-Metal). Dies ist VMware ESXi, Linux KVM, Hyper-V
- Typ 2 - Der Hypervisor wird im Host-Betriebssystem (Betriebssystem) gestartet. Dies ist VMware Workstation oder Oracle VirtualBox.
Eine Diskussion darüber, was besser und was schlechter ist, würde den Rahmen dieses Artikels sprengen.

Die Eisenproduzenten mussten ebenfalls ihren Beitrag leisten, um eine akzeptable Leistung sicherzustellen.
Das vielleicht wichtigste und am weitesten verbreitete ist Intel VT (Virtualization Technology) - eine Reihe von Erweiterungen, die von Intel für seine x86-Prozessoren entwickelt wurden und für den effektiven Betrieb des Hypervisors verwendet werden (und in einigen Fällen beispielsweise erforderlich sind, funktioniert KVM beispielsweise ohne eingeschaltetes VT nicht -x und ohne es ist der Hypervisor gezwungen, eine reine Softwareemulation ohne Hardwarebeschleunigung durchzuführen).
Zwei dieser Erweiterungen sind am bekanntesten - VT-x und VT-d. Der erste ist wichtig für die Verbesserung der CPU-Leistung während der Virtualisierung, da er Hardware-Unterstützung für einige seiner Funktionen bietet (mit VT-x 99,9% wird der Code des Gastbetriebssystems direkt auf dem physischen Prozessor ausgeführt, sodass die Emulation nur in den notwendigsten Fällen ausgegeben wird), der zweite dient zum direkten Verbinden physischer Geräte an eine virtuelle Maschine (für Forward Virtual Functions (VF) SRIOV muss beispielsweise VT-d
aktiviert sein ).
Das nächste wichtige Konzept ist der Unterschied zwischen vollständiger Virtualisierung und Paravirtualisierung.
Die vollständige Virtualisierung ist gut. Sie ermöglicht die Ausführung jedes Betriebssystems auf jedem Prozessor. Sie ist jedoch äußerst ineffizient und für hoch ausgelastete Systeme absolut nicht geeignet.
Kurz gesagt, Paravirtualisierung ist, wenn das Gastbetriebssystem versteht, dass es in einer virtuellen Umgebung ausgeführt wird, und mit dem Hypervisor zusammenarbeitet, um eine höhere Effizienz zu erzielen. Das heißt, die Gast-Hypervisor-Oberfläche wird angezeigt.
Die überwiegende Mehrheit der heute verwendeten Betriebssysteme unterstützt die Paravirtualisierung - im Linux-Kernel ist dies seit der Kernel-Version 2.6.20 der Fall.
Damit eine virtuelle Maschine funktioniert, sind nicht nur ein virtueller Prozessor (vCPU) und ein virtueller Speicher (RAM) erforderlich, sondern auch die Emulation von PCI-Geräten. Das heißt, tatsächlich ist eine Reihe von Treibern erforderlich, um virtuelle Netzwerkschnittstellen, Festplatten usw. zu verwalten.
Im Linux KVM-Hypervisor wurde diese Aufgabe durch die Implementierung von
virtio gelöst, einem Framework für die Entwicklung und Verwendung virtualisierter E / A-Geräte.
Virtio ist eine zusätzliche Abstraktionsebene, mit der Sie verschiedene E / A-Geräte in einem paravirtualisierten Hypervisor emulieren können und eine einheitliche und standardisierte Schnittstelle zur Seite der virtuellen Maschine bereitstellen. Auf diese Weise können Sie den virtio-Treibercode für verschiedene inhärente Geräte wiederverwenden. Virtio besteht aus:
- Front-End-Treiber - Was ist in der virtuellen Maschine
- Backend-Treiber - was ist im Hypervisor
- Transportfahrer - was verbindet das Backend und das Frontend
Diese Modularität ermöglicht es Ihnen, die im Hypervisor verwendeten Technologien zu ändern, ohne die Treiber in der virtuellen Maschine zu beeinflussen (dieser Moment ist für Netzwerkbeschleunigungstechnologien und Cloud-Lösungen im Allgemeinen sehr wichtig, aber dazu später mehr).
