Hallo! Mein Name ist Antonina, ich bin ein Oracle-Entwickler der IT-Abteilung von Sportmaster Lab. Ich arbeite hier erst seit zwei Jahren, aber dank eines freundlichen Teams, eines engmaschigen Teams, eines Mentorensystems und einer Unternehmensschulung hat sich die kritische Masse angesammelt, wenn ich nicht nur Wissen konsumieren, sondern auch meine Erfahrungen teilen möchte.

Also, Edition-basierte Neudefinition. Warum mussten wir diese Technologie überhaupt studieren, und hier hilft uns der Begriff "Hochverfügbarkeit" und wie die auf Edition basierende Neudefinition als Oracle-Entwickler Zeit spart?
Was wird von Oracle als Lösung vorgeschlagen? Was ist im Hinterhof los, wenn diese Technologie angewendet wird, auf welche Probleme wir gestoßen sind ... Im Allgemeinen gibt es viele Fragen. Ich werde versuchen, sie in zwei Beiträgen zum Thema zu beantworten, und der erste ist bereits unter dem Schnitt.
Jedes Entwicklerteam, das seine eigene Anwendung erstellt, ist bestrebt, den kostengünstigsten, fehlertolerantesten und zuverlässigsten Algorithmus zu entwickeln. Warum streben wir alle danach? Wahrscheinlich nicht, weil wir so gut sind und ein cooles Produkt veröffentlichen wollen. Genauer gesagt, nicht nur, weil wir so gut sind. Es ist auch wichtig für das Geschäft. Trotz der Tatsache, dass wir einen coolen Algorithmus schreiben, ihn mit Komponententests abdecken und feststellen können, dass er fehlertolerant ist, haben wir (die Oracle-Entwickler) immer noch ein Problem - wir stehen vor der Notwendigkeit, unsere Anwendungen zu aktualisieren. Zum Beispiel sind unsere Kollegen im Loyalitätssystem gezwungen, dies nachts zu tun.
In diesem Fall würden die Benutzer ein Bild sehen: "Bitte entschuldigen Sie!", "Seien Sie nicht traurig!", "Warten Sie, wir haben hier Updates und technische Arbeiten." Warum ist das so wichtig für das Geschäft? Aber es ist sehr einfach: Seit langem hat das Geschäft nicht nur Verluste einiger realer Güter, materieller Werte, sondern auch Verluste durch Ausfallzeiten der Infrastruktur verursacht. Laut dem Forbes-Magazin kostete beispielsweise eine Minute Amazon-Dienstausfall im Jahr 13 66.000 Dollar. Das heißt, in einer halben Stunde haben die Jungs fast 2 Millionen Dollar verloren.
