
Mit dem Aufkommen von Mobiltelefonen mit hochwertigen Kameras haben wir begonnen, immer mehr Bilder und Videos von hellen und unvergesslichen Momenten in unserem Leben zu machen. Viele von uns haben Fotoarchive, die sich über Jahrzehnte erstrecken und Tausende von Bildern umfassen, wodurch die Navigation immer schwieriger wird. Denken Sie daran, wie lange es vor einigen Jahren gedauert hat, ein interessantes Bild zu finden.
Eines der Ziele von Mail.ru Cloud ist es, die einfachsten Mittel für den Zugriff auf und die Suche in Ihren eigenen Foto- und Videoarchiven bereitzustellen. Zu diesem Zweck haben wir vom Mail.ru Computer Vision Team Systeme für die intelligente Bildverarbeitung erstellt und implementiert: Suche nach Objekt, Szene, Gesicht usw. Eine weitere spektakuläre Technologie ist die Erkennung von Meilensteinen. Heute werde ich Ihnen erzählen, wie wir dies mit Deep Learning verwirklicht haben.
Stellen Sie sich die Situation vor: Sie kehren mit einer Menge Fotos von Ihrem Urlaub zurück. Wenn Sie mit Ihren Freunden sprechen, werden Sie gebeten, ein Bild eines sehenswerten Ortes wie Palast, Burg, Pyramide, Tempel, See, Wasserfall, Berg usw. zu zeigen. Sie beeilen sich, durch Ihren Galerieordner zu scrollen und versuchen, einen wirklich guten zu finden. Höchstwahrscheinlich geht es unter Hunderten von Bildern verloren, und Sie sagen, Sie werden es später zeigen.
Wir lösen dieses Problem, indem wir Benutzerfotos in Alben gruppieren. So finden Sie mit wenigen Klicks die benötigten Bilder. Jetzt haben wir Alben zusammengestellt nach Gesicht, Objekt und Szene sowie nach Wahrzeichen.
Fotos mit Sehenswürdigkeiten sind unerlässlich, da sie häufig Höhepunkte unseres Lebens festhalten (z. B. Reisen). Dies können Bilder mit Architektur oder Wildnis im Hintergrund sein. Aus diesem Grund versuchen wir, solche Bilder zu finden und den Benutzern zur Verfügung zu stellen.
Besonderheiten der Landmarkerkennung
Hier gibt es eine Nuance: Man lehrt ein Modell nicht nur und lässt es Landmarken sofort erkennen - es gibt eine Reihe von Herausforderungen.
Erstens können wir nicht klar sagen, was ein „Wahrzeichen“ wirklich ist. Wir können nicht sagen, warum ein Gebäude ein Wahrzeichen ist, ein anderes daneben nicht. Es ist kein formalisiertes Konzept, was die Angabe der Erkennungsaufgabe erschwert.
Zweitens sind Sehenswürdigkeiten unglaublich vielfältig. Dies können Gebäude von historischem oder kulturellem Wert sein, wie ein Tempel, ein Palast oder eine Burg. Alternativ können dies alle Arten von Denkmälern sein. Oder natürliche Merkmale: Seen, Schluchten, Wasserfälle und so weiter. Es gibt auch ein einziges Modell, das alle diese Orientierungspunkte finden sollte.
Drittens gibt es nur sehr wenige Bilder mit Orientierungspunkten. Nach unseren Schätzungen machen sie nur 1 bis 3 Prozent der Benutzerfotos aus. Deshalb können wir es uns nicht leisten, Fehler bei der Erkennung zu machen, denn wenn wir jemandem ein Foto ohne Orientierungspunkt zeigen, ist dies ziemlich offensichtlich und führt zu einer negativen Reaktion. Oder stellen Sie sich umgekehrt vor, Sie zeigen einer Person, die noch nie in den USA war, ein Bild mit einem interessanten Ort in New York. Daher sollte das Erkennungsmodell einen niedrigen FPR (False Positive Rate) aufweisen.
Viertens deaktivieren etwa 50% der Benutzer oder noch häufiger das Speichern von Geodaten. Wir müssen dies berücksichtigen und nur das Bild selbst verwenden, um den Ort zu identifizieren. Heutzutage verwenden die meisten Dienste, die in der Lage sind, Orientierungspunkte zu verarbeiten, Geodaten aus Bildeigenschaften. Unsere anfänglichen Anforderungen waren jedoch strenger.
Lassen Sie mich nun einige Beispiele zeigen.
Hier sind drei gleichartige Objekte, drei gotische Kathedralen in Frankreich. Auf der linken Seite befindet sich die Kathedrale von Amiens, in der Mitte die Kathedrale von Reims und auf der rechten Seite Notre-Dame de Paris.

Selbst ein Mensch braucht einige Zeit, um genau hinzuschauen und festzustellen, dass es sich um verschiedene Kathedralen handelt, aber der Motor sollte in der Lage sein, dasselbe zu tun und sogar schneller als ein Mensch.
Hier ist eine weitere Herausforderung: Alle drei Fotos hier zeigen Notre-Dame de Paris aus verschiedenen Blickwinkeln. Die Fotos sind sehr unterschiedlich, müssen aber noch erkannt und abgerufen werden.

Natürliche Merkmale unterscheiden sich grundlegend von der Architektur. Links ist Caesarea in Israel, rechts der Englische Garten in München.

Diese Fotos geben dem Modell nur sehr wenige Hinweise.
Unsere Methode
Unsere Methode basiert vollständig auf tiefen Faltungs-Neuronalen Netzen. Die Trainingsstrategie, die wir gewählt haben, war das sogenannte Curriculum-Lernen, dh das Lernen in mehreren Schritten. Um eine höhere Effizienz sowohl mit als auch ohne verfügbare Geodaten zu erzielen, haben wir eine spezifische Schlussfolgerung gezogen. Lassen Sie mich Ihnen jeden Schritt genauer erläutern.
Datensatz
Daten sind der Treibstoff des maschinellen Lernens. Zuerst mussten wir den Datensatz zusammenstellen, um das Modell zu lehren.
