Inhalt
Manchmal finden uns selbst Käfer. Also haben wir eine große Datenreihe verschoben - und das System hing. Liegt es an 1 Million Charakteren, die gefallen sind? Oder mochte sie keinen bestimmten?
Oder die Datei wurde auf das System hochgeladen und stürzte ab. Von was? Aufgrund von Name, Erweiterung, Daten oder Größen? Sie können die Lokalisierung auf den Entwickler übertragen und ihn überlegen lassen, was in der Datei schlecht ist. Aber oft können Sie den Grund selbst finden und das Problem dann genauer beschreiben.
Wenn Sie die Mindestdaten für die Wiedergabe finden, dann:
- Sie sparen Zeit für den Entwickler - er muss keine Verbindung zum Prüfstand herstellen, die Datei selbst laden und debütieren
- Der Manager kann die Priorität der Aufgabe leicht beurteilen. Muss sie dringend behoben werden, oder kann der Fehler warten? Während der Name "einige Dateien fallen, xs warum" ist schwer zu tun ...
- Eine Beschreibung des Fehlers aus dem Verständnis der Ursache des Sturzes wird ebenfalls von Vorteil sein.
Wie finde ich die Mindestdaten für das Abspielen eines Fehlers? Wenn die Protokolle Hinweise enthalten, wenden Sie diese an. Wenn es keine Hinweise gibt, ist die beste Methode die Methode der halbierten Teilung (auch als Methode der „Halbierung“ oder „Dichotomie“ bekannt).
Methodenbeschreibung
Die Methode wird verwendet, um den genauen Ort des Sturzes zu finden:
- Nehmen Sie ein fallendes Datenpaket.
- In zwei Hälften brechen.
- Überprüfen Sie die Hälfte 1
- Wenn es gefallen ist, dann ist das Problem da. Wir arbeiten weiter mit ihr.
- Wenn es nicht fällt → Hälfte 2 prüfen.
- Wiederholen Sie die Schritte 1 bis 3, bis ein fallender Wert erhalten bleibt.

Mit dieser Methode können Sie das Problem schnell lokalisieren, insbesondere wenn es programmgesteuert ausgeführt wird. Entwickler integrieren solche Mechanismen in die Datenverarbeitung. Und wenn sie es nicht einbauen, leiden sie später selbst, wenn der Tester zu ihnen kommt und sagt: "Es fällt auf diese Datei, aber ich konnte den genauen Grund nicht finden."
Anwendung durch Tester
Datenzeile
Eine Zeile mit 1 Million Daten geladen - das System friert ein.
Wir versuchen 500 Tausend (in zwei Hälften geteilt) - es hängt immer noch.
Wir versuchen 250 Tausend - es hängt nicht, alles ist in Ordnung.
↓
Daher die Schlussfolgerung, dass das Problem irgendwo zwischen 250 und 500.000 liegt. Wieder wenden wir die Bisektionsteilung an.
Wir versuchen es mit 350.000 (Teilen durch "Auge" - es ist durchaus zulässig, dass Sie beim manuellen Spielen nicht auf exakte Zahlen stoßen müssen) - alles ist in Ordnung
Wir versuchen 450.000 - es ist schlecht.
Wir versuchen 400 Tausend - es ist schlecht.
↓
Im Allgemeinen können Sie bereits einen Fehler bekommen. Es ist sehr selten erforderlich, dass der Tester meldet, dass die Grenze oder der Fehler eindeutig die Nummer 286 586 hat. Es reicht völlig aus, sie ungefähr zu lokalisieren - 290 Tausend.
Es ist nur eine Sache, "10" und sofort "300.000" zu überprüfen, und es ist völlig anders, vollständigere Informationen bereitzustellen: "Bis zu 10.000 ist alles in Ordnung, von 10 bis 280.000 Bremsen starten, es fällt bereits auf 290.000".
Es ist klar, dass die manuelle Suche nach einem bestimmten Gesicht zu lange dauert, wenn die Menge in Tausend gemessen wird. Ja, der Entwickler braucht das nicht. Nun, niemand will vergeblich Zeit verschwenden.
