Die Fähigkeit, in einem Versionskontrollsystem zu arbeiten, ist eine Fähigkeit, die jeder Programmierer benötigt. Oft scheint es eine zusätzliche Zeitverschwendung zu sein, sich mit Git zu beschäftigen und seine Interna zu verstehen, und grundlegende Aufgaben können durch einen grundlegenden Befehlssatz gelöst werden.
Das AppsCast-Team wollte natürlich mehr wissen, und um Ratschläge zur praktischen Anwendung aller Funktionen von Git zu erhalten, wandten sich die Jungs von Square an
Yegor Andreyevich .
 Daniil Popov
Daniil Popov : Hallo allerseits. Heute ist Jegor Andreyevich vom Square zu uns gekommen.
Egor Andreyevich : Hallo allerseits. Ich lebe in Kanada und arbeite für Square, ein Software- und Hardwareunternehmen für die Finanzindustrie. Wir haben mit Terminals für die Annahme von Zahlungen mit Kreditkarten begonnen, jetzt bieten wir Dienstleistungen für Geschäftsinhaber an. Ich arbeite an einem Cash App-Produkt. Dies ist eine mobile Bank, mit der Sie Geld mit Freunden austauschen und eine Debitkarte für die Zahlung in Geschäften bestellen können. Das Unternehmen hat viele Büros auf der ganzen Welt und das kanadische Büro hat ungefähr 60 Programmierer.
Daniil Popov : In der Umgebung von Android-Entwicklern ist
Square für seine Open-Source-Projekte bekannt, die zu Industriestandards geworden sind: OkHttp, Picasso, Retrofit. Es ist logisch, dass Sie bei der Entwicklung solcher Tools, die für alle offen sind, viel mit Git arbeiten. Wir möchten darüber sprechen.
Was ist Schwachkopf?
Egor Andreevich : Ich benutze Git schon lange als Werkzeug und irgendwann wurde ich interessiert, mehr darüber zu erfahren.
Git ist ein vereinfachtes Dateisystem, zu dem eine Reihe von Operationen für die Arbeit mit der Versionskontrolle gehören.
Mit Git können Sie Dateien in einem bestimmten Format speichern. Jedes Mal, wenn Sie eine Datei schreiben, gibt Git den Schlüssel für Ihr Objekt zurück -
Hash .
Daniil Popov : Viele Leute haben bemerkt, dass das Repository ein magisches verstecktes Verzeichnis hat
.git . Warum wird es benötigt? Kann ich es löschen oder umbenennen?
Egor Andreevich : Das Erstellen eines Repositorys ist über den Befehl
git init möglich. Es erstellt das
.git- Verzeichnis, mit dem Git Dateien steuert.
.Git speichert alles, was Sie in Ihrem Projekt tun, nur in einem komprimierten Format. Daher können Sie das Repository aus diesem Verzeichnis wiederherstellen.
Alexei Kudryavtsev : Es stellt sich heraus, dass Ihr Projektordner eine der Versionen des erweiterten Git-Ordners ist?
Egor Andreevich : Je nachdem, in welchem Zweig Sie sich befinden, stellt git ein Projekt wieder her, mit dem Sie arbeiten können.
Alexei Kudryavtsev : Was ist in dem Ordner?
Egor Andreevich : Git erstellt bestimmte Ordner und Dateien. Der wichtigste Ordner ist .git / properties, in dem alle Objekte gespeichert sind. Das einfachste Objekt ist Blob, im Wesentlichen dasselbe wie eine Datei, jedoch in einem Format, das Git versteht. Wenn Sie eine Textdatei im Repository speichern möchten, komprimiert Git sie, archiviert sie, fügt Daten hinzu und erstellt einen Blob.
Es gibt Verzeichnisse - dies sind Ordner mit Unterordnern, d. H. Git hat einen Baumobjekttyp, der Verweise auf Blob und andere Bäume enthält.
Grundsätzlich ist ein Baum eine Momentaufnahme, die den Status Ihres Verzeichnisses an einem bestimmten Punkt beschreibt.