Wir haben die Welt in 4 Regionen unterteilt, die jeweils in einem bestimmten Schritt des Lernprozesses verwendet werden. Dann haben wir Länder in jeder Region ausgewählt, eine Liste von Städten für jedes Land ausgewählt und eine Reihe von Fotos gesammelt. Nachfolgend einige Beispiele.

Zuerst haben wir versucht, unser Modell aus der erhaltenen Datenbank lernen zu lassen. Die Ergebnisse waren schlecht. Unsere Analyse ergab, dass die Daten verschmutzt waren. Es gab zu viel Lärm, der die Erkennung jedes Orientierungspunkts störte. Was sollten wir tun? Es wäre teuer, umständlich und nicht zu klug, den gesamten Datenbestand manuell zu überprüfen. Daher haben wir ein Verfahren zur automatischen Datenbankbereinigung entwickelt, bei dem die manuelle Handhabung nur in einem Schritt verwendet wird: Wir haben 3 bis 5 Referenzfotos für jeden Orientierungspunkt ausgewählt, die das gewünschte Objekt definitiv in einem mehr oder weniger geeigneten Winkel zeigten. Es funktioniert schnell genug, da die Menge solcher Referenzdaten im Vergleich zur gesamten Datenbank gering ist. Dann wird eine automatische Reinigung basierend auf tiefen Faltungs-Neuronalen Netzen durchgeführt.
Weiter werde ich den Begriff "Einbettung" verwenden, womit ich Folgendes meine. Wir haben ein Faltungsnetzwerk. Wir haben es trainiert, um Objekte zu klassifizieren, dann haben wir die letzte Klassifizierungsebene abgeschnitten, einige Bilder ausgewählt, sie vom Netzwerk analysieren lassen und am Ausgang einen numerischen Vektor erhalten. Das nenne ich Einbettung.
Wie ich bereits sagte, haben wir unseren Lernprozess in mehreren Schritten angeordnet, die Teilen unserer Datenbank entsprechen. Also nehmen wir zuerst entweder das neuronale Netzwerk aus dem vorhergehenden Schritt oder das Initialisierungsnetzwerk.
Wir haben Referenzfotos eines Wahrzeichens, verarbeiten sie vom Netzwerk und erhalten mehrere Einbettungen. Jetzt können wir mit der Datenbereinigung fortfahren. Wir nehmen alle Bilder aus dem Datensatz für das Wahrzeichen auf und lassen jedes Bild auch vom Netzwerk verarbeiten. Wir erhalten einige Einbettungen und bestimmen für jede die Entfernung zu Referenz-Einbettungen. Dann bestimmen wir die durchschnittliche Entfernung und behandeln das Objekt als Nicht-Landmark, wenn es einen Schwellenwert überschreitet, der ein Parameter des Algorithmus ist. Wenn der durchschnittliche Abstand unter dem Schwellenwert liegt, behalten wir das Foto.
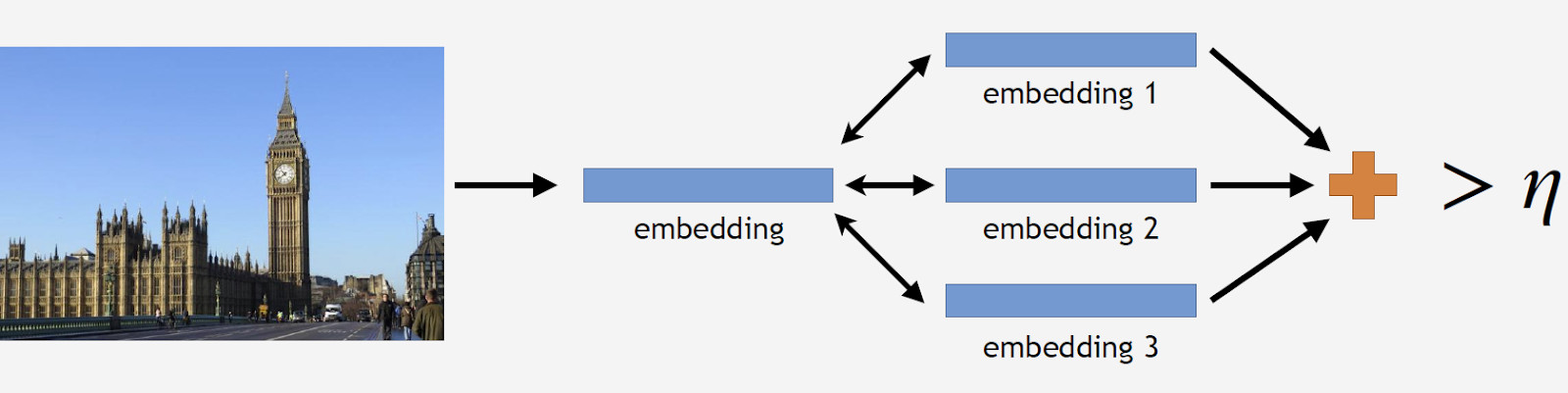
Als Ergebnis hatten wir eine Datenbank, die über 11.000 Sehenswürdigkeiten aus über 500 Städten in 70 Ländern enthielt, mehr als 2,3 Millionen Fotos. Denken Sie daran, dass der größte Teil der Fotos überhaupt keine Orientierungspunkte aufweist. Wir müssen es unseren Modellen irgendwie erzählen. Aus diesem Grund haben wir unserer Datenbank 900.000 Fotos ohne Orientierungspunkte hinzugefügt und unser Modell mit dem resultierenden Datensatz trainiert.
Wir haben einen Offline-Test eingeführt, um die Lernqualität zu messen. Da Landmarken nur in 1 bis 3% aller Fotos vorkommen, haben wir manuell einen Satz von 290 Bildern zusammengestellt, die eine Landmarke zeigten. Diese Fotos waren sehr vielfältig und komplex, mit einer großen Anzahl von Objekten, die aus verschiedenen Winkeln aufgenommen wurden, um den Test für das Modell so schwierig wie möglich zu machen. Nach dem gleichen Muster haben wir 11.000 Fotos ohne Orientierungspunkte ausgewählt, was ebenfalls ziemlich kompliziert ist, und wir haben versucht, Objekte zu finden, die den Orientierungspunkten in unserer Datenbank sehr ähnlich sind.
