Im
letzten Artikel haben wir herausgefunden, dass der Cache sicherlich eine nützliche Sache ist, aber in Bezug auf die Controller-Logik führt dies manchmal zu Schwierigkeiten. Insbesondere führt dies zu einer Unvorhersehbarkeit von Impulsdauern oder anderen Verzögerungen bei der programmatischen Erstellung von Zeitdiagrammen. Nun, und im "allgemeinen programmatischen" Plan kann die schlechte Position der Funktion die Verstärkung aus dem Cache auf nichts reduzieren und ihn ständig dazu veranlassen, aus einem langsamen Speicher neu zu starten. Ich erwähnte, dass wir vor 15 Jahren einen speziellen Präprozessor herstellen mussten, der die für den SPARC-8-Prozessor auftretenden Probleme behebt, und versprach zu erklären, wie einfach es sein würde, solche Schwierigkeiten bei der Entwicklung eines synthetisierten Nios II-Prozessors zu beheben, der für die Verwendung im Redd-Paket empfohlen wird. Es ist an der Zeit, das Versprechen zu erfüllen.

Frühere Artikel in der Reihe:
- Entwicklung der einfachsten „Firmware“ für in Redd installierte FPGAs und Debugging am Beispiel des Speichertests.
- Entwicklung der einfachsten „Firmware“ für in Redd installierte FPGAs. Teil 2. Programmcode.
- Entwicklung eines eigenen Kerns zur Einbettung in ein FPGA-basiertes Prozessorsystem.
- Entwicklung von Programmen für den Zentralprozessor Redd am Beispiel des Zugriffs auf das FPGA.
- Die ersten Experimente am Streaming-Protokoll am Beispiel der Verbindung von CPU und Prozessor im FPGA des Redd-Komplexes.
- Merry Quartusel oder wie der Prozessor zu einem solchen Leben gekommen ist.
- Codeoptimierungsmethoden für Redd. Teil 1: Cache-Effekt.
Unser Nachschlagewerk wird heute das
Embedded Design Handbook bzw. Abschnitt
7.5 sein. Verwenden des eng gekoppelten Speichers mit dem Nios II-Prozessor-Lernprogramm . Der Abschnitt selbst ist bunt. Heute entwerfen wir Prozessorsysteme für Intel FPGAs im Programm Platform Designer. In den Tagen von Altera hieß es QSys (daher die Erweiterung
.qsys der Projektdatei). Bevor QSsys erschien, benutzte jeder seinen Vorfahren, den
SOPC Builder (in dessen Speicher die
Dateierweiterung .sopcinfo verblieben war ). Obwohl das Dokument mit dem Intel-Logo gekennzeichnet ist, handelt es sich bei den darin enthaltenen Bildern um Screenshots dieses SOPC Builder. Es wurde vor mehr als zehn Jahren klar geschrieben, und seitdem wurden nur Begriffe darin korrigiert. Die Texte sind zwar recht modern, daher ist dieses Dokument als Schulungshandbuch sehr nützlich.
Gerätevorbereitung
Also. Wir möchten unserem spartanischen Prozessorsystem Speicher hinzufügen, der niemals zwischengespeichert wird und gleichzeitig mit der höchstmöglichen Geschwindigkeit ausgeführt wird. Dies wird natürlich der interne FPGA-Speicher sein. Wir werden Speicher für Code und Daten hinzufügen, aber dies sind verschiedene Blöcke. Beginnen wir mit dem Datenspeicher als dem einfachsten. Wir
fügen dem System
den bereits bekannten
OnChip-Speicher hinzu .
Nehmen wir an, das Volumen beträgt 2 Kilobyte (das Hauptproblem des internen Speichers des FPGA besteht darin, dass er klein ist, sodass Sie ihn speichern müssen). Der Rest ist gewöhnliche Erinnerung, die wir bereits hinzugefügt haben.

Wir werden es aber nicht an den Datenbus anschließen, sondern an einen speziellen Bus. Um es erscheinen zu lassen, gehen wir in die Prozessoreigenschaften, gehen zur Registerkarte
Caches und Speicherschnittstellen und wählen in der Auswahlliste
Anzahl der eng zusammengewürfelten Datenmaster-Ports den Wert 1 aus.