Das heißt, es besteht eine Gast-Hypervisor-Verbindung, wenn das Gastbetriebssystem „weiß“, dass es in einer virtuellen Umgebung ausgeführt wird.
Wenn Sie jemals eine Frage in RFP geschrieben oder eine Frage in RFP beantwortet haben: "Wird virtio in Ihrem Produkt unterstützt?" Es ging nur darum, den Front-End-Virtio-Treiber zu unterstützen.
Arten von virtuellen Ressourcen - Rechnen, Speichern, Netzwerk
Woraus besteht eine virtuelle Maschine?
Es gibt drei Haupttypen von virtuellen Ressourcen:
- Rechenprozessor und RAM
- Speicher - Systemfestplatte und Blockspeicher der virtuellen Maschine
- Netzwerk - Netzwerkkarten und Ein- / Ausgabegeräte
Berechnen
CPU
Theoretisch ist QEMU in der Lage, jeden Prozessortyp und die entsprechenden Flags und Funktionen zu emulieren. In der Praxis verwenden sie entweder das Host-Modell und deaktivieren die Flags punktweise, bevor sie an das Gastbetriebssystem übertragen werden, oder sie nehmen das benannte Modell und aktivieren und deaktivieren die Flags punktweise.
Standardmäßig emuliert QEMU einen Prozessor, den das Gastbetriebssystem als virtuelle QEMU-CPU erkennt. Dies ist nicht der optimalste Prozessortyp, insbesondere wenn eine Anwendung, die in einer virtuellen Maschine ausgeführt wird, CPU-Flags für ihre Arbeit verwendet.
Erfahren Sie mehr über die verschiedenen CPU-Modelle in QEMU .
Mit QEMU / KVM können Sie auch die Prozessortopologie, die Anzahl der Threads, die Cache-Größe, die Bindung von vCPU an den physischen Kern und vieles mehr steuern.
Ob dies für eine virtuelle Maschine erforderlich ist oder nicht, hängt von der Art der Anwendung ab, die unter dem Gastbetriebssystem ausgeführt wird. Es ist beispielsweise bekannt, dass es für Anwendungen, die Pakete mit hohem PPS verarbeiten, wichtig ist,
CPU-Pinning durchzuführen ,
dh nicht zuzulassen, dass der physische Prozessor auf andere virtuelle Maschinen übertragen wird.
Speicher
Als nächstes kommt RAM. Aus Sicht des Host-Betriebssystems unterscheidet sich eine mit QEMU / KVM gestartete virtuelle Maschine nicht von anderen Prozessen, die im Benutzerbereich des Betriebssystems ausgeführt werden. Dementsprechend wird der Prozess zum Zuweisen von Speicher zu einer virtuellen Maschine durch dieselben Aufrufe im Kernel-Host-Betriebssystem ausgeführt, als ob Sie beispielsweise einen Chrome-Browser gestartet hätten.
Bevor Sie die Geschichte des Arbeitsspeichers in virtuellen Maschinen fortsetzen, müssen Sie den Begriff NUMA - Non-Uniform Memory Access abschweifen und erläutern.
Die Architektur moderner physischer Server umfasst das Vorhandensein von zwei oder mehr Prozessoren (CPU) und den damit verbundenen Direktzugriffsspeicher (RAM). Ein solcher Bündel von Prozessor + Speicher wird als Knoten oder Knoten bezeichnet. Die Kommunikation zwischen verschiedenen NUMA-Knoten erfolgt über einen speziellen Bus - QPI (QuickPath Interconnect).