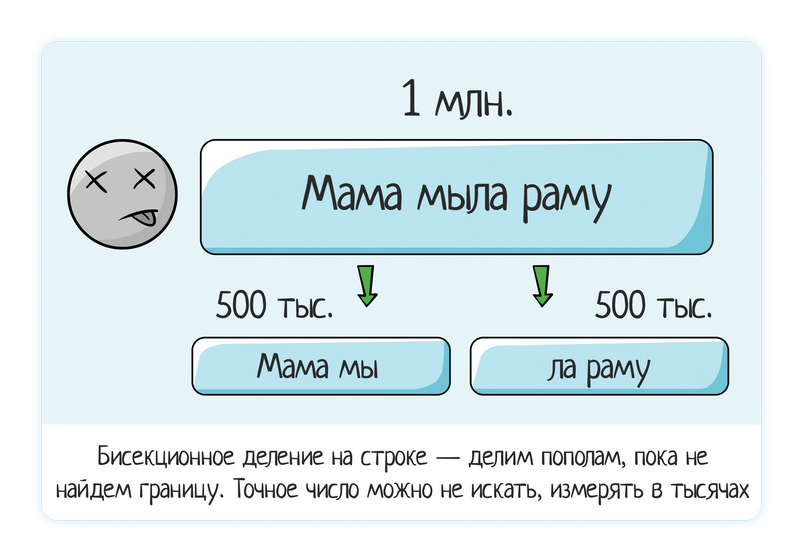
Wenn sich das ursprüngliche Problem in einer Zeile mit einer Länge von 10 bis 30 Zeichen befand, können Sie natürlich den genauen Rand finden. Es ist alles eine Frage eines vernünftigen Verhältnisses zur Zeit - wenn Sie Vermutungen oder halbierte Teilungen verwenden, können Sie schnell den genauen Wert finden und er ist klein (normalerweise bis zu 100) - wir suchen sicher. Wenn die Probleme in einer großen Zeile liegen, suchen mehr als 1000 → nach ungefähr.
Datei
Datei hochgeladen - abgestürzt! Wie, warum? Zunächst versuchen wir selbst zu analysieren, was sich auf das auswirken könnte, was unser Test getestet hat. Dies ist der Hauptregelchip "zuerst positiv, dann negativ". Wenn Sie nicht versuchen, alles auf einmal in einen Test zu packen:
- Überprüfte eine kleine Beispieldatei
- Wir haben eine riesige 2-GB-Datei mit einer Reihe von Spalten, einer Reihe von Spalten und verschiedenen Variationen der internen Daten überprüft
Es wird schwierig sein, hier zu lokalisieren. Und wenn Sie die Schecks trennen:
- Viele Zeilen (aber die Daten sind positiv und wurden früher überprüft)
- Viele Spalten
- Schweres Gewicht
- ...
Das ist schon ungefähr verständlich, was ist der Grund. Zum Beispiel fällt es auf eine große Anzahl von Zeilen - von 100.000. Ok, wir suchen nach einer genaueren Grenze unter Verwendung der halbierten Teilung:
- Wir haben die Datei durch 50.000 in zwei geteilt und die erste überprüft.
- Wenn Sie fallen, teilen Sie es
- Und so, bis wir einen bestimmten Ort zum Fallen finden
Wenn der Abfall von der Anzahl der Zeilen abhängt, suchen wir nach einer ungefähren Grenze: "Nach 5000 fallen keine 4000.000 mehr." Die Suche nach einem bestimmten Ort (4589) ist nicht erforderlich. Zu lang und die Zeit nicht wert.
Dieser Fehler wurde von Studenten in Dadat gefunden . Dort können Datendateien geladen werden, das System verarbeitet und standardisiert diese Daten: Tippfehler korrigieren, fehlende Informationen aus Verzeichnissen ermitteln (KLADR-Code, FIAS, Geokoordinaten, Stadtteil, Postleitzahl ...).
Das Mädchen hat versucht, eine große Datei herunterzuladen und hat das Ergebnis erhalten: Das System zeigt einen Fortschrittsbalken bei 100% Auslastung an und bleibt länger als 30 Minuten hängen.
Die Lokalisierung ging weiter - wann beginnt das Einfrieren? Dies ist wichtig, da dies die Priorität der Aufgabe beeinflusst. Was ist die typische Downloadgröße? Wie oft versenden Benutzer gerade LOTS?
Vielleicht ist das System so konzipiert, dass es Tausende von Zeilen verarbeitet, und dann wird ein solcher Fehler in „Fix it eines Tages“ eingepfercht. Oder typische Downloads - 10-50.000 Zeilen, die normal verarbeitet werden. Das bedeutet, dass der Fehler nicht brennt. Wir werden ihn etwas später beheben.