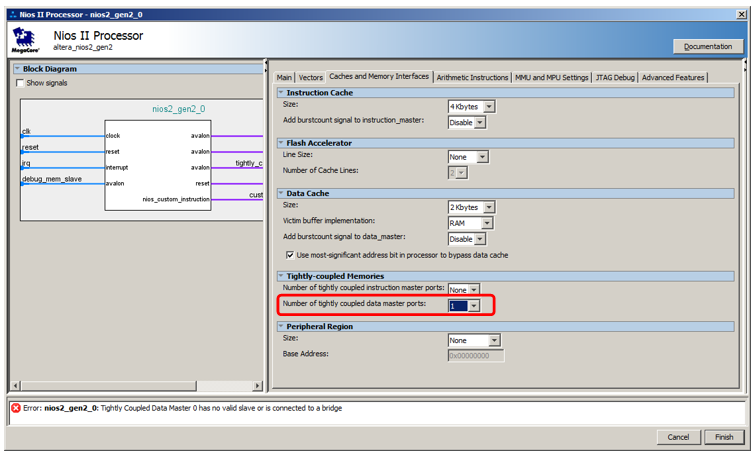
Hier ist ein neuer Port für den Prozessor:

Wir haben kürzlich den neu hinzugefügten Speicherblock damit verbunden!
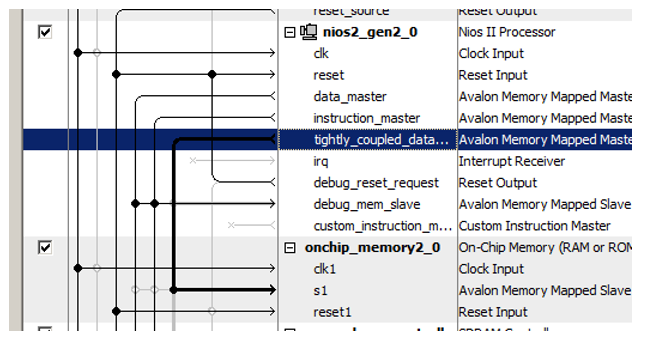
Ein weiterer Trick besteht darin, diesem neuen Speicher Adressen zuzuweisen. Das Dokument enthält eine lange Reihe von Überlegungen zur Optimalität der Adressdecodierung. Es besagt, dass nicht zwischengespeicherter Speicher von allen anderen Speichertypen durch ein klar ausgedrücktes Bit der Adresse unterschieden werden muss. Daher gehört im Dokument der gesamte nicht zwischenspeicherbare Speicher zum Bereich 0x2XXXXXXX. Geben Sie also die Adresse 0x2000000 manuell ein und sperren Sie sie, damit sie sich bei den folgenden automatischen Zuweisungen nicht ändert.
 Benennen
Benennen Sie den Block aus rein ästhetischen
Gründen um ... Nennen wir ihn beispielsweise
NonCachedData .

Mit Hardware für nicht zwischengespeicherten Datenspeicher ist es soweit. Wir übergeben den Speicher zur Codespeicherung. Hier ist fast alles gleich, aber etwas komplizierter. Tatsächlich kann alles vollständig identisch ausgeführt werden, nur der Bus-Master-Port wird in der Liste
Anzahl eng zusammengewürfelter Befehls-Master-Ports geöffnet, es ist jedoch nicht möglich, ein solches System zu debuggen. Wenn das Programm mit dem Debugger gefüllt ist, fließt es dort durch den Datenbus. Beim Anhalten wird der zerlegte Code auch vom Debugger über den Datenbus gelesen. Und selbst wenn das Programm von einem externen Loader geladen wird (wir haben eine solche Methode noch nicht in Betracht gezogen, zumal wir in der kostenlosen Version der Entwicklungsumgebung nur mit dem angeschlossenen JTAG-Debugger arbeiten müssen, aber im Allgemeinen verbietet dies niemand), geht die Füllung auch über den Bus Daten. Daher muss der Speicher Dual-Port ausführen. Schließen Sie an einen Port einen nicht zwischengespeicherten Anweisungsassistenten an, der in der Hauptzeit arbeitet, und an den anderen - einen zusätzlichen Vollzeitdatenbus. Es wird verwendet, um das Programm von außen herunterzuladen und den RAM-Inhalt vom Debugger abzurufen. Der Rest der Zeit wird dieser Reifen im Leerlauf sein. So sieht alles im theoretischen Teil des Dokuments aus:

Beachten Sie, dass das Dokument nicht erklärt, warum, aber es wird angemerkt, dass selbst mit Dual-Port-Speicher nur ein Port mit einem nicht zwischengespeicherten Master verbunden werden kann. Der zweite sollte an das Übliche angeschlossen werden.