Es ist klar, dass diese quantitativen Merkmale für mittlere und kleine Unternehmen und nicht für einen Riesen wie Amazon viel geringer sein werden, aber relativ gesehen bleibt dies dennoch ein wichtiges Bewertungsmerkmal.
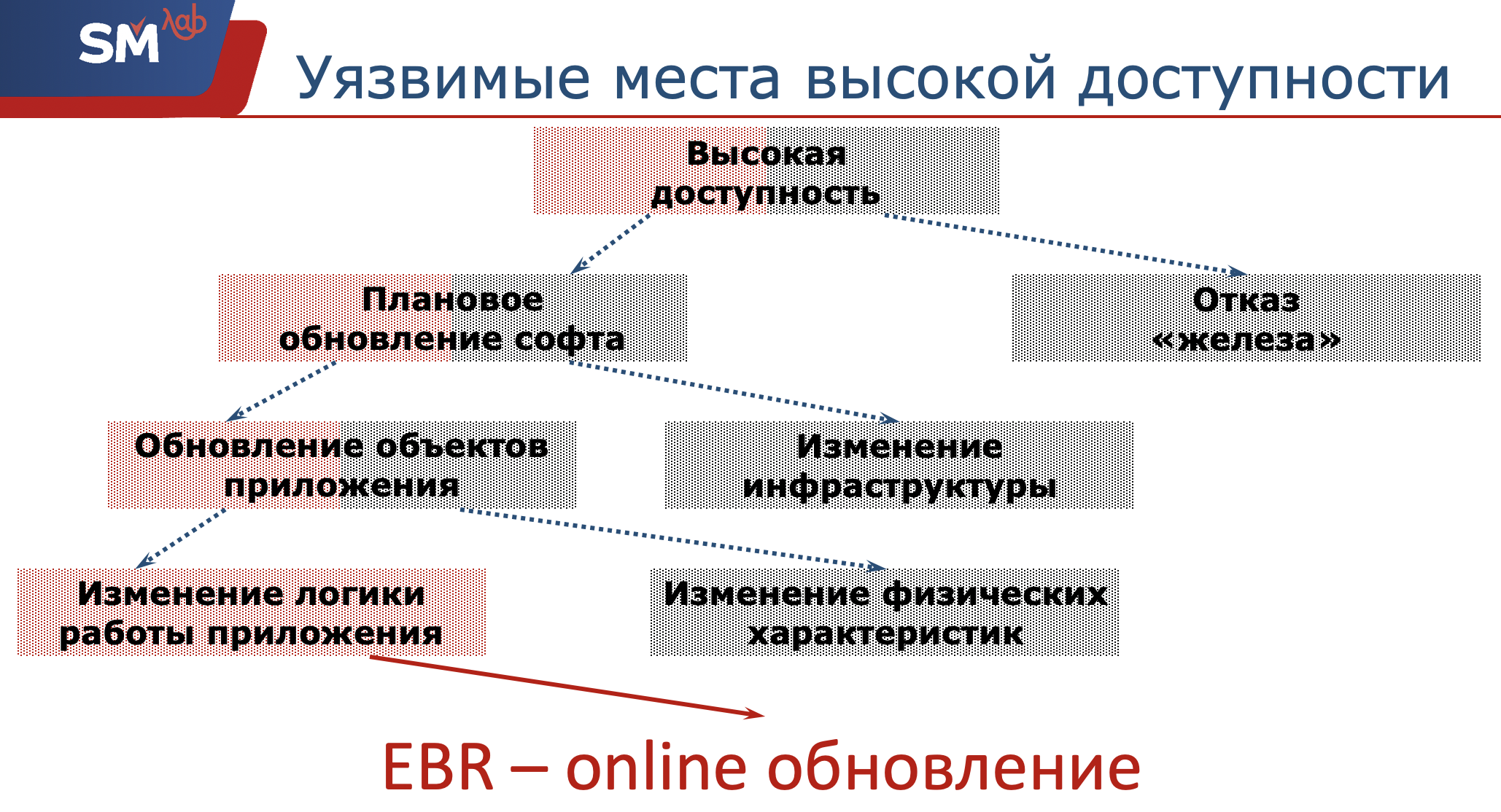
Daher müssen wir die hohe Verfügbarkeit unserer Anwendung sicherstellen. Welche potenziell gefährlichen Stellen haben Oracle-Entwickler für diese Barrierefreiheit?
Das Wichtigste zuerst: Unsere Hardware kann ausfallen. Wir als Entwickler sind dafür nicht verantwortlich. Netzwerkadministratoren müssen sicherstellen, dass der Server und die Strukturobjekte betriebsbereit sind. Was wir führen, ist ein Software-Upgrade. Auch hier können geplante Softwareupdates in zwei Klassen unterteilt werden. Oder wir ändern eine Art Infrastruktur, indem wir beispielsweise das Betriebssystem aktualisieren, auf dem sich der Server dreht. Entweder haben wir uns für die Umstellung auf die neue Version von Oracle entschieden (es wäre schön, wenn wir erfolgreich darauf umsteigen würden :)) ... Oder für die zweite Klasse haben wir die maximale Beziehung - dies aktualisiert die Anwendungsobjekte, die wir mit Ihnen entwickeln.
Auch dieses Update kann in zwei weitere Klassen unterteilt werden.
Oder wir ändern einige physikalische Eigenschaften dieses Objekts (ich denke, dass jeder Oracle-Entwickler manchmal auf die Tatsache gestoßen ist, dass sein Index gefallen ist und er den Index im laufenden Betrieb neu erstellen musste). Oder nehmen wir an, wir haben neue Abschnitte in unsere Tabellen aufgenommen, dh es wird kein Stopp auftreten. Und dieser sehr problematische Ort ist eine Änderung in der Logik der Anwendung.
Was hat Edition-Based Redefinition damit zu tun? Und diese Technologie - es geht nur darum, wie Sie die Anwendung online und im laufenden Betrieb aktualisieren können, ohne die Arbeit der Benutzer zu beeinträchtigen.