Der lokale NUMA-Knoten wird zugewiesen - wenn der im Betriebssystem ausgeführte Prozess den Prozessor und den RAM verwendet, die sich im selben NUMA-Knoten befinden, und der entfernte NUMA-Knoten - wenn der im Betriebssystem ausgeführte Prozess den Prozessor und den RAM verwendet, die sich in verschiedenen NUMA-Knoten befinden. Das heißt, für das Zusammenspiel von Prozessor und Speicher ist eine Datenübertragung über den QPI-Bus erforderlich.
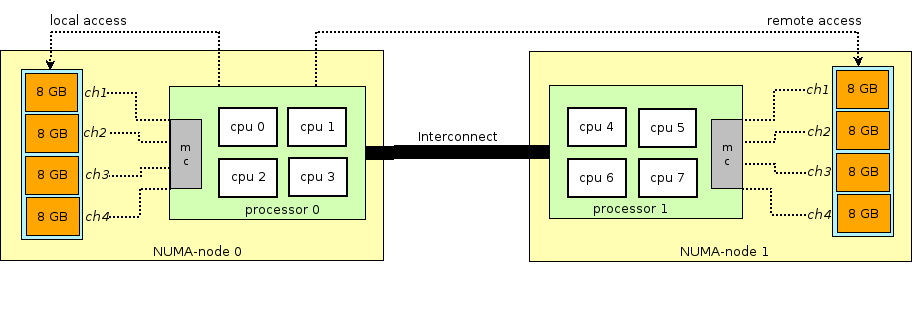
Aus Sicht der virtuellen Maschine wurde ihr bereits zum Zeitpunkt des Starts Speicher zugewiesen, in Wirklichkeit ist dies jedoch nicht der Fall, und das Kernel-Host-Betriebssystem weist dem QEMU / KVM-Prozess neue Speicherabschnitte zu, da die Anwendung im Gastbetriebssystem zusätzlichen Speicher anfordert (obwohl dies möglicherweise auch der Fall ist) eine Ausnahme, wenn Sie QEMU / KVM direkt angeben, um den gesamten Speicher direkt beim Start der virtuellen Maschine zuzuweisen).
Der Speicher wird nicht byteweise zugewiesen, sondern durch eine bestimmte
Seitengröße . Die Seitengröße ist konfigurierbar und kann theoretisch beliebig sein. In der Praxis beträgt die Größe jedoch 4 KB (Standard), 2 MB und 1 GB. Die letzten beiden Größen werden als
HugePages bezeichnet und häufig zum
Zuweisen von Speicher für speicherintensive virtuelle Maschinen verwendet. Der Grund für die Verwendung von HugePages bei der Suche nach einer Übereinstimmung zwischen der virtuellen Seitenadresse und dem physischen Speicher im
TLB (
Translation Lookaside Buffer ), der wiederum begrenzt ist und nur Informationen zu den zuletzt verwendeten Seiten speichert. Wenn keine Informationen über die gewünschte Seite im TLB vorhanden sind, tritt ein Prozess namens
Miss TLB auf, und Sie müssen den Host-Betriebssystemprozessor verwenden, um die physische Speicherzelle zu finden, die der gewünschten Seite entspricht.
Dieser Prozess ist ineffizient und langsam, sodass weniger größere Seiten verwendet werden.
Mit QEMU / KVM können Sie auch verschiedene NUMA-Topologien für das Gastbetriebssystem emulieren, Speicher für eine virtuelle Maschine nur von einem bestimmten NUMA-Knoten-Host-Betriebssystem abrufen und so weiter. Am häufigsten wird Speicher für eine virtuelle Maschine von einem lokalen NUMA-Knoten für die der virtuellen Maschine zugewiesenen Prozessoren verwendet. Der Grund ist der Wunsch, eine unnötige Belastung des
QPI- Busses zu vermeiden, der die CPU-Sockel des physischen Servers verbindet (dies ist natürlich logisch, wenn Ihr Server über zwei oder mehr Sockel verfügt).
