Hallo allerseits! In diesem Beitrag werde ich Ihnen sagen, welche Ansätze wir in Mail.ru Search verwenden, um Texte zu vergleichen. Wofür ist das? Sobald wir lernen, verschiedene Texte gut miteinander zu vergleichen, kann die Suchmaschine Benutzeranfragen besser verstehen.
Was brauchen wir dafür? Stellen Sie die Aufgabe zunächst genau ein. Sie müssen selbst bestimmen, welche Texte wir als ähnlich betrachten und welche nicht, und dann eine Strategie zur automatischen Bestimmung der Ähnlichkeit formulieren. In unserem Fall werden die Texte von Benutzeranfragen mit den Texten von Dokumenten verglichen.
Die Aufgabe, die Textrelevanz zu bestimmen, besteht aus drei Schritten. Am einfachsten: Suchen Sie in zwei Texten nach passenden Wörtern und ziehen Sie anhand der Ergebnisse Schlussfolgerungen zur Ähnlichkeit. Die nächste, schwierigere Aufgabe besteht darin, nach der Verbindung zwischen verschiedenen Wörtern zu suchen und Synonyme zu verstehen. Und schließlich die dritte Stufe: Analyse des gesamten Satzes / Textes, Isolierung der Bedeutung und Vergleich von Sätzen / Texten nach Bedeutungen.

Eine Möglichkeit, dieses Problem zu lösen, besteht darin, eine Zuordnung vom Textbereich zu einer einfacheren zu finden. Sie können beispielsweise Texte in den Vektorraum übersetzen und Vektoren vergleichen.
Kehren wir zum Anfang zurück und betrachten den einfachsten Ansatz: Finden passender Wörter in Abfragen und Dokumenten. Eine solche Aufgabe an sich ist schon ziemlich kompliziert: Um dies gut zu machen, müssen wir lernen, wie man die normale Form von Wörtern erhält, die an sich nicht trivial ist.
Das direkte Mapping-Modell kann erheblich verbessert werden. Eine Lösung besteht darin, bedingte Synonyme abzugleichen. Beispielsweise können Sie probabilistische Annahmen zur Verteilung von Wörtern in Texten eingeben. Sie können mit Vektordarstellungen arbeiten und die Verbindungen zwischen den nicht übereinstimmenden Wörtern implizit isolieren und dies automatisch tun.
Da wir uns mit der Suche beschäftigen, verfügen wir über viele Daten zum Verhalten von Benutzern beim Empfang bestimmter Dokumente als Antwort auf einige Fragen. Basierend auf diesen Daten können wir Schlussfolgerungen über die Beziehung zwischen verschiedenen Wörtern ziehen.
Nehmen wir zwei Sätze:

Weisen Sie jedem Wortpaar aus der Abfrage und dem Titel eine gewisse Gewichtung zu, was bedeutet, wie stark das erste Wort dem zweiten zugeordnet ist. Wir werden den Klick als sigmoidale Transformation der Summe dieser Gewichte vorhersagen. Das heißt, wir legen die Aufgabe der logistischen Regression fest, bei der die Attribute durch eine Reihe von Paaren des Formulars dargestellt werden (Wort aus der Abfrage, Wort aus dem Titel / Text des Dokuments). Wenn wir ein solches Modell trainieren können, werden wir verstehen, welche Wörter Synonyme sind, genauer gesagt, verbunden werden können und welche höchstwahrscheinlich nicht.
textbfKlickwahrscheinlichkeit= sigma left( sum varphii right) textbf,wobei varphii textbf−GewichteinigerWörter(Abfragewort,Dokumentwort)
Jetzt müssen Sie einen guten Datensatz erstellen. Es stellt sich heraus, dass es ausreicht, den Klickverlauf der Benutzer zu erfassen und negative Beispiele hinzuzufügen. Wie mische ich negative Beispiele ein? Es ist am besten, sie im Verhältnis 1: 1 zum Datensatz hinzuzufügen. Darüber hinaus können die Beispiele selbst in der ersten Phase des Trainings zufällig erstellt werden: Für ein Abfrage-Dokument-Paar finden wir ein anderes zufälliges Dokument, und wir betrachten ein solches Paar als negativ. In den späteren Phasen des Trainings ist es vorteilhaft, komplexere Beispiele anzugeben: solche mit Schnittpunkten sowie zufällige Beispiele, die das Modell als ähnlich betrachtet (hartes negatives Mining).
Beispiel: Synonyme für das Wort "Dreieck".