Aufgabenlokalisierung:
- für eine Datei mit 50.000 Zeilen hängen 15 Sekunden,
- für eine Datei mit 100.000 Zeilen hängen 30 Sekunden,
- für eine Datei mit 150 Tausend Zeilen hängt 1 min,
- für eine Datei mit 165 Tausend Zeilen hängt 4 Minuten,
- Für eine Datei frieren 172.000 Zeilen mit einem 100% vollständigen Fortschrittsbalken länger als eine halbe Stunde ein
Hier wird die Arbeit des Testers bereits qualitativ erledigt. Es werden vollständige Informationen über den Betrieb des Systems bereitgestellt, auf deren Grundlage der Manager bereits feststellen kann, wie dringend es erforderlich ist, den Fehler zu beheben.
Die Überprüfung dauert auch nicht zu lange. Sie können gehen oder von Ende - hier haben wir 200.000 Zeilen heruntergeladen, und wann beginnt das Problem? Wir verwenden die Methode der halbierten Teilung!
Oder beginnen Sie mit einer relativ kleinen Zahl - 50.000, die allmählich zunimmt (um die Hälfte der Methode der halbierten Teilung, genau umgekehrt). Da wir wissen, dass bei 200.000 alles schlecht sein wird, verstehen wir, dass es nicht viele Tests geben wird. Wir haben 50, 100, 150 überprüft - für drei Tests haben wir eine ungefähre Grenze gefunden. Und dann ist das Graben nicht mehr nötig.
Aber denken Sie daran, dass Sie auch Ihre Theorie testen müssen. Stimmt es, dass das Problem in der Anzahl der Zeilen und nicht in den Daten in der Datei liegt? Dies zu überprüfen ist sehr einfach - erstellen Sie eine 5000-Zeilen-Datei mit einem einzigen „positiven“ Wert. Der Wert, der genau funktioniert und den Sie bereits zuvor überprüft haben. Wenn es keinen Fall gibt, ist die Angelegenheit unrein =)) Es scheint, dass die Theorie der Anzahl der Zeilen falsch war und die Angelegenheit in den Daten selbst enthalten ist.
Sie können zwar 10 Tausend Zeilen mit genau einem positiven Wert ausprobieren. Es ist möglich, dass der Sturz erneut eintreten wird. Nur Ihre Quelldatei befand sich in mehreren Spalten. Oder es gab Zeichen, die mehr Bytes als einen positiven Wert einnahmen ... Lehnen Sie die Theorie der Dateigröße oder der Anzahl der Zeilen im Allgemeinen nicht sofort ab. Versuchen Sie im Gegenteil die halbierte Teilung - verdoppeln Sie die Datei.
Denken Sie jedoch auf jeden Fall daran, dass es umso schwieriger ist, den Fehler zu lokalisieren, je mehr Prüfungen in einer gemischt werden. Daher ist es besser, die Anzahl der Zeilen oder Spalten sofort auf einem einzelnen positiven Wert zu testen. Damit Sie sicher sind, dass Sie die Datenmenge testen, nicht die Daten selbst. Testanalyse und all das =)
Was aber, wenn das Problem nicht in der Anzahl der Zeilen liegt, sondern in den Daten selbst? Und Sie wissen nicht genau wo. Vielleicht haben Sie Daten aus „Krieg und Frieden“ in eine Testdatei gepackt oder eine große Tabelle von irgendwo im Internet heruntergeladen ... Oder der Benutzer hat überhaupt ein Problem gefunden - er hat seine Datei hochgeladen und alles ist heruntergefallen. Er kam zur Unterstützung, Unterstützung kam zu Ihnen: Die Datei liegt bei Ihnen, spielen Sie sie ab.
Weitere Maßnahmen hängen von der Situation ab. Wenn die Fristen des Benutzers abgelaufen sind oder Geld von ihm abgebucht wird und die Dateiverarbeitung dann gesunken ist, ist dies ein Blocker-Fehler. Und es ist keine Zeit, einen Lokalisierungstester zu schulen. Es ist einfacher, dem Entwickler die genau fallende Datei zu geben, ihn frei zu lassen und den Grund selbst zu finden.
Aber wenn Sie selbst einen Fehler gefunden haben, ist es Zeit, ihn selbst zu graben. Auch hier ist der gesunde Menschenverstand nicht zu vergessen, wie immer bei der Lokalisierung. Zuerst haben wir versucht, selbst Schlussfolgerungen zu ziehen, dann haben wir uns um Hilfe bemüht. Um selbst eine Schlussfolgerung zu ziehen, benötigen Sie:
- Überprüfen Sie die Protokolle, möglicherweise gibt es die richtige Antwort.
- Anzeigen des Inhalts der Datei: Möglicherweise fällt Ihnen etwas auf. Dies ist die erste Theorie.
- Verwenden Sie die Methode der halbierten Teilung.