Lagerung
Wie Sie wissen, wird RAM als Betriebsspeicher bezeichnet, da sein Inhalt beim Ausschalten oder Neustarten des Betriebssystems verschwindet. Zum Speichern von Informationen benötigen Sie ein persistentes Speichergerät (ROM) oder einen
persistenten Speicher .
Es gibt zwei Haupttypen von persistentem Speicher:
- Blockspeicher - Ein Block Speicherplatz, mit dem das Dateisystem installiert und Partitionen erstellt werden können. Wenn es unhöflich ist, können Sie es als normale Festplatte verwenden.
- Objektspeicherung - Informationen können nur als Objekt (Datei) gespeichert werden, auf das über HTTP / HTTPS zugegriffen werden kann. Typische Beispiele für die Objektspeicherung sind AWS S3 oder Dropbox.
Die virtuelle Maschine benötigt
dauerhaften Speicher . Wie geht das, wenn die virtuelle Maschine im RAM des Host-Betriebssystems "lebt"? Kurz gesagt, jeder Gastbetriebssystemaufruf an den Controller der virtuellen Festplatte wird von QEMU / KVM abgefangen und in einen Datensatz auf der physischen Festplatte des Hostbetriebssystems umgewandelt. Diese Methode ist ineffizient, und daher wird hier wie auch für Netzwerkgeräte der virtio-Treiber verwendet, anstatt ein IDE- oder iSCSI-Gerät vollständig zu emulieren. Lesen Sie hier mehr darüber. Somit greift die virtuelle Maschine über einen virtio-Treiber auf ihre virtuelle Festplatte zu, und dann schreibt QEMU / KVM die übertragenen Informationen auf die physische Festplatte. Es ist wichtig zu verstehen, dass in Host OS ein Festplatten-Backend als CEPH-, NFS- oder iSCSI-Shelf implementiert werden kann.
Der einfachste Weg, persistenten Speicher zu emulieren, besteht darin, die Datei in einem Verzeichnis des Host-Betriebssystems als Speicherplatz einer virtuellen Maschine zu verwenden. QEMU / KVM unterstützt viele verschiedene Formate dieser Art von Dateien - raw, vdi, vmdk und andere. Das am häufigsten verwendete Format ist jedoch
qcow2 (QEMU Copy-on-Write-Version 2). Im Allgemeinen ist qcow2 in gewisser Weise eine strukturierte Datei ohne Betriebssystem. Eine große Anzahl virtueller Maschinen wird in Form von qcow2-Images (Images) verteilt und ist eine Kopie der Systemfestplatte einer virtuellen Maschine, die im qcow2-Format gepackt ist. Dies hat mehrere Vorteile: Die qcow2-Codierung benötigt viel weniger Speicherplatz als eine Rohkopie einer Byte-zu-Byte-Festplatte. QEMU / KVM kann die Größe einer qcow2-Datei ändern. Dies bedeutet, dass die Größe der Festplatte einer virtuellen Maschine geändert werden kann. Die AES-qcow2-Verschlüsselung wird ebenfalls unterstützt (Dies ist sinnvoll, da das Image einer virtuellen Maschine geistiges Eigentum enthalten kann.)
Wenn die virtuelle Maschine gestartet wird, verwendet QEMU / KVM die qcow2-Datei als Systemfestplatte (ich lasse das Laden der virtuellen Maschine hier weg, obwohl dies auch eine interessante Aufgabe ist), und die virtuelle Maschine kann Daten über virtio in die qcow2-Datei lesen / schreiben Fahrer. Somit funktioniert das Aufnehmen von Images von virtuellen Maschinen, da die qcow2-Datei jederzeit eine vollständige Kopie der Systemfestplatte der virtuellen Maschine enthält und das Image zum Sichern, Übertragen auf einen anderen Host usw. verwendet werden kann.