Zu diesem Zeitpunkt können wir bereits eine gute Funktion unterscheiden, die mit Wörtern übereinstimmt, aber dies ist nicht das, wonach wir streben. Eine solche Funktion ermöglicht es uns, indirekte Wörter abzugleichen, und wir möchten ganze Sätze vergleichen.
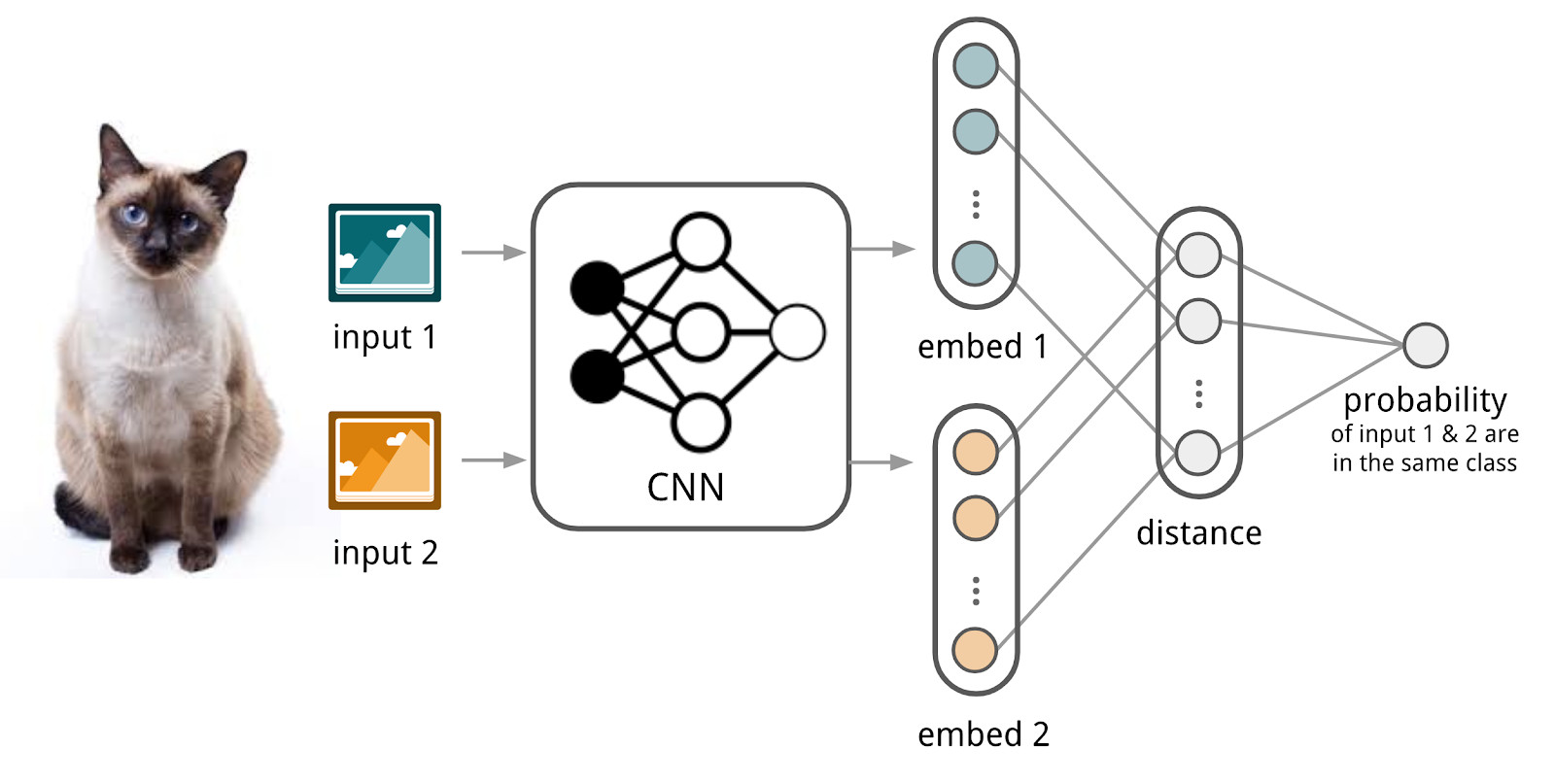
Hier helfen uns neuronale Netze. Lassen Sie uns einen Encoder erstellen, der Text (eine Anforderung oder ein Dokument) akzeptiert und eine Vektordarstellung erzeugt, sodass ähnliche Texte nahe und entfernte Vektoren haben. Beispielsweise können Sie den Kosinusabstand als Maß für die Ähnlichkeit verwenden.