Um die Lernqualität zu bewerten, messen wir die Genauigkeit unseres Modells anhand von Fotos mit und ohne Orientierungspunkte. Dies sind unsere beiden Hauptmetriken.
Bestehende Ansätze
In der Literatur gibt es relativ wenige Informationen zur Erkennung von Orientierungspunkten. Die meisten Lösungen basieren auf lokalen Funktionen. Die Hauptidee ist, dass wir ein Abfragebild und ein Bild aus der Datenbank haben. Lokale Merkmale - Schlüsselpunkte - werden gefunden und dann abgeglichen. Wenn die Anzahl der Übereinstimmungen groß genug ist, schließen wir, dass wir einen Orientierungspunkt gefunden haben.
Derzeit ist die beste Methode DELF (Deep Local Features) von Google, bei der lokale Features mit Deep Learning kombiniert werden. Indem ein Eingabebild vom Faltungsnetzwerk verarbeitet wird, erhalten wir einige DELF-Merkmale.
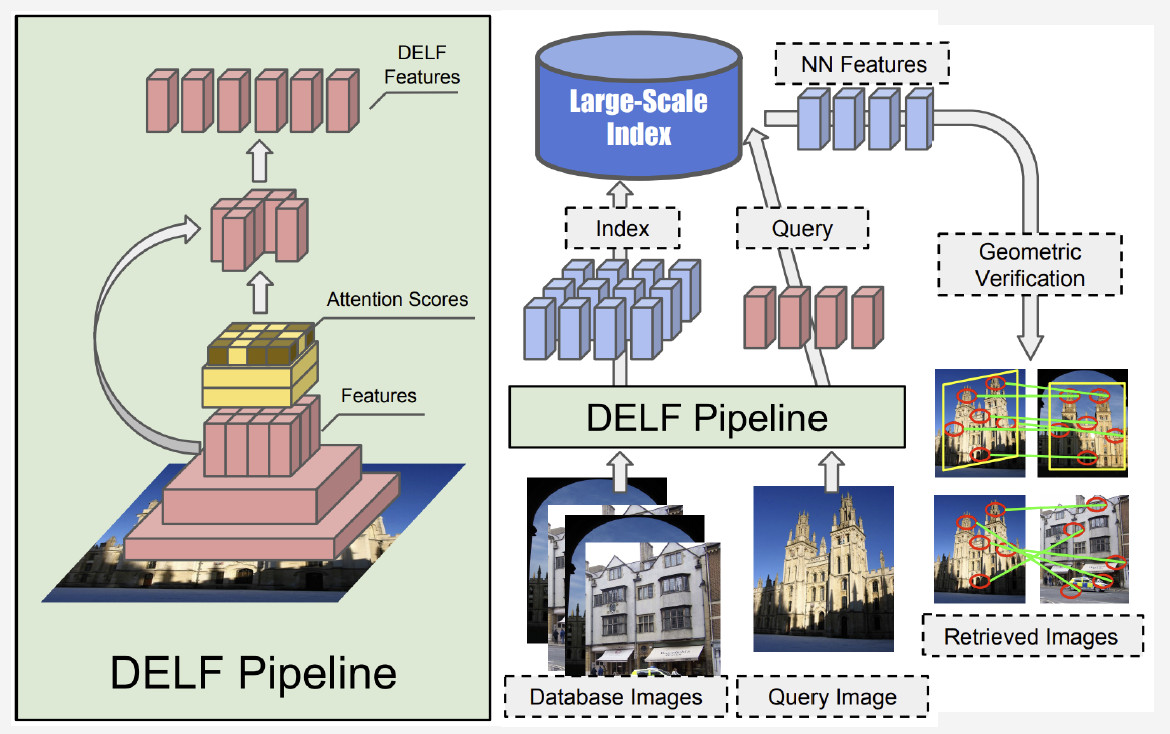
Wie funktioniert die Erkennung von Orientierungspunkten? Wir haben eine Reihe von Fotos und ein Eingabebild und möchten wissen, ob es eine Landmarke zeigt oder nicht. Durch Ausführen des DELF-Netzwerks aller Fotos können entsprechende Funktionen für die Datenbank und das Eingabebild erhalten werden. Dann führen wir eine Suche nach der Methode des nächsten Nachbarn durch und erhalten Kandidatenbilder mit Merkmalen am Ausgang. Wir verwenden eine geometrische Überprüfung, um die Merkmale abzugleichen: Wenn dies erfolgreich ist, schließen wir, dass das Bild einen Orientierungspunkt zeigt.
Faltungs-Neuronales Netzwerk
Das Pre-Training ist entscheidend für Deep Learning. Deshalb haben wir eine Datenbank mit Szenen verwendet, um unser neuronales Netzwerk vorab zu trainieren. Warum so? Eine Szene ist ein Mehrfachobjekt, das eine große Anzahl anderer Objekte umfasst. Landmark ist eine Instanz einer Szene. Indem wir das Modell mit einer solchen Datenbank vorab trainieren, können wir ihm eine Vorstellung von einigen Funktionen auf niedriger Ebene geben, die dann für eine erfolgreiche Erkennung von Orientierungspunkten verallgemeinert werden können.
Wir haben ein neuronales Netzwerk aus der Residual-Netzwerkfamilie als Modell verwendet. Der entscheidende Unterschied solcher Netzwerke besteht darin, dass sie einen Restblock verwenden, der eine Sprungverbindung enthält, die es einem Signal ermöglicht, über Schichten mit Gewichten zu springen und frei zu passieren. Eine solche Architektur ermöglicht es, tiefe Netzwerke mit einem hohen Maß an Qualität zu trainieren und verschwindende Gradienteneffekte zu kontrollieren, was für das Training wesentlich ist.
Unser Modell ist Wide ResNet-50-2, eine Version von ResNet-50, bei der die Anzahl der Windungen im internen Engpassblock verdoppelt wird.