Im Allgemeinen wird diese qcow2-Datei im Gastbetriebssystem als
/ dev / vda-Gerät definiert , und das Gastbetriebssystem partitioniert den Speicherplatz in Partitionen und installiert das Dateisystem. In ähnlicher Weise können die folgenden qcow2-Dateien, die über QEMU / KVM als
/ dev / vdX- Geräte verbunden sind, als
Blockspeicher in einer virtuellen Maschine zum Speichern von Informationen verwendet werden (genau so funktioniert die Openstack Cinder-Komponente).
Netzwerk
Als letztes auf unserer Liste der virtuellen Ressourcen stehen Netzwerkkarten und E / A-Geräte. Eine virtuelle Maschine benötigt wie ein physischer Host einen
PCI / PCIe-Bus , um E / A-Geräte anzuschließen. QEMU / KVM kann verschiedene Arten von Chipsätzen emulieren - q35 oder i440fx (der erste unterstützt PCIe, der zweite unterstützt ältere PCI) sowie verschiedene PCI-Topologien erstellen beispielsweise separate PCI-Busse (PCI-Expander-Bus) für NUMA-Knoten. Gastbetriebssystem.
Nach dem Erstellen des PCI / PCIe-Busses müssen Sie ein E / A-Gerät daran anschließen. Im Allgemeinen kann es sich um eine Netzwerkkarte oder eine physische GPU handeln. Und natürlich eine Netzwerkkarte, die sowohl vollständig virtualisiert (z. B. vollständig virtualisierte e1000-Schnittstelle) als auch paravirtualisiert (z. B. virtio) oder eine physische Netzwerkkarte ist. Die letzte Option wird für virtuelle Maschinen auf Datenebene verwendet, bei denen Sie Paketraten mit Leitungsrate abrufen müssen - Router, Firewalls usw.
Hier gibt es zwei Hauptansätze:
PCI-Passthrough und
SR-IOV . Der Hauptunterschied zwischen ihnen besteht darin, dass für PCI-PT der Treiber nur innerhalb des Gastbetriebssystems verwendet wird und für SRIOV der Treiber für das Host-Betriebssystem (zum Erstellen von
VF - Virtuelle Funktionen ) und der Treiber für das Gastbetriebssystem zur Steuerung von SR-IOV VF verwendet werden.
Juniper hat hervorragende Details zu PCI-PT und SRIOV geschrieben.

Zur Verdeutlichung ist anzumerken, dass PCI-Passthrough und SR-IOV komplementäre Technologien sind. SR-IOV zerlegt eine physische Funktion in virtuelle Funktionen. Dies erfolgt auf der Ebene des Host-Betriebssystems. Gleichzeitig sieht das Host-Betriebssystem virtuelle Funktionen als ein anderes PCI / PCIe-Gerät. Was er als nächstes mit ihnen macht, ist nicht wichtig.
Und PCI-PT ist ein Mechanismus zum Weiterleiten eines beliebigen Host-Betriebssystem-PCI-Geräts im Gastbetriebssystem, einschließlich der vom SR-IOV-Gerät erstellten virtuellen Funktion
Daher haben wir die Haupttypen virtueller Ressourcen untersucht. Der nächste Schritt besteht darin, zu verstehen, wie die virtuelle Maschine über ein Netzwerk mit der Außenwelt kommuniziert.
Virtuelles Schalten
Wenn es eine virtuelle Maschine und eine virtuelle Schnittstelle gibt, tritt offensichtlich das Problem auf, ein Paket von einer VM auf eine andere zu übertragen. In Linux-basierten Hypervisoren (z. B. KVM) kann dieses Problem mithilfe der Linux-Brücke gelöst werden. Das
Open vSwitch (OVS) -Projekt hat jedoch breite Akzeptanz gefunden.
Es gibt mehrere Kernfunktionen, die es OVS ermöglicht haben, sich weit zu verbreiten und die de facto primäre Paketvermittlungsmethode zu werden, die in vielen Cloud-Computing-Plattformen (wie Openstack) und virtualisierten Lösungen verwendet wird.