Fügen wir 8 Kilobyte Speicher hinzu, machen Sie es zu einem Dual-Port, lassen Sie den Rest standardmäßig:
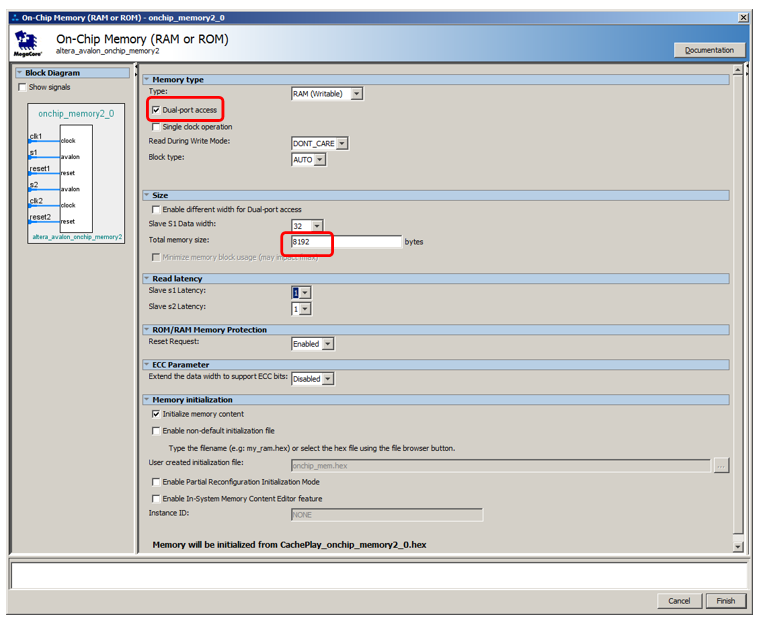
Fügen Sie dem Prozessor einen nicht zwischenspeicherbaren Anweisungsport hinzu:

Wir nennen den Speicher
NonCachedCode , verbinden den Speicher mit den Bussen, weisen ihm die Adresse 0x20010000 zu und sperren ihn (für beide Ports). Insgesamt bekommen wir so etwas:
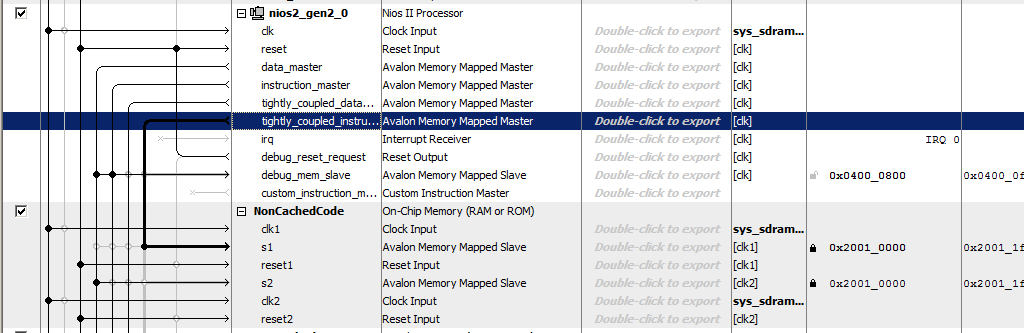
Das ist alles. Wir speichern und generieren das System, sammeln das Projekt. Die Hardware ist bereit. Wir gehen zum Software-Teil über.