Beim Erstellen eines Commits ist ein Link zum Arbeitsverzeichnis fest - Baum.
Ein Commit ist ein Link zu einem Baum mit Informationen darüber, wer ihn erstellt hat: E-Mail, Name, Erstellungszeit, Link zum übergeordneten Element (übergeordneter Zweig) und Nachricht. Git komprimiert und schreibt Commits in das Objektverzeichnis.
Um zu sehen, wie dies alles funktioniert, müssen Sie die Unterverzeichnisse über die Befehlszeile auflisten.
Vorteile der Arbeit mit Git
Daniil Popov : Wie funktioniert Git? Warum ist der Aktionsalgorithmus so kompliziert?
Egor Andreevich : Wenn Sie Git mit Subversion (SVN) vergleichen, gibt es im ersten System eine Reihe von Funktionen, die Sie verstehen müssen. Ich beginne mit dem
Staging-Bereich , der nicht als Einschränkung von Git, sondern als Funktionen angesehen werden sollte.
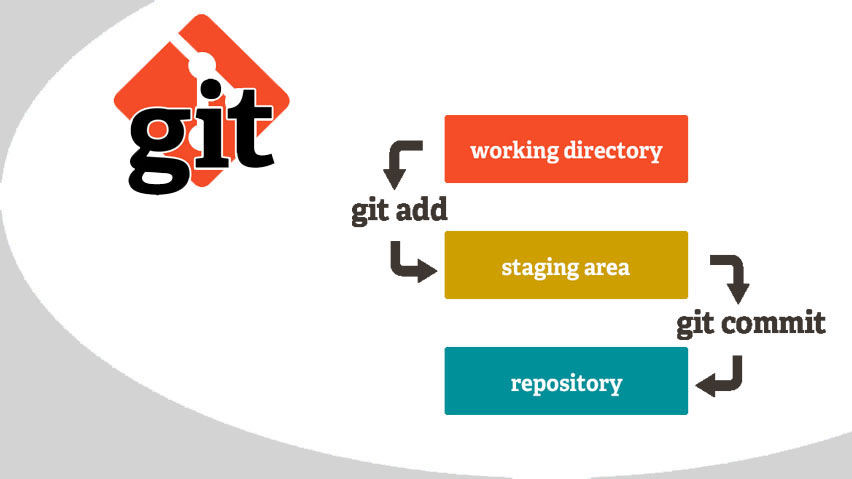
Es ist bekannt, dass bei der Arbeit mit Code nicht alles sofort funktioniert: Irgendwo müssen Sie das Layout ändern, irgendwo, um Fehler zu beheben. Infolgedessen werden nach einer Arbeitssitzung eine Reihe betroffener Dateien angezeigt, die nicht miteinander verbunden sind. Wenn Sie alle Änderungen in einem Commit vornehmen, ist dies unpraktisch, da die Änderungen unterschiedlicher Natur sind. Dann kommt eine Reihe von Commits zur Ausgabe, die nur dank des Staging-Bereichs erstellt werden können. Beispielsweise werden alle Änderungen an der Layoutdatei an eine Serie gesendet, z. B. Unit-Tests an eine andere. Wir nehmen mehrere Dateien, verschieben sie in den Staging-Bereich und erstellen nur mit ihrer Teilnahme ein Commit. Andere Dateien aus dem Arbeitsverzeichnis fallen nicht hinein. Auf diese Weise teilen Sie alle im Arbeitsverzeichnis ausgeführten Arbeiten in mehrere Commits auf, von denen jede eine bestimmte Arbeit darstellt.
Alexei Kudryavtsev : Wie unterscheidet sich Git von anderen Versionskontrollsystemen?
Egor Andreevich : Ich persönlich habe mit SVN angefangen und bin dann sofort zu Git gewechselt. Wichtig ist, dass Git ein dezentrales Versionskontrollsystem ist. Alle Kopien des Git-Repositorys sind genau gleich. Jedes Unternehmen verfügt über einen Server, auf dem sich die Hauptversion befindet. Dieser unterscheidet sich jedoch nicht von dem Server, den der Entwickler auf dem Computer installiert hat.