Das Netzwerk funktioniert sehr gut. Wir haben es mit unserer Szenendatenbank getestet und hier sind die Ergebnisse:
Wide ResNet arbeitete fast doppelt so schnell wie ResNet-200. Schließlich ist die Laufgeschwindigkeit entscheidend für die Produktion. Angesichts all dieser Überlegungen haben wir Wide ResNet-50-2 als unser wichtigstes neuronales Netzwerk ausgewählt.
Schulung
Wir brauchen eine Verlustfunktion, um unser Netzwerk zu trainieren. Wir haben uns für den metrischen Lernansatz entschieden: Ein neuronales Netzwerk wird so trainiert, dass Elemente derselben Klasse zu einem Cluster strömen, während Cluster für verschiedene Klassen so weit wie möglich voneinander entfernt sein sollen. Für Orientierungspunkte haben wir den Center-Verlust verwendet, der Elemente einer Klasse in Richtung eines Centers zieht. Ein wichtiges Merkmal dieses Ansatzes ist, dass keine negative Abtastung erforderlich ist, was in späteren Epochen ziemlich schwierig wird.
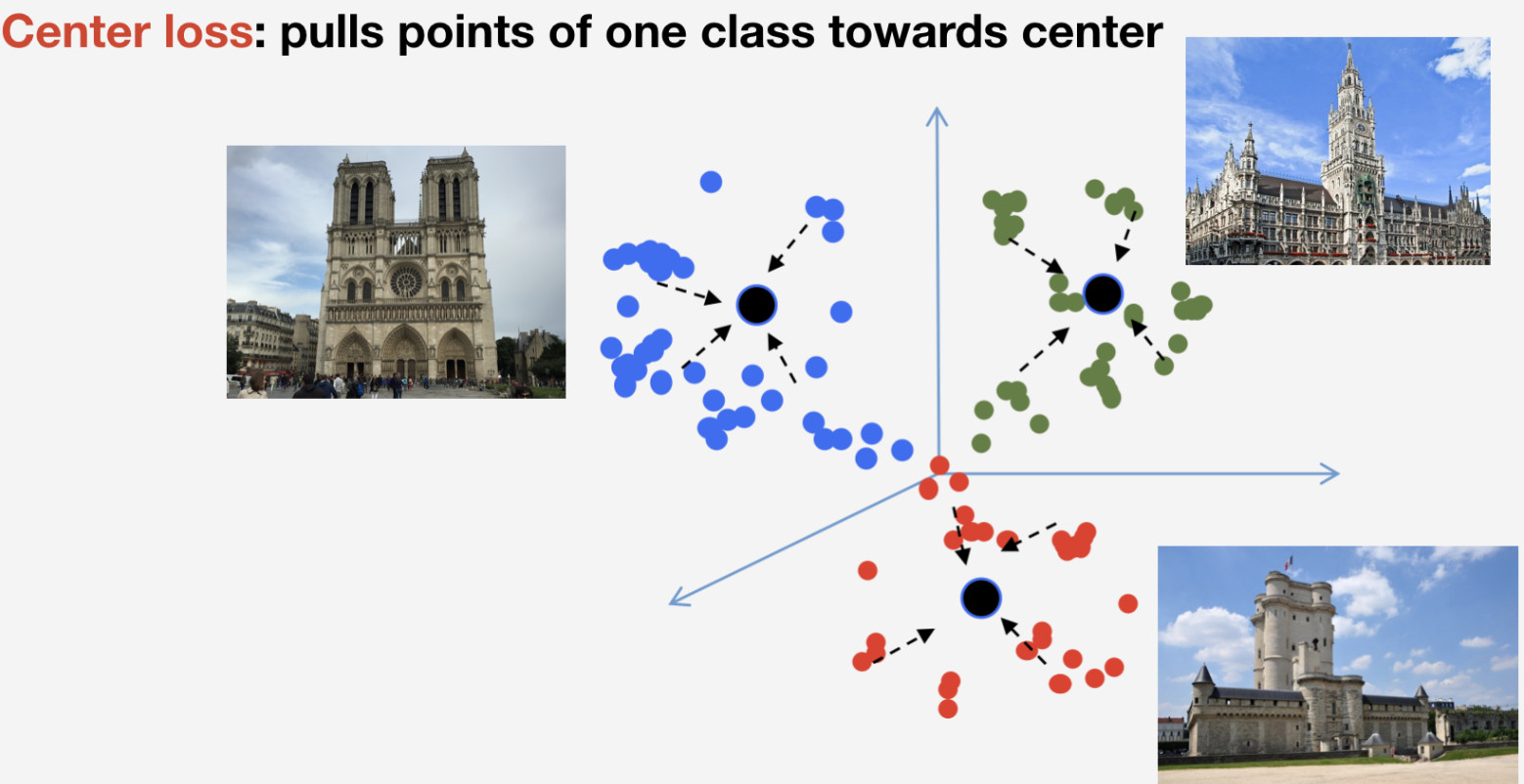
Denken Sie daran, dass wir n Klassen von Orientierungspunkten und eine weitere Klasse von „Nicht-Orientierungspunkten“ haben, für die der Verlust des Zentrums nicht verwendet wird. Wir implizieren, dass ein Orientierungspunkt ein und dasselbe Objekt ist und eine Struktur hat. Daher ist es sinnvoll, sein Zentrum zu bestimmen. Nicht-Landmarken können sich auf alles beziehen, daher ist es nicht sinnvoll, das Zentrum dafür zu bestimmen.
Wir setzen das alles dann zusammen und es gibt unser Modell für das Training. Es besteht aus drei Hauptteilen:
- Wide ResNet 50-2 Faltungs-Neuronales Netzwerk mit einer Datenbank von Szenen vorab trainiert;
- Einbettungsteil, umfassend eine vollständig verbundene Schicht und eine Chargennormschicht;
- Klassifikator, der eine vollständig verbundene Schicht ist, gefolgt von einem Paar aus Softmax-Verlust und Center-Verlust.