Vorbereitung von BSP im Software-Teil
Normalerweise wählen
Sie nach dem Ändern des Prozessorsystems einfach den Menüpunkt
BSP generieren aus , aber heute müssen wir den BSP-Editor öffnen. Da wir dies selten tun, möchte ich Sie daran erinnern, wo sich der entsprechende Menüpunkt befindet:
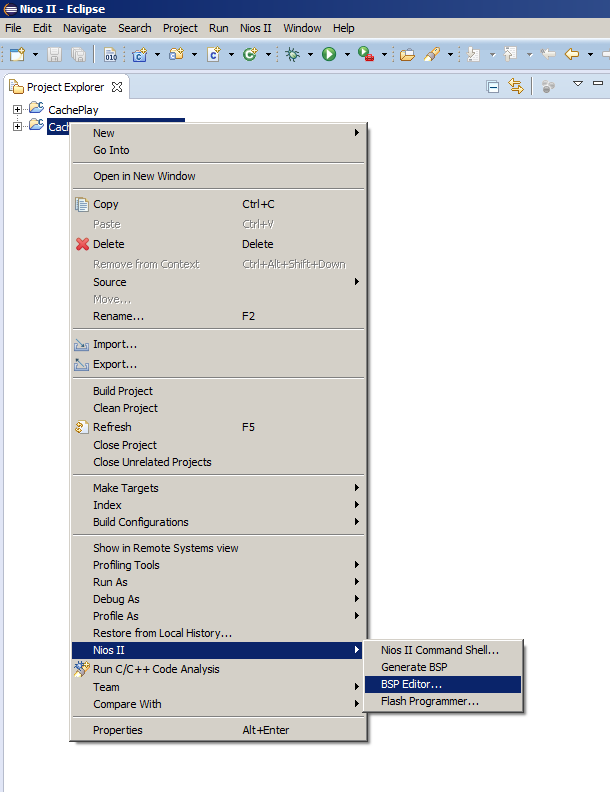
Dort gehen wir zur Registerkarte
Linker Script . Wir sehen, dass wir Regionen hinzugefügt haben, die Namen von RAM-Blöcken erben:
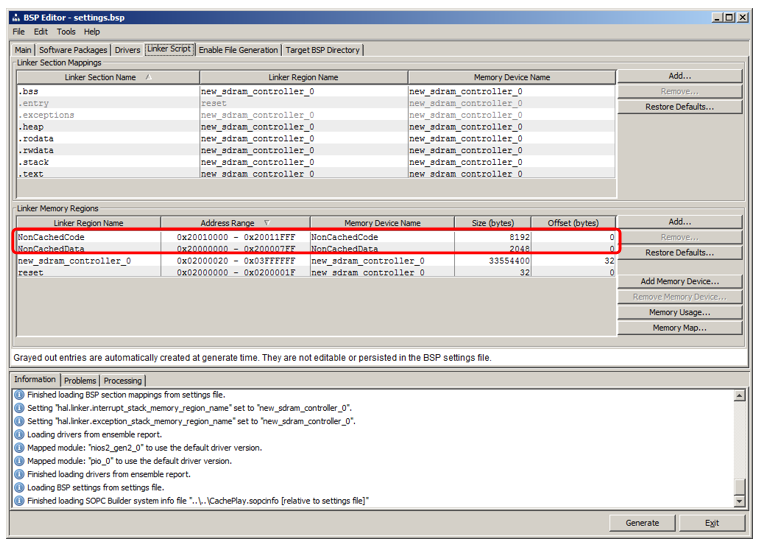
Ich werde zeigen, wie man einen Abschnitt hinzufügt, in dem der Code platziert wird. Klicken Sie im Abschnitt auf Hinzufügen:
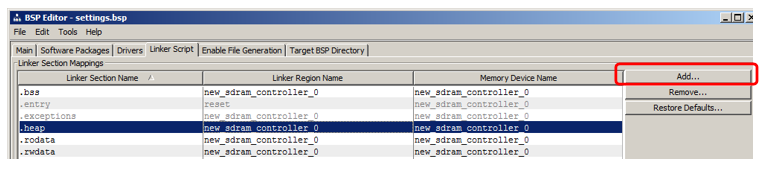
Geben Sie im angezeigten Fenster den Namen des Abschnitts an (um Verwirrung im Artikel zu vermeiden, benenne ich ihn ganz anders als den Namen der Region, nämlich nccode) und ordne ihn der Region zu (ich habe
NonCachedCode aus der Liste ausgewählt):

Das war's, generiere den BSP und schließe den Editor.