SVN verfügt über ein zentrales Repository und lokale Kopien. Dies bedeutet, dass jeder Entwickler das zentrale Repository alleine beschädigen kann.
In Git wird dies nicht passieren. Wenn der zentrale Server die Repository-Daten verliert, können sie von jeder lokalen Kopie wiederhergestellt werden. Git ist anders gestaltet und bietet die Vorteile der Geschwindigkeit.
Daniil Popov : Git ist berühmt für seine Verzweigung, die spürbar schneller läuft als SVN. Wie macht er das?
Egor Andreevich : In SVN ist ein Zweig eine vollständige Kopie des vorherigen Zweigs. In Git gibt es keine physische Zweigdarstellung. Dies ist ein Link zum letzten Commit in einer bestimmten Entwicklungslinie. Wenn Git Objekte speichert, erstellt es beim Erstellen eines Commits eine Datei mit spezifischen Informationen zum Commit. Git erstellt eine symbolische Datei - Symlink mit einem Link zu einer anderen Datei. Wenn Sie viele Zweige haben, verweisen Sie auf verschiedene Commits im Repository. Um den Verlauf eines Zweigs zu verfolgen, müssen Sie von jedem Commit über den Link zurück zum übergeordneten Commit wechseln.
Merjim Zweige
Daniil Popov : Es gibt zwei Möglichkeiten, zwei Zweige zu einem zusammenzuführen - das ist Zusammenführen und Wiederherstellen. Wie benutzt du sie?
Egor Andreevich : Jede Methode hat ihre Vor- und Nachteile.
Zusammenführen ist die einfachste Option. Zum Beispiel gibt es zwei Zweige: Master und das daraus ausgewählte Feature.
Zum Zusammenführen können Sie den Schnellvorlauf verwenden. Dies ist möglich, wenn ab dem Zeitpunkt, an dem die Arbeit im Feature-Zweig begonnen wurde, keine neuen Commits im Master vorgenommen wurden. Das heißt, das erste Commit in Feature ist das letzte Commit im Master.
In diesem Fall ist der Zeiger auf dem Hauptzweig fixiert und wechselt zum letzten Commit im Feature-Zweig. Auf diese Weise wird die Verzweigung beseitigt, indem der Feature-Zweig mit dem Haupt-Master-Thread verbunden und der unnötige Zweig entfernt wird. Es stellt sich eine lineare Geschichte heraus, in der alle Commits aufeinander folgen. In der Praxis kommt diese Option selten vor, da ständig jemand Commits zum Master zusammenführt.
Es kann auch anders sein. Git erstellt ein neues Commit - Merge Commit, das zwei Links zu übergeordneten Commits enthält: einen im Master und einen im Feature. Mit dem neuen Commit werden zwei Zweige verbunden und die Funktion kann wieder gelöscht werden.
Nach dem Zusammenführungs-Commit können Sie sich die Story ansehen und feststellen, dass sie gegabelt ist. Wenn Sie ein Tool verwenden, das Commits grafisch darstellt, sieht es visuell wie ein Weihnachtsbaum aus. Dies bricht Git nicht, aber es ist für einen Entwickler schwierig, eine solche Geschichte zu sehen.
Ein weiteres Tool ist
Rebase . Konzeptionell nehmen Sie alle Änderungen aus dem Feature-Zweig und drehen sie über den Master-Zweig. Das erste Feature-Commit wird zum neuen Commit zusätzlich zum letzten Master-Commit.
Es gibt einen Haken: Git kann Commits nicht ändern. Es gab ein Commit in der Funktion und wir können es nicht einfach über den Master wickeln, da jedes Commit einen Zeitstempel hat.
