Habr, hallo.
Dieser Beitrag gibt einen kurzen Überblick über allgemeine Algorithmen für maschinelles Lernen. Jedes wird von einer kurzen Beschreibung, Anleitungen und nützlichen Links begleitet.
Hauptkomponentenmethode (PCA) / SVD
Dies ist einer der grundlegenden Algorithmen für maschinelles Lernen. Ermöglicht es Ihnen, die Dimensionalität der Daten zu reduzieren und dabei die geringste Informationsmenge zu verlieren. Es wird in vielen Bereichen wie Objekterkennung, Computer Vision, Datenkomprimierung usw. verwendet. Die Berechnung der Hauptkomponenten reduziert sich auf die Berechnung der Eigenvektoren und Eigenwerte der Kovarianzmatrix der Quelldaten oder auf die singuläre Zerlegung der Datenmatrix.
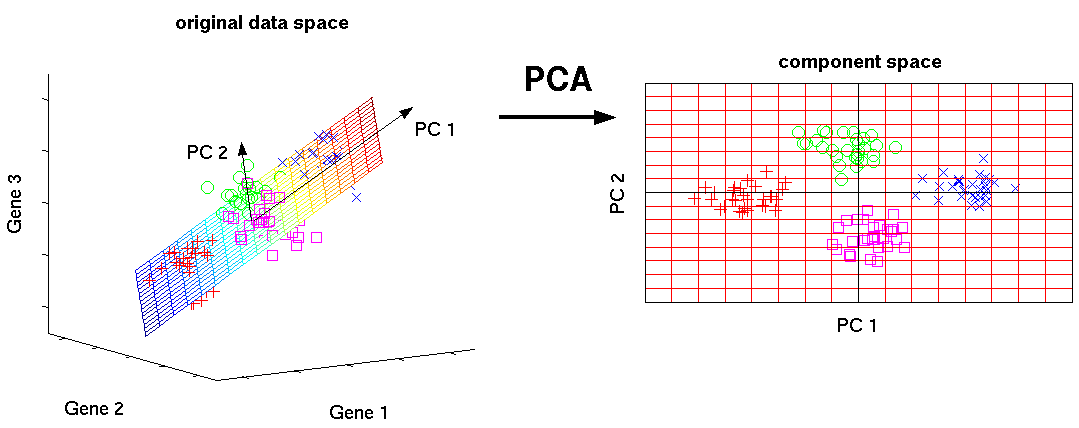
SVD ist eine Methode zur Berechnung geordneter Komponenten.
Nützliche Links:
Einführungsleitfaden:
Methode der kleinsten Quadrate
Die Methode der kleinsten Quadrate ist eine mathematische Methode zur Lösung verschiedener Probleme, die auf der Minimierung der Summe der Quadrate der Abweichungen einiger Funktionen von den gewünschten Variablen basiert. Es kann verwendet werden, um überbestimmte Gleichungssysteme zu „lösen“ (wenn die Anzahl der Gleichungen die Anzahl der Unbekannten überschreitet), um eine Lösung bei gewöhnlichen (nicht neu definierten) nichtlinearen Gleichungssystemen zu finden und um auch die Punktwerte einer Funktion zu approximieren.
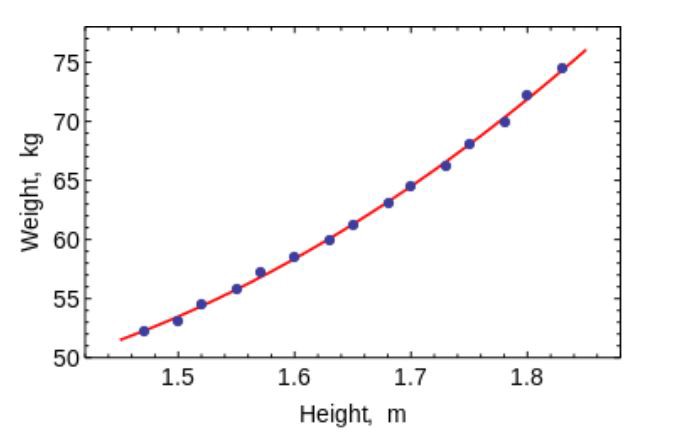
Verwenden Sie diesen Algorithmus, um einfache Kurven / Regressionen anzupassen.