Wie Sie sich erinnern, ist unsere Datenbank nach Regionen in 4 Teile unterteilt. Wir verwenden diese 4 Teile in einem Lehrplan-Lernparadigma. Wir haben einen aktuellen Datensatz und fügen in jeder Lernphase einen weiteren Teil der Welt hinzu, um einen neuen Datensatz für das Training zu erhalten.
Das Modell besteht aus drei Teilen, und wir verwenden für jeden Teil des Trainingsprozesses eine spezifische Lernrate. Dies ist erforderlich, damit das Netzwerk sowohl Orientierungspunkte aus einem neuen Datensatzteil, den wir hinzugefügt haben, lernen als auch bereits gelernte Daten speichern kann. Viele Experimente haben gezeigt, dass dieser Ansatz am effizientesten ist.
Also haben wir unser Modell trainiert. Jetzt müssen wir erkennen, wie es funktioniert. Verwenden wir die Klassenaktivierungskarte, um den Teil des Bildes zu finden, auf den unser neuronales Netzwerk am schnellsten reagiert. Das folgende Bild zeigt Eingabebilder in der ersten Zeile, und in der zweiten Zeile werden dieselben Bilder angezeigt, die mit der Klassenaktivierungskarte aus dem Netzwerk überlagert sind, das wir im vorherigen Schritt trainiert haben.

Die Heatmap zeigt, welche Teile des Bildes stärker vom Netzwerk besucht werden. Wie die Klassenaktivierungskarte zeigt, hat unser neuronales Netzwerk das Konzept des Orientierungspunkts erfolgreich gelernt.
Folgerung
Jetzt müssen wir dieses Wissen irgendwie nutzen, um Dinge zu erledigen. Da wir den Center-Verlust für das Training verwendet haben, erscheint es im Falle von Inferenzen ziemlich logisch, auch Zentroide für Orientierungspunkte zu bestimmen.
Zu diesem Zweck nehmen wir einen Teil der Bilder aus dem Trainingsset für ein Wahrzeichen, beispielsweise den Bronze-Reiter in Sankt Petersburg. Dann lassen wir sie vom Netzwerk verarbeiten, Einbettungen erhalten, den Durchschnitt ermitteln und einen Schwerpunkt ableiten.
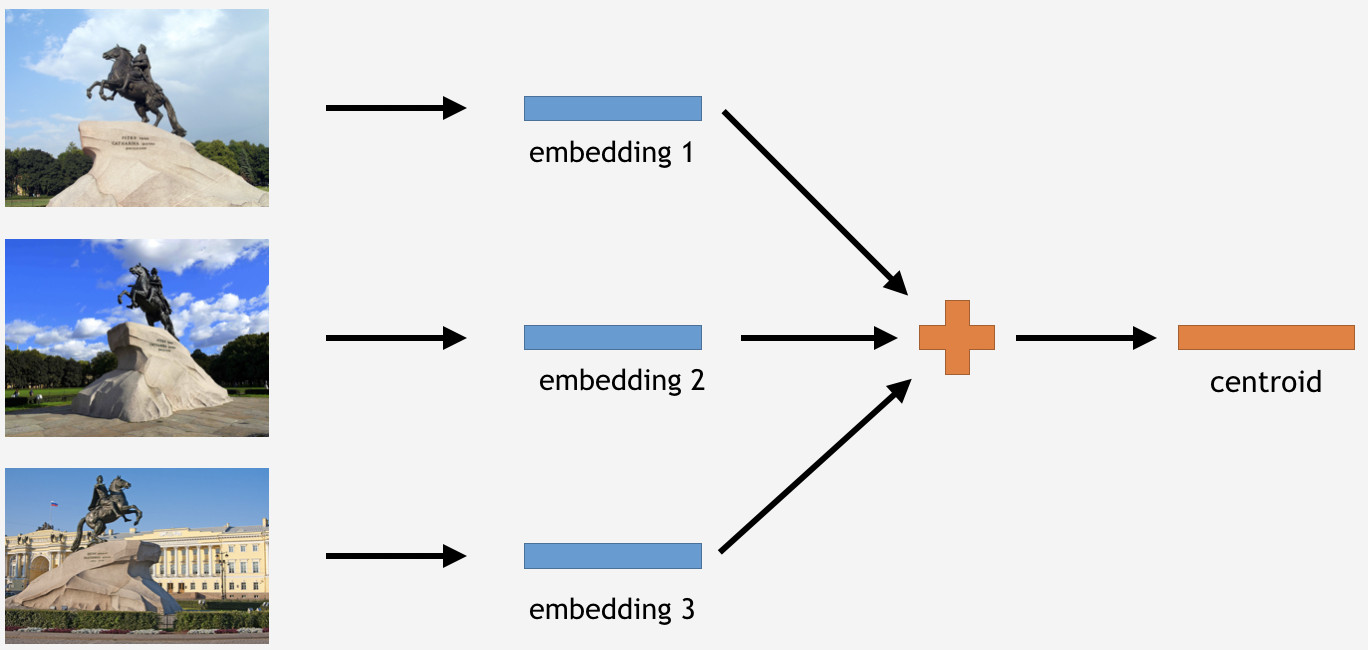
Hier ist jedoch eine Frage: Wie viele Zentroide pro Landmarke ist sinnvoll abzuleiten? Anfangs schien es klar und logisch zu sein zu sagen: ein Schwerpunkt. Nicht genau, wie sich herausstellte. Wir haben uns zunächst entschieden, auch einen einzelnen Schwerpunkt zu erstellen, und das Ergebnis war nicht schlecht. Warum also mehrere Zentroide?
Erstens sind die Daten, die wir haben, nicht so sauber. Obwohl wir den Datensatz bereinigt haben, haben wir nur offensichtliche Abfalldaten entfernt. Es kann jedoch immer noch Bilder geben, die nicht offensichtlich verschwendet werden, sondern das Ergebnis nachteilig beeinflussen.
