Hallo allerseits!
Ich habe bereits in diesem Blog über die Organisation eines modularen Überwachungssystems für die Microservice-Architektur und über den Übergang von Graphite + Whisper zu Graphite + ClickHouse zum Speichern von Metriken unter hoher Last gesprochen. Danach schrieb mein Kollege Sergey Noskov über die allererste Verbindung unseres Überwachungssystems - den von uns entwickelten Bioyino , einen verteilten skalierbaren Metrikaggregator .
Es ist an der Zeit, die Informationen darüber, wie wir die Überwachung in Avito vorbereiten, aufzufrischen. Unser letzter Artikel war bereits im Jahr 2018 und während dieser Zeit gab es einige interessante Änderungen in der Überwachungsarchitektur, im Trigger- und Benachrichtigungsmanagement, verschiedene Datenoptimierungen in ClickHouse und andere Innovationen. über die ich dir nur erzählen möchte.

Aber fangen wir in der richtigen Reihenfolge an.
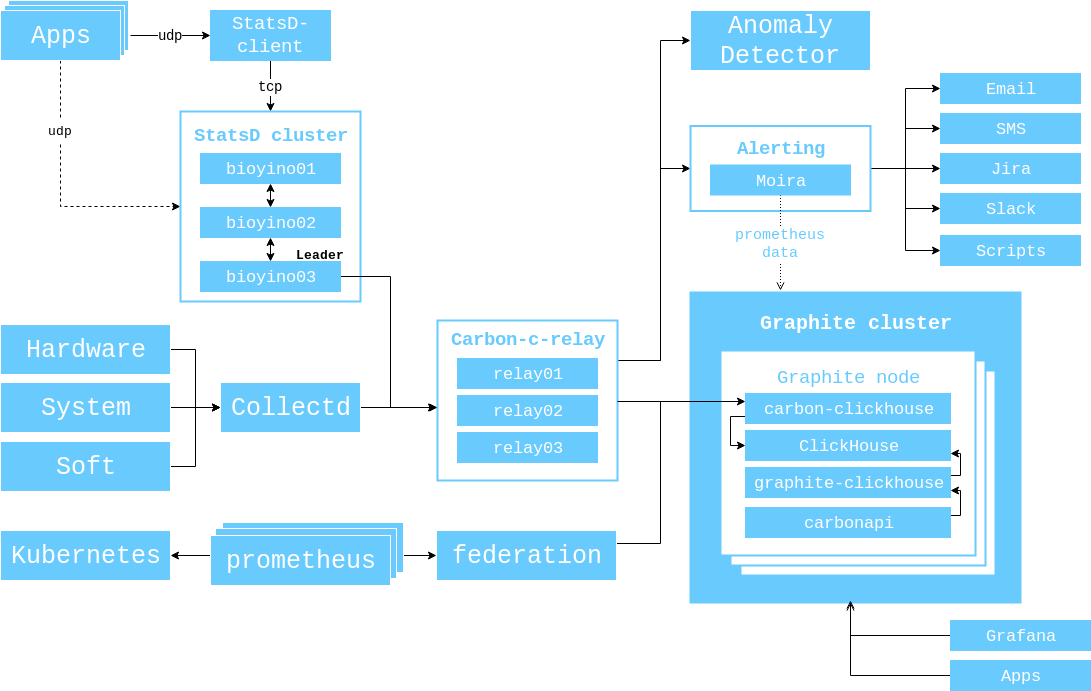
Bereits 2017 habe ich ein Diagramm der Interaktion von Komponenten gezeigt, das zu diesem Zeitpunkt relevant war, und ich möchte es erneut demonstrieren, damit Sie nicht noch einmal die Registerkarten wechseln müssen.

Von diesem Moment an geschah Folgendes.
Die Anzahl der Server im Graphite-Cluster wurde von 3 auf 6 erhöht.
( 56 CPU 2.60GHz, 384GB RAM, 10 SSD SAS 745GB, Raid 6, 10GBit/s Net ).
Wir haben brubeck durch bioyino ersetzt - unsere eigene Implementierung von StatsD mit Rust - und sogar einen ganzen Artikel darüber geschrieben . Nach der Veröffentlichung des Artikels haben wir jedoch die Unterstützung für Tags (Graphite) und Raft in diesem Artikel erwähnt, um einen Anführer auszuwählen.