Hier werden wir den Apparat siamesischer Netzwerke verwenden, weil sie viel einfacher zu trainieren sind. Das siamesische Netzwerk besteht aus einem Codierer, der zum Abtasten von Daten aus zwei oder mehr Familien angewendet wird, und einer Vergleichsoperation (z. B. Kosinusabstand). Beim Anwenden des Encoders auf Elemente aus verschiedenen Familien werden die gleichen Gewichte verwendet. Dies allein ergibt eine gute Regularisierung und reduziert die Anzahl der für das Training erforderlichen Faktoren erheblich.
Der Encoder erzeugt Vektordarstellungen aus Texten und lernt, so dass der Kosinus zwischen Darstellungen ähnlicher Texte maximal und zwischen Darstellungen unterschiedlicher Texte minimal ist.
Ein Netzwerk von tiefer semantischer Komplexität DSSM ist für unsere Aufgabe geeignet. Wir verwenden es mit geringfügigen Änderungen, die ich unten diskutieren werde.
So funktioniert das klassische DSSM: Abfragen und Dokumente werden in Form eines Trigrammbeutels dargestellt, aus dem eine Standardvektordarstellung erhalten wird. Es wird durch mehrere vollständig verbundene Schichten geleitet, und das Netzwerk wird so trainiert, dass die bedingte Wahrscheinlichkeit des Dokuments auf Anfrage maximiert wird, was der Maximierung des Kosinusabstands zwischen den Vektordarstellungen entspricht, die durch einen vollständigen Durchgang durch das Netzwerk erhalten werden.
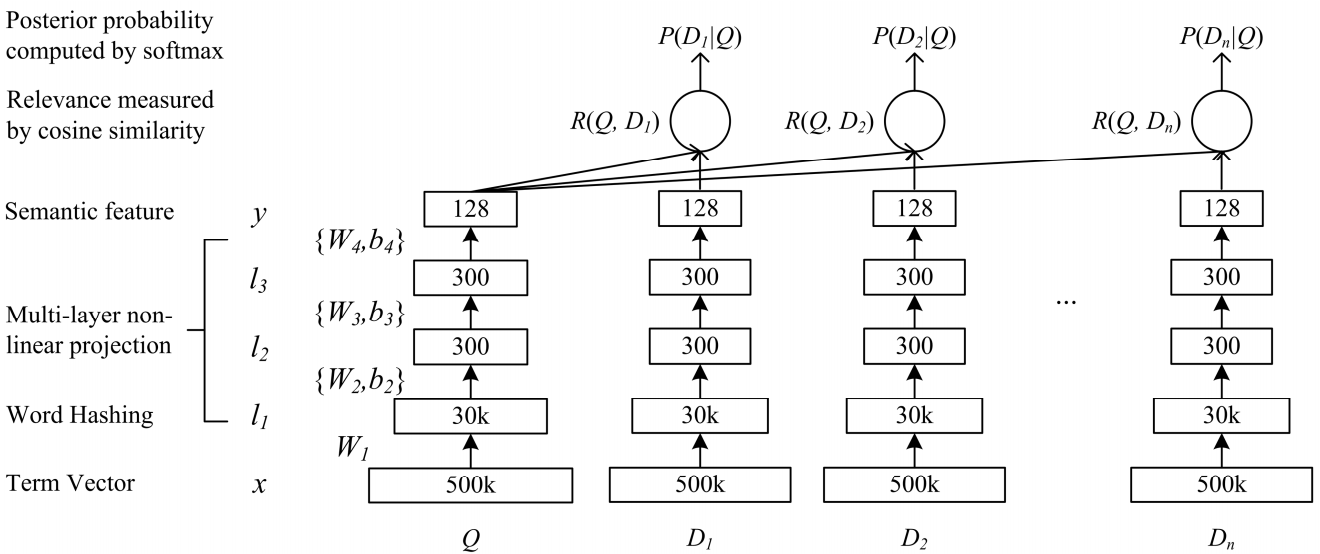 Po-Sen Huang Xiaodong Er Jianfeng Gao Li Deng Alex Acero Larry Heck. 2013 Lernen tief strukturierter semantischer Modelle für die Websuche mithilfe von Klickdaten
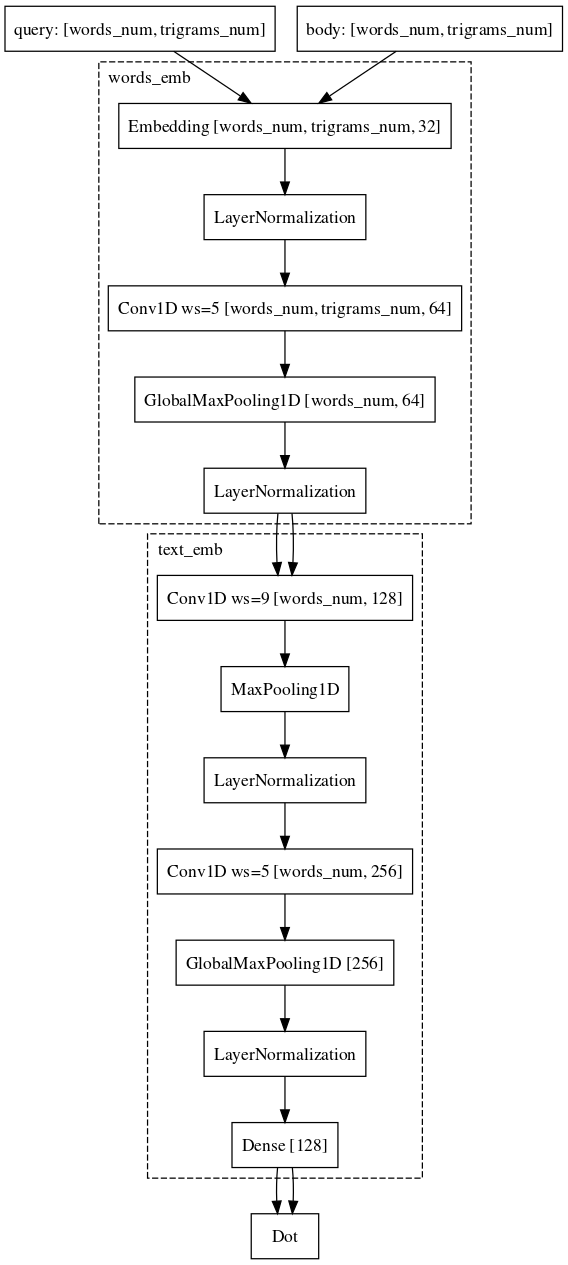