- Netzwerkstatusübertragung - Bei der Migration einer VM zwischen Hypervisoren besteht die Aufgabe darin, ACLs, QoSs, L2 / L3-Weiterleitungstabellen und mehr zu übertragen. Und OVS kann es schaffen.
- Implementierung des Paketübertragungsmechanismus (Datenpfad) sowohl im Kernel als auch im Benutzerbereich
- CUPS-Architektur (Control / User-Plane Separation) - Ermöglicht die Übertragung der Funktionalität der Paketverarbeitung auf einen speziellen Chipsatz (Broadcom- und Marvell-Chipsatz können dies beispielsweise tun) und steuert diese über die OVS der Steuerebene.
- Unterstützung für Remote-Verkehrssteuerungsmethoden - OpenFlow-Protokoll (hi, SDN).
Die OVS-Architektur sieht auf den ersten Blick ziemlich beängstigend aus, ist aber nur auf den ersten Blick.
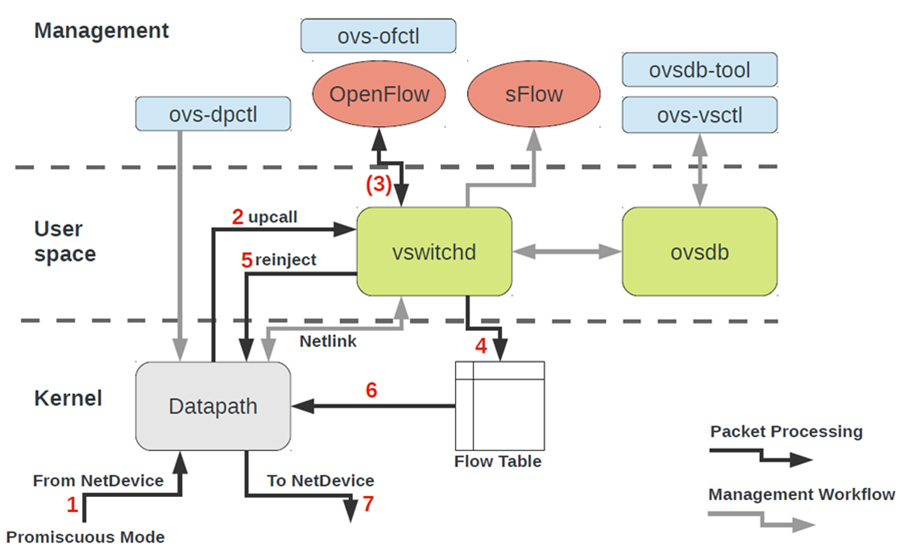
Um mit OVS arbeiten zu können, müssen Sie Folgendes verstehen:
- Datenpfad - Pakete werden hier verarbeitet. Die Analogie ist die Schalterstruktur eines Eisenschalters. Datapath umfasst das Empfangen von Paketen, das Verarbeiten von Headern und das Übereinstimmen von Übereinstimmungen in der Flusstabelle, die bereits in Datapath programmiert ist. Wenn OVS im Kernel ausgeführt wird, wird es als Kernelmodul implementiert. Wenn OVS im User-Space ausgeführt wird, ist dies ein Prozess im User-Space-Linux.
- vswitchd und ovsdb sind Dämonen im User-Space, die die Funktionalität des Switches direkt implementieren, die Konfiguration speichern, den Flow auf den Datenpfad setzen und ihn programmieren.
- Eine Reihe von Tools zur Konfiguration und Fehlerbehebung von OVS - ovs-vsctl, ovs-dpctl, ovs-ofctl, ovs-appctl . Alles, was benötigt wird, um die Portkonfiguration in ovsdb zu registrieren, zu registrieren, auf welchen Fluss umgeschaltet werden soll, Statistiken zu sammeln und so weiter. Gute Leute haben einen Artikel darüber geschrieben.