Was sind die Anforderungen für dieses Online-Update? Wir müssen dies vom Benutzer unbemerkt tun, dh alles muss in einwandfreiem Zustand bleiben, alle Anwendungen. Vorausgesetzt, eine solche Situation kann auftreten, wenn sich der Benutzer hinsetzt, mit der Arbeit beginnt und sich scharf daran erinnert, dass er ein dringendes Meeting hatte oder das Auto zum Service bringen musste. Er stand auf und lief wegen seines Arbeitsplatzes aus. Und zu diesem Zeitpunkt haben wir unsere Anwendung irgendwie aktualisiert, die Arbeitslogik hat sich geändert, neue Benutzer haben sich bereits mit uns verbunden, die Daten wurden auf eine neue Art und Weise verarbeitet. Wir müssen also letztendlich den Datenaustausch zwischen der Originalversion der Anwendung und der neuen Version der Anwendung sicherstellen. Hier sind zwei Anforderungen, die für Online-Updates gestellt werden.

Was wird als Lösung vorgeschlagen? Ab Version 11.2 Release Oracle wird die Edition-Based Redefenition-Technologie eingeführt und Konzepte wie Edition, editierbare Objekte, Editionsansicht, Cross-Edition-Trigger eingeführt. Wir haben uns eine solche Übersetzung als "Versionierung" erlaubt. Im Allgemeinen kann die EBR-Technologie mit einer gewissen Ausdehnung als Versionierung von DBMS-Objekten innerhalb des DBMS selbst bezeichnet werden.
Was ist Edition als Ganzes?
Dies ist eine Art Container, in dem Sie den Code ändern und festlegen können. In Ihrem eigenen Bereich, in Ihrer eigenen Version. In diesem Fall werden die Daten nur in die Strukturen geändert und geschrieben, die in der aktuellen Ausgabe sichtbar sind. Versionsdarstellungen werden dafür verantwortlich sein, und wir werden ihre Arbeit weiter betrachten.

So sieht die Technologie draußen aus. Wie funktioniert das? Für den Anfang - auf Code-Ebene. Wir werden unsere ursprüngliche Anwendung, Version 1, haben, in der es einige Algorithmen gibt, die unsere Daten verarbeiten. Wenn wir verstehen, dass wir beim Erstellen einer neuen Edition ein Upgrade durchführen müssen, geschieht Folgendes: Alle Objekte, die den Code verarbeiten, werden in der neuen Edition geerbt ... Gleichzeitig können wir in dieser neu erstellten Sandbox unsichtbar Spaß haben, für den Benutzer: Wir können die Arbeit ändern Funktionen, Verfahren; Ändern Sie das Paket. Wir können sogar die Verwendung von Objekten verweigern.
Was wird passieren? Die Originalversion bleibt unverändert, steht dem Benutzer weiterhin zur Verfügung und alle Funktionen sind verfügbar. In der von uns erstellten Version in der neuen Ausgabe sind die nicht geänderten Objekte unverändert geblieben, dh von der ursprünglichen Version der Anwendung geerbt worden. Mit dem Block, den wir berührt haben, werden Objekte in der neuen Version aktualisiert. Und wenn Sie ein Objekt löschen, steht es uns in der neuen Version unserer Anwendung natürlich nicht zur Verfügung, aber es bleibt in der Originalversion funktionsfähig. So einfach funktioniert es auf Codeebene.

Was passiert mit Datenstrukturen und was hat die Versionsansicht damit zu tun?

