
Probleme in der Arbeitsumgebung sind immer eine Katastrophe. Es passiert, wenn Sie nach Hause gehen, und der Grund scheint immer dumm. In letzter Zeit ist auf den Knoten im Kubernetes-Cluster nicht mehr genügend Speicher vorhanden, obwohl der Knoten ohne sichtbare Unterbrechungen sofort wiederhergestellt wurde. Heute werden wir über diesen Fall sprechen, darüber, welchen Schaden wir erlitten haben und wie wir ein ähnliches Problem in Zukunft vermeiden wollen.
Fall eins
Samstag, 15. Juni 2019, 17:12 Uhr
Blue Matador (ja, wir überwachen uns selbst!) Erzeugt eine Warnung: ein Ereignis auf einem der Knoten im Kubernetes-Produktionscluster - SystemOOM.
17:16
Blue Matador generiert eine Warnung: EBS Burst Balance ist auf dem Root-Volume des Knotens niedrig - dem, auf dem das SystemOOM-Ereignis stattgefunden hat. Obwohl nach einer Benachrichtigung über SystemOOM eine Warnung zum Burst Balance angezeigt wurde, zeigen die tatsächlichen CloudWatch-Daten, dass das Burst Balance um 17:02 Uhr einen Mindestwert erreicht hat. Der Grund für die Verzögerung ist, dass die EBS-Metriken ständig 10 bis 15 Minuten zurückliegen und unser System nicht alle Ereignisse in Echtzeit erfasst.
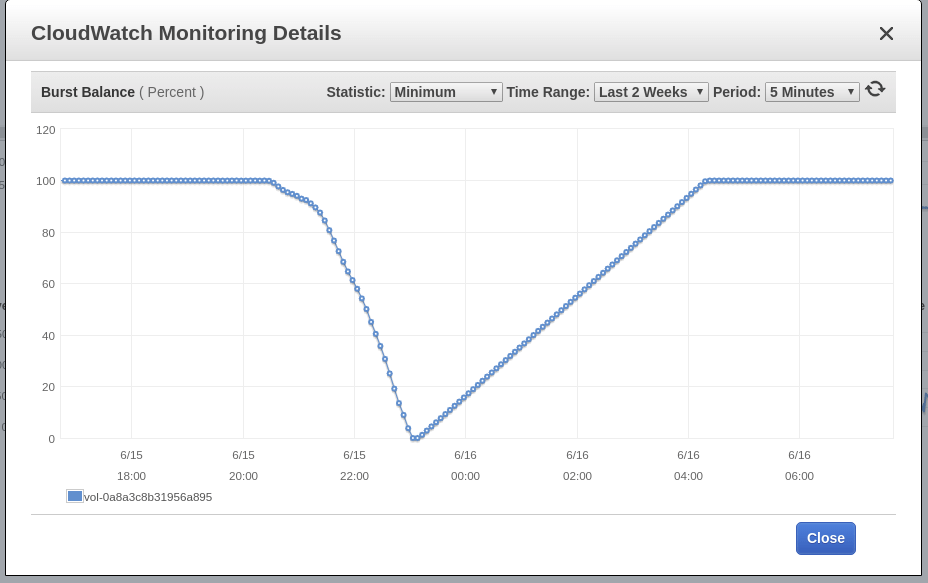
17:18
Im Moment sah ich eine Warnung und eine Warnung. Ich führe kubectl get pods schnell aus, um zu sehen, welchen Schaden wir erlitten haben, und ich bin überrascht, dass die Pods in der Anwendung genau 0 gestorben sind. Ich führe kubectl top knoten durch , aber diese Überprüfung zeigt auch, dass der verdächtige Knoten ein Speicherproblem hat; Es stimmt, es hat sich bereits erholt und verwendet ungefähr 60% seines Speichers. Es ist 17 Uhr und das Craft Beer wärmt sich bereits auf. Nachdem ich sichergestellt hatte, dass der Knoten betriebsbereit war und kein einziger Pod beschädigt war, entschied ich, dass ein Unfall aufgetreten war. Wenn überhaupt, werde ich es am Montag herausfinden.