Zum Beispiel habe ich einen Winterpalast in Sankt Petersburg. Ich möchte einen Schwerpunkt dafür ableiten. Der Datensatz enthält jedoch einige Fotos mit dem Palastplatz und dem Bogen des Hauptquartiers, da diese Objekte nahe beieinander liegen. Wenn der Schwerpunkt für alle Bilder bestimmt werden soll, ist das Ergebnis nicht so stabil. Was wir tun müssen, ist, ihre vom neuronalen Netzwerk abgeleiteten Einbettungen irgendwie zu gruppieren, nur den Schwerpunkt zu nehmen, der sich mit dem Winterpalast befasst, und die resultierenden Daten zu mitteln.

Zweitens könnten Fotos aus verschiedenen Blickwinkeln aufgenommen worden sein.
Hier ist ein Beispiel für ein solches Verhalten, das am Belfried von Brügge veranschaulicht wird. Dafür wurden zwei Zentroide abgeleitet. In der oberen Reihe des Bildes befinden sich die Fotos, die näher am ersten Schwerpunkt liegen, und in der zweiten Reihe diejenigen, die näher am zweiten Schwerpunkt liegen.

Der erste Schwerpunkt befasst sich mit mehr „großartigen“ Fotos, die auf kurzer Distanz auf dem Markt in Brügge aufgenommen wurden. Der zweite Schwerpunkt befasst sich mit Fotografien, die in bestimmten Straßen aus der Ferne aufgenommen wurden.
Wie sich herausstellt, können wir durch Ableiten mehrerer Zentroide pro Orientierungspunktklasse unterschiedliche Inferenzwinkel für diesen Orientierungspunkt reflektieren.
Wie erhalten wir diese Mengen zur Ableitung von Zentroiden? Wir wenden hierarchisches Clustering (vollständiger Link) auf Datensätze für jeden Orientierungspunkt an. Wir verwenden es, um gültige Cluster zu finden, aus denen Zentroide abgeleitet werden sollen. Mit gültigen Clustern meinen wir diejenigen, die aufgrund von Clustering mindestens 50 Fotos umfassen. Die anderen Cluster werden abgelehnt. Als Ergebnis haben wir rund 20% der Orientierungspunkte mit mehr als einem Schwerpunkt erhalten.
Nun zum Schluss. Es wird in zwei Schritten erhalten: Erstens führen wir das Eingabebild in unser neuronales Faltungsnetzwerk ein und erhalten eine Einbettung. Anschließend ordnen wir die Einbettung mit Hilfe des Punktprodukts den Schwerpunkten zu. Wenn Bilder Geodaten enthalten, beschränken wir die Suche auf Schwerpunkte, die sich auf Orientierungspunkte beziehen, die sich innerhalb eines Quadrats von 1 x 1 km vom Bildort befinden. Dies ermöglicht eine genauere Suche und einen niedrigeren Schwellenwert für den nachfolgenden Abgleich. Wenn der resultierende Abstand den Schwellenwert überschreitet, der ein Parameter des Algorithmus ist, schließen wir, dass ein Foto einen Orientierungspunkt mit dem maximalen Punktproduktwert hat. Wenn es weniger ist, ist es ein Foto ohne Orientierungspunkt.
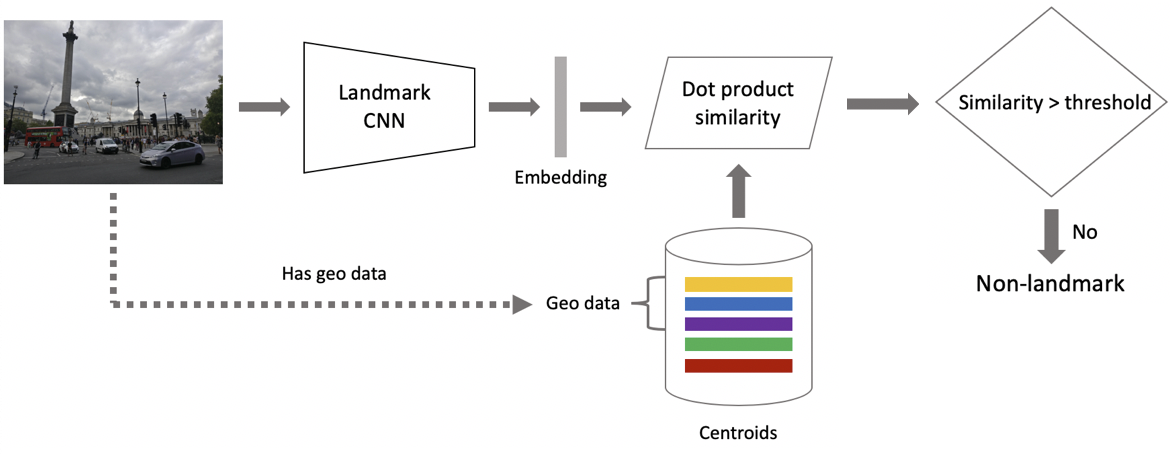
Angenommen, ein Foto hat einen Orientierungspunkt. Wenn wir Geodaten haben, verwenden wir diese und leiten eine Antwort ab. Wenn keine Geodaten verfügbar sind, führen wir eine zusätzliche Überprüfung durch. Beim Bereinigen des Datensatzes haben wir für jede Klasse eine Reihe von Referenzbildern erstellt. Wir können Einbettungen für sie bestimmen und dann den durchschnittlichen Abstand von ihnen zur Einbettung des Abfragebilds ermitteln. Wenn ein bestimmter Schwellenwert überschritten wird, wird die Überprüfung bestanden, und wir bringen Metadaten ein und leiten ein Ergebnis ab. Es ist wichtig zu beachten, dass wir dieses Verfahren für mehrere Orientierungspunkte ausführen können, die in einem Bild gefunden wurden.