Da wir unter Datenstrukturen eine Tabelle und eine Versionsansicht verstehen, handelt es sich in der Tat um eine Shell (ich habe mich das ethologische „Nachschlagen“ unserer Tabelle genannt), die eine Projektion auf die ursprünglichen Spalten darstellt. Wenn wir verstehen, dass wir den Betrieb unserer Anwendung ändern und beispielsweise Spalten zur Tabelle hinzufügen oder deren Verwendung sogar verbieten müssen, erstellen wir in unserer neuen Version eine neue Versionsansicht.

Dementsprechend werden wir darin nur den Satz von Spalten verwenden, den wir benötigen, den wir verarbeiten werden. In der Originalversion der Anwendung werden Daten in den in diesem Bereich definierten Satz geschrieben. Die neue Anwendung schreibt in den Satz von Spalten, der in ihrem Bereich definiert ist.

Die Strukturen sind klar, aber was passiert mit den Daten? Und wie all dies miteinander verbunden ist, hatten wir Daten in den ursprünglichen Strukturen gespeichert. Wenn wir verstehen, dass wir einen bestimmten Algorithmus haben, mit dem wir Daten aus der ursprünglichen Struktur konvertieren und diese Daten in eine neue Struktur zerlegen können, kann dieser Algorithmus in die sogenannten versionierungsübergreifenden Trigger eingefügt werden. Sie zielen nur darauf ab, Strukturen aus verschiedenen Versionen der Anwendung zu sehen. Das heißt, vorbehaltlich der Verfügbarkeit eines solchen Algorithmus können wir