Hier ist unsere Korrespondenz mit der Tankstelle in Slack an diesem Abend:

Fall zwei
Samstag, 16. Juni 2019, 18:02 Uhr
Blue Matador generiert eine Warnung: Das Ereignis befindet sich bereits auf einem anderen Knoten, ebenfalls SystemOOM. Es muss gewesen sein, dass die Tankstelle in diesem Moment nur auf den Bildschirm des Smartphones schaute, weil sie mir schrieb und mich sofort dazu brachte, das Ereignis aufzunehmen. Ich selbst kann den Computer nicht einschalten (ist es Zeit, Windows erneut zu installieren?). Und wieder scheint alles normal zu sein. Es wird kein einziger Pod getötet, und der Knoten belegt kaum 70% des Speichers.
18:06
Blue Matador generiert erneut eine Warnung: EBS Burst Balance. Das zweite Mal an einem Tag, was bedeutet, dass ich dieses Problem nicht auf den Bremsen lösen kann. Bei unveränderter CloudWatch weicht Burst Balance 2 Stunden oder länger von der Norm ab, bevor das Problem identifiziert wurde.
18:11
Ich gehe zu Datalog und schaue mir die Daten zum Speicherverbrauch an. Ich sehe, dass der verdächtige Knoten kurz vor dem SystemOOM-Ereignis wirklich viel Speicherplatz beansprucht hat. Der Weg führt zu unseren fließend-sumologischen Kapseln.

Sie können deutlich eine starke Abweichung des Speicherverbrauchs erkennen, ungefähr zur gleichen Zeit, zu der SystemOOM-Ereignisse aufgetreten sind. Mein Fazit: Es waren diese Pods, die den gesamten Speicher beanspruchten, und als SystemOOM passierte, erkannte Kubernetes, dass diese Pods getötet und neu gestartet werden konnten, um den erforderlichen Speicher zurückzugeben, ohne meine anderen Pods zu beeinträchtigen. Gut gemacht, Kubernetes!
Warum habe ich das am Samstag nicht gesehen, als ich herausgefunden habe, welche Pods neu gestartet wurden? Tatsache ist, dass ich fließend-sumologische Pods in einem separaten Namespace verwende und in Eile einfach nicht daran gedacht habe, mich damit zu befassen.
Schlussfolgerung 1: Wenn Sie nach neu gestarteten Pods suchen, überprüfen Sie alle Namespaces.
Nachdem ich diese Daten erhalten hatte, berechnete ich, dass der Speicher auf anderen Knoten am nächsten Tag nicht enden würde. Ich startete jedoch alle sumologischen Pods neu, sodass sie mit geringem Speicherverbrauch arbeiteten. Am nächsten Morgen habe ich vor, die Arbeit an dem Problem in einen Wochenplan zu integrieren und nicht zu viel Sonntagabend zu laden.
23:00
Ich sah mir die nächste Serie von "Black Mirror" an (übrigens mochte ich Miley) und beschloss, mir anzusehen, wie es dem Cluster ging. Der Speicherverbrauch ist normal. Sie können also alles so lassen, wie es für die Nacht ist.
Fix
Am Montag habe ich mir Zeit für dieses Problem genommen. Es tut nicht weh, jede Nacht mit ihr herum zu jagen. Was ich im Moment weiß:
- Fließend-sumologische Behälter verschlang eine Tonne Speicher;
- Dem SystemOOM-Ereignis geht eine hohe Festplattenaktivität voraus, aber ich weiß nicht, welche.
Zuerst dachte ich, dass flüssig-sumologische Behälter akzeptiert werden, um bei einem plötzlichen Zufluss von Protokollen Speicher zu fressen. Nachdem ich Sumologic überprüft hatte, stellte ich jedoch fest, dass die Protokolle stabil verwendet wurden, und zur gleichen Zeit, als es Probleme gab, gab es keine Zunahme dieser Protokolle.