Im Falle einer Neubasis liest Git alle Commits in der Funktion, speichert sie vorübergehend und erstellt sie dann in der gleichen Reihenfolge im Master neu. Nach der erneuten Basisung verschwinden die anfänglichen Festschreibungen, und neue Festschreibungen mit demselben Inhalt werden über dem Master angezeigt. Es gibt Probleme. Wenn Sie versuchen, einen Zweig, mit dem andere Personen arbeiten, neu zu gründen, können Sie das Repository beschädigen. Zum Beispiel, wenn jemand seinen Zweig von einem Commit gestartet hat, das in der Funktion enthalten war, und Sie dieses Commit zerstört und neu erstellt haben. Rebase ist besser für lokale Niederlassungen geeignet.
Daniil Popov : Wenn Sie Einschränkungen einführen, nach denen ausschließlich eine Person an einem Feature-Zweig arbeitet, stimmen Sie zu, dass Sie nicht einen Feature-Zweig von einem anderen trennen können, dann tritt dieses Problem nicht auf. Aber welchen Ansatz üben Sie?
Egor Andreevich : Wir verwenden keine Feature-Zweige im direkten Sinne dieses Begriffs. Jedes Mal, wenn wir eine Änderung vornehmen, erstellen Sie einen neuen Zweig, arbeiten darin und gießen ihn sofort in den Master. Es gibt keine langjährigen Zweige.
Dies löst eine große Anzahl von Problemen beim Zusammenführen und Wiederherstellen, insbesondere bei Konflikten. Zweige bestehen für eine Stunde und es besteht eine hohe Wahrscheinlichkeit, dass der schnelle Vorlauf verwendet wird, da niemand dem Master etwas hinzugefügt hat. Wenn wir eine Pull-Anforderung zusammenführen, wird nur das Erstellen eines Zusammenführungs-Commits zusammengeführt
Daniil Popov : Wie haben Sie keine Angst davor, eine Master-Leerlauffunktion zusammenzuführen, weil es oft unrealistisch ist, eine Aufgabe in stündliche Intervalle zu zerlegen?
Egor Andreevich : Wir verwenden den
Feature-Flags- Ansatz. Dies sind dynamische Flags, ein spezifisches Merkmal mit unterschiedlichen Zuständen. Beispielsweise ist die Funktion zum Senden von Zahlungen aneinander entweder aktiviert oder deaktiviert. Wir haben einen Service, der diesen Status dynamisch an Kunden liefert. Sie erhalten vom Server die Funktion "Wert aus" oder nicht. Sie können diesen Wert im Code verwenden - schalten Sie die Schaltfläche aus, die zum Bildschirm führt. Der Code selbst befindet sich in der Anwendung und kann freigegeben werden, es besteht jedoch kein Zugriff auf diese Funktionalität, da er sich hinter dem Feature-Flag befindet.
Daniil Popov : Oft wird Neulingen bei Git gesagt, dass man nach dem Rebase mit Gewalt pushen muss. Woher kommt es?
Egor Andreevich : Wenn Sie nur pushen, kann ein anderes Repository einen Fehler auslösen: Sie versuchen, einen Zweig auszuführen, aber Sie haben völlig andere Commits für diesen Zweig. Git überprüft alle Informationen, damit Sie das Repository nicht versehentlich beschädigen. Wenn Sie
git push force sagen, schalten Sie diesen Check aus, weil Sie glauben, dass Sie es besser wissen als er, und fordern Sie, den Zweig neu zu schreiben.
Warum wird dies nach dem Rebase benötigt? Rebase erstellt Commits neu. Es stellt sich heraus, dass der Zweig auch aufgerufen wird, sich aber mit anderen Hashes darin festlegt, und Git schwört auf dich. In dieser Situation ist es absolut normal, einen Kraftstoß auszuführen, da Sie die Kontrolle über die Situation haben.
Daniil Popov : Es gibt immer noch das Konzept der
interaktiven Rebase , und viele haben Angst davor.
Egor Andreevich : Es gibt nichts Schreckliches. Aufgrund der Tatsache, dass Git die Story während des Rebases neu erstellt, speichert sie sie vorübergehend, bevor sie geworfen wird. Wenn es temporären Speicher hat, kann es alles mit Commits machen.