Nützliche Links:
Einführungsleitfaden:
Begrenzte lineare Regression
Die Methode der kleinsten Quadrate kann Ausreißer, falsche Felder usw. verwirren. Einschränkungen sind erforderlich, um die Varianz der Linie zu verringern, die wir in den Datensatz einfügen. Die richtige Lösung besteht darin, ein lineares Regressionsmodell anzupassen, das sicherstellt, dass sich Gewichte nicht „schlecht“ verhalten. Modelle können die Norm L1 (LASSO) oder L2 (Ridge Regression) oder beides (elastische Regression) haben.
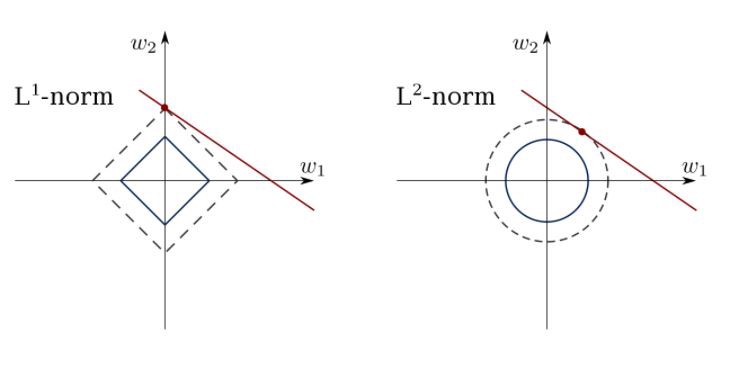
Verwenden Sie diesen Algorithmus, um eingeschränkte Regressionslinien abzugleichen und ein Überschreiben zu vermeiden.
Nützlicher Link:
Einführungsleitfäden:
K-Mittel-Methode
Jedermanns beliebtester unkontrollierter Clustering-Algorithmus. Bei einem gegebenen Datensatz in Form von Vektoren können wir Punktcluster basierend auf den Abständen zwischen ihnen erstellen. Dies ist einer der Algorithmen für maschinelles Lernen, der die Zentren der Cluster nacheinander verschiebt und dann die Punkte mit jedem Zentrum des Clusters gruppiert. Die Eingabe ist die Anzahl der zu erstellenden Cluster und die Anzahl der Iterationen.
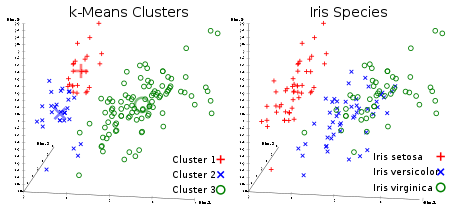
Nützlicher Link:
Einführungsleitfäden:
Logistische Regression
Die logistische Regression wird durch lineare Regression mit Nichtlinearität (hauptsächlich unter Verwendung der Sigmoidfunktion oder tanh) nach dem Anwenden von Gewichten begrenzt, daher liegt die Ausgabebeschränkung nahe an den +/- Klassen (die bei einem Sigmoid 1 und 0 sind). Kreuzentropieverlustfunktionen werden unter Verwendung der Gradientenabstiegsmethode optimiert.
Hinweis für Anfänger: Die logistische Regression wird zur Klassifizierung verwendet, nicht zur Regression. Im Allgemeinen ähnelt es einem einschichtigen neuronalen Netzwerk. Training mit Optimierungstechniken wie Gradientenabstieg oder L-BFGS. NLP-Entwickler verwenden es häufig und nennen es „maximale Entropieklassifizierung“.

Verwenden Sie LR, um einfache, aber sehr „starke“ Klassifikatoren zu trainieren.
Nützlicher Link:
Einführungsleitfaden:
SVM (Support Vector Method)
SVM ist ein lineares Modell wie die lineare / logistische Regression. Der Unterschied besteht darin, dass es eine margenbasierte Verlustfunktion hat. Sie können die Verlustfunktion mit Optimierungsmethoden wie L-BFGS oder SGD optimieren.

Eine einzigartige Sache, die SVM tun kann, ist das Lernen von Klassenklassifikatoren.
SVM kann verwendet werden, um Klassifikatoren (sogar Regressoren) zu trainieren.
Nützlicher Link:
Einführungsleitfäden:
Neuronale Netze mit direkter Verteilung
Grundsätzlich handelt es sich hierbei um mehrstufige Klassifikatoren der logistischen Regression. Viele Gewichtsschichten sind durch Nichtlinearitäten getrennt (Sigmoid, Tanh, Relu + Softmax und Cool New Selu). Sie werden auch als mehrschichtige Perzeptrone bezeichnet. FFNNs können zur Klassifizierung und „lehrerlosen Ausbildung“ als Auto-Encoder verwendet werden.