Platzieren von Code in einem neuen Speicherbereich
Ich möchte Sie daran erinnern, dass das Programm zwei Funktionen enthält, die vom vorherigen Artikel übernommen wurden:
MagicFunction1 () und
MagicFunction2 () . Beim ersten Durchgang luden beide ihre Körper in den Cache, der auf dem Oszilloskop sichtbar war. Außerdem arbeiteten sie je nach Umgebungssituation entweder mit maximaler Geschwindigkeit oder rieben sich ständig mit ihren Körpern, was zu ständigen Downloads von SDRAM führte.
Verschieben wir die erste Funktion in ein neues nicht zwischengespeichertes Segment, lassen die zweite an Ort und Stelle und führen dann einige Läufe durch.
Fügen Sie das Abschnittsattribut hinzu, um eine Funktion in einem neuen Abschnitt zu platzieren.
Bevor wir die
MagicFunction1 () -Funktion definieren, platzieren
wir ihre Deklaration auch mit diesem Attribut:
void MagicFunction1()__attribute__ ((section("nccode"))); void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); ...
Wir führen den ersten Durchlauf einer Iteration der Schleife durch (ich habe einen Haltepunkt auf die while-Zeile gesetzt):
while (1) { MagicFunction1(); MagicFunction2(); }
Wir sehen folgendes Ergebnis:
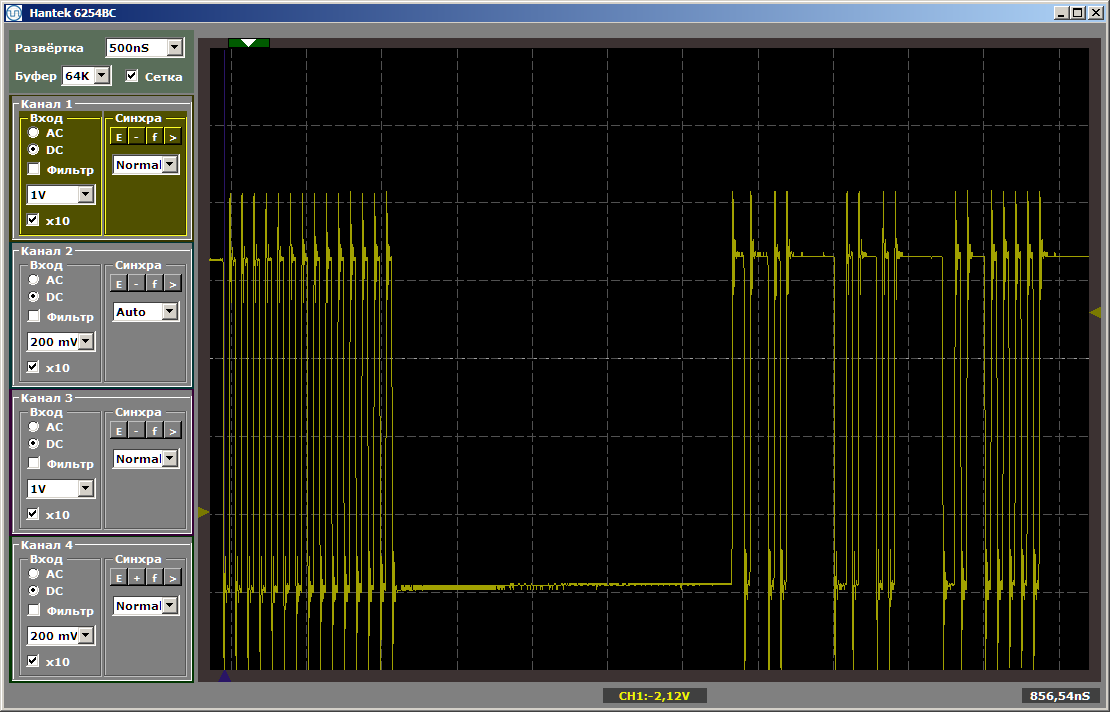
Wie Sie sehen können, wird die erste Funktion wirklich mit maximaler Geschwindigkeit ausgeführt, die zweite wird aus dem SDRAM geladen. Führen Sie den zweiten Lauf aus:
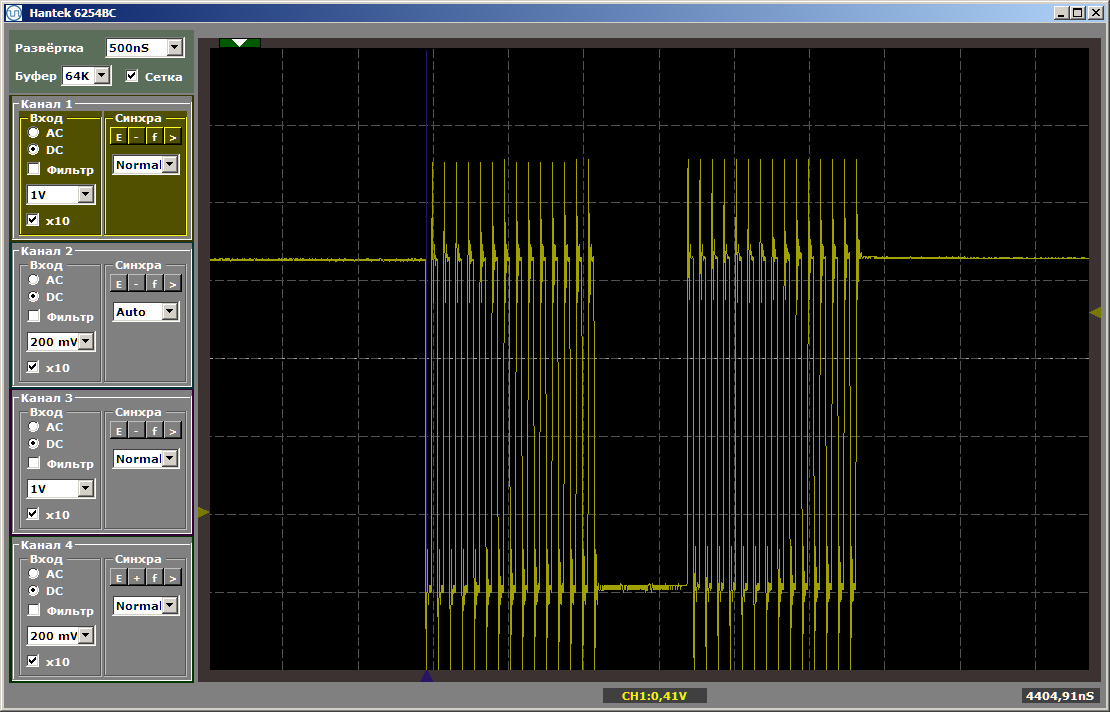
Beide Funktionen arbeiten mit maximaler Geschwindigkeit. Und die erste Funktion entlädt die zweite nicht aus dem Cache, obwohl zwischen ihnen die Einfügung ist, die ich nach dem Schreiben des letzten Artikels hinterlassen habe:
volatile void FuncBetween() { Nops256 Nops256 Nops256 Nops64 Nops64 Nops64 Nops16 Nops16 }
Diese Einfügung wirkt sich nicht mehr auf die relative Position der beiden Funktionen aus, da die erste in einem völlig anderen Speicherbereich verbleibt.
Ein paar Worte zu Daten
In ähnlicher Weise können Sie einen Abschnitt mit nicht zwischengespeicherten Daten erstellen und dort globale Variablen platzieren, indem Sie ihnen dasselbe Attribut zuweisen. Um jedoch Platz zu sparen, werde ich solche Beispiele nicht nennen.
Wir haben eine Region für diesen Speicher erstellt. Die Zuordnung zum Abschnitt kann auf die gleiche Weise wie für den Codeabschnitt erfolgen. Es bleibt nur zu verstehen, wie das entsprechende Attribut einer Variablen zugewiesen wird. Hier ist das erste Beispiel für die Deklaration solcher Daten, die im Darm von automatisch generiertem Code gefunden wurden:
volatile alt_u32 alt_log_boot_on_flag \ __attribute__ ((section (".sdata"))) = ALT_LOG_BOOT_ON_FLAG_SETTING;
Was gibt es uns?