Beim erneuten Basieren im interaktiven Modus wird davon ausgegangen, dass Git vor dem erneuten Basieren ein Fenster eines Texteditors öffnet, in dem Sie angeben können, was mit jedem einzelnen Commit getan werden muss. Es sieht aus wie mehrere Textzeilen, wobei jede Zeile eine der Festschreibungen in der Verzweigung ist. Vor jedem Commit gibt es einen Hinweis auf die Operation, die es wert ist, ausgeführt zu werden. Die einfachste Standardoperation ist
pick , d. H. zu nehmen und in Rebase aufzunehmen. Am häufigsten wird
Squash verwendet , dann übernimmt Git die Änderungen aus diesem Commit und führt sie mit den Änderungen aus dem vorherigen zusammen.
Oft gibt es ein solches Szenario. Sie haben lokal in Ihrer Niederlassung gearbeitet und Commits für das Speichern erstellt. Das Ergebnis ist eine lange Geschichte von Commits, die für Sie interessant ist, aber auf die gleiche Weise nicht in die Hauptgeschichte aufgenommen werden sollte. Dann geben Sie Squash, um das allgemeine Commit umzubenennen.
Die Liste der Teams ist lang. Sie können den Commit-
Drop auslösen und er verschwindet, Sie können die Commit-Nachricht ändern usw.
Alexei Kudryavtsev : Wenn Sie Konflikte bei der interaktiven Rebase haben, gehen Sie durch alle Kreise der Hölle.
Egor Andreevich : Ich bin weit davon entfernt, alle Weisheiten des interaktiven Rebases zu verstehen, aber es ist ein mächtiges und komplexes Werkzeug.
Praktische Git-Anwendung
Daniil Popov : Lass uns weiter üben. Beim Interview frage ich oft: „Sie haben tausend Commits. Am ersten ist alles in Ordnung, am tausendsten Test brach. Wie kann man mit Hilfe einer Gita die Veränderung finden, die dazu geführt hat? “
Egor Andreevich : In dieser Situation müssen Sie die
Halbierung verwenden , obwohl es einfacher ist, die Schuld zu tragen.
Beginnen wir mit dem interessanten. Git bisect ist auf eine Situation anwendbar, in der Sie eine Regression haben - es war funktionsfähig, es hat funktioniert, aber es hat plötzlich aufgehört. Um festzustellen, wann die Funktionalität fehlerhaft ist, können Sie theoretisch nach dem Zufallsprinzip zur vorherigen Version der Anwendung zurückkehren und sich den Code ansehen. Es gibt jedoch ein Tool, mit dem Sie das Problem strukturiert angehen können.
Git bisect ist ein interaktives Tool. Es gibt einen Befehl "git bisect bad bad", mit dem Sie über das Vorhandensein eines fehlerhaften Commits und git bisect good berichten - für einen funktionierenden Commit. Jedes Mal, wenn die Anwendung freigegeben wird, erinnern wir uns an den Hash des Commits, aus dem die Freigabe erfolgt ist. Dieser Hash kann auch verwendet werden, um schlechte und gute Commits anzuzeigen. Bisect erhält Informationen über das Intervall, in dem eines der Commits die Funktionalität unterbrochen hat, und startet die
binäre Suchsitzung, in der nach und nach Commits ausgegeben werden, um zu überprüfen, ob sie funktionieren oder nicht.
Sie haben die Sitzung gestartet, Git wechselt zu einem der Commits im Intervall und meldet dies. Bei tausend Commits wird es nicht viele Iterationen geben.
Die Überprüfung muss manuell erfolgen: durch Komponententests oder führen Sie die Anwendung aus und klicken Sie manuell. Git bisect ist bequem skriptfähig. Jedes Mal, wenn er ein Commit ausgibt, geben Sie ihm ein Skript, um zu überprüfen, ob der Code funktioniert.
Schuld ist ein einfacheres Werkzeug, mit dem Sie anhand seines Namens den "Schuldigen" eines Funktionsfehlers finden können. Aufgrund dieser negativen Definition mögen es viele in der Schuldgemeinschaft nicht.