FFNN kann verwendet werden, um den Klassifikator zu trainieren oder Funktionen als Auto-Encoder zu extrahieren.
Nützliche Links:
Einführungsleitfäden:
Faltungs-Neuronale Netze
Fast alle modernen Errungenschaften auf dem Gebiet des maschinellen Lernens wurden mit Faltungs-Neuronalen Netzen erzielt. Sie werden verwendet, um Bilder zu klassifizieren, Objekte zu erkennen oder sogar Bilder zu segmentieren. Netzwerke wurden Anfang der 90er Jahre von Jan Lekun erfunden und haben Faltungsschichten, die als hierarchische Extraktoren von Objekten fungieren. Sie können sie verwenden, um mit Text zu arbeiten (und sogar um mit Grafiken zu arbeiten).
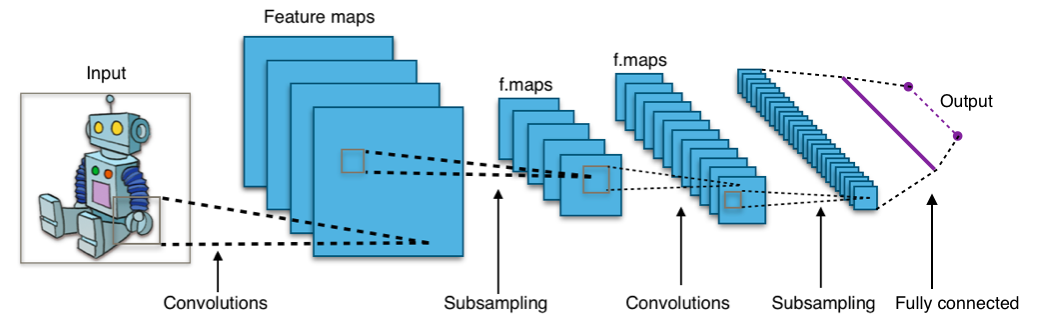
Nützliche Links:
Einführungsleitfäden:
Wiederkehrende neuronale Netze (RNNs)
RNNs modellieren Sequenzen, indem der gleiche Satz von Gewichten rekursiv auf den Zustand des Aggregators zum Zeitpunkt t und die Eingabe zum Zeitpunkt t angewendet wird. Reine RNNs werden derzeit selten verwendet, aber ihre Gegenstücke wie LSTM und GRU sind bei den meisten Sequenzmodellierungsaufgaben am weitesten fortgeschritten. LSTM, das anstelle von einer einfachen dichten Schicht in reinem RNN verwendet wird.

Verwenden Sie RNN für alle Aufgaben der Textklassifizierung, maschinellen Übersetzung und Sprachmodellierung.
Nützliche Links:
Einführungsleitfäden:
Bedingte Zufallsfelder (CRFs)
Sie werden wie RNNs für die Sequenzmodellierung verwendet und können in Kombination mit RNNs verwendet werden. Sie können auch in anderen strukturierten Prognoseaufgaben verwendet werden, beispielsweise bei der Bildsegmentierung. CRF modelliert jedes Element der Sequenz (z. B. einen Satz), sodass Nachbarn die Beschriftung der Komponente in der Sequenz beeinflussen und nicht alle Beschriftungen, die unabhängig voneinander sind.
Verwenden Sie CRF zum Verknüpfen von Sequenzen (in Text, Bild, Zeitreihen, DNA usw.).
Nützlicher Link:
Einführungsleitfäden:
Entscheidungsbäume und zufällige Wälder
Einer der häufigsten Algorithmen für maschinelles Lernen. Wird in der Statistik und Datenanalyse für Prognosemodelle verwendet. Die Struktur ist "Blätter" und "Zweige". Attribute, von denen die Zielfunktion abhängt, werden in den „Zweigen“ des Entscheidungsbaums aufgezeichnet, die Werte der Zielfunktion werden in die „Blätter“ geschrieben und die Attribute, die Fälle unterscheiden, werden in den verbleibenden Knoten aufgezeichnet.
Um einen neuen Fall zu klassifizieren, müssen Sie den Baum bis zum Blatt hinuntergehen und den entsprechenden Wert ausgeben. Ziel ist es, ein Modell zu erstellen, das den Wert der Zielvariablen basierend auf mehreren Eingabevariablen vorhersagt.
Nützliche Links:
Einführungsleitfäden:
Weitere Informationen zu maschinellem Lernen und Data Science erhalten Sie, indem Sie meinen Account bei
Habré und dem Telegrammkanal
Neuron abonnieren. Überspringen Sie keine zukünftigen Artikel.
Alles Wissen!