Seit fast einem Jahr nutze ich den Yandex Music Service und alles passt zu mir. Aber es gibt eine interessante Seite in diesem Service - die Geschichte. Es speichert alle Titel, die in chronologischer Reihenfolge gehört wurden. Und natürlich wollte ich es herunterladen und analysieren, was ich dort die ganze Zeit gehört hatte.

Erste Versuche
Als ich anfing, mich mit dieser Seite zu beschäftigen, stieß ich sofort auf ein Problem. Der Dienst lädt nicht alle Titel gleichzeitig herunter, sondern nur beim Scrollen. Ich wollte den Schnüffler nicht herunterladen und den Verkehr verstehen, und ich hatte zu diesem Zeitpunkt keine Fähigkeiten in dieser Angelegenheit. Aus diesem Grund habe ich mich entschlossen, den Browser einfacher mit Selen zu emulieren.
Das Skript wurde geschrieben. Aber er arbeitete sehr instabil und lange. Aber er hat es geschafft, die Geschichte zu laden. Nach einer einfachen Analyse ließ ich das Skript ohne Änderungen, bis ich nach einiger Zeit die Geschichte wieder nicht herunterladen wollte. In der Hoffnung auf das Beste habe ich es gestartet. Und natürlich gab er einen Fehler. Dann wurde mir klar, dass es Zeit war, alles menschlich zu machen.
Arbeitsoption
Für die Analyse des Datenverkehrs habe ich mich für Fiddler entschieden, da es im Gegensatz zu Wireshark eine leistungsfähigere Schnittstelle für den HTTP-Datenverkehr gibt. Beim Ausführen des Sniffers erwartete ich Anfragen nach API mit einem Token. Aber nein. Unser Ziel war music.yandex.ru/handlers/library.jsx . Für Anfragen war eine vollständige Autorisierung auf der Website erforderlich. Wir fangen mit ihr an.
Login
Hier ist nichts kompliziert. Wir gehen zu passport.yandex.ru/auth , finden die Parameter für die Anfragen und stellen zwei Autorisierungsanfragen.
auth_page = self.get('/auth').text csrf_token, process_uuid = self.find_auth_data(auth_page) auth_login = self.post( '/registration-validations/auth/multi_step/start', data={'csrf_token': csrf_token, 'process_uuid': process_uuid, 'login': self.login} ).json() auth_password = self.post( '/registration-validations/auth/multi_step/commit_password', data={'csrf_token': csrf_token, 'track_id': auth_login['track_id'], 'password': self.password} ).json()
Und so haben wir uns angemeldet.
Verlauf herunterladen
Gehen Sie als music.yandex.ru/user/<user>/history zu music.yandex.ru/user/<user>/history , wo wir auch einige Parameter music.yandex.ru/user/<user>/history , die für uns nützlich sind, wenn wir Informationen über die Tracks erhalten. Jetzt können Sie die Geschichte herunterladen. Wir erhalten die music.yandex.ru/handlers/library.jsx unter music.yandex.ru/handlers/library.jsx mit den Parametern {'owner': <user>, 'filter': 'history', 'likeFilter': 'favorite', 'lang': 'ru', 'external-domain': 'music.yandex.ru', 'overembed': 'false', 'ncrnd': '0.9546193023464256'} . Ich habe mich hier für den Parameter ncrnd interessiert. Bei Anfragen weist Yandex diesem Parameter immer unterschiedliche Werte zu, aber alles funktioniert mit demselben. Zurück erhalten wir den Verlauf in Form von ID-Tracks und detaillierten Informationen zu den Top-Ten-Tracks. Aus den detaillierten Streckeninformationen können Sie viele interessante Daten für eine spätere Analyse speichern. Zum Beispiel Erscheinungsjahr, Titeldauer und Genre. Informationen zu den restlichen Tracks erhalten Sie unter music.yandex.ru/handlers/track-entries.jsx . Wir speichern all dieses Geschäft in CSV und gehen zur Analyse über.
Analyse
Für die Analyse verwenden wir Standardwerkzeuge in Form von Pandas und Matplotlib.
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv('statistics.csv') df.head(3)
Ändern Sie Pythons None in NaN und werfen Sie sie weg.
df = df.replace('None', pd.np.nan).dropna()
Beginnen wir mit einem einfachen. Mal sehen, wie viel Zeit wir damit verbracht haben, alle Tracks anzuhören
duration_sec = df['duration_sec'].astype('int64').sum() ss = duration_sec % 60 m = duration_sec // 60 mm = m % 60 h = m // 60 hh = h % 60 f'{h // 24} {hh}:{mm}:{ss}'
'15 15:30:14'
Aber hier können Sie über die Genauigkeit dieser Figur streiten, da nicht klar ist, welcher Teil des Tracks, den Sie zum Anhören benötigen, Yandex zur Geschichte hinzugefügt hat.
Schauen wir uns nun die Verteilung der Tracks nach Erscheinungsjahr an.
plt.rcParams['figure.figsize'] = [15, 5] plt.hist(df['year'].sort_values(), bins=len(df['year'].unique())) plt.xticks(rotation='vertical') plt.show()
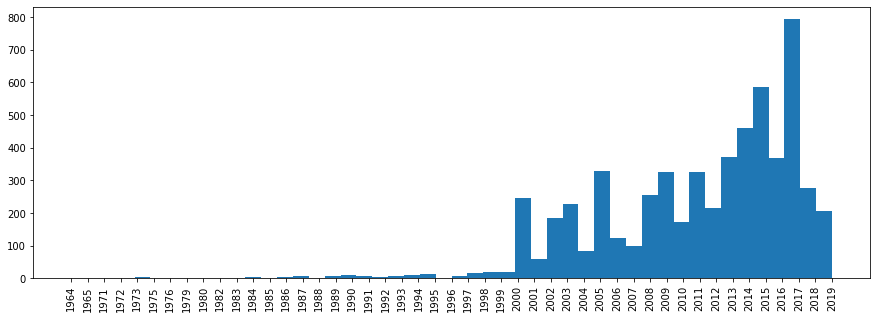
Hier ist das nicht so einfach, da die verschiedenen Sammlungen von „Best Hits“ ein späteres Jahr haben werden.
Andere Statistiken basieren auf einem sehr ähnlichen Prinzip. Ich werde ein Beispiel für die am meisten gehörten Titel geben
df.groupby(['track_id', 'artist','track'])['track_id'].count().sort_values(ascending=False).head()
und die meisten gespielten Titel des Künstlers
artist_name = 'Coldplay' df.groupby([ 'artist_id', 'track_id', 'artist', 'track' ])['artist_id'].count().sort_values(ascending=False)[:,:,artist_name].head(5)
Den vollständigen Code finden Sie hier.