Wie landet das Netzwerkgerät einer virtuellen Maschine in OVS?Um dieses Problem zu lösen, müssen wir die im Benutzerbereich des Betriebssystems befindliche virtuelle Schnittstelle irgendwie mit dem im Kernel befindlichen Datenpfad-OVS verbinden.
Im Linux-Betriebssystem werden Pakete zwischen dem Kernel und den User-Space-Prozessen über zwei spezielle Schnittstellen übertragen. / / user-space- kernel — file descriptor (FD) ( , datapath OVS kernel — / FD)
- TUN (tunnel) — , L3 / IP / FD.
- TAP (network tap) — , tun + Ethernet-, .. L2.
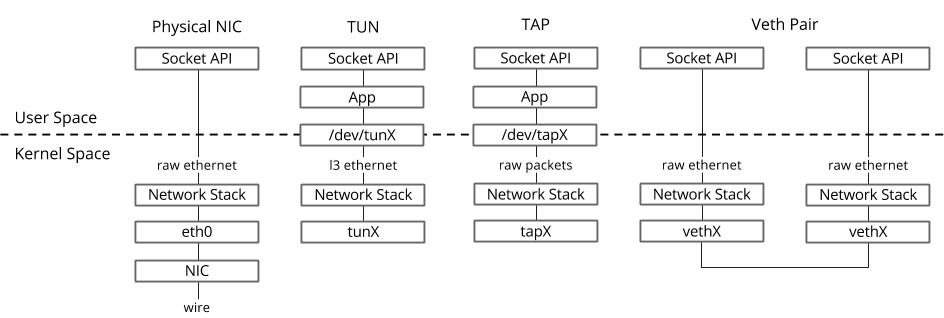
Host OS TAP-
ip link ifconfig — «» virtio, «» kernel Host OS. , TAP- MAC- virtio- .
TAP- OVS
ovs-vsctl — , OVS TAP-, file descriptor.
, .. OVS bridge, , OVS, .
, , , OVS bridge TAP- ovs-vsctl. .
OVS bridges, , Openstack Neutron, namespace multi-tenancy.
OVS bridges?—
veth pair . Veth pair , — , «» , «» . Veth pair OVS bridges Linux bridges. veth pair namespace Linux OS, veth pair namespace .
— libvirt, virsh
, , KVM-.
, 90 :
- libvirt
- virsh CLI
- virt-install
, CLI-, , , qemu_system_x86_64 virt manager, . Cloud-, Openstack, , libvirt.
libvirt
libvirt — open-source , . QEMU/KVM, ESXi, LXC .
— XML- API. libvirt ,
, , .
, libvirt - .
, libvirt.

libvirt — Host OS — Ubuntu, CentOS RHEL, , , libvirt . (apt, yum ).
libvirt Linux bridge virbr0 .
Ubuntu Server, , ifconfig Linux bridge virbr0 — libvirtd
Linux bridge , , . Libvirt OVS, , OVS bridges OVS-.
, (compute, network, storage) libvirt. XML-.
, libvirt:
PCI- libvirt domain.
libvirt , XML-.
XML- , , — , , , . XML- libvirt XML dump XML.
, libvirt XML, , , .
, libvirt XML Ubuntu Desktop Guest OS — 40-50 . libvirt XML (NUMA-, CPU-, CPU pinning ), libvirt XML . , , libvirt XML.
virsh CLI
Das Dienstprogramm virsh ist eine "native" Befehlszeile zum Verwalten von libvirt. Der Hauptzweck besteht darin, libvirt-Objekte zu verwalten, die als XML-Dateien bezeichnet werden. Typische Beispiele sind Starten, Stoppen, Definieren, Zerstören usw. Das heißt, der Lebenszyklus von Objekten - Lebenszyklusmanagement.Eine Beschreibung aller virsh-Befehle und -Flaggen finden Sie auch in der libvirt- Dokumentation .virt-install
, libvirt. — XML-, , virsh-install. — .
, libvirt, .
Fazit
, . , , «step-by-step guide». - , .
Nützliche Links