Po-Sen Huang Xiaodong Er Jianfeng Gao Li Deng Alex Acero Larry Heck. 2013 Lernen tief strukturierter semantischer Modelle für die Websuche mithilfe von KlickdatenWir sind fast den gleichen Weg gegangen. Jedes Wort in der Abfrage wird nämlich als Trigrammvektor und der Text als Wortvektor dargestellt, wodurch Informationen darüber verbleiben, welches Wort stand. Als nächstes verwenden wir eindimensionale Faltungen innerhalb der Wörter, um deren Darstellung zu glätten, und die Operation des globalen maximalen Ziehens, um Informationen über den Satz in einer einfachen Vektordarstellung zu aggregieren.

Der Datensatz, den wir für das Training verwendet haben, stimmt im Wesentlichen vollständig mit dem für das lineare Modell verwendeten überein.
Wir haben hier nicht aufgehört. Erstens haben sie einen Pre-Training-Modus entwickelt. Wir nehmen eine Liste von Abfragen für das Dokument, geben ein, welche Benutzer mit diesem Dokument interagieren, und trainieren das neuronale Netzwerk, um solche Paare eng einzubetten. Da diese Paare aus derselben Familie stammen, ist ein solches Netzwerk leichter zu erlernen. Außerdem ist es einfacher, Kampfbeispiele neu zu trainieren, wenn wir Anfragen und Dokumente vergleichen.
Beispiel: Benutzer gehen zu e.mail.ru/login mit Anfragen: E-Mail, E-Mail-Eingabe, E-Mail-Adresse, ...Schließlich ist der letzte schwierige Teil, mit dem wir immer noch zu kämpfen haben und in dem wir fast Erfolg haben, die Aufgabe, die Anfrage mit einem langen Dokument zu vergleichen. Warum ist diese Aufgabe schwieriger? Hier ist die Maschinerie siamesischer Netzwerke bereits schlechter geeignet, da die Anfrage und das lange Dokument zu verschiedenen Objektfamilien gehören. Trotzdem können wir es uns leisten, die Architektur kaum zu verändern. Es ist nur erforderlich, Windungen auch entsprechend den Wörtern hinzuzufügen, wodurch mehr Informationen über den Kontext jedes Wortes für die endgültige Vektordarstellung des Textes gespeichert werden.
Derzeit verbessern wir die Qualität unserer Modelle weiter, indem wir Architekturen modifizieren und mit Datenquellen und Stichprobenmechanismen experimentieren.