Was macht er? Wenn Sie einer bestimmten Datei die Schuld geben, zeigt sie linear in dieser Datei an, welches Commit diese oder jene Zeile geändert hat. Ich habe noch nie Git-Schuld von der Kommandozeile aus benutzt. Dies geschieht in der Regel in IDEA oder Android Studio. Klicken Sie auf und sehen Sie, wer welche Zeile der Datei und in welchem Commit geändert hat.
Daniil Popov : Übrigens hieß es in Android Studio Annotate. Die negative Konnotation der Schuld wurde entfernt.
Alexei Kudryavtsev : Genau, in xCode haben sie es in Autoren umbenannt.
Egor Andreevich : Ich habe auch gelesen, dass es ein Utility-Git-Lob gibt - denjenigen zu finden, der diesen hervorragenden Code geschrieben hat.
Daniil Popov : Es sollte beachtet werden, dass auf Schuld Vorschläge von Rezensenten auf Pull-Request-Arbeit. Er sieht sich an, wer eine bestimmte Datei am meisten berührt hat, und schlägt vor, dass diese Person Ihren Code gut überprüfen kann.
Im Fall von etwa tausend Commits zeigt die Schuld in 99% der Fälle, was schief gelaufen ist. Bisect ist bereits der letzte Ausweg.
Egor Andreevich : Ja, ich greife extrem selten auf Halbierung zurück, aber ich benutze regelmäßig Anmerkungen. Obwohl es manchmal unmöglich ist zu verstehen, warum es in der Codezeile auf Null gesetzt ist, ist während des gesamten Commits klar, was der Autor tun wollte.
Wie arbeite ich mit gestapelten PRs?
Daniil Popov : Ich habe gehört, dass Square Stacked Pull Requests (PRs) verwendet.
Egor Andreevich : Zumindest in unserem Android-Team verwenden wir sie oft.
Wir verwenden viel Zeit, um die Überprüfung jeder Pull-Anfrage zu vereinfachen. Manchmal besteht die Versuchung, schnell zu füttern und die Prüfer zu verstehen. Wir versuchen, kleine Pull-Anfragen und eine kurze Beschreibung zu erstellen - der Code sollte für sich selbst sprechen. Wenn Pull-Anfragen klein sind, ist es einfach und schnell zu brüllen.
Hier tritt das Problem auf. Sie arbeiten an einer Funktion, die eine große Anzahl von Änderungen in der Codebasis erfordert. Was kannst du tun Sie können es in eine Pull-Anfrage einfügen, aber dann wird es riesig. Sie können arbeiten, indem Sie nach und nach eine Pull-Anforderung erstellen. Das Problem besteht jedoch darin, dass Sie einen Zweig erstellt, einige Änderungen hinzugefügt und eine Pull-Anforderung gesendet, an den Master zurückgegeben und der Code, den Sie in der Pull-Anforderung hatten, erst im Master verfügbar sind Zusammenführung wird nicht stattfinden. Wenn Sie auf Änderungen in diesen Dateien angewiesen sind, ist es schwierig, weiter zu arbeiten, da es keinen solchen Code gibt.
Wie kommen wir darum herum? Nachdem wir die erste Pull-Anforderung erstellt haben, arbeiten wir weiter und erstellen einen neuen Zweig aus dem vorhandenen Zweig, den wir vor der Pull-Anforderung verwendet haben. Jeder Zweig stammt nicht vom Master, sondern vom vorherigen Zweig. Wenn wir mit der Arbeit an dieser Funktionalität fertig sind, senden wir eine weitere Pull-Anfrage und geben erneut an, dass sie beim Zusammenführen nicht im Master, sondern im vorherigen Zweig zusammengeführt wird. Es stellt sich heraus, dass es eine solche Kette von Pull-Anfragen gibt - gestapelte Prs. Wenn eine Person überarbeitet, sieht sie die Änderungen, die nur durch diese Funktion vorgenommen wurden, nicht jedoch durch die vorherige.