ihn an einen Tisch hängen. In diesem Fall werden Daten von den ursprünglichen Strukturen in neue transformiert, und progressive Vorwärtsauslöser sind dafür verantwortlich. Vorausgesetzt, wir müssen sicherstellen, dass die Daten auf die alte Version übertragen werden, sind wiederum Reverse-Trigger dafür verantwortlich, basierend auf einem Algorithmus.
Was passiert, wenn wir feststellen, dass sich unsere Datenstruktur geändert hat und wir bereit sind, sowohl für die alte Version der Anwendung als auch für die neue Version der Anwendung im parallelen Modus zu arbeiten? Wir können einfach das Füllen neuer Strukturen mit einem Leerlauf-Update initialisieren. Danach stehen unsere beiden Versionen der Anwendung dem Benutzer zur Verfügung. Die Funktionalität bleibt für alte Benutzer aus der alten Version der Anwendung erhalten, für neue Benutzer wird die Funktionalität aus der neuen Version der Anwendung übernommen.
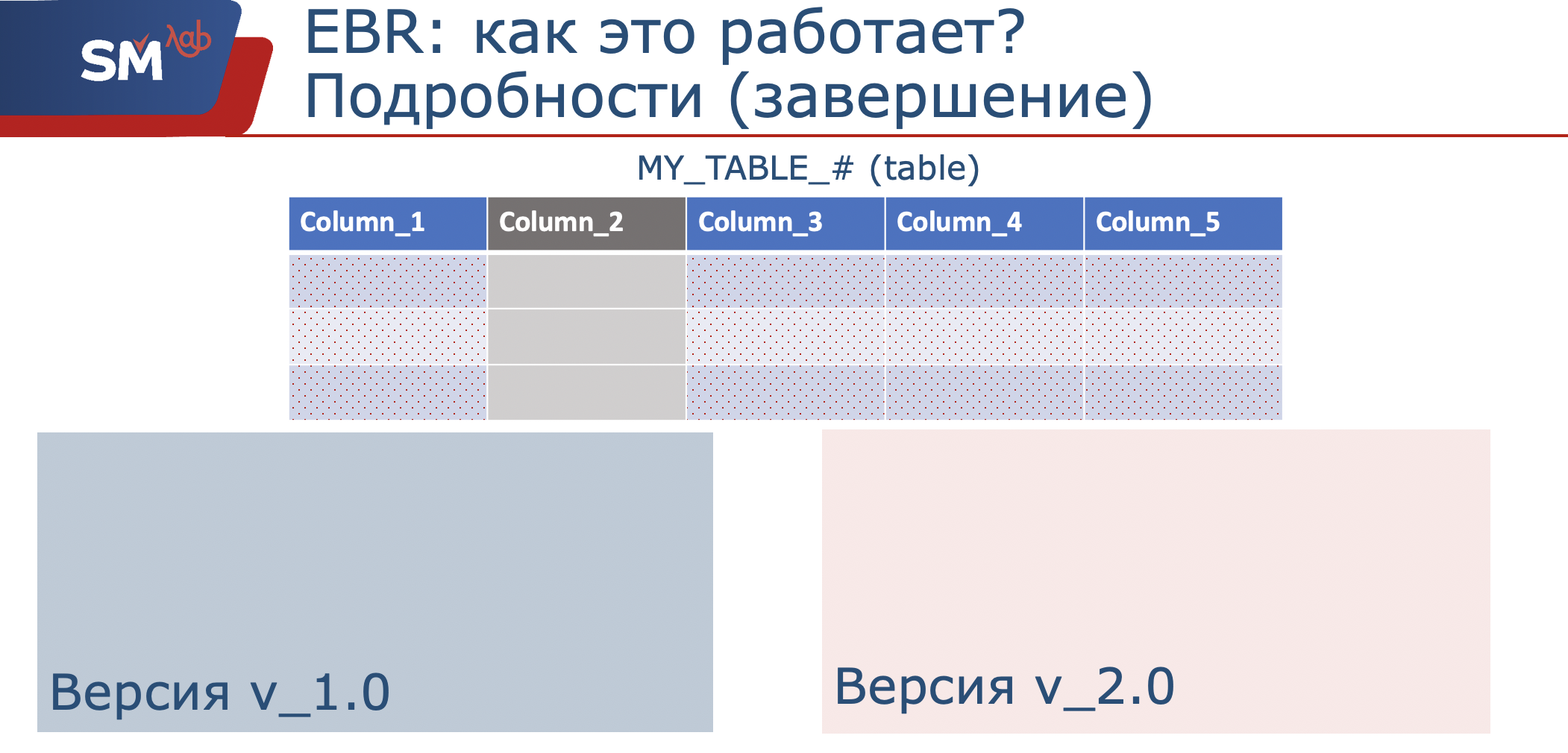
Als wir feststellten, dass Benutzer aus der alten Anwendung alle getrennt waren, konnte diese Version für die Verwendung ausgeblendet werden. Vielleicht wurde sogar die Datenstruktur geändert. Wir erinnern uns, dass bei uns die Versionsansicht in der neu erstellten Version bereits nur die Spalten 1, 3,4,5 betrachtet. Wenn wir diese Struktur nicht benötigen, kann sie gelöscht werden. Hier ist eine kurze Zusammenfassung, wie es funktioniert.