Ein wenig googeln, fand ich diese Aufgabe auf Github , die vorschlägt, einige Ruby-Einstellungen anzupassen - um den Speicherverbrauch zu reduzieren. Ich habe beschlossen, es auszuprobieren, der Pod-Spezifikation eine Umgebungsvariable hinzuzufügen und auszuführen:
env: - name: RUBY_GC_HEAP_OLDOBJECT_LIMIT_FACTOR value: "0.9"
Beim Durchsehen des fließend-sumologischen Manifests stellte ich fest, dass ich keine Ressourcenanforderungen und -beschränkungen definiert hatte. Ich fange an zu vermuten, dass der RUBY_GCP_HEAP-Fix ein Wunder bewirken wird. Daher ist es jetzt sinnvoll, Speicherverbrauchsgrenzen festzulegen. Selbst wenn ich das Speicherproblem nicht behebe, ist es zumindest möglich, den Verbrauch auf diesen Satz von Pods zu beschränken. Verwenden von kubectl top pods | grep fluentd-sumologic , ich weiß bereits, wie viele Ressourcen ich anfordern muss:
resources: requests: memory: "128Mi" cpu: "100m" limits: memory: "1024Mi" cpu: "250m"
Schlussfolgerung 2: Festlegen von Ressourcenlimits, insbesondere für Anwendungen von Drittanbietern.
Ausführungsüberprüfung
Nach einigen Tagen bestätige ich, dass die oben beschriebene Methode funktioniert. Der Speicherverbrauch war stabil und - keine Probleme mit Komponenten von Kubernetes, EC2 und EBS. Jetzt ist klar, wie wichtig es ist, Ressourcenanforderungen und -einschränkungen für alle von mir ausgeführten Pods zu ermitteln. Folgendes muss getan werden: Wenden Sie eine Kombination aus Standardressourcenlimits und Ressourcenquoten an .
Das letzte ungelöste Rätsel ist EBS Burst Balance, das mit dem SystemOOM-Ereignis zusammenfiel. Ich weiß, dass das Betriebssystem bei wenig Speicher den Auslagerungsbereich verwendet, um nicht vollständig ohne Speicher zu bleiben. Aber ich wurde gestern nicht geboren und mir ist bewusst, dass Kubernetes nicht einmal auf Servern startet, auf denen die Auslagerungsdatei aktiviert ist. Um sicherzugehen, bin ich über SSH in meine Knoten geklettert, um zu überprüfen, ob die Auslagerungsdatei aktiviert wurde. Ich habe sowohl freien Speicher als auch den im Swap-Bereich verwendet. Die Datei wurde nicht aktiviert.
Und da das Austauschen nicht funktioniert, habe ich mehr Hinweise darauf, was das Wachstum der E / A-Flüsse verursacht hat, weshalb dem Knoten fast der Speicher ausgegangen ist, nein. Eigentlich habe ich eine Ahnung: Der fließend-sumologische Pod selbst hat zu diesem Zeitpunkt eine Menge Protokollnachrichten geschrieben, möglicherweise sogar eine Protokollnachricht im Zusammenhang mit der Einrichtung von Ruby GC. Es ist auch möglich, dass es andere Quellen für Kubernetes oder Journald-Nachrichten gibt, die übermäßig produktiv werden, wenn der Speicher knapp wird, und ich habe sie beim Einrichten von fließend beseitigt. Leider habe ich keinen Zugriff mehr auf die Protokolldateien, die unmittelbar vor der Fehlfunktion aufgezeichnet wurden, und kann jetzt nicht tiefer graben.
Schlussfolgerung 3: Während es eine Gelegenheit gibt, sollten Sie bei der Analyse der Grundursachen, unabhängig vom Problem, tiefer gehen.
Fazit
Und obwohl ich den Ursachen nicht auf den Grund gegangen bin, bin ich sicher, dass sie nicht benötigt werden, um die gleichen Fehlfunktionen in Zukunft zu verhindern. Zeit ist Geld, aber ich war zu lange beschäftigt, und danach habe ich auch diesen Beitrag für Sie geschrieben. Und da wir Blue Matador verwenden , werden solche Störungen sehr detailliert behandelt, sodass ich mir erlaube, etwas auf den Bremsen zu lösen, ohne vom Hauptprojekt abgelenkt zu werden.