Nun, eigentlich aus offensichtlichen Gründen: Jetzt können wir den Hauptteil des Codes in SDRAM platzieren und im nicht zwischenspeicherbaren Abschnitt jene Funktionen ausgeben, die programmgesteuert Zeitdiagramme bilden oder deren Leistung maximal sein sollte, was bedeutet, dass sie aufgrund von nicht verlangsamt werden sollten dass eine andere Funktion ständig den entsprechenden Code aus dem Cache speichert.
Schauen Sie sich die Reifen genau an.
Schauen Sie sich nun die Reifen im resultierenden Prozessorsystem genau an. Wir haben fast vier davon. Ich kreiste rot um den Hauptbus (was die Vereinigung der beiden ist, weshalb ich „fast“ schrieb: physisch - es gibt zwei Reifen, aber logischerweise - einen). Ich habe den Bus, der zum nicht zwischengespeicherten Befehlsspeicher führt, grün hervorgehoben, blau - zum nicht zwischengespeicherten Datenspeicher.
Diese drei Reifen arbeiten parallel und unabhängig voneinander!
Denken Sie daran, dass ich in dem
Artikel über DMA argumentiert habe, dass einer der leistungsbeschränkenden Faktoren darin besteht, dass die Daten auf demselben Bus übertragen werden. Der DMA-Block liest Daten vom Bus, schreibt Daten darauf, und selbst zur gleichen Zeit verwendet der Prozessorkern denselben Bus. Wie Sie sehen können, wird dieser Nachteil geschlossener Systeme im FPGA vollständig beseitigt. Bei vorgefertigten Steuerungen sind Hersteller beim Verlegen von Verbindungen gezwungen, zwischen Anforderungen und Fähigkeiten zu wechseln. Der Programmierer benötigt diese Option möglicherweise. Und so. Und so. Und so ... Möglicherweise sind viele Dinge erforderlich. Aber Ressourcen kosten Geld und auf dem ausgewählten Kristall ist nicht immer genug Platz für sie. Sie können nicht alles posten. Wir müssen entscheiden, was jeder wirklich braucht und was in Einzelfällen benötigt wird. Und welche Einzelfälle sollten eingeführt und welche vergessen werden. Und dann erscheinen Kompromisslösungen, deren Feinheiten der Programmierer berücksichtigen muss, wenn er sie verwenden möchte. In unserem Fall können wir ohne weiteres handeln. Was wir heute brauchen, ist heute gelegt. Unsere Ressource ist flexibel. Wir geben es aus, damit die Ausrüstung für unsere heutige Aufgabe optimal ist. Für die Aufgaben von morgen und gestern müssen keine Ressourcen reserviert werden. In der heutigen Zeit werden wir jedoch alles so einstellen, dass das Programm so effizient wie möglich funktioniert, ohne dass besondere Programmierfreuden erforderlich sind.
Es war einmal an einer Universität in einem Kurs über Signalprozessoren, wie man zwei Busse parallel zu einem Team einsetzt. Soweit ich weiß, ermöglicht in modernen ARM-Controllern die detaillierte Kenntnis der Busmatrix auch eine Optimierung. Aber das alles ist gut, wenn ein Entwickler seit Jahren mit demselben System arbeitet. Wenn Sie von Projekt zu Projekt völlig unterschiedliche Hardwareteile fahren müssen, können Sie sich nicht alles merken. Bei FPGAs untersuchen wir nicht die Merkmale der Umgebung, sondern können die Umgebung selbst anpassen.
In Bezug auf den Ansatz „Wir verbringen nicht viel Zeit mit Entwicklung“ klingt dies folgendermaßen:
Wir müssen keine Anstrengungen unternehmen, um die Verwendung von vorgefertigten Standardreifen zu optimieren. Wir können sie schnell und optimal für die zu lösende Aufgabe verlegen, diese Hilfsentwicklung schnell abschließen und den Prozess des Debuggens oder Testens des Hauptprojekts schnell sicherstellen.
Schauen wir uns ein Beispiel für die Aufnahme eines DMA-Blocks aus dem
IP-Benutzerhandbuch für
eingebettete Peripheriegeräte an, um das Material zu konsolidieren.