Was sind die auferlegten Einschränkungen? Das heißt, gut gemachtes Oracle, exzellentes Oracle, exzellentes Oracle: Sie haben sich eine coole Sache ausgedacht. Die erste Einschränkung im Moment sind Objekte vom versionierten Typ. Dies sind PL / SQL-Objekte, dh Prozeduren, Pakete, Funktionen, Trigger usw. Synonyme werden versioniert und Ansichten werden versioniert.
Was nicht versioniert ist und niemals versioniert wird, sind Tabellen und Indizes, materialisierte Ansichten. Das heißt, in der ersten Version ändern Sie und ich nur Metadaten und können Kopien davon so oft speichern, wie Sie möchten ... tatsächlich eine begrenzte Anzahl von Kopien dieser Metadaten, aber dazu später mehr. Die zweite betrifft Benutzerdaten, und ihre Replikation würde viel Speicherplatz erfordern, was nicht logisch und sehr teuer ist.

Die nächste Einschränkung besteht darin, dass die Schemaobjekte genau dann vollständig versioniert werden, wenn sie dem von der Version autorisierten Benutzer gehören. Tatsächlich sind diese Berechtigungen für den Benutzer nur eine Art Markierung in der Datenbank. Sie können diese Berechtigungen mit dem üblichen Befehl erteilen. Ich mache Sie jedoch darauf aufmerksam, dass diese Aktion irreversibel ist. Lassen Sie uns daher nicht sofort die Ärmel hochkrempeln, all dies auf dem Kampfserver eingeben und zuerst testen.
Die nächste Einschränkung besteht darin, dass nicht versionierte Objekte nicht von versionierten Objekten abhängen können. Das ist ziemlich logisch. Zumindest werden wir nicht verstehen, welche Edition, welche Version des Objekts wir betrachten sollen. Auf diesen Punkt möchte ich aufmerksam machen, weil wir mit diesem Moment konkurrieren mussten.
Weiter. Versionsansichten gehören dem Schemabesitzer, Tabellenbesitzer und nur in jeder Version. Eine versionierte Ansicht ist im Kern ein Tabellen-Wrapper. Es ist daher klar, dass sie in jeder Version der Anwendung eindeutig sein sollte.
Wichtig ist auch, dass die Anzahl der Versionen in der Hierarchie 2000 betragen kann. Dies liegt höchstwahrscheinlich daran, dass Sie das Wörterbuch nicht schwer laden. Ich sagte anfangs, dass Objekte beim Erstellen einer neuen Edition vererbt werden. Jetzt ist diese Hierarchie ausschließlich linear aufgebaut - ein Elternteil, ein Nachkomme. Vielleicht gibt es eine Art Baumstruktur. Ich sehe einige Voraussetzungen dafür darin, dass Sie den Befehl zur Versionserstellung als Erben einer bestimmten Edition festlegen können. Dies ist derzeit eine streng lineare Hierarchie, und die Anzahl der Glieder in dieser Kette beträgt 2000.
Es ist klar, dass bei einigen häufigen Upgrades unserer Anwendung diese Anzahl erschöpft oder überschritten werden kann. Ab der 12. Version von Oracle können die in dieser Kette erstellten extremen Editionen jedoch gekürzt werden, sofern sie nicht mehr verwendet werden.

Ich hoffe, Sie verstehen jetzt ungefähr, wie das funktioniert. Wenn Sie sich entscheiden - "Ja, wir möchten es berühren" -, was muss getan werden, um auf die Verwendung dieser Technologie umzusteigen?
Zuerst müssen Sie die Verwendungsstrategie bestimmen. Worum geht es? Verstehen Sie, wie oft sich unsere Tabellenstrukturen ändern, ob wir versionierte Ansichten verwenden müssen, insbesondere wenn wir versionierungsübergreifende Trigger benötigen, um Datenänderungen sicherzustellen. Oder wir werden nur unseren PL / SQL-Code versionieren. In unserem Fall haben wir beim Testen festgestellt, dass sich die Tabellen immer noch ändern, sodass wir wahrscheinlich auch versionierte Ansichten verwenden werden.
Ferner werden dem ausgewählten Schema natürlich versionierte Berechtigungen gewährt.
Danach benennen wir die Tabelle um. Warum wird das gemacht? Nur um unsere PL / SQL-Codeobjekte vor Änderungen von Tabellen zu schützen.
Angesichts der Beschränkung auf 30 Zeichen haben wir beschlossen, ein scharfes Symbol am Ende unserer Tabellen zu platzieren. Danach werden Versionsansichten mit dem ursprünglichen Tabellennamen erstellt. Und schon werden sie im Code verwendet. Es ist wichtig, dass in der ersten Version, zu der wir wechseln, die versionierte Ansicht ein vollständiger Satz von Spalten in der Quelltabelle ist, da PL / SQL-Codeobjekte auf alle diese Spalten genau gleich zugreifen können.
Danach überwiegen die DML-Trigger von Tabellen zu versionierten Ansichten (ja, versionierte Ansichten ermöglichen es uns, Trigger an sie zu hängen). Vielleicht widerrufen wir die Zuschüsse aus den Tabellen und geben sie an die neu erstellten Ansichten weiter ... Theoretisch reichen all diese Punkte aus, wir müssen nur den PL / SQL-Code und die abhängigen Ansichten neu kompilieren.
Ich-und-und-und-und ... Natürlich Tests, Tests und so viele Tests wie möglich. Warum testen? Es könnte nicht so einfach sein. Worüber sind wir gestolpert?
Darum geht es in
meinem zweiten Beitrag .