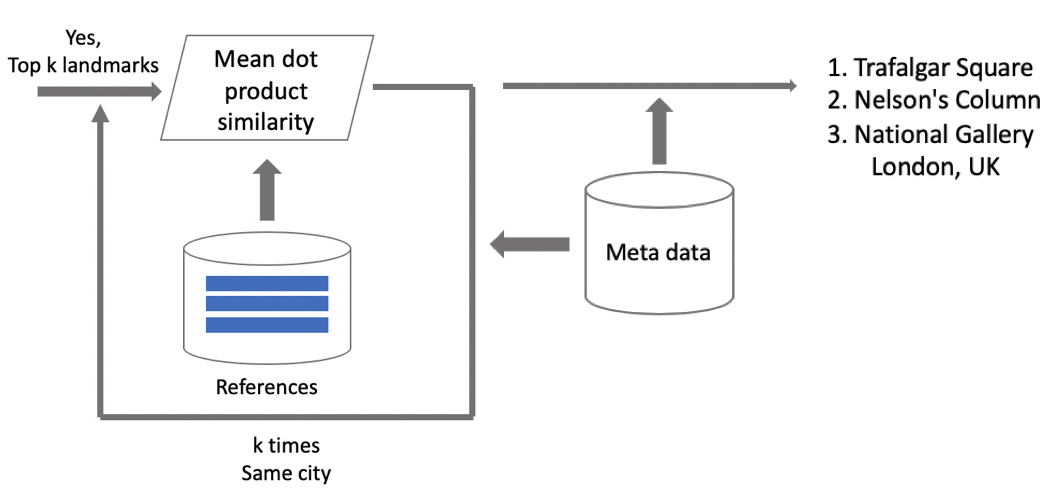
Testergebnisse
Wir haben unser Modell mit DELF verglichen, für das wir Parameter verwendet haben, mit denen es die beste Leistung in unserem Test zeigen würde. Die Ergebnisse sind nahezu identisch.
Dann haben wir Orientierungspunkte in zwei Typen eingeteilt: häufig (über 100 Fotos in der Datenbank), die 87% aller Orientierungspunkte im Test ausmachten, und selten. Unser Modell funktioniert gut mit den häufigen: 85,3% Präzision. Mit seltenen Orientierungspunkten hatten wir 46%, was auch überhaupt nicht schlecht war, was bedeutet, dass unser Ansatz selbst mit wenigen Daten ziemlich gut funktionierte.
Dann haben wir einen A / B-Test mit Benutzerfotos durchgeführt. Infolgedessen stieg die Conversion-Rate für den Kauf von Cloud-Speicherplatz um 10%, die Conversion-Rate für die Deinstallation von mobilen Apps um 3% und die Anzahl der Albumaufrufe um 13%.
Vergleichen wir unsere Geschwindigkeit mit der von DELF. Bei der GPU erfordert DELF 7 Netzwerkläufe, da 7 Bildskalen verwendet werden, während bei unserem Ansatz nur 1 verwendet wird. Bei der CPU verwendet DELF eine längere Suche nach der Methode des nächsten Nachbarn und eine sehr lange geometrische Überprüfung. Am Ende war unsere Methode mit CPU 15-mal schneller. Unser Ansatz zeigt in beiden Fällen eine höhere Geschwindigkeit, was für die Produktion entscheidend ist.
Ergebnisse: Erinnerungen aus dem Urlaub
Am Anfang dieses Artikels erwähnte ich eine Lösung zum Scrollen und Finden der gewünschten Landmarkenbilder. Hier ist es.
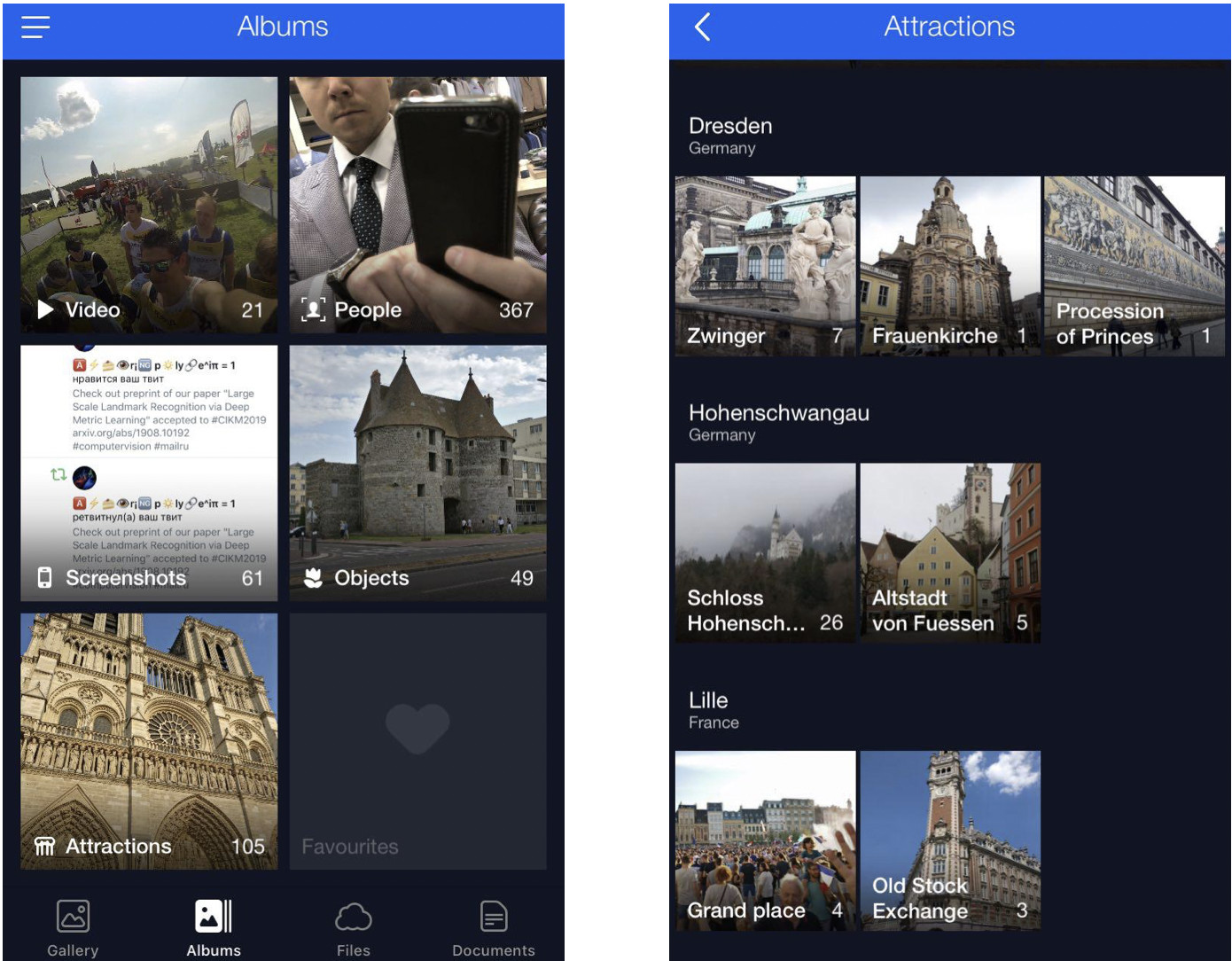
Dies ist meine Cloud, in der alle Fotos in Alben klassifiziert sind. Es gibt Alben "People", "Objects" und "Attractions". Im Album "Attraktionen" werden die Orientierungspunkte in Alben eingeteilt, die nach Stadt gruppiert sind. Ein Klick auf Dresdner Zwinger öffnet ein Album nur mit Fotos dieses Wahrzeichens.
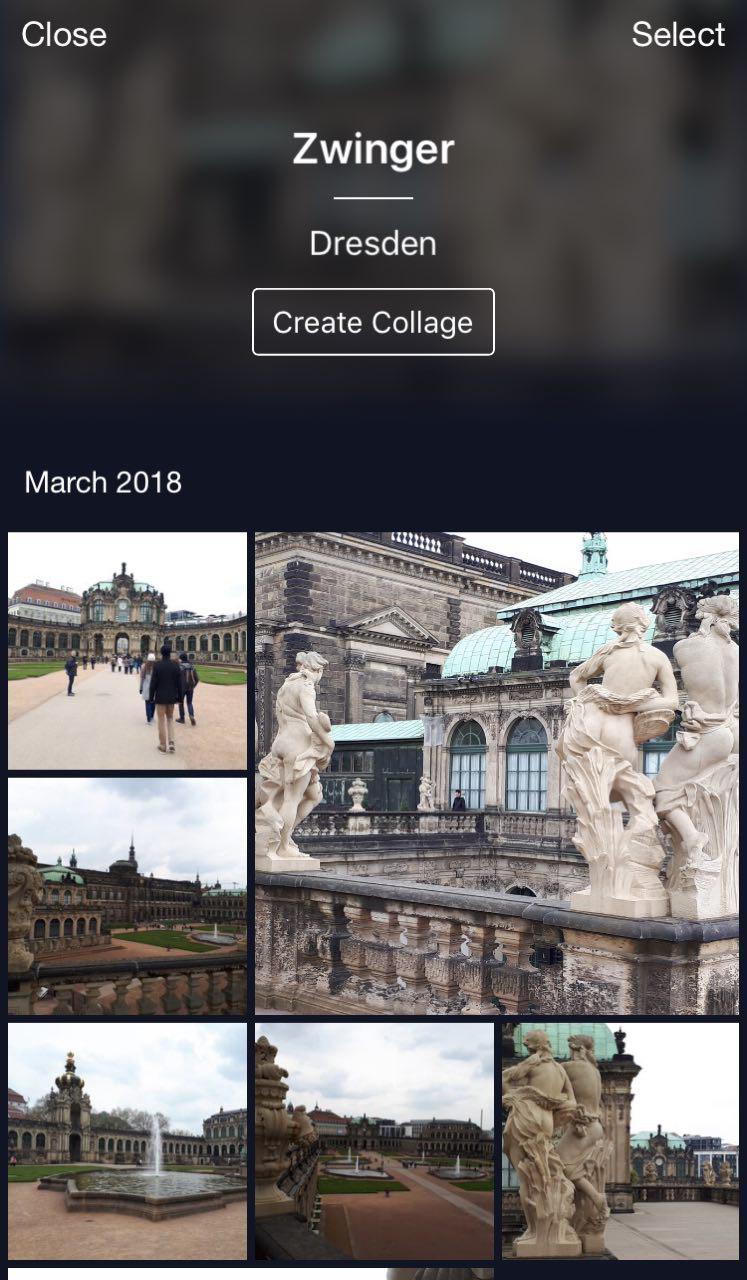
Eine praktische Funktion: Sie können in den Urlaub fahren, Fotos aufnehmen und in Ihrer Cloud speichern. Wenn Sie sie später auf Instagram hochladen oder mit Freunden und Familie teilen möchten, müssen Sie nicht zu lange suchen und auswählen - die gewünschten Fotos sind mit nur wenigen Klicks verfügbar.
Schlussfolgerungen
Ich möchte Sie an die Hauptmerkmale unserer Lösung erinnern.
- Halbautomatische Datenbankbereinigung. Für die anfängliche Zuordnung ist ein wenig manuelle Arbeit erforderlich, und das neuronale Netzwerk erledigt den Rest. Auf diese Weise können neue Daten schnell bereinigt und zum erneuten Trainieren des Modells verwendet werden.
- Wir verwenden tiefe Faltungs-Neuronale Netze und tiefes metrisches Lernen, wodurch wir die Struktur in Klassen effizient lernen können.
- Wir haben das Lernen von Lehrplänen, d. H. Das Training in Teilen, als Trainingsparadigma verwendet. Dieser Ansatz war für uns sehr hilfreich. Wir verwenden mehrere Inferenzschwerpunkte, die es ermöglichen, sauberere Daten zu verwenden und unterschiedliche Ansichten von Orientierungspunkten zu finden.
Es scheint, dass die Objekterkennung eine triviale Aufgabe ist. Bei der Untersuchung der realen Benutzeranforderungen stellen wir jedoch neue Herausforderungen wie die Erkennung von Orientierungspunkten. Diese Technik ermöglicht es, Menschen mithilfe neuronaler Netze etwas Neues über die Welt zu erzählen. Es ist sehr ermutigend und motivierend!