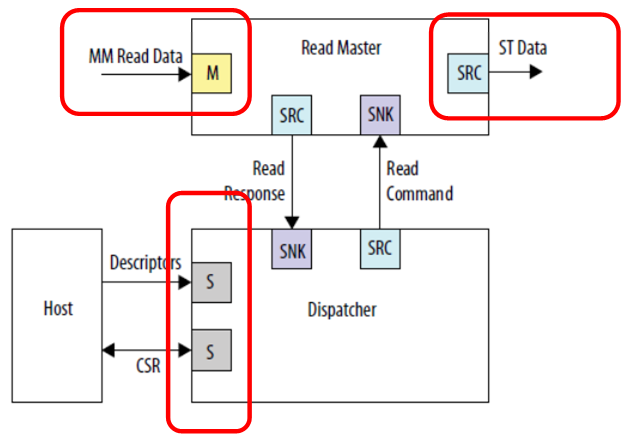
Wir sehen drei unabhängige Verbindungen. Eingabedaten (in dieser Abbildung ist es ein auf den Speicher projizierter Bus), Ausgabedaten (in dieser Abbildung ist es ein völlig anderer Bustyp - eine Stream-Schnittstelle) und die Kommunikation mit dem Steuerprozessor. Niemand stört sich daran, alles an verschiedene Busse anzuschließen, dann wird die Arbeit parallel verlaufen. Eingabedaten (z. B. vom SDRAM) werden in einem Stream gespeichert, den niemand stört. Die Ausgabe erfolgt in einem anderen Stream, beispielsweise an den FT245-FIFO-Kanal, den wir bereits berücksichtigt haben. und der Zentralprozessor frisst nicht von diesen Taktbussen weg, da der Hauptbus isoliert ist. Obwohl in diesem Fall natürlich der Speicher im SDRAM, der sich auf einem separaten Bus befindet, programmgesteuert nicht verfügbar ist. Aber niemand wird verhindern, dass es von DMA gelesen wird. Wenn das Ziel darin besteht, mit dem Puffer eine hohe Leistung zu erzielen, muss dies um jeden Preis erreicht werden. Es sei denn, das gesamte Programm muss in den im FPGA integrierten Speicher passen, da die Redd-Hardware keine anderen Speichereinheiten enthält.
Um Reifen zu parallelisieren, können Sie auch nicht zwischengespeicherte Reifen verwenden, da wir gesehen haben, dass es mehrere geben kann. Slaves, die mit diesen Bussen verbunden sind, unterliegen einer Reihe von Einschränkungen:
- der Sklave ist immer einer im Bus;
- Der Slave verwendet den Busverzögerungsmechanismus nicht.
- Die Schreiblatenz ist immer Null, die Leselatenz ist immer Eins.
Wenn diese Bedingungen erfüllt sind, kann ein solches Slave-Gerät an einen nicht zwischengespeicherten Bus angeschlossen werden. Natürlich wird es höchstwahrscheinlich ein Datenbus sein.
Wenn Sie diese Grundprinzipien kennen, können Sie sie im Allgemeinen durchaus für reale Aufgaben verwenden. Aber im Allgemeinen können Sie. Sie können darauf verzichten, wenn das Ergebnis mit herkömmlichen Mitteln erzielt wird. Aber denken Sie daran. Manchmal ist die Optimierung eines Systems durch diese Mechanismen einfacher als die Feinabstimmung des Programms.
Fazit
Wir haben eine Technik zum Übertragen von Codeabschnitten untersucht, die für die Leistung oder die Vorhersagbarkeit der Verarbeitungsausführung in einem nicht zwischenspeicherbaren Speicher von entscheidender Bedeutung sind. Dabei haben wir die Möglichkeit einer Leistungsoptimierung durch den Einsatz mehrerer parallel und unabhängig voneinander arbeitender Reifen untersucht.
Um das Thema zu beenden, müssen wir noch lernen, wie man die Systemtaktfrequenz erhöht (jetzt ist sie auf die Komponente beschränkt, die Taktimpulse für den SDRAM-Chip erzeugt). Da die Artikel jedoch dem Prinzip „eins - ein Artikel“ folgen, werden wir dies beim nächsten Mal tun.