Infolgedessen haben Sie anstelle des Fehlers "Falls-Datei, warum xs, hier ist ein 2-GB-Dateianhang" einen gut durchdachten und lokalisierten Fehler angezeigt: "Die Datei fällt, wenn das Datum des TT / MM / JJJJJ-Formats innerhalb liegt". Und dann brauchen Sie noch keine 2-GB-Datei, sondern nur eine Datei für eine Zeile und eine Spalte!

Anwendung durch Entwickler
Bei einer großen Datenmenge sucht der Tester nicht nach einer klaren Grenze, da dies nicht zumutbar ist. Entwickler verwenden jedoch die Methode der halbierten Teilung im Code und können immer einen bestimmten Ort finden, an dem sie fallen können. Schließlich wird sich das System bis zum Sieg teilen und nicht eine Person!
Zum Beispiel haben wir einen Mechanismus zum Laden von Daten in das System. Es kann als 10 Tausend und eine Million laden. Dies spielt jedoch keine Rolle, da der Download in Stapeln von 200 Einträgen erfolgt. Wenn etwas schief gelaufen ist, führt das System selbst eine halbierte Teilung durch. Selbst. Bis es einen Problemort findet. Dann lesen Sie in den Protokollen:
- Ich habe 1000 Einträge
- 200 Datensätze verarbeitet
- Verarbeitete 400 Datensätze
- Ups, fiel auf eine Packung mit 200 Platten!
- Ich versuche eine Packung der Größe 100 zu verarbeiten
- Ich versuche eine Packung der Größe 50 zu verarbeiten
- Ich versuche eine Packung der Größe 25 zu verarbeiten
...
- Fehler bei solchen Kennungen: Das erforderliche E-Mail-Feld ist nicht ausgefüllt
- 600 Datensätze verarbeitet
...
Hier hängt natürlich auch die weitere Logik vom Entwickler ab. Entweder stoppt die Verarbeitung nach Auftreten eines Fehlers oder geht weiter. Auf eine Packung mit 200 Einträgen gestolpert? Wir fanden einen Engpass, markierten den Eintrag als fehlerhaft, verarbeiteten die restlichen 199 und fuhren weiter.
Aber was ist, wenn das ganze Rudel auseinander fällt? Wir haben den Datensatz als fehlerhaft markiert, aber die restlichen 199 konnten ebenfalls nicht verarbeitet werden. Warum? Wir wenden dieselbe Methode an und suchen nach einem neuen Problem. Der Trick ist, dass Sie immer pünktlich anhalten müssen.
Wenn die Anzahl der Fehler mehr als 10-50-100 beträgt, ist es besser, den Download zu stoppen. Es ist möglich, dass im ursprünglichen System ein Upload-Fehler aufgetreten ist und wir eine Million „Kurven“ von Daten erhalten haben. Wenn das System jede Packung mit 200 Datensätzen in zwei Hälften teilt und dann die verbleibenden 199 Datensätze usw. aufteilt, ist dies für alle schlecht:
- Das Protokoll wächst von den üblichen 15 MB auf 3 GB und wird unlesbar.
- Das System stürzt möglicherweise ab, wenn versucht wird, eine endgültige Fehlermeldung zu generieren (ich habe im Abschnitt BMW Mnemonics über diese Situation gesprochen).
- Es wird viel Zeit darauf verwendet, nach allen Fehlern zu suchen. Ja, das System erledigt dies schneller als eine Person, aber wenn Sie eine Million Packungen mit 200 Datensätzen teilen, wird es einige Zeit dauern.
Das Gehirn muss also überall einbezogen werden - sowohl beim manuellen Testen als auch beim Schreiben von Programmcode. Sie müssen immer verstehen, wann Sie aufhören müssen. Nur bei manuellen Tests wird es „im Begriff sein, die Grenze zu finden“ und in der Entwicklung „aufhören, wenn es viele Stürze gibt“.
Zusammenfassung
Die Methode der halbierten Teilung wird verwendet, um nach dem genauen Ort des Sturzes und der Lokalisierung des Fehlers zu suchen.
Suchen Sie nach der Zahl und teilen Sie sie in zwei Hälften:
- Zeilenlänge;
- Dateigröße
- Dateigewicht;
- Anzahl der Zeilen / Spalten;
- Menge an freiem Speicher in einem Mobiltelefon;
- ...
Aber denk dran - eines Tages musst du aufhören! Sie müssen nicht anhalten und nach der genauen Nummer suchen, wenn Tausende zusätzlicher Tests erforderlich sind. Die Lokalisierung kann jedoch 5-10 Minuten dauern.
PS - Suche nach nützlicheren Artikeln in meinem Blog unter dem Tag "nützlich"