Die Aufgabe besteht darin, jede Pull-Anforderung so klein und klar wie möglich zu gestalten, damit keine Änderungen erforderlich sind. Denn wenn Sie den Code in den Zweigen ändern müssen, die sich in der Mitte des Stapels befinden, wird alles oben kaputt gehen, da Sie eine Neubasis durchführen müssen. Wenn Pull-Anforderungen klein sind, versuchen wir, sie so schnell wie möglich einzufrieren. Anschließend werden alle gestapelten Anforderungen Schritt für Schritt in den Master eingefügt.
Daniil Popov : Ich verstehe richtig, dass es am Ende eine letzte Pull-Anfrage geben wird, die alle kleinen Pull-Anfragen enthält. Sie gießen diesen Faden ohne zu schauen?
Egor Andreevich : Zusammenführen kommt von der gestapelten Quelle: Zuerst wird die allererste Pull-Anforderung im Master zusammengeführt, im nächsten ändert sich die Basis von Zweig zu Master, und dementsprechend berechnet Git, dass es bereits einige Änderungen im Master gibt, weniger Snapshot.
Alexei Kudryavtsev : Haben Sie eine Rennbedingung, wenn der erste Zweig bereits gestoppt hat und erst danach der zweite im ersten gestoppt hat, weil das Ziel nicht geändert wurde, um es zu meistern?
Egor Andreevich : Wir halten es von Hand, es gibt also keine solchen Situationen. Ich öffne eine Pull-Anfrage, notiere die Kollegen, von denen ich eine Bewertung erhalten möchte, und wenn sie bereit sind, gehe zu Bitbucket und drücke Merge.
Alexei Kudryavtsev : Aber was ist mit der Überprüfung von CI, dass nichts kaputt ist?
Egor Andreevich : Das machen wir nicht. CI wird auf dem Zweig ausgeführt, der die Basis für die Pull-Anforderung darstellt, und nach Überprüfung überprüfen wir die Basis. Technisch ändert sich nichts, da Sie auch die Anzahl der Änderungen festlegen.
Daniil Popov : Drängst du direkt in den Meister ein oder entwickelst du dich? Und wenn Sie freigeben, geben Sie explizit das Commit an, von dem gesammelt werden soll?
Egor Andreevich : Wir haben uns nicht entwickelt, nur Meister. Wir werden definitiv alle zwei Wochen veröffentlichen. Wenn wir mit der Vorbereitung eines Releases beginnen, öffnen wir einen Release-Zweig und einige letzte Korrekturen gehen sowohl an den Master als auch an diesen Zweig. Wir verwenden Tags - permanente Links zu einem bestimmten Commit, optional mit einigen Informationen. Wenn es sich bei einem Commit um ein Release-Commit handelt, wäre es schön, in der Historie zu bleiben, dass wir ein Release von diesem Commit erstellt haben. Ein Tag wird erstellt, Git speichert die Versionsinformationen und Sie können später darauf zurückgreifen.
Alexei Kudryavtsev : Wo kann man Git unterrichten, was soll man lesen?
Egor Andreevich : Git hat ein
offizielles Buch . Ich mag die Art und Weise, wie es geschrieben steht, es gibt gute Beispiele. Es gibt ein Kapitel über die Innenseiten, Sie können es gründlich studieren. Auf StackOverflow finden Sie viele esoterische Situationen und Lösungen. Sie können auch verwendet werden.
Wir werden auf der kommenden Saint AppsConf nicht über Git sprechen . Auf der anderen Seite haben wir uns für ein Experiment entschieden und dem ereignisreichen Konferenzprogramm Einführungsberichte hinzugefügt, in denen Referenten aus verwandten Entwicklungsbranchen Wissen austauschen, um den Horizont eines mobilen Entwicklers zu erweitern. Wir empfehlen Ihnen, auf die Präsentation von Nikolai Golov von Avito zu Datenbanken zu achten : Wie Sie keinen Fehler machen und die richtige Datenbank auswählen, wie Sie sich auf das Wachstum vorbereiten und was 2019 relevant ist.
AppsCast wird mittwochs alle zwei Wochen veröffentlicht. Wenn Sie die Soundversion der Textversion vorziehen, abonnieren Sie uns in SoundCloud und diskutieren Sie Themen in unserem Chat .