Wir haben die Möglichkeit erarbeitet, Bioyino als StatsD-Agent zu verwenden, und solche Agenten neben den Monolith-Instanzen sowie dort platziert, wo sie in k8s benötigt wurden.
Wir haben das alte Munin-Überwachungssystem endlich losgeworden (formal haben wir es noch, aber seine Daten werden nicht mehr verwendet).
Die Datenerfassung aus Kubernetes-Clustern wurde über Prometheus / Federations organisiert, da Heapster in neuen Versionen von Kubernetes nicht unterstützt wurde.
Überwachung
In den letzten zwei Jahren hat sich die Anzahl der akzeptierten und verarbeiteten Metriken um das Neunfache erhöht.
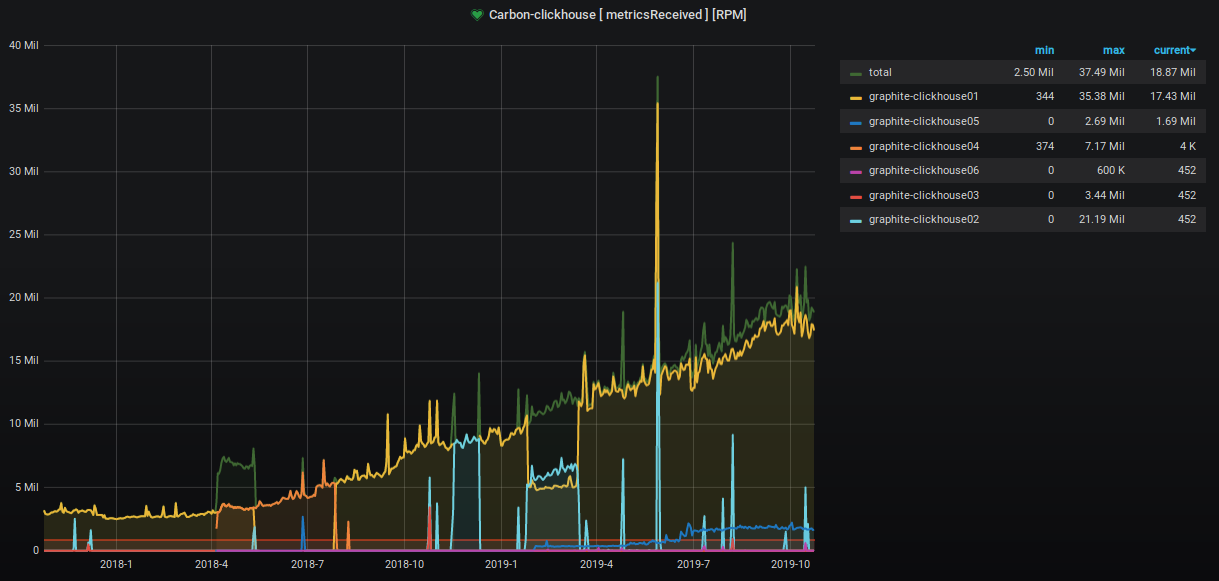
Der Prozentsatz des belegten Serverplatzes steigt ebenfalls unaufhaltsam an, und wir unternehmen verschiedene Schritte, um ihn zu verringern. Dies ist in der Tabelle deutlich sichtbar.
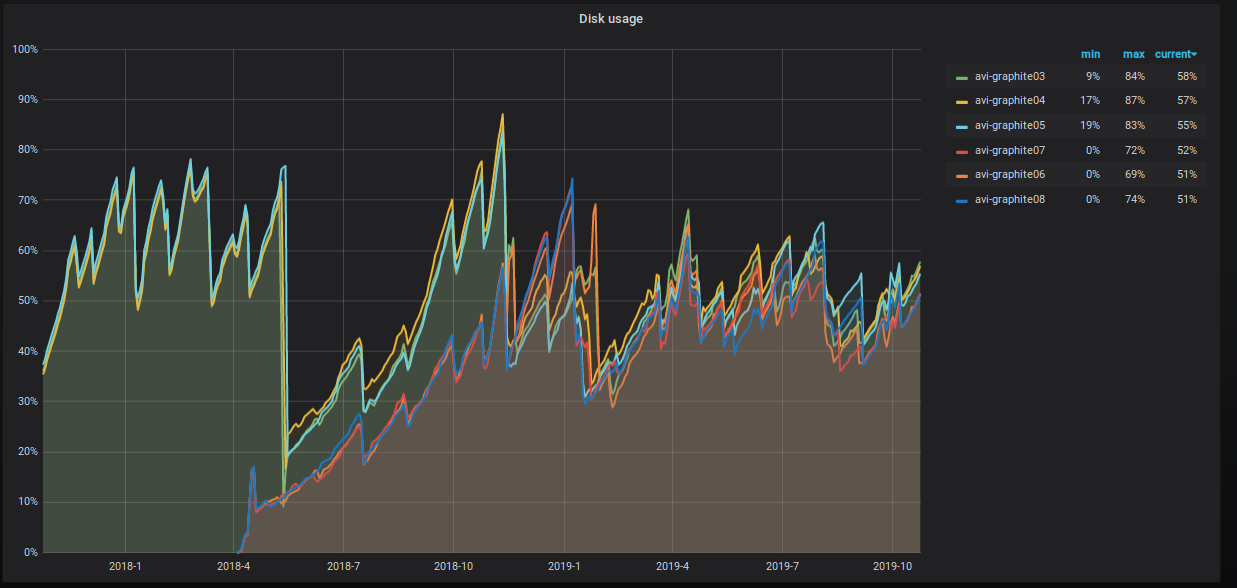
Was genau machen wir?
10 10 10 * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data' and max_date between today()-55 AND today()-35;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "OPTIMIZE TABLE graphite.data PARTITION ('"$PART"') FINAL";done
- Wir haben Datentabellen geteilt. Jetzt haben wir drei Shards mit zwei Replikaten mit jeweils einem Hash-Sharding-Schlüssel für die Metrik. Dieser Ansatz bietet uns die Möglichkeit, Rollup-Prozeduren durchzuführen , da sich alle Werte für eine bestimmte Metrik innerhalb desselben Shards befinden und der Speicherplatz auf allen Shards einheitlich belegt ist.
Das verteilte Tabellenschema lautet wie folgt.
CREATE TABLE graphite.data_all ( `Path` String, `Value` Float64, `Time` UInt32, `Date` Date, `Timestamp` UInt32 ) ENGINE = Distributed ( 'graphite_cluster', 'graphite', 'data', jumpConsistentHash(cityHash64(Path), 3) )
Wir haben dem Benutzer auch "Standard" -Schreibrechte zugewiesen und die Ausführung von Schreibprozeduren in die Tabellen an ein separates BenutzersystemXXX systemXXX .
Die Konfiguration des Graphite-Clusters in ClickHouse ist wie folgt.
<remote_servers> <graphite_cluster> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse01</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse04</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse02</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse05</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse03</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse06</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> </graphite_cluster> </remote_servers>
Zusätzlich zur Schreiblast hat die Anzahl der Anforderungen zum Lesen von Daten aus Graphite zugenommen. Diese Daten werden verwendet für:
- Triggerverarbeitung und Alarmgenerierung;
- Anzeigen von Grafiken auf Monitoren im Büro sowie auf Laptop- und PC-Bildschirmen einer wachsenden Anzahl von Mitarbeitern des Unternehmens.
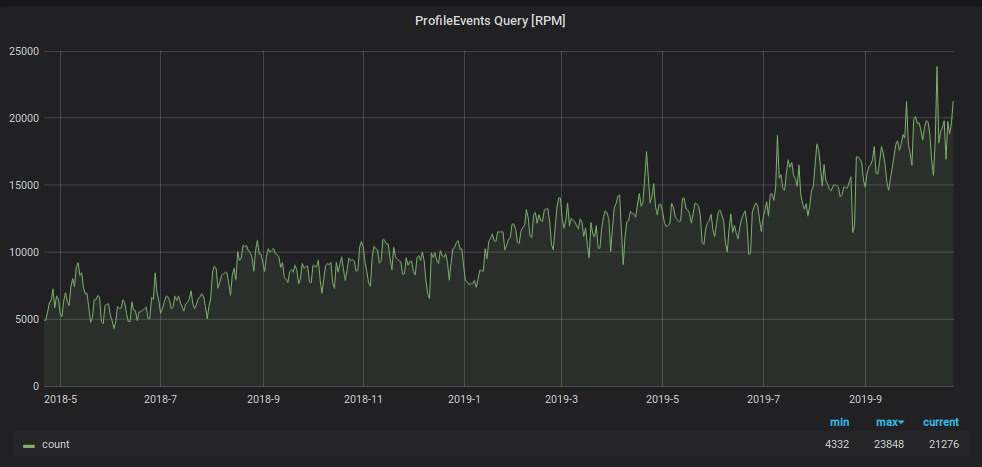
Um zu verhindern, dass die Überwachung unter dieser Last ertrinkt, haben wir einen anderen Hack verwendet: Wir speichern die Daten der letzten zwei Tage in einer separaten „kleinen“ Platte und senden dort alle Leseanforderungen für die letzten zwei Tage, wodurch die Last auf der Haupt-Shard-Tabelle verringert wird. Auch für dieses „kleine“ Tablet haben wir ein Speicherschema mit umgekehrter Metrik verwendet, das die Suche nach den darin enthaltenen Daten erheblich beschleunigte und eine tägliche Partition dafür organisierte. Das Schema dieser Platte ist wie folgt.
CREATE TABLE graphite.data_reverse ( `Path` String, `Value` Float64, `Time` UInt32 CODEC(Delta(4), ZSTD(1)), `Date` Date, `Timestamp` UInt32 ) ENGINE = ReplicatedGraphiteMergeTree ( '/clickhouse/tables/{cluster}/data_reverse', '{replica}', 'graphite_rollup' ) PARTITION BY Date ORDER BY (Path, Time) SETTINGS index_granularity = 4096
Um Daten darauf zu leiten, haben wir der Konfigurationsdatei der Carbon-Clickhouse- Anwendung einen neuen Abschnitt hinzugefügt.
[upload.graphite_reverse] type = "points-reverse" table = "graphite.data_reverse" threads = 2 url = "http://systemXXX:XXXXXXX@localhost:8123/" timeout = "60s" cache-ttl = "6h0m0s" zero-timestamp = true
Um Partitionen zu löschen, die älter als zwei Tage sind, haben wir eine Cron-Aufgabe geschrieben. Es sieht ungefähr so aus.
1 12 * * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data_reverse' and max_date<today()-2;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "ALTER TABLE graphite.data_reverse DROP PARTITION ('"$PART"')";done
Um Daten aus der Tabelle zu lesen, wurde in der Konfigurationsdatei für Graphit-Clickhouse ein Abschnitt hinzugefügt:
[[data-table]] table = "graphite.data_reverse" max-age = "48h" reverse = true
Als Ergebnis haben wir eine Tabelle, in der 100% der Daten auf alle sechs Server repliziert werden, die die gesamte Leselast von Anforderungen mit einem Fenster von weniger als zwei Tagen verarbeiten (und wir haben 95% davon). Außerdem haben wir eine Sharded-Tabelle mit 1/3 der Daten auf jedem Shard, in der alle historischen Daten gelesen werden können. Und selbst wenn solche Anforderungen viel kleiner sind, ist die Belastung durch sie viel höher.
Was passiert mit der CPU ?! Infolge der Zunahme des Volumens der aufgezeichneten und gelesenen Daten im Graphite-Cluster stieg auch die Gesamt-CPU-Auslastung der Server. Es sieht ungefähr so aus.
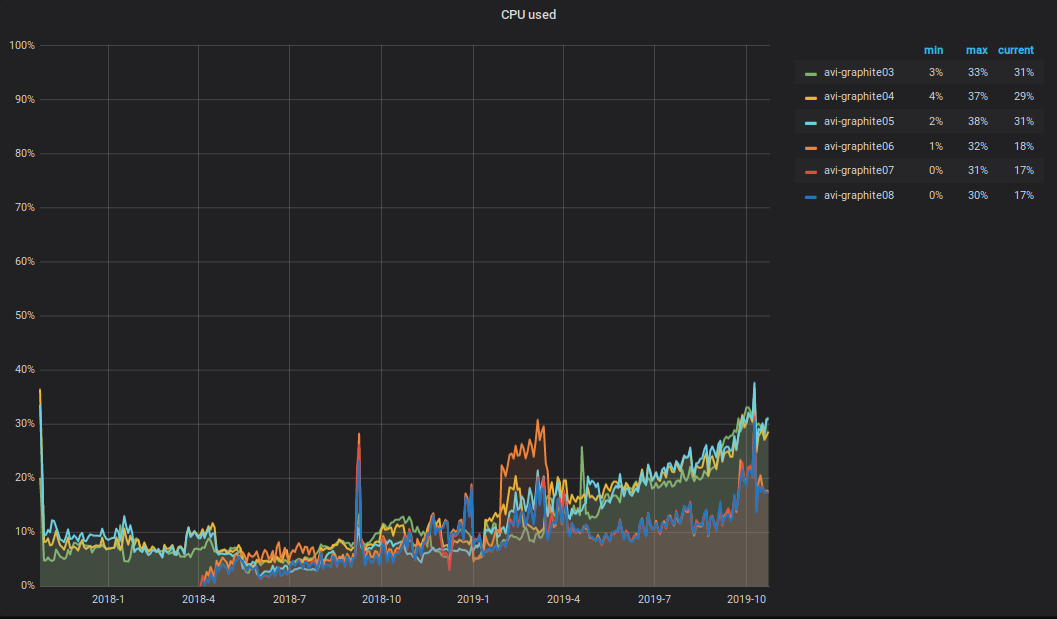
Ich möchte auf die folgende Nuance aufmerksam machen: Die Hälfte der CPU verwendet das Parsen und die primäre Verarbeitung von Metriken in Carbon-C-Relay (Version 3.2 vom 05.09.2018, das für den Transport von Metriken verantwortlich ist), das sich auf drei von sechs Servern befindet. Wie Sie in der Grafik sehen können, befinden sich diese drei Server im TOP.
Alarm
Als Warnsystem haben wir immer noch Moira und den Moira-Client dafür geschrieben. Für die flexible Verwaltung von Triggern, Benachrichtigungen und Eskalationen verwenden wir eine deklarative Beschreibung namens alert.yaml. Es wird automatisch generiert, wenn ein Service über PaaS erstellt wird (mehr dazu im Artikel von Vadim Madison „Was wir über Microservices wissen“ ) und in sein Repository gestellt. Um mit alert.yaml zu arbeiten, haben wir eine Bindung für moira-client erstellt und diese als alert-autoconf bezeichnet (wir planen, sie zu öffnen). Es gibt einen Schritt in der Zusammenstellung des Dienstes in TeamCity mit dem Export von Triggern und Benachrichtigungen an Moira über alert-autoconf. Beim Festschreiben von Änderungen an alert.yaml werden automatische Tests ausgeführt, die die Gültigkeit der yaml-Datei überprüfen und für jede Metrikvorlage Anforderungen an Graphite stellen, um deren Richtigkeit zu überprüfen.
Für Infrastrukturteams, die kein PaaS verwenden, haben wir ein separates Repository namens Alerting organisiert. Es wurde die Struktur des Formulars erstellt: Team / Project / alert.yaml. Für jede alert.yaml generieren wir in TeamCity eine separate Assembly, die Tests ausführt und den Inhalt von alert.yaml in Moira weiterleitet.
Auf diese Weise können alle unsere Mitarbeiter ihre Auslöser, Benachrichtigungen und Eskalationen mit einem einzigen Ansatz verwalten.
Da wir bereits Trigger über die GUI ausgelöst hatten, haben wir die Möglichkeit implementiert, sie im Yaml-Format hochzuladen. Der Inhalt des empfangenen yaml-Dokuments kann praktisch ohne zusätzliche Transformationen in alert.yaml eingefügt und die Änderungen dann an den Assistenten übertragen werden. Während des Builds erkennt alert-autoconf, dass ein solcher Trigger bereits vorhanden ist, und registriert ihn in unserer Registrierung in Redis.
Und vor nicht allzu langer Zeit haben wir eine Schicht von Ingenieuren rund um die Uhr. Um Trigger für den Service an sie zu übertragen, reicht es in Ihrer alert.yaml aus, die Beschreibung "Was tun, wenn Sie sie sehen" korrekt einzugeben, das Tag [24x7] einzufügen und die Änderungen an den Assistenten zu senden. Nach dem Rollen von alert.yaml fallen alle darin beschriebenen Auslöser automatisch rund um die Uhr unter die 24-Stunden-Schichtüberwachung. U - Vereinfachen! Schönheit!
Sammlung von Geschäftsmetriken
Seit dem letzten Artikel über das Sammeln und Verarbeiten von Geschäftsmetriken ist unser Bioyino noch besser geworden.
- Anstatt einen Führer durch den Konsul auszuwählen , wird das eingebaute Floß verwendet .
- Tags werden im Graphitformat korrekt verarbeitet.
- Jetzt können Sie Bioyino (StatsD-Server) als Agent verwenden.
- Zum Zählen eindeutiger Werte wird das Format "set" unterstützt.
- Die endgültige Aggregation von Metriken kann in mehreren Threads erfolgen.
- Daten können in mehreren parallelen Verbindungen an Graphitblöcke gesendet werden.
- Alle gefundenen Fehler behoben.
Jetzt funktioniert es so.
Wir haben begonnen, StatsD-Agenten neben allen großen großen Metrikgeneratoren aktiv einzuführen: in Containern mit Monolith-Instanzen, in k8s-Pods neben Diensten, auf Hosts mit Infrastrukturkomponenten usw.
Der Statsd-Agent befindet sich neben der Anwendung. Es werden Metriken von dieser Anwendung über UDP verwendet, aber das Netzwerksubsystem wird nicht mehr verwendet (aufgrund von Optimierungen im Linux-Kernel). Alle Ereignisse sind voraggregiert und die gesammelten Daten werden jede Sekunde (das Intervall kann konfiguriert werden) im Cap'n Proto-Format an den Hauptcluster von StatsD-Servern (bioyino0 [1-3]) gesendet.
Die weitere Verarbeitung und Aggregation von Metriken, die Auswahl eines Marktführers im StatsD-Cluster und das Senden der Metriken durch den Marktführer an Graphite blieben praktisch unverändert. Sie können dies ausführlich in unserem letzten Artikel lesen.
Die Zahlen lauten wie folgt.
Diagramm der empfangenen StatsD-Ereignisse
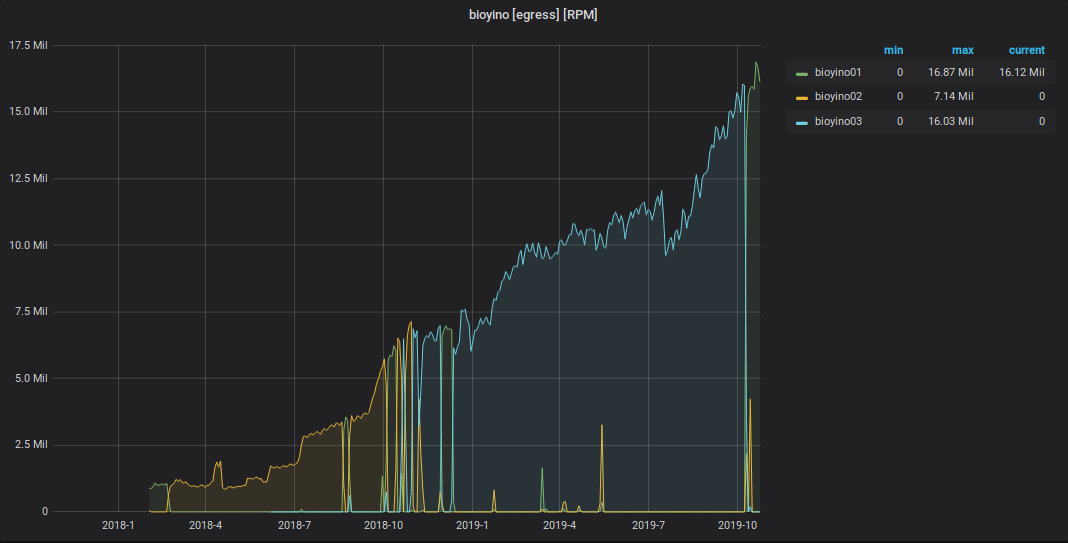

Diagramm der von StatsD an Graphite gesendeten Metriken
Insgesamt
Das derzeitige allgemeine Schema der Interaktion zwischen Überwachungskomponenten sieht folgendermaßen aus.
Gesamtzahl der Metriken: 2 189 484 898 474.
Gesamte Lagertiefe von Metriken: 3 Jahre.
Die Anzahl der eindeutigen Metriknamen: 6 585 413 171.
Anzahl der Trigger: 1053, sie dienen von 1 bis 15.000 Metriken.
Pläne für die nahe Zukunft:
- Verschieben von Produktservices in ein mit Tags versehenes Metrikspeicherschema;
- Fügen Sie dem Graphite-Cluster drei weitere Server hinzu.
- Freunde Moira mit hartnäckigem Gewebe ;
- Finden Sie einen anderen Entwickler im Überwachungsteam.
Ich freue mich über Kommentare und Fragen hier - schreiben Sie. Und ich werde am 7. November auch auf Highload ++ auftreten . Wenn Sie dort sind, können